7. Reference Guide
The reference guide walks through WD Fusion's various screens, providing a basic explanation of what everything does. For specific instruction on how to perform a particular task, you should view the Admin Guide
7.1 Technical Overview
What is WANdisco Fusion
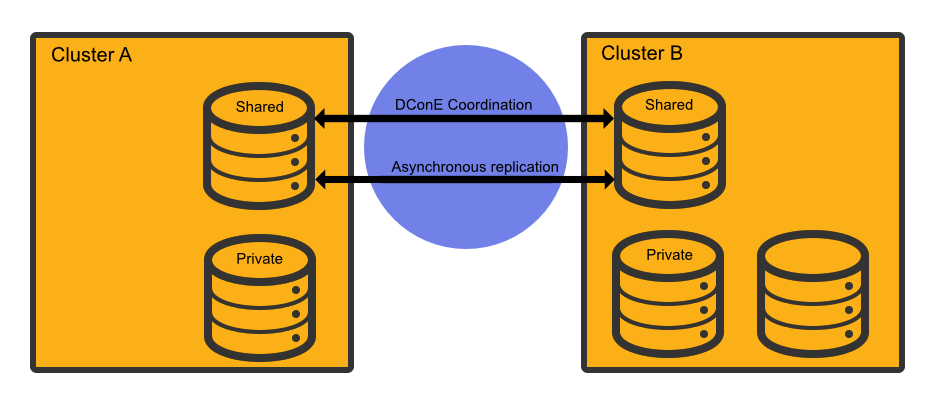
WANdisco Fusion (WD Fusion) shares data between two or more clusters. Shared data is replicated between clusters using DConE, WANdisco's proprietory coordination engine. This isn't a spin on mirroring data, every cluster can write into the shared data directories and the resulting changes are coordinated in real-time between clusters.
100% Reliablity
Paxos-based algorithms enable DConE to continue to replicate even after brief networks outages, data changes will automatically catch up once connectivity between clusters is restored.
Below the coordination stream, actual data transfer is done as an asynchronous background process and doesn't consume MapReduce resources.
Replication where and when you need
WD Fusion supports Selective replication, where you control which data is replicated to particular clusters, based on your security or data management policies. Data can be replicated globally if data is available to every cluster or just one cluster.
The Benefits of WANdisco Fusion
- Ingest data to any cluster, sharing it quickly and reliably with other clusters. Removing fragile data transfer bottlenecks, and letting you process data at multiple places improving performance and getting you more utilization from backup clusters.
- Support a bimodal or multimodal architecture to enable innovation without jeopardizing SLAs. Perform different stages of the processing pipeline on the best cluster. Need a dedicated high-memory cluster for in-memory analytics? Or want to take advantage of an elastic scale-out on a cheaper cloud environment? Got a legacy application that's locked to a specific version of Hadoop? WANdisco Fusion has the connections to make it happen. And unlike batch data transfer tools, WANdisco Fusion provides fully consistent data that can be read and written from any site.
- Put away the emergency pager. If you lose data on one cluster, or even an entire cluster, WANdisco Fusion has made sure that you have consistent copies of the data at other locations.
- Set up security tiers to isolate sensitive data on secure clusters, or keep data local to its country of origin.
- Perform risk-free migrations. Stand up a new cluster and seamlessly share data using WANdisco Fusion. Then migrate applications and users at your leisure, and retire the old cluster whenever you're ready.
7.2 A Primer on Paxos
Replication networks are composed of a number of nodes, each node takes on one of a number of roles:
Acceptors (A)
The Acceptors act as the gatekeepers for state change and are collected into groups called Quorums. For any proposal to be accepted, it must be sent to a Quorum of Acceptors. Any proposal received from an Acceptor node will be ignored unless it is received from each Acceptor in the Quorum.
Proposers (P)
Proposer nodes are responsible for proposing changes, via client requests, and aims to receive agreement from a majority of Acceptors.
Learners (L)
Learners handle the actual work of replication. Once a Client request has been agreed on by a Quorum the Learner may take the action, such as executing a request and sending a response to the client. Adding more learner nodes will improve availability for the processing.
Distinguished Node
It's common for a Quorum to be a majority of participating Acceptors. However, if there's an even number of nodes within a Quorum this introduces a problem: the possibility that a vote may tie. To handle this scenario a special type of Acceptor is available, called a Distinguished Node. This machine gets a slightly larger vote so that it can break 50/50 ties.
7.3 Paxos Node Roles in DConE
When setting up your WD Fusion servers they'll all be Acceptors, Proposers and Learners. In a future version of the product you'll then be able to modify each WD Fusion server's role to balance between resilience and performance, or to remove any risk of a tied vote.
7.3.1 Creating resilient Memberships
WD Fusion is able to maintain HDFS replication even after the loss of WD Fusion nodes from a cluster. However, there are some configuration rules that are worth considering:
Rule 1: Understand Learners and Acceptors
The unique Active-Active replication technology used by WD Fusion is an evolution of the Paxos algorithm, as such we use some Paxos concepts which are useful to understand:
Learners:
Learners are the WD Fusion nodes that are involved in the actual replication of Namespace data. When changes are made to HDFS metadata these nodes raise a proposal for the changes to be made on all the other copies of the filesystem space on the other data centers running WD Fusion within the membership.Learner nodes are required for the actual storage and replication of hdfs data. You need a learner node where ever you need to store a copy of the shared hdfs data.
-
Acceptors:
All changes being made in the replicated space at each data center must be made in exactly the same order. This is a crucial requirement for maintaining synchronization. Acceptors are nodes that take part in the vote for the order in which proposals are played out.
Acceptor Nodes are required for keeping replication going. You need enough Acceptors to ensure that agreement over proposal ordering can always be met, even after accounting for possible node loss. For configurations where there are a an even number of Acceptors it is possible that voting could become tied. For this reason it is possible to make an Acceptor node into a tie-breaker which has slightly more voting power so that it can outvote another single Acceptor node.
Rule 2: Replication groups should have a minimum membership of three learner nodes
Two-node clusters (running two WD Fusion servers) are not fault tolerant, you should strive to replicate according to the following guideline:
The number of learner nodes required to survive population loss of N nodes = 2N+1
where N is your number of nodes.So in order to survive the loss of a single WD Fusion server equipped datacenter you need to have a minium of 2x1+1= 3 nodes
In order to keep on replicating after losing a second node you need 5 nodes.
Rule 3: Learner Population - resilience vs rightness
During the installation of each of your nodes you can configure the Content Node Count number, this is the number of other learner nodes in the replication group that need to receive the content for a proposal before the proposal can be submitted for agreement.
Setting this number to 1 ensures that replication won't halt if some nodes are behind and have not received replicated content yet. This strategy reduces the chance that a temporary outage or heavily loaded node will stop replication, however, it also increases the risk that namenode data will go out of sync (requiring admin-intervention) in the event of an outage.
Rule 4: 2 nodes per site provides resilience and performance benefits
Running with two nodes per site provides two important advantages.
- Firstly it provides every site with a local hot-backup of the namenode data.
- Enables a site to load-balance namenode access between the nodes which can improve performance during times of heavy usage.
- Providing the nodes are Acceptors, it increases the population of nodes that can form agreement and improves resilience for replication.
Replication Frequently Asked Questions
What stops a file replication between zones from failing if an operation such as a file name change is done on a file that is still transferring to another zone?
Operations, such as a rename only affects metadata, so long as the file's underlying data isn't changed, the operation to transfer the file will complete. Only then will the rename operation play out. When you start reading a file for the first time you acquire all the block locations necessary to fulfill the read, at this point metadata changes won't halt the transfer of the file to another zone.
7.4 Agreement recovery in WD Fusion
This section explains why when monitoring replication recovery, it may be possible to see a brief delay and seemingly out-of-order delivery of proposals at the catching-up node.
In the event that the WAN link between clusters is temporarily dropped, it may be noticed that when the link returns, there's a brief delay before the reconnected zones are back in sync and it may appear that recovery is happening with agreements being made out of order, in terms of the global sequence numbers (GSNs) associated with each agreement.
This behavior can be explained as follows:
- "non-writer" nodes review the GSNs to determine which agreements the current writer has processed and which agreements they can remove from their own store, where they are kept in case the writer node fails and they have to take over.
- when a new writer is elected, the presence/absence of a particular GSN tells the new writer which agreements can be skipped. There may be gaps in this sequence as not all propsals are filesystem operations. For example, writer and leader election proposials are not filesystem operations, therefore their GSNs are not written to the underlying filesystem.
Why are proposals seemingly being delivered out-of-order?
This is related and why you will see gsn's written "out-of-order" in the filesystem. Internally within Fusion "non-interfering" agreements are processed in parallel so we can increase throughout and the global sequence is not blocked on operations that may take a long time, such as a large file copy.
Example
Consider the following global sequence, where /repl1 is the replicated directory:
- Copy 10TB file to
/repl1/dir1/file1 - Copy 10TB file to
/repl1/dir2/file1 - Chown
/repl/dir1
Agreements 1. and 2. may be executed in parallel since they do not interfere with one-another. However, agreement 3. must wait for agreement 1 to complete before it can be applied to the filesystem. If agreement 2 completes before 1 then its gsn will be recorded before the preceding agreement and look on the surface like out-of-order delivery of GSNs.
Under the hood
DConE's Output Proposal Sequence (OPS) delivers agreed values in strict sequence, one-at-a-time, to an application. Applying these values to the application state in the sequence delivered by the OPS ensures the state is consistent with other replicas at that point in the sequence. However, an optimization can be made: if two or more values do not interfere with one another (see below for definition of 'interfere') they may be applied in parallel without adverse effects. This parallelization has several benefits, for example:
- It may increase the rate of agreed values applied to the application state if there are many non-interfering agreements;
- It avoids an agreement that takes a long time to complete (such as a large file transfer) from blocking later agreements that aren't dependent on that agreement having completed.
8. WD Fusion Configuration
This section lists the available configuration for WD Fusion's component applications. You should take care when making any configuration changes on your clusters.
8.1 WD Fusion Server
WD Fusion server configuration is stored in two files:/etc/wandisco/fusion/server/application.properties| Property | Description | Permitted Values | Default | Checked at... |
| application.port | The port DConE uses for communication. | 1-65535 | 6444 | Startup |
| dcone.system.db.panic.if.dirty | If set to true and the DConE system database was not shut down 'cleanly' (i.e., the prevaylers weren't closed) then on restart the server will not start. | true or false | true | Startup |
| application.integration.db.panic.if.dirty | If set to true and the application integration database was not shut down cleanly (with the prevaylers closed) then on restart the server will not start. | true or false | true | Startup |
| database.location | The directory DConE will use for persistence. | Any existing path | None - must be present | Startup |
| executor.threads | The number of threads executing agreements in parallel. | 1-Integer.MAX_VALUE | 20 | Startup |
| fusion.decoupler | The decoupler the Fusion server will use. See Decoupler Guide | dcone, disruptor, simple | dcone | Startup |
| disruptor.wait.strategy | The wait strategy to use when the disruptor is selected for fusion.decoupler. | blocking, busy.spin, lite.blocking, sleeping, yielding | yielding | Startup |
| jetty.http.port | The port the Fusion HTTP server will use. | 1-65535 | 8082 | Startup |
| request.port | The port Fusion clients will use. | 1-65535 | None - must be present | Startup |
| transport | The transport the Fusion server should use. | OIO, NIO, EPOLL | NIO | Startup |
| transfer.chunk.size | The size of the "chunks" used in a file transfer. Used as input to Netty's ChunkedStream. | 1 - Integer.MAX_VALUE | 4 KiB | When each pull is initiated |
| dcone.use.boxcar | Indicates use of boxcars or not. | true or false | false | startup |
| license.file | The path to the license file | A valid file system path to a license key file. | /etc/wandisco/server/license.key | On each periodic license check |
| max.retry.attempts | The maximum number of times to retry an agreed request. | 1 - integer.MAX_VALUE | 10 | When executing an agreed request. |
| retry.sleep.time | The sleep time (ms) in between retries of an agreed request. | 1 - Long.MAX_VALUE (notice the capital L, make sure you include it). | 1000L | When executing an agreed request |
/etc/hadoop/conf/core-site.xml
Please take note that in WD Fusion 2.8 many of the properties in the following table have had the fs. prefix removed. The fs. is now used exclusively for filesystem specific properties.
| Property | Description | Permitted Values (default value in bold) |
| fusion.http.authentication.enabled | Enables authentication on the REST API | true or false |
| fusion.http.authentication.type | Type of authentication used. | "simple" or "kerberos" |
| fusion.http.authentication.simple.anonymous.allowed | If type is "simple", whether anonymous API calls are allowed. If set to false, users must append a query parameter at the end of their URL "user.name=$USER_NAME" | true or false |
| fusion.http.authentication.kerberos.principal | If type is "kerberos", the principal the fusion server will use to login with. The name of the principal must be "HTTP". | '*' (Putting simply an asterisk will cause the filter to pick up any principal found in the keytab that is of the form "HTTP/*" and log in with all of them) "HTTP/${HOSTNAME_OF_FUSION_SERVER}@${KERBEROS_REALM}" "HTTP/_HOST@${KERBEROS_REALM}" ("_HOST" will auto-resolve to the hostname of the fusion server) |
| fusion.http.authentication.kerberos.keytab | If type is "kerberos", the path to a keytab that contains the principal specified. | Any String |
| fusion.http.authentication.signature.secret.file | Path to a readable secret file. File is used to authenticate cookies. | Any String |
| fusion.enable.early.pulls | A property targeted at FileSystems that do not support appends (e.g. S3, Azure). When set to the default "false" the Fusion server will ignore incoming HFlushRequests. The "fs." prefix has been removed as the property may not be specific to FileSystems in future. | true or false |
| fusion.http.authorization.enabled | Property that sets the state of authorization. | true or false. |
| fusion.http.authorization.authorized.read.writers | The read-writers config dictates which user is allowed to make write REST calls (e.g. DELETE, PATCH, POST, and PUT). Read-writers have both RW-permissions. | A comma-delimited list of authorized users. |
| fusion.http.authorization.authorized.readers | Users who have read-only permission. They are unable to do all of the calls noted in the read.writers entry, above. | A comma-delimited list of authorized users. |
| fusion.http.authorization.authorized.proxies | The core filter reads a new local property which specifies proxy principals - this is the remote user principal that the UI will authenticate as. The value for the property should be set to the user part of the UI kerberos credential, e.g. hdfs
|
A comma-delimited list of authorized users. |
| fusion.client.can.bypass | Enables or disables the ability for the client to bypass to underlying filesystem without waiting for a response from WD Fusion. | true or false |
| fusion.client.bypass.response.secs | Sets how long the client will wait for a response from Fusion for before bypassing to underlying. | integer (seconds) |
| fusion.client.bypass.retry.interval.secs | Sets how long to keep bypassing for once a client has been forced to bypass for the first time. | integer (seconds) |
| fusion.username.translations | This property enables administrators to handle user-mapping between replicated folders. This consists off a comma-separated list of regex rules. Each rule consists of a username (from an incoming request) seperated from a translated pattern by a "/". See further explanation Important: Take note that the username translation feature only translates the usernames on operations from remote zones. |
null by default. pattern-string/translate-to-string |
Username Translations
Example
<property>
<name>fusion.username.translations</name>
<value>hdp-(.*)/cdh-$1,([A-Z]*)-([0-9]*)-user/usa-$2-$1</value>
</property>In the data center where the fusion.username.translations property is set, when a request comes in, it will check the username of the request against each listed pattern, and if the username matches that pattern, an attempt is made to translate using the listed value. If, during a check, none of the rules are found to match, we default to the username of the request, with no attempt to translate it.
Looking at the example translation rules:
hdp-(.*)/cdh-$1,([A-Z]*)-([0-9]*)-user/usa-$2-$1- hdp-(.*)/cdh-$1
- ([A-Z]*)-([0-9]*)-user/usa-$2-$1
- Rules are comma separated.
- Patterns and translations are separated by "/".
- Patterns and translations don't contain "/".
- White spaces should be accounted for in code, but are discouraged.
For the above config example, assume a createRequest comes in with the following usernames:
- Username: ROOT-1991-user
- We will check against the first pattern, hdp-(.*), and notice it doesn't match.
- We will check against the second pattern, ([A-Z]*)-([0-9]*)-user, and notice it matches.
- Attempt to translate the username using usa-$2-$1.
- Username is translated to usa-1991-ROOT.
- Create is done on the underlying filesystem using username, usa-1991-ROOT.
- We will check against the first pattern, hdp-(.*), and notice it matches.
- Attempt to translate the username using cdh-$1.
- Username is translated to cdh-KPac.
- Create is done on the underlying filesystem using username, cdh-KPac.
- We will check against the first pattern, hdp-(.*), and notice it doesn't match.
- We will check against the second pattern, ([A-Z]*)-([0-9]*)-user, and notice it doesn't match.
- Username is left as hdfs. Create is done on the underlying filesystem using username, hdfs.
Because these are config properties, any data center can have any set of rules. They must be identical across fusion-servers that occupy the same zone but do not have to be identical across data centers.
See more about enabling Kerberos authentication on WD Fusion's REST API.
8.2 IHC Server
The Inter-Hadoop Communication Server is configured from a single file located at:
/etc/wandisco/fusion/ihc/server/{distro}/{version string}.ihc.
| Property | Description | Permitted Values | Default | Checked at... |
| ihc.server | The hostname and port the IHC server will listen on. | String:[1 - 65535] | None - must be present | Startup |
| ihc.transport | The transport the IHC server should use. | OIO, NIO, EPOLL | NIO | Startup |
| ihc.ssl.enabled | Signifies that WD Fusion server - IHC communications should use SSL encryption. | true, false | false | Startup |
| http.server | The hostname and port the IHC HTTP server will listen on. | String:[1 - 65535] | None - must be present | Startup |
8.3 WD Fusion Client
Client configuration is handled in
/etc/hadoop/conf/core-site.xml
| Property | Description | Permitted Values | Default | Checked at... |
| fs.fusion.client.retry.max.attempts | Max number of times to attempt to connect to a Fusion server before failing over (in the case of multiple Fusion servers). | Any integer | 3 | Startup |
| fs.fusion.impl | The FileSystem implementation to be used. | See Usage Guide | None | Startup |
| fs.AbstractFileSystem.fusion.impl | The Abstract FileSystem implementation to be used. | See Usage Guide | None | Startup |
| fs.fusion.server | The hostname and request port of the Fusion server. Comma-separated list of hostname:port for multiple Fusion servers. | String:[1 - 65535] (Comma-separated list of Fusion servers) |
None - must be present | Startup |
| fs.fusion.transport | The transport the FsClient should use. | OIO, NIO, EPOLL | NIO | Startup |
| fs.fusion.push.threshold | The number of bytes the client will write before sending a push request to the Fusion server indicating bytes are available for transfer. | Block size of underlying filesystem - Long.MAX_VALUE.
(If the threshold is set to a figure less than the block size, the block size will be used. If the threshold is 0, pushes are disabled.) |
The block size of the underlying filesystem | Startup |
| fs.fusion.ssl.enabled | If Client-WD Fusion server communications use SSL encryption. | true, false | false | Startup |
| fusion.underlyingFs | The address of the underlying filesystem | Often this is the same as the fs.defaultFS property of the underlying hadoop. However, in cases like EMRFS, the fs.defaultFS points to a local HDFS built on the instance storage which is temporary, with persistent data being stored in S3. Users are more likely to deploy S3 storage as the fusion.underlyingFs.
|
None - must be present | Startup |
| fs.hdfs.impl | DistributedFileSystem implementation to be used | See Usage Guide | None | Startup |
| fs.hdfs.impl.disable.cache | Disables the HDFS filesystem cache. Note that from 2.6.7, this parameter is no longer added to core-site.xml. | See Usage Guide | None | Startup |
Usage Guide
There's a fixed relationship between the type of deployment and some of the Fusion Client parameters. The following table descibes this relationship:
| Configuration | fs.fusion.impl |
fs.AbstractFileSystem.fusion.impl |
fs.hdfs.impl |
| Use of fusion:/// with HCFS | com.wandisco.fs.client.FusionHcfs | com.wandisco.fs.client.FusionAbstractFs | Blank |
| Use of fusion:/// with HDFS | com.wandisco.fs.client.FusionHdfs | com.wandisco.fs.client.FusionAbstractFs | Blank |
| Use of hdfs:/// with HDFS | Blank | Blank | com.wandisco.fs.client.FusionHdfs |
| Use of fusion:/// and hdfs:/// with HDFS | com.wandisco.fs.client.FusionHdfs | com.wandisco.fs.client.FusionAbstractFs | com.wandisco.fs.client.FusionHdfs |
LocalFileSystems
We've introduced FusionLocalFs for LocalFileSystems using WD Fusion. This is necessary because there are a couple of places where the system expects to use a Local File System.
| Configuration | fs.fusion.impl |
fs.AbstractFileSystem.fusion.impl |
fs.hdfs.impl |
| LocalFileSystems (See below) | com.wandisco.fs.client.FusionLocalFs | com.wandisco.fs.client.FusionLocalFs | com.wandisco.fs.client.FusionLocalFs |
Therefore, for LocalFileSystems, users should set their fs.<parameter>.impl configuration to com.wandisco.fs.client.FusionLocalFs.
- Set
fs.file.impltoFusionLocalFs, (then any file:/// command will go through FusionLocalFs) - Set
fs.fusion.impltoFusionLocalFs, (then any fusion:/// command will go through FusionLocalFs). -
Set
fs.orange.implto FusionLocalFs, (then any oranges:/// command will go through FusionLocalFs). - Set
fs.lemon.implto FusionHdfs, (then any lemon:/// command will go through FusionHdfs).
Usage
Further more, a user can now set any scheme to any Fusion*Fs and when running a command with that scheme, it will go through that Fusion*Fs. e.g.,
Decoupler Guide
WD Fusion can decouple the handling of client requests from their processing using the Disruptor library. Consider "client request" to be shorthand for any coordinated filesystem operation submitted by client's FusionFs file system to the Fusion server, such as "make directory", "delete" or "close file"
Decoupler implementations
- Disruptor (default)
- This is the default implementation. The disruptor provides a buffer so that the receiving thread can place the request in and return immediately. The potential advantage of the disruptor is that it uses relatively few resources (a fixed amount of memory and a single processing thread) whilst achieving low-latency and high throughput.
Disruptor strategy "runs hot".
In most deployments, running the decoupler in the Disruptor implementation makes sense because of its benefits in terms of reduced overhead for very large number of agreements compared to a more low-latency strategy. You should be aware that a side-effect of the disruptor strategy is that CPU cores will run at 100%. - Simple
- In this implementation there is no decoupling at all - all processing is done on the receiving thread. This implementation should only be used for functional testing of the Fusion server.
- DConE
- When this option is set the incoming request is processed by DConE's internal decoupler. The size of the decoupler thread pool can be set through DConE's configuration, and the default is 50 processing threads. However, when there are a large number of agreements being made we may not want to use DConE's resources for the handling of client requests - this may starve the coordination engine of the threads it needs to perform agreement.
- Activity in the last hour
- This element monitors the data transfer activity, specifically, the imbound data coming into the Zone. It can't report on any data activity taking place in another zone.
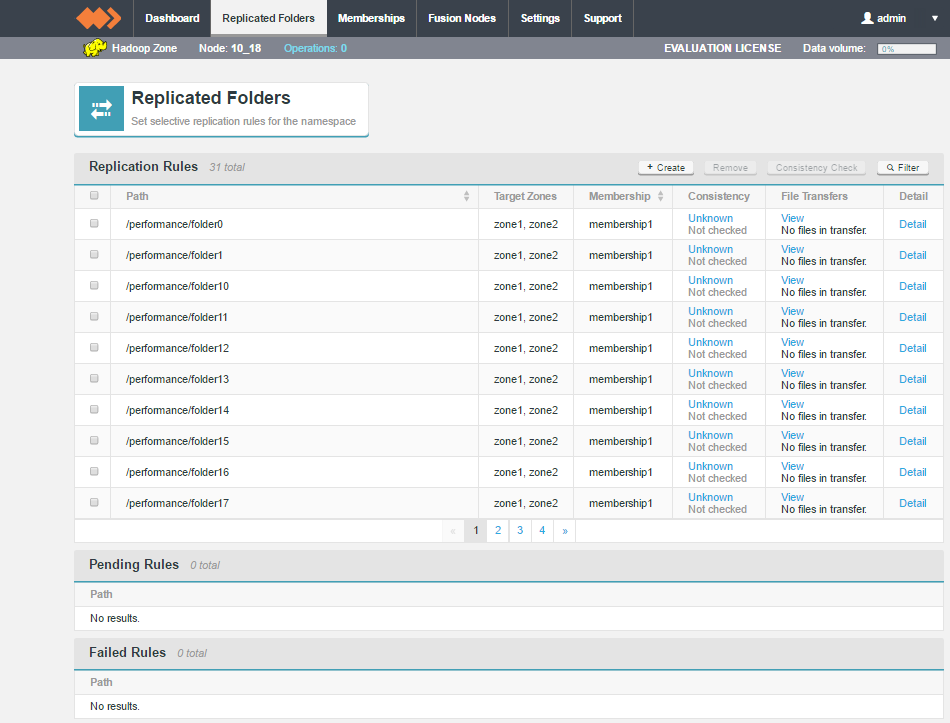
- Replication Rules
- Lists all active replicated folders, currently running on the node.
- Pending Rules
- Replicated folders that have been added but have not yet been established across all nodes. In most situations, pending rules will eventually move up to the Replication Rules table.
- Failed Rules
- In rare situations, a replicated folder creation will be rejected because of a file inconsistency between nodes. In such cases, the Failure will be reported in the Failed Rules table.
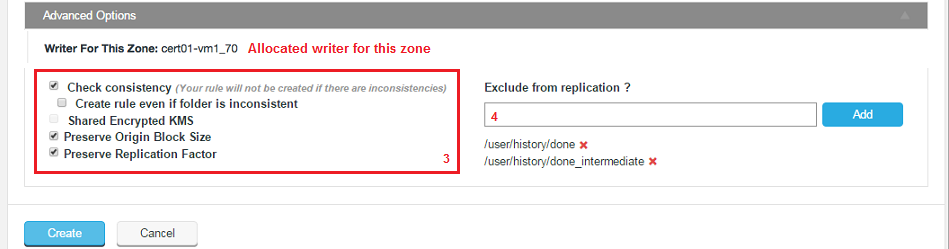
- Writer For This Zone
- This identifies which node is assigned as the writer for this node. See the glossary for an explanation of the role of the writer.
- Check consistency (Your rule will not be created if there are inconsistencies)
- Use this option to perform a consistency check before creating the replicated folder space. The check must succeed in order for the rule to be applied. If you want to peform the check but not enforce consistency see the next checkbox.
- Create rule even if folder is inconsistent
- The replication space is added, even if it has been found to be inconsistent between nodes. This option lets you create new replicated folders and then remedy consistencies.
- Shared Encrypted KMS
- In deployments where multiple zones share a command KMS server, then enable this parameter to specify a virtual prefix path.
- Preserve Origin Block Size
- The option to preserve the block size from the originating file system is required when Hadoop has been set up to use a columnar storage solution such as Apache Parquet. If you are using a columnar storage format in any of your applications then you should enable this option to ensure that each file sits within the same HDFS block.
- Preserve Replication Factor
- By default, data that is shared between clusters will follow the local cluster's replication rules rather than preserve the replication rules of the originating cluster. When this option is enabled, the replication factor of the originating cluster is preserved.
Example
Data in Zone A which has a replication factor of 3 is replicated to Zone B, which has a replication factor of 5. When Preserve Replication Factor is enabled this replica of the data in Zone B will continue to use a replication factor of 3 rather than use Zone B's native replication factor of 5. - Exclude from replication ?
- You can select files or file system locations that will be excluded from replication across your clusters and will not show up as inconsistent when a consistency check is run on the file system.
This feature is used to remove housekeeping and temporary system files that you don't want clogging up the replication traffic. The entry field will accept specific paths and files or a glob pattern (sets of filenames with wildcard characters) for paths or files.
Default ExclusionsThe following glob patterns are automatically excluded from replication:
/**/.fusion, /**/.fusion/**
.fusion directories store WD Fusion's housekeeping files, it should always be excluded in the global zone properties (even after update)/**/.Trash, /**/.Trash/**
.Trash directories are excluded by default but it can be removed if required.Example
Requirement: exclude all files in the replicated directory with the "norep_" prefix from replication.
Folder structure:
Required rule:/repl1/rep_a /repl1/norep_b /repl1/subfolder/rep_c /repl1/subfolder1/norep_d /repl1/subfolder2/rep_e /repl1/subfolder2/norep_e**/norep_*
- Pattern does not need to be an absolute path, e.g. /repl1/subfolder2/no_rep_3, patterns are automatically treated as relative to the replicated folder, e.g. /subfolder/no_rep_3
- Take care when adding exclusion rules as there is currently no validation on the field.
- Fusion UI Version
- The current version of the WD Fusion UI.
- Fusion Build Number
- The specific build for this version of the WD Fusion UI.
- Hadoop Version
- The version of the underlying Hadoop deployment.
- WD Fusion Version
- The version of the WD Fusion replicator component.
- WD Fusion Uptime
- The time elapsed system the WD Fusion system last booted up.
- Cluster Manager
- The management application used with the underlying Hadoop.
- Warning
- At the warn level, the need for administrator intervention is likely, although the state should have no current impact on operation. On a breach, there is the option for WD Fusion to send out an alerting email, providing that you have configured the email notification system. See Set up email notifications.
- Critical
- At the critical level, the need for administrator intervention may be urgent, especially if the breach concerns partition usage where reaching 100% will cause the system to fail and potentially result in data corruption. On a breach, there is the option for WD Fusion to send out an alerting email, providing that you have configured the email notification system. See Set up email notifications.
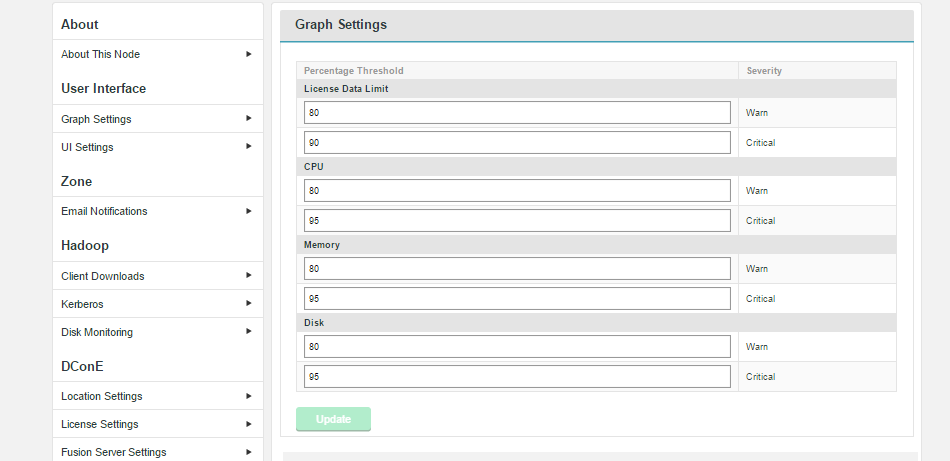
- License Data Limit
- This corresponds with the dashboard graph "License Limit: Volume of Replicated Data". The graph tracks the percentage of replicated data permitted by the current license. Enter your own values for the "Warn" trigger and "Critical" trigger. Defaults: Warn 80%, Critical 90%.
- CPU
- This corresponds with the dashboard graph "System CPU Load", it tracks usage in terms of percentage of available cycles. Defaults: Warn 80%, Critical 95%.
- Memory
- This corresponds with the dashboard graph "Java Heap Consumption" which tracks the ammount of JAVA heap currently in use, based on the Maximum Heap Settings that were applied during the installation. Defaults: Warn 80%, Critical 95%.
- Disk
- This corresponds with the dashboard graph "Fusion Database Partition Disk Usage". This graph measures the percentage of the available partition specifically being used by WD Fusion. The monitor is important because exhausting the available storage will cause WD Fusion to fail and potentially could result in corruption to the internal prevayler database. Defaults: Warn 80%, Critical 95%.
- HTTP Port
- Port used to access WD Fusion UI.
- HTTP Host
- Hostname of the WD Fusion UI.
- List of client nodes
- Link to a list of nodes on the platform.
- Client RPMs
- Link to RPMs
- Client DEBs
- Link to Debian Package files, for use with Ubuntu deployments.
- Client Parcels
- (available on a Cloudera platform) Link to the client in Cloudera's parcel package format.
- Client Stacks
- (available on a Hortonworks platform) Link to the client in Hortonworks Stack format.
- Configuration file path
- Path to the Kerberos configuration file, e.g.
krb5.conf. - Keytab file path
- Path to the generated keytab.
- Principle
- Principle for the keytab file.
- Enable Kerberos on WD Fusion
- Check-box to enable Kerberos authentication
- Keytab file path
- Path to the generated keytab.
- Principle
- Principle for the keytab file.
- Enable Authorization
- The check-box is used to enable support for Authorization, within WD Fusion, which enables administrators to allow two levels of access; full user access and read-only access, where a user does not have authorization to make changes to data. This checkbox is only visible if Kerberos core authentication has been enabled and configured.
For auditing purposes, every time an unauthorized request is made, the WD Fusion server will log the user and attempted request.Manually distribute client configuration.
You will need to redistribute the client configurations after making this change because the core-site.xml config file will be modified. The WD Fusion server will then need to be restarted for these settings to take effect.Enabling Authorization sets up some default values, the UI will add the "fusionUISystem" user automatically when Authorization is enabled as well as adding the correct proxy principal. All other users need to be configured manually. but you will still need to ensure that configuration is applied manually, to match your deployment's specific needs.
See the authorization properties, as written to the
core-site.xmlfile.Now whenever the Fusion UI wants to make a REST call on behalf of another user, they'll include a header (tentatively called proxy.user.name) with the real user. Example curl call:
curl --negotiate -u: -H "proxy.user.name: bob" hostname:8082/fusion/fs - File system path
- Enter the full path of the system directory that will be monitored for disk usage.
- Severity level
- Select a system log severity level (Severe, Warning, Info or Debug) that will correspond with the Disk Capacity Threshold.
Caution Assigning a monitor with Severe level will impact operation should its trigger Disk Capacity Threshold be met. The affected WD Fusion will immediately shut down to protect its file system from corruption. Ensure that Severe level monitors are set up with a threshold that corresponds with serious risk. Set the threshold too low and you may find WD Fusion nodes are shutdown needlessly.
- Disk Capacity Threshold (bytes)
- The maximum amount of data that can be consumed by the selected system path before the monitor sends an alert message to the log file.
- Message
- A human-readible message that will be sent to the log at the point that the Disk Capacity Threshold is reached.
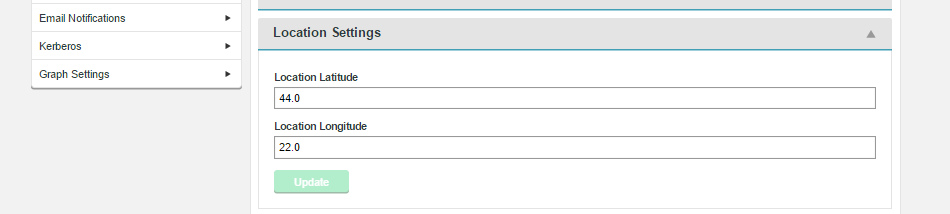
- Location Latitude
- Latitudinal coordinate for the server's location.
- Location Longitude
- Longitudinal coordinate for the server's location.
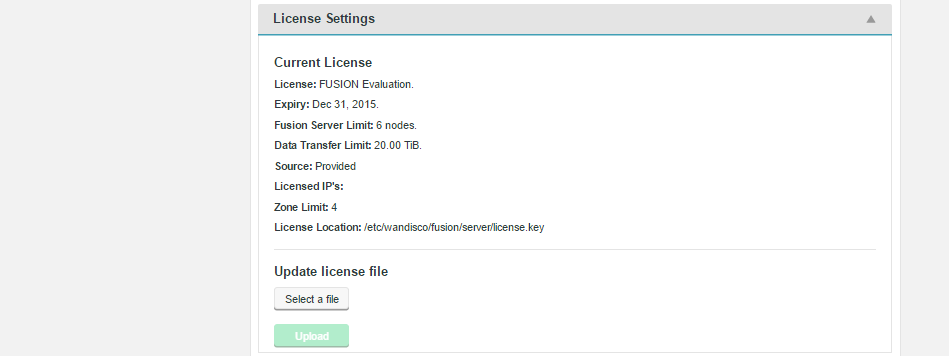
- License:
- Type of license employed.
- Expiry:
- Date on which the license will expire -- at which point a new license will be required.
- Fusion Server Limit:
- Maximum number of WD Fusion servers covered under the license.
- Data Transfer Limit:
- The maximum amount of replicated data permitted by the license.
- Source
- Provided or Downloaded.
- Licensed IPs:
- Machine IP addresses that are covered under the license.
- Zone Limit:
- The maximum number of zones supported under the license.
- License Location:
- Location of the license key on the server's file system.
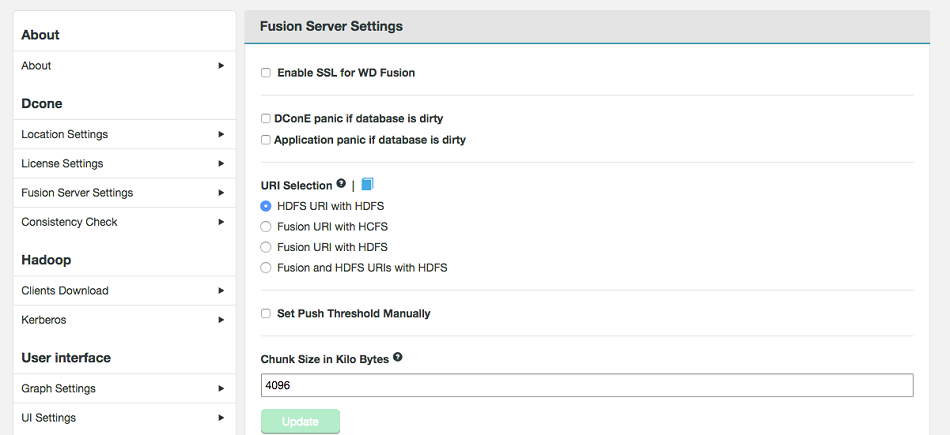
- Enable SSL for WD Fusion (checkbox)
- Tick to enable the WD Fusion server to encrypt traffic using SSL. See below for additional settings that appear if you enable SSL.
- KeyStore Path
- Path to the keystore
- KeyStore Password
- Encrypted password for the KeyStore
- Key Alias
- The Alias of the private key
- Key Password
- Private key encrypted password
- TrustStore Path
- path to the TrustStore
- TrustStore Password
- Encrypted password for the TrustStore
- DConE panic if dirty (checkbox)
- This option lets you enable the strict recovery option for WANdisco's replication engine, to ensure that any corruption to its prevayler database doesn't lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
- App Integration panic of dirty (checkbox)
- This option lets you enable the strict recovery option for WD Fusion's database, to ensure that any corruption to its internal database doesn't lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
- Use HDFS URI with HDFS file system

This option is available for deployments where the Hadoop applications support neither the WD Fusion URI or the HCFS standards. WD Fusion operates entirely within HDFS.
This configuration will not allow paths with thefusion://uri to be used; only paths starting withhdfs://or no scheme that correspond to a mapped path will be replicated. The underlying file system will be an instance of the HDFS DistributedFileSystem, which will support applications that aren't written to the HCFS specification.- Use WD Fusion URI with HCFS file system
-

This is the default option that applies if you don't enable Advanced Options, and was the only option in WD Fusion prior to version 2.6. When selected, you need to usefusion://for all data that must be replicated over an instance of the Hadoop Compatible File System. If your deployment includes Hadoop applications that are either unable to support the Fusion URI or are not written to the HCFS specfication, this option will not work. - Use Fusion URI with HDFS file system

This differs from the default in that while the WD Fusion URI is used to identify data to be replicated, the replication is performed using HDFS itself. This option should be used if you are deploying applications that can support the WD Fusion URI but not the Hadoop Compatible File System.- Use Fusion URI and HDFS URI with HDFS file system

This "mixed mode" supports all the replication schemes (fusion://,hdfs://and no scheme) and uses HDFS for the underlying file system, to support applications that aren't written to the HCFS specification.- Default Check Interval
- The entered value must be an integer between 1 and 24, representing number of hours before a consistency check will automatically take place.
- Save
- Click the save button to store the entered value and use it for all replicated folders that don't have their own set interval (using the Override the Consistency Check interval Advanced Option.
- Apply to All
- This button lets you for a new default value onto all replicated folders, even those that have specified an override (noted above).
Replicated Directories
.fusion subdirectory
The .fusion folder keeps track of where the writer is up to. If it fails, a newly elected writer (or when that one comes back) takes over from that GSN. You should not delete it because in certain failure scenarios the file system could become inconsistent, although it is not critical, even in these scenarios.
The contents of the directory are not kept perminently, there is a periodic clean up to ensure that it doesn't get too large
9. WD Fusion UI Reference Guide
9.1 Installation directories
WD Fusion Server
Default installation directory:
/etc/wandisco/fusion/server/application.properties
The server directory contains the following subdirectories:
-rw-r--r-- 1 hdfs hdfs 62983 Mar 30 21:09 activation-1.1.jar
-rw-r--r-- 1 hdfs hdfs 44925 Mar 30 21:09 apacheds-i18n-2.0.0-M15.jar
-rw-r--r-- 1 hdfs hdfs 691479 Mar 30 21:09 apacheds-kerberos-codec-2.0.0-M15.jar
-rw-r--r-- 1 hdfs hdfs 16560 Mar 30 21:09 api-asn1-api-1.0.0-M20.jar
-rw-r--r-- 1 hdfs hdfs 79912 Mar 30 21:09 api-util-1.0.0-M20.jar
-rw-r--r-- 1 hdfs hdfs 314 Apr 1 17:21 application.properties
-rw-r--r-- 1 hdfs hdfs 43033 Mar 30 21:09 asm-3.1.jar
-rw-r--r-- 1 hdfs hdfs 436561 Mar 30 21:09 avro-1.7.6-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 94463 Mar 30 21:09 bcmail-jdk14-1.48.jar
-rw-r--r-- 1 hdfs hdfs 590499 Mar 30 21:09 bcpkix-jdk14-1.48.jar
-rw-r--r-- 1 hdfs hdfs 2319441 Mar 30 21:09 bcprov-jdk14-1.48.jar
-rw-r--r-- 1 hdfs hdfs 188671 Mar 30 21:09 commons-beanutils-1.7.0.jar
-rw-r--r-- 1 hdfs hdfs 206035 Mar 30 21:09 commons-beanutils-core-1.8.0.jar
-rw-r--r-- 1 hdfs hdfs 41123 Mar 30 21:09 commons-cli-1.2.jar
-rw-r--r-- 1 hdfs hdfs 58160 Mar 30 21:09 commons-codec-1.4.jar
-rw-r--r-- 1 hdfs hdfs 575389 Mar 30 21:09 commons-collections-3.2.1.jar
-rw-r--r-- 1 hdfs hdfs 241367 Mar 30 21:09 commons-compress-1.4.1.jar
-rw-r--r-- 1 hdfs hdfs 298829 Mar 30 21:09 commons-configuration-1.6.jar
-rw-r--r-- 1 hdfs hdfs 24239 Mar 30 21:09 commons-daemon-1.0.13.jar
-rw-r--r-- 1 hdfs hdfs 143602 Mar 30 21:09 commons-digester-1.8.jar
-rw-r--r-- 1 hdfs hdfs 112341 Mar 30 21:09 commons-el-1.0.jar
-rw-r--r-- 1 hdfs hdfs 305001 Mar 30 21:09 commons-httpclient-3.1.jar
-rw-r--r-- 1 hdfs hdfs 185140 Mar 30 21:09 commons-io-2.4.jar
-rw-r--r-- 1 hdfs hdfs 284220 Mar 30 21:09 commons-lang-2.6.jar
-rw-r--r-- 1 hdfs hdfs 62050 Mar 30 21:09 commons-logging-1.1.3.jar
-rw-r--r-- 1 hdfs hdfs 1599627 Mar 30 21:09 commons-math3-3.1.1.jar
-rw-r--r-- 1 hdfs hdfs 273370 Mar 30 21:09 commons-net-3.1.jar
-rw-r--r-- 1 hdfs hdfs 417 Apr 1 17:21 core-site.xml
-rw-r--r-- 1 hdfs hdfs 68866 Mar 30 21:09 curator-client-2.6.0.jar
-rw-r--r-- 1 hdfs hdfs 185245 Mar 30 21:09 curator-framework-2.6.0.jar
-rw-r--r-- 1 hdfs hdfs 248171 Mar 30 21:09 curator-recipes-2.6.0.jar
drwxr-xr-x 1 hdfs hdfs 4 Apr 1 17:21 dcone
-rw-r--r-- 1 hdfs hdfs 504946 Mar 30 21:09 DConE-1.3.0-rc6.jar
-rw-r--r-- 1 hdfs hdfs 897053 Mar 30 21:09 DConE_Platform-1.3.0-rc5.jar
-rw-r--r-- 1 hdfs hdfs 79474 Mar 30 21:09 disruptor-3.3.2.jar
-rw-r--r-- 1 hdfs hdfs 19167 Mar 30 21:09 enunciate-core-annotations-1.29.jar
-rw-r--r-- 1 hdfs hdfs 22659 Mar 30 21:09 enunciate-core-rt-1.29.jar
-rw-r--r-- 1 hdfs hdfs 25653 Mar 30 21:09 enunciate-jersey-rt-1.29.jar
-rw-r--r-- 1 hdfs hdfs 48238 Mar 30 21:09 fusion-common-2.0.2-SNAPSHOT-cdh-5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 7129 Mar 30 21:09 fusion-ihc-client-2.0.2-SNAPSHOT-cdh-5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 11573 Mar 30 21:09 fusion-ihc-common-2.0.2-SNAPSHOT-cdh-5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 12486 Mar 30 21:09 fusion-netty-2.0.2-SNAPSHOT.jar
-rw-r--r-- 1 hdfs hdfs 239075 Mar 30 21:09 fusion-server-2.0.2-SNAPSHOT.jar
-rw-r--r-- 1 hdfs hdfs 190432 Mar 30 21:09 gson-2.2.4.jar
-rw-r--r-- 1 hdfs hdfs 1648200 Mar 30 21:09 guava-11.0.2.jar
-rw-r--r-- 1 hdfs hdfs 21575 Mar 30 21:09 hadoop-annotations-2.5.0-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 73096 Mar 30 21:09 hadoop-auth-2.5.0-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 3151457 Mar 30 21:09 hadoop-common-2.5.0-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 7689502 Mar 30 21:09 hadoop-hdfs-2.5.0-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 352254 Mar 30 21:09 httpclient-4.1.2.jar
-rw-r--r-- 1 hdfs hdfs 181200 Mar 30 21:09 httpcore-4.1.2.jar
-rw-r--r-- 1 hdfs hdfs 227517 Mar 30 21:09 jackson-core-asl-1.8.8.jar
-rw-r--r-- 1 hdfs hdfs 17883 Mar 30 21:09 jackson-jaxrs-1.8.3.jar
-rw-r--r-- 1 hdfs hdfs 669065 Mar 30 21:09 jackson-mapper-asl-1.8.8.jar
-rw-r--r-- 1 hdfs hdfs 32319 Mar 30 21:09 jackson-xc-1.8.3.jar
-rw-r--r-- 1 hdfs hdfs 38940 Mar 30 21:09 java-uuid-generator-3.1.3.jar
-rw-r--r-- 1 hdfs hdfs 18490 Mar 30 21:09 java-xmlbuilder-0.4.jar
-rw-r--r-- 1 hdfs hdfs 105134 Mar 30 21:09 jaxb-api-2.2.2.jar
-rw-r--r-- 1 hdfs hdfs 890168 Mar 30 21:09 jaxb-impl-2.2.3-1.jar
-rw-r--r-- 1 hdfs hdfs 458739 Mar 30 21:09 jersey-core-1.9.jar
-rw-r--r-- 1 hdfs hdfs 147952 Mar 30 21:09 jersey-json-1.9.jar
-rw-r--r-- 1 hdfs hdfs 713089 Mar 30 21:09 jersey-server-1.9.jar
-rw-r--r-- 1 hdfs hdfs 539735 Mar 30 21:09 jets3t-0.9.0.jar
-rw-r--r-- 1 hdfs hdfs 67758 Mar 30 21:09 jettison-1.1.jar
-rw-r--r-- 1 hdfs hdfs 516429 Mar 30 21:09 jetty-6.1.14.jar
-rw-r--r-- 1 hdfs hdfs 163121 Mar 30 21:09 jetty-util-6.1.14.jar
-rw-r--r-- 1 hdfs hdfs 185746 Mar 30 21:09 jsch-0.1.42.jar
-rw-r--r-- 1 hdfs hdfs 100636 Mar 30 21:09 jsp-api-2.1.jar
-rw-r--r-- 1 hdfs hdfs 33015 Mar 30 21:09 jsr305-1.3.9.jar
-rw-r--r-- 1 hdfs hdfs 489884 Mar 30 21:09 log4j-1.2.17.jar
-rw-r--r-- 1 hdfs hdfs 847 Mar 30 21:09 log4j.properties
-rw-r--r-- 1 hdfs hdfs 1610 Mar 30 21:09 logger.properties
-rw-r--r-- 1 hdfs hdfs 1199572 Mar 30 21:09 netty-3.6.2.Final.jar
-rw-r--r-- 1 hdfs hdfs 1887979 Mar 30 21:09 netty-all-4.0.25.Final.jar
-rw-r--r-- 1 hdfs hdfs 105291 Mar 30 21:09 prevayler-2.3WD5.jar
-rw-r--r-- 1 hdfs hdfs 533455 Mar 30 21:09 protobuf-java-2.5.0.jar
-rw-r--r-- 1 hdfs hdfs 105112 Mar 30 21:09 servlet-api-2.5.jar
-rw-r--r-- 1 hdfs hdfs 26176 Mar 30 21:09 slf4j-api-1.6.6.jar
-rw-r--r-- 1 hdfs hdfs 9711 Mar 30 21:09 slf4j-log4j12-1.6.6.jar
-rw-r--r-- 1 hdfs hdfs 23346 Mar 30 21:09 stax-api-1.0-2.jar
drwxr-xr-x 1 hdfs hdfs 12 Apr 1 17:21 webapps
-rw-r--r-- 1 hdfs hdfs 15010 Mar 30 21:09 xmlenc-0.52.jar
-rw-r--r-- 1 hdfs hdfs 7188 Mar 30 21:09 xmlpull-1.1.3.1.jar
-rw-r--r-- 1 hdfs hdfs 481770 Mar 30 21:09 xstream-1.4.3.jar
-rw-r--r-- 1 hdfs hdfs 94672 Mar 30 21:09 xz-1.0.jar
-rw-r--r-- 1 hdfs hdfs 1351733 Mar 30 21:09 zookeeper-3.4.5-cdh5.3.0.jar
WD Fusion UI
Default installation directory for WD Fusion is
/opt/wandisco/fusion-ui-serverThis folder contains the following subfolders:
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 bin
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 config
drwxr-xr-x 3 hdfs hdfs 4096 Mar 30 14:28 docs
-rw-r--r-- 1 hdfs hdfs 12614 Mar 27 22:07 fusion-ui-server-delegate.jar
-rw-r--r-- 1 hdfs hdfs 499861 Mar 27 22:07 fusion-ui-server.jar
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 lib
drwxr-xr-x 2 hdfs hdfs 4096 Apr 7 10:51 logs
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 properties
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 tmp
drwxr-xr-x 8 hdfs hdfs 4096 Mar 30 14:28 ui
drwxr-xr-x 3 hdfs hdfs 4096 Mar 30 14:28 var9.2 WD Fusion Guide
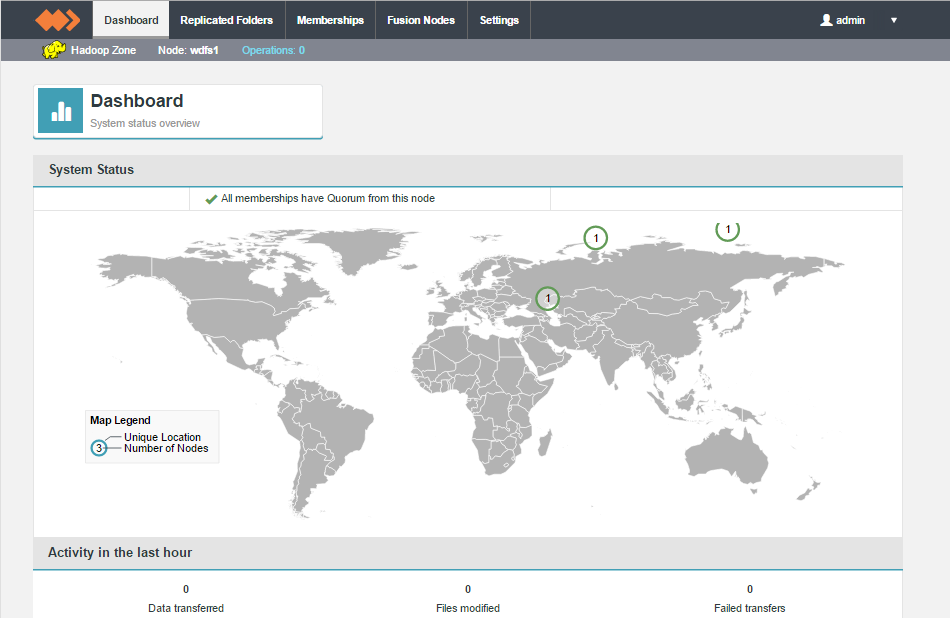
Dashboard
System Usage Graphs
The dashboard provides running monitors for key system resources.

On nodes that have data limits on their product license, there's a graph that displays the volume of replicated data, as a percentage of the license limit.
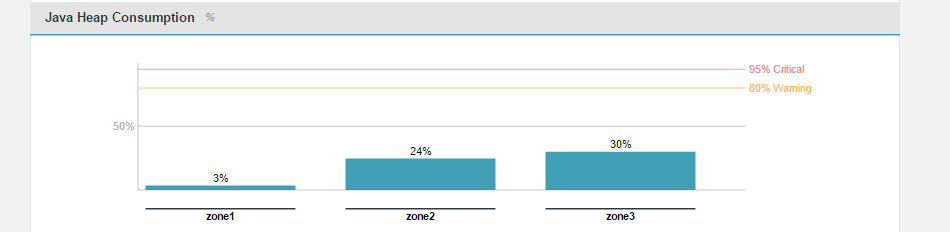
This graph tracks the percentage of configured Java Heap space that is currently in use across the cluster.
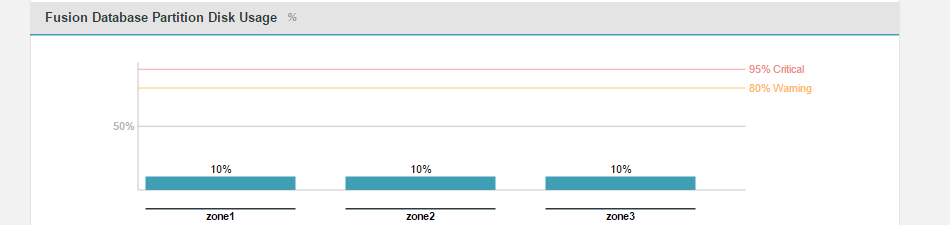
This graph measures the percentage of available storage in the partition that hosts the WD Fusion installation.
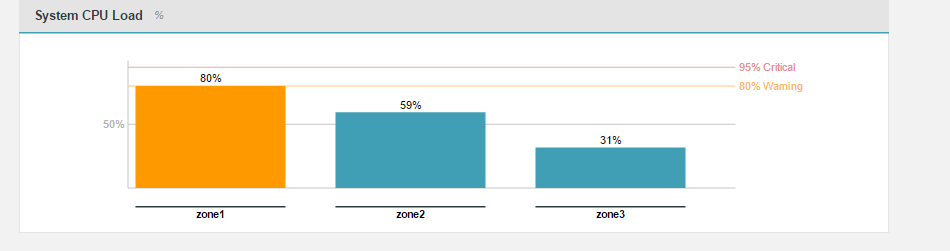
This graph tracks the current percentage load on the cluster's processors.
CPU Graph clarification
Now we display SystemCpuLoad / AvailableProcessors . This will ensure the value is much lower and closer to correct value. The problem still lies that in a virtualised/container based environment JMX may report the incorrect number of CPUs based on the host machine.
In previous releases this graph displayed the SystemCpuLoad value as returned by the JMX (Java Management Endpoint). While potentially useful in itself, it was misleading as an indicator of load as it showed a percentage up value up to 1, without taking into account multiple CPUs/cores where the value could be greater than 1 (up to the number of cores/processors).
Replicated Folders
The Replicated Folders screen lists those folders in the cluster's hdfs space that are set for replication between WD Fusion nodes.
Filtering
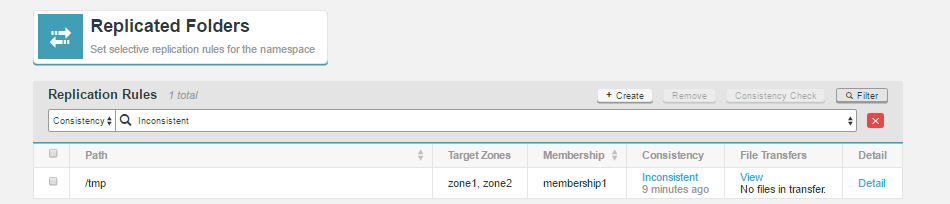
In deployments that use large numbers of rules, You can use the filter tool to focus on specific sets of rules. Filtering by Path, Membership or Consistency.
Create Rule
Click on Create Rule to set up a new replicated folder.
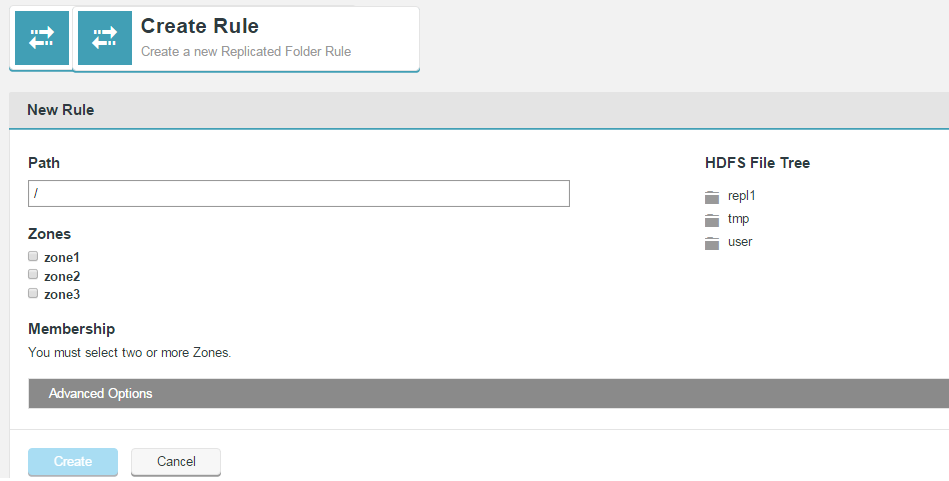
Advanced Options
The Advanced Options provide additional control for replicated folders.

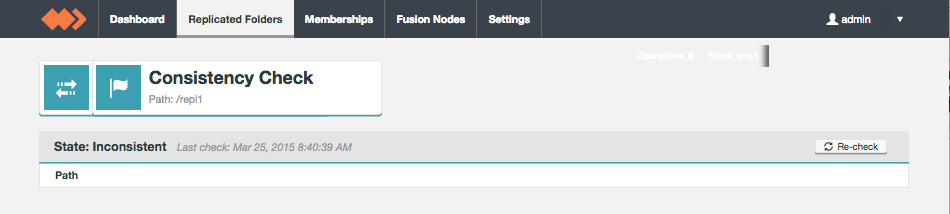
Consistency Check
Membership
Membership is used to organise WANdisco's data replication. Each WD Fusion node takes on a particular PAXOS-based role which determines whether the node take part in the vote for transaction order agreement or whether it hosts its own replica data. The collective configuration of all member nodes is what defines a membership.
The Membership section of the WD Fusion UI is split between three tabs:
Current
The current tab lists those memberships that are current in use. A membership is said to be in use when it is associated with a replicated directory or set of directories.
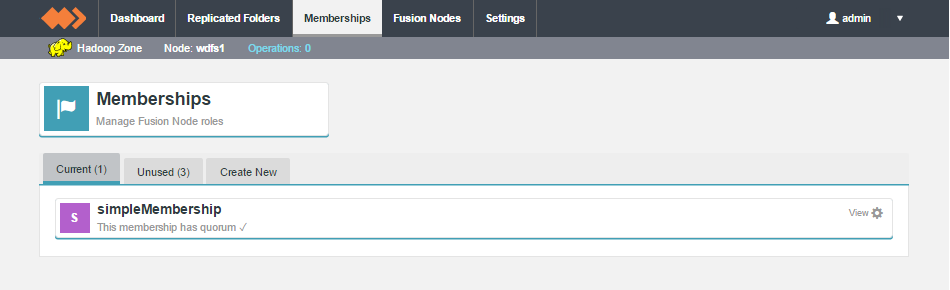
Unused
Shows memberships that have been created but are not yet applied to any data. You can change a membership from Unused to Current by associating it to a replicated folder.
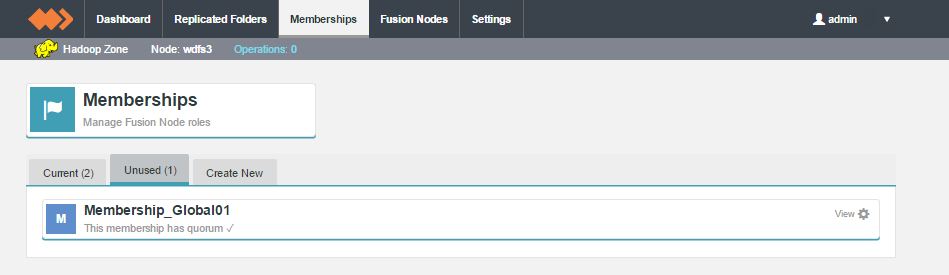
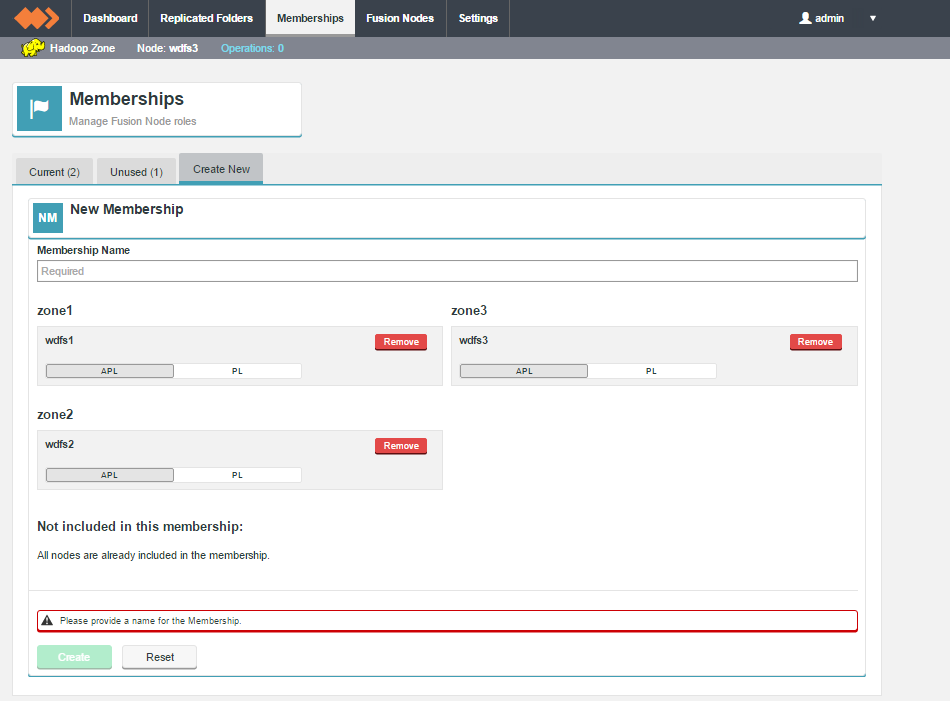
Create New
The third tab is used for the Create New membership screen.
Fusion Nodes
The Fusion Nodes setting screen displays the available nodes under each connected zone.
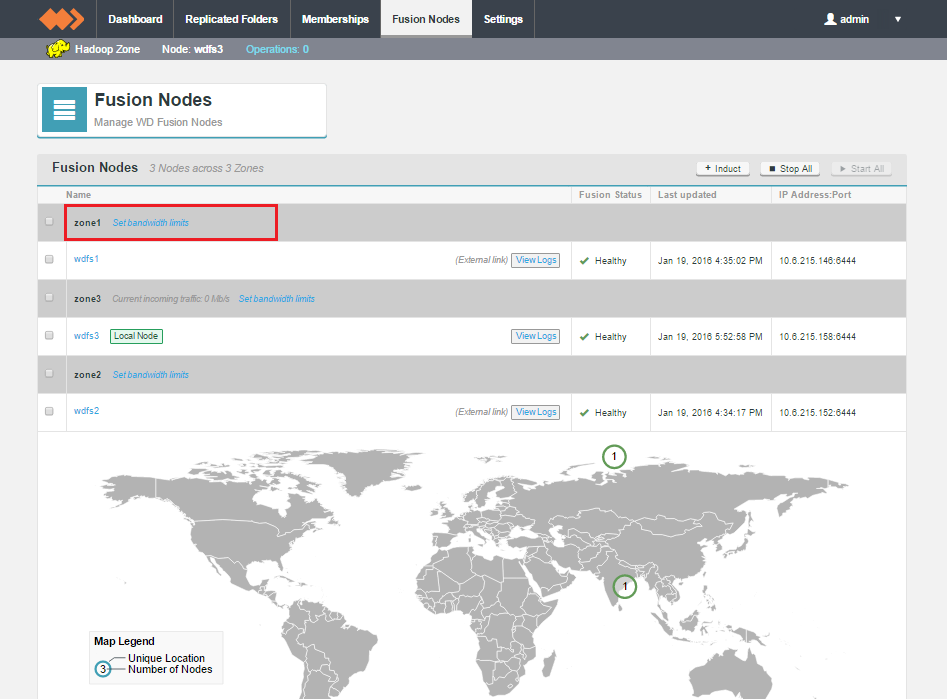
Current traffic rate is only shown for the local zone.
When running under an enterprise license, there are additional screens available for the limiting of the rate of data transfer between zones. For more information, see Setting up Bandwidth Management
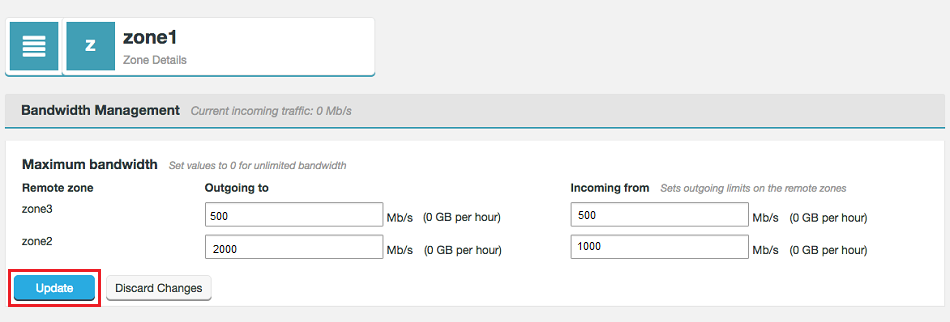
Maximum bandwidth dialog
Enter limits for the rate of transfer between each zone. Note that the Incoming from limit is not applied locally, instead it is applied as the Outgoing to limit at the target zone.
Logs
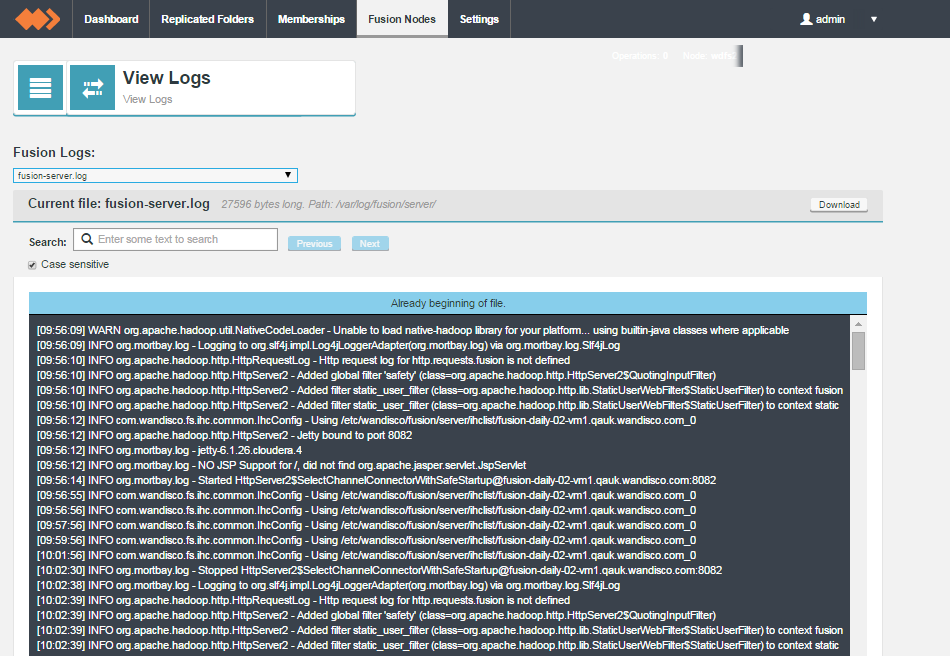
Settings
The Settings tab is home for most of WD Fusions various configuration settings. This section runs through each setting, explaing what it does.
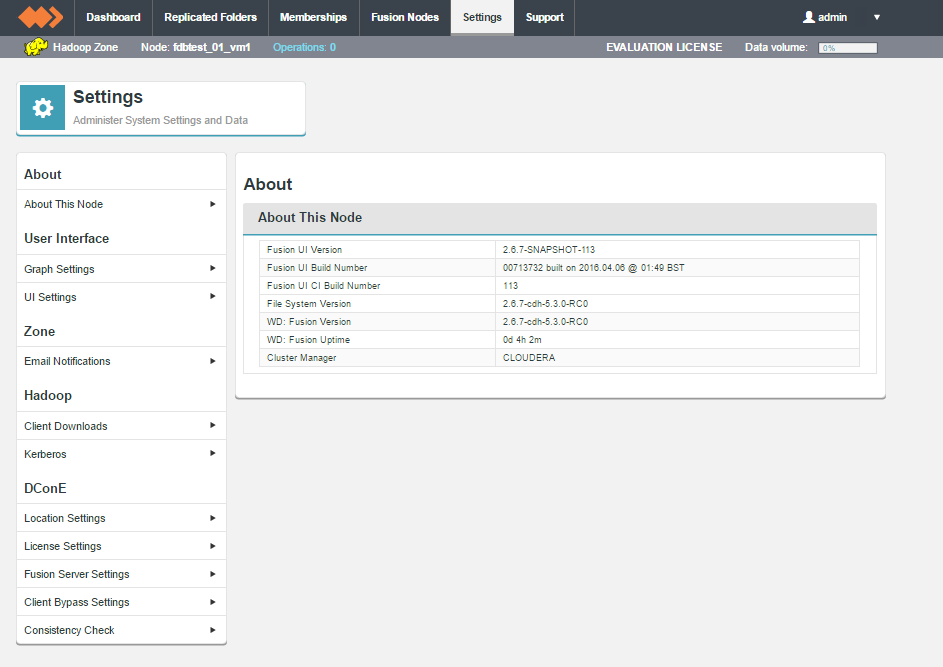
About This Node
The About This Node panel shows the version information for the underlaying Hadoop deployment as well as the WD Fusion server and UI components:
Graph Settings
The graphs that are displayed on the WD Fusion dashboard can be modified so that they use different thresholds for their "Warning" and "Critical" levels. By default, warn triggers at 80% usage and critical triggers at 90% or 95%.
Support
The support tab contains links and details that may help you if you run into problems using WD Fusion.
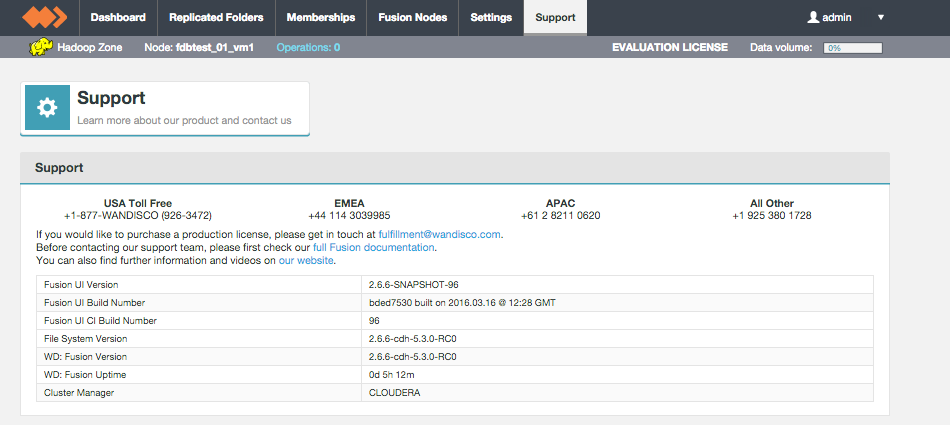
Support tab.
User Interface
UI Settings
Settings that control the TPC Port and hostname used by the WD Fusion server.
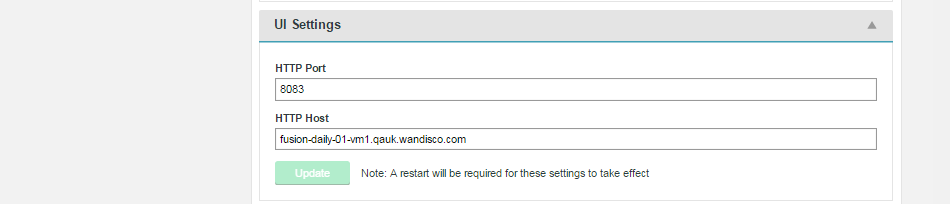
Restart required
Any change that you make will require a restart of the WD Fusion server in order for it to be applied.
Zone
Email Notifications
The Email Notification let you set up system emails that can be triggered is a particular system event occurs.
Email notification lets you set up notification emails that can be sent from the WD Fusion server if there's a system event that requires administrator attention. For more information about setting up email notifications, see Set up email notifications
Hadoop
Client Downloads
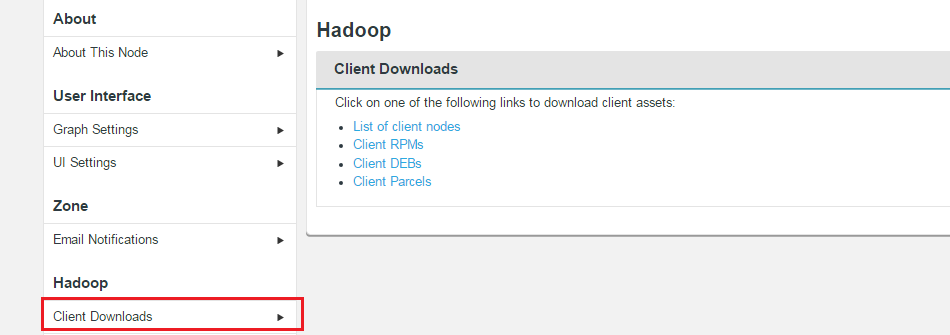
The client applications required to talk to WD Fusion are provided here. The client packages are provided during installation, they're listed in the Settings section in case they are required again, after installation is complete.
Kerberos
WD Fusion supports Kerberized environments, supporting the use of an established Kerberos Key Distribution Center (KDC) and realms.
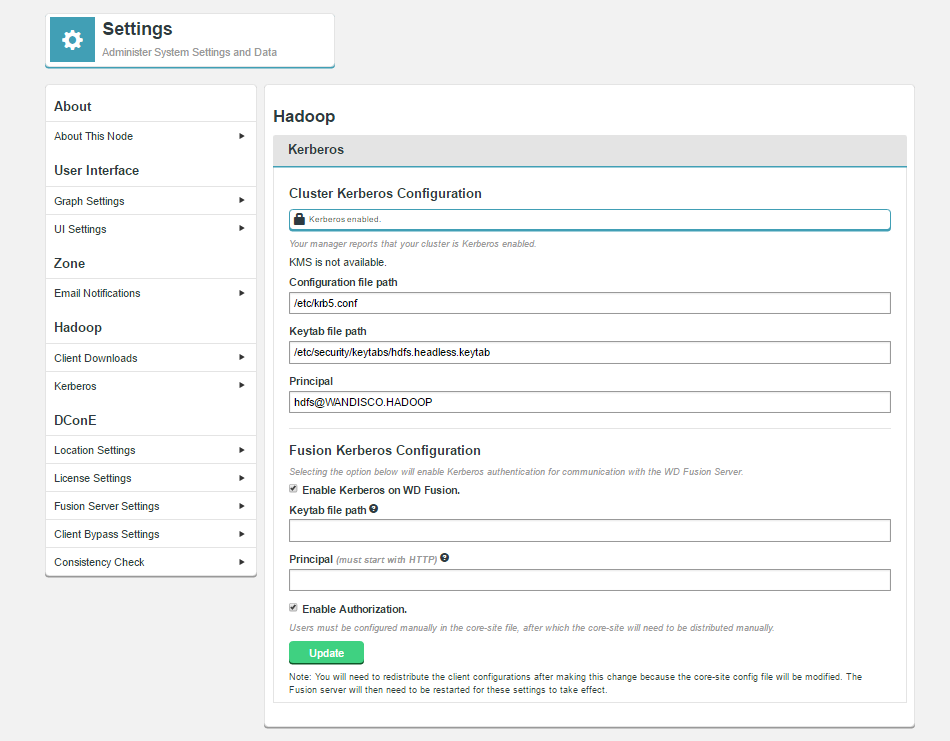
Cluster Kerberos Configuration
KMS
The status of the KMS is presented here.
Fusion Kerberos Configuration
Selecting the option below will enable Kerberos authentication for communication with the WD Fusion Server.
See Setting up Kerberos for more information about Kerberos setup.
Delete usercache user directory when moving to a kerberized environment.
When you've run yarn jobs on a nonsecure cluster then install kerberos security on it and try to run yarn jobs as that same user again you may get this error:
15/09/12 23:24:57 INFO mapreduce.Job: Job job_1442093296589_0003 failed with state FAILED due to: Application application_1442093296589_0003 failed 2 times due to AM Container for appattempt_1442093296589_0003_000002 exited with exitCode: -1000
For more detailed output, check application tracking page:http://vmhost01-vm1.bdva.wandisco.com:8088/proxy/application_1442093296589_0003/Then, click on links to logs of each attempt.
Diagnostics: Application application_1442093296589_0003 initialization failed (exitCode=255) with output: main : command provided 0
main : user is hadoopuser
main : requested yarn user is hadoopuser
Can't create directory /yarn/nm/usercache/hadoopuser/appcache/application_1442093296589_0003 - Permission denied
Did not create any app directories
Failing this attempt. Failing the application.
15/09/12 23:24:57 INFO mapreduce.Job: Counters: 0
Fix
Remove or move the "user" cache directory from all the nodes, the directories will get re-created during a run. e.g. On all nodes, run the following on your "user" cache directory:
rm -rf /yarn/nm/usercache/hadoopuser/
Disk Monitoring
The Disk Monitor provides a basic level of protection against potential system failure due to the exhaustion of available storage space.
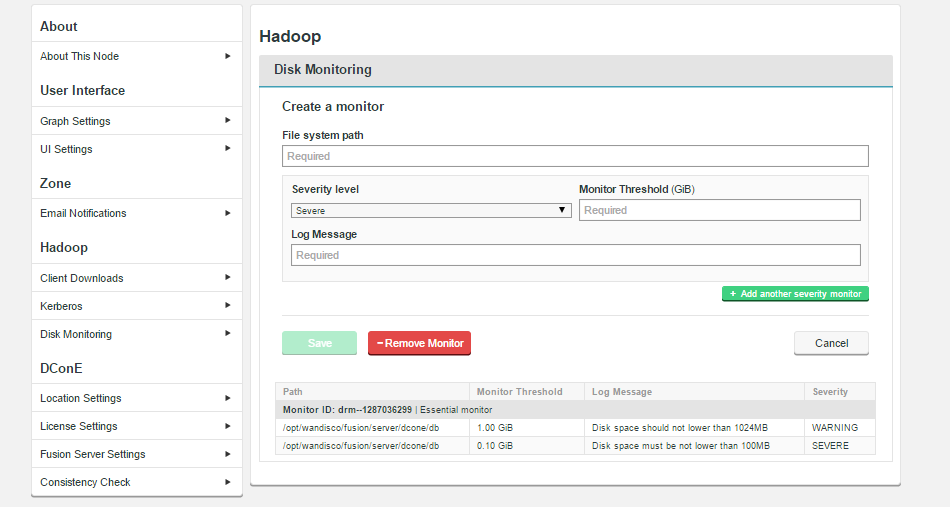
Create Monitor
See Set up a Custom Disk Monitor in the Admin section.
DConE
Location Settings
The Location Settings are used to pin the WD Fusion server to the map on the Fusion Nodes screen.
License Settings
The License Settings panel gives you a summary of the server's license status.
Fusion Server Settings
The server settings give you control over traffic encryption between WD Fusion and IHC servers.
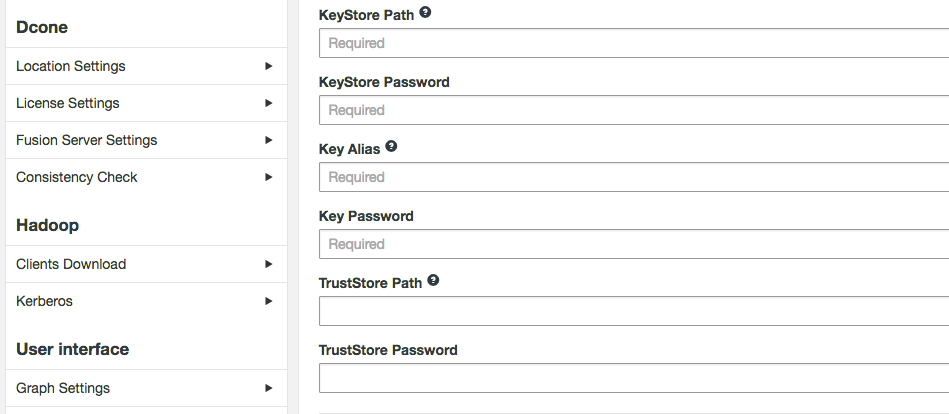
Changes must be applied to all servers
Changes to SSL settings require the same changes to be made manually in the UI of every other WD Fusion node. Updating will also make changes in core-site file via the management endpoint. You will need to push out configs and restart some services.
Configuration changes
These options set the following properties in /etc/hadoop/conf/core-site.xml
fusion.ssl.enabled=true
fusion.ihc.ssl.enabled=true
This ensures that both WD Fusion server and the IHC server traffic is secured using SSL. The properties, as defined in the Reference Guide are repeated below:
| Property | Description | Permitted Values | Default | Checked at... |
| fs.fusion.ssl.enabled | If Client-WD Fusion server communications use SSL encryption. | true, false | false | Startup |
| ihc.ssl.enabled | Signifies that WD Fusion server - IHC communications should use SSL encryption. | true, false | false | Startup |
Setting a password for SSL encryption
Use our provided bash script for generating a password. Run the script at the command line, enter a plaintext password, the script then generates and outputs the encrypted version of the entry:
[root@vmhost01-vm3 fusion-server]# ./encrypt-password.sh
Please enter the password to be encrypted
> ********
btQoDMuub7F47LivT3k1TFAjWSoAgM7DM+uMnZUA0GUet01zwZl7M8zixVZDT+7l0sUuw6IqGse9kK0TiDuZi0eSWreeW8ZC59o4R15CCz0CtohER7O3uUzYdHaW6hmT+21RaFkUF5STXXHcwdflwq4Zgm+KdUXKF/8TrgEVqT854gci1KQyk+2TKSGtGbANg12LplEre3DEGoMFOpy2wXbwO5kGOQM07bZPjsDkJmAyNwERg0F3k2sebbuGmz4VSAY1NTq4djX1bVwMWoPwcuiQXLwWLgfrGZDHaT+Cm88vRUsYaK2CDlZI4C7r+Lkkm/U4F/M6TFLGT6ZFlB+xRQ==
URI Selection
The default behavior for WD Fusion is to handle all replication using the Hadoop Distributed File System via the hdfs:/// URI. Selecting the HDFS-scheme provides the widest support for Hadoop client applications, since some applications can't support the available fusion:/// URI or they can only run on HDFS instead of the less strict HCFS. Each option is explained below:
Set Push Threshold Manually

The feature exposes the configuration property fs.fusion.push.threshold, stored in the core-site.xml file. It provides administrators with a means of making a small performance improvement, useful in a small number of cases. The default value is matched to the block size of the underlying filesystem. When enabled in the UI the entry displays as "0".
You can enter your own value (in bytes) and click the Update button.
Amazon cloud deployments
Set to zero "0", to disable HFLUSH, given that appends are not supported for S3 storage.
Client Bypass Settings
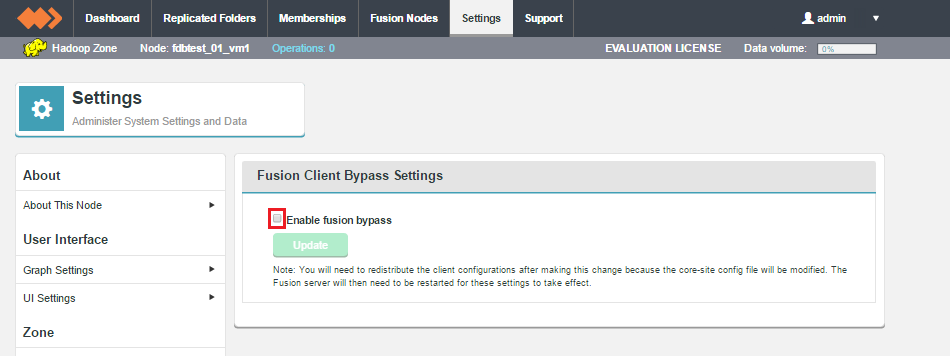
The emergency bypass feature gives the administrator an option to bypass WD Fusion and write to the underlying file system, which will introduce inconsistencies between zones. This is suitable for when short-term inconsistency is seen as a lesser evil compared to blocked progress.
For an explanation about how to use this feature, see Emergency bypass to allow writes to proceed.
Consistency Check
The consistency check options provide administrators with additional tunable properties concerning the tool for validating that all replica data is synchronized.
Default Check Interval
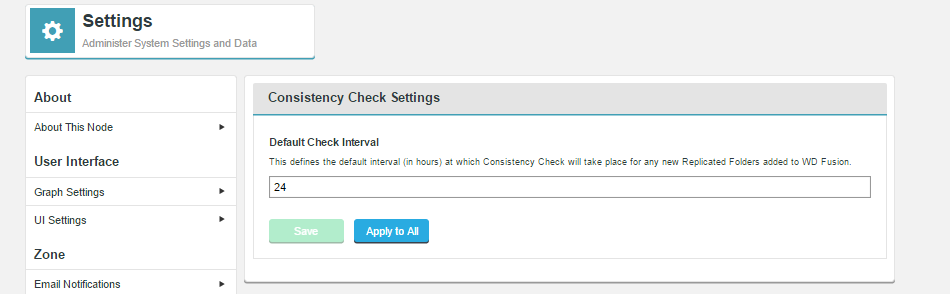
This lets you set the default amount of time that is allowed to pass before a new replicated folder is checked for consistency between replicas. The default value is 24 hours. It's possible to set a different value for each specific replicated folder, using the Advanced Options available when setting up or editing a Replicated Folder.