Glossary
Technical guide and glossary for Hadoop and WANdisco Fusion terms.
Introducing WD Fusion
WD Fusion provides consistent, continuous data replication between file systems in Hadoop clusters. Client applications that use WD Fusion interact with a virtual file system that integrates the underlying storage across multiple clusters. When changes are made to files in one cluster, they are replicated immediately and consistently to the other clusters that WD Fusion spans.
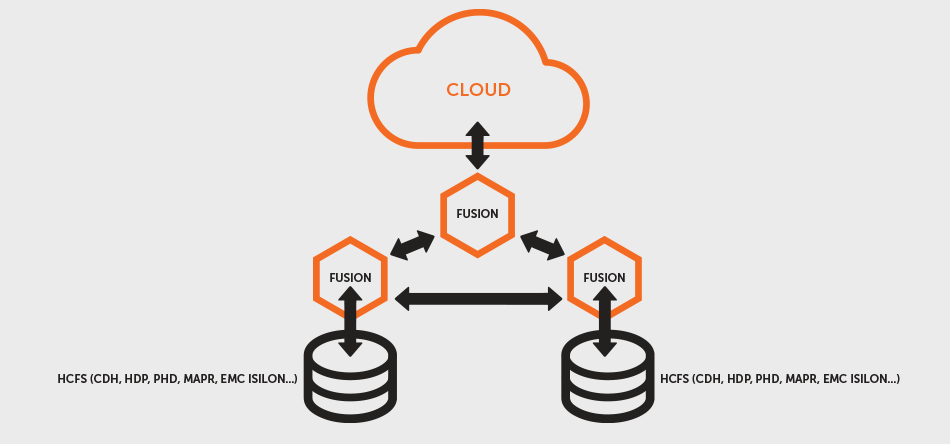
- Applications in all clusters can read and write to the file system through WD Fusion at any time, and be guaranteed that the file systems will remain consistent across all the participating clusters.
- WD Fusion can span different versions and distributions of Hadoop, including CDH, HDP, EMC Isilon, Amazon S3/EMRFS and MapR, and presents the standard Hadoop-Compatible File System interface to applications, which do not need to be modified.
- Similarly, WD Fusion does not require any changes to the underlying Hadoop clusters or their file systems. It operates as a proxy that client applications use when working with replicated file system content.
WD Fusion Terms
To help you understand how WD Fusion operates, this documentation uses the terms Zone, Membership and Replication Rule. They each play a critical role in your configuration and use of WD Fusion. You should understand this terminology before installing WD Fusion.
Zones
A Zone represents the file system used in a standalone Hadoop cluster. Multiple Zones could be from separate clusters in the same data center, or could be from distinct clusters operating in geographically-separate data centers that span the globe. WD Fusion operates as a distributed collection of servers. While each WD Fusion server always belongs to only one Zone, a Zone can have multiple WD Fusion servers (for load balancing and high availability). When you install WD Fusion, you should create a Zone for each cluster's file system.
Edge Nodes
Edge nodes (AKA gateway nodes) are servers that interface between the Hadoop cluster and systems that are outside the network. Most commonly, edge nodes are used to run client applications and cluster administration tools. Read more.
DConE Terms
Memberships
A Membership is a defined group of WD Fusion servers that replicate data between their Zones. You can have as many WD Fusion servers in a Membership as you like, and each WD Fusion server can participate in multiple Memberships. WD Fusion allows you to define multiple Memberships, and WD Fusion servers can fulfil different roles in each Membership they participate in. This allows you to control exactly how your WD Fusion environment operates normally, and how it behaves when faced with network failures, host failures and other types of issues.
Replication Rules
File system content is replicated selectively by defining Replication Rules, which specify: the directory in the file system that will be replicated, the Zones that will participate in that replication, and the Membership associated with those Zones. Without any Replication Rules defined, each Zone's file system operates independently of the others. With the combination of Zones, Memberships and Replication Rules, WD Fusion gives you complete control over how data are replicated between the file systems of your Hadoop clusters.
Induction
The process of forming a membership between a number of WD Fusion nodes is called Induction.
Apache Kafka
A fast, scalable, fault-tolerant messaging system
Kafka is a fast, scalable, durable, and fault-tolerant publish-subscribe messaging system. Kafka is often used in place of traditional message brokers like JMS and AMQP because of its higher throughput, reliability and replication.
Kafka works in combination with Apache Storm, Apache HBase and Apache Spark for real-time analysis and rendering of streaming data.
Writer
In the WD Fusion's architecture, only one process (node/fusion server) per zone is allowed to write into a replicated filespace - this node is the "Writer" for that replicated folder. Therefore, if there is one replicated folder and two zones, there will be two writers for the replicated folder, one in each zone. If there are two replicated folders and two zones there will be four writers, two in each zone.
The writer for a replicated folder does not have to be the same node as the writer for another replicated folder, e.g., node1 may be the writer for /dir1/dir2 and /dir1/dir3 and node2 may be the writer for /dir1/dir4, which allows for some degree of load-balancing across fusion servers within a zone. If a writer fails, the election process will ensure a new writer for that folder is elected within a given period (set through the process for Tuning Writer Re-election.
Currently, the writer for a replicated folder is elected at random - it may be any node in a zone. In a future release, WD Fusion will let administrators specify a particular node to be the writer, using the REST API. However, if the specified node fails another will be elected at random.
HDInsight
HDInsight deploys and creates Apache Hadoop clusters in the cloud, providing a software framework designed to manage, analyze, and report on big data with high reliability and availability. HDInsight uses the Hortonworks Data Platform (HDP) Hadoop distribution. Hadoop often refers to the entire Hadoop ecosystem of components, which includes Apache Hadoop, Apache Storm and Apache HBase clusters, as well as other technologies under the Hadoop umbrella.
Microsoft Azure
Azure is Microsoft's cloud computing platform, a growing collection of integrated services-analytics, computing, database, mobile, networking, storage, and web-for moving faster, achieving more, and saving money. Azure provides an Azure Preview Portal for monitoring and managing the cluster.
For more information, see What is Microsoft Azure? and Microsoft Azure infographics.
Azure resource group
Applications are typically made up of many components, for example a web app, database, database server, storage, and 3rd party services. Azure Resource Manager (ARM) enables you to work with the resources in your application as a group, referred to as an Azure Resource Group. You can deploy, update, monitor or delete all of the resources for your application in a single, coordinated operation. You use a template for deployment and that template can work for different environments such as testing, staging and production. You can clarify billing for your organization by viewing the rolled-up costs for the entire group. For more information, see Azure Resource Manager Overview.
Azure Blob storage
Azure Blob storage is a robust, general-purpose storage solution that integrates seamlessly with HDInsight. Through the WASB driver and the WebWasb (WebHDFS over WASB) interface, the full set of components in HDInsight can operate directly via standard Hadoop DFS tools (command line, File System Java API) on structured or unstructured data in Blob storage.
There are several benefits associated with using Azure Blob Storage as the native file system:
- Storing data in Blob storage enables users to safely delete the HDInsight clusters that are used for computation without losing user data.
- Data reuse and sharing
- Data storage cost
Although there an implied performance cost of not co-locating computer clusters and storage resources, this is mitigated by the way the compute clusters are created close to the storage account resources inside the Azure datacenter, where the high-speed network makes it very efficient for the compute nodes to access the data inside Azure Blob storage.
For more information, see Use Azure Blob storage with Hadoop in HDInsight.
Address files in Blob storage
HDInsight uses Azure Storage Blob through the WASB(S) (A.K.A Windows Azure Storage - Blob) driver. Azure Blob storage is transparent to users and developers.
To access the files on the default storage account, you can use one of the following syntax:
/example/jars/hadoop-mapreduce-examples.jar wasb:///example/jars/hadoop-mapreduce-examples.jar wasb://mycontainer@myaccount.blob.core.windows.net/example/jars/hadoop-mapreduce-examples.jar
If the data is store outside the default storage account, you must link to the storage account at the creation time. The URI scheme for accessing files in Blob storage from HDInsight is:
wasb[s]://<BlobStorageContainerName>@<StorageAccountName>.blob.core.windows.net/<path>
- wasb[s]: The URI scheme provides unencrypted access (with the wasb: prefix) and SSL encrypted access (with wasbs). We recommend using wasbs wherever possible, even when accessing data that lives inside the same datacenter in Azure.
- <BlobStorageContainerName>: Identifies the name of the container in Azure Blob storage.
- <StorageAccountName>: Identifies the Azure Storage account name. A fully qualified domain name (FQDN) is required.
- <path> is the file or directory HDFS path name. Because containers in Azure Blob storage are simply key-value stores, there is no true hierarchical file system. A slash character ( / ) inside a blob key is interpreted as a directory separator. For example, the blob name for hadoop-mapreduce-examples.jar is:
example/jars/hadoop-mapreduce-examples.jar
When working with blobs outside of HDInsight, most utilities do not recognize the WASB format and instead expect a basic path format, such as example/jars/hadoop-mapreduce-examples.jar.
Best Practices for using blob storage with HDInsight- Don't share a default container between two live clusters. This is not a supported scenario.
- Re-use the default container to reuse the same root path on a different cluster.
- Use additional linked storage account for user data.
WebWasb
WebHDFS is the implementation of HTTP Rest API for HDFS compatible file systems. WebWasb is simply WebHDFS for the WASB file system.
WebWasb can be installed on the edge node where the ISV applications live. From the edge node, WebWasb can be accessed by referring to localhost and the port 50073.
WebWasb works off of the default file system for the cluster (a specified default container in the default storage account) specified in /etc/hadoop/conf/core-site.xml under the property fs.defaultFS. As an example, if your default storage account is named storage1 and your default container is named container1, you could create a new directory called dir1 within that container by the following WebHDFS command:
Curl -i -X PUT http://localhost:50073/WebWasb/webhdfs/v1/dir1?op=MKDIRS
WebWasb commands are case sensitive, so pay specific attention to the casing of "WebWasb" and the operations should all be uppercase.
Azure virtual network
With virtual network integration, Hadoop clusters can be deployed to the same virtual network as your applications so that applications can communicate with Hadoop directly. The benefits include:
- Direct connectivity of web applications or ISV applications to the nodes of the Hadoop cluster, which enables communication to all ports via various protocols, such as HTTP or Java RPC.
- Improved performance by not having your traffic go over multiple gateways and load-balancers.
- Virtual network gives you the ability to process info more securely, and only provide specific endpoints to be accessed publicly.