
Subversion is a version control system, a software toolset that helps people to manage changes that are made to collections of shared files. Even when we work alone, most of us will make use of some form of version control, although often crude and inconsistent - such as when we use an application's SAVE AS and cook up a new file name to distinguish the new version from the old. Without version control systems, collaboration (especially in software development) quickly devolves into a horrible mess as different contributors make change to the same files, overwriting or just mangling each others work.
 VCS not SCM
VCS not SCM
There's a specialist form of version control system (called a Configuration Management system) designed specifically for handling software development. Although Subversion is most often used for software development it remains a mainstream version control system that is ready to handle files and documents of pretty much any type, and is occasionally put to novel use, such as managing backups, shared todo lists and even in the writing of collaborative fiction.
Subversion was originally written by a group of CVS (Concurrent Versioning System) users who were frustrated by CVS's drawbacks. They designed Subversion to build on CVS's stengths, while avoiding its limitations. So when people talk about Subversion's key features, they are usually talking about the things it does that CVS can't do.
Subversion uses an approach to versioning called Copy-Modify-Merge which has some big advantages over earlier systems that usually locked files when they were edited to ensure that two people couldn't change a file at the same time. With Copy-Modify-Merge any number of people can make a change to a file at the same time without problem. Each person takes a copy of the file from the repository, this is called a Working Copy and is a snapshot of the file from the latest revision. Changes are always made to this working copy, and when the editor is ready to share the changes, the file is committed back to the repository, where it is given a new revision number.
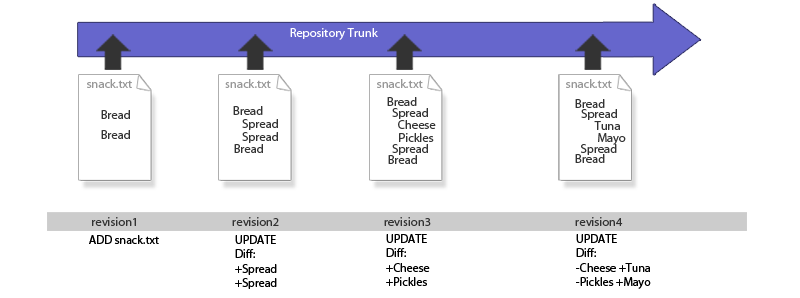
A file is added to the repository and undergoes a series of changes.
Each time the file is changed and committed to the repository it generates a new snapshot of the file. However, this snapshot is not a full copy of the file, instead it is a diff, which only contains a description of what has changed in the file. The above illustration shows how the changing state of snack.txt is recorded as series of additions and subtractions. No matter what changes are made, or when they are made, it will be possible to recreate any revision by applying the appropriate diffs.
Revision numbers are global, not file specific
The above illustration may give the impression that the revision number is specific to the file, as in snack.txt. In Subversion this is not the case as the revision number reflects any changes that are made within the entire file system. So it's not really revision 5 of snack.txt, more precisely it is the version of snack.txt that appears in revision 5 of the repository, even if it is the only change that was made in revision 5.
So, what does happen when two people make a change to the same file? How does Subversion handle conflicting changes? We'll run through an example situation, illustrated below.
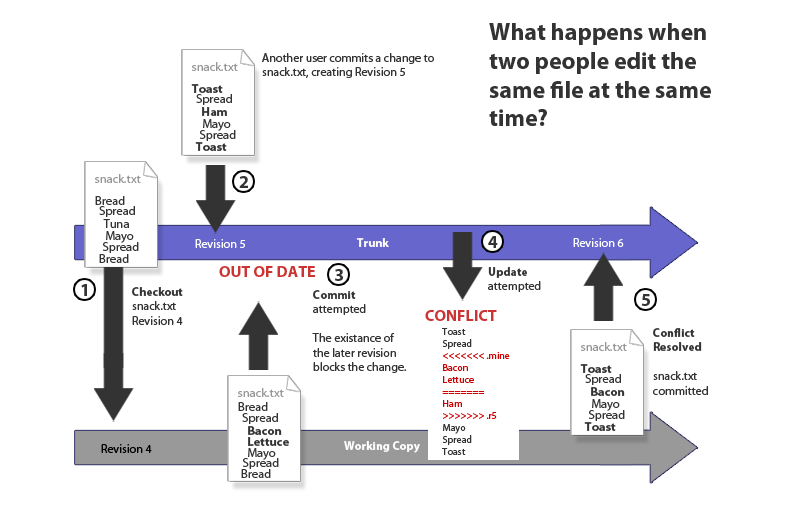
Using Subversion means your food fights leave an audit trail...
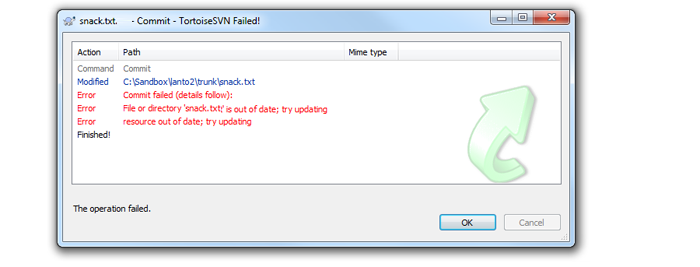
What an out of date error looks like on the Tortoise Subversion client (on Windows).
Tip
When Subversion detects a conflict it creates 3 temporary files:
file.mine (your current working copy)
file.rOldRev (the file at the revision before your changes were made)
file.rNewRev (the file as it is in the latest revision in the repository)
Subversion also annotates the original file to show the conflicts within the file (illustrated in the image below).
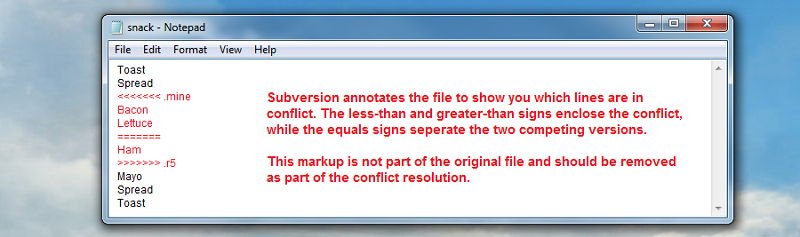
How a conflicted file is tagged to aid editing.
Tip
After a conflicted file has been fixed, you tell Subversion that the conflict has been resolved.
Subversion will then delete the three temp files and allow the file to be updated or committed.
Conflicts rarely occur if you remember to do an update of your local copy before making any changes.
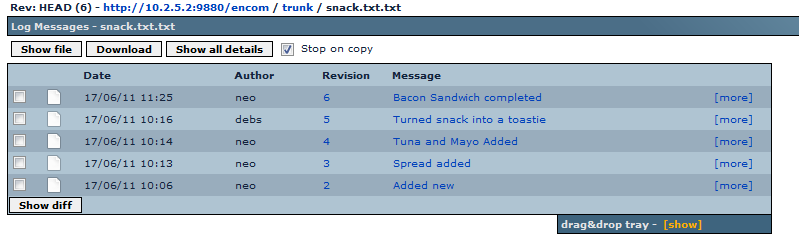
The log view of snack.txt showing the changes over.
Subversion doesn't force you to organize your files in any particular way, although there is a best practise for how to keep Subversion repository files. This isn't essential, but as the term 'best practise' suggests, everyone agrees this is a good way to work - especially those who started out by ignoring it and ended up in a mess.

A repository created with the recommended directory structure.
Prior to Subversion 1.7, every directory in a working copy contains a administrative directory called .svn. The files in each administrative directory help Subversion recognize which files contain unpublished changes, and which files are out of date with respect to others' work. There's never any good reason for entering the directory and making any manual changes - just leave it alone.
Subversion 1.7 contains a rewritten Working Copy Library (called WC:NG). This does away with seperate .svn directories, using instead a single .svn directory located in the repository's main directory.
 Alert
Alert
Don't delete or change anything in the .svn directory! Subversion depends on it to manage your working copy. If you accidentally remove the .svn subdirectory, the easiest way to fix the problem is to remove the entire directory (a normal system deletion, not svn delete), then do an svn update from a parent directory. The Subversion client will pull in a fresh copy of the directory you've deleted, along with a new .svn folder.
The trunk directory is for current development code. The name is a reference to a growing trunk of a tree, not a place to store your spare tyres. This is where your current release code should be stored. It's best not to muddy the Trunk directory with revisions or release names.
http://10.2.5.2:9880/encom/trunk
Growing off the trunk are your branches. Branches, like the branches of a tree are "offshoots" of the trunk. The idea is to use branches to work on significant changes, variations of code, without causing disruption to the current release code.
A major bug might be fixed on a branch created for this purpose. This allows for bug fixing changes to be worked on without the potential for disrupting other work going on in the trunk/development branches.
It's common to use a branch as a code "sandbox" when you want to try a new technology out. If everything gets broken, you can walk away, with no risk to the working code, but if the experiment works out, it can be easily merged back into the trunk.
http://10.2.5.2:9880/encom/branches/R1.02 http://10.2.5.2:9880/encom/branches/soapflax
Finally there are tags. Tags work like branches, but are not meant to be developed. Instead, they are code milestones, giving you a snapshot of the code at specific points in its history.
http://10.2.5.2:9880/encom/tags/version1.03
When you create a code or bug fix branch it's useful to create a tag of the code before the changes are made (called the "PRE" tag) and a tag after the bugfix or code change has been made (called the "POST" tag).
http://10.2.5.2:9880/encom/tags/PRE_authchange_bug9343 http://10.2.5.2:9880/encom/tags/POST_authchange_bug9343
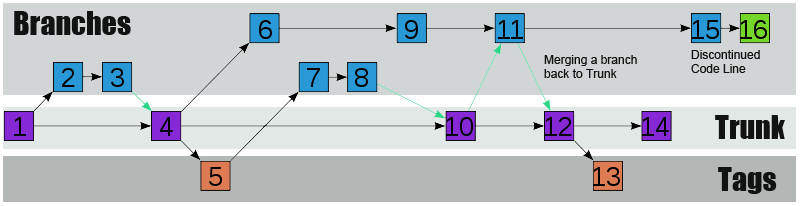
An illustration of how a Subversion Repository evolves using branching, tagging and a code trunk.
Alert
Subversion itself makes no distinction between tags and branches. It won't stop you from committing changes to tags or fixing major bugs on the trunk, it's important that you are aware of this so you can guard against mistakes. A benefit of using a Subversion client such as TortoiseSVN is that they add a lot of useful functionality that helps you guard against errors.
LDAP stands for Lightweight Directory Access Protocol. It's a kind of database language that is optimised for handling information look-ups, ideal for an organisational address book, or in this case an authentication directory that controls user access to an organisation's systems, such as Subversion repositories.
Lightweight, you say? To the uninitiated, LDAP looks a bit involved, and some question whether it could be described as lightweight. But, compared to its predecessor, X.500, LDAP is in fact much more lightweight. X.500 doesn't use the Internet standard TCP/IP protocol, has very convoluted naming conventions, and requires a lot of resources to implement. LDAP keeps most of X.500's good stuff, but is simpler to setup and use.
LDAP arranges information in the form of a hierarchical tree, made up of entries which are themselves made up of a number of attributes. At the top of the tree are the top level entries such as organisation, country or company with lower level entries dealing with people, products or systems etc. Some LDAP directories use the Internet domain naming system for their arrangement which allows for directory services to be located using the DNS.
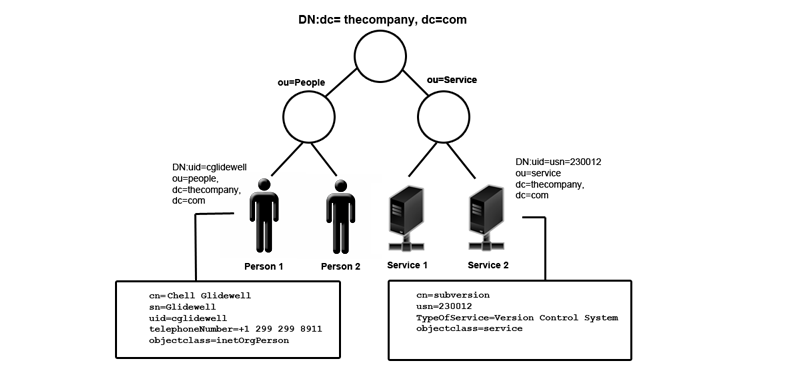
LDAP example
The above illustration shows a simple directory for 'thecompany'. Entries are identified using globally-unique Distinguished Name (DN), which allows each entry to be referenced without fear of duplication or ambiguity. The DN of an entry is formed by taking the name of the entry, called the Relative Distinguished Name (RDN) and concatenating the names of the entries that sit above it on the directory tree.
example Chell Glidewell's LDAP entry has an RDN of uid=cglidewell The DN is uid=cglidewell,ou=People,dc=thecompany,dc=com.
Each of the entry's attributes has a type and one or more values. The types are typically mnemonic strings, like "cn" for common name, or "mail" for email address. Different attributes use different syntax. For example, a cn attribute might contain the value Chell Glidewell. A telephoneNumber attribute might contain the value "+1 299 299 8911".
LDAP lets you control which attributes are required for an entry, using a special attribute called objectClass. The values of objectClass determind the schema rule for the entry.
Copyright © 2010 WANdisco Inc.
All Rights Reserved
This product is protected by copyright and distributed under
licenses restricting copying, distribution and decompilation.
uberSVN 11.8 Build:7270
Last doc build: 14:25 - Thursday 28th July 2011