Deployment options
There are three options for deploying LiveData Migrator for Azure.
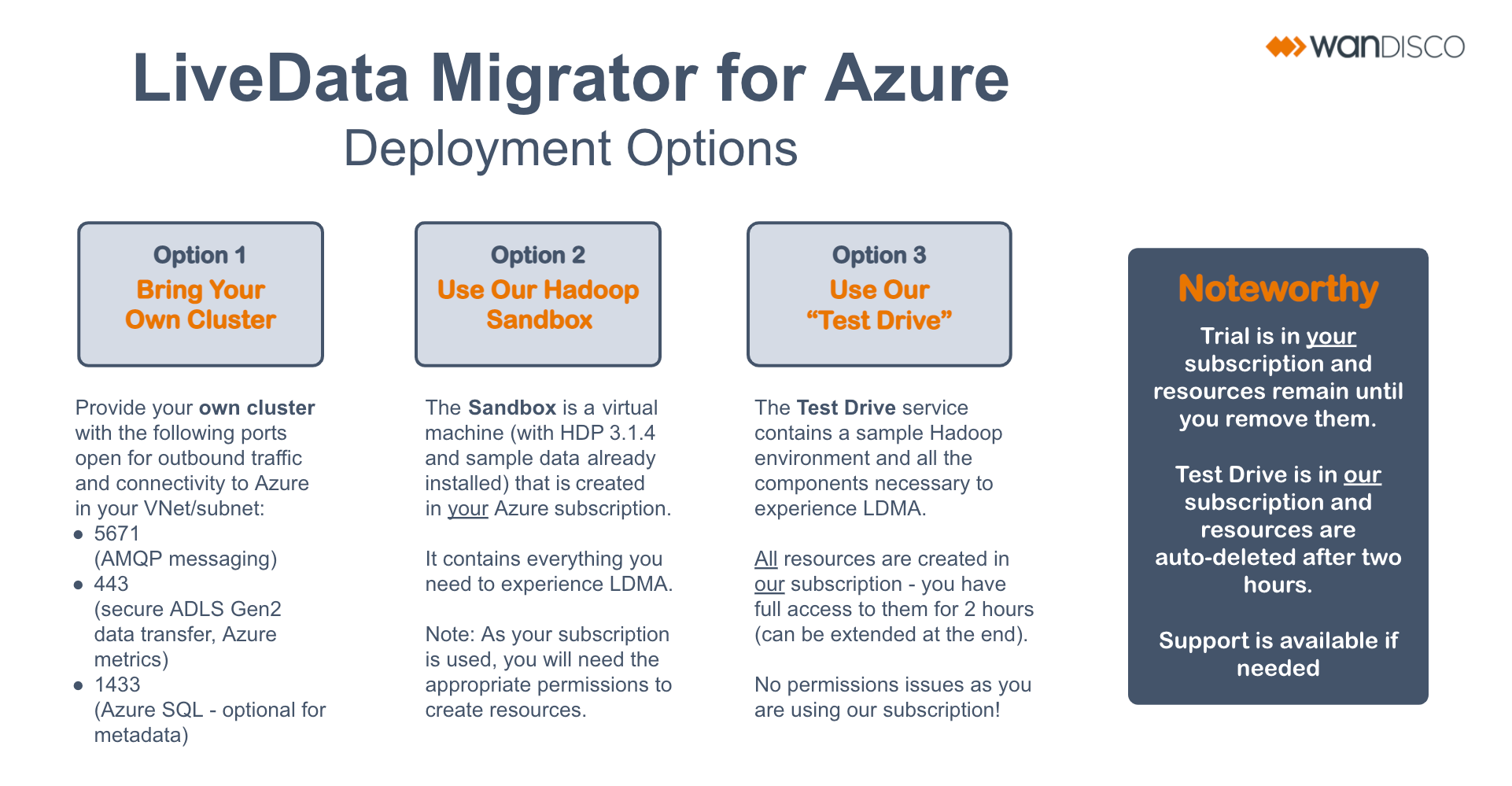
Bring your own cluster
Use your own cluster with the following ports open for outbound traffic and connectivity to Azure in your Azure Virtual Network (VNet) or subnet:
| Port | Required for |
|---|---|
| 5671 | Advanced Message Queuing Protocol |
| 443 | Transferring Azure Data Lake Storage (ADLS) Gen2 data securely; Azure metrics |
| 1443 | Connecting to the Azure SQL Database (optional for transferring metadata) |
Other requirements
In addition to ensuring the ports are open, you will need the following:
- Azure resource group to contain resources related to LiveData Migrator.
- Root access to your Hadoop cluster to install LiveData Migrator.
- ADLS Gen2 storage account and container with an enabled hierarchical namespace.
- Owner/Contributor-level access to the resource group chosen.
- Azure CLI (version 2.26 or higher) - this is only necessary if you'd like to use LiveData Migrator with your command line.
- Azure SQL Database - required for Hive metadata migration only.
- Databricks cluster - required for Databricks metadata migration only.
- Snowflake warehouse - required for Snowflake metadata migration only.
For more information, see the Prerequisites section of the user guide.
Sandbox
The Sandbox WANdisco provides is a virtual machine (with HDP 3.1.4 and sample data already installed) that is created in your Azure subscription. It contains everything you need to test LiveData Migrator.
See the LiveData Migrator for Azure Sandbox guide to get started.
You need permission to create resources in your subscription to deploy LiveData Migrator for Azure.
Test Drive
The "Test Drive" service contains a sample Hadoop environment and all the components necessary to experience LiveData Migrator.
All resources are created in our subscription. You have full access to the resources for two hours, with the option to extend your access in Azure portal.
You don't need any additional permission to create resources as you use our subscription.
See the Test Drive page to get started.