2. Installation Guide
This section will run through the installation of WD Fusion from the initial steps where we make sure that your existing environment is compatible, through the procedure for installing the necessary components and then finally configuration.
Deployment Overview
We'll start with a quick overview of this installation guide so that you can seen what's coming or quickly find the part that you want:
- 2.1 Deployment Checklist
- Important hardware and software requirements, along with considerations that need to be made before starting to install WD Fusion.
- 2.2 Final Preparations
- Things that you need to do immediately before you start the installation.
- 2.3 Installation procedure
- Step by step guide to the installation process.
- 2.4 Configuration
- Runs through the changes you need to make to start WD Fusion working on your platform.
- 2.5 Deployment
- Necessary steps for getting WD Fusion to work with supported Hadoop applications.
- 2.6 Appendix
- Extras that you may need that we didn't want cluttering up the installation guide - Installation Troubleshooting, How to remove an existing WD Fusion installation.
WD Fusion 2.2 Unified installation
WD Fusion is now has a unified installation package that installs all of WD Fusion's components (WD Fusion server, IHC servers and WD Fusion UI). If you need help running through the installation of an earlier version of WD Fusion or need to co-opt the earlier version's orchestration script, see the Orchestration Installation Guide.
See the latest version of the Orchestration mydefines.sh file.
2.1 Deployment Checklist
2.1.1 WD Fusion and IHC servers' requirements
This section describes hardware requirements for deploying Hadoop using WD Fusion. These are guidelines that provide a starting point for setting up data replication between your Hadoop clusters.
Glossary
We'll be using terms that relate to the Hadoop ecosystem, WD Fusion and WANdisco's DconE replication technology. If you encounter any unfamiliar terms checkout out the Glossary.
WD Fusion Deployment Components
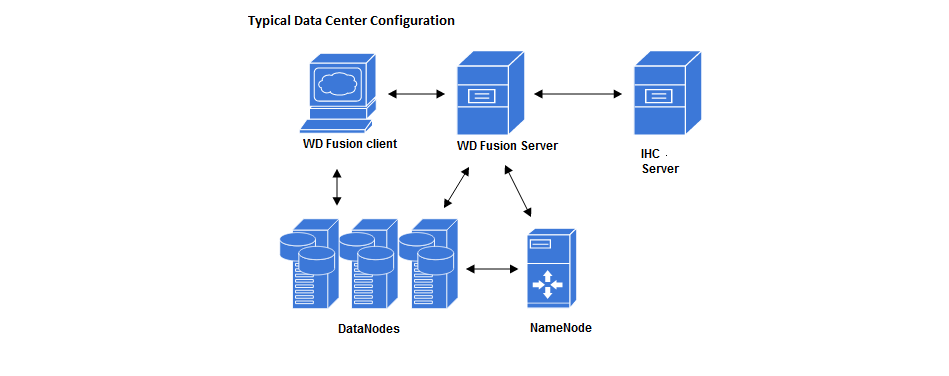
Example WD Fusion Data Center Deployment.
- WD Fusion Server
- The core WD Fusion server. Using HCFS (Hadoop Compatible File System) to permit the replication of HDFS data between data centers, while maintaining strong consistency.
- WD Fusion UI
- A seperate server that provides administrators with a browser-based management console for each WD Fusion server. This can be installed on the same machine as WD Fusion's server or on a different machine within your data center.
- IHC Server
- Inter Hadoop Communication servers handle the traffic that runs between zones or data centers that use different versions of Hadoop. IHC Servers are matched to the version of Hadoop running locally. It's possible to deploy different numbers of IHC servers at each data center, additional IHC Servers can form part of a High Availability mechanism.
- WD Fusion Client
- Client jar files to be installed on each Hadoop client, such as mappers and reducers that are connected to the cluster. The client is designed to have a minimal memory footprint and impact on CPU utilization.
WD Fusion servers can co-located with IHC servers
Providing that a server has sufficient resources, it is possible to co-locate your WD Fusion server with the IHC servers.
WD Fusion servers must not be co-located with HDFS servers (DataNodes, etc)
HDFS's default block placement policy dictates that if a client is co-located on a DataNode, then that co-located DataNode will receive 1 block of whatever file is being put into HDFS from that client. This means that if the WD Fusion Server (where all transfers go through) is co-located on a DataNode, then all incoming transfers will place 1 block onto that DataNode. In which case the DataNode is likely to consumes lots of disk space in a transfer-heavy cluster, potentially forcing the WD Fusion Server to shut down in order to keep the Prevaylers from getting corrupted.
The following guidelines apply to both the WD Fusion server and for separate IHC servers. We recommend that you deploy on physical hardware rather than on a virtual platform, however, there are no reasons why you can't deploy on a virtual environment.
If you plan to locate both the WD Fusion and IHC servers on the same machine then check the Collocated Server requirements:
| CPUs: | Small WD Fusion server Deployment : 8 cores Large WD Fusion server deploymet: : 16 cores Architecture: 64-bit only. |
| System memory: | There are no special memory requirements, except for the need to support a high throughput of data:
Type: Use ECC RAM Size: Recommended 64 GB recommended (minimum of 16 GB) Small WD Fusion server Deployment: 32GB Large WD Fusion server deploymet: 128GB System memory requirements are matched to the expected cluster size and should take into account the number of files and block size. The more RAM you have, the bigger the supported file system, or the smaller the block size. Collocation of WD Fusion/IHC servers |
| Disk space: | Type: Hadoop operations are disk-intensive so we strongly recommend that you use Enterprise class Solid State Drives (SSDs). Size: Recommended: 1 TB Minimum: You need at least 500 GB of disk space for a production environment. |
| Network | Connectivity: Minimum 1Gb Ethernet between local nodes. Small WANdisco Fusion server: 2Gbps Large WANdisco Fusion server: 4x10 Gbps (cross-rack) TCP Port Allocation: Two ports are required for deployment of WD Fusion: DConE port: (default 8082) IHC ports: (7000 range for command ports) (8000 range for HTTP) HTTP interface: (default 50070) is re-used from the stand-alone Hadoop NameNode Web UI interface: (default 8083) |
2.1.2 Software requirements
| Operating systems: |
|
| Java: | Hadoop requires Java JRE 1.7. It is built and tested on Oracle's version of Java Runtime Environment, which is used in most test environments. We do not recommend using a different version of Java. Architecture: 64-bit only Heap size: Set Java Heap Size of to a minimum of 1Gigabytes, or the maximum available memory on your server. Use a fixed heap size. Give -Xminf and -Xmaxf the same value. Make this as large as your server can support. Avoid Java defaults. Ensure that garbage collection will run in an orderly manner. Configure NewSize and MaxNewSize Use 1/10 to 1/5 of Max Heap size for JVMs larger than 4GB. Stay deterministic! Where's Java? Ensure that you set the JAVA_HOME environment variable for the root user on all nodes. Remember that, on some systems, invoking sudo strips environmental variables, so you may need to add the JAVA_HOME to Sudo's list of preserved variables. |
| File descriptor/Maximum number of processes limit: | Maximum User Processes and Open Files limits are low by default on some systems. It is possible to check their value with the ulimit or limit command:
ulimit -u && ulimit -n
-u The maximum number of processes available to a single user. For optimal performance, we recommend both hard and soft limits values to be set to 64000 or more: RHEL6 and later: A file /etc/security/limits.d/90-nproc.conf explicitly overrides the settings in security.conf, i.e.:
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 1024 <- Increase this limit or ulimit -u will be reset to 1024
Both Ambari and Cloudera manager will set various ulimit entries, you must ensure hard and soft limits are set to 64000 or higher. Check with the ulimit or limit command. If the limit is exceeded the JVM will throw an error: java.lang.OutOfMemoryError: unable to create new native thread.
|
| Additional requirements: | passwordless ssh If you plan to set up the cluster using the supplied WD Fusion orchestration script you must be able to establish secure shell connections without using a passphrase. KB Security Enhanced (SE) Linux You need to disable Security-Enhanced Linux (SELinux) for the installation to ensure that it doesn't block activity that's necessary to complete the installation. Disable SELinux on all nodes, then reboot them: sudo vi /etc/sysconfig/selinuxSet SELINUX to the following value: SELINUX=disabled iptables Disable iptables. $ sudo chkconfig iptables offReboot. When the installation is complete you can re-enable iptables using the corresponding command: sudo chkconfig iptables on Comment out requiretty in /etc/sudoersThe installer's use of sudo won't work with some linux distributions (CentOS where /etc/sudoer sets enables requiretty, where sudo can only be invoked from a logged in terminal session, not through cron or a bash script. When enabled the installer will fail with an error:
execution refused with "sorry, you must have a tty to run sudo" messageEnsure that requiretty is commented out: # Defaults requiretty |
2.1.3 Supported versions
This table shows the versions of Hadoop and Java that we currently support:
| Distribution: | Console: | JRE: |
| Apache Hadoop 2.5.0 | Oracle JDK 1.7_45 64-bit | |
| HDP 2.1 / 2.2 | Ambari 1.6.1 / 1.7 Support for EMC Isilon 7.2.0.1 and 7.2.0.2 |
Oracle JDK 1.7_45 64-bit |
| CDH 5.2.0/5.3.0/5.4 | Cloudera Manager 5.3.2 Support for EMC Isilon 7.2.0.1 and 7.2.0.2 |
Oracle JDK 1.7_45 64-bit |
2.2 Final Preparations
We'll now look at what you should know and do as you begin the installation.
Time requirements
The time required to complete a deployment of WD Fusion will in part be based on its size, larger deployments with more nodes and more complex replication rules will take correspondingly more time to set up. Use the guide below to help you plan for for deployments.
- Run through this document and create a checklist of your requirements. (1-2 hours).
- Complete the WD Fusion server installations (20 minutes per node, or 1 hour for a test deployment).
- Install WD Fusion UI (30 minutes).
- Complete client installations and complete basic tests (1-2 hours).
Of course, this is a guideline to help you plan your deployment. You should think ahead and determine if there are additional steps or requirements introduced by your organization's specific needs.
Network requirements
See the deployment checklist for a list of the TCP ports that need to be open for WD Fusion.
Running WD Fusion on multi-homed servers
The following guide runs through what you need to do to correctly configure a WD Fusion deployment if the nodes are running with multiple network interfaces.
Overview
- A file is created in DC1. A Client writes the Data.
- Periodically after the data is written, a proposal is sent by the WD Fusion Server in DC1, telling the WD Fusion server in DC2 to pull the new file. This proposal includes the map of IHC server public IP addresses, in this case, listening at <Public-IP>:7000 (Fusion Server in DC1 read this from
/etc/wandisco/fusion/server/ihcList)
- Fusion Server in DC2 gets this agreement, connects to <Public-IP>:7000 and pulls the data.
Procedure
- Stop all WD Fusion services.
- Reconfigure your IHCs to your preferred address in /etc/wandisco/ihc/*.ihc for each IHC node.
- For the WD Fusion servers, delete all files in /etc/wandisco/fusion/server/ihclist/*.
- Copy zone1 IHC's
/etc/wandisco/ihc/*.ihcfiles to zone1 Fusion-Server/etc/wandisco/server/ihcList - Copy zone2 IHC's
/etc/wandisco/ihc/*.ihcfiles to zone2 Fusion-Server/etc/wandisco/server/ihcList - Restart all services
Kerberos Security
If you are running Kerberos on your cluster you should consider the following requirements:
- Kerberos is already installed and running on your cluster
- Fusion-Server is configured for Kerberos as described in Setting up Kerberos.
- We will be using the same keytab and principal we generated for fusion-server. Assume it's in
/etc/hadoop/conf/fusion.keytab
Update Fusion-UI configuration:
- Copy DC's /etc/hadoop/conf/hdfs-site.xml into fusion UI's lib folder:
/opt/wandisco/fusion-ui-server/lib/ - Copy DC's /etc/hadoop/conf/core-site.xml into fusion UI's lib folder:
/opt/wandisco/fusion-ui-server/lib/ - Add core-site.xml and hdfs-site.xml path to the configuration file:
client.core.site=/etc/hadoop/conf/core-site.xml client.hdfs.site=/etc/hadoop/conf/hdfs-site.xml - Enable kerberos in fusion-ui configuration (
/opt/wandisco/fusion-u-serveri/properties/ui.properties):kerberos.enabled=true kerberos.generated.config.path=/opt/wandisco/fusion-ui-server/properties/kerberos.cfg kerberos.keytab.path=/etc/hadoop/comf/fusion.keytab kerberos.principal=fusion/${hostname}@${krb_realm}
Clean Environment
Before you start the installation you must ensure that there are no existing WD Fusion installations or WD Fusion components installed on your elected machines. If you are about to upgrade to a new version of WD Fusion you must first make sure that you run through the removal instructions provided in the Appendix - Cleanup WD Fusion.
Installer File
You need to match WANdisco's WD Fusion installer file to each data center's version of Hadoop. Installing the wrong version of WD Fusion will result in the IHC servers being misconfigured.
License File
After completing an evaulation deployment, you will need to contact WANdisco about getting a license file for your moving your deployment into production.
2.3 Installation procedure
- Open a terminal session on your first installation server. Copy the WD Fusion installer script into a suitable directory.
- Make the script executable, e.g.
chmod +x fusion-ui-server-<version>_rpm_installer.sh - Execute the file with root permissions, e.g.
sudo ./fusion-ui-server-<version>_rpm_installer.sh - The isntaller will now start.
The installer will perform an integrity check, confirm the product version that will be installed, then invite you to continue. Enter "Y" to continue the installation.Verifying archive integrity... All good. Uncompressing WANdisco Fusion............ :: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### ##### Welcome to the WANdisco Fusion installation You are about to install WANdisco Fusion version 2.2-57 Do you want to continue with the installation? (Y/n) y - The installer performs some basic checks and lets you modify the Java heap settings. The heap settings apply only to the WD Fusion UI.
The installer checks for Perl and Java. See the Installation Checklist for more information about these requirements. Enter "Y" to continue the installation.Checking prerequisites: Checking for perl: OK Checking for java: OK INFO: Using the following Memory settings: INFO: -Xms128m -Xmx512m Do you want to use these settings for the installation? (Y/n) y - Next, confirm the port and system user accounts that will run WD Fusion.
You need to confirm the TCP port on which the WD Fusion UI will be served. The default value is 8083. See the deployment checklist about WD Fusions full TCP port requirements.Which port should the UI Server listen on? [8083]: We strongly advise against running Fusion as the root user. Which user should Fusion run as? hdfs Which group should Fusion run as? hdfs
Next you need to enter the system user and group with which WD Fusion will be run.Ensure system user "hdfs"
Ensure that you have user "hdfs" on your Fusion Servers. This is because the WD Fusion server is started as user "hdfs" and will fail otherwise.Never run WD Fusion using the root user
Should exploits exist this would open the entire system to possible intrusion.
We recommend that you use thehdfs. - Check the summary to confirm that you're happy with your chosen settings:
You are now given a summary of all the settings provided so far. If these settings are correct then enter "Y" to complete the installation of the WD Fusion server.Installing with the following settings: UI Hostname: <YOUR-SERVER-ADDRESS.com UI Port: 8083 Target Hostname: <YOUR-SERVER-ADDRESS.com Target Port: 8082 Application Minimum memory: 128 Application Maximum memory: 512 Do you want to continue with the installation? (Y/n) y - The WD Fusion server will now start up:
At this point the WD Fusion server and corresponding IHC server will be installed. The next step is to configure the WD Fusion UI. Open a web browser and point it at the provided URL. E.gWANdisco Fusion IHC Server installed successfully. WANdisco Fusion Server installed successfully. Starting delegate:[ OK ] Starting ui:[ OK ] Checking if the GUI is listening on port 8083: .....Done Please visit http://<YOUR-SERVER-ADDRESS>.com:8083/ to access the WANdisco Fusion Installation Complete [root@cert01-vm1 opt]#http://<YOUR-SERVER-ADDRESS>.com:8083/ - In the first "Welcome" screen you're asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows:- Creating a new WD Fusion cluster
- Select Create a new Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
- Select Add to an existing Zone.
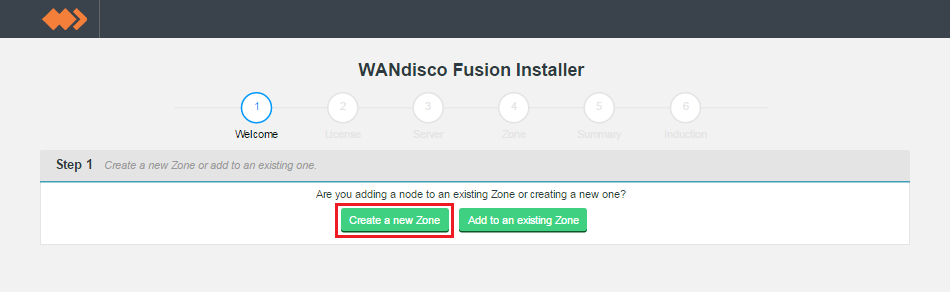
Welcome.
- Select your license file.
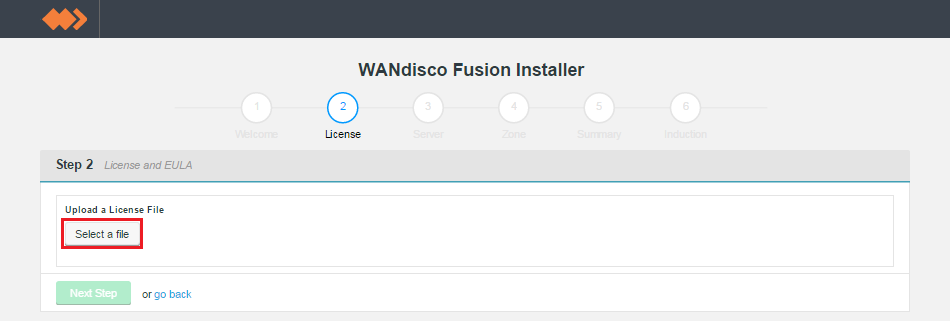
License screen.
- Upload the license file.
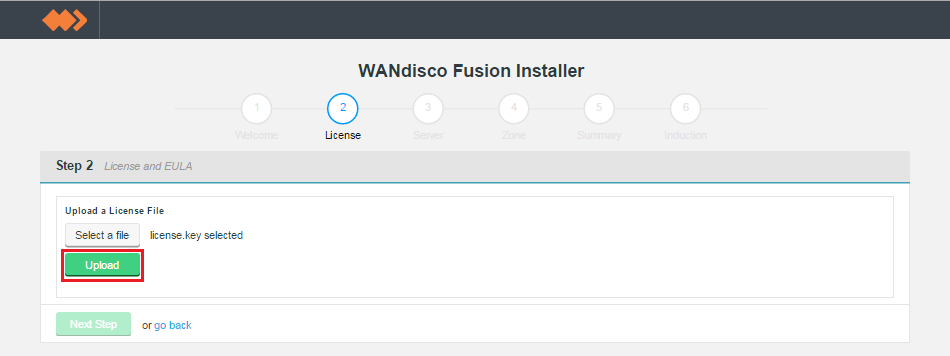
Upload your license file.
- The conditions of your license agreement will be presented in the top panel, including License Type, Expiry data, Name Node Limit and Data Node Limit.
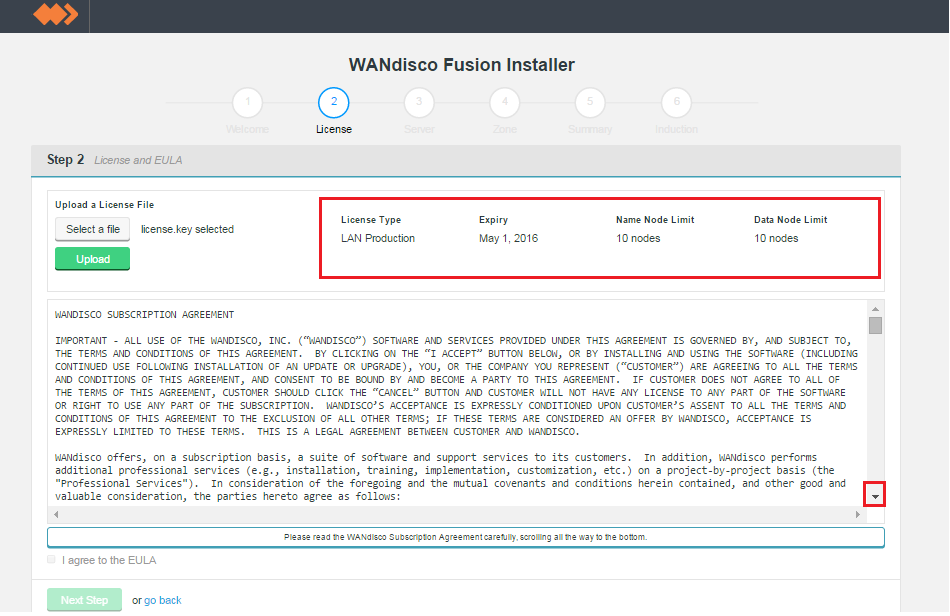
Verify license and agree to subscription agreement.
- Click on the I agree to the EULA to continue.

Next step.
- Enter settings for the WD Fusion server.
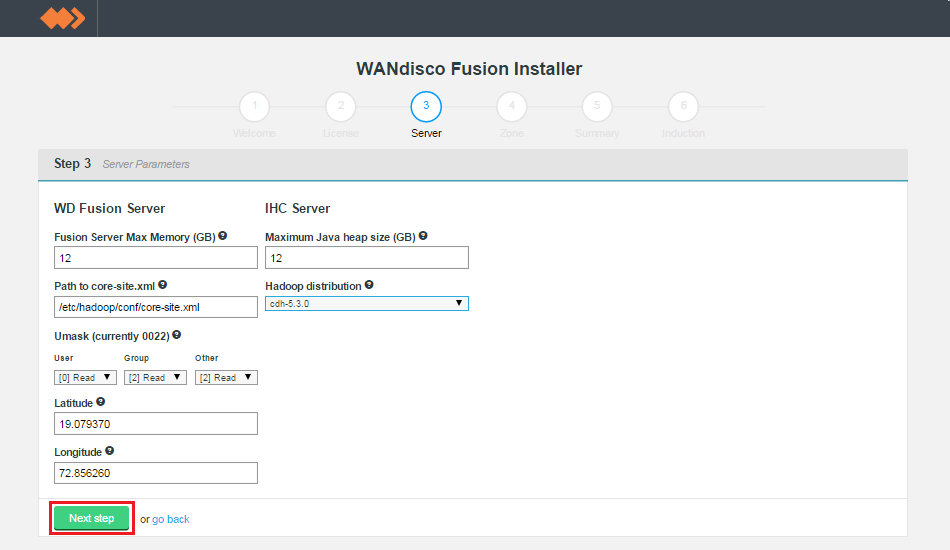
screen 6.
WD Fusion Server
- Fusion Server Max Memory (GB)
- Enter the maximum Java Heap value for the WD Fusion server.
- Path to core-site.xml
- The local file system path for Hadoop's
core-site.xmlconfiguration file. - Umask (currently 022)
- Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
- Latitude
- The north-south coordinate angle for the installation's geographical location.
- Longitude
- The east-west coordinate angle for the installation's geographical location. The latitude and longitude is used to place the WD Fusion server on a global map to aid coordination in a far-flug cluster.
IHC Server
- Maximum Java heap size (GB)
- Enter the maximum Java Heap value for the WD Inter-Hadoop Communication server.
- Next, you will enter the settings for your new Zone.
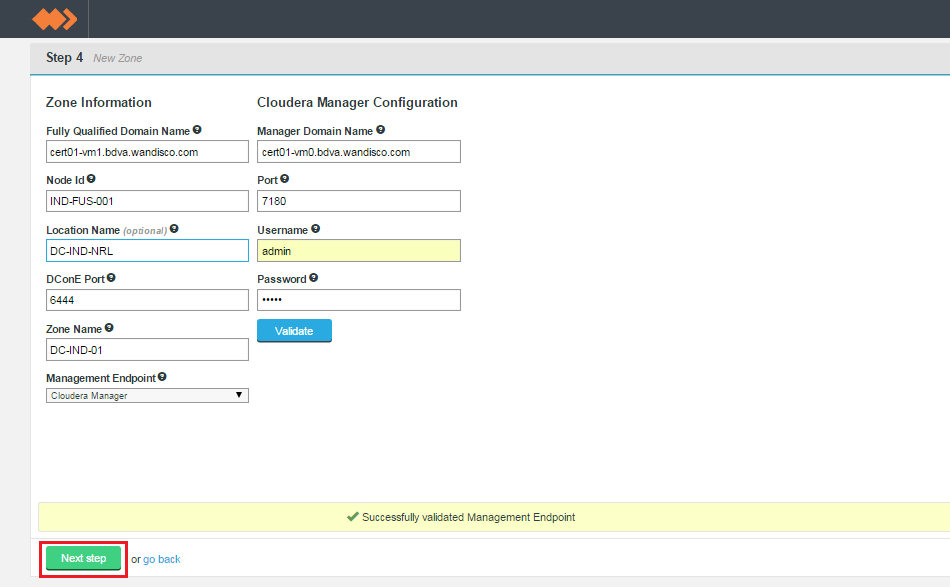
New Zone
Zone Information
Entry fields for zone properties
- Fully Qualified Domain Name
- the full hostname for the server.
- Node Id
- A unique idenfier that will be used by WD Fusion UI to identify the server.
- Location Name (optional)
- A location name that can quickly identify where the server is located.
- DConE Port
- TCP port used by WD Fusion for replicated traffic.
- Zone Name
- The name used to identify the zone in which the server operates.
- Management Endpoint
- Select the Hadoop manager that you are using, i.e. Cloudera Manager or Ambari. The selection will trigger the entry fields for your selected manager:
<Hadoop Management Layer> Configuration
- Manager Domain Name
- The full hostname for the working server that hosts the Hadoop manager.
- Port
- TCP port on which the Hadoop manager is running.
- Username
- The username of the account that runs the Hadoop manager.
- Password
- The password that corresponds with the above username.
- Click Validate to confirm that your settings are valid. Once validated, click Next step.
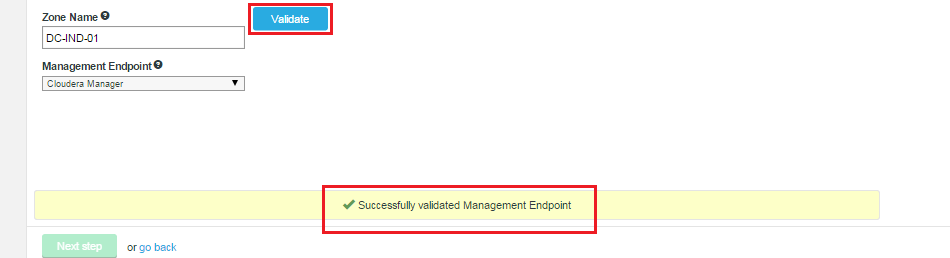
Zone information.
- In Step 5 we get a detailed summary of all the installation settings. All your license, WD Fusion and IHC server settings are shown. If you spot anything that needs to be changed you can click on the go back
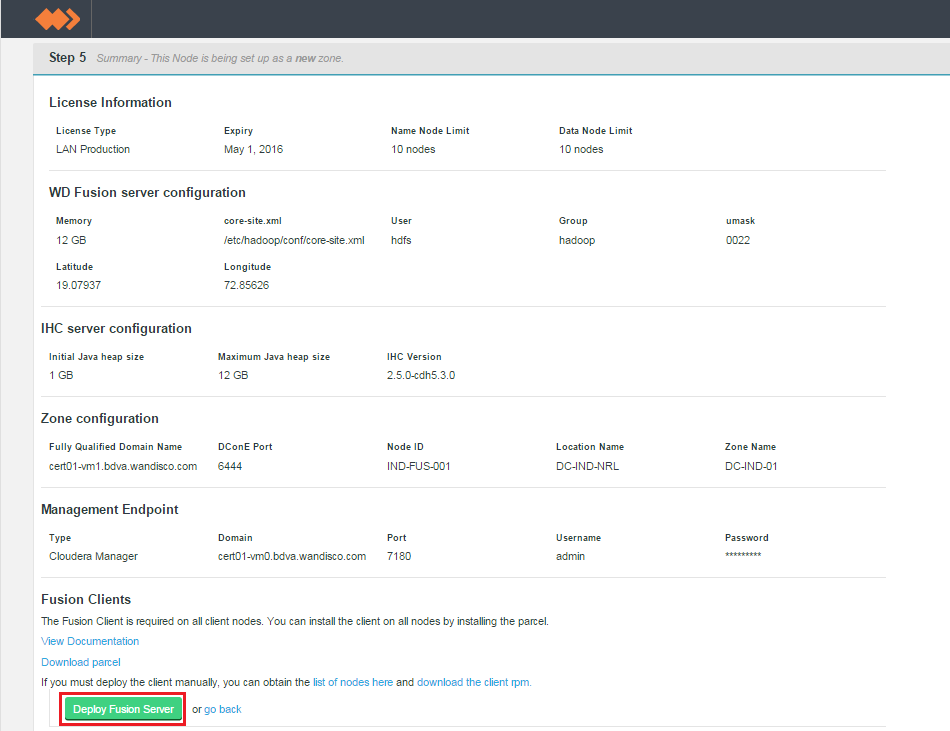
Summary
Fusion Clients
The WD Fusion client is required on all client nodes. There's an link at the bottom of the screen to the package / parcel file, as well as a link to dynamically generated list of nodes in the deployment.
For more information see Fusion Client installation.
Once you are happy with the settings and all your WD Fusion clients are installed, click Deploy Fusion Server. - The next step details with induction. Where the newly installed WD Fusion server is connected to an existing WD Fusion deployment.
First WD Fusion node installation
When installing WD Fusion for the first time, this step is skipped. Click Skip Induction.
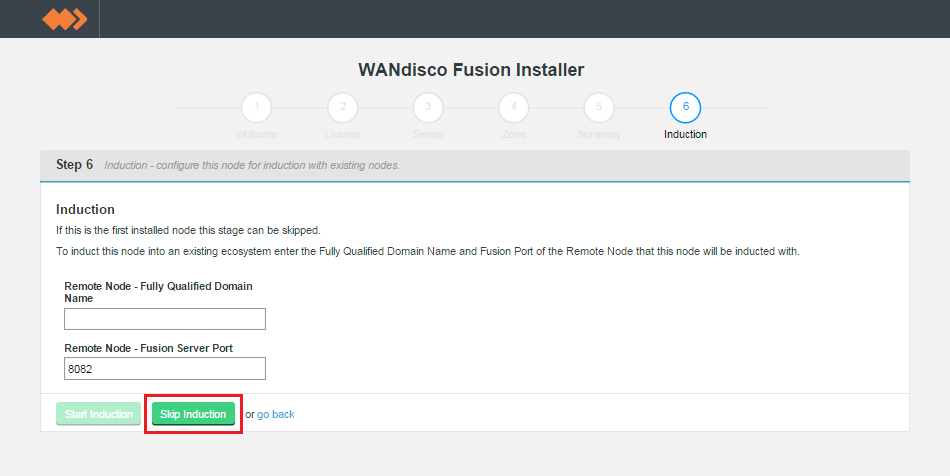
Skip or start.
Second and subsequent WD Fusion node installations
For the second and all subsequent WD Fusion nodes in a zone, you must complete the induction step. Enter the fully qualified domain name for the existing node, along with the WD Fusion server port (8082 by default). Click Start Induction.
- The installation will now complete.
Completying installation. Please wait.
- Once the installation is complete you will get access to the WD Fusion UI.
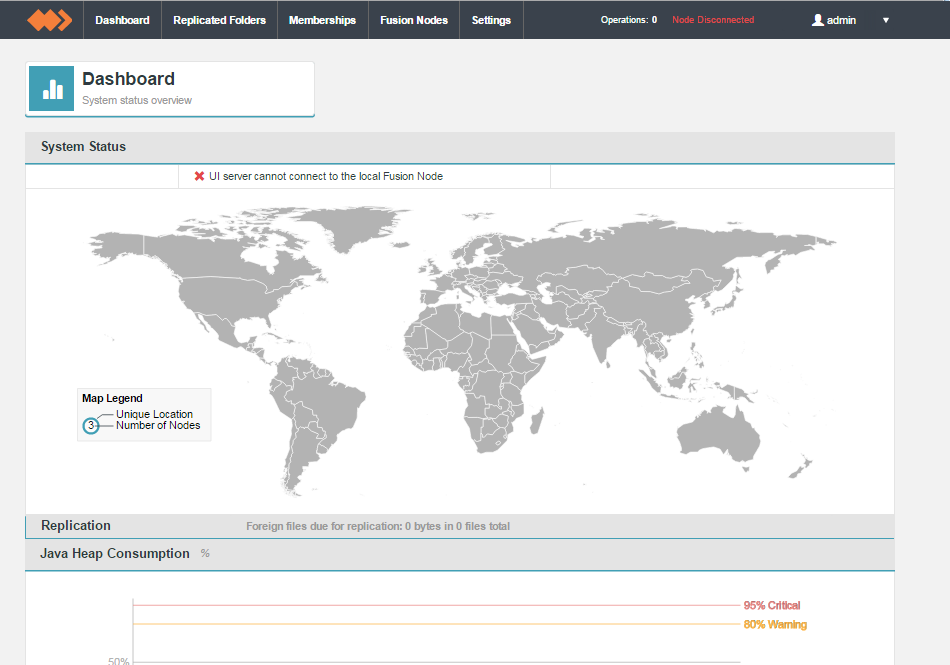
WD Fusion UI
2.4 Configuration
Once WD Fusion has been installed on all data centers you can proceed with setting up replication on your HDFS file system. You should plan your requirements ahead of the installation, matching up your replication with your cluster to maximise performance and resiliance. The next section will take a brief look at a example configuration and run through the necessary steps for setting up data replication between two data centers.
Replication Overview

Example WD Fusion Deployment in a 3 data center deployment.
In this example, each one of three data centers ingests data from it's own datasets, "Weblogs", "phone support" and "Twitter feed". An administrator can choose to replicate any or all of these data sets so that the data is replicated across any of the data centers where it will be available for compute activiities by the whole cluster. The only change required to your Hadoop applications will be the addition of a replication specific URI. You can read more about adapting your Hadoop applications for replication.
Setting up Replication
The following steps are used to start replicating hdfs data. The detail of each step will depend on your cluster setup and your specific replication requirements, although the basic steps remain the same.
- Create a membership including all the data centers that will share a particular directory. See Create Membership
- Create and configure a Replicated Folder. See Replicated Folders
- Perform a consistency check on your replicated folder. See Consistency Check
- Configure your Hadoop applications to use WANdisco's protocol. See Configure Hadoop for WANdisco replication
- Run Tests to validate that your replicated folder remains consistent while data is being written to each data center. See Testing replication
2.5 Deployment
The deployment section covers the final step in setting up a WD Fusion cluster, where supported Hadoop applications are plugged into WD Fusion's synchronized distributed namespace. It won't be possible to cover all the requirements for all the third-party software covered here, we strongly recommend that you get hold of the documenation that corresponds to each Hadoop application before you work through these procedures.
2.5.1 Hive
This guide integrates WD Fusion with Apache Hive, it aims to accomplish the following goals:
- Replicate Hive table storage.
- Use fusion URIs as store paths.
- Use fusion URIs as load paths.
- Share the Hive metastore between two clusters.
Prerequisites
- Knowledge of Hive architecture.
- Ability to modify Hadoop site configuration.
- WD Fusion installed and operating.
Replicating Hive Storage
In order to store a Hive table in WD Fusion you specify a WD Fusion URI when creating a table. E.g. consider creating a table called log that will be stored in a replicated directory.
CREATE TABLE log(requestline string) stored as textfile location 'fusion:///repl1/hive/log';
Exceptions
Hive from CDH 5.3/5.4 does not work with WD Fusion, as a result of HIVE-9991. The issue will be addressed once this fix for Hive is released.
This requires that modify the default Hive file system setting when using CDH 5.3 and 5.4. In Cloudera Manager, add the following property to hive-site.xml:
<property>
<name>fs.defaultFS</name>
<value>fusion:///</value>
</property><
This property should be added in 3 areas:
- Service Wide
- GateWay Group
- Hiveserver2 group
Replicated directories as store paths
It's possible to configure Hive to use WD fusion URIs as output paths for storing data, to do this you must specify a fusion URI when writing data back to the underlying Hadoop-compatible file system (HCFS). For example, consider writing data out from a table called log to a file stored in a replicated directory:
INSERT OVERWRITE DIRECTORY 'fusion:///repl1/hive-out.csv' SELECT*FROMlog;
Exceptions
HDP 2.2
When running MapReduce jobs on HDP 2.2, you need to append the following entry to mapreduce.application.classpath in mapred-site.xml:
/usr/hdp/<hdp version>/hadoop-hdfs/lib/*
Replicated directories as load paths
In this section we'll describe how to configure Hive to use fusion URIs as input paths for loading data.
It is not common to load data into a Hive table from a file using the fusion URI. When loading data into Hive from files the core-site.xml setting fs.default.name must also be set to fusion, which may not be desirable. It is much more common to load data from a local file using the LOCAL keyword:
LOAD DATA LOCAL INPATH '/tmp/log.csv' INTO TABLE log;If you do wish to use a fusion URI as a load path, you must change the
fs.defaultFS setting to use WD Fusion, as noted in a previous section. Then you may run:
LOAD DATA INPATH 'fusion:///repl1/log.csv' INTO TABLE log;
Sharing the Hive metastore
Advanced configuration - please contact WANdisco before attempting
In this section we'll describe how to share the Hive metastore between two clusters. Since WANdisco Fusion can replicate the file system that contains the Hive data storage, sharing the metadata presents a single logical view of Hive to users on both clusters.
When sharing the Hive metastore, note that Hive users on all clusters will know about all tables. If a table is not actually replicated, Hive users on other clusters will experience errors if they try to access that table.
There are two options available.
Hive metastore available read-only on other clusters
In this configuration, the Hive metastore is configured normally on one cluster. On other clusters, the metastore process points to a read-only copy of the metastore database. MySQL can be used in master-slave replication mode to provide the metastore.
Hive metastore writable on all clusters
In this configuration, the Hive metastore is writable on all clusters.
- Configure the Hive metastore to support high availability.
- Place the standby Hive metastore in the second data center.
- Configure both Hive services to use the active Hive metastore.
Performance of Hive metastore updates may suffer if the writes are routed over the WAN.
2.5.2 Impala
Prerequisites
- Knowledge of Impala architecture.
- Ability to modify Hadoop site configuration.
- WD Fusion installed and operating.
Query a table stored in a replicated directory
Impala does not allow the use of non-HDFS file system URIs for table storage. To work around this, WANdisco Fusion 2.3 comes with a client program that will support reading data from a table stored in a replicated directory.
2.6.3 Oracle: Big Data Appliance
Each node in an Oracle:BDA deployment has multiple network interfaces, with at least one used for intra-rack communications and one used for external communications. WD Fusion requires external communications so configuration using the public IP address is required instead of using host names.
Prerequisites
- Knowledge of Oracle:BDA architecture and configuration.
- Ability to modify Hadoop site configuration.
Required steps
- Install WD Fusion and make sure it's capable of Operating in a multi-homed environment.
- Configure WD Fusion to support Kerberos. See Setting up Kerberos
- Configure WD Fusion to work with NameNode High Availability described in Oracles documenation
- Restart the cluster, WD Fusion and IHC processes. See
- Test that replication between zones is working.
Operating in a multi-homed environment
Oracle:BDA is built on top of Cloudera's Hadoop and requires some extra steps to support multi-homed network environment.
Procedure
- Complete a standard installation, following the steps provided in the Installation Guide. Retrieve and use the public interface IP addresses for the nodes that will host the WD Fusion and IHC servers.
- Once the installation is completed you need to set up WD Fusion for a multi-homed environment, first edit WD Fusion's properties file (/opt/fusion-server/application.properties). Create a backup of the file, then add the following line at the end:
communication.hostname=0.0.0.0
Resave the file - Next we need to update the IHC servers so that they will also use the public IP addresses rather than hostnames. The specific number and names of the configuration files that you need to update will depend on the details of your installation. If you run both WD Fusion server and IHCs on the same server you can get a view of the files with the following command:
tree /etc/wandisco
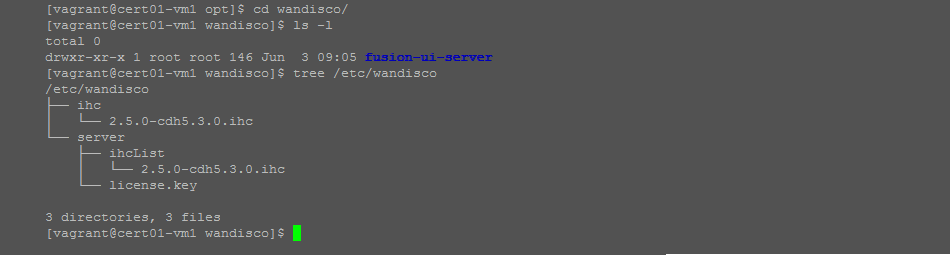
View of the WD Fusion configuration files.
- Edit each of the revealed config files. In the above example there are two instances of
2.5.0-cdh5.3.0.ihcthat will need to be edited:#Fusion Server Properties #Wed Jun 03 10:14:41 BST 2015 ihc.server=cert01-vm1.obda.domain.com\:7000 http.server=cert01-vm1.obda.domain.com\:9001
In each case you should change the addresses so that they use the public IP addresses instead of the hostnames. - Open a terminal session on the node hosting the WD Fusion UI. Edit the properties file /opt/wandisco/fusion-ui-server/properties/ui.properties
Add the property to allow the UI to listen on all interfaces, i.e.
ui.hostname=0.0.0.0
This should now ensure that the multi-homed deployment will work with WD Fusion.
Troubleshooting
If you suspect that the multi-homed enviroment is causing difficulty, verify that you can communicate to the IHC server(s) from other data centers. For example, from a machine in another data center, run:
ncIf you see errors from that command, you must fix the network configuration.<IHC server IP address>:<IHC server port>
2.5.4 EMS Isilon
Prerequisites
- Knowledge of EMC Isilon administration.
- Ability to modify Hadoop site configuration.
HDP on Isilon
Follow these steps to install WANdisco Fusion on a Hortonworks (HDP) cluster on Isilon storage.
- Complete a standard installation, following the steps provided in the Installation Guide.
- Copy
/opt/fusion-server/core-site.xmlfrom the WANdisco Fusion server to/opt/fusion/ihc-server/<package-version>/on the IHC server(s). - Restart IHC services.
2.5.5 Apache Tez
Apache Tez is a YARN application framework that supports high performance data processing through DAGs. When set up, Tez uses its own tez.tar.gz containing the dependencies and libraries that it needs to run DAGs. For a DAG to access WD Fusion's fusion:/// URI it needs our client jars:
Configure the tez.lib.uris property with the path to the WD Fusion client jar files.
...
<property>
<name>tez.lib.uris</name>
# Location of the Tez jars and their dependencies.
# Tez applications download required jar files from this location, so it should be public accessible.
<value>${fs.default.name}/apps/tez/,${fs.default.name}/apps/tez/lib/</value>
</property>
...2.6 Appendix
The appendix section contains extra help and procedures that may be required when running through a WD Fusion deployment.
Fusion Client installation
The WD Fusion installer doesn't currently handle the installation of the thin-client to the rest of the cluster. You need to go through the following procedure:
- In the Client Installation section of the installer you will see a link to a parcel file. Use this if you have Cloudera's Hadoop deployed and are using their Parcels packaging system. Otherwise, use the link to the list of nodes here and the link to the client RPM package.
RPM package location
If you need to find the packages after leaving the installer page with the link, you can find there in your installation directory, here:/opt/wandisco/fusion-ui-server/ui/client_packages - If you are installing the RPMs, download and install the package on each of the nodes that appear on the list from step 1.
Cleanup WD Fusion
The following section is used when preparing to install WD Fusion on system that already has an earlier version of WD Fusion installed. Before you install an updated version of WD Fusion you need to ensure that components and configurartion for an earlier installation have been removed. Go through the following steps before installing a new version of WD Fusion:
Cleanup WD Fusion / IHC Server processes
Ensure that there are no WD Fusion / IHC server processes running. The WD Fusion orchestration script has a cleanup option for this. Run:
sudo ./orchestrate-fusion.sh ./mydefines.sh cleanupjps -lCheck that none of your WD Fusion machines are not running.
'com.wandisco.fs.ihc.server.Main' or 'com.wandisco.fs.server.Main'
If required "kill -9 the processes. Then clean up the DConE databased with the following command:
rm -rf /opt/fusion-server/dcone/db/*/*
Cleanup WD Fusion packages
If you have a previous install of WD Fusion on your clusters, run 'removerpms' first to remove the RPMs.
In case RPM file names have been changed, you should use the orchestration script that corresponds with your old version, rather than the latest version.
sudo ./orchestrate-fusion.sh ./mydefines.sh removerpms
Continue with your new installation
You can now continue with the installation of the latest version of WD Fusion. Remember to make any necessary changes to the mydefines.sh file to include the new packages.
Non-interactive Installation
WD Fusion UI supports a non-interactive installation method favoured by administrators who need to script/automate their work.
- Place the installer script on your server.
- Set up the necessary variables that are required by the installer:
- FUSIONUI_USER
- The system user account that will run the WD Fusion UI.
- FUSIONUI_GROUP
- The system group that will be associated with WD Fusion UI.
- FUSIONUI_UMASK
- THe umask setting for the server. See File descriptor limit
- FUSIONUI_MEM_LOW
- The Java heap minimum memory allocation for the UI's JVM.
- FUSIONUI_MEM_HIGH The Java heap Maximum allocated memory.
- FUSIONUI_INIT
- FUSIONUI_UI_HOSTNAME
- The hostname or IP of the server hosting the WD Fusion UI.
- FUSIONUI_UI_PORT
- The TCP port used for handling access to the UI.
- FUSIONUI_TARGET_HOSTNAME
- The hostname or IP of the machine hosting the WD Fusion server.
- FUSIONUI_TARGET_DELEGATE_PORT
- The TPC port that WD Fusion server uses to deligate write operations, for replication.
- FUSIONUI_TARGET_PORT
- The TCP port used by WD Fusion server.
- FUSIONUI_MANAGER_TYPE
- The Hadoop management application, e.g. "CLOUDERA" or "AMBARI".
- FUSIONUI_MANAGER_HOSTNAME
- Hostname or IP address of the Hadoop manager.
- FUSIONUI_MANAGER_PORT
- The Hadoop manager's TCP port.
- FUSIONUI_HDFS_HOSTNAME
- The hostname or IP address of the NameNode.
- FUSIONUI_HDFS_PORT
- The TCP port used for communicating with the NameNode. E.g. 50070.
- Start an installation using your own variant of the following command:
sudo FUSIONUI_MANAGER_TYPE=AMBARIFUSIONUI_MANAGER_HOSTNAME=managerhostFUSIONUI_MANAGER_PORT=9876FUSIONUI_HDFS_HOSTNAME=hdfshostFUSIONUI_USER=hdfsFUSIONUI_GROUP=hadoop ./fusion-ui-server_rpm_installer.sh
orchestrate-fusion.sh script commands
Below are the available commands for running
Install all RPMs
sudo ./orchestrate-fusion.sh ./mydefines.sh installrpms
Configure replication directory
sudo ./orchestrate-fusion.sh ./mydefines.sh configure /repl1
Completely uninstall Fusion
Before installing new Fusion build with
orch.tar.gz.2.XX-YYY user needs to uninstall old build from existing /orch dir
sudo ./orchestrate-fusion.sh ./mydefines.sh removerpms
Stop all Fusion services
sudo ./orchestrate-fusion.sh ./mydefines.sh stopservices
Start all Fusion services
sudo ./orchestrate-fusion.sh ./mydefines.sh startservices
Remove configs and Dcone DBs
sudo ./orchestrate-fusion.sh ./mydefines.sh cleanup
Removing WD Fusion UI
If you need to remove WD Fusion UI from a system, follow these steps:
- Open a terminal session and run the following package removal command.
sudo yum erase fusion-ui-server
- Remove the install files with:
sudo rm -rf /opt/wandisco/fusion-ui-server
WD Fusion will now be completely removed from the server.