The Hive Metastore plugin enables WD Fusion to replicate Hive's metastore, allowing WD Fusion to maintain a replicated instance of Hive's metadata and, in future, support Hive deployments that are distributed between data centers. This guide is specifically aimed at deployments into IBM's BigReplicate platform.
Check out the Hive Metastore Plugin Release Notes for the latest information. See 1.0 WD Hive Metastore Plugin Release Notes
Along with the default requirements that you can find on the WD Fusion Deployment Checklist, you also need to ensure that the Hive service is already running on your server. Installation will fail if the WD Fusion Plugin can't detect that Hive is already running.
All zones within a membership must be running Hive in order to support replication. We're aware that this currently prevents the popular use case for replicating between on-premises clusters and s3/cloud storage, where Hive is not running. We intend to remove the limitation in a future release.
cd /opt/wandisco/wd-hive-metastore
ln -s /usr/ibmpacks/current/bigsql/bigsql/lib/java/bigsql-sync.jar bigsql-sync.jar
/opt/wandisco/wd-hive-metastore
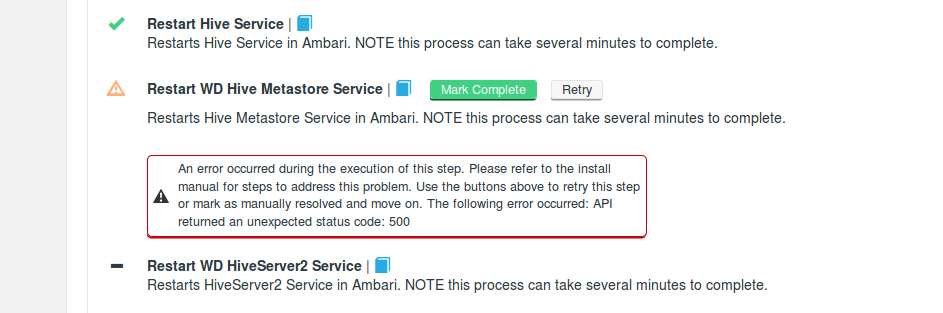
Example failure, during BigInsight installation. The error is caused by the stack not being available via ambari-server.
ps -aux | grep ambari-serverkill -9 [pid of process]service ambari-server restartps -aux | grep ambari-server
Currently, you can't run the standard Hive metastore service on the same host as the wd-hive-metastore service, because HDP uses the hive.metastore.uris parameter to set the port for the standard hive metastore service. This impacts IBM BigReplicate which is based on HDP.
As noted above, HDP uses the hive.metastore.uris parameter to set the Hive Metastore port. Without the WD Hive Template installed, the HiveServer2 service would use an embedded metastore service and not the separate Hive Metastore service. When this is the case we can't support running the standard Hive Metastore and the wd-hive-metastore on the same host, when using a HDP distribution. We recommend that you stop the standard Hive metastore when using WD Hive on HDP, and to be clear, even if the wd-hive-metastore service is deployed onto another host then the standard Hive metastore service port will be changed by our configuration of hive.metastore.uris.
addprinc -randkey hive/<WD-hive-metstore-hostname>@<REALM>
addprinc -randkey HTTP/<WD-hive-metstore-hostname>@<REALM>
xst -norandkey -k hive.keytab hive/<WD-hive-metstore-hostname>@<REALM> HTTP/<WD-hive-metstore-hostname>@<REALM>klist -e -k -t hive.keytabsudo mv hive.keytab /etc/wandisco/hive/sudo chown hive:hive /etc/wandisco/hive/hive.keytabservice fusion-server restart/tmp/hive e.g.hdfs dfs -chown 733 /tmp/hive./fusion-ui-server-ibm-hive_rpm_installer.sh./fusion-ui-server-ibm-hive_rpm_installer.sh /opt/some/other/location[root@dc00-vm1 IBMTEST]# ll
total 703112
-rw-r--r-- 1 vagrant vagrant 718215802 Jun 16 10:28 fusion-cdh-nothive-33.sh
-rw-r--r-- 1 vagrant vagrant 1763050 Jun 16 10:26 fusion-ui-server-ibm-hive_rpm_installer.sh
-rwxr-xr-x 1 vagrant vagrant 1346 Jun 16 10:23 fusion-ui-server-ibm-hive_rpm_installer.sh
drwxr-xr-x 1 vagrant vagrant 154 Jun 16 10:18 lib
[root@dc00-vm1 IBMTEST]# ./fusion-ui-server-ibm-hive_rpm_installer.sh
LICENSE INFORMATION
The Programs listed below are licensed under the following
License Information terms and conditions in addition to the
Program license terms previously agreed to by Client and
IBM. If Client does not have previously agreed to license
terms in effect for the Program, the International Program
License Agreement (Z125-3301-14) applies.
Program Name: IBM Big Replicate 2.0
Program Number: 5737-A55
As described in the International Program License Agreement
("IPLA") and this License Information, IBM grants Licensee
a limited right to use the Program. This right is limited
Press Enter to continue viewing the license agreement, or
enter "1" to accept the agreement, "2" to decline it, "3"
to print it, or "99" to go back to the previous screen.Installing WD Fusion
Verifying archive integrity... All good.
Uncompressing WANdisco Fusion........................
:: :: :: # # ## #### ###### # ##### ##### #####
:::: :::: ::: # # # # ## ## # # # # # # # # #
::::::::::: ::: # # # # # # # # # # # # # #
::::::::::::: ::: # # # # # # # # # # # ##### # # #
::::::::::: ::: # # # # # # # # # # # # # # #
:::: :::: ::: ## ## # ## # # # # # # # # # # #
:: :: :: # # ## # # # ###### # ##### ##### #####
Welcome to the WANdisco Fusion installation
You are about to install WANdisco Fusion version 2.8-33
Do you want to continue with the installation? (Y/n) Checking prerequisites:
Checking for perl: OK
Checking for java: OK
INFO: Using the following Memory settings for the WANdisco Fusion Admin UI process:
INFO: -Xms128m -Xmx512m
Do you want to use these settings for the installation? (Y/n)
Which port should the UI Server listen on? [8083]:
Please specify the appropriate platform from the list below:
[0] ibm-4.0
[1] ibm-4.1
[2] ibm-4.2
Which fusion platform do you wish to use? 1
You chose ibm-4.1:2.7.1
We strongly advise against running Fusion as the root user.
For default CDH setups, the user should be set to 'hdfs'. However, you should choose a user appropriate for running HDFS commands on your system.
Which user should Fusion run as? [hdfs]
Checking 'hdfs' ...
... 'hdfs' found.
Please choose an appropriate group for your system. By default CDH uses the 'hdfs' group.
Which group should Fusion run as? [hdfs]
Checking 'hdfs' ...
... 'hdfs' found.Installing with the following settings:
User and Group: hdfs:hadoop
Hostname: ip-10-11-0-40
Fusion Admin UI Listening on: 0.0.0.0:8083
Fusion Admin UI Minimum Memory: 128
Fusion Admin UI Maximum memory: 512
Platform: ibm-4.1 (2.7.1)
Fusion Server Hostname and Port: ip-10-12-0-40:8082
Do you want to continue with the installation? (Y/n)Adding the user hdfs to the hive group if the hive group is present.
Installing ibm-4.1 packages:
fusion-hcfs-ibm-4.1-server-2.9_RC7.el6-1925.noarch.rpm ... Done
fusion-hcfs-ibm-4.1-ihc-server-2.9_RC7.el6-1925.noarch.rpm ... Done
Installing plugin packages:
Installing fusion-ui-server package:
fusion-ui-server-2.9-74.noarch.rpm ... Done
Starting fusion-ui-server: [ OK ]
Checking if the GUI is listening on port 8083: .....Done
Please visit http://your.hostname.server.com:8083/ to complete installation of WANdisco Fusion
If 'your.hostname.server.com' is internal or not available from your browser, replace
this with an externally available address to access it.
Stopping fusion-ui-server:. [ OK ]
Starting fusion-ui-server: [ OK ]Follow this section to complete the installation by configuring WD Fusion using a browser-based graphical user interface.
Silent Installation
For large deployments it may be worth using Silent Installation option, detailed in the main WANdisco installation guide.
http://<YOUR-SERVER-ADDRESS>.com:8083/It's possible to enable High Availability in your WD Fusion cluster by adding additional WD Fusion/IHC servers to a zone. These additional nodes ensure that in the event of a system outage, there will remain sufficient WD Fusion/IHC servers running to maintain replication.
Add HA nodes to the cluster using the installer and choose to Add to an existing Zone, using a new node name.
Configuration for High Availability
When setting up the configuration for a High Availability cluster, ensure that fs.defaultFS, located in the core-site.xml is not duplicated between zones. This property is used to determine if an operation is being executed locally or remotely, if two separate zones have the same default file system address, then problems will occur. WD Fusion should never see the same URI (Scheme + authority) for two different clusters.
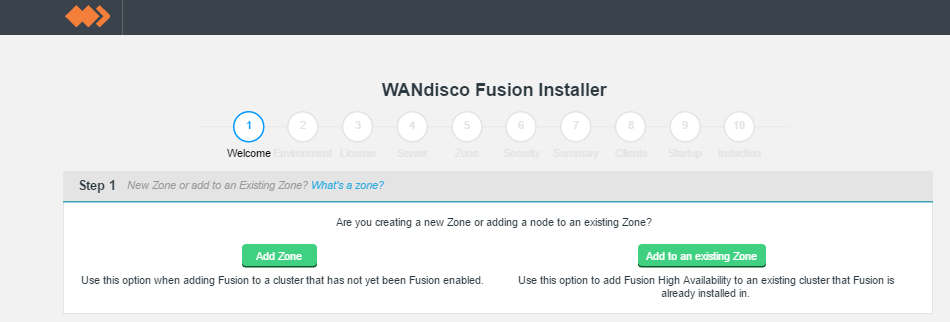
Welcome.
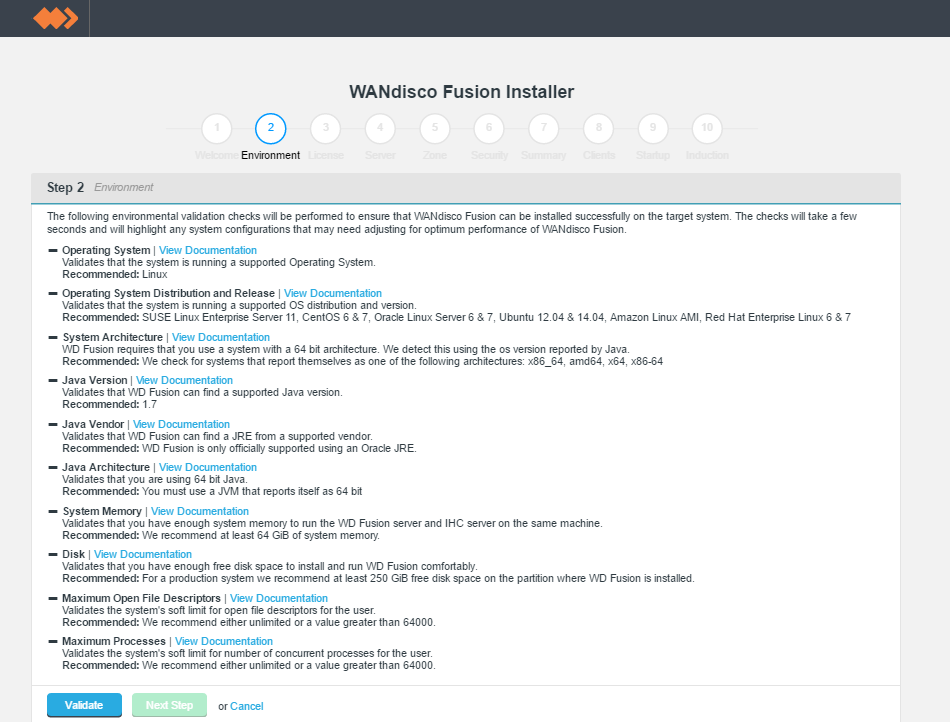
Environmental checks.
On clicking validate the installer will run through a series of checks of your system's hardware and software setup and warn you if any of WD Fusion's prerequisites are missing.

Example check results.
Any element that fails the check should be addressed before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if the installation is only for evaluation purposes and not for production. However, when installing for production, you should also address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
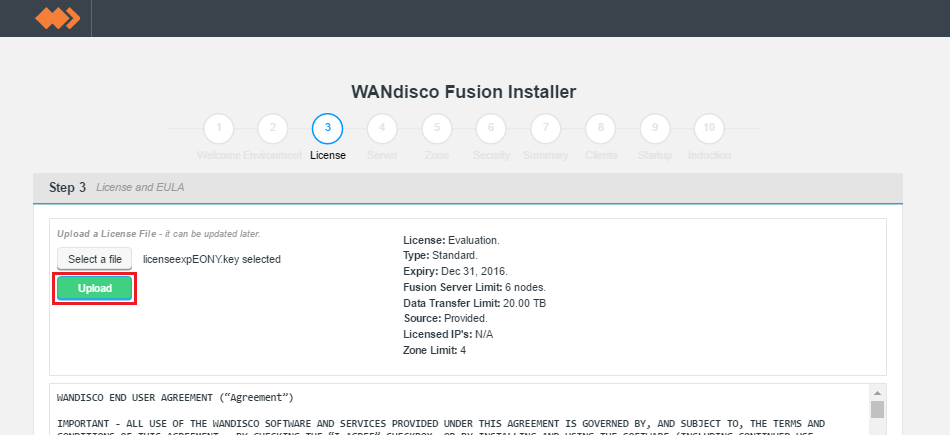
Upload your license file.
Verify license and agree to subscription agreement.
Click on the I agree to the EULA to continue, then click Next Step.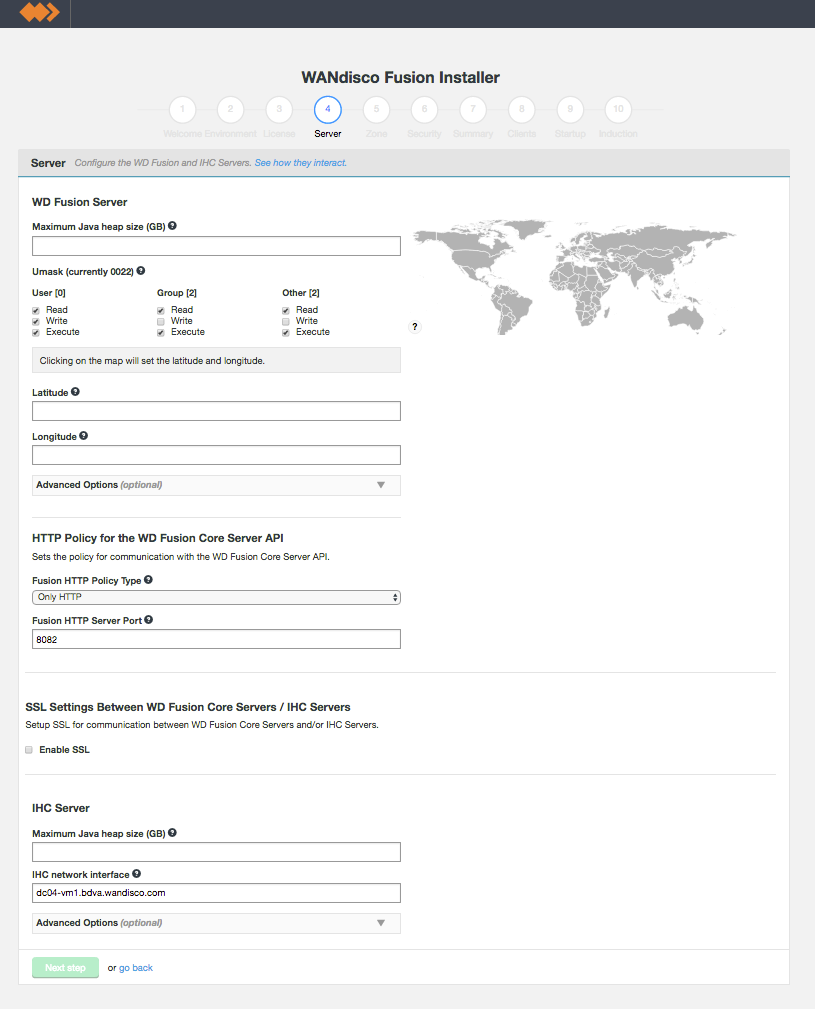
screen 4 - Server settings
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments. The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco's support team before enabling them.
Tick the checkbox to enable SSL

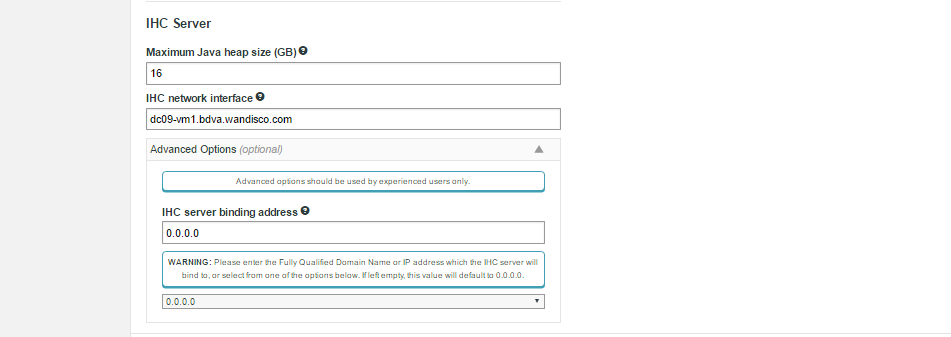
IHC Settings
ihc.server field. In all cases the port should be identical to the port used in the ihc.server address. i.e. /etc/wandisco/fusion/ihc/server/cdh-5.4.0/2.6.0-cdh5.4.0.ihc
or /etc/wandisco/fusion/ihc/server/localfs-2.7.0/2.7.0.ihc
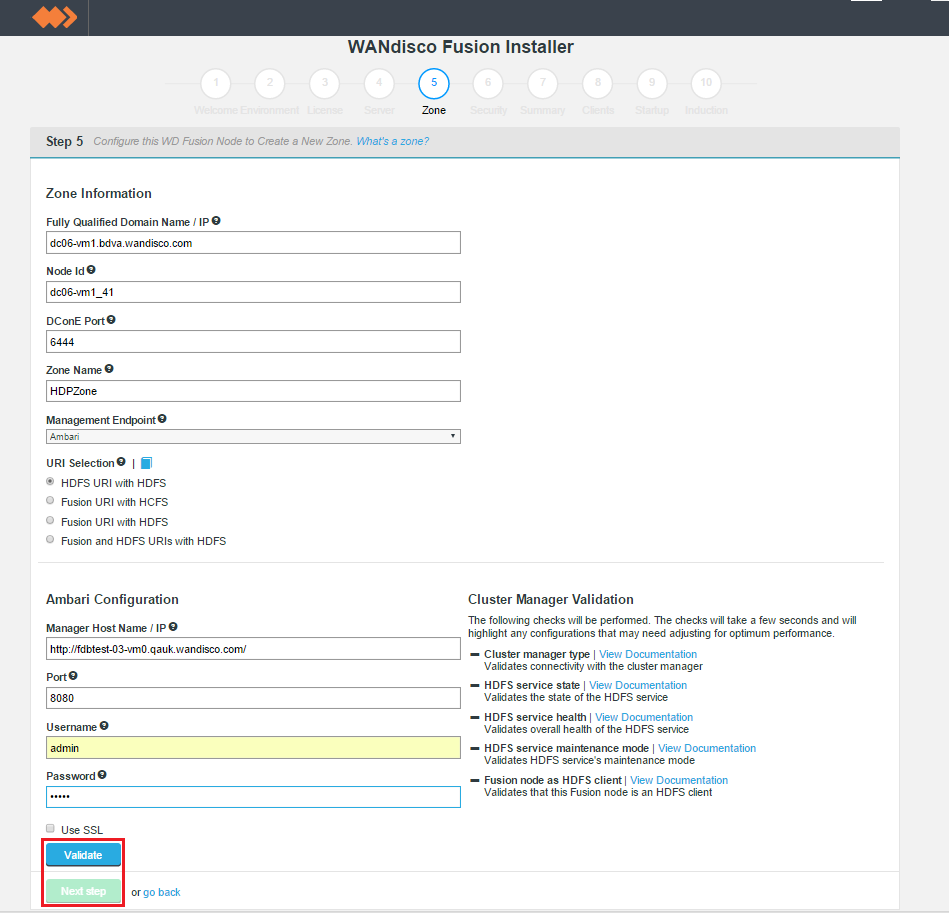
New Zone
Entry fields for zone properties
Induction failure
If induction fails, attempting a fresh installation may be the most straight forward cure, however, it is possible to push through an induction manually, using the REST API. See Handling Induction Failure.
Known issue with Location names
You must use different Location names /Node IDs for each zone. If you use the same name for multiple zones then you will not be able to complete the induction between those nodes.
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments. The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco's support team before enabling them.
The default behavior for WD Fusion is to fix all replication to the Hadoop Distributed File System / hdfs:/// URI. Setting the hdfs-scheme provides the widest support for Hadoop client applications, since some applications can't support the available "fusion:///" URI they can only use the HDFS protocol. Each option is explained below:

fusion:// URI to be used; only paths starting with hdfs:// or no scheme that correspond to a mapped path will be replicated. The underlying file system will be an instance of the HDFS DistributedFileSystem, which will support applications that aren't written to the HCFS specification.
fusion:// for all data that must be replicated over an instance of the Hadoop Compatible File System. If your deployment includes Hadoop applications that are either unable to support the Fusion URI or are not written to the HCFS specfication, this option will not work.
MapR deployments
Use this URI selection if you are installing into a MapR cluster.


fusion://, hdfs:// and no scheme) and uses HDFS for the underlying file system, to support applications that aren't written to the HCFS specification.This option lets you select the TCP port that is used for WD Fusion's API.
Two advanced options are provided to change the way that WD Fusion responds to a system shutdown where WD Fusion was not shutdown cleanly. Currently the default setting is to not enforce a panic event in the logs, if during startup we detect that WD Fusion wasn't shutdown. This is suitable for using the product as part of an evaluation effort. However, when operating in a production environment, you may prefer to enforce the panic event which will stop any attempted restarts to prevent possible corruption to the database.
This section configures WD Fusion to interact with the management layer, which could be Ambari or Cloudera Manager, etc.
https in your Manager Host Name and Port. You may be prompted to update the port if you enable SSL but don't update from the default http port.Authentication without a management layer
WD Fusion normally uses the authentication built into your cluster's management layer, i.e. the Cloudera Manager username and password are required to login to WD Fusion. However, in Cloud-based deployments, such as Amazon's S3, there is no management layer. In this situation, WD Fusion adds a local user to WD Fusion's ui.properties file, either during the silent installation or through the command-line during an installation.
Should you forget these credentials, see Reset internally managed password
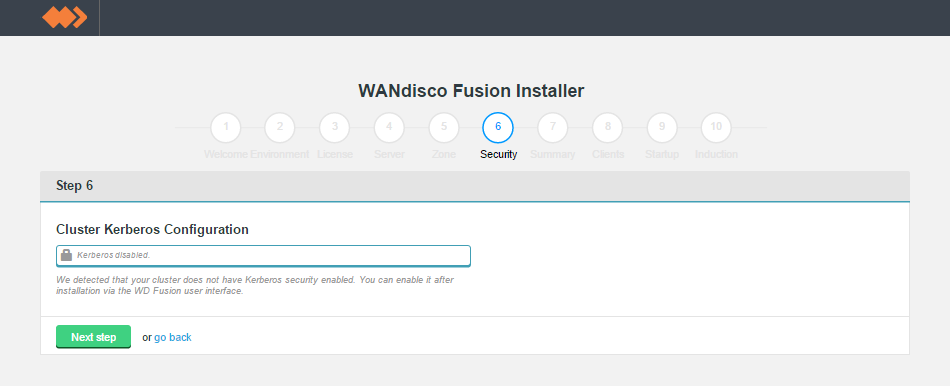
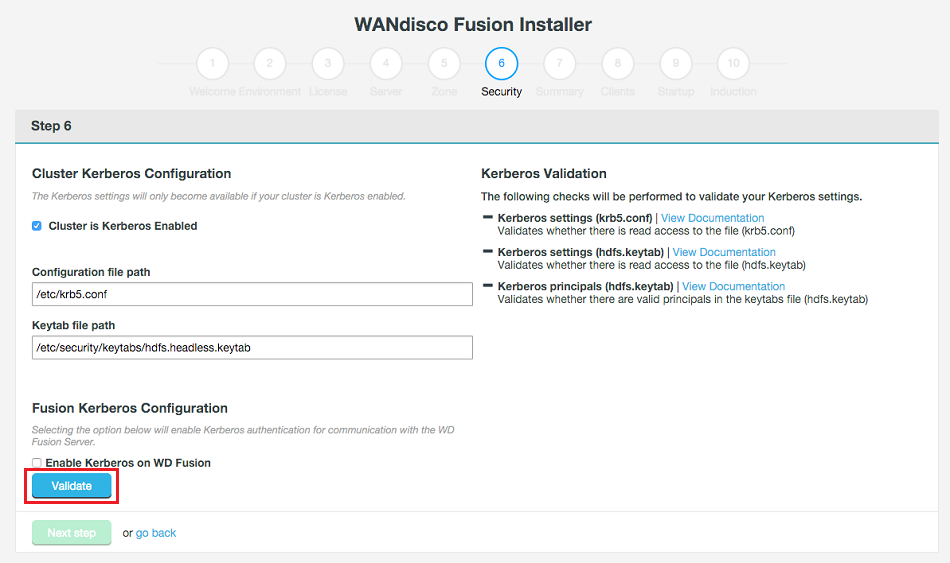
In this step you also set the configuration for an existing Kerberos setup. If you are installing into a Kerberized cluster, include the following configuration.
Enabling Kerberos authentication on WD Fusion's REST API
When a user has enabled Kerberos-authentication on their REST API, they must kinit before making REST calls, and enable GSS-Negotiate authentication. To do this with curl, the user must include the "-negotiate" and "-u:" options, like so:
curl --negotiate -u: -X GET "http://${HOSTNAME}:8082/fusion/fs/transfers"
See Setting up Kerberos for more information about Kerberos setup.
Zone information.
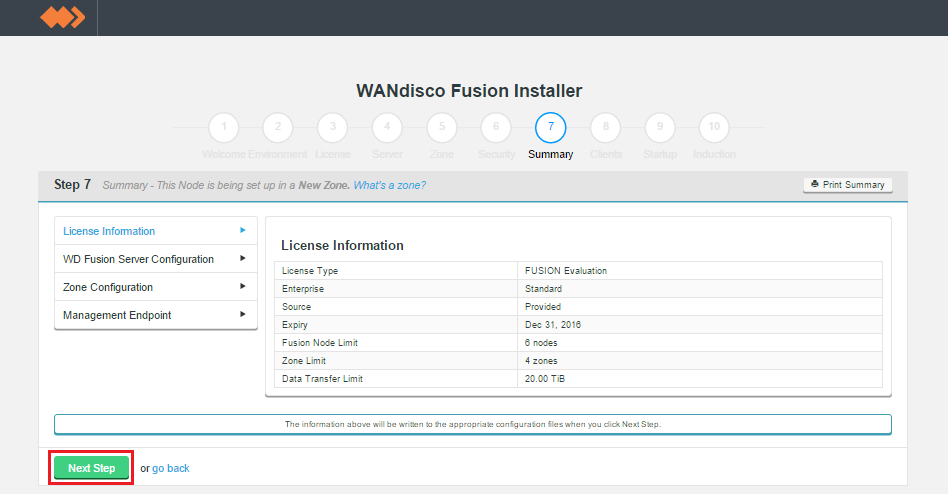
Summary
Once you are happy with the settings and all your WD Fusion clients are installed, click Deploy Fusion Server.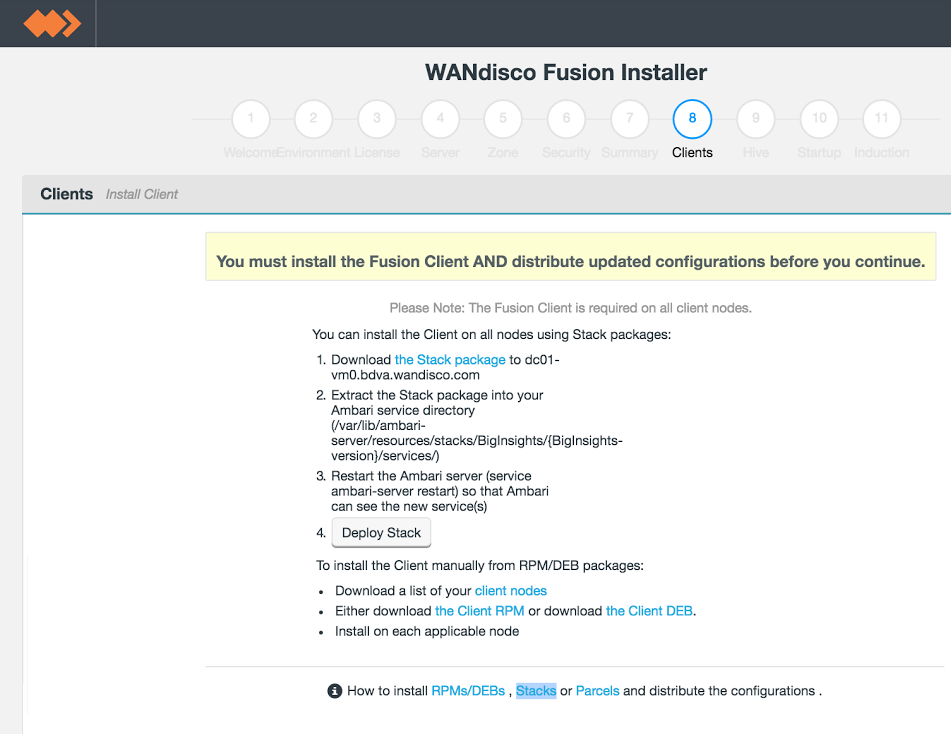
Client installations.
The installer supports three different packaging systems for installing Clients, regular RPMs, Parcels for Cloudera and HDP Stack for Hortonworks/Ambari.
client package location
You can find them in your installation directory, here:
/opt/wandisco/fusion-ui-server/ui/client_packages
/opt/wandisco/fusion-ui-server/ui/stack_packages
/opt/wandisco/fusion-ui-server/ui/parcel_packagesImportant! If you are installing on Ambari 1.7 or CHD 5.3.x
Additionally, due to a bug in Ambari 1.7, and an issue with the classpath in CDH 5.3.x, before you can continue you must log into Ambari/Cloudera Mananger and complete a restart of HDFS, in order to re-apply WD Fusion's client configuration.
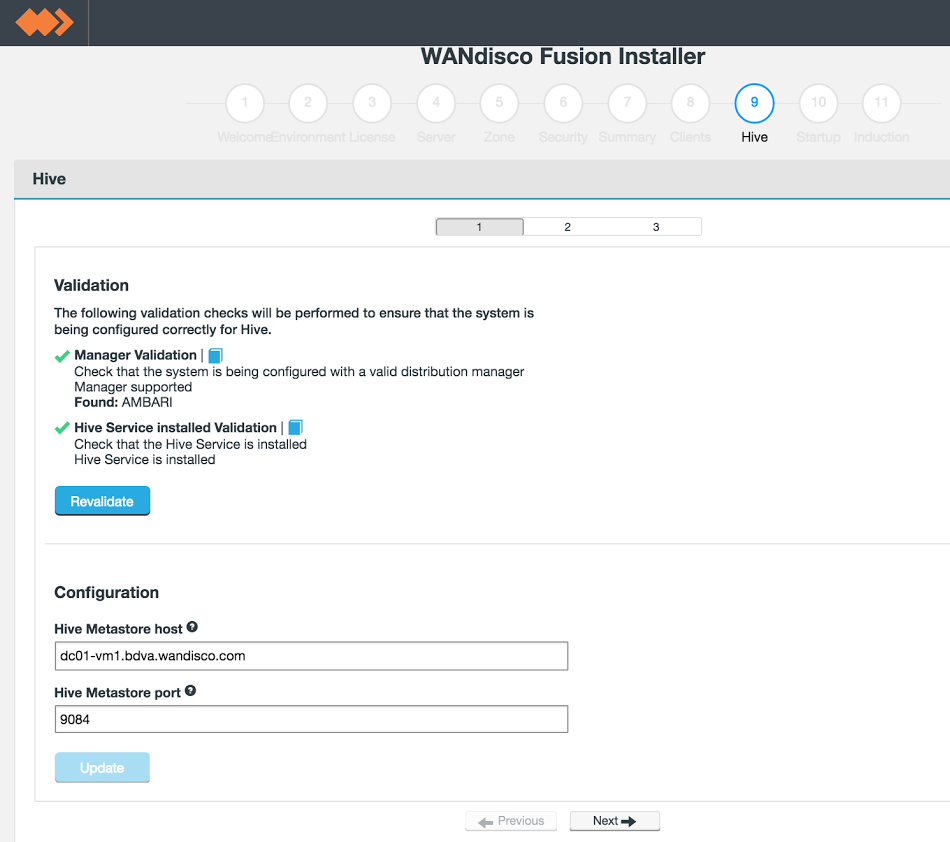
Hive Metastore plugin installation - substep 1.
The installer performs some basic validation, checking the following criteria:
During the installation you need to enter the following properties:
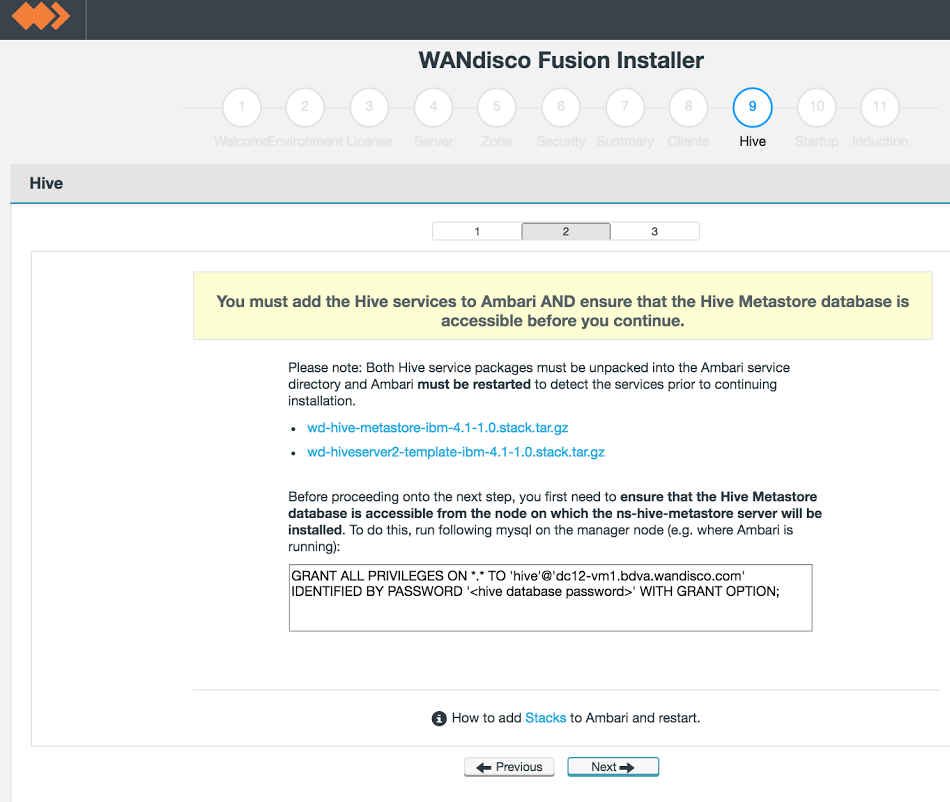
Hive Metastore plugin installation - sub-step 2.
If you check Ambari, providing the new packages are correctly put in place, you will see them listed. Do not enable them through Ambari, they will be installed later.
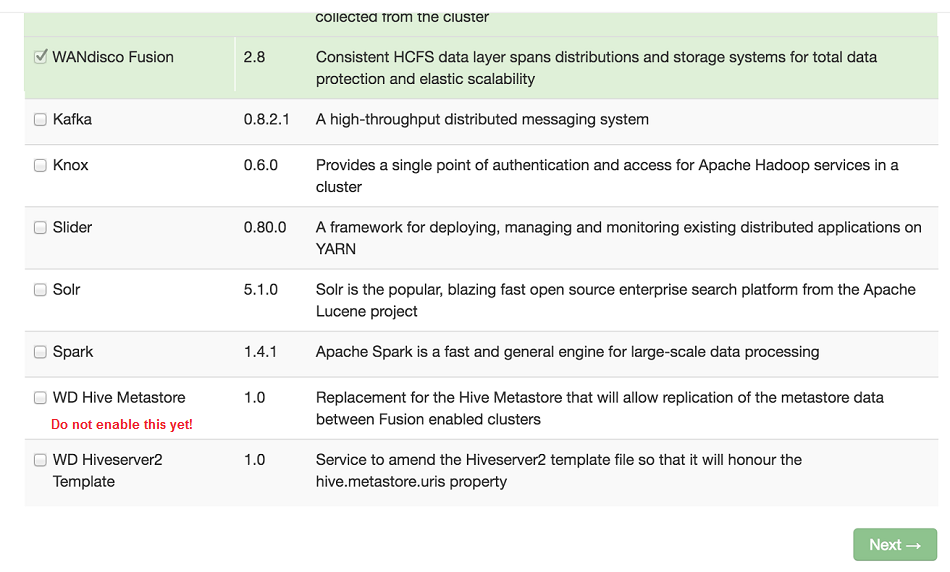
Hive Metastore plugin installation - check the service packages have been picked up.
GRANT ALL PRIVILEGES ON *.* TO 'hive'@'<HOSTNAME-FOR-HIVE-METASTORE-SERVICE-NODE>'
IDENTIFIED BY PASSWORD '<hive database password>' WITH GRANT OPTION;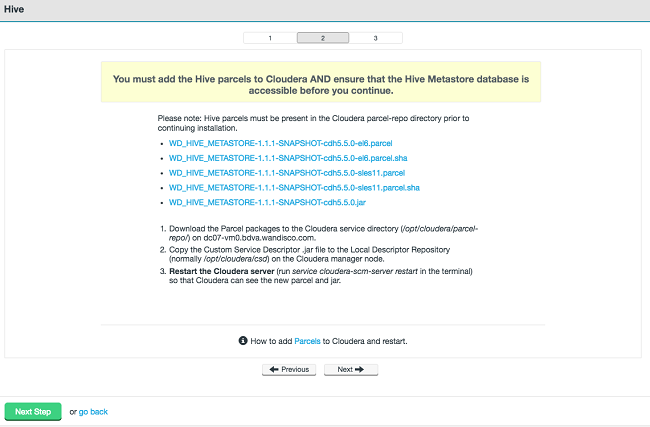
Hive Metastore plugin installation - sub-step 2.
You must add the Hive parcels to Cloudera AND ensure that the Hive Metastore database is accessible before you continue
Please note: Hive parcels must be present in the Cloudera parcel-repo directory prior to continuing installation.
1. Download the Parcel packages to Cloudera service directory (/opt/cloudera.parcel-repo/ on dc07-vm0.bdva.wandisco.com)
2. Copy the Custom Service Descriptor .jar file to the Local Descriptor Repository (normally /opt/cloudera/csd) on the Cloudera manager node.
3. Restart the Cloudera server (run service cloudera-scm-server restart in the terminal) so that Cloudera can see the new parcel and jar.
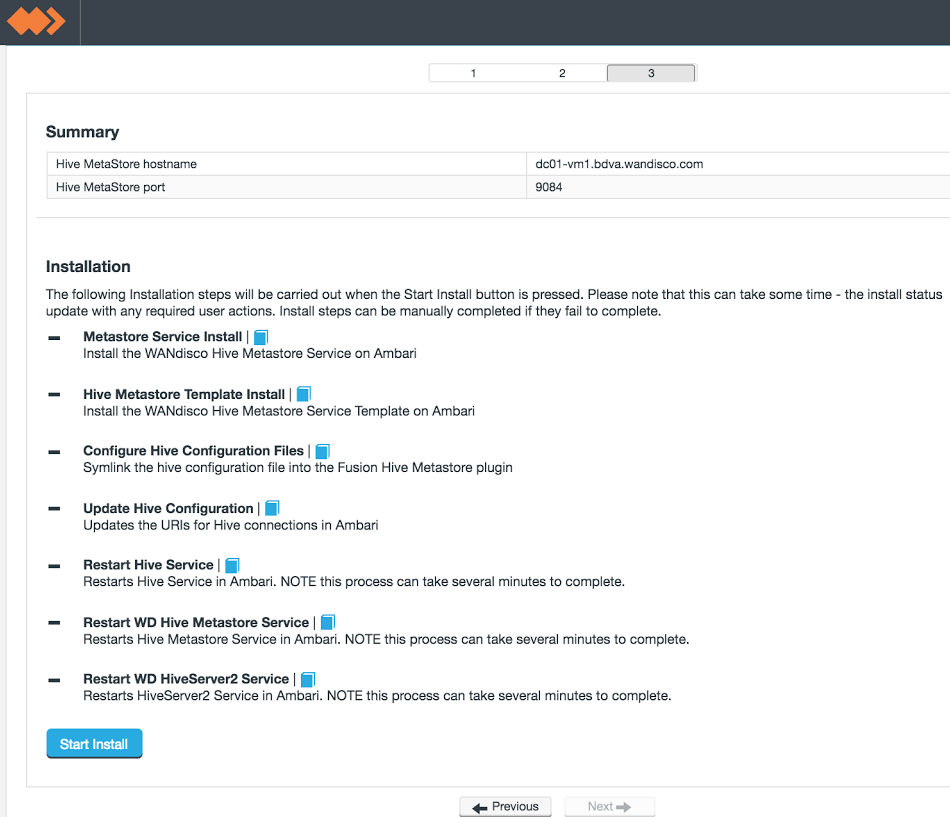
Hive Metastore plugin installation - sub-step 3.
When you have confirmed that the stack files are in place, on the installer screen, click Next.The summary confirms the values of the entries you provided in the first sub-step of the WANdisco Hive Metastore installation section.
To begin the installation of the Plugin, click Start Install.
The following notes explain what is happening during each phase of the installation into a Ambari-based cluster:
The following notes explain what is happening during each phase of the installation into a CDH-based cluster:
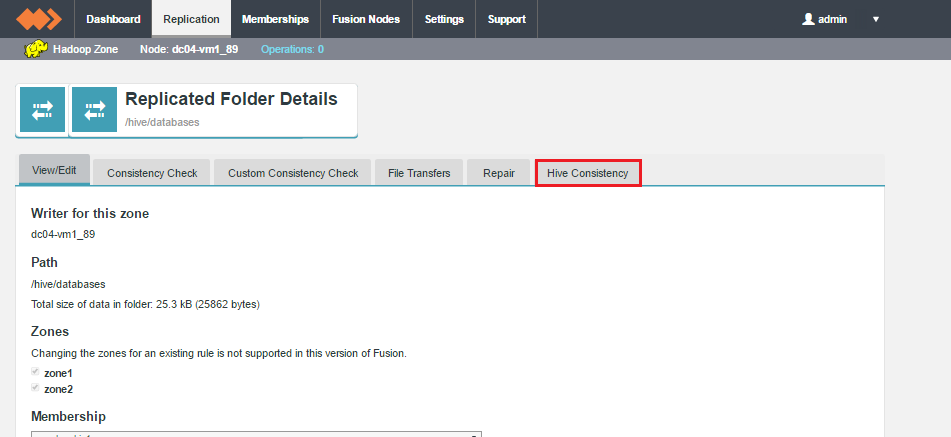
The WD Fusion Consistency Check tool is available for each replicated folder, under the Replication tab. For Hive Metastore data, a dedicated Hive Consistency tab is available.
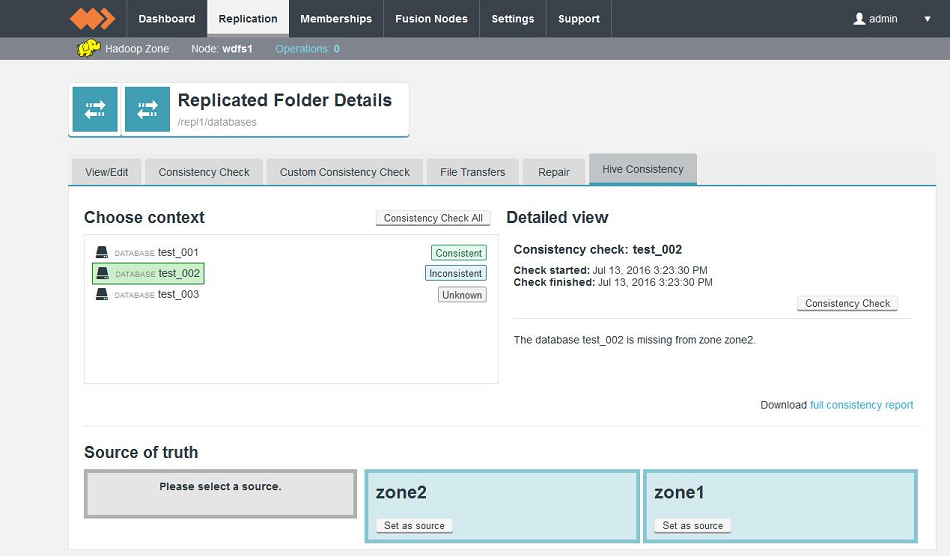
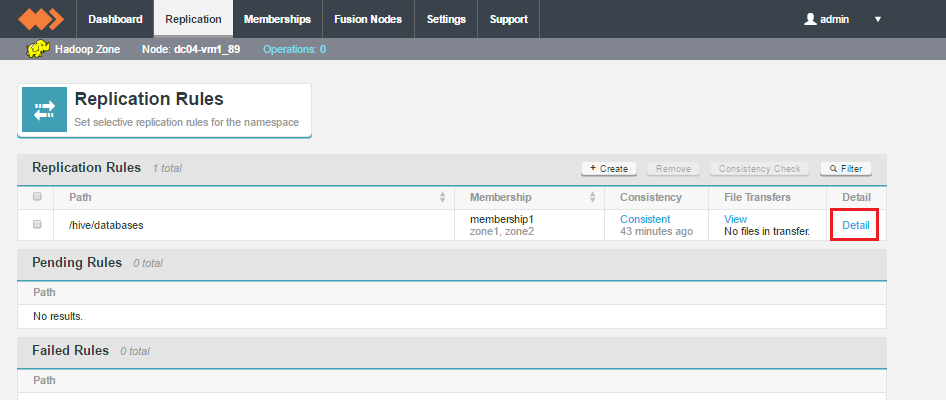
Don't click the Consistency link for Metastore data
When clicking on a replicated folder that stores Hive Metastore data, don't follow the "consistency" link in the Consistency column as this takes you to the general consistency check tool which is not used for checking Hive Metastore data.
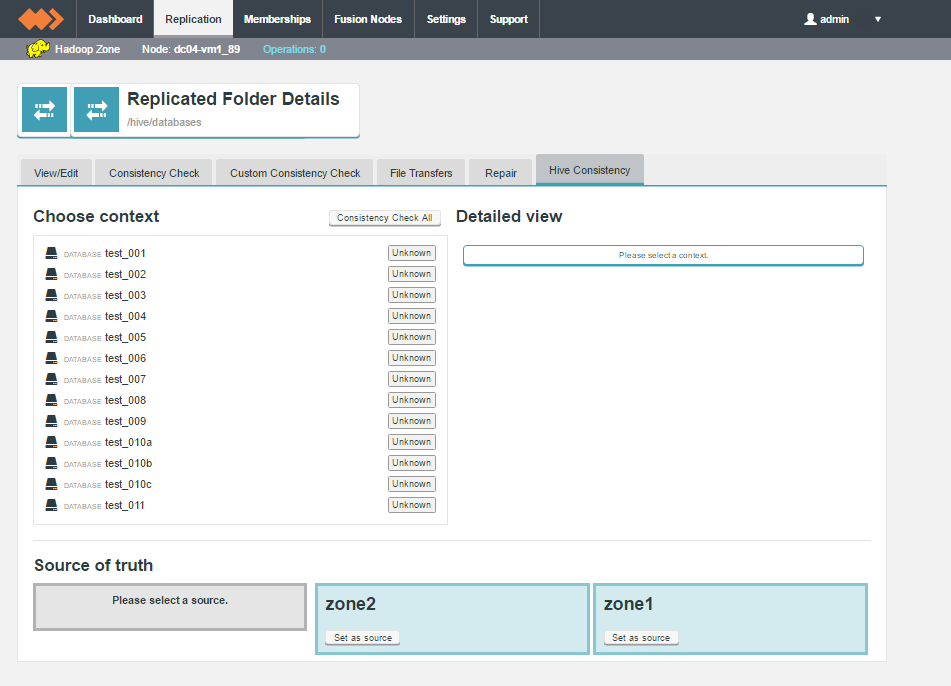
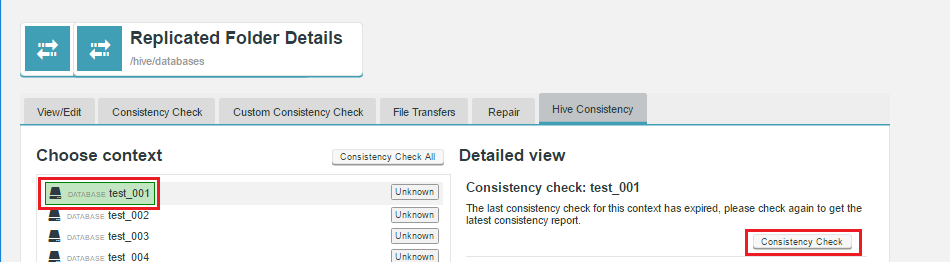
"Unknown" status appears if:
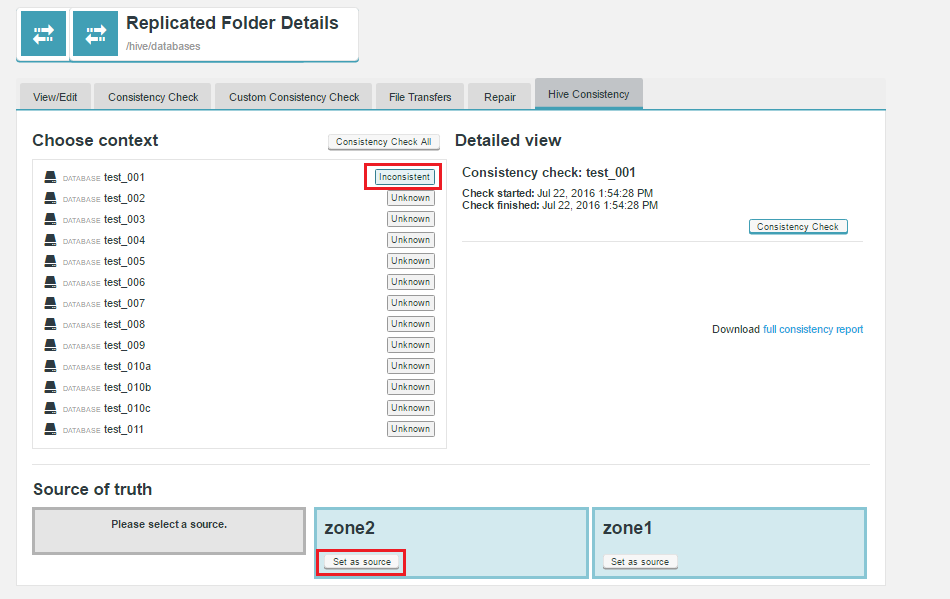
The following example shows the contents of a simple consistency check report
<diffPage>
<pageNum>0</pageNum>
<pageSize>20</pageSize>
<totalSize>2</totalSize>
<dbName>test_011</dbName>
<objectDiffs>
<type>table</type>
<key>test_011_table_001</key>
<diffKind>SomeMissing</diffKind>
<subtree>1</subtree>
<zones>
<z>1</z>
<z>0</z>
</zones>
</objectDiffs>
<objectDiffs>
<type>table</type>
<key>test_011__test_011_table_001_index_dept__</key>
<diffKind>SomeMissing</diffKind>
<subtree>0</subtree>
<zones>
<z>1</z>
<z>0</z>
</zones>
</objectDiffs>
</diffPage>
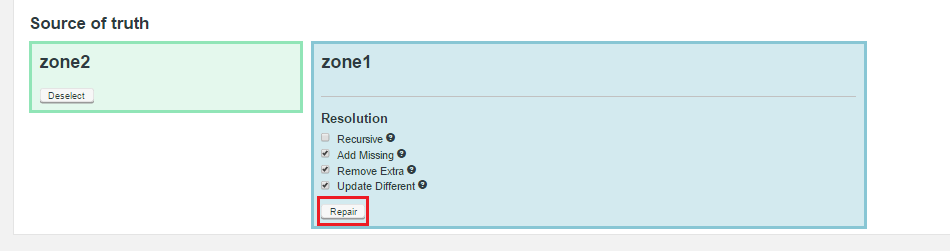
Monitor Repair Status
Known Issue with failed consistency repairs (FUI-3272)
There is a known issue that may appear if Hive contains two indexes that have the same name that then apply to a column of the same name (even though the indexes apply to different tables in different databases). In this scenario, repairs will fail. The cause of the issue is related to the ordering of actions. You can work around the issue using the following procedure.
If you need to repair a database that contains Index tables then you will need to repair them in stages as follows:
The Installer lets you configure WD Fusion to use your platform's Kerberos implementation. You can find supporting information about how WD Fusion handles Kerberos in the Admin Guide, see Setting up Kerberos.
The Installer lets you configure WD Fusion to use your platform's Kerberos implementation. You can find supporting information about how WD Fusion handles Kerberos in the Admin Guide, see Setting up Kerberos.
You need to configure kerberos principals for the wd-hive-metastore and hive fusion plugin to use. All these steps need to be carried out with reference to the host where the wd-hive-metastore and fusion services are running.
For reference
See Cloudera's documentation on Create and Deploy the Kerberos Principals and Keytab Files.
fusion-server.wandisco.com with the actual FQDN name for your wd-hive-metastore host.kadmin.local or kadmin on the host machine running wd-hive-metastore.addprinc -randkey hive/fusion-server.wandisco.com@WANDISCO.HADOOPaddprinc -randkey HTTP/fusion-server.wandisco.com@WANDISCO.HADOOPxst -k hive.service.keytab hive/fusion-server.wandisco.com@WANDISCO.HADOOP
HTTP/fusion-server.wandisco.com@WANDISCO.HADOOPklist -e -k -t hive.service.keytabsudo mv hive.service.keytab /etc/security/keytabs/sudo chown hive:hadoop /etc/wandisco/hive.service.keytab
sudo chmod +r /etc/wandisco/hive.service.keytabhive-site.xml:
<property>
<name>hive.metastore.kerberos.keytab.file</name>
<value>hive.service.keytab</value>
</property><property>
<name>hive.metastore.kerberos.keytab.file</name>
<value>/etc/wandisco/hive/hive.service.keytab</value>
</property>
!connect jdbc:hive2://your.server.url:10000/default;principal=hive/principle.server.com@WANDISCO.HADOOP
It's possible to set up High Availability in a Fusion-Hive deployment. For a basic setup, use the following procedure:
Hive is a Hadoop-specific data warehouse component. It provides facilities to abstract a structured representation of data in Hadoop's file system. This structure is presented as databases containing tables that are split into partitions. Hive can prescribe structure onto existing Hadoop data, or it can be used to create and manage that data.
It uses an architecture that includes a "metastore", which provides the interface for accessing all metadata for Hive tables and partitions. The metastore is the component that persists the structure information of the various tables and partitions in the warehouse, including column and column type information, the serializers and deserializers necessary to read and write data and the location of any corresponding Hadoop files where the data is stored.
Hive offers a range of options for the deployment of a metastore:
As a metastore database:
As a metastore server:
In remote mode, the metastore server is a Thrift service. In embedded mode, the Hive client connects directly to the underlying database using JDBC. Embedded mode supports only a single client session, so is not used normally for multi-user product environments.
WANdisco's implementation of a replicated Hive metastore supports deployments that use a remote metastore server. As tools exist that use interfaces to the metastore other than the thrift interface, the implementation does not just proxy that interface.
The WANdisco Hive Metastore can act as a replacement or complement for the standard Hive Metastore, and provides two components:
The resulting system ensures that Hive metadata can be made consistent across multiple Hadoop clusters, and by performing that coordination in conjunction with actions performed against the Hadoop file system, also ensures that this consistency applies to Hive-resident metadata and any corresponding files where Hive table/partition data is stored.
The following diagram provides a simplified view of how WANdisco's Hive Metastore plugin interfaces between your Hive deployment and WD Fusion.
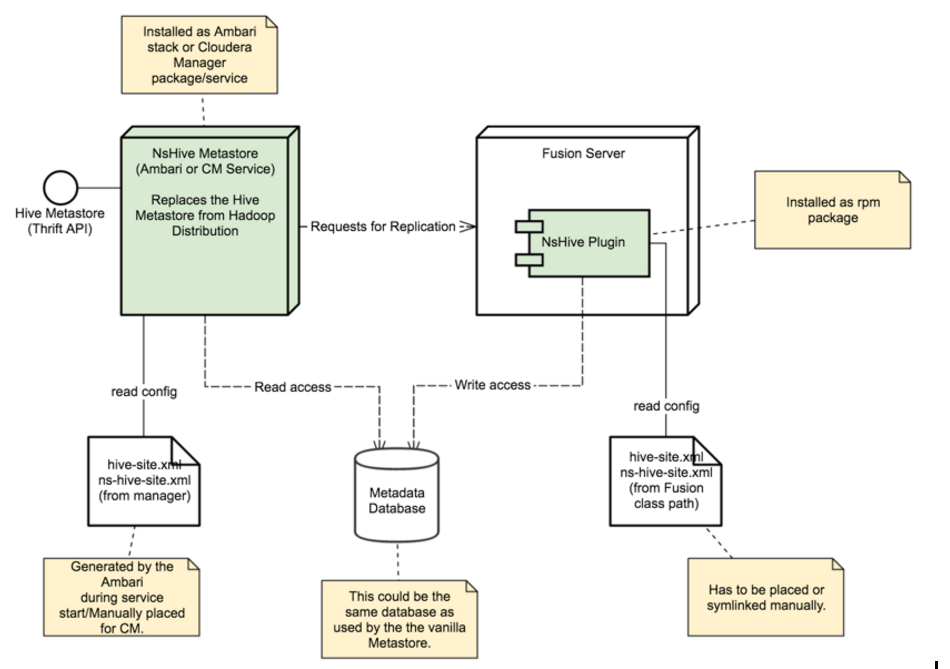
The WANdisco Hive Metastore (NsHive Metastore in the diagram above) can replace the standard Hive Metastore from the Hadoop distribution, or run alongside that Metastore. It provides all the functionality of the standard Hive Metastore, but adds interaction with WANdisco Fusion when coordination and replication is required (i.e. for activities that result in writes against the metadata database used by Hive). Different versions of the Hive Metastore are supported.
The WANdisco Hive Metastore will provide functionality for the replication of Hive metadata and underlying table data as a plugin to Fusion 2.8 or later.
This document describes the plugin's functionality, behaviour and user experience.
The functionality will address the core use case of interacting with Hive as a data warehouse technology in environments where active-active replication of Hive information is required, including underlying table data. Changes made to Hive metadata and data are replicated between multiple participating Hadoop clusters.
All files that hold the data for a given Hive table need to exist under a single root directory that can be replicated using Fusion. This is because there is a need for a single distributed state machine (DSM) to coordinate the activities of metadata changes with underlying table/partition content.
This limitation may be removed if/when Fusion adds the ability to coordinate multiple otherwise independent DSMs.
In order to coordinate all actions across multiple Metastore servers, the current solution replaces each standard Metastore server with a minimally-modified version of it, as provided by WANdisco. If selected portions of Hive metadata require replication, the WANdisco Hive Metastore can operate in addition to the standard Metastore server.
The Hive Metastore differs in implementation across versions. The WANdisco Hive Metastore provides versions to match Hive 0.13, 0.14, 1.1.0 and 1.2.1.
The Metastore version used by all participating replicated instances must match. Future versions of the the Replicated Hive Metastore may allow replication between different versions of Hive.
The following functionality does not exist in the 1.0 release of the WANdisco Hive Metastore:
Changes made to Hive metadata are replicated between multiple participating Hadoop clusters, by coordinating all write operations that will affect the metastore database, and ensuring that these operations are performed in a consistent manner across all WANdisco Hive Metastore instances within a Fusion membership.
The functionality of consistency check and repair provides the means to:
Assumptions made for the operation of this feature include:
Key facilities of this feature are:
Here are some examples for testing basic functionality of the WAN Hive Metastore. They cover connection, creation of a replicated database, population of temporary table data, populating partitions of a table, creating inconsistent data to test consistency check and repair functionality.
You can use the hdfs user to prevent any permission issues:
beeline!connect jdbc:hive2://hiveserver2_host:10000 hdfshdfs dfs -mkdir -p /hive/databasesCREATE DATABASE test_01 LOCATION '/hive/databases/test_01';/usr/local/share/installers/Batting.csv.
USE test_01;create table temp_batting (col_value STRING);
LOAD DATA LOCAL INPATH '/usr/local/share/installers/Batting.csv' OVERWRITE INTO TABLE temp_batting;This should replicate to the data to the second cluster for you. You need to replace the location of the uploaded Batting.csv file.
SELECT * FROM temp_batting LIMIT 100;USE test_01;create table batting (player_id STRING,runs INT) PARTITIONED BY(year INT);insert overwrite table batting PARTITION(year) SELECT regexp_extract(col_value, '^(?:([^,]*),?){1}', 1) player_id, regexp_extract(col_value, '^(?:([^,]*),?){9}', 1) run, regexp_extract(col_value, '^(?:([^,]*),?){2}', 1) year from temp_batting;SELECT * FROM batting WHERE year='2000' LIMIT 100;hdfs dfs -mkdir /testingCREATE DATABASE testing_01 LOCATION '/testing/testing_01';USE testing_01;create table temp_batting (col_value STRING);LOAD DATA LOCAL INPATH '/usr/local/share/installers/Batting.csv' OVERWRITE INTO TABLE temp_batting;
create table batting (player_id STRING,runs INT, year INT);
insert overwrite table batting SELECT regexp_extract(col_value, '^(?:([^,]*),?){1}', 1) player_id, regexp_extract(col_value, '^(?:([^,]*),?){9}', 1) run, regexp_extract(col_value, '^(?:([^,]*),?){2}', 1) year from temp_batting;