1. Introduction
1.2. What is WD Fusion?
WD Fusion is a software application that allows Hadoop deployments to replicate HDFS data between Hadoop clusters that are running different, even incompatible versions of Hadoop. It is even possible to replicate between different vendor distributions and versions of Hadoop.
1.2.1. Benefits
-
Virtual File System for Hadoop, compatible with all Hadoop applications.
-
Single, virtual Namespace that integrates storage from different types of Hadoop, including CDH, HDP, EMC Isilon, Amazon S3/EMRFS and MapR.
-
Storage can be globally distributed.
-
WAN replication using Wandisco’s patented active-active replication technology, delivering single-copy consistent HDFS data, replicated between far-flung data centers.
1.3. Using this guide
This guide describes how to install and administer WD Fusion as part of a multi data center Hadoop deployment, using either on premises or cloud-based clusters. We break down the guide into the following three sections:
- Deployment Guide
-
Covers the various requirements for running WD Fusion, in terms of hardware, software and environment. Reading and understanding these requirements help you to avoid deployment problems. Additionally, if you need to make changes on your platform, we strongly recommend that you re-check the Deployment Checklist.
Working in the Hadoop ecosystem covers any special requirements or limitations imposed when running WD Fusion along with various Hadoop applications.
The Installation section covers on-premises deployments into data centers. See Cloud Installation for cloud or hybrid installations.
- Administration Guide
-
This section describes all the common actions and procedures that are required as part of managing WD Fusion in a deployment. It covers how to work with the UI’s monitoring and management tools. Use the Administration Guide if you need to know how to do something.
- Reference Guide
-
This section describes the UI, systematically covering all screens and providing an explanation for what everything does. Use the Reference Guide if you need to check what something does on the UI, or gain a better understanding of WD Fusion’s underlying architecture.
1.4. Admonitions
In the guide we highlight types of information using the following call outs:
| The alert symbol highlights important information. |
| The STOP symbol cautions you against doing something. |
| Tips are principles or practices that you’ll benefit from knowing or using. |
| The KB symbol shows where you can find more information, such as in our online Knowledgebase. |
1.5. Get support
See our online Knowledgebase which contains updates and more information.
If you need more help raise a case on our support website.
1.6. Give feedback
If you find an error or if you think some information needs improving, raise a case on our support website or email docs@wandisco.com.
2. Release Notes
Releases:
December 2017 - Release 2.10.5.2 Hotfix
November 2017 - Release 2.10.5.1
November 2017 - Release 2.10.5
November 2017 - Release 2.10.3.4 Hotfix
October 2017 - Release 2.10.4
September 2017 - Release 2.10.3.2
August 2017 - Release 2.10.3.1
May 2017 - Release 2.10.2
April 2017 - Release 2.10
2.1. Release 2.10.5.2 Hotfix Build 807
22 December 2017
WANdisco Fusion 2.10.5.2 is a hotfix release for customers using 2.10.5.x versions of the product. It addresses a small number of minor issues.
WANdisco advises that all customers using the product should apply this hotfix to their environment.
2.1.1. Installation
Application of the hotfix is performed by the update of the IHC server RPM, the Fusion server RPM and the client stack or package. e.g. the following packages should be updated for HDP 2.6.0:
fusion-hcfs-hdp-2.6.0-ihc-server-2.10.5.2.el6-xxxx.noarch.rpm fusion-hcfs-hdp-2.6.0-server-2.10.5.2.el6-xxxx.noarch.rpm fusion-hcfs-hdp-2.6.0-2.10.5.2.stack.tar.gz
Please contact WANdisco support for assistance with this process.
2.1.2. Issues Resolved
This hotfix addresses the following issues.
FUS-4785 - Unsuccessful EMR-HDFS replication following target restart
The restart of a writer Fusion node on an AWS EMR zone during file transfer could result in that transfer failing.
FUS-4803 - Document need for exclusion for HDI to HDI replication
Replication between HD Insight clusters requires an exclusion patter for replication rules to account for lack of append support in default HDI configuration.
FUS-4807 - S3 content replication correction
Under some circumstances, file content replication to an S3 zone could result in target object sizes that were larger than those in the source zone.
FUS-4808 - Document link correction
Product documentation links to sample application.properties files are corrected.
FUS-4832/FUS-4314 - Support AWS SSE-S3
The fs.fusion.s3.sse.enabled property has been introduced to allow support of AWS SSE-S3.
Once SSE is enabled on the bucket, this configuration property can be set to true to enable SSE-S3.
FUS-4841 - Document SSL for Fusion on AWS
Documentation for the use of SSL in an AWS deployment has been updated.
http://docs.wandisco.com/bigdata/wdfusion/2.10/#SSL-with-AWS
FUS-4852 - Improved repair_task_cleaner.sh script
Correction to an auxiliary script that cleans stale repair tasks.
2.1.3. Available Packages
Packages are available for all 2.10.5.x supported platforms. Please contact WANdisco support for access to the hotfix packages.
WANdisco Fusion 2.10.5.2 is a hotfix release for customers using 2.10.5.x versions of the product. It addresses a small number of minor issues.
WANdisco advises that all customers using the product should apply this hotfix to their environment.
2.1.4. Installation
Application of the hotfix is performed by the update of the IHC server RPM, the Fusion server RPM and the client stack or package. e.g. the following packages should be updated for HDP 2.6.0:
fusion-hcfs-hdp-2.6.0-ihc-server-2.10.5.2.el6-xxxx.noarch.rpm fusion-hcfs-hdp-2.6.0-server-2.10.5.2.el6-xxxx.noarch.rpm fusion-hcfs-hdp-2.6.0-2.10.5.2.stack.tar.gz
Please contact WANdisco support for assistance with this process.
2.1.5. Issues Resolved
This hotfix addresses the following issues.
FUS-4785 - Unsuccessful EMR-HDFS replication following target restart
The restart of a writer Fusion node on an AWS EMR zone during file transfer could result in that transfer failing.
FUS-4803 - Document need for exclusion for HDI to HDI replication
Replication between HD Insight clusters requires an exclusion patter for replication rules to account for lack of append support in default HDI configuration.
FUS-4807 - S3 content replication correction
Under some circumstances, file content replication to an S3 zone could result in target object sizes that were larger than those in the source zone.
FUS-4808 - Document link correction
Product documentation links to sample application.properties files are corrected.
FUS-4832/FUS-4314 - Support AWS SSE-S3
The fs.fusion.s3.sse.enabled property has been introduced to allow support of AWS SSE-S3.
Once SSE is enabled on the bucket, this configuration property can be set to true to enable SSE-S3.
FUS-4841 - Document SSL for Fusion on AWS
Documentation for the use of SSL in an AWS deployment has been updated.
http://docs.wandisco.com/bigdata/wdfusion/2.10/#SSL-with-AWS
FUS-4852 - Improved repair_task_cleaner.sh script
Correction to an auxiliary script that cleans stale repair tasks.
2.2. Release 2.10.5.1 Build 805
23 November 2017
WANdisco Fusion 2.10.5.1 is a minor release that fixes a handful of issues that could impact 2.10.5 deployments:
2.2.1. General Improvements
FUS-4620 - OutOfMemoryError: Java heap space fix
Fixed an issue that could result in OutofMemoryError as a result of FUS-4643-2.
FUS-4714 - On renameDirToReplicated, non-writer will never know the source zone is complete
Fixed an issue where the none-writer zone was unable to detect that a repair was completed on the source zone, allowing task records to accumulate in non-writers.
FUS-4700 - EMR sending 0-length request due to eventual consistency
We’ve clarified in the documentation that when replicating EMR to LocalFileSystem, you must enable "consistent view" to avoid replication errors that result in 0-length files.
2.3. Release 2.10.5 Build 801
14 November 2017
WANdisco Fusion 2.10.5 is a minor release that offers bug fixes and other improvements as detailed below.
2.3.1. Installation
Find detailed installation instructions in the user guide at http://docs.wandisco.com/bigdata/wdfusion/install.html#procedure.
2.3.2. Upgrades from Earlier Versions
As a minor release, Fusion 2.10.5 supports a simplified upgrade process for existing users of Fusion 2.10.3 and later. Please consult WANdisco support for details of the upgrade process.
2.3.3. General Improvements
FUS-4473 - Repair from S3 to HDFS modifies permissions for files
WD Fusion no longer applies default permissions on repaired files when the source zone does not have permissions for content. This could previously affect the outcome of a repair from an S3 zone to an HDFS zone.
FUS-4628 - Repair task accumulation
Repair tasks that were initiated before, and that completed after the failure of an HDFS NameNode were previously not marked as Done, resulting in the accumulation of tasks in the Fusion server.
FUS-4643, FUS-4683 - Restart of non-writer can cause re-execution of agreements
Under specific conditions, a non-writer Fusion node that becomes a writer can execute agreements that have already been processed by the previous writer node. For this to occur, a non-writer node that has been re-started must have switched to the writer role after observing continued agreement execution by a writer which has not failed. This can happen as a result of intermittent network failure or very large garbage collection pauses at that writer node.
Because the outcome of agreement re-execution is dependent on intervening activity in the underlying storage, the impact of this issue is indeterminate, however it can result in data loss.
FUS-4602 - Repair Resource returns 500 for valid Task ID
Under some scenarios, querying the /fs/repair/task endpoint results in an
HTTP 500 response code instead of the expected task information.
FUS-4550 - Fusion client failure when name service URI contains whitespace
Cilent applications that reference the file system with a URI that contains both an authority and a path that has a whitespace character could fail to initialize their file system reference correctly. This could result in job failure or failure to access specific file system content.
FUS-4489 - null Fusion authority incorrectly applied
When configured with the fusion:// URI scheme, clients that do not provide an
authority in the URI may fail to obtain a file system reference correctly.
FUS-4493 - Compatibility with 2.10.3.1
The WD Fusion 2.10.4 release introduced a serialization change the prevented wire-level compatibility with environments operating WD Fusion 2.10.3.x versions.
FUS-4002 - Fusion to IHC connections should use SO_REUSEADDR
WD Fusion IHC servers were not defaulting socket configuration to accommodate high rates of connection re-establishment. This can be worked around by configuration of kernel properties to modify those defaults, and the 2.10.5 release does not require that configuration change to be made in the operating system.
FUS-4471 Removing last replicated directory causes NPE
A WD Fusion environment that has only a single replication rule may not succeed in removing that rule on request.
FUS-4394 - MapR Fusion client RPM does not correctly modify hadoop-env.sh
Installation of the MapR client library can result in an incorrect attempt to
modify the cluster hadoop-env.sh script.
FUS-4490 - Cloudera Navigator Metadata Server logs classpath error
Actions taken on Cloudera parcel installation may not correctly set the libraries referenced by Cloudera Navigator.
FUS-4556 - Update Azure to Azure file size limit
Azure to Azure replication in WD Fusion 2.10.3.1 would not accommodate files larger than 4MB due to a lack of support for appends. See Known Issue.
FUI-5267 - Additional .hive-staging default exclusion rule
Default exclusion rules did not include .hive-staging correctly.
FUI-4579 - Support object store endpoints that require SSL certificates
Installation of WD Fusion for S3 can fail if the endpoint requires SSL certificates.
FUI-4909 - Add explicit HTTPS support to Swift installer
Swift installer requires explicit configuration for HTTPS endpoints and improved validation.
FUI-5219 - EMR UI installer validation fails
A specific set of actions in the installer could result in failure of validation for EMR environments only.
FUI-5253 - Incomplete repair listing
A failure of the repair API to provide all repair tasks from the non-initiating node when a mix of historical and ongoing repairs are present.
FUI-5256 - Resolution for dependency with CVE-2104-0114
Resolution for a benign, but reported exposure to CVE-2014-0114 by updating the version of commons-beanutils to 1.9.3.
FUI-5269 - Graph % shown only for one node in dashboard
If the ui.hostname property is left at default 0.0.0.0 setting, it can
affect the ability for the dashboard to display graph information for the node.
FUI-4649 - Improved link generation for UI hosts in HA zones
If the WD Fusion UI is configured to run on a host that is not that of the Fusion server, links generated to that node from other UI instances are incorrect, using the hostname from the Fusion server.
FUI-5229 - Silent installer for Kerberos without Ambari management
Silent installer for Fusion with Hive in a non-managed environment was not catered for.
FUI-5260 - UI RPM upgrade Java detection on unmanaged node
In-place upgrade from 2.10.2 in a mixed HDP/S3 configuration can fail to detect Java on an unmanaged node.
FUI-5261 - UI RPM upgrade user detection on unmanaged node
In-place upgrade from 2.10.2 in a mixed HDP/S3 configuration can fail to detect the user correctly on an unmanaged node.
FUI-4483 - LocalFS installer client step improved
Change in text displayed during client installation for LocalFS variant.
FUI-4548 - Update WD Hive installer documentation links
Correct links to documentation for WD Hive installation.
FUI-5221 - Kerberos settings tab shown for EMR and S3
Kerberos settings tab is not required for EMR or S3 variants.
FUI-5247 - Unable to update custom UI settings
Custom UI settings when a custom port is used may not update correctly.
FUI-5248 - Installer redirects to IP
Using custom setting for UI port and host may result in redirection to the UI server’s IP address rather than hostname.
HIVE-639 - Hive tab will now show records if DB has whitespace in location
The Fusion UI does not show table or database information if a database exists with whitespace in its location path.
2.3.4. Available Packages
This release of WANdisco Fusion supports the following versions of Hadoop:
-
ASF Apache Hadoop 2.5.0 - 2.7.0
-
CDH 5.2.0 - 5.11.0
-
HDP 2.1.0 - 2.6.2
-
MapR 4.0.1 - 5.2.0
-
IOP (BigInsights) 4.0 - 4.2.5
The trial download includes the installation packages for CDH and HDP distributions only.
2.3.5. System Requirements
Before installing, ensure that your systems, software and hardware meet the requirements found in our online user guide at http://docs.wandisco.com/bigdata/wdfusion.
2.3.6. Third-Party Component Interoperability
WANdisco Fusion is interoperable with a wide variety of systems, including Hadoop distributions, object storage platforms, and cloud environments.
-
Amazon S3
-
Amazon EMR 5.0, 5.3, 5.4
-
Ambari 1.6, 1.7, 2.0, 3.1
-
Apache Hadoop 2.5.0 - 2.7.0
-
CDH 5.2 - 5.11
-
EMC Isilon 7.2, 8.0
-
Google Cloud Storage
-
Google Cloud Dataproc
-
HDP 2.1.0 - 2.6.2
-
IBM BI 4.0 - 4.2.5
-
MapR M4.0 - M5.2
-
Microsoft Azure Blob Storage
-
Microsoft Azure HDInsights 3.2 - 3.6
-
MySQL, Oracle (Hive Metastore)
-
Oracle BDA, Oracle BDCS
2.3.7. Client Applications Supported
WANdisco Fusion is architected for maximum compatibility and interoperability with applications that use standard Hadoop File System APIs. All applications that use the standard Hadoop Distributed File System API or any Hadoop-Compatible File System API should be interoperable with WANdisco Fusion, and will be treated as supported applications. Additionally, Fusion supports the replication of content with Amazon S3 and S3-compatible objects stores, locally-mounted file systems, and NetApp NFS devices, but does not require or provide application compatibility libraries for these storage services.
2.3.8. Known Issues
Fusion 2.10.5 includes a small set of known issues with workarounds. In each case, resolution for the known issues is underway.
- FUS-387
-
Renaming the parent directory of a location with current file transfers may result in incomplete transfer
In some circumstances, modification of the metadata for a parent directory within a replicated location can prevent the completion of content transfer that is underway for files underneath that directory. Fusion’s metadata consistency is unaffected, but file content may not be available in full. Consistency check and repair can be used to both detect and resolve any resulting missing content.
- FUS-3022
-
Fusion does not support truncate command
The
public boolean truncate(Path f, long newLength)operation inorg.apache.hadoop.fs.FileSystem(> 2.7.0) is not yet supported. Files will be truncated only in the cluster where the operation is initiated. Consistency check and repair can be used to both detect and resolve any resulting inconsistencies. - FUS-3714
-
Fusion does not support
concat()operationThe
public void concat(Path trg, Path[] psrcs)operation inorg.apache.hadoop.fs.FileSystemis not yet supported, and will result in filesystem inconsistency. Consistency check and repair can be used to both detect and resolve any resulting inconsistencies.
- FUS-4556
-
Replication between Azure HDI and objective-based storage solutions, e.g., Azure HDI ←→ Azure HDI or Azure HDI ←→ Amazon EMR will fail because these platforms can’t support file append operations.
Incore-site.xmlyou must setfs.azure.enable.append.supporttotrueto be able to replicate files larger than 4MB.
2.4. Release 2.10.3.4 Hotfix
10 November 2017
WD Fusion 2.10.3.4 is a hotfix release for customers using 2.10.3.x versions of the product. It addresses a small number of important issues including one that under adverse network conditions can result in data inconsistencies.
WANdisco advises that all customers using the product should apply this hotfix to their environment.
2.4.1. Hotfix installation
Application of the hotfix is performed by the update of the IHC server RPM, the Fusion server RPM and the client stack or package. e.g. the following packages should be updated for HDP 2.6.0:
fusion-hcfs-hdp-2.6.0-ihc-server-2.10.3.4.el6-2491.noarch.rpm fusion-hcfs-hdp-2.6.0-server-2.10.3.4.el6-2491.noarch.rpm fusion-hcfs-hdp-2.6.0-2.10.3.4.stack.tar.gz
Please contact WANdisco support for assistance with this process.
2.4.2. Issues Resolved
This hotfix addresses the following issues.
FUS-4643 - Restart of non-writer can cause re-execution of agreements
Under specific conditions, a non-writer Fusion node that becomes a writer can execute agreements that have already been processed by the previous writer node. For this to occur, a non-writer node that has been re-started must have switched to the writer role after observing continued agreement execution by a writer which has not failed. This can happen as a result of intermittent network failure or very large garbage collection pauses at that writer node.
Because the outcome of agreement re-execution is dependent on intervening activity in the underlying storage, the impact of this issue is indeterminate, however it can result in data loss.
FUS-4602 - Repair Resource returns 500 for valid Task ID
Under some scenarios, querying the /fs/repair/task endpoint results in an
HTTP 500 response code instead of the expected task information.
FUS-4550 - Fusion client failure when name service URI contains whitespace
Cilent applications that reference the file system with a URI that contains both an authority and a path that has a whitespace character would fail to initialize their file system reference correctly. This could result in job failure or failure to access specific file system content.
2.5. Release 2.10.4 Build 630
2 October 2017
WANdisco is pleased to present WD Fusion 2.10.4. This release adds support for a number of new Hadoop distribution versions, and includes new features that are detailed below. This is a minor release, and offers bug fixes and other improvements as detailed below.
2.5.1. Installation
Find detailed installation instructions in the user guide at http://docs.wandisco.com/bigdata/wdfusion/install.html#procedure.
2.5.2. Upgrades from Earlier Versions
As a minor release, Fusion 2.10.4 supports a simplified upgrade process for existing users of Fusion 2.10.3. Please consult WANdisco support for details of the upgrade process.
2.5.3. General Improvements
URISyntaxException when Illegal character in path
Fixes issue when a hive table name contains a whitespace character
Dependency on fusion-server for non-repl operations, even with repl_exchange_dir
Fixes issue triggered by particular combination of system restart order
Incorrect Hive safety value property
Corrects safety valve setting used to configure cluster for use of replicated metastore
Fusion Client handhskae handler NPE
Fixes NPE issue during handshake between replicated metastore and Fusion server
CDH / Hive Install Issues
Fixes minor display issue with installer at Cloudera Impala configuration step
Fusion client NPE in WD Hive MS
Fixes issue with combination of Sentry grants and service restart order
Hive CLI hangs randomly with SocketTimeoutException in WD-Hive Metastore HA
Fixes issue exhibited by read timeout exception from hiveserver2
Can’t see Hive databases on Hive CC tab
Resolves problem with visibility of databases during consistency check
Some installations don’t give the right permission to /var/log/wd-hive-metastore/ and /var/run/wd-hive-metastore/. wd-hive-metastore fails to start
Corrected permissions on runtime directories
CDH Plugin deployment should generate own keytabs
Hive plugin installation in a Kerberos-enabled CDH deployment automates keytab generation if required
Solr symlinks must be careful to only reference activated fusion parcel
fusion_env.sh updated to improve referencing of parcels
Assertion Error after Cancelling Repair Task = Full System Down and won’t restart
Resolves Fusion server panic on repair task cancellation
Talkback not able to customize setting for TALKBACKNAME, FUSION_MARKER variables
Fixes to non-interactive mode for talkback.sh script
REST API: GET response about tasks finished is stable "HTTP Error 500"
NPE in Fusion server resolved for task retrieval API
Fusion client cannot authenticate to hadoop if RPC privacy mode is enabled
Fix for authentication when SaSL-based auth and impersonation of Kerberos users is enabled
Talkback improvement - Store Temporary Files within $TMPDIR
Simple extension to allow talkbacks to be processed without assuming use of /tmp
Swift consistency check doesn’t notice sub-folders
Swift object store listing no longer ignores pseudo-subdirectories
Talkback does not follow log location change
Change in the configured location for log data is accommodated by talkback
CDH Fusion Parcels Updates
Umbrella ticket for a set of individual issues related to management of CDH parcels
RPM upgrade is looking for htrace-core4.jar which should be htrace-core.jar
Simple correction to JAR naming
NetApp: setowner throws NPE can cause fusion to lock up
Resolves issue specific to NetApp deployments
Disable and remove DES, 3DES, and RC4 ciphers
Documentation fix for approach to disabling ciphers deemed insecure in some environments
Client RPM upgrade or uninstall leaves dead symlinks
Fixes to post-install script that is run on upgrade or uninstallation
Allow Environment Variables to be sourced from File
Allows the user to run talkback non-interactively by providing it with a configuration file
Talkback to respect custom fusion.dsmToken.dir
Talkbacks load and respect the value of this parameter
Talkback does not generate replicated_directory_info on Swift
Talkback accommodates a command mechanism dependent on the zone type it is run under
Transferring small files to S3 records Long.MAX_VALUE as transfer speed
Corrected transfer progress listener
Default to exclude tmp files from replication
New defaults for exclusion patterns applied to replication rules
Talkback not able to customize setting for TALKBACKNAME, FUSION_MARKER variables
Also corrects descriptions in operation
Relocatable RPM does not work for stack in hardened envs
Stack packaging changes to account for non-root hardened installations
Provide interoperability with S3 compatible object storages
Confirmed interoperability with a variety of S3 compatible systems
Documentation for needing to create hive principles and keytabs if Ambari does not manage Kerberos but Kerberos itself is enabled
Documentation improvement
Consistency check result cutting off part of the table due to long filenames
Retain content within table boundaries
Missing Kerberos configuration on security step for LocalFS
The possibility to configure Kerberos is restored on the security step during UI installation
Decommission SPARK_CLASSPATH from the installer
Use of SPARK_CLASSPATH is deprecated and should not be used
Document known issue: FUI-4352
Document need for JAVA_HOME to be set for user that runs the Fusion server process
MapR install fails to write core-site.xml with "Not supported: indent-number"
Correction for MapR 5.0
Unmanaged installation has problems with removing core-site properties
Correct installation issue related to core-site modification for unmanaged installs
UI installer is setting defaultFS in safety valve
Remove addition of fs.defaultFS in the core-site safety valve
Missing Step when installing hive-plugin
Correct instruction to restart Cloudera Manager service at specific step in Hive installation
Hive tab will not show records if any DB has a space in location
The Fusion UI will now show tables or databases when there is any Database with a space in the location path.
Fusion UI installer impala client parcel has incorrect download link
Correct Impala client parcel download links
WD-Hive plugin installer fails to detect the completion of hive service restart
Corrected issue when installing Fusion with Hive plugin on HDP 2.6 single node cluster, the installer failed to detect the hive service has completed the restart.
Hive install steps should only ask for Kadmin creds if Ambari is managing Kerberos
The installer should query Ambari as to whether it is managing Kerberos, and only request kadmin credentials if this is the case
Shared KMS toggle should be disabled if KMS is not available
Clusters that do not have KMS enabled should not provide the KMS toggle in the Replicated path addition or edit page.
S3 filetree throws NPE if we try to list a / object
S3 listings no longer fail under some virtual directory configurations
Swift install on a hadoop client node pulls in cluster core-site
Improved referencing existing configuration from core-site.xml
Clicking on Re-check button on CC tab should not navigate away from the page
Fixed minor navigation issue
EMR silent installer often fails with "Failed to start WD Fusion Server…" message
Improved startup during silent installation
UI Settings - having HTTP External blank caused APInotFound error due to Dcone bug
Corrected error relating to update of HTTP port setting with blanks
Kadmin Credentials / Validation workflow enhancement
Disable validation of hive settings if no kadmin credentials are provided
Cluster graph bandwidth limit arrows not showing
Cluster graph bandwidth limit arrows now showing on enterprise license when required
Replicated Folder page does not update (shows pending spinner animation) after stopping local node during automation test scenario
Closed with spinner removal
Next button disabled after going back and navigation block not shading- Hive installer
Correction to when after going back from step 2 → step 1, especially when kadmin validation has not been performed, then the Next button is inactive.
[REPL-53] - "Can’t get Kerberos realm" when install BigReplicate on a ppc Kerberos enabled BI 425 environment
Properly configure the default_realm in krb5.conf
Start a node button sometimes asks for confirmation
Fusion no longer asks for confirmation to start a node
Remove MySQL GRANTs for Ambari deployments
The page instructing users to grant permissions has been removed, no longer required.
Unable to Update License when License is Expired
Corrected permissions issue when applied in non-default location
"Select All" checkbox disabled after a RR is added on the remote node.
Corrected: The "Select All" checkbox is disabled the first time you navigate to the Replicated Rules tab after adding a rule on the remote zone. If you navigate away from the page and back, the checkbox is enabled.
Replication > Rules Section > Select all checkbox true by default when there are no rules
False by default when no rules
Improve where plugins are injected at startup in the index.html.
Inject the plugins in the position marked by fusion-ui-client.
S3 Plugin Fusion - Fetching IP’s and hostnames of machine takes a long time if Fusion is installed on a non cloud machine
New case when S3 plugin checks to see if it is running on EC2 first
CDH and HDP is returning different status for HDFS service health while the HDFS service is stopped during fusion Installation
Consistent representation
Follow up → Introduce "stalled" Transfer state
Better solution for displaying transfers identified as "stalled".
UI needs to support enpoints that require SSL certs
UI no longer fails to validate the object storage if the endpoint requires SSL certs
[REPL-31] - Fusion Server fails to start after Kerberos disabled,If Kerberos enabled with "Enable HTTP Authentication" during BigReplicate installation
Warning message if Kerberos is configured, but the Cluster is not kerberized
2.5.4. New Platform Support
WD Fusion has added support for the following new platforms since Fusion 2.10:
-
ASF Apache Hadoop 2.5.0 - 2.7.0
-
CDH 5.12
-
HDP 2.6.2
Additionally, the Pivotal Hadoop Distribution is no longer a supported platform.
2.5.5. Available Packages
This release of WANdisco Fusion supports the following versions of Hadoop:
-
ASF Apache Hadoop 2.5.0 - 2.7.0
-
CDH 5.2.0 - 5.12.0
-
HDP 2.1.0 - 2.6.2
-
MapR 4.0.1 - 5.2.0
-
IOP (BigInsights) 4.0 - 4.2.5
The trial download includes the installation packages for CDH and HDP distributions only.
2.5.6. System Requirements
Before installing, ensure that your systems, software, and hardware meet the requirements found in our online user guide at http://docs.wandisco.com/bigdata/wdfusion.
Third-Party Component Interoperability
WANdisco Fusion is interoperable with a wide variety of systems, including Hadoop distributions, object storage platforms, and cloud environments.
-
Amazon S3
-
Amazon EMR 5.0, 5.3, 5.4
-
Ambari 1.6, 1.7, 2.0, 3.1
-
Apache Hadoop 2.5.0 - 2.7.0
-
CDH 5.2 - 5.12
-
EMC Isilon 7.2, 8.0
-
Google Cloud Storage
-
Google Cloud Dataproc
-
HDP 2.1.0 - 2.6.0
-
IBM BI 4.0 - 4.2.5
-
MapR M4.0 - M5.2
-
Microsoft Azure Blob Storage
-
Microsoft Azure HDInsights 3.2 - 3.6
-
MySQL, Oracle (Hive Metastore)
-
Oracle BDA, Oracle BDCS
Client Applications Supported
WANdisco Fusion is architected for maximum compatibility and interoperability with applications that use standard Hadoop File System APIs. All applications that use the standard Hadoop Distributed File System API or any Hadoop-Compatible File System API should be interoperable with WANdisco Fusion, and will be treated as supported applications. Additionally, Fusion supports the replication of content with Amazon S3 and S3-compatible objects stores, locally-mounted file systems, and NetApp NFS devices, but does not require or provide application compatibility libraries for these storage services.
2.5.7. Known Issues
Fusion 2.10.4 includes a small set of known issues with workarounds. In each case, resolution of the known issues is underway.
-
Renaming the parent directory of a location with current file transfers may result in incomplete transfer - FUS-387.
In some circumstances, modification of the metadata for a parent directory within a replicated location can prevent the completion of content transfer that is underway for files underneath that directory. Fusion’s metadata consistency is unaffected, but file content may not be available in full. Consistency check and repair can be used to both detect and resolve any resulting missing content.
-
Fusion does not support truncate command - FUS-3022
The public boolean truncate(Path f, long newLength) operation in
org.apache.hadoop.fs.FileSystem (> 2.7.0) is not yet supported. Files
will be truncated only in the cluster where the operation is initiated.
Consistency check and repair can be used to both detect and resolve any
resulting inconsistencies.
-
Fusion does not support
concat()operation - FUS-3714
The public void concat(Path trg, Path[] psrcs) operation in
org.apache.hadoop.fs.FileSystem is not yet supported, and will result
in filesystem inconsistency. Consistency check and repair can be used to
both detect and resolve any resulting inconsistencies.
-
Minor issues relating to the changing of UI settings FUI-5247, FUI-5248
There’s an issue with changing the UI settings in the Fusion UI settings screen if the custom port you plan to use is already specified in UI settings - the entry of your change will be blocked with an error. Workaround: temporarily change the in-use port. Also, setting a custom value for the UI port/host/external host during installation will cause the Fusion UI to redirect to the HTTP host IP instead of the provided hostname.
2.6. Release 2.10.3.2 Hotfix
27 September 2017
WD Fusion 2.10.3.2 includes a fix relating to the WANdisco Hive Metastore function, in HDP 2.6.2:
-
Added a new method for
get_all_functionsalong with a corresponding change to the API for AlterTableEvent.
2.7. Release 2.10.3.1 Build 504
9 August 2017
WANdisco is pleased to present WD Fusion 2.10.3. This release adds support for some new Hadoop distribution versions and includes new features that are detailed below.
2.7.1. Installation
Find detailed installation instructions in the user guide at Installation Procedure.
2.7.2. Upgrades from Earlier Versions
Fusion 2.10.3 supports a different upgrade process for existing users of Fusion 2.10. Please consult WANdisco support for details of the upgrade process.
2.7.3. New Feature Highlights
This release includes the following new features.
Non-interactive Talkback
The talkback script used to capture environment and log information can be run in a non-interactive mode where user input is not required during execution. (FUS-3454, FUS-3649)
Recovery from failed DataNodes
WD Fusion 2.10.3 overrides these modified Hadoop settings
-
for automatic replacement of failed datanodes
dfs.client.block.write.replace-datanode-on-failure.enableto "true", and -
for replacement policy
dfs.client.block.write.replace-datanode-on-failure.policyto "DEFAULT".
2.7.4. Hive-Specific Improvements
Hive Installation
Ambari-based installations of the Hive Replicated Metastore accommodate nodes with multiple network interfaces or multiple hostnames. (HIVE-471)
2.7.5. Metastore Event Listener Events
MetaStoreEventListener events are replicated across Hive metastore instances. (HIVE-410, HIVE-234, HIVE-243, HIVE-222, REPL-2, REPL-7, REPl-22)
Add If Not Exists Partition
Hive commands that include "ADD IF NOT EXISTS PARTITION" will function correctly. (HIVE-439)
Large Database List Performance
Environments with very large numbers of Hive databases can be listed with good performance in the WD Fusion UI. (HIVE-497)
/tmp/hive Scratch Directory Permissions
If Hive is configured to use a scratch directory through hive.start.cleanup.scratchdir, it will now be recreated with the correct permissions. (HIVE-283)
Installer Deployment Detection
Hive installation succeeds when Ambari hostname labels differ from the actual hostnames. (HIVE-429)
Hive Restart on BigInsights
Restarting the hosts on which the Hive Replicated Metastore and Hiveserver2 Template reside now results in the associated services starting. (HIVE-437, HIVE-446, HIVE-442)
RHEL7 Init Scripts
WD Hive stacks and init scripts account for the removal of paths created under /var/run on RHEL7. (HIVE-450, HIVE-464)
Support Large Max Rows
Repair functionality is no longer limited by the maximum integer value. (HIVE-452)
Fix to Add Constraint
Fix provided for a failure to progress during execution of an alter table add constraint operation. (REPL-39, HIVE-455)
Update Hive Configuration for Kerberos
Enabling Kerberos after installation functions correctly. (HIVE-473, REPL-48)
2.7.6. Other Improvements
Improved Operation Under Load
Conditions of significant load no longer risk application level timeouts due to contention over coordinated activities. (FUS-3576, FUS-3799, FUS-3810)
Recovery From Errors During Transfer
Better handling of failed TCP connections during final stages of file content transfer. (FUS-3837)
Configurable Notification Buffer
Internal buffers sizes used for notification event and request events can be configured. (FUS-3849)
SSL Configuration Recommendations
WANdisco advises customers to avoid the use of OpenSSL as it can exhibit a memory leak. (FUS-3867)
Failed Transfer Reporting
Failed transfers no longer remain in incomplete status indefinitely. Stalled transfers are shown. (FUS-3833, FUS-3869)
New Node Installation with Ambari
Installation of new cluster nodes via Ambari now honors dependencies for the Fusion client libraries correctly. (FUS-3887)
Improved S3 Performance
The performance of replication to Amazon S3 endpoints is enhanced, enabled in part by the introduction of a new configuration parameter (fs.fusion.s3.transferThreads). (FUS-3978, FUS-3984)
Robust Replication Rule Removal
Replication rule removal does not trigger a failure of the Fusion server. (FUS-3987)
Memory Usage Improvements
Memory use during consistency check and regular operation is improved. (FUS-4013, DCO-709, FUS-4027, FUS-4050, FUS-3489, FUS-3733, FUS-4032)
Fix to Metadata Modification Failure
The FUS-3433 known issue in prior releases is resolved, allowing metadata modifications to files that are recently moved from non-replicated to replicated locations to behave as expected. (FUS-3433)
REST API Timeout Behavior
Timeouts are applied on execution of REST APIs to prevent clients waiting indefinitely. (FUS-3477)
Lack of S3 copyObject accommodated
Fusion can accommodate S3 implementations that do not provide copyObject functionality. (FUS-3588)
Fusion REST API Availability
The Fusion server REST API is available regardless of the state of quorum in the system. (FUS-3619)
Improved behavior with large ingest
Ingesting very large numbers of files to a replicated directory at once is handled with better performance than previous releases. (FUS-3620, FUS-2469, FUS-3663, FUS-3673, FUS-3631)
Fixed Repair to Amazon EMR
When performing repair to an Amazon EMR zone, Fusion will perform correctly regardless of the state of existing files in EMR. (FUS-3701)
Empty Bandwidth Policy Handling
Ill-defined bandwidth limit policies do not result in Fusion server failure. (FUS-3716, FUS-3756)
Hadoop Rename Variant Support
The rename with options method in the Hadoop FileSystem API is supported. (FUS-3739, REPL-24)
NetApp Repair Improvement
iNode modifications made on a NetApp instance during repair are ignored to allow completion. (FUS-3850)
License Check Deadlock Corrected
A potential startup deadlock condition related to license checks has been corrected. (FUS-3863)
Configuration Changes for S3
Additional configuration options are provided for replication with S3 endpoints:
-
fs.fusion.s3.connectionTimeout, default is10s -
fs.fusion.s3.socketTimeout, default is50s -
fs.fusion.s3.maxConnections, default is50 -
fs.fusion.s3.maxErrorRetry, default is3 -
fs.fusion.s3.tcpKeepAlive, default isfalse
(FUS-3902)
Configuration Defaults For Performance
Internal configuration defaults have been modified to improve performance. (FUS-4099, FUS-4070)
Improved Startup Time
WD Fusion 2.10.3 improves startup time for processing agreed proposals. (FUS-4071, FUS-4086)
Prevent Read-after-write Inconsistency on S3
Changes made to interaction with the S3 API to avoid triggering conditions that can result in read-after-write inconsistency, affecting correct outcomes for replication. (FUS-3908, FUS-3936)
Consistency Check Reporting
WD Fusion 2.10.3 resolves the known issue in 2.10 where a consistency check that is triggered from a non-writer node may never complete. (FUS-2675, FUS-3684, FUS-3775)
Separate Execution Pools for Request Types
Introduced new executor thread pools to avoid processing starvation from long-running activities. (FUS-3799)
Scale Dependency Calculations
Fusion’s ability to scale effectively with extremely large numbers of outstanding agreements is improved. (FUS-3974, REPL-38)
No Scheduled Consistency Checks
There is no longer a requirement to run scheduled consistency checks for regular operation of WD Fusion. 2.10.3 turns off these checks by default. (FUS-4041, FUS-4003, FUS-3615)
Allow Reference to Remote File System
The Fusion client library will determine whether the scheme of the URI used to reference the underlying file system indicates that coordination via Fusion is not required, and act accordingly. This improves interoperability with distcp in particular. (FUS-1970)
API Information Corrected
Information returned from the /fusion/fs/transfers REST API no longer reports negative values. The repair API is similarly improved. (FUS-3219, FUS-3291)
Eliminate Generation of Extraneous Files During Rename
Multiple renames occurring in quick succession on a single file no longer result in extraneous files in non-originating zones. (FUS-3439)
Oozie Classpath Setup
Installation ensures that Oozie classpaths are configured to reference WD Fusion client libraries as required. (FUS-3659, FUS-3690)
Minimize Unecessary Logging
Hadoop clusters that do not have ACL support no longer result in excessive logging of aclStatus messages. (FUS-3704, FUS-3657)
Setting global exclusions via zone properties API
The behavior of the zone properties API when updating global exclusions has been corrected. (FUS-3741)
Improved S3 Interoperability
Configurations where a Hadoop cluster uses S3 as the underlying file system are improved. (FUS-3039)
Handle Data Pipeline Errors
WD Fusion interoperates with HDFS in a best-effort mode by default to avoid stalling from failed data pipeline errors. (FUS-3597)
Failed Transfers Marked as Failed
File content transfer that fails for external reasons no longer marks those transfers as incomplete. (FUS-3605)
Improved Content Transfer
Non-recoverable failures during content transfer are no longer retried. (FUS-3697)
Deterministic Default Exclusions
The default exclusions that apply to replication rules remain set regardless of changes to global zone properties. (FUS-3741)
Group names with spaces
Post-installation scripts allow for group names that include whitespace characters. (FUS-3774)
Missing files do not trigger retry loop
Non-recoverable failures on file pulls (due to a source file being removed or modified) no longer result in retry behavior. (FUS-3805, FUS-3833)
Fixed Relocatable Installation
Ambari-based installations performed to a non-standard directory work as expected. (FUS-4025)
Apache NiFi Interoperability
Classpath issues that occurred when using Nifi are resolved. (FUS-3852)
Reinstallation of decommissioned node
WD Fusion can be reinstalled on a node that has had a previous installation in place that has not been uninstalled correctly.
Improved resilience to failed content transfer
Origin zone file renames do not affect successful content transfer.
Updated Apache Commons Collection Version
Apache Commons Collection 3.2.2 is used in preference to 3.2.1. (FUS-1803)
Client JAR symbolic links for Spark2
Apache Spark2 follows a different model for third-party JAR integration than Spark. Fusion integrates correctly with Spark2. Resolution also applies to Accumulo. (FUS-4031)
Plugin Configuration on Classpath
Plugins can read configuration available on the CLASSPATH. (FUS-3815)
IHC Restart Messages
The service fusion-ihc-server-xxx_x_x restart command will indicate success or otherwise in response. (FUS-4039)
No Overwrite of Custom Logger Properties
Customization of the java.util.logging.FileHandler.pattern can be performed. (FUS-4045)
2.7.7. Fusion UI Improvements
Many minor improvements to user interface behavior are provided with this release. (FUI-4459 - FUI-4845)
2.7.8. Available Packages
This release of WANdisco Fusion supports the following versions of Hadoop:
-
CDH 5.2.0 - CDH 5.11.0
-
HDP 2.1.0 - HDP 2.6.0
-
MapR 4.0.1 - MapR 5.2.0
-
Pivotal HD 3.0.0 - 3.4.0
-
IOP (BigInsights) 4.0 - 4.2.5
The trial download includes the installation packages for CDH and HDP distributions only.
2.7.9. System Requirements
Before installing, ensure that your systems, software and hardware meet the requirements found in our online user guide at http://docs.wandisco.com/bigdata/wdfusion.
Third-Party Component Interoperability
WANdisco Fusion is interoperable with a wide variety of systems, including Hadoop distributions, object storage platforms, and cloud environments.
-
Amazon S3
-
Amazon EMR 5.0, 5.3, 5.4
-
Ambari 1.6, 1.7, 2.0, 3.1
-
CDH 5.2 - 5.11
-
EMC Isilon 7.2, 8.0
-
Google Cloud Storage
-
Google Cloud Dataproc
-
HDP 2.1.0 - 2.6.0
-
IBM BI 4.0 - 4.2.5
-
MapR M4.0 - M5.2
-
Microsoft Azure Blob Storage
-
Microsoft Azure HDInsights 3.2 - 3.6
-
MySQL, Oracle (Hive Metastore)
-
Oracle BDA, Oracle BDCS
-
Pivotal HD 3.0 - 3.4
Client Applications Supported
WANdisco Fusion is architected for maximum compatibility and interoperability with applications that use standard Hadoop File System APIs. All applications that use the standard Hadoop Distributed File System API or any Hadoop-Compatible File System API should be interoperable with WANdisco Fusion, and will be treated as supported applications. Additionally, Fusion supports the replication of content with Amazon S3 and S3-compatible objects stores, locally-mounted file systems, and NetApp NFS devices, but does not require or provide application compatibility libraries for these storage services.
2.7.10. Known Issues
Fusion 2.10.3 includes a small set of known issues with workarounds. In each case, resolution for the known issues is underway.
-
Renaming the parent directory of a location with current file transfers may result in incomplete transfer - FUS-387.
In some circumstances, modification of the metadata for a parent directory within a replicated location can prevent the completion of content transfer that is underway for files underneath that directory. Fusion’s metadata consistency is unaffected, but file content may not be available in full. Consistency check and repair can be used to both detect and resolve any resulting missing content.
-
Fusion does not support truncate command - FUS-3022
The public boolean truncate(Path f, long newLength) operation in org.apache.hadoop.fs.FileSystem (> 2.7.0) is not yet supported.
Files will be truncated only in the cluster where the operation is initiated.
Consistency check and repair can be used to both detect and resolve any resulting inconsistencies.
-
Fusion does not support
concat()operation - FUS-3714
The public void concat(Path trg, Path[] psrcs) operation in org.apache.hadoop.fs.FileSystem is not yet supported, and will result in filesystem inconsistency. Consistency check and repair can be used to both detect and resolve any resulting inconsistencies.
-
Consistency repair tool fails for files in Swift storage - FUS-3642
An issue impacting Swift storage which will be fixed in a future release.
2.8. Release 2.10.2 Build 413
13 May 2017
WD Fusion 2.10.1 introduces fixes and refinements that are specific to deployment into IBM’s BigInsights platform.
-
Supported added for IBM BigInsights 4.3
-
There is improved feedback given when making DSM changed on the web UI.
-
Made a refinement to the IHC
ihcFailureTrackercode to improve the handling of transient network issues that resulted from longer than expected timeouts.
2.8.1. Known Issues
There’s a problem that impacts BigInsights with BigReplication without Hive plugin that is caused by the client in HDFS.
Specifically, if Hive is using the hive.start.cleanup.scratchdir the wd-hive-metastore is recreating that directory with the wrong permissions.
There’s a workaround:
-
In Ambari go to Hive Configs and search for 'scratch'.
-
Modify setting 'hive.start.cleanup.scratchdir' to false.
-
Deploy configuration to all nodes.
-
Modify permissions in HDFS for /tmp/hive e.g. hdfs dfs -chown 733 /tmp/hive . -Restart all hive components through Ambari.
This issue will be fixed in the next release, 2.10.3.
2.9. Release 2.10 Build 46
13 April 2017
WANdisco is pleased to present WD Fusion 2.10 as the next major release of the Fusion platform, available now from the WANdisco file distribution site. This release includes significant new product functionality that leverages the Fusion architecture to support a broader range of use cases, expand performance and scale, and ease the administration of Fusion environments.
2.9.1. Installation
Find detailed installation instructions in the user guide at http://docs.wandisco.com/bigdata/wdfusion/2.10/#install
2.9.2. New Feature Highlights
This release includes the following major new features.
WANdisco Fusion for Network File Systems
WD Fusion 2.10 adds support for replicating data efficiently from Network File Systems (NFS) for NetApp devices to any mix of on-premises and cloud environments. This feature allows data replication at any scale from NFS to other Fusion zones.
User Interface
The WD Fusion user interface now presents a logical view of the Fusion operational components, Fusion zones and bandwidth limit policies in place of the physical map of locations. This makes it easier to observe the deployment of complex solutions and navigate directly to detailed views of individual item configuration.
Client Bypass
An improvement has been made to the mechanism used by the HDFS and HCFS client library to detect when a working Fusion server is unavailable. The improvement allows clients to bypass the Fusion server when needed without waiting for a TCP connection loss or timeout.
Replication of Read-Only Locations
Fusion 2.10 can be configured to replicate from storage system locations that do not provide write access for the identity used by the Fusion server.
S3 Enhancements
Fusion configuration options now include custom S3 endpoints so that replication can occur to non-AWS S3 providers. Additionally, when Fusion is hosted in AWS EC2, replication can occur to an S3 endpoint that is in a region other than where the Fusion services reside.
Repair Features and Improvements
The Fusion repair feature allows the transfer of initial content between Fusion zones that have not previously replicated, and can be used as a mechanism to perform once-off replication that remains consistent with other replication activity. Repair has been enhanced significantly in Fusion 2.10, including the following:
Auto-Parallelization of Repair
Fusion repair functionality has been extended with major improvements in performance by automatically scaling a single repair task across multiple threads of execution. This removes the need to issue multiple repair requests for subset of a replicated location. It also provides the ability to tune the threads used for repair independently of those used for consensus-driven activity of replicated content.
Checkpoint Repair
When initiating a repair task for initial data transfer or similar, you now have the option of selecting a checkpoint repair.
This avoids the need for Fusion to scan the file system of the originating zone under the repair path to determine content.
Checkpoint repair refers to content from an HDFS fsimage file, avoiding the need to lock other operations during a repair scan.
Consistency Check Features and Improvements
Consistency Check ACL Information
File system ACL information will be reported by consistency check and repaired by repair.
|
Restart WD Fusion if you enable ACLs on your cluster
After enabling ACLs on your cluster, Fusion Servers must be restarted, or the ACLs will behave as if ACLs are disabled, and would not appear in consistency check and repair operations.
|
User Interface Security
The WANdisco Fusion user interface can be accessed over HTTPS, and for that configuration to be performed independently of other SSL configuration.
Relocatable Installation
You can choose to install WD Fusion 2.10 in a location other than the default /opt/wandisco.
See Custom Location Installations.
Network Support for Firewalled Fusion Zones
Fusion 2.10 can operate in an environment where one Fusion zone does not allow inbound network connectivity. This is typical for a secured on-premises deployment, where it may be difficult to modify or establish corporate firewall rules to allow inbound TCP connections to the Fusion services.
ACL Replication
ACL replication can be enabled to allow changes from local- and remote-originated zones to be replicated. ACL information will be represented in consistency check results as appropriate.
|
LocalFS to LocalFS ACL Replication
We support replication of Hadoop ACLs as exposed via the FileSystem object. Deployments which don’t expose ACLs in this way (e.g. local filesystem) or don’t support ACLs at all (S3) will not replicate the ACLs between zones.
|
Enhanced Logging
Among a range of minor improvements to logged information, Fusion 2.10 adds the ability to log the identity of the proxy user for which requests are made.
Manual Fast Bypass
This feature introduces a mechanism to quickly prevent applications from using Fusion when interacting with the underlying file system, without the need to make configuration changes.
The fusion.replicated.dir.exchange configuration property in core-site.xml specifies the location under which a directory named bypass can be created to trigger this. Subsequent client activity in that cluster will bypass coordination through Fusion.
API to Track Completion of Transfers for a Specified Location
The API to track the status of transfers under a replicated directory now allows that tracking to be limited to a subdirectory of a replicated location.
Installation without Root Identity
Fusion 2.10 can be installed as a non-root user with sufficient permissions (sudo tar, sudo ambari-server, sudo cp).
Shadow Client JAR
The Fusion 2.10 client library for HDFS and HCFS compatibility ensures that classpath conflicts do not occur with any client application, allowing Fusion to be used by applications that use alternative versions of the Guava and Netty libraries.
Unsidelining
Periods of extended network outage between Fusion zones can be accommodated by limits that allow Fusion servers to identify a sidelined node, ensuring that operation of other nodes can continue in its absence. Prior to this release, bringing a sidelined node back into operation was a completely manual process. Fusion 2.10 adds a mechanism by which sidelined nodes can be recovered and participate in ongoing activity.
Operation as an HDFS Non-Superuser
To support operation in environments where minimal security privileges must be allocated, the Fusion server can now operate as a principal without HDFS superuser privileges.
Selective Replication of open() Requests
A configuration option (fusion.client.coordinate.read) is provided to allow coordination of open() requests, which by default is false.
Preferred Writer Selection
This release provides an API by which a preferred writer node can be specified for a given replicated path. The writer node is the Fusion server instance responsible for executing modifications to the local zone’s metadata via the file system API.
Grace Period for License Expiry
License expiration allows continued operation for a short grace period (by default one month for production licenses), during which notifications are presented to the administrator about the license expiry. This is in addition to the existing warnings provided prior to license expiration.
Additionally, license expiry does not halt operation of the Fusion server, which remains available to service activities that occur in non-replicated locations.
2.9.3. Available Packages
This release of WANdisco Fusion supports the following versions of Hadoop:
-
CDH 5.2.0 - CDH 5.10.0
-
HDP 2.1.0 - HDP 2.5.0
-
MapR 4.0.1 - MapR 5.2.0
-
Pivotal HD 3.0.0 - 3.4.0
-
IOP (BigInsights) 2.1.2 - 4.2
The trial download includes the installation packages for CDH and HDP distributions only.
2.9.4. System Requirements
Before installing, ensure that your systems, software and hardware meet the requirements found in our online user guide at docs.wandisco.com/bigdata/wdfusion/2.10/#_deployment_guide
Certified Third-Party Components
WANdisco certifies the interoperability of Fusion with a wide variety of systems, including Hadoop distributions, object storage platforms, cloud environments, and applications.
-
Amazon S3
-
Amazon EMR 4.6, 4.7.1, 5.0
-
Ambari 1.6, 1.7, 2.0, 3.1
-
CDH 4.4, 5.2 - 5.10
-
EMC Isilon 7.2, 8.0
-
Google Cloud Storage
-
Google Cloud Dataproc
-
HDP 2.1.0 - 2.5.0
-
IBM BI 2.1.2 - 4.2
-
MapR M4.0 - M5.0
-
Microsoft Azure Blob Storage
-
Microsoft Azure HDInsights 3.2 - 3.5
-
MySQL (Hive Metastore)
-
Oracle BDA
-
Pivotal HD 3.0 - 3.4
Client Applications Supported
WANdisco Fusion is architected for maximum compatibility and interoperability with applications that use standard Hadoop File System APIs. All applications that use the standard Hadoop Distributed File System API or any Hadoop-Compatible File System API should be interoperable with WANdisco Fusion, and will be treated as supported applications. Additionally, Fusion supports the replication of content with Amazon S3 and S3-compatible objects stores, locally-mounted file systems, and NetApp NFS devices, but does not require or provide application compatibility libraries for these storage services.
2.9.5. Known Issues
Fusion 2.10 includes a small set of known issues with workarounds. In each case, resolution of the known issues is underway.
-
Renaming the parent directory of a location with current file transfers may result in incomplete transfer - FUS-387.
In some circumstances, modification of the metadata for a parent directory within a replicated location can prevent the completion of content transfer that is underway for files underneath that directory. Fusion’s metadata consistency is unaffected, but file content may not be available in full. Consistency check and repair can be used to both detect and resolve any resulting missing content.
-
Metadata change following move of file from non-replicated to replicated location may be overwritten - FUS-3433
Under certain conditions, a metadata modification to a file that has recently been moved from a non-replicated to replicated location may be lost. Consistency check and repair can be used to both detect and resolve any resulting missing content.
-
Fusion does not support truncate command - FUS-3022
The public boolean truncate(Path f, long newLength) operation in org.apache.hadoop.fs.FileSystem (> 2.7.0) is not yet supported. Files will be truncated only in the cluster where the operation is initiated. Consistency check and repair can be used to both detect and resolve any resulting inconsistencies.
-
Fusion does not support
concat()operation - FUS-3714
The public void concat(Path trg, Path[] psrcs) operation in org.apache.hadoop.fs.FileSystem is not yet supported, and will result in filesystem inconsistency. Consistency check and repair can be used to both detect and resolve any resulting inconsistencies.
-
Consistency check will not be marked as done when initiated from a non-writer node - FUS-2675
While a consistency check initiated via the API at a non-writer node will execute and complete, its status will not be marked as such. Issue fixed in 2.10.3.
-
There are reports of a Linux Kernal bug that may cause WD Fusion to hang. See our KB article.
2.9.6. Other Improvements
In addition to the highlighted features listed above, Fusion 2.10 includes a wide set of improvements in performance, functionality, scale, interoperability and general operation.
-
Parallel repair functionality avoids duplicate repair activity - FUS-3073
-
Correction to handling of specific path names to avoid issues with Hive replication - FUS-3543
-
Stack installer does not access non-initialized variables (fix for install on Oracle Enterprise Linux) - FUS-3551
-
Installation completes with WebHDFS disabled - FUS-3555
-
/fusion/fsno longer returns 500 response when adding removed replicated location - FUS-2148 -
Talkback does not attempt to ssh to KDC as root user - FUS-3192
-
Consistency check tasks can be canceled - FUS-3053
-
service fusion-server restartdisplays success - FUS-3193 -
Installer supports configuration changes needed for SOLR - FUS-3200
-
Client library no longer conflicts with user jars - FUS-3372, FUS-3407
-
CDH parcel upgrade performed for
alternatives- FUS-3418 -
IHC SSL configuration no longer in
core-site.xml- FUS-2828 -
MapR 5.2.0 support - FUS-2870
-
Fusion UI now applies
auth_to_localsetting when browsing HDFS - FUI-3995 -
Repair page redesigned to avoid unselectable source of truth - FUI-3759
-
Fusion handshake token directory installer input is pre-populated when adding node to an existing zone - FUI-3920
-
UI correctly displayed size of replicated folder - FUI-3974/FUI-3995
-
Support for CDH 5.9 - FUI-4084
-
Support for Cloudera Manager 5.9 - FUI-4085
-
Support for CDH and Cloudera Manager 5.10 - FUI-4089
-
Consistency check marked as done when initiated from a non-writer node - FUI-3921/FUS-2675
-
Improved checks for Fusion client installation - FUI-3922
-
Install accommodates HIVE_AUX_JARS with single jar - FUS-3438
-
Allow operation with ambari-agent as non-root user - FUS-3211
-
Log proxy.user.name for requests - FUS-3154
-
Improve default exclusion paths for Hive tables - HIVE-310
-
Heap requirements for consistency check now independent of data volume - FUS-2402, FUS-3292
-
Avoid out of memory under failed socket connection scenario - DCO-683
-
Empty metadata content does not result in recursive delete - FUS-3190
-
Correct permission replication for Hive tables - FUS-3095, REPL-16
-
Allow cancellation of repair tasks that are underway - FUS-3052
-
Provide aggregate reporting of repair status across zones - FUS-2823, FUS-2948
-
Integrate with alternative native SSL libraries - FUS-2859
-
Talkback improves host resolution - FUS-3249
-
Service init functions allow AD groups with spaces in name - FUI-4278
-
RPM upgrades do not overwrite logging configuration - FUI-3894
-
Email alert interval polling defaults to 60s - FUI-3768
-
Metastore starts with DBTokenStore configured on CDH 5.5 - HIVE-384, HIVE-389
-
Support replication of external tables via default DSM - HIVE-225, HIVE-284
-
Correct Metastore configuration deployment with multiple nodes - HIVE-299
-
Bypass mechanism for replicated Metastore - HIVE-134
-
Metastore event listener replication - HIVE-222, HIVE-243, HIVE-234, REPL-2, REPL-7
-
WD Hive Metastore service status in Cloudera Manager - HIVE-257
-
Correct Hive installation on RHEL 7 - HIVE-261
-
Improve installation of Hive for HDP configuration - HIVE-296
-
Stack removal for Hive improved - HIVE-307
-
Standardized Java detection - FUS-2479, FUI-3165, HIVE-327
-
Hive support for CDH 5.9 - HIVE-356
-
Hive support for CDH 5.10 - HIVE-257
-
Correct permissions on
/tmp/wd-hive-metrics.loget al. - HIVE-392 -
Sidelined DSMs no longer trigger re-elections - FUS-3083
-
fusion.ssl.enabledproperty renamed tofusion.client.ssl.enabled- FUS-3013 -
Additional properties for S3 configuration - FUS-3513
-
Client requests to sidelined DSM no longer retry - FUS-3003, FUS-2927, FUS-3051, FUS-3299
-
HttpFS classpath corrections - FUS-3201
3. Deployment Guide
3.1. WANdisco server requirements
This section describes hardware requirements for deploying Hadoop using WD Fusion. These are guidelines that provide a starting point for setting up data replication between your Hadoop clusters.
|
Glossary
We’ll be using terms that relate to the Hadoop ecosystem, WD Fusion and WANdisco’s DconE replication technology. If you encounter any unfamiliar terms checkout the Glossary.
|
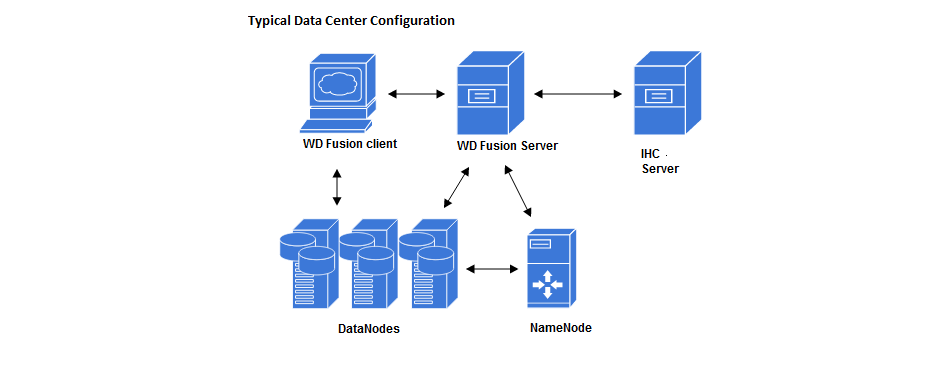
- WD Fusion UI
-
A separate server that provides administrators with a browser-based management console for each WD Fusion server. This can be installed on the same machine as WD Fusion’s server or on a different machine within your data center.
- IHC Server
-
Inter Hadoop Communication servers handle the traffic that runs between zones or data centers that use different versions of Hadoop. IHC Servers are matched to the version of Hadoop running locally. It’s possible to deploy different numbers of IHC servers at each data center, additional IHC Servers can form part of a High Availability mechanism.
|
WD Fusion servers don’t need to be collocated with IHC servers
If you deploy using the installer, both the WD Fusion and IHC servers are installed into the same system by default. This configuration is made for convenience, but they can be installed on separate systems. This would be recommended if your servers don’t have the recommended amount of system memory.
|
- WD Fusion Client
-
Client jar files to be installed on each Hadoop client, such as mappers and reducers that are connected to the cluster. The client is designed to have a minimal memory footprint and impact on CPU utilization.
|
WD Fusion must not be collocated with HDFS servers (DataNodes, etc)
HDFS’s default block placement policy dictates that if a client is collocated on a DataNode, then that collocated DataNode will receive 1 block of whatever file is being put into HDFS from that client. This means that if the WD Fusion Server (where all transfers go through) is collocated on a DataNode, then all incoming transfers will place 1 block onto that DataNode. In which case the DataNode is likely to consume lots of disk space in a transfer-heavy cluster, potentially forcing the WD Fusion Server to shut down in order to keep the Prevaylers from getting corrupted.
|
3.2. Licensing
WD Fusion includes a licensing model that can limit operation based on time, the number of nodes and the volume of data under replication. WANdisco generates a license file matched to your agreed usage model. You need to renew your license if you exceeds these limits or if your license period ends. See License renewals.
3.2.1. License Limits
When your license limits are exceeded, WD Fusion will operate in a limited manner, but allows you to apply a new license to bring the system back to full operation. Once a license is no longer valid:
-
Write operations to replicated locations are blocked,
-
Warnings and notifications related to the license expiry are delivered to the administrator,
-
Replication of data will no longer occur,
-
Consistency checks and repair operations are not allowed, and
-
Operations for adding replication rules and memberships will be denied.
Each different type of license has different limits.
Evaluation license
To simplify the process of pre-deployment testing, WD Fusion is supplied with an evaluation license (also known as a "trial license"). This type of license imposes limits:
| Source | Time limit | No. fusion servers | No. of Zones | Replicated Data | Plugins | Specified IPs |
|---|---|---|---|---|---|---|
Website |
14 days |
1-2 |
1-2 |
5TB |
No |
No |
Production license
Customers entering production need a production license file for each node. These license files are tied to the node’s IP address. In the event that a node needs to be moved to a new server with a different IP address customers should contact WANdisco’s support team and request that a new license be generated. Production licenses can be set to expire or they can be perpetual.
| Source | Time limit | No. fusion servers | No. of Zones | Replicated Data | Plugins | Specified IPs |
|---|---|---|---|---|---|---|
WANdisco |
variable (default: 1 year) |
variable (default: 20) |
variable (default: 10) |
variable (default: 20TB) |
Yes |
Yes |
3.2.2. License updates
Unless there’s a problem that stops you from reaching the {productname} UI, the correct way to upgrade a node license is through the License panel, under the Settings tab.
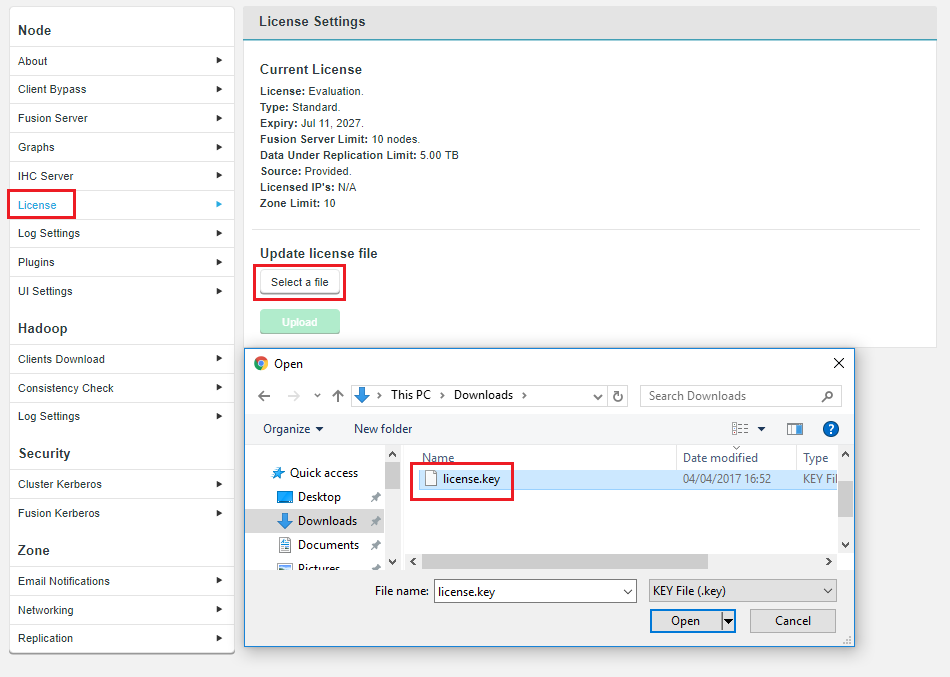
-
Click on License to bring up the License Settings panel.
-
Click Select a file. Navigate to and select your replacement License file.
-
Click Upload and review the details of your replacement license file.
License updates when a node is not accessible.
If one or more of your nodes are down or expired, you can still perform a license update by updating the license file on all nodes, via the UI. In this situation, the license upgrade cannot be done in a coordinated fashion, from a single node, but it can be completed locally if done on all nodes.
Manual license update
The following manual procedure should only be used if the above method is not available, such as when a node cannot be started - maybe caused by ownership or permissions errors on an existing license file. If you can, use the procedure outlined above.
-
Log in to your server’s command line, navigate to the properties directory:
/etc/wandisco/fusion/server
-
We recommend that you rename the
license.keyto something versioned, e.g.license.20170711. -
Get your new license.key and drop it into the
/etc/wandisco/fusion/serverdirectory. You need to account for the following factors:-
Ensure the filename is license.key
-
Ownership should be the same as the original file.
-
Permissions should be the same as the original file.
-
-
Restart the replicator by running the Fusion init.d script with the following argument:
[root@redhat6 init.d]# service fusion-ui-server restart
This will trigger the WD Fusion replicator restart, which will force WD Fusion to pick up the new license file and apply any changes to permitted usage.
If you don’t restartIf you follow the above instructions but don’t do the restart WD Fusion will continue to run with the old license until it performs a daily license validation (which runs at midnight). Providing that your new license key file is valid and has been put in the right place then WD Fusion will then update its license properties without the need to restart. -
If you run into problems, check the replicator logs (
/var/log/fusion/server/) for more information.PANIC: License is invalid com.wandisco.fsfs.licensing.LicenseException: Failed to load filepath>
3.3. Prerequisites Checklist
The following prerequisites checklist apply to both the WD Fusion server and for separate IHC servers. We recommend that you deploy on physical hardware rather than on a virtual platform, however, there are no reasons why you can’t deploy on a virtual environment.
3.3.1. Scaling a deployment
How much WD Fusion you need to deploy is not proportionate to the amount of data stored in your clusters, or the number of nodes in your clusters. You deploy WD Fusion/IHC server nodes in proportion to the data traffic between clusters; the more data traffic you need to handle, the more resources you need to put into the WD Fusion server software.
If you plan to locate both the WD Fusion and IHC servers on the same machine then check the Collocated Server requirements:
- CPUs
-
Small WD Fusion server deployment : 8 cores
Large WD Fusion server deployment: : 16 cores
Architecture: 64-bit only.
- System memory
-
There are no special memory requirements, except for the need to support a high throughput of data:
Type: Use ECC RAM
Size: Recommended 64 GB recommended (minimum of 16 GB)
Small WD Fusion server Deployment: 32 GB
Large WD Fusion server deployment: 128 GB
System memory requirements are matched to the expected cluster size and should take into account the number of files and block size. The more RAM you have, the bigger the supported file system, or the smaller the block size.
|
Collocation of WD Fusion/IHC servers
Both the WD Fusion server and the IHC server are, by default, installed on the same machine, in which case you would need to double the minimum memory requirements stated above. E.g.
Size: Recommended 64 GB recommended (minimum of 32 GB)Small WD Fusion server Deployment: 64 GB Large WD Fusion server deployment: 128 GB or more |
- Storage space
-
Type: Hadoop operations are storage-heavy and disk-intensive so we strongly recommend that you use enterprise-class Solid State Drives (SSDs).
Size: Recommended: 1 TiB
Minimum: You need at least 250 GiB of disk space for a production environment.
- Network Connectivity
-
Minimum 1Gb Ethernet between local nodes.
Small WANdisco Fusion server: 2Gbps
Large WANdisco Fusion server: 4x10 Gbps (cross-rack)
TCP Port Allocation: The following default TCP ports need to be reserved for WD Fusion installations:

- WD Fusion Server
-
DConE replication port: 6444
DCone port handles all coordination traffic that manages replication. It needs to be open between all WD Fusion nodes. Nodes that are situated in zones that are external to the data center’s network will require unidirectional access through the firewall.Application/REST API: 8082
REST port is used by the WD Fusion application for configuration and reporting, both internally and via REST API. The port needs to be open between all WD Fusion nodes and any systems or scripts that interface with WD Fusion through the REST API.
WD Fusion Client port: 8023
Port used by WD Fusion server to communicate with HCFS/HDFS clients. The port is generally only open to the local WD Fusion server, however you must make sure that it is open to edge nodes.
WD Fusion Server listening port: 8024
Port used by WD Fusion server to listen for connections from remote IHC servers. It is only used in unidirectional mode, but it’s always opened for listening. Remote IHCs connect to this port if the connection can’t be made in the other direction because of a firewall. The SSL configuration for this port is controlled by the same ihc.ssl.enabled property that is used for IHC connections performed from the other side. See Enable SSL for WD Fusion.
IHC ports: 7000-range or 9000-range
7000 range, (exact port is determined at installation time based on what ports are available), used for data transfer between Fusion Server and IHC servers. Must be accessible from all WD Fusion nodes in the replicated system.
9000 range, exact port is determined at installation time based on available ports), used for an HTTP Server that exposes JMX metrics from the IHC server.
- WD Fusion UI
-
Web UI interface: 8083 Used to access the WD Fusion Administration UI by end users (requires authentication), also used for inter-UI communication. This port should be accessible from all Fusion servers in the replicated system as well as visible to any part of the network where administrators require UI access.
3.3.2. Software requirements
Operating systems:
RHEL 6 x86_64
RHEL 7 x86_64
Oracle Linux 6 x86_64
Oracle Linux 7 x86_64
CentOS 6 x86_64
CentOS 7 x86_64
Ubuntu 12.04LTS
Ubuntu 14.04LTS
SLES 11 x86_64
- Web browsers
-
Mozilla Firefox 11 and higher
Google Chrome
- Java
-
Java JRE 1.7 / 1.8 See Supported versions Hadoop requires Java JRE 1.7. as a minimum. It is built and tested on Oracle’s version of Java Runtime Environment. We have now added support for Open JDK 7, which is used in Amazon Cloud deployments. For other types of deployment we recommend running with Oracle’s Java as it has undergone more testing.
|
"JAVA_HOME could not be discovered" error
You need to ensure that the system user that is set to run Fusion has the JAVA_HOME variable set. Installation failures that result in a message "JAVA_HOME could not be discovered" are usually caused by the specific WAND_USER account not having JAVA_HOME set. In WD Fusion 2.10.x
From WD Fusion 2.11 |
- Architecture
-
64-bit only
Heap size: Set Java Heap Size of to a minimum of 1Gigabytes, or the maximum available memory on your server.
Use a fixed heap size. Give -Xminf and -Xmaxf the same value. Make this as large as your server can support.
Avoid Java defaults. Ensure that garbage collection will run in an orderly manner. Configure NewSize and MaxNewSize Use 1/10 to 1/5 of Max Heap size for JVMs larger than 4GB. Stay deterministic!
When deploying to a cluster, make sure you have exactly the same version of the Java environment on all nodes.
Where’s Java?
Although WD Fusion only requires the Java Runtime Environment (JRE), Cloudera and Hortonworks may install the full Oracle JDK with the high strength encryption package included. This JCE package is a requirement for running Kerberized clusters.
For good measure, remove any JDK 6 that might be present in /usr/java. Make sure that /usr/java/default and /usr/java/latest point to an instance of java 7 version, your Hadoop manager should install this.
Ensure that you set the JAVA_HOME environment variable for the root user on all nodes. Remember that, on some systems, invoking sudo strips environmental variables, so you may need to add the JAVA_HOME to Sudo’s list of preserved variables.
Due to a bug in JRE 7, you should not run FINER level logging for javax.security.sasl if you are running on JDK 7. Doing so may result in an NPE. You can guard against the problem by locking down logging with the addition of the following line in WD Fusion’s logger.properties file (in /etc/fusion/server):
|
`javax.security.sasl.level=INFO`
The problem has been fixed for JDK 8. FUS-1946 Due to a bug in JDK 8 prior to 8u60, replication throughput with SSL enabled can be extremely slow (less than 4MB/sec). This is down to an inefficient GCM implementation.
Workaround
Upgrade to Java 8u60 or greater, or ensure WD Fusion is able to make use of OpenSSL libraries instead of JDK. Requirements for this can be found at http://netty.io/wiki/requirements-for-4.x.html[FUS-3041]
ulimit -u && ulimit -n
-u The maximum number of processes available to a single user.
-n The maximum number of open file descriptors.
For optimal performance, we recommend both hard and soft limits values to be set to 64000 or more:
RHEL6 and later: A file /etc/security/limits.d/90-nproc.conf explicitly overrides the settings in security.conf, i.e.:
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 1024 <- Increase this limit or ulimit -u will be reset to 1024
Ambari/Pivotal HD and Cloudera manager will set various ulimit entries, you must ensure hard and soft limits are set to 64000 or higher. Check with the ulimit or limit command. If the limit is exceeded the JVM will throw an error: java.lang.OutOfMemoryError: unable to create new native thread.
- Additional requirements
-
iptables Use the following procedure to temporarily disable iptables, during installation:
RedHat 6
-
Turn off with
$ sudo chkconfig iptables off
-
Reboot the system.
-
On completing installation, re-enable with
$ sudo chkconfig iptables on
RedHat 7
-
Turn off with
$ sudo systemctl disable firewalld
-
Reboot the system.
-
On completing installation, re-enable with
$ sudo systemctl enable firewalld
Comment out requiretty in /etc/sudoers
The installer’s use of sudo won’t work with some linux distributions (CentOS where /etc/sudoer sets enables requiretty, where sudo can only be invoked from a logged in terminal session, not through cron or a bash script. When enabled the installer will fail with an error:
execution refused with "sorry, you must have a tty to run sudo" message Ensure that requiretty is commented out: # Defaults requiretty
- SSL encryption
-
Basics
WD Fusion supports SSL for any or all of the three channels of communication: Fusion Server - Fusion Server, Fusion Server - Fusion Client, and Fusion Server - IHC Server.
keystore
A keystore (containing a private key / certificate chain) is used by an SSL server to encrypt the communication and create digital signatures.
truststore
A truststore is used by an SSL client for validating certificates sent by other servers. It simply contains certificates that are considered "trusted". For convenience you can use the same file as both the keystore and the truststore, you can also use the same file for multiple processes.
- Enabling SSL
-
You can enable SSL during installation (Step 4 Server) or through the SSL Settings screen, selecting a suitable Fusion HTTP Policy Type. It is also possible to enable SSL through a manual edit of the application.properties file. We don’t recommend using the manual method, although it is available if needed: Enable HTTPS.
| Due to a bug in JDK 8 prior to 8u60, replication throughput with SSL enabled can be extremely slow (less than 4MB/sec). This is down to an inefficient GCM implementation. |
Workaround
Upgrade to Java 8u60 or greater, or ensure WD Fusion is able to make use of OpenSSL libraries instead of JDK. Requirements for this can be found at http://netty.io/wiki/requirements-for-4.x.html
FUS-3041
Disabling low strength encryption ciphers
Transport Layer Security (TLS) and its predecessor, Secure Socket Layer (SSL) are widely adopted protocols that are used transfer of data between the client and the server through authentication and encryption and integrity.
Recent research has indicated that some of the cipher systems that are commonly used in these protocols do not offer the level of security that was previously thought.
In order to stop WD Fusion from using the disavowed ciphers (DES, 3DES, and RC4), use the following procedure on each node where the Fusion service runs:
-
Confirm JRE_HOME/lib/security/java.security allows override of security properties, which requires
security.overridePropertiesFile=true -
As root user:
mkdir /etc/wandisco/fusion/security chown hdfs:hadoop /etc/wandisco/fusion/security
-
As hdfs user:
cd /etc/wandisco/fusion/security echo "jdk.tls.disabledAlgorithms=SSLv3, DES, DESede, RC4" >> /etc/wandisco/fusion/security/fusion.security
-
As root user:
cd /etc/init.d
-
Edit the fusion-server file to add
-Djava.security.properties=/etc/wandisco/fusion/security/fusion.security
to the JVM_ARG property.
-
Edit the
fusion-ihc-server-xxxfile to add-Djava.security.properties=/etc/wandisco/fusion/security/fusion.security
to the JVM_ARG property.
cd /opt/wandisco/fusion-ui-server/lib
-
Edit the init-functions.sh file to add
-Djava.security.properties=/etc/wandisco/fusion/security/fusion.security
to the JAVA_ARGS property.
-
-
Restart the fusion server, ui server and IHC server.
3.3.3. Supported versions
This table shows the versions of Hadoop and Java that we currently support:
Distribution: |
Console: |
JRE: |
Apache Hadoop 2.5.0 |
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
|
HDP 2.1.0 - HDP 2.6.2 |
Ambari (Check Stack Compatibility) |
Oracle JDK 1.7 (1.7 is deprecated from HDP 2.6.0-2 and not compatible from 2.6.3) / 1.8 or OpenJDK 7/8 |
CDH 5.2.0 - CDH 5.11.0 |
Cloudera Manager (Check CDH requirements) |
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
Pivotal HD 3.0, 3.4 |
Ambari 1.6.1 / 1.7 |
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
MapR 4.0.x, 4.1.0, 5.0.0, 5.2 |
Ambari 1.6.1 / 1.7 |
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
Amazon S3 |
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
|
IOP (BigInsights) 4.0 / 4.1 / 4.2 / 4.2.5 |
Ambari 1.7 (with IOP 4.0) / 2.1 / 2.2. /2.4 |
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
3.3.4. Supported applications
Supported Big Data applications my be noted here, as we complete testing:
Application: |
Version Supported: |
Tested with: |
Syncsort DMX-h: |
8.2.4. |
See Knowledge base |
3.3.5. Final Preparations
We’ll now look at what you should know and do as you begin the installation.
Time requirements
The time required to complete a deployment of WD Fusion will in part be based on its size, larger deployments with more nodes and more complex replication rules will take correspondingly more time to set up. Use the guide below to help you plan for deployments.
-
Run through this document and create a checklist of your requirements. (1-2 hours).
-
Complete the WD Fusion installation (about 20 minutes per node, or 1 hour for a test deployment).
-
Complete client installations and complete basic tests (1-2 hours).
Of course, this is a guideline to help you plan your deployment. You should think ahead and determine if there are additional steps or requirements introduced by your organization’s specific needs.
Network requirements
See the deployment checklist for a list of the TCP ports that need to be open for WD Fusion.
3.3.6. Kerberos Security
If you are running Kerberos on your cluster you should consider the following requirements:
-
Kerberos is already installed and running on your cluster
-
Fusion-Server is configured for Kerberos as described in Setting up Kerberos
-
Kerberos Configuration before starting the installation
Before running the installer on a platform that is secured by Kerberos, you’ll need to run through the following steps: Setting up Kerberos.
|
Warning about mixed Kerberized / Non-Kerberized zones
In deployments that mix kerberized and non-kerberized zones it’s possible that permission errors will occur because the different zones don’t share the same underlying system superusers. In this scenario you would need to ensure that the superuser for each zone is created on the other zones.
|
For example, if you connect a Zone that runs CDH, which has superuser 'hdfs" with a zone running MapR, which has superuser 'mapr', you would need to create the user 'hdfs' on the MapR zone and 'mapr' on the CDH zone.
|
Kerberos Relogin Failure with Hadoop 2.6.0 and JDK7u80 or later
Hadoop Kerberos relogin fails silently due to HADOOP-10786. This impacts Hadoop 2.6.0 when JDK7u80 or later is used (including JDK8).
Users should downgrade to JDK7u79 or earlier, or upgrade to Hadoop 2.6.1 or later.
|
Manual instructions
See the Knowledge Base for instructions on setting up manual Kerberos settings. You only need these in special cases as the steps have been handled by the installer. See Manual Updates for WD Fusion UI Configuration.
See the above Knowledge Base article for instructions on setting up auth-to-local permissions, mapping a Kerberos principal onto a local system user. See the KB article - Setting up Auth-to-local.
3.3.7. Clean Environment
Before you start the installation you must ensure that there are no existing WD Fusion installations or WD Fusion components installed on your elected machines. If you are about to upgrade to a new version of WD Fusion you must first make sure that you run through the removal instructions provided in the Appendix - Cleanup WD Fusion.
|
Ensure HADOOP_HOME is set in the environment
Where the hadoop command isn’t in the standard system path, administrators must ensure that the HADOOP_HOME environment variable is set for the root user and the user WD fusion will run as, typically hdfs.
When set, HADOOP_HOME must be the parent of the bin directory into which the Hadoop scripts are installed.
Example: if the hadoop command is:
|
/opt/hadoop-2.6.0-cdh5.4.0/bin/hadoop
then HADOOP_HOME must be set to
/opt/hadoop-2.6.0-cdh5.4.0/.
3.3.8. Installer File
You need to match WANdisco’s WD Fusion installer file to each data center’s version of Hadoop. Installing the wrong version of WD Fusion will result in the IHC servers being misconfigured.
|
Why installation requires root user
WD Fusion core and WD Fusion UI packages are installed using root permissions, using the RPM tool (or equivalent for .deb packages). RPM requires root to run - hence the need for the permissions. The main requirement for running with root is the need for the installer to create the folder structure for WD Fusion components, e.g.
Once all files are put into place, they are permissioned and owned by a specific fusion user. After the installation of the artifacts root is not used and the Fusion processes themselves are run as a specific Fusion user (usually "hdfs"). |
4. Installation
This section will run through the installation of WD Fusion from the initial steps where we make sure that your existing environment is compatible, through the procedure for installing the necessary components and then finally configuration.
- Deployment Checklist
-
Important hardware and software requirements, along with considerations that need to be made before starting to install WD Fusion.
- Final Preparations
-
Things that you need to do immediately before you start the installation.
- Starting the installer
-
Step by step guide to the installation process when using the unified installer. For instructions on completing a fully manual installation see On-premises Installation.
- Configuration
-
Runs through the changes you need to make to start WD Fusion working on your platform.
- Working in the Hadoop ecosystem
-
Necessary steps for getting WD Fusion to work with supported Hadoop applications.
- Deployment appendix
-
Extras that you may need that we didn’t want cluttering up the installation guide.
4.1. On premises installation
The following section covers the installation of WANdisco Fusion into a cluster that is based in your organization’s own premises.
|
Installation via sudo-restricted non-root user
In some deployments it may not be permitted to complete the installation using root user. It should be possible to complete an installation with a limited set of sudo commands.
|
4.1.1. Starting the installation
Use the following steps to complete an installation using the installer file.
This requires an administrator to enter details throughout the procedure.
Once the initial settings are entered through the terminal session, the installation is then completed through a browser or alternatively, using a Silent Installation option to handle configuration programmatically.
Note: The screenshots shown in this section are from a Cloudera installation so there may be slight differences to your set up.
-
Open a terminal session on your first installation server. Download the appropriate installer from WANdisco’s FD website. You need the appropriate one for your platform.
-
Ensure the downloaded files are executable e.g.
chmod +x fusion-ui-server-<version>_rpm_installer.sh
-
Execute the file with root permissions, e.g.
sudo ./fusion-ui-server-<version>_rpm_installer.sh
-
The installer will now start.
Verifying archive integrity... All good. Uncompressing WANdisco Fusion.............................. :: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### ##### Welcome to the WANdisco Fusion installation You are about to install WANdisco Fusion version 2.10.5 Do you want to continue with the installation? (Y/n) yThe installer will perform an integrity check, confirm the product version that will be installed, then invite you to continue. Enter "Y" to continue the installation.
-
The installer checks that both Perl and Java are installed on the system.
Checking prerequisites: Checking for perl: OK Checking for java: OK
See the Installation Checklist Java Requirements for more information about these requirements.
-
Next, confirm the port that will be used to access WD Fusion through a browser.
Which port should the UI Server listen on? [8083]:
-
Select the platform version and type from the list of supported platforms. The examples given below are from a Cloudera installation.
Please specify the appropriate backend from the list below: [0] cdh-5.3.x [1] cdh-5.4.x [2] cdh-5.5.x [3] cdh-5.6.x [4] cdh-5.7.x [5] cdh-5.8.x [6] cdh-5.9.x [7] cdh-5.10.x [8] cdh-5.11.x Which fusion backend do you wish to use? 5
Installing on AmbariIf you are using HDP-2.6.x ensure you specify the correct platform version - version 2.6.0 and 2.6.1 need a separate installer to 2.6.2 and above.MapR/Pivotal availabilityThe MapR/PHD versions of Hadoop have been removed from the trial version of WD Fusion in order to reduce the size of the installer for most prospective customers. These versions are run by a small minority of customers, while their presence nearly doubled the size of the installer package. Contact WANdisco if you need to evaluate WD Fusion running with MapR or PHD.
Additional available packages
[1] mapr-4.0.1 [2] mapr-4.0.2 [3] mapr-4.1.0 [4] mapr-5.0.0 [5] phd-3.0.0
URI MapR needs to use WD Fusion’s native "fusion:///" URI, instead of the default hdfs:///.
Ensure that during installation you select the Use WD Fusion URI with HCFS file system URI option.
Superuser
If you install into a MapR cluster then you need to assign the MapR superuser system account/groupmaprif you need to run WD Fusion using the fusion:/// URI. See the requirement for MapR Client Configuration. See the requirement for MapR impersonation. When using MapR and doing a TeraSort run, if one runs without the simple partitioner configuration, then the YARN containers will fail with a Fusion Client ClassNotFoundException. The remedy is to setyarn.application.classpathon each node’s yarn-site.xml.
FUI-1853 -
Next, you set the system user group for running the application.
We strongly advise against running Fusion as the root user. For default CDH setups, the user should be set to 'hdfs'. However, you should choose a user appropriate for running HDFS commands on your system. Which user should Fusion run as? [hdfs] Checking 'hdfs' ... ... 'hdfs' found. Please choose an appropriate group for your system. By default CDH uses the 'hdfs' group. Which group should Fusion run as? [hdfs] Checking 'hdfs' ... ... 'hdfs' found.
-
The installer does a search for the commonly used account and group, assigning these by default. Check the summary to confirm that your chosen settings are appropriate: Installing with the following settings:
Installing with the following settings: Installation Prefix: /opt/wandisco User and Group: hdfs:hdfs Hostname: <your.fusion.hostname> WD Fusion Admin UI Listening on: 0.0.0.0:8083 WD Fusion Admin UI Minimum Memory: 128 WD Fusion Admin UI Maximum memory: 512 Platform: <your selected platform and version> WD Fusion Server Hostname and Port: <your.fusion.hostname>:8082 Do you want to continue with the installation? (Y/n)
If these settings are correct then enter "Y" to complete the installation of the WD Fusion server.
-
The package will now install.
Installing <your selected packages> server packages: <your selected server package> ... Done <your selected ihc-server package> ... Done Installing plugin packages: <any selected plugin packages> ... Done Installing fusion-ui-server package: fusion-ui-server-<your version>.noarch.rpm ... Done Starting fusion-ui-server: [ OK ] Checking if the GUI is listening on port 8083: .......Done
-
The WD Fusion server will now start up:
Please visit <your.fusion.hostname> to complete installation of WANdisco Fusion If <your.fusion.hostname> is internal or not available from your browser, replace this with an externally available address to access it.
At this point the WD Fusion server and corresponding IHC server will be installed. The next step is to configure the WD Fusion UI through a browser or using the silent installation script.
4.1.2. Configure WD Fusion through a browser
Follow this section to complete the installation by configuring WD Fusion using a browser-based graphical user interface.
|
Silent Installation
For large deployments it may be worth using Silent Installation option.
|
-
Open a web browser and point it at the provided URL. e.g.
http://<your.fusion.hostname>.com:8083/
-
In the first "Welcome" screen you’re asked to choose between Create a new Zone and Add to an existing Zone.
 Figure 3. Welcome
Figure 3. WelcomeMake your selection as follows: Adding a new WD Fusion cluster Select Add Zone. Adding additional WD Fusion servers to an existing WD Fusion cluster Select Add to an existing Zone.
High Availability for WD Fusion / IHC Servers
It’s possible to enable High Availability in your WD Fusion cluster by adding additional WD Fusion/IHC servers to a zone. These additional nodes ensure that in the event of a system outage, there will remain sufficient WD Fusion/IHC servers running to maintain replication.Add HA nodes to the cluster using the installer and choosing to Add to an existing Zone. A new node name will be assigned but you can chose a label if preferred.
-
Run through the installer’s detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
 Figure 4. Installer screen
Figure 4. Installer screen -
On clicking validate the installer will run through a series of checks of your system’s hardware and software setup and warn you if any of WD Fusion’s prerequisites are missing.
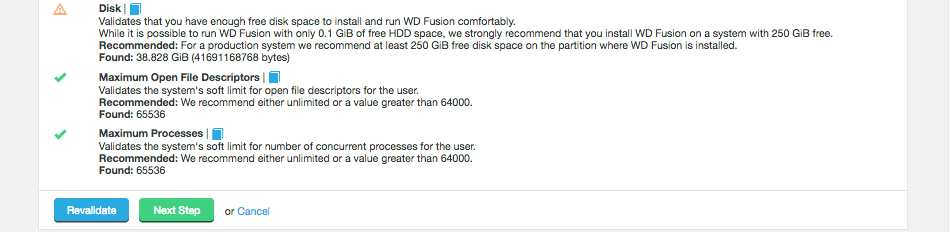 Figure 5. Validation results
Figure 5. Validation resultsAny element that fails the check should be addressed before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if only for evaluation purposes and not for production. However, when installing for production, you should address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
-
Upload the license file.
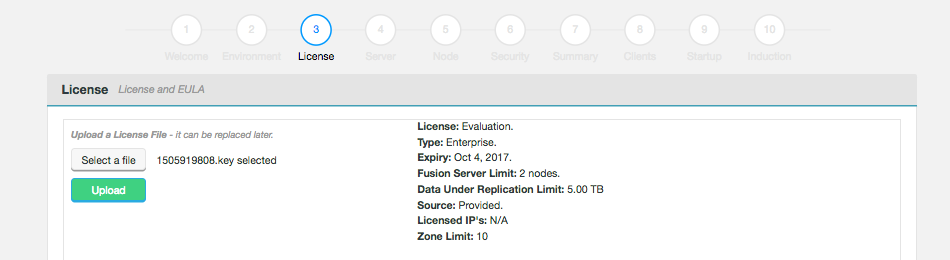 Figure 6. Installer screen
Figure 6. Installer screenThe conditions of your license agreement will be shown in the top panel.
-
In the lower panel is the EULA. Read through the EULA. When the scroll bar reaches the bottom you can click on the I agree to the EULA to continue, then click Next Step.
 Figure 7. Verify license and agree to subscription agreement
Figure 7. Verify license and agree to subscription agreement -
Enter settings for the WD Fusion server.
 Figure 8. Fusion server settings
Figure 8. Fusion server settingsWD Fusion Server
- Fully Qualified Domain Name / IP
-
The full hostname for the server.
- We have detected the following hostname/IP addresses for this machine.
-
The installer will try to detect the server’s hostname from its network settings. Additional hostnames will be listed on a dropdown selector.
- DConE Port
-
TCP port used by WD Fusion for replicated traffic. Validation will check that the port is free and that it can be bound to.
- Fusion HTTP Policy Type
-
Sets the policy for communication with the WD Fusion Core Server API.
Select from one of the following policies:
Only HTTP - WD Fusion will not use SSL encryption on its API traffic.
Only HTTPS - WD Fusion will only use SSL encryption for API traffic.
Use HTTP and HTTPS - WD Fusion will use both encrypted and un-encrypted traffic.Known IssueCurrently, the HTTP policy and SSL settings both independently alter how WD Fusion uses SSL, when they should be linked. You need to make sure that your HTTP policy selection and the use of SSL (enabled in the next section of the Installer) are in sync. If you choose either to the policies that use HTTPS, then you must enable SSL. If you stick with "Only HTTP" then you must ensure that you do not enable SSL. In a future release these two settings will be linked so it wont be possible to have contradictory settings. - Fusion HTTP Server Port
-
The TCP port used for standard HTTP traffic. Validation checks whether the port is free and that it can be bound.
- Maximum Java heap size (GB)
-
Enter the maximum Java Heap value for the WD Fusion server. The minimum for production is 16GB but 64GB is recommended.
- Umask (currently 0022)
-
Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
Advanced options
|
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments.
The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco’s support team before enabling them.
|
Custom Fusion Request Port
You can provide a custom TCP port for the Fusion Request Port (also known as WD Fusion client port).
The default value is 8023.
Strict Recovery
Two advanced options are provided to change the way that WD Fusion responds to a system shutdown where WD Fusion was not shutdown cleanly.
Currently the default setting is to not enforce a panic event in the logs, if during startup we detect that WD Fusion wasn’t shutdown.
This is suitable for using the product as part of an evaluation effort.
However, when operating in a production environment, you may prefer to enforce the panic event which will stop any attempted restarts to prevent possible corruption to the database.
-
DConE panic if db is dirty
This option lets you enable the strict recovery option for WANdisco’s replication engine, to ensure that any corruption to its prevayler database doesn’t lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
-
App panic if db is dirty
This option lets you enable the strict recovery option for WD Fusion’s database, to ensure that any corruption to its internal database doesn’t lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
Push Threshold
-
Set threshold manually
Set to blocksize, by default. See Set Push Threshold Manually
Chunk Size
The size of the 'chunks' used in file transfer.
| If synchronizing with s3 then the Hadoop clusters that replicate to object stores (because it could be more than s3) should turn set to off '0'. |
-
Enter the settings for the IHC Server.
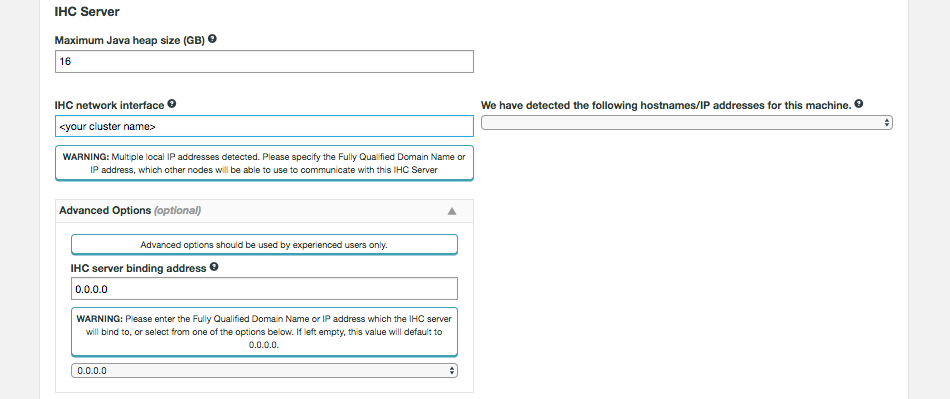 Figure 9. IHC Server details
Figure 9. IHC Server details- Maximum Java heap size (GB)
-
Enter the maximum Java Heap value for the WD Inter-Hadoop Communication (IHC) server. The minimum for production is 16GB but 64GB is recommended.
- IHC network interface
-
The hostname for the IHC server. The hostname for the IHC server. It can be typed or selected from the dropdown on the right.
Advanced Options (optional)
- IHC server binding address
-
In the advanced settings you can decide which address the IHC server will bind to. The address is optional, by default the IHC server binds to all interfaces (0.0.0.0), using the port specified in the
ihc.serverfield.
Once all settings have been entered, click Next step.
-
Next, you will enter the settings for your new Zone.
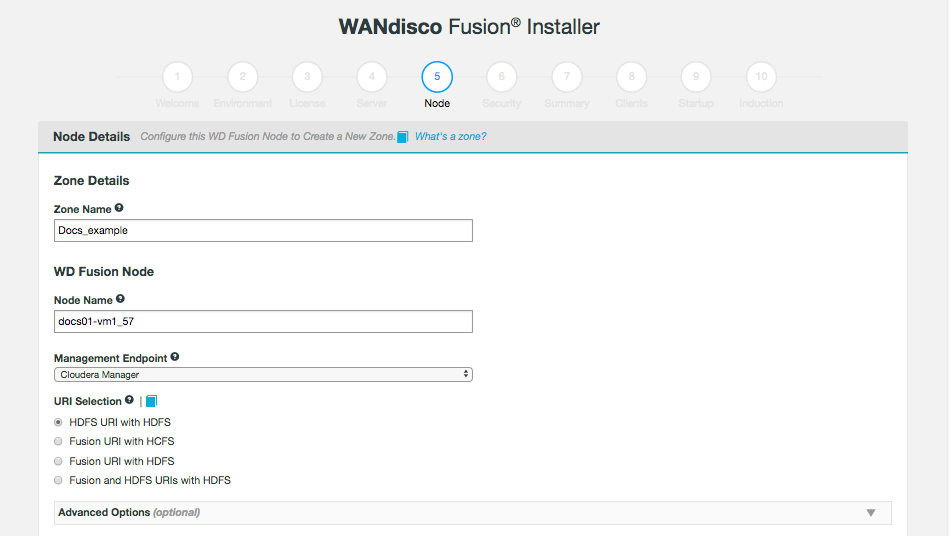 Figure 10. Zone information
Figure 10. Zone informationEntry fields for zone properties:
- Zone Name
-
The name used to identify the zone in which the server operates.
- Node Name
-
The Node’s assigned name that is used in with the UI and referenced in the node server’s hostname.
Induction failureIf induction fails, attempting a fresh installation may be the most straight forward cure, however, it is possible to push through an induction manually, using the REST API. See Handling Induction Failure.Known issue with Node IDsYou must use different Node IDs for each zone. If you use the same name for multiple zones, then you will not be able to complete the induction between those nodes. - Management Endpoint
-
If relevant to your set up, select the manager that you are using, for example Cloudera or Ambari. The selection will display the entry fields for your selected manager.
URI Selection
The default behavior for WD Fusion is to fix all replication to the Hadoop Distributed File System / hdfs:/// URI. Setting the hdfs-scheme provides the widest support for Hadoop client applications, since some applications can’t support the available "fusion:///" URI they can only use the HDFS protocol. Each option is explained below:
- Use HDFS URI with HDFS file system
-
The element appears in a radio button selector:

This option is available for deployments where the Hadoop applications support neither the WD Fusion URI nor the HCFS standards. WD Fusion operates entirely within HDFS.
This configuration will not allow paths with the fusion:/// uri to be used; only paths starting with hdfs:/// or no scheme that correspond to a mapped path will be replicated. The underlying file system will be an instance of the HDFS DistributedFileSystem, which will support applications that aren’t written to the HCFS specification.
- Use WD Fusion URI with HCFS file system
-
 Figure 12. URI option B
Figure 12. URI option BThis is the default option that applies if you don’t enable Advanced Options, and was the only option in WD Fusion prior to version 2.6. When selected, you need to use
fusion://for all data that must be replicated over an instance of the Hadoop Compatible File System. If your deployment includes Hadoop applications that are either unable to support the Fusion URI or are not written to the HCFS specification, this option will not work.
| Platforms that must be run with Fusion URI with HCFS: |
|---|
Azure |
LocalFS |
OnTapLocalFs |
UnmanagedBigInsights |
UnmanagedSwift |
UnmanagedGoogle |
UnmanagedS3 |
UnmanagedEMR |
MapR |
- Use Fusion URI with HDFS file system
-
 Figure 13. URI option C
Figure 13. URI option C
This differs from the default in that while the WD Fusion URI is used to identify data to be replicated, the replication is performed using HDFS itself. This option should be used if you are deploying applications that can support the WD Fusion URI but not the Hadoop Compatible File System.
Benefits of HDFS.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments.
The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco’s support team before enabling them.
- Use Fusion URI and HDFS URI with HDFS file system
-
This "mixed mode" supports all the replication schemes (
fusion://, hdfs:// and no scheme) and uses HDFS for the underlying file system, to support applications that aren’t written to the HCFS specification. Figure 14. URI option D
Figure 14. URI option D
Advanced Options
|
Only apply these options if you fully understand what they do.
The following Advanced Options provide a number of low level configuration settings that may be required for installation into certain environments. The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco’s support team before enabling them.
|
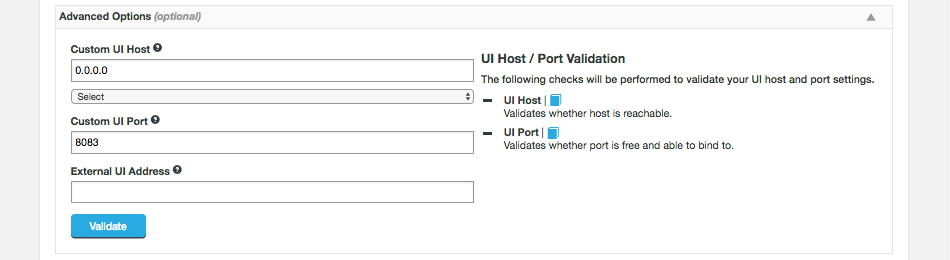
- Custom UI Host
-
Enter your UI host or select it from the drop down below.
- Custom UI Port
-
Enter the port number for the Fusion UI.
- External UI Address
-
The address external processes should use to connect to the UI on.
-
In the lower panel you now need to configure the Cloudera or Ambari manager if relevant to your set up.
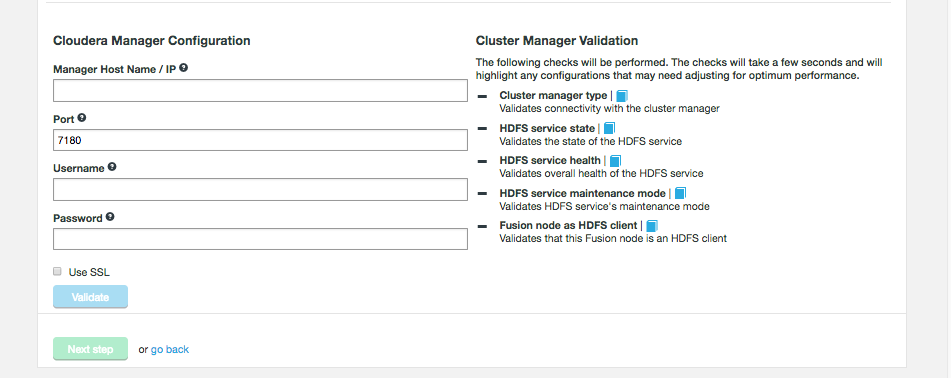 Figure 16. Manager Configuration
Figure 16. Manager Configuration- Manager Host Name /IP
-
The FQDN for the server the manager is running on.
- Port
-
The TCP port the manager is served from. The default is 7180.
- Username
-
The username of the account that runs the manager. This account must have admin privileges on the Management endpoint.
- Password
-
The password that corresponds with the above username.
- SSL
-
Tick the SSL checkbox to use https in your Manager Host Name and Port. You may be prompted to update the port if you enable SSL but don’t update from the default http port.
Once you have entered the information click Validate.
- Cluster manager type
-
Validates connectivity with the cluster manager.
- HDFS service state
-
Validates the state of the HDFS service.
- HDFS service health
-
Validates the overall health of the HDFS service.
- HDFS service health
-
Validates HDFS service’s maintenance mode.
- Fusion node as HDFS client
-
Validates that this Fusion node is a HDFS client.
|
Installing with Isilon
If you install into an Isilon deployment, review the Isilon validation changes.
|
-
Enter the security details applicable to your deployment.
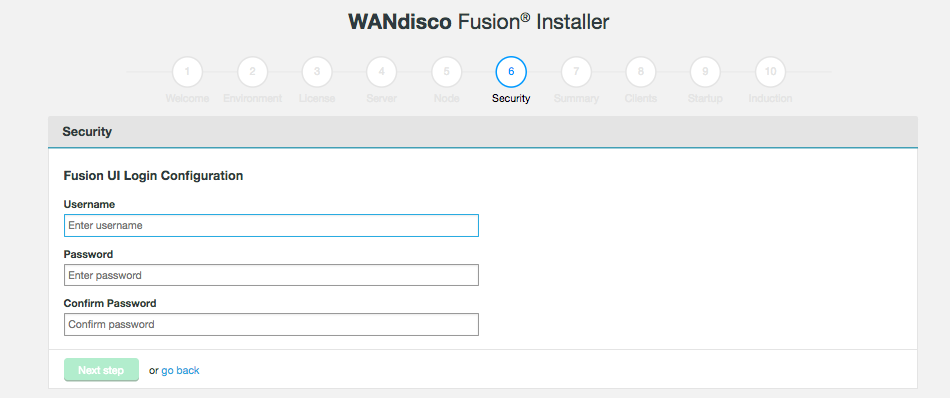 Figure 17. "Security
Figure 17. "Security- Username
-
The username for the controlling account that will be used to access the WD Fusion UI.
- Password
-
The password used to access the WD Fusion UI.
- Confirm Password
-
A verification that you have correctly entered the above password.
-
At this stage of the installation you are provided with a complete summary of all of the entries that you have so far made. Go through the options and check each entry.
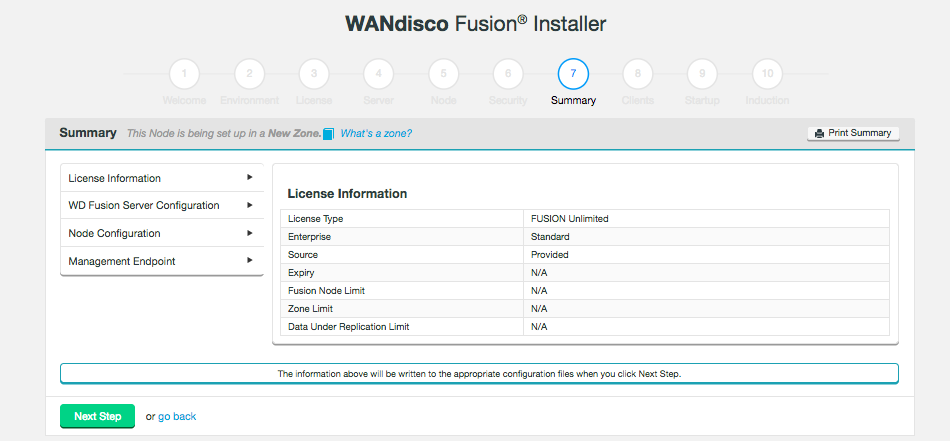 Figure 18. Summary
Figure 18. SummaryOnce you are happy with the settings and all your WD Fusion clients are installed, click Deploy Fusion Server.
-
In the next step you need to place the WD Fusion client parcel on the manager node and distribute to all nodes in the cluster. The WD Fusion client is required to support data WD Fusion’s replication across the Hadoop ecosystem.
Follow the on-screen instructions relevant to your installation, this may involve going to the UI of your manager. Figure 19. Clients
Figure 19. Clients
Ambari Installation
If you are installing onto a platform that is running Ambari (HDP or Pivotal HD), once the clients are installed you should log in to Ambari and restart services that are flagged as waiting for a restart. This will apply to MapReduce and YARN, in particular.
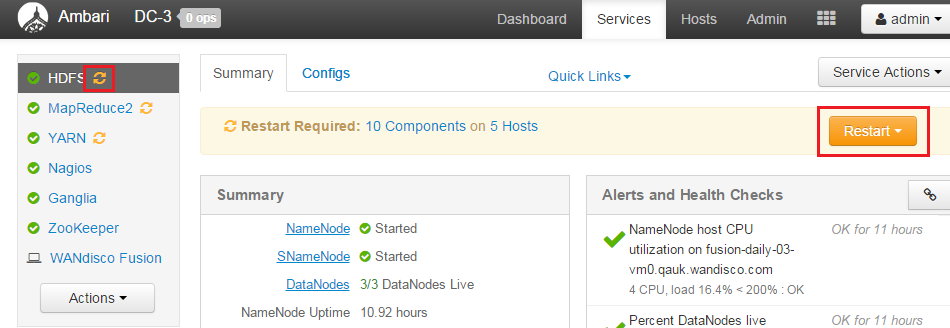
|
Potential failures on restart
In some deployments, particularly running HBase, you may find that you experience failures after restarting. In these situations if possible, leave the failed service down until you have completed the next step where you will restart WD Fusion.
|
If you are running Ambari 1.7, you’ll be prompted to confirm this is done.

Confirm that you have completed the restarts.
|
Important! If you are installing on Ambari 1.7 or CHD 5.3.x
Additionally, due to a bug in Ambari 1.7, and an issue with the classpath in CDH 5.3.x, before you can continue you must log into Ambari/Cloudera Mananger and complete a restart of HDFS, in order to re-apply WD Fusion’s client configuration.
|
-
Configuration is now complete. You may receive a notices or warning messages, for situations such as if your clients have not yet been installed. You can now address any client installations, then click Revalidate Client Install to make the warning go away. Once you have followed the on screen instructions click Start WD Fusion to continue.
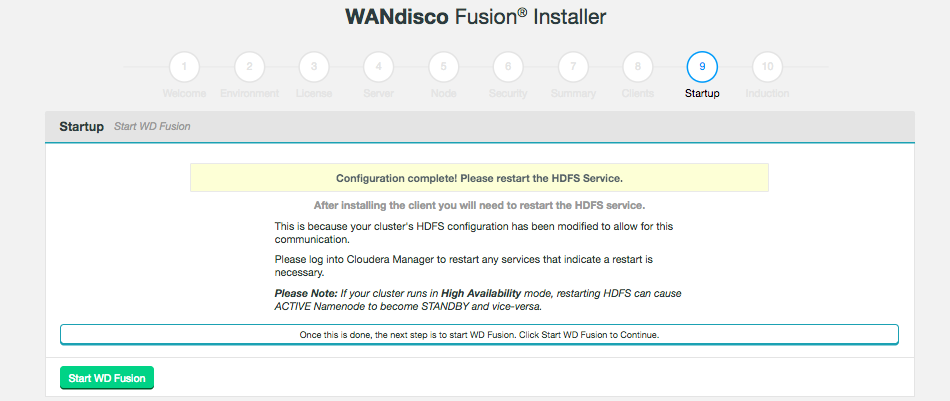 Figure 22. Startup
Figure 22. Startup -
If you have existing nodes you can induct them now. If you would rather induct them later, click Skip Induction.
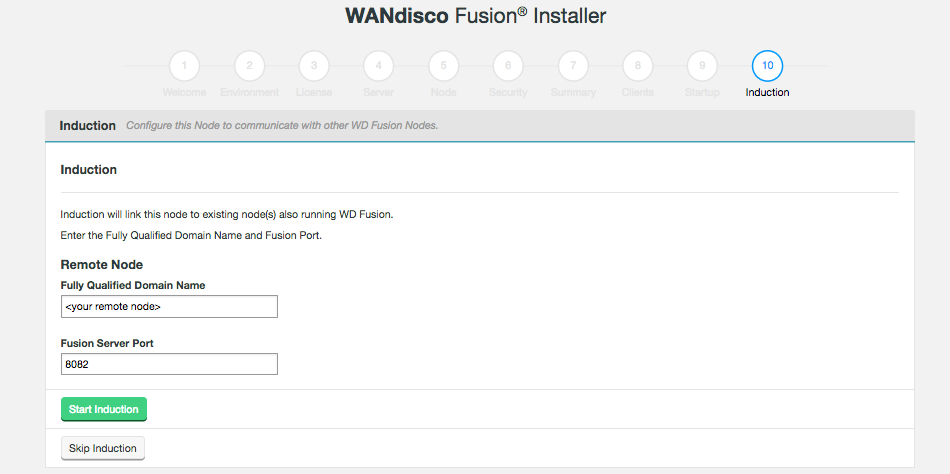 Figure 23. Induction
Figure 23. Induction- Fully Qualified Domain Name
-
The fully qualified domain name of the node that you wish to connect to.
- Fusion Server Port
-
The TCP port used by the remote node that you are connecting to. 8082 is the default port.
|
No induction for the first installed node
When you install the first node, you can’t complete an induction. Instead you will click "Skip Induction".
|
Configuration
Once WD Fusion has been installed on all data centers you can proceed with setting up replication on your HDFS file system. You should plan your requirements ahead of the installation, matching up your replication with your cluster to maximize performance and resilience. The next section will take a brief look at a example configuration and run through the necessary steps for setting up data replication between two data centers.
Setting up Replication
The following steps are used to start replicating HDFS data. The detail of each step will depend on your cluster setup and your specific replication requirements, although the basic steps remain the same.
-
Create a membership including all the data centers that will share a particular directory. See Create Membership.
-
Create and configure a Replicated Folder. See Replicated Folders.
-
Perform a consistency check on your replicated folder. See Consistency Check.
-
Configure your Hadoop applications to use WANdisco’s protocol. See Configure Hadoop for WANdisco replication.
-
Run Tests to validate that your replicated folder remains consistent while data is being written to each data center.
4.2. Silent Installation
The "Silent" installation tools are still under development, although, with a bit of scripting, it should now be possible to automate WD Fusion node installation. The following section looks at the provided tools, in the form of a number of scripts, which automate different parts of the installation process.
|
Client Installations
The silent installer does not handle the deployment of client stacks/parcels. You must be aware of the following:
Stacks/Parcels must be in place before the silent installer is run, this includes restarting/checking for parcels on their respective managers.
Failure to do so will leave the HDFS cluster in a state without fusion clients and running with a config that expects them to be there, this can be fixed by reverting service configs if necessary.
See Installing Parcels and Stacks.
|
4.2.1. Overview
The silent installation process supports two levels: Unattended installation handles just the command line steps of the installation, leaving the web UI-based configuration steps in the hands of an administrator. See unattended installation.
Fully Automated also includes the steps to handle the configuration without the need for user interaction.
4.2.2. Unattended Installation
Use the following command for an unattended installation where an administrator will complete the configuration steps using the browser UI.
sudo FUSIONUI_USER=x FUSIONUI_GROUP=y FUSIONUI_FUSION_BACKEND_CHOICE=z ./fusion-ui-server_rpm_installer.sh
4.2.3. Set the environment
There are a number of properties that need to be set up before the installer can be run:
- FUSIONUI_USER
-
User which will run WD Fusion services. This should match the user who runs the hdfs service.
- FUSIONUI_GROUP
-
Group of the user which will run Fusion services. The specified group must be one that FUSIONUI_USER is in.
|
Check FUSIONUI_USER is in FUSIONUI_GROUP
Verify that your chosen user is in your selected group. > groups hdfs hdfs : hdfs hadoop |
- FUSIONUI_FUSION_BACKEND_CHOICE
-
Should be one of the supported package names, as per the following list, which includes all options, not all will be available on a single installer:
-
cdh-5.2.0:2.5.0-cdh5.2.0
-
cdh-5.3.0:2.5.0-cdh5.3.0
-
cdh-5.4.0:2.6.0-cdh5.4.0
-
cdh-5.5.0:2.6.0-cdh5.5.0
-
cdh-5.6.0:2.6.0-cdh5.6.0
-
cdh-5.8.0:2.6.0-cdh5.8.0
-
cdh-5.9.0:2.6.0-cdh5.9.0
-
cdh-5.10.0:2.6.0-cdh5.10.0
-
cdh-5.11.0:2.6.0-cdh5.11.0
-
emr-5.3.0:2.7.3-amzn-1
-
emr-5.4.0:2.7.3-amzn-1
-
gcs-0.1:2.7.1
-
gcs-0.2:2.7.1
-
hdi-3.4:2.7.1.2.4.2.0-258
-
hdi-3.5:2.7.3.2.5.0.0-1245
-
hdp-2.1.0:2.4.0.2.1.5.0-695
-
hdp-2.2.0:2.6.0.2.2.0.0-2041
-
hdp-2.3.0:2.7.1.2.3.0.0-2557
-
hdp-2.4.0:2.7.1.2.4.0.0-169
-
hdp-2.5.0:2.7.3.2.5.0.0-1245
-
hdp-2.6.0:2.7.3.2.6.0.3-8
-
ibm-4.0:2.6.0
-
ibm-4.1:2.7.1
-
ibm-4.2:2.7.2
-
ibm-3.0:2.2.0
-
localfs-2.7.0:2.7.0
-
mapr-5.2.0:2.7.0-mapr-1607
-
(ontap) asf-2.5.0:2.5.0
-
phd-3.0.0:2.6.0.3.0.0.0-249
-
(s3) asf-2.5.0:2.5.0
-
(swt) asf-2.5.0:2.5.0
-
|
(ontap)/(s3)/(swt)
Each of these version use the same package "asf-2.5.0:2.5.0".
|
This mode only automates the initial command line installation step, the configuration steps still need to be handled manually in the browser steps.
4.2.4. Fully Automated Installation
This mode is closer to a full "Silent" installation as it handles the configuration steps as well as the installation.
Properties that need to be set:
- SILENT_CONFIG_PATH
-
Path for the environmental variables used in the command-line driven part of the installation. The paths are added to a file called silent_installer_env.sh.
- SILENT_PROPERTIES_PATH
-
Path to 'silent_installer.properties' file. This is a file that will be parsed during the installation, providing all the remaining parameters that are required for getting set up. The template is annotated with information to guide you through making the changes that you’ll need.
Take note that parameters stored in this file will automatically override any default settings in the installer. - FUSIONUI_USER
-
User which will run Fusion services. This should match the user who runs the hdfs service.
- FUSIONUI_GROUP
-
Group of the user which will run Fusion services. The specified group must be one that FUSIONUI_USER is in.
- FUSIONUI_FUSION_BACKEND_CHOICE
-
Should be one of the supported package names, as per the following list:
- FUSIONUI_UI_HOSTNAME
-
The hostname for the WD Fusion server.
- FUSIONUI_UI_PORT
-
Specify a fusion-ui-server port (default is 8083)
- FUSIONUI_TARGET_HOSTNAME
-
The hostname or IP of the machine hosting the WD Fusion server.
- FUSIONUI_TARGET_PORT
-
The fusion-server port (default is 8082)
- FUSIONUI_MEM_LOW
-
Starting Java Heap value for the WD Fusion server.
- FUSIONUI_MEM_HIGH
-
Maximum Java Heap.
- FUSIONUI_UMASK
-
Sets the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
- FUSIONUI_INIT
-
Sets whether the server will start automatically when the system boots. Set as "1" for yes or "0" for no
Cluster Manager Variables are deprecated
The cluster manager variables are mostly redundant as they generally get set in different processes though they currently remain in the installer code.
FUSIONUI_MANAGER_TYPE FUSIONUI_MANAGER_HOSTNAME FUSIONUI_MANAGER_PORT
- FUSIONUI_MANAGER_TYPE
-
"AMBARI", "CLOUDERA", "MAPR" or "UNMANAGED_EMR" and "UNMANAGED_BIGINSIGHTS" for IBM deployments. This setting can still be used but it is generally set at a different point in the installation now.
- validation.environment.checks.enabled
-
Permits the validation checks for environmental
- validation.manager.checks.enabled
-
Note manager validation is currently not available for S3 installs
- validation.kerberos.checks.enabled
-
Note kerberos validation is currently not available for S3 installs
If this part of the installation fails it is possible to re-run the silent_installer part of the installation by running:
/opt/wandisco/fusion-ui-server/scripts/silent_installer_full_install.sh /path/to/silent_installer.properties
4.2.5. Uninstall WD Fusion UI only
This procedure is useful for UI-only installations:
sudo yum erase -y fusion-ui-server sudo rm -rf /opt/wandisco/fusion-ui-server /etc/wandisco/fusion/ui
4.2.6. To UNINSTALL Fusion UI, Fusion Server and Fusion IHC Server (leaving any fusion clients installed):
See the Uninstall Script Usage Section for information on removing Fusion.
4.2.7. Silent Installation files
For every package of WD Fusion there’s both an env.sh and a .properties file. The env.sh sets environment variables that complete the initial command step of an installation. The env.sh also points to a properties file that is used to automate the browser-based portion of the installer. The properties files for the different installation types are provided below:
- silent_installer.properties
-
standard HDFS installation.
- s3_silent_installer.properties
-
properties file for Amazon S3-based installation.
- swift_silent_installer.properties
-
file for Swift-based installation.
4.3. Manual installation
The following procedures covers the hands-on approach to installation and basic setup of a deployment that deploys over the LocalFileSystem. For the vast majority of cases you should use the previous Installer-based LocalFileSystem Deployment procedure.
|
Don’t do it this way unless you have to.
We provide this example to illustrate how a completely hands-on installation can be performed. We don’t recommend that you use it for a deployment unless you absolutely can’t use the installers. Instead, use it as a reference so that you can see what changes are made by our installer.
|
4.3.1. Non-HA Local filesystem setup
-
Start with the regular WD Fusion setup. You can go through either the installation manually or using the installer.
-
When you select the $user:$group you should pick a master user account that will have complete access to the local directory that you plan to replicate. You can set this manually by modifying etc/wandisco/fusion-env.sh setting FUSION_SERVER_GROUP to
$groupand FUSION_SERVER_USER to$user. -
Next, you’ll need to configure the core-site.xml, typically in /etc/hadoop/conf/, and override “fs.file.impl” to “com.wandisco.fs.client.FusionLocalFs”, “fs.defaultFS” to "file:///", and "fusion.underlyingFs" to "file:///". (Make sure to add the usual Fusion properties as well, such as "fusion.server").
-
If you are running with fusion URI, (via “fs.fusion.impl”), then you should still set the value to “com.wandisco.fs.client.FusionLocalFs”.
-
If you are running with Kerberos then you should also override “fusion.handshakeToken.dir” to point to some directory that will exist within the local directory you plan to replicate to/from. You should also make sure to have “fs.fusion.keytab” and “fs.fusion.principal” defined as usual.
-
Ensure that the local directory you plan to replicate to/from alreadly exists. If not, create it and give it 777 permissions or create a symlink (locally) that will point to the local path you plan to replicate to/from.
-
For example, if you want to replicate /repl1/ but don’t want to create a directory on your root level, you can create a symlink to repl1 on your root level and point it to wherever you want to actually be your replicated directory. In the case of using NFS, it should be used to point to /mnt/nfs/.
-
Set-up an NFS.
Be sure to point your replicated directory to your NFS mount, either directly or using a a symlink.
4.3.2. HA local file system setup
-
Install Fusion UI, Server, IHC, and Client (for LocalFileSystem) on every node you plan to use for HA.
-
When you select the
$user:$groupyou should pick a master user account that will have complete access to the local directory that you plan to replicate. You can set this manually by modifying /etc/wandisco/fusion-env.sh setting FUSION_SERVER_GROUP to$groupand FUSION_SERVER_USER to$user. -
Next, you’ll need to configure the core-site.xml, typically in /etc/hadoop/conf/, and override “fs.file.impl” to “com.wandisco.fs.client.FusionLocalFs”, “fs.defaultFS” to "file:///", and “fusion.underlyingFs” to "file:///". (Make sure to add the usual Fusion properties as well, such as "fs.fusion.server").
-
If you are running with fusion URI, (via “fs.fusion.impl”), then you should still set the value to “com.wandisco.fs.client.FusionLocalFs”.
-
If you are running with Kerberos then you should also override “fusion.handshakeToken.dir” to point to some directory that will exist within the local directory you plan to replicate to/from. You should also make sure to have “fs.fusion.keytab” and “fs.fusion.principal” defined as usual.
-
Ensure that the local directory you plan to replicate to/from alreadly exists. If not, create it and give it 777 permissions or create a symlink (locally) that will point to the local path you plan to replicate to/from.
-
For ex, if you want to replicate /repl1/ but don’t want to create a directory on your root level, you can create a symlink to repl1 on your root level and point it to wherever you want to actually be your replicated directory. In the case of using NFS, it should be used to point to /mnt/nfs/.
-
Now follow a regular HA set up, making sure that you copy over the core-site.xml and fusion-env.sh everywhere so all HA nodes have the same configuration.
-
Create the replicated directory (or symlink to it) on every HA node and chmod it to 777.
5. Working in the Hadoop ecosystem
The deployment section covers the final step in setting up a WD Fusion cluster, where supported Hadoop applications are plugged into WD Fusion’s synchronized distributed namespace. It won’t be possible to cover all the requirements for all the third-party software covered here, we strongly recommend that you get hold of the corresponding documentation for each Hadoop application before you work through these procedures.
Deployed Hadoop applications
5.1. Hive
This guide integrates WD Fusion with Apache Hive, it aims to accomplish the following goals:
-
Replicate Hive table storage.
-
Use fusion URIs as store paths.
-
Use fusion URIs as load paths.
-
Share the Hive metastore between two clusters.
5.1.1. Prerequisites
-
Knowledge of Hive architecture.
-
Ability to modify Hadoop site configuration.
-
WD Fusion installed and operating.
5.1.2. Replicating Hive Storage via fusion:///
The following requirements come into play if you have deployed WD Fusion using with its native fusion:/// URI.
In order to store a Hive table in WD Fusion you specify a WD Fusion URI when creating a table. E.g. consider creating a table called log that will be stored in a replicated directory.
CREATE TABLE log(requestline string) stored as textfile location 'fusion:///repl1/hive/log'; Note: Replicating table storage without sharing the Hive metadata will create a logical discrepancy in the Hive catalog. For example, consider a case where a table is defined on one cluster and replicated on the HCFS to another cluster. A Hive user on the other cluster would need to define the table locally in order to make use of it.
5.1.3. Exceptions
Hive from CDH 5.3/5.4 does not work with WD Fusion, (because of HIVE-9991). To get it working with CDH 5.3 and 5.4. you need to modify the default Hive file system setting. In Cloudera Manager, add the following property to hive-site.xml:
<property>
<name>fs.defaultFS</name>
<value>fusion:///</value>
</property>
This property should be added in 3 areas:
-
Service Wide
-
GateWay Group
-
Hiveserver2 group
5.1.4. Replicated directories as store paths
It’s possible to configure Hive to use WD Fusion URIs as output paths for storing data, to do this you must specify a Fusion URI when writing data back to the underlying Hadoop-compatible file system (HCFS). For example, consider writing data out from a table called log to a file stored in a replicated directory:
INSERT OVERWRITE DIRECTORY 'fusion:///repl1/hive-out.csv' SELECT * FROM log;
5.1.5. Replicated directories as load paths
In this section we’ll describe how to configure Hive to use fusion URIs as input paths for loading data.
It is not common to load data into a Hive table from a file using the fusion URI. When loading data into Hive from files the core-site.xml setting fs.default.name must also be set to fusion, which may not be desirable. It is much more common to load data from a local file using the LOCAL keyword:
LOAD DATA LOCAL INPATH '/tmp/log.csv' INTO TABLE log;
If you do wish to use a fusion URI as a load path, you must change the fs.defaultFS setting to use WD Fusion, as noted in a previous section. Then you may run:
LOAD DATA INPATH 'fusion:///repl1/log.csv' INTO TABLE log;
5.1.6. Sharing the Hive metastore
Advanced configuration - please contact WANdisco before attempting
In this section we’ll describe how to share the Hive metastore between two clusters. Since WANdisco Fusion can replicate the file system that contains the Hive data storage, sharing the metadata presents a single logical view of Hive to users on both clusters.
When sharing the Hive metastore, note that Hive users on all clusters will know about all tables. If a table is not actually replicated, Hive users on other clusters will experience errors if they try to access that table.
There are two options available.
5.1.7. Hive metastore available read-only on other clusters
In this configuration, the Hive metastore is configured normally on one cluster. On other clusters, the metastore process points to a read-only copy of the metastore database. MySQL can be used in master-slave replication mode to provide the metastore.
5.1.8. Hive metastore writable on all clusters
In this configuration, the Hive metastore is writable on all clusters.
-
Configure the Hive metastore to support high availability.
-
Place the standby Hive metastore in the second data center.
-
Configure both Hive services to use the active Hive metastore.
|
Performance over WAN
Performance of Hive metastore updates may suffer if the writes are routed over the WAN.
Hive metastore replication
There are three strategies for replicating Hive metastore data with WD Fusion:
|
Standard
For Cloudera CDH: See Hive Metastore High Availability.
For Hortonworks/Ambari: High Availability for Hive Metastore.
Manual Replication
In order to manually replicate metastore data ensure that the DDLs are placed on two clusters, and perform a partitions rescan.
5.2. Impala
5.2.1. Prerequisites
-
Knowledge of Impala architecture.
-
Ability to modify Hadoop site configuration.
-
WD Fusion installed and operating.
5.2.2. Impala Parcel
If you plan to use WD Fusion’s own fusion:/// URI, then you will need to use the provided parcel (see the screenshot, below for link in the Client Download section of the Settings screen):
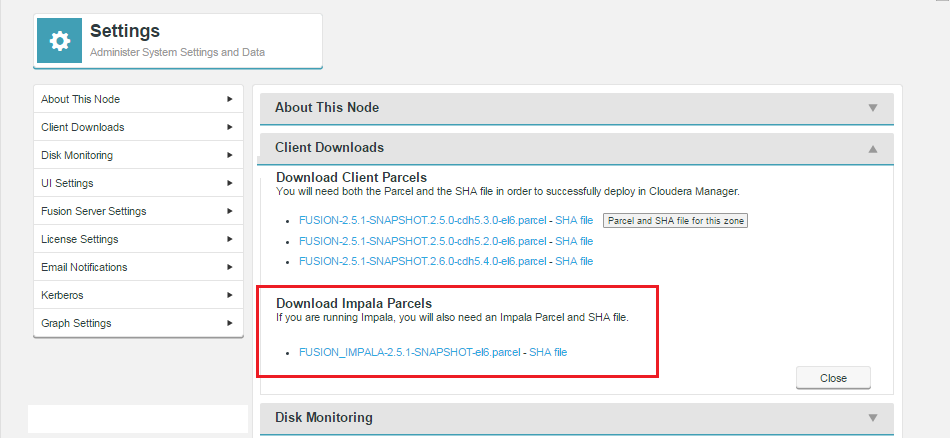
Follow the same steps described for installing the WD Fusion client, downloading the parcel and SHA file, i.e.:
-
Have cluster with CDH installed with parcels and Impala.
-
Copy the
FUSION_IMPALAparcel and SHA into the local parcels repository, on the same node where Cloudera Manager Services is installed, this need not be the same location where the Cloudera Manager Server is installed. The default location is at: /opt/cloudera/parcel-repo, but is configurable. In Cloudera Manager, you can go to the Parcels Management Page → Edit Settings to find the Local Parcel Repository Path. See Parcel Locations.FUSION_IMPALA should be available to distribute and activate on the Parcels Management Page, remember to click Check for New Parcels button.
-
Once installed, restart the cluster.
-
Impala reads on Fusion files should now be available.
5.2.3. Setting the CLASSPATH
In order for Impala to load the Fusion Client jars, the user needs to make a small configuration change in their Impala service, through Cloudera Manager. In Cloudera Manager, the user needs to add an environment variable in the section Impala Service Environment Advanced Configuration Snippet (Safety Valve).
AUX_CLASSPATH='colon-delimited list of all the Fusion client jars'
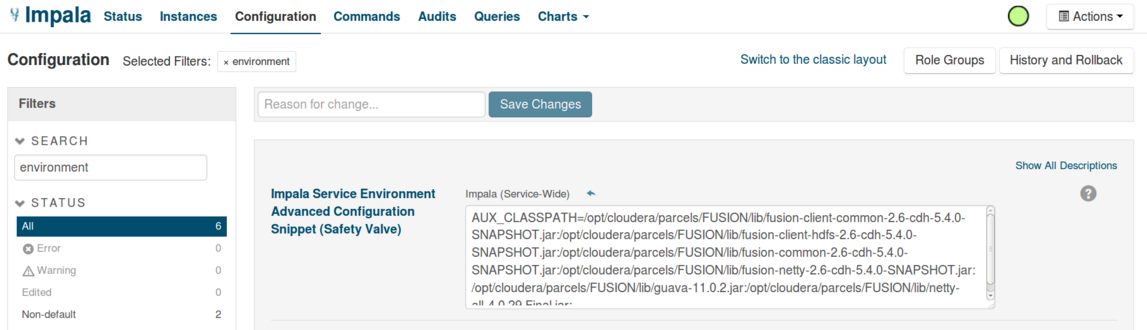
5.3. Presto
5.3.1. Presto Interoperability
Presto is an open source distributed SQL query engine for running interactive analytic queries. It can query and interact with multiple data sources, and can be extended with plugins.
Presto requires the use of Java 8 and has internal dependencies on Java library versions that may conflict with those of the Hadoop distribution with which it communicates when using the “hive-hadoop2” plugin. For example, Presto makes use of guava-18.0.jar, while HDP 2.4 uses guava-11.0.2.jar.
5.3.2. Presto and Fusion
WANdisco Fusion leverages a replacement client library when overriding the hdfs:// scheme for access to the cluster file system in order to coordinate that access among multiple clusters. This replacement library is provided in a collection of jar files in the /opt/wandisco/fusion/client/lib directory for a standard installation. These jar files need to be available to any process that accesses the file system using the com.wandisco.fs.client.FusionHdfs implementation of the Apache Hadoop FileSystem API.
Because Presto requires these classes to be available to the hive-hadoop2 plugin, they must reside in the plugin/hive-hadoop2 directory of the Presto installation. Additionally, the additional JARs made available in that directory must not provide conflicting versions of classes already used by the hive-hadoop2 plugin.
As Fusion uses conflicting versions of some classes (e.g. guava), the Fusion client library used by Presto must be repackaged to avoid such conflicts.
5.3.3. Repackaging the Fusion Client Library
WANdisco have provided a repackaged version of the Fusion 2.10 client libraries to help demonstrate Fusion-Presto interoperability. Please take note that this is an early access release of the client library that is specifically for Presto DB deployment.
The repackaged client library consists of several JAR files:
bcprov-jdk15on-1.54.jar fusion-adk-netty-2.10.jar fusion-client-hdfs-2.10-hdp-2.4.0.jar wd-netty-all-4.0.37.Final.jar fusion-adk-client-2.10-hdp-2.4.0.jar fusion-adk-security-2.10.jar fusion-common-2.10-hdp-2.4.0.jar fusion-adk-common-2.10.jar fusion-client-common-2.10-hdp-2.4.0.jar wd-guava-15.0.jar
The three 3rd-party JARs have had their classes repackaged under "shadow" package names in order that they do not conflict with the alternative versions used by Presto. Additionally, the WANdisco Fusion client library has been adjusted to use those versions of the classes under their alternative package names.
WANdisco has made this repackaged client library available for customers on fd.wandisco.com.
5.3.4. Using the Repackaged Fusion Client Library with Presto
-
Copy the JAR files in the plugin/hive-hadoop2 directory of each Presto server.
-
Restart the Presto coordinators.
It is also important to confirm that the Presto configuration includes the necessary properties to function correctly with the hive-hadoop2 plugin.
The specific values below will need to be adjusted for the actual environment, including references to the WANdisco replicated metastore, the HDP cluster configuration that includes Fusion configuration, and Kerberos-specific information to allow Presto to interoperate with a secured cluster.
connector.name=hive-hadoop2 hive.metastore.uri=thrift://presto02-vm1.test.server.com:9084 hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml hive.metastore.authentication.type=KERBEROS hive.metastore.service.principal=hive/presto02-vm1.test.server.com@WANDISCO.HADOOP hive.metastore.client.principal=presto/presto02-vm0.test.server.com@WANDISCO.HADOOP hive.metastore.client.keytab=/etc/security/keytabs/presto.keytab hive.hdfs.authentication.type=KERBEROS hive.hdfs.impersonation.enabled=true hive.hdfs.presto.principal=hdfs-presto2@WANDISCO.HADOOP hive.hdfs.presto.keytab=/etc/security/keytabs/hdfs.headless.keytab
Keytabs and principals will need to be configured correctly, and as the hive-hadoop2 Presto plugin uses YARN for operation, the /user/yarn directory must exist and be writable by the yarn user in all clusters in which Fusion operates.
5.3.5. Known Issue
Presto embeds Hadoop configuration defaults into the hive-hadoop2 plugin, including a core-default.xml file that specifies the following property entry:
<property> <name>hadoop.security.authentication</name> <value>simple</value> <description>Possible values are simple (no authentication), and kerberos </description> </property>
Although Presto allows the hive-hadoop2 plugin to use additional configuration properties by adding entries like the following in a .properties file in the etc/catalog directory:
hive.config.resources=/etc/hadoop/conf/core-site.xml,/etc/hadoop/conf/hdfs-site.xml
This entry allows extra configuration properties to be loaded from a standard Hadoop configuration file, but those entries cannot override settings that are embedded in the core-default.xml that ships with the Presto hive-hadoop2 plugin.
In a kerberized implementation the Fusion client library relies on the ability to read the hadoop.security.authentication configuration property to determine if it should perform a secure handshake with the Fusion server. Without that property defined, the client and server will fail to perform their security handshake, and Presto queries will not succeed.
5.3.6. Workaround
The solution to this issue is to update the core-default.xml file contained in the hive-hadoop2 plugin:
$ mkdir ~/tmp $ cd ~/tmp $ jar -xvf <path to…>/presto-server-0.164/plugin/hive-hadoop2/hadoop-apache2-0.10.jar
Edit the core-default.xml file to update the hadoop.security.authentication property so that its value is “kerberos”
$ Jar -uf <path to...>/presto-server-0.164/plugin/hive-hadoop2/hadoop-apache2-0.10.jar core-default.xml
Distribute the hadoop-apache2-0.10.jar to all Presto nodes, and restart the Presto coordinator.
5.4. Oozie
The Oozie service can function with Fusion, running without problem with Cloudera CDH. Under Hortonworks HDP you need to apply the following procedure, after completing the WD Fusion installation:
-
Open a terminal to the node with root privileges.
-
If Fusion was previously installed and has now been removed, check that any dead symlinks have been removed.
cd /usr/hdp/current/oozie-server/libext ls -l rm [broken symlinks]
-
Create the symlinks for fusion client jars.
ln -s /opt/wandisco/fusion.client/lib/* /usr/hdp/current/oozie-server/libext
-
In Ambari, stop the Oozie Server service.
-
Open a terminal session as user oozie and run:
/usr/hdp/current/oozie-server/bin/oozie-setup.sh prepare-war
-
In Ambari, start the Oozie Server service.
It is worth noting that as of Fusion 2.10, the new symlinks get created, but if previous symlinks have not been manually removed first, the war packaging which happens when oozie server is started will fail, causing the oozie server startup to fail.
You need to ensure old symlinks in
/usr/hdp/current/oozie-server/libextare removed before we install the new client stack.
5.4.1. Oozie installation changes
(WD Fusion2.10. onwards)
Something to be aware of in Hyper Scale-Out Platform (HSP) installations - when you install the client stack, the fusion-client RPM creates symlinks in /usr/hdp/current/oozie-server/libext for the client jars. However, these get left behind if the client stack/RPM are removed.
If a new version of fusion-client is installed, Oozie server will refuse to start because of the broken symlinks.
A change in behavior
Installing clients via RPM/Deb packages no longer automatically stop and repackage Oozie. If Oozie was running prior to the client installation, you will need to manually stop Oozie, then Oozie setup command -
oozie-setup.sh prepare-war
If possible, complete these actions through Ambari.
If Oozie is installed after WD Fusion
In this case, the symlinks necessary for the jar archive files will not have been created. Under Ambari, using the "Refresh configs" service action on the WANdisco Fusion service should trigger re-linking and the prepare-war process.
If not installed directly via RPM/Deb packages, you should use the manual process for reinstalling the package, followed by the same steps noted above to stop and restart Oozie, using the setup script.
5.5. Oracle: Big Data Appliance
Each node in an Oracle:BDA deployment has multiple network interfaces, with at least one used for intra-rack communications and one used for external communications. WD Fusion requires external communications so configuration using the public IP address is required instead of using host names.
5.5.1. Prerequisites
-
Knowledge of Oracle:BDA architecture and configuration.
-
Ability to modify Hadoop site configuration.
5.5.2. Required steps
-
Configure WD Fusion to support Kerberos. See Setting up Kerberos
-
Configure WD Fusion to work with NameNode High Availability described in Oracle’s documentation
-
Restart the cluster, WD Fusion and IHC processes. See init.d management script
-
Test that replication between zones is working.
5.5.3. Operating in a multi-homed environment
Oracle:BDA is built on top of Cloudera’s Hadoop and requires some extra steps to support multi-homed network environment.
5.5.4. Running Fusion with Oracle BDA 4.2 / CDH 5.5.1
There’s a known issue concerning configuration and the Cloudera Navigator Metadata Server classpath.
Error message:
2016-04-19 08:50:31,434 ERROR com.cloudera.nav.hdfs.extractor.HdfsExtractorShim [CDHExecutor-0-CDHUrlClassLoader@3bd4729d]: Internal Error while extracting
java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.wandisco.fs.client.FusionHdfs not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2199)
There’s no clear way to override the fs.hdfs.impl setting just for the Navigator Metadata server, as is required for running with WD Fusion.
5.5.5. Fix Script
Use the following fix script to overcome the problem:
CLIENT_JARS=$(for i in $(ls -1 /opt/cloudera/parcels/CDH/lib/hadoop/client/*.jar | grep -v jsr305 | awk '{print $NF}' ) ; do echo -n $i: ; done)
NAVIGATOR_EXTRA_CLASSPATH=/opt/wandisco/fusion/client/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop/lib/jetty-*.jar:$CLIENT_JARS
echo "NAVIGATOR_EXTRA_CLASSPATH=$NAVIGATOR_EXTRA_CLASSPATH" > ~/navigator_env.txt
The environment variables are provided here - navigator_env.txt
You need to put this in the configuration for the Cloudera Management Service under "Navigator Metadata Server Environment Advanced Configuration Snippet (Safety Valve)". This modification needs to be done any time the Cloudera version is changed (upgrade or downgrade).
5.6. Apache Tez
Apache Tez is a YARN application framework that supports high performance data processing through DAGs. When set up, Tez uses its own tez.tar.gz containing the dependencies and libraries that it needs to run DAGs. For a DAG to access WD Fusion’s fusion:/// URI it needs our client jars:
Configure the tez.lib.uris property with the path to the WD Fusion client jar files.
<property>
<name>tez.lib.uris</name>
# Location of the Tez jars and their dependencies.
# Tez applications download required jar files from this location, so it should be public accessible.
<value>${fs.default.name}/apps/tez/,${fs.default.name}/apps/tez/lib/</value>
</property>
5.6.1. Tez with Hive
In order to make Hive with Tez work, you need to append the Fusion jar files in tez.cluster.additional.classpath.prefix under the Advanced tez-site section:
tez.cluster.additional.classpath.prefix = /opt/wandisco/fusion/client/lib/*
e.g. WD Fusion tree

Running Hortonworks Data Platform, the tez.lib.uris parameter defaults to /hdp/apps/${hdp.version}/tez/tez.tar.gz. So, to add Fusion libs, there are two choices:
Option 1: Delete the above value, and instead have a list including the path where the above gz unpacks to, and the path where Fusion libs are. or Option 2: Unpack the above gz, repack with WD Fusion libs and re-upload to HDFS. Note that both changes are vulnerable to a platform (HDP) upgrade.
5.6.2. Tez / Hive2 with LLAP
We have tested Hive2 with LLAP Low Latency Analytical Processing, using Apache Slider to run Tez Application Masters on YARN. Inevitably, running a Tez query through this interface results in a FusionHDFS class not found.
The following steps show an example remedy, through the bundling of the client jars into the tez.lib.uris tar.gz.
|
Verified on HDP 2.6.2
The following example is tested on HDP 2.6.2. The procedure may alter on different platforms.
|
-
First, extract existing Tez library to a local folder.
# mkdir /tmp/tezdir # cd /tmp/tezdir # cp /usr/hdp/2.6*/tez_hive2/lib/tez.tar.gz . # tar xvzf tez.tar.gz
-
Add the Fusion client jars to the same extracted location.
# cp /opt/wandisco/fusion/client/lib/* .
-
Re-package the Tez library including the Fusion jars.
# tar cvzf tez.tar.gz *
-
Upload the enlarged Tez library to HDFS (taking a backup of original).
# hdfs dfs -cp /hdp/apps/tez_hive2/tez.tar.gz /user/<username>/tez.tar.gz.pre-WANdisco # hdfs dfs -put tez.tar.gz /hdp/apps/tez_hive2/
-
Restart LLAP service through Ambari.
5.7. Apache Ranger
Apache Ranger is another centralized security console for Hadoop clusters, a preferred solution for Hortonworks HDP (whereas Cloudera prefers Apache Sentry). While Apache Sentry stores its policy file in HDFS, Ranger uses its own local MySQL database, which introduces concerns over non-replicated security policies.
Ranger also applies its policies to the ecosystem via java plugins into the ecosystem components - the namenode, hiveserver etc. In testing, the WD Fusion client has not experienced any problems communicating with Apache Ranger-enabled platforms (Ranger+HDFS).
Ensure that the Hadoop system user, typically HDFS, has permission to impersonate other users.
<property> <name>hadoop.proxyuser.hdfs.users</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.hdfs.groups</name> <value>*</value> </property>
5.8. Solr
Apache Solr is a scalable search engine that can be used with HDFS. In this section we cover what you need to do for Solr to work with a WD Fusion deployment.
5.8.1. Minimal deployment using the default hdfs:// URI
Getting set up with the default URI is simple, Solr just needs to be able to find the fusion client jar files that contain the FusionHdfs class.
-
Copy the Fusion/Netty jars into the classpath. Please follow these steps on all deployed Solr servers. For CDH5.4 with parcels, use these two commands:
cp /opt/cloudera/parcels/FUSION/lib/fusion* /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib cp /opt/cloudera/parcels/FUSION/lib/netty-all-*.Final.jar /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib
-
Restart all Solr Servers.
-
Solr is now successfully configured to work with WD Fusion.
5.8.2. Minimal deployment using the WANdisco "fusion://" URI
This is a minimal working solution with Solr on top of fusion.
Requirements
Solr will use a shared replicated directory.
-
Symlink the WD Fusion jars into Solr webapp.
cd /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib ln -s /opt/cloudera/parcels/FUSION/lib/fusion* . ln -s /opt/cloudera/parcels/FUSION/lib/netty-all-4* . ln -s /opt/cloudera/parcels/FUSION/lib/bcprov-jdk15on-1.52 .
-
Restart Solr.
-
Create instance configuration.
$ solrctl instancedir --generate conf1
-
Edit conf1/conf/solrconfig.xml and replace
solr.hdfs.homein directoryFactory definition with actual fusion:/// uri, like fusion:///repl1/solr -
Create solr directory and set solr:solr permissions on it.
$ sudo -u hdfs hdfs dfs -mkdir fusion:///repl1/solr $ sudo -u hdfs hdfs dfs -chown solr:solr fusion:///repl1/solr
-
Upload configuration to zk.
vvvvvvv$ solrctl instancedir --create conf1 conf1
-
Create collection on first cluster.
$ solrctl collection --create col1 -c conf1 -s 3
|
Tip
For cloudera fusion.impl.disable.cache = true should be set for Solr servers. (don’t set this options cluster-wide, that will stall the WD Fusion server with an unbounded number of client connections).
|
5.9. Flume
This set of instructions will set up Flume to ingest data via the fusion:///` URI.
Edit the configuration, set "agent.sources.flumeSource.command" to the path of the source data.
Set “agent.sinks.flumeHDFS.hdfs.path” to the replicated directory of one of the DCs. Make sure it begins with fusion:/// to push the files to Fusion and not hdfs.
5.9.1. Prerequisites
-
Create a user in both the clusters
'useradd -G hadoop <username>' -
Create user directory in hadoop fs
'hadoop fs -mkdir /user/<username>' -
Create replication directory in both DC’s
'hadoop fs -mkdir /fus-repl' -
Set permission to replication directory
'hadoop fs -chown username:hadoop /fus-repl' -
Install and configure WD Fusion.
5.9.2. Setting up Flume through Cloudera Manager
If you want to set up Flume through Cloudera Manager follow these steps:
-
Download the client in the form of a parcel and the parcel.sha through the UI.
-
Put the parcel and .sha into /opt/cloudera/parcel-repo on the Cloudera Managed node.
-
Go to the UI on the Cloudera Manager node. On the main page, click the small button that looks like a gift wrapped. box and the FUSION parcel should appear (if it doesn’t, try clicking Check for new parcels and wait a moment).
-
Install, distribute, and activate the parcel.
-
Repeat steps 1-4 for the second zone.
-
Make sure membership and replicated directories are created for sharing between Zones.
-
Go onto Cloudera Manager’s UI on one of the zones and click Add Service.
-
Select the Flume Service. Install the service on any of the nodes.
-
Once installed, go to Flume→Configurations.
-
Set 'System User' to 'hdfs'
-
Set 'Agent Name' to 'agent'
-
Set 'Configuration File' to the contents of the flume.conf configuration.
-
Restart Flume Service.
-
Selected data should now be in Zone1 and replicated in Zone2
-
To check data was replicated, open a terminal onto one of the DCs and become
hdfsuser, e.g.su hdfs, and run.hadoop fs -ls /repl1/flume_out"
-
On both Zones, there should be the same FlumeData file with a long number. This file will contain the contents of the source(s) you chose in your configuration file.
5.10. Spark
It’s possible to deploy WD Fusion with Apache’s high-speed data processing engine. Note that prior to version 2.9.1 you needed to manually add the SPARK_CLASSPATH.
5.10.1. Spark with CDH
There is a known issue where Spark is not picking up hive-site.xml, So that Hadoop configuration is not localised when submitting job in yarn-cluster mode (Fixed in version Spark 1.4).
You need to manually add it in by either:
-
Copy /etc/hive/conf/hive-site.xml into /etc/spark/conf. or
-
Do one of the following, depending on which deployment mode you are running in:
- Client
-
set
HADOOP_CONF_DIRto /etc/hive/conf/ (or the directory where hive-site.xml is located). - Cluster
-
add --files=/etc/hive/conf/hive-site.xml (or the path for hive-site.xml) to the spark-submit script.
-
Deploy configs and restart services.
|
Using the FusionUri
The fusion:/// URI has a known issue where it complains about "Wrong fs". For now Spark is only verified with FusionHdfs going through the hdfs:/// URI.
|
5.10.2. Fusion Spark Interoperability
Spark applications are run on a cluster as independent sets of processes, coordinated by the SparkContext object in the driver program. To run on a cluster, the SparkContext can connect to several types of cluster managers (either Spark’s own standalone cluster manager, Mesos or YARN), which allocate resources across applications. Once connected, Spark acquires executors on nodes in the cluster, which are processes that run computations and store data for your application. Next, it sends your application code (defined by JAR or Python files passed to SparkContext) to the executors. Finally, SparkContext sends tasks to the executors to run.
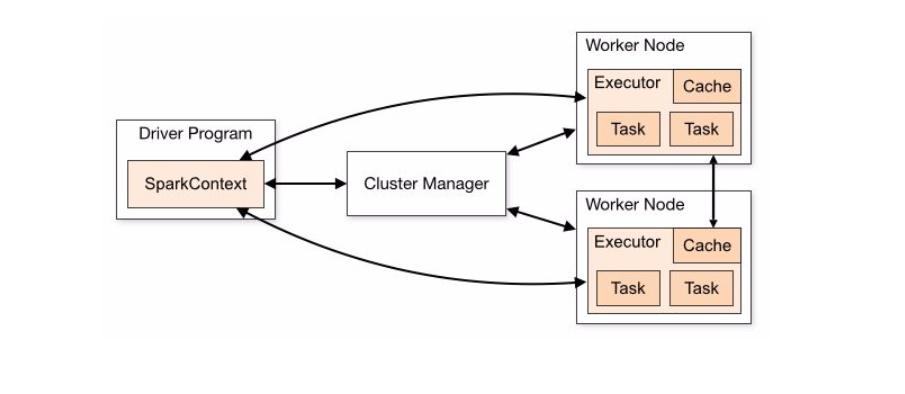
5.10.3. Spark and Fusion
WANdisco Fusion uses a replacement client library when overriding the hdfs:// scheme for access to the cluster file system in order to coordinate that access among multiple clusters. This replacement library is provided in a collection of jar files in the /opt/wandisco/fusion/client/lib directory for a standard installation. These jar files need to be available to any process that accesses the file system using the com.wandisco.fs.client.FusionHdfs implementation of the Apache Hadoop File System API.
Because Spark does not provide a configurable mechanism for making the Fusion classes available to the Spark history server, the Spark Executor or Spark Driver programs, WANdisco Fusion client library classes need to be made available in the existing Spark assembly jar that holds the classes used by these Spark components. This requires updating that assembly jar to incorporate the Fusion client library classes.
5.10.4. Updating the Spark Assembly JAR
This is one of a number of methods that may be employed to provide Fusion-Spark integration. We hope to cover some alternate methods at a later date.
Hortonworks HDP
-
First, make a backup of the original Spark assembly jar:
$ cp /usr/hdp/2.4.2.0-258/spark/lib/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar /usr/hdp/2.4.2.0-258/spark/lib/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar.original
Then follow this process to update the Spark assembly jar.
$ mkdir /tmp/spark_assembly $ cd /tmp/spark_assembly $ jar -xf /opt/wandisco/fusion/client/lib/bcprov-jdk15on-1.54.jar $ jar -xf /opt/wandisco/fusion/client/lib/fusion-adk-client-2.10.4-hdp-2.4.0.jar $ jar -xf /opt/wandisco/fusion/client/lib/fusion-adk-common-2.10.4.jar $ jar -xf /opt/wandisco/fusion/client/lib/fusion-adk-netty-2.10.4.jar $ jar -xf /opt/wandisco/fusion/client/lib/fusion-adk-security-2.10.4.jar $ jar -xf /opt/wandisco/fusion/client/lib/fusion-client-common-2.10.4-hdp-2.4.0.jar $ jar -xf /opt/wandisco/fusion/client/lib/fusion-client-hdfs-2.10.4-hdp-2.4.0.jar $ jar -xf /opt/wandisco/fusion/client/lib/fusion-common-2.10.4-hdp-2.4.0.jar $ jar -xf /opt/wandisco/fusion/client/lib/wd-guava-11.0.2.jar $ jar -xf /opt/wandisco/fusion/client/lib/wd-netty-all-4.0.23.Final.jar jar -uf /usr/hdp/2.4.2.0-258/spark/lib/spark-assembly-1.6.1.2.4.2.0-258-hadoop2.7.1.2.4.2.0-258.jar com/** org/** META-INF/**
-
You now have both the original Spark assembly jar (with the extension “.original”) and a version with the Fusion client libraries available in it. The updated version needs to be made available on each node in the cluster in the /usr/hdp/2.4.2.0-258/spark/lib directory.
-
If you need to revert to the original Spark assembly jar, simply copy it back in place on each node in the cluster.
Cloudera CDH
The procedure for Cloudera CDH is much the same as the one for HDP, provided above. Note that path differences:
-
First, make a backup of the original Spark assembly jar:
$ cp /opt/cloudera/parcels/CDH-5.9.1-1.cdh5.9.1.p0.4/jars/spark-assembly-1.6.0-cdh5.9.1-hadoop2.6.0-cdh5.9.1.jar /opt/cloudera/parcels/CDH-5.9.1-1.cdh5.9.1.p0.4/jars/spark-assembly-1.6.0-cdh5.9.1-hadoop2.6.0-cdh5.9.1.jar.original
Then follow this process to update the Spark assembly jar.
$ mkdir /tmp/spark_assembly $ cd /tmp/spark_assembly jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/bcprov-jdk15on-1.54.jar jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/fusion-adk-client-2.10.4-cdh-5.9.0.jar / jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/fusion-adk-common-2.10.4.jar jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/fusion-adk-security-2.10.4.jar jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/fusion-adk-netty-2.10.4.jar jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/ jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/fusion-common-2.10.4-cdh-5.9.0.jar jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/fusion-client-hdfs-2.10.4-cdh-5.9.0.jar jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/fusion-client-common-2.10.4-cdh-5.9.0.jar jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/wd-guava-15.0.jar jar -xf /opt/cloudera/parcels/FUSION-2.10.4.2.6.0-cdh5.9.0/lib/wd-netty-all-4.0.37.Final.jar jar -uf /opt/cloudera/parcels/CDH-5.9.1-1.cdh5.9.1.p0.4/jars/spark-assembly-1.6.0-cdh5.9.1-hadoop2.6.0-cdh5.9.1.jar com/** org/** META-INF/**
-
You now have both the original Spark assembly jar (with the extension “.original”) and a version with the Fusion client libraries available in it. The updated version needs to be made available on each node in the cluster in the /opt/cloudera/parcels/CDH-5.9.1-1.cdh5.9.1.p0.4/jars/ directory.
-
If you need to revert to the original Spark assembly jar, simply copy it back in place on each node in the cluster.
5.10.5. Spark Assembly Upgrade
The following example covers how you may upgrade the Spark Assembly as part of a Fusion upgrade. This example uses CDH 5.11, although it can be applied generically:
# Create staging path for client and spark assembly
mkdir -p /tmp/spark_assembly/assembly
# Copy existing Spark assembly to work on
cp /opt/cloudera/parcels/CDH/jars/spark-assembly-*.jar /tmp/spark_assembly/assembly/
# Collect file list for purging, sanitise the list as follows
# * List jar files. Do not list symlinks
# * Exclude directory entries which end with a '/'
# * Sort the list
# * Ensure output is unique
# * Store in file
find /opt/cloudera/parcels/FUSION/lib -name '*.jar' -type f -exec jar tf {} \; | grep -Ev '/$' | sort | uniq > /tmp/spark_assembly/old_client_classes.txt
# Purge assembly copy
xargs zip -d /tmp/spark_assembly/assembly/spark-assembly-*.jar < /tmp/spark_assembly/old_client_classes.txt
The resulting spark-assembly is now purged and requires one of two actions:
-
If WD Fusion is being removed, distribute the new assembly to all hosts.
-
If Fusion is being upgraded, retain this jar for the moment and use it within the assembly packaging process for the new client.
5.11. Spark2
Spark 2 comes with significant performance improvements at the cost of incompatibility with Spark (1). The installation of Spark 2 is more straight forward but there is one known issue concerning the need to restart the Spark2 service during a silent installation. Without a restart, configuration changes will not be picked up.
5.12. HBase (Cold Back-up mode)
It’s possible to run HBase in a cold-back-up mode across multiple data centers using WD Fusion, so that in the event of the active HBase node going down, you can bring up the HBase cluster in another data centre, etc. However, there will be unavoidable and considerable inconsistency between the lost node and the awakened replica. The following procedure should make it possible to overcome corruption problems enough to start running HBase again, however, since the damage dealt to underlying filesystem might be arbitrary, it’s impossible to account for all possible corruptions.
5.12.1. Requirements
For HBase to run with WD Fusion, the following directories need to be created and permissioned, as shown below:
platform |
path |
|---|---|
permission |
CDH5.x |
/user/hbase |
hbase:hbase |
HDP2.x |
/hbase
/user/hbase |
|
Known problem: permissions error blocks HBase repair.
Error example: 2016-09-22 17:14:43,617 WARN [main] util.HBaseFsck: Got AccessControlException when preCheckPermission
org.apache.hadoop.security.AccessControlException: Permission denied: action=WRITE path=hdfs://supp16-vm0.supp:8020/apps/hbase/data/.fusion user=hbase
at org.apache.hadoop.hbase.util.FSUtils.checkAccess(FSUtils.java:1685)
at org.apache.hadoop.hbase.util.HBaseFsck.preCheckPermission(HBaseFsck.java:1606)
at org.apache.hadoop.hbase.util.HBaseFsck.exec(HBaseFsck.java:4223)
at org.apache.hadoop.hbase.util.HBaseFsck$HBaseFsckTool.run(HBaseFsck.java:4063)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:70)
at org.apache.hadoop.util.ToolRunner.run(ToolRunner.java:84)
You can configure the root path for all .fusion directories associated with Deterministic State Machines (DSMs). Customizable DSM token directories
These can be set in the respective configurations to change the location of the .fusion directory. It is important to note that the configuration and same path must be added to all fusion servers in all zones if used. |
5.12.2. Procedure
The steps below provide a method of handling a recovery using a cold back-up. Note that multiple HMaster/region servers restarts might be needed for certain steps, since hbck command generally requires master to be up, which may require fixing filesystem-level inconsistencies first.
-
Delete all recovered.edits folder artifacts from possible log splitting for each table/region. This might not be strictly necessary, but could reduce the numbers of errors observed during startup.
hdfs dfs -rm /apps/hbase/data/data/default/TestTable/8fdee4924ac36e3f3fa430a68b403889/recovered.edits
-
Detect and clean up (quarantine) all corrupted HFiles in all tables (including system tables - hbase:meta and hbase:namespace). Sideline option forces hbck to move corrupted HFiles to a special .corrupted folder, which could be examined/cleanup up by admins:
hbase hbck -checkCorruptHFiles -sidelineCorruptHFiles
-
Attempt to rebuild corrupted table descriptors based on filesystem information:
hbase hbck -fixTableOrphans
-
General recovery step - try to fix assignments, possible region overlaps and region holes in HDFS - just in case:
hbase hbck -repair
-
Clean up ZK. This is particularly necessary if hbase:meta or hbase:namespace were messed up (note that exact name of ZK znode is set by cluster admin).
hbase zkcli rmr /hbase-unsecure
Final step to correct metadata-related errors.
hbase hbck -metaonly hbase hbck -fixMeta
5.13. Apache Phoenix
The Phoenix Query Server provides an alternative means for interaction with Phoenix and HBase. When WD Fusion is installed, the Phoenix query server may fail to start. The following workaround will get it running with Fusion.
-
Open up phoenix_utils.py, comment out.
#phoenix_class_path = os.getenv('PHOENIX_LIB_DIR','')and set Wandisco Fusion’s classpath instead (using the client jar file as a colon separated string). e.g.
def setPath(): PHOENIX_CLIENT_JAR_PATTERN = "phoenix-*-client.jar" PHOENIX_THIN_CLIENT_JAR_PATTERN = "phoenix-*-thin-client.jar" PHOENIX_QUERYSERVER_JAR_PATTERN = "phoenix-server-*-runnable.jar" PHOENIX_TESTS_JAR_PATTERN = "phoenix-core-*-tests*.jar" # Backward support old env variable PHOENIX_LIB_DIR replaced by PHOENIX_CLASS_PATH global phoenix_class_path #phoenix_class_path = os.getenv('PHOENIX_LIB_DIR','') phoenix_class_path = "/opt/wandisco/fusion/client/lib/fusion-client-hdfs-2.6.7-hdp-2.3.0.jar:/opt/wandisco/fusion/client/lib/fusion-client-common-2.6.7-hdp-2.3.0.jar:/opt/wandisco/fusion/client/lib/fusion-netty-2.6.7-hdp-2.3.0.jar:/opt/wandisco/fusion/client/lib/netty-all-4.0.23.Final.jar:/opt/wandisco/fusion/client/lib/guava-11.0.2.jar:/opt/wandisco/fusion/client/lib/fusion-common-2.6.7-hdp-2.3.0.jar" if phoenix_class_path == "": phoenix_class_path = os.getenv('PHOENIX_CLASS_PATH','') -
Edit: queryserver.py, change the Java construction command to look like the one below by appending the phoenix_class_path to it within the "else" portion of java_home :
if java_home:
java = os.path.join(java_home, 'bin', 'java')
else:
java = 'java'
# " -Xdebug -Xrunjdwp:transport=dt_socket,address=5005,server=y,suspend=n " + \
# " -XX:+UnlockCommercialFeatures -XX:+FlightRecorder -XX:FlightRecorderOptions=defaultrecording=true,dumponexit=true" + \
java_cmd = '%(java)s -cp ' + hbase_config_path + os.pathsep + phoenix_utils.phoenix_queryserver_jar + os.pathsep + phoenix_utils.phoenix_class_path + \
" -Dproc_phoenixserver" + \
" -Dlog4j.configuration=file:" + os.path.join(phoenix_utils.current_dir, "log4j.properties") + \
" -Dpsql.root.logger=%(root_logger)s" + \
" -Dpsql.log.dir=%(log_dir)s" + \
" -Dpsql.log.file=%(log_file)s" + \
" " + opts + \
5.14. Running with Apache HAWQ
In order to get Hawq to work with fusion HDFS client libs there needs to be an update made to the pxf classpath. This can be done in Ambari through the "Advanced pxf-public-classpath" setting adding an entry to the client lib path:
/opt/wandisco/fusion/client/lib/*
5.15. Apache Slider
Apache Slider is a application to deploy existing distributed applications on an Apache Hadoop YARN cluster, monitor them and make them larger or smaller as desired -even while the application is running.
5.15.1. Issue running service check on slider
Running service check on Slider in Ambari results in a ClassNotFoundException error.
To fix this, add the following line into 'Advanced slider-env.sh' configuration in Ambari:
export SLIDER_CLASSPATH_EXTRA=$SLIDER_CLASSPATH_EXTRA:`for i in /opt/wandisco/fusion/client/lib/*;do echo -n "$i:" ; done`
5.16. KMS / TDE Encryption and Fusion
TDE (Transparent Data Encryption) is available to enhance their data security. TDE uses Hadoop KMS (Key Management Server) and is typically done using Ranger KMS (in Hortonworks / Ambari installs) or Navigator Key Trustee (Cloudera installs).
In simple terms, a security / encryption key or EEK (encrypted encryption key) is used to encrypt the HDFS data that is physical stored to disk. This encryption occurs within the HDFS client, before the data is transported to the datanode.
The key management server (KMS) centrally holds these EEKs in an encrypted format. ACL (access control lists) defines what users/groups are permitted to do with these keys. This includes creating keys, deleting keys, rolling over (re-encrypting the EEK, not changing the EEK itself), obtaining the EEK, listing the key or keys and so on.
Data encrypted in HDFS is split into encrypted zones. This is the act of defining a path (e.g. /data/warehouse/encrypted1) and specifying which EEK is used to to protect this zone (i.e. the key used to encrypt / decrypt the data). A zone is configured with a single key, but different zones can have different keys. Not all of HDFS needs to be encrypted, only the specific zones (and all sub-directories of that zone) an admin defines are.
A user then needs to be granted appropriate ACL access to a get (specifically the "Get Metadata" and "Decrypt EEK" permissions) the EEK needed, to read / write from the zone.
Wandisco Fusion runs as a HDFS user just like any other user. As such, Fusion will need permissions in order to read / write to an encrypted zone.
Fusion may want to write metadata (consistency check, repair and other meta operations), tokens or other items for administrative reasons which may fall under an encrypted zone. Depending on configuration and requirements, repair itself will be writing data thus needs access.
Additionally, KMS provides its own Proxyuser implementation which is separate to the HDFS proxyusers. Although this works in the same, defining who is permitted to impersonate another user whilst working with EEKs.
To add complication. The "hdfs" user is typically blacklisted from performing the "Decrypt EEK" function by default. The fact "hdfs" is a superuser means they wield great power in the cluster. That does not mean they are superuser in KMS. As "hdfs" is commonly the default user of choice to use to fix things in HDFS (given the simple fact it overrides permissions), it seems wise to prevent such authority to access EEKs by default. Note: Cloudera also seems to blacklist the group "supergroup" which is the group defined as the superusergroup. That is, any users added to "supergroup" become superusers, however they then also automatically get blacklisted from being able to perform EEK operations.
5.16.1. Configuring Fusion
To configure Fusion for access to encrypted zones, two aspects need to be considered:
-
The local user that Fusion runs as in HDFS (after kerberos auth_to_local mapping) must be able to access and decrypt EEKs.
-
Although other users will be performing the requests themselves, the Fusion server will proxy that request. As such, a proxyuser within the KMS configs for the Fusion user must also be provided.
5.16.2. Step-by-step guide
The following items need to be considered within KMS configuration to ensure Fusion has access:
The kms-site configuration (such as Advanced kms-site in Ambari) contains its own auth_to_local type parameter called “hadoop.kms.authentication.kerberos.name.rules”
Ensure that any auth_to_local mapping used for the Fusion principal is also contained here. This can be most easily achieved via simple copy/paste from core-site.xml.
The kms-site configuration (such as Custom kms-site in Ambari) contains proxyuser paramaters such as
hadoop.kms.proxyuser.USERNAME.hosts
hadoop.kms.proxyuser.USERNAME.groups
hadoop.kms.proxyuser.USERNAME.usersEntries should be created for the local Fusion user (after auth_to_local translation) to allow Fusion to proxy / impersonate other users requests. This could be as simple as.
hadoop.kms.proxyuser.USERNAME.hosts=fusion.node1.hostname,fusion.node2.hostname
hadoop.kms.proxyuser.USERNAME.groups=*
hadoop.kms.proxyuser.USERNAME.users =*In the dbks-site configuration, the parameter hadoop.kms.blacklist.DECRYPT_EEK exists. Ensure this does not contain the username that Fusion uses (after auth_to_local translation).
In the KMS ACLs, such as using Ranger KMS, ensure that the Fusion user (after auth_to_local translation) has "Get Metadata" and "Decrypt EEK" permissions to keys.
This could be granted access to all keys. This will avoid a need to review rules when new keys are added. However, Fusion will only need these permissions to keys that apply to zones that fall within a replicated path. Consideration is needed here based on the user that Fusion has been configured as - either "HDFS" will need access to EEKs, OR the fusion user will need access, OR the supergroup could be given access to EEKs (it is enabled by default on Ambari but disabled on CDH), and then make the Fusion user a member of the supergroup.
5.16.3. Troubleshooting
If you do not perform the correct configuration, both local operations (as performed by a client) and / or the replicated actions may fail when the Fusion client is invoked. This should only apply to replicated paths.
So to troubleshoot:
-
Perform the same command without Fusion (use the -D "fs.hdfs.impl=org.apache.hadoop.hdfs.DistributedFileSystem" parameter if running basic HDFS CLI tests). If clients can read/write encrypted content without Fusion, this points to misconfiguration in the above.
-
Test with an encrypted but non-replicated folder through Fusion client. If this works, but replicated folder does not, this suggests issues on the remote cluster.
-
Look in client side application / service logs for permissions issues. (This may be mapreduce, Hive, HBase Region Server logs etc). This may require debug logging being enabled temporarily.
-
Search for the path / file under investigation; you are looking for KMS ACL exceptions.
5.17. WebWasb
WebHDFS is the implementation of HTTP Rest API for HDFS compatible file systems. WebWasb is simply WebHDFS for the WASB file system.
WebWasb can be installed on the edge node where the ISV applications live. From the edge node, WebWasb can be accessed by referring to localhost and the port 50073.
WebWasb works off of the default file system for the cluster (a specified default container in the default storage account) specified in /etc/hadoop/conf/core-site.xml under the property fs.defaultFS. As an example, if your default storage account is named storage1 and your default container is named container1, you could create a new directory called dir1 within that container by the following WebHDFS command:
curl -i -X PUT http://localhost:50073/WebWasb/webhdfs/v1/dir1?op=MKDIRS
WebWasb commands are case sensitive, so pay specific attention to the casing of "WebWasb" and the operations should all be uppercase.
- Azure virtual network
-
With virtual network integration, Hadoop clusters can be deployed to the same virtual network as your applications so that applications can communicate with Hadoop directly. The benefits include:
-
Direct connectivity of web applications or ISV applications to the nodes of the Hadoop cluster, which enables communication to all ports via various protocols, such as HTTP or Java RPC.
-
Improved performance by not having your traffic go over multiple gateways and load-balancers.
-
Virtual network gives you the ability to process info more securely, and only provide specific endpoints to be accessed publicly.
-
5.18. HttpFS
HttpFS is a server that provides a REST HTTP gateway supporting all HDFS File System operations (read and write), and it is interoperable with the webhdfs REST HTTP API.
If httpFS is installed after WD Fusion, then you will need to manually add the following script to avoid getting a "ClassNotFound" error.
Add the following lines to /etc/hadoop-httpfs/tomcat-deployment/bin/setenv.sh in the HttpFS node:
# START_FUSION - do not remove this line, or the STOP_FUSION line (shopt -s nullglob if [ -d /opt/wandisco/fusion/client/lib ]; then for jar in /opt/wandisco/fusion/client/lib/*; do cp $jar /usr/hdp/current/hadoop-httpfs/webapps/webhdfs/WEB-INF/lib done fi) # STOP_FUSION
6. Deployment Appendix
The appendix section contains extra help and procedures that may be required when running through a WD Fusion deployment.
6.1. Environmental Checks
During the installation, your system’s environment is checked to ensure that it will support WANdisco Fusion, the Environment checks are intended to catch basic compatibility issues, especially those that may appear during an early evaluation phase. The checks are not intended to replace carefully running through the Deployment Checklist.
- Operating System
-
The WD Fusion installer verifies that you are installing onto a system that is running on a compatible operating system.
See the Operating system section of the Deployment Checklist, although the current supported distributions of Linux are listed here:
Supported Operating Systems
-
RHEL 6 x86_64
-
RHEL 7 x86_64
-
Oracle Linux 6 x86_64
-
Oracle Linux 7 x86_64
-
CentOS 6 x86_64
-
CentOS 7 x86_64
-
Ubuntu 12.04LTS
-
Ubuntu 14.04LTS
-
SLES 11 x86_64
- Architecture
-
64-bit only
The WD Fusion installer verifies that the necessary Java components are installed on the system.The installer checks:
-
Env variables:
JRE_HOME,JAVA_HOMEand runs thewhich javacommand. -
Version: 1.7/1.8 recommended. Must be at least 1.7.
-
Architecture: JVM must be 64-bit.
-
Distribution: Must be from Oracle. See Oracle’s Java Download page.
For more information about JAVA requirements, see the Java section of the Deployment Checklist.
- Kerberos Relogin Failure with Hadoop 2.6.0 and JDK7u80 or later
-
Hadoop Kerberos relogin fails silently due to HADOOP-10786. This impacts Hadoop 2.6.0 when JDK7u80 or later is used (including JDK8).
Users should downgrade to JDK7u79 or earlier, or upgrade to Hadoop 2.6.1 or later.
- ulimit
-
The WD Fusion installer verifies that the system’s maximum user processes and maximum open files are set to 64000.
For more information about setting, see the File descriptor/Maximum number of processes limit on the Deployment Checklist.
- System memory and storage
-
WD Fusion’s requirements for system resources are split between its component parts, WD Fusion server, Inter-Hadoop Communication servers (IHCs) and the WD Fusion UI, all of which can, in principle be either collocated on the same machine or hosted separately.
The installer will warn you if the system on which you are currently installing WD Fusion is falling below the requirement. For more details about the RAM and storage requirements, see the Memory and Storage sections of the Deployment Checklist. - Compatible Hadoop flavour
-
WD Fusion’s installer confirms that a compatible Hadoop platform is installed. Currently, it takes the Cluster Manager detail provided on the Zone screen and polls the Hadoop Manager (CM or Ambari) for details. The installation can only continue if the Hadoop Manager is running a compatible version of Hadoop.
See the Deployment Checklist for Supported Versions of Hadoop - HDFS service state
-
WD Fusion validates that the HDFS service is running. If it is unable to confirm the HDFS state a warning is given that will tell you to check the UI logs for possible errors.
See the Logs section for more information. - HDFS service health
-
WD Fusion validates the overall health of the HDFS service. If the installer is unable to communicate with the HDFS service then you’re told to check the WD Fusion UI logs for any clues.
See the Logs section for more information. - HDFS maintenance mode
-
WD Fusion looks to see if HDFS is currently in maintenance mode. Both Hortonworks and Ambari support this mode for when you need to make changes to your Hadoop configuration or hardware, it suppresses alerts for a host, service, role or, if required, the entire cluster.
- WD Fusion node running as a client
-
We validate that the WD Fusion server is configured as a HDFS client.
- HTTP Server Port
-
Validates whether the port number that you entered is free and can be bound.
- HTTPS Server Port
-
Validates whether the port number that you entered is free and can be bound.
- Fusion DConE Port Validation
-
Validates whether the port number is free and can be bound.
6.2. Installing to a custom location
The WD Fusion installer places files into a fixed location, /opt/wandisco. We strongly recommend that you use the default location as it’s better supported and more roundly tested, however, for deployments where this location is not permitted, the following RPM relocation feature is available, allowing installations of WD Fusion to a user-selected location:
6.2.1. Pre-requisites
-
Red Hat Enterprise Linux and derivatives only (SuSE not currently supported)
-
Special attention will be required for client installations.
-
Limitation concerning Ambari stack installation
|
Non-root Ambari agents
Unfortunately the Ambari Stack installer cannot be configured for non-root if you intend to use this RPM relocation feature.
Ambari can be configured for non-root Ambari Agents.
|
FUSION_PREFIX Environmental variable
When running the installer, first set the following environmental variable:
sudo FUSION_PREFIX=<custom-directory> ./fusion-ui-server-hdp_rpm_installer.sh
This will change the installation directory from the default to the one that you provide, e.g.
sudo FUSION_PREFIX=/CustomInstallLocation ./fusion-ui-server-hdp_rpm_installer.sh
The above example would install fusion-ui-server into /CustomInstallLocation/fusion-ui-server. Also, the WD Fusion server and IHC server will be installed under /CustomInstallLocation/fusion/server and /CustomInstallLocation/fusion/ihc/server/ respectively.
If you run with the FUSION_PREFIX, an additional line will appear on the summary screen of the installer:
:: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### ##### Installing with the following settings: Installation Prefix: /CustomInstallLocation User and Group: hdfs:hdfs Hostname: localhost.localdomain Fusion Admin UI Listening on: 0.0.0.0:8083 Fusion Admin UI Minimum Memory: 128 Fusion Admin UI Maximum memory: 512 Platform: hdp-2.4.0 (2.7.1.2.4.0.0-169) Fusion Server Hostname and Port: localhost.localdomain:8082 Do you want to continue with the installation? (Y/n)
6.2.2. Alternate method
You can also perform an installation to a custom directory using the following alternative:
Inject the environmental variable:
`export FUSION_PREFIX=<custom-directory>`
Run the installer as per the usual method, i.e.:
./fusion-ui-server-hdp_rpm_installer.sh
The installer will use the provided path for the installation, as described in the main procedure.
6.2.3. Custom location installations - Client Installation
When installing to a customer location, you will need to ensure that your clients are configured with the matching location. You should be able to correctly install clients using the normal procedure, outlined above. See Client Installation, immediately below.
6.3. Client Installations
6.3.1. Client Installation with RPMs
The WD Fusion installer doesn’t currently handle the installation of the client to the rest of the nodes in the cluster. You need to go through the following procedure:
In the Client Installation section of the installer you will see line "Download a list of your client nodes" along with links to the client RPM packages.
RPM package location
If you need to find the packages after leaving the installer page with
the link, you can find them in your installation directory, here:
/opt/wandisco/fusion-ui-server/ui/client_packages
If you are installing the RPMs, download and install the package on each of the nodes that appear on the list from step 1.
Installing the client RPM is done in the usual way:
rpm -i <package-name>
6.3.2. Install checks
-
First, we check if we can run
hadoop classpath, in order to complete the installation. -
If we’re unable to run
hadoop classpaththen we check forHADOOP_HOMEand run the Hadoop classpath from that location. -
If the checks cause the installation to fail, you need to export HADOOP_HOME and set it so that the hadoop binary is available at $HADOOP_HOME/bin/hadoop, e.g.
export HADOOP_HOME=/opt/hadoop/hadoop export HIVE_HOME=/opt/hadoop/hive export PATH=$HADOOP_HOME/bin:$HIVE_HOME/bin
HDP2.1/Ambari 1.6: Start services after installation
When installing clients via RPM into HDP2.1/Ambari 1.6., ensure that you
restart services in Ambari before continuing to the next step.
6.3.3. Installation with DEB
Debian not supported
Although Ubuntu uses Debian’s packaging system, currently Debian itself
is not supported. Note: Hortonworks HDP does not support Debian.
If you are running with an Ubuntu Linux distribution, you need to go through the following procedure for installing the clients using Debian’s DEB package:
-
In the Client Installation section of the installer you will see the link to the list of nodes here and the link to the client DEB package.
DEB package location
If you need to find the packages after leaving the installer page with the link, you can find them in your installation directory, here:
/opt/wandisco/fusion-ui-server/ui/client_packages
-
To install WANdisco Fusion client, download and install the package on each of the nodes that appear on the list from step 1.
-
You can install it using
sudo dpkg -i /path/to/deb/file
followed by
sudo apt-get install -f
Alternatively, move the DEB file to
/var/cache/apt/archives/and then runapt-get install <fusion-client-filename.deb>
6.3.4. Client Installation with Parcels
For deployments into Cloudera clusters, clients can be installed using Cloudera’s own packaging format: Parcels.
Parcel Locations
By default local parcels are stored on the Cloudera Manager Server:/opt/cloudera/parcel-repo. To change this location, follow the instructions in Configuring Server Parcel Settings.
The location can be changed by setting the parcel_dir property in /etc/cloudera-scm-agent/config.ini file of the Cloudera Manager Agent and restart the Cloudera Manager Agent or by following the instructions in Configuring the Host Parcel Directory.
|
Don’t link to /usr/lib/
The path to the CDH libraries is /opt/cloudera/parcels/CDH/lib instead of the usual /usr/lib.
We strongly recommend that you don’t link /usr/lib/ elements to parcel deployed paths, as some scripts distinguish between the two paths.
|
Installing the parcel
-
Open a terminal session to the location of your parcels repository, it may be your Cloudera Manager server, although the location may have been customized. Ensure that you have suitable permissions for handling files.
-
Download the appropriate parcel and sha for your deployment.
wget "http://fusion.example.host.com:8083/ui/parcel_packages/FUSION-<version>-cdh5.<version>.parcel" wget "http://node01-example.host.com:8083/ui/parcel_packages/FUSION-<version>-cdh5.<version>.parcel.sha"
-
Change the ownership of the parcel and .sha files so that they match the system account that runs Cloudera Manager:
chown cloudera-scm:cloudera-scm FUSION-<version>-cdh5.<version>.parcel*
-
Move the files into the server’s local repository, i.e.
mv FUSION-<version>-cdh5.<version>.parcel* /opt/cloudera/parcel-repo/
-
Open Cloudera Manager and navigate to the Parcels screen by clicking on the Parcel icon.
 Figure 30. Open Cloudera Manager
Figure 30. Open Cloudera Manager -
Click Check for New Parcels.
 Figure 31. Check for new parcels
Figure 31. Check for new parcels -
The WD Fusion client package is now ready to distribute. Click on the Distribute button to install WANdisco Fusion from the parcel.
 Figure 32. Ready to distribute
Figure 32. Ready to distribute -
Click on the Activate button to activate WANdisco Fusion from the parcel.
 Figure 33. Activate Parcels
Figure 33. Activate ParcelsThen confirm you want to activate Fusion.
-
The configuration files need redeploying to ensure the WD Fusion elements are put in place correctly. You will need to check Cloudera Manager to see which processes will need to be restarted in order for the parcel to be deployed. Cloudera Manager provides a visual cue about which processes will need a restart.
Important
To be clear, you must restart the services, it is not sufficient to run the "Deploy client configuration" action.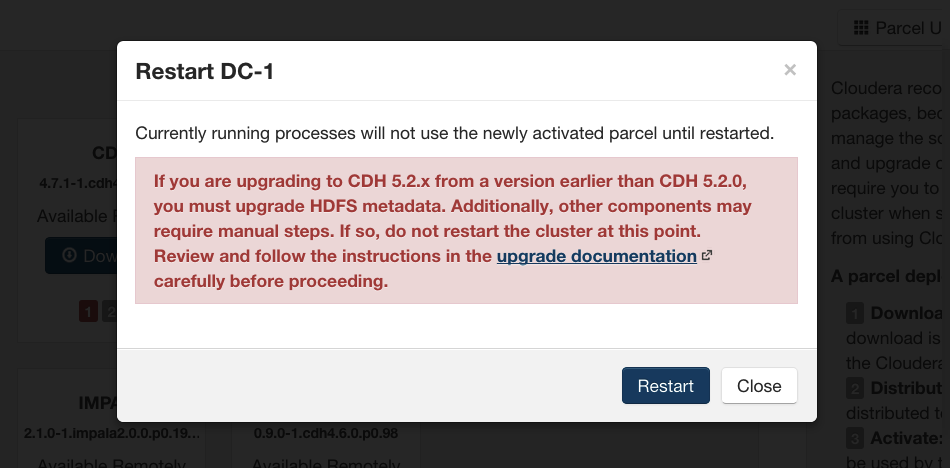 Figure 34. Restarts
Figure 34. RestartsWD Fusion uses Hadoop configuration files associated with the Yarn Gateway service and not HDFS Gateway. WD Fusion uses config files under /etc/hadoop/conf and CDH deploys the Yarn Gateway files into this directory.
Replacing earlier parcels?
If you are replacing an existing package that was installed using a parcel, once the new package is activated you should remove the old package through Cloudera Manager. Use the Remove From Host button.

Installing HttpFS with parcels
HttpFS is a server that provides a REST HTTP gateway supporting all HDFS File System operations (read and write). And it is interoperable with the webhdfs REST HTTP API.
While HttpFS runs fine with WD Fusion, there is an issue where it may be installed without the correct class paths being put in place, which can result in errors when running Mammoth test scripts.
Example errors
Running An HttpFS Server Test -- accessing hdfs directory info via curl requests
Start running httpfs test
HTTP/1.1 401 Unauthorized
Server: Apache-Coyote/1.1
WWW-Authenticate: Negotiate
Set-Cookie: hadoop.auth=; Path=/; Expires=Thu, 01-Jan-1970 00:00:00 GMT; HttpOnly
Content-Type: text/html;charset=utf-8
Content-Length: 997
Date: Thu, 04 Feb 2016 16:06:52 GMT
HTTP/1.1 500 Internal Server Error
Server: Apache-Coyote/1.1
Set-Cookie: hadoop.auth="u=oracle&p=oracle/bdatestuser@UATBDAKRB.COM&t=kerberos&e=1454638012050&s=7qupbmrZ5D0hhtBIuop2+pVrtmk="; Path=/; Expires=Fri, 05-Feb-2016 02:06:52 GMT; HttpOnly
Content-Type: application/json
Transfer-Encoding: chunked
Date: Thu, 04 Feb 2016 16:06:52 GMT
Connection: close
{"RemoteException":{"message":"java.lang.ClassNotFoundException: Class com.wandisco.fs.client.FusionHdfs not found","exception":"RuntimeException","javaClassName":"java.lang.RuntimeException"}}
6.3.5. Fusion Client installation with HDP Stack / Pivotal HD / IBM BigInsights
For deployments into Hortonworks HDP/Ambari/IBM BigInsights cluster, version 1.7 or later. Clients can be installed using Hortonwork’s own packaging format: HDP Stack. This approach always works for Pivotal HD.
Ambari 1.6 and earlier
If you are deploying with Ambari 1.6 or earlier, don’t use the provided
Stacks, instead use the generic RPMs.
Ambari 1.7
If you are deploying with Ambari 1.7, take note of the requirement to
perform some necessary restarts on Ambari
before completing an installation.
Ambari 2.0
When adding a stack to Ambari 2.0 (any stack, not just WD Fusion client)
there is a bug which causes the YARN parameter
yarn.nodemanager.resource.memory-mb to reset to a default value for
the YARN stack. This may result in the Java heap dropping from a
manually-defined value, back to a low default value (2Gb). Note that
this issue is fixed from Ambari 2.1.
Upgrading Ambari
When running Ambari prior to 2.0.1, we recommend that you remove and
then reinstall the WD Fusion stack if you perform an update of Ambari.
Prior to version 2.0.1, an upgraded Ambari refuses to restart the WD
Fusion stack because the upgrade may wipe out the added services folder
on the stack.
If you perform an Ambari upgrade and the Ambari server fails to restart , the workaround is to copy the WD Fusion service directory from the old to the new directory, so that it is picked up by the new version of Ambari, e.g.:
cp -R /var/lib/ambari-server/resources/stacks_25_08_15_21_06.old/HDP/2.2/services/FUSION /var/lib/ambari-server/resources/stacks/HDP/2.2/services
Again, this issue doesn’t occur once Ambari 2.0.1 is installed.
HDP 2.3/Ambari 2.1.1 install
There’s currently a problem that can block the installation of the WD
Fusion client stack. If the installation of the client service gets
stuck at the "Customize Service" step, you may need to use a
workaround:
-
If possible, restart the sequence again, if the option is not available, because the Next button is disabled, or it doesn’t work try the next workaround.
-
Try installing the client RPMs.
-
Install the WD Fusion client service manually, using the Ambari API.
6.3.6. Install & Start the service via Ambari’s API
Make sure the service components are created and the configurations attached by making a GET call, e.g.
http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/services/<service-name>
1. Add the service
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/services -d '{"ServiceInfo":{"service_name":"FUSION"}}'
2. Add the component
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/services/FUSION/components/FUSION_CLIENT -X POST
3. Get a list of the hosts
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/hosts/
4. For each of the hosts in the list, add the FUSION_CLIENT
component
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/hosts/<host-name>/host_components/FUSION_CLIENT -X POST
5. Install the FUSION_CLIENT component
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/services/FUSION/components/FUSION_CLIENT -X PUT -d '{"ServiceComponentInfo":{"state": "INSTALLED"}}'
6.3.7. Installing the WANdisco service into your HDP Stack
-
Download the service from the installer client download panel, or after the installation is complete, from the client packages section on the Settings screen.
-
The service is a gz file (e.g. fusion-hdp-<your_version>.stack.tar.gz) that will expand to a folder called /FUSION.
-
For HDP, place this folder in
/var/lib/ambari-server/resources/stacks/HDP/<version-of-stack>/services.
For Pivotal HD deployments, place in one of the following or similar folders:/var/lib/ambari-server/resources/stacks/PHD/<version-of-stack>/services, or/var/lib/ambari-server/resources/stacks/<distribution>/<version-of-stack>/services. -
Restart the ambari-server
service ambari-server restart
-
After the server restarts, go to + Add Service.
 Figure 35. Ambari - Add service
Figure 35. Ambari - Add service -
Scroll down the Choose Services window to check that WANdisco Fusion is present on the list
 Figure 36. Choose service
Figure 36. Choose service -
Do not add the service here, instead go back to the Fusion Installer UI and follow the on screen instructions.
6.4. Removing a WD Fusion client stack
When we use the "Deploy Stack" button it can on rare occasions fail. If it does you can recover the situation with the following procedure, which involves removing the stack, then adding it again using Ambari’s "Add New Service" wizard.
-
Send these two curl calls to Ambari:
curl -u admin:admin -X PUT -d '{"RequestInfo":{"context":"Stop Service"},"Body":{"ServiceInfo":{"state":"INSTALLED"}}}' http://<manager_hostname>:<manager_port>/api/v1/clusters/<cluster_name>/services/FUSION -H "X-Requested-By: admin" curl -u admin:admin -X DELETE http://<manager_hostname>:<manager_port>/api/v1/clusters/<cluster_name>//services/FUSION -H "X-Requested-By: admin" -
Now remove the client from each node:
yum erase <the client> rm -rf /opt/wandisco/fusion/client/
-
Restart ambari-server using the following command on the manager node:
ambari-server restart
-
Finally, add the service using Ambari’s Add Service Wizard.

6.4.1. MapR Client Configuration
On MapR clusters, you need to copy WD Fusion configuration onto all other nodes in the cluster:
-
Open a terminal to your WD Fusion node.
-
Navigate to
/opt/mapr/hadoop/<hadoop-version>/etc/hadoop. -
Copy the
core-site.xmlandyarn-site.xmlfiles to the same location on all other nodes in the cluster. -
Now restart HDFS, and any other service that indicates that a restart is required.
6.4.2. MapR Impersonation
Enable impersonation when cluster security is disabled
Follow these steps on the client to configure impersonation without enabling cluster security.
-
Enable impersonation for all relevant components in your ecosystem. See the MapR documentation - Component Requirements for Impersonation.
-
Enable impersonation for the MapR core components:
The following steps will ensure that MapR will have the necessary permissions on your Hadoop cluster:-
Open the
core-site.xmlfile in a suitable editor. -
Add the following *hadoop.proxyuser* properties:
<property> <name>hadoop.proxyuser.mapr.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.mapr.groups</name> <value>*</value> </property>Note: The wildcard asterisk * lets the "mapr" user connect from any host and impersonate any user in any group.
-
Check that your settings are correct, save and close the
core-site.xmlfile.
-
-
On each client system on which you need to run impersonation:
-
Set a MAPR_IMPERSONATION_ENABLED environment variable with the value, true. This value must be set in the environment of any process you start that does impersonation. E.g.
export MAPR_IMPERSONATION_ENABLED=true
-
Create a file in
/opt/mapr/conf/proxy/that has the name of the mapr superuser. The default file name would be mapr. To verify the superuser name, check themapr.daemon.user=line in the/opt/mapr/conf/daemon.conffile on a MapR cluster server.
-
6.5. Removing WANdisco Service
If you are removing WD Fusion, maybe as part of a reinstallation, you
should remove the client packages as well. Ambari never deletes any
services from the stack it only disables them. If you remove the WD
Fusion service from your stack, remember to also delete
fusion-client.repo.
[WANdisco-fusion-client] name=WANdisco Fusion Client repo baseurl=file:///opt/wandisco/fusion/client/packages gpgcheck=0
For instructions for the cleanup of Stack, see Host Cleanup for Ambari and Stack
6.5.1. Cleanup WD Fusion HD
When installing WD Fusion on a system that already has an earlier version of WD Fusion installed, you need to first ensure that components and configuration for an earlier installation have been removed. Go through the steps in the Uninstall chapter, Clean WD Fusion HD, before installing a new version of WD Fusion.
6.5.2. Uninstall WD Fusion
There’s an uninstaller script, so that you don’t need to clean up your deployment manually. If you used the unified installer then use the uninstall script, following the steps described in Uninstall.
Cloudera Manager:
-
Go to "Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml"
-
Delete all Fusion-related content
-
Remove WD Fusion parcel
-
Restart services
For more detailed steps see Uninstalling Fusion - Cloudera.
Ambari
-
Got to HDFS → Configs → Advanced → Custom core-site
-
Delete all WD Fusion-related elements
-
Remove stack (See Removing WANdisco Service)
-
Remove the package from all clients, e.g.
yum remove -y fusion*client*.rpm
-
Restart services
For more detailed steps see Uninstalling Fusion - Ambari.
6.5.3. Core-site Properties to delete:
For a complete uninstallation, remove the following properties from the
core-site.xml:
-
fs.fusion.server (If removing a single node from a zone, remove just that node from the property’s value, instead).
-
fs.hdfs.impl (its removal ensures that this native hadoop class is used, e.g.
org.apache.hadoop.hdfs.DistributedFileSystem). -
fs.fusion.impl
Reinstalling fusion server only
If you reinstall the fusion-server without also reinstalling the
fusion-ui-server, then you should restart the fusion-ui-server service
to ensure the correct function of some parts of the UI. If the service
is not restarted then you may find that the dashboard graphs stop
working properly, along with the UI’s Stop/start controls. e.g. run:
[root@redhat6 init.d]# service fusion-ui-server restart
7. Upgrade WD Fusion
This section covers the steps you need to follow to upgrade WD Fusion 2.10.3.x to 2.10.5 and later point releases.
7.1. Cloudera Upgrade
The following section covers the upgrade steps for a Cloudera-based deployment. See here for the HDP Upgrade steps.
-
Enable the Fusion Client Bypass. See Enable/disable emergency bypass via the UI.
-
Stop all Fusion services, e.g.
service fusion-server stop service fusion-ihc-server-VERSION stop service fusion-ui-server stop
-
Back up your WD Fusion installation and configuration directories, e.g.
mkdir /tmp/fusion-upgrade cp -pdr /etc/wandisco /tmp/fusion-upgrade/etc-wandisco-backup cp -pdr /opt/wandisco /tmp/fusion-upgrade/opt-wandisco-backup
/opt/wandisco/ contains the following configuration and prevayler library data, which will be necessary in case, after upgrading, you decide to roll back to your current Fusion version.
Property files:
cp -pdr /opt/wandisco/fusion-ui-server/lib/fusion_ui_log4j.properties /tmp/fusion-upgrade/properties cp -pdr /opt/wandisco/fusion-ui-server/properties/ui.properties /tmp/fusion-upgrade/properties cp -pdr /etc/wandisco/fusion/server/application.properties /tmp/fusion-upgrade/properties cp -pdr /etc/wandisco/fusion/server/log4j.properties /tmp/fusion-upgrade/properties cp -pdr /etc/wandisco/fusion/server/logger.properties /tmp/fusion-upgrade/properties cp -pdr /etc/wandisco/fusion/ihc/server/cdh-5.3.0/log4j.properties /tmp/fusion-upgrade/properties
Prevayler:
cp -pdr /opt/wandisco/fusion/server/dcone /tmp/fusion-upgrade/prevayler
You will perform a check of the configuration files in /etc/wandisco at the end of the upgrade.
To also preserve log files:
cp -pdr /var/log/fusion /tmp/fusion-upgrade/logs
-
Remove the Fusion parcel.
Navigate to the parcels page in Cloudera Manager, deactivate and remove the existing Fusion parcel from hosts.
-
Download the installer script of the Fusion version you intend to upgrade to and extract its contents:
chmod +x fusion-ui-server_rpm_installer.sh ./fusion-ui-server_rpm_installer.sh --noexec --keep
The contents of the installer will be extracted to the directory installer/ by default.
-
Upgrade the Fusion server:
yum -y upgrade installer/resources/fusion-server/fusion-hcfs-<DISTRO-VERSION>-server-<FUSION_VERSION>.noarch.rpm
You should see the following output:
WANdisco Fusion Server upgraded successfully.
Fusion server startsThe Fusion server has been started after the upgrade completes. -
Upgrade the Fusion IHC server:
yum -y upgrade installer/resources/fusion-ihc-server/fusion-hcfs-<DISTRO-VERSION>-ihc-server-<FUSION_VERSION>.noarch.rpm
You should see the following output:
WANdisco Fusion IHC Server upgraded successfully.
IHC server startThe Fusion IHC server has been started after the upgrade completes. -
Upgrade the Fusion UI server:
yum -y upgrade installer/rpm/fusion-ui-server-<FUSION_VERSION>.noarch.rpm
The upgrade will now complete.
No automatic restartThe Fusion UI server has not been started and will need to be started manually at the end of the upgrade. -
Install the new Fusion parcel.
Copy the new Fusion .parcel and .parcel.sha files from /opt/wandisco/fusion-ui-server/ui/parcel_packages/ to the Cloudera Manager node’s /opt/cloudera/parcel-repo directory. Navigate to the parcels page of Cloudera Manager and press ‘Check for new parcels’.
Distribute and activate the new Fusion parcel.
-
Upgrade WD Hive if installed.
Create a back-up of the WD Hive configuration files of your current WD Hive installation:
cp -pdr wd-hive-metastore-env.sh /tmp/fusion-upgrade/hive-configs cp -pdr wd-hive-metastore-memory.sh /tmp/fusion-upgrade/hive-configs cp -pdr wd-hive-site.xml /tmp/fusion-upgrade/hive-configs
Deactivate and remove the old WD Hive parcel from hosts.
Copy the new wd-hive-metastore parcel from /opt/wandisco/fusion-ui-server/ui/core_plugins/wd-hive/parcel_packages to the Cloudera Manager’s /opt/cloudera/parcel-repo.
Navigate to the parcels page of Cloudera Manager and press ‘Check for new parcels’.
Distribute and activate the new WD Hive Metastore parcel.
Upgrade the WD Hive plugin bits:
yum -y upgrade installer/resources/core-plugins/wd-hive/wd-hive-plugin-<DISTRO>-<VERSION>-<FUSION-VERSION>.noarch.rpm
-
Verify using your old configuration files that your WD Hive configuration has not changed. If it has, the new properties need to be changed back manually in the Cloudera Manager.
-
Verify your Fusion configuration has not changed. Use the back-up files you’ve created copies of to verify that your Fusion configuration has not changed. If it has, the changed properties need to be changed back manually in the Cloudera manager.
-
Restart all services marked as requiring a restart on the cluster manager.
-
IMPORTANT! Ensure that all old windows are closed and the browser cache is cleared prior to starting the Fusion UI server. Once this step is complete, proceed with the start-up:
service fusion-ui-server start
The UI server should start successfully.
-
Disable bypass.
7.2. HDP Upgrade
The following section covers the steps for upgrading WD Fusion on a HDP platform. If you are on a CDH platform, see how to perform an upgrade on a Cloudera platform.
-
Enable the Fusion Client Bypass. See Enable/disable emergency bypass via the UI.
-
Stop all Fusion services
Stop the Fusion server:
service fusion-server stop
Stop the Fusion IHC server:
service fusion-ihc-server-DISTRO_VERSION stop
Stop the Fusion UI server:
service fusion-ui-server stop
-
Create a back-up of Fusion installation and configuration directories:
mkdir /tmp/fusion-upgrade cp -pdr /etc/wandisco /tmp/fusion-upgrade/etc-wandisco-backup cp -pdr /opt/wandisco /tmp/fusion-upgrade/opt-wandisco-backup
Note that /opt/wandisco contains the following property files and the prevayler, which will be necessary in case you decide to roll back to your previous Fusion version after upgrading. Make sure you have backed up these files and directory prior to moving on with the upgrade process.
Property files:
cp -pdr /opt/wandisco/fusion-ui-server/lib/fusion_ui_log4j.properties /tmp/fusion-upgrade/properties cp -pdr /opt/wandisco/fusion-ui-server/properties/ui.properties /tmp/fusion-upgrade/properties cp -pdr /etc/wandisco/fusion/server/application.properties /tmp/fusion-upgrade/properties cp -pdr /etc/wandisco/fusion/server/log4j.properties /tmp/fusion-upgrade/properties cp -pdr /etc/wandisco/fusion/server/logger.properties /tmp/fusion-upgrade/properties cp -pdr /etc/wandisco/fusion/ihc/server/cdh-5.3.0/log4j.properties /tmp/fusion-upgrade/properties
Prevayler:
cp -pdr /opt/wandisco/fusion/server/dcone /tmp/fusion-upgrade/prevayler
You will perform a check of the configuration files in /etc/wandisco at the end of the upgrade.
To also preserve log files:
cp -pdr /var/log/fusion /tmp/fusion-upgrade/logs
-
Download the installer script of the Fusion version you intend to upgrade to and extract its contents.
chmod +x fusion-ui-server_rpm_installer.sh ./fusion-ui-server_rpm_installer.sh --noexec --keep
The contents of the installer will be extracted to the directory installer/ by default.
-
Upgrade the Fusion server.
yum -y upgrade installer/resources/fusion-server/fusion-hcfs-<DISTRO-VERSION>-server-<FUSION_VERSION>.noarch.rpm
You should see the following output:
WANdisco Fusion Server upgraded successfully.
Fusion server startsThe Fusion server has been started after the upgrade completes. -
Upgrade the Fusion IHC server.
yum -y upgrade installer/resources/fusion-ihc-server/fusion-hcfs-<DISTRO-VERSION>-ihc-server-<FUSION_VERSION>.noarch.rpm
You should see the following output:
WANdisco Fusion IHC Server upgraded successfully.
IHC server startThe Fusion IHC server has been started after the upgrade completes. -
Upgrade the Fusion UI server.
yum -y upgrade installer/rpm/fusion-ui-server-<FUSION_VERSION>.noarch.rpm
The upgrade will now complete.
Fusion server not startedThe Fusion UI server has not been started and will need to be started manually at the end of the upgrade. -
Uninstall WD Hive stacks if the service is installed.
If you have WD Hive installed, uninstall the WD Hive Metastore and WD Hiveserver 2 stacks and prepare the service for an upgrade. These steps must be completed before upgrading the Fusion stack because the WD Hive stacks prevent deletion of the Fusion stack on Ambari.
If you are not using WD Hive, move on to the next step.
-
Create a back-up of the WD Hive configuration files of your current WD Hive installation:
mkdir /tmp/fusion-upgrade/hive-configs cp -pdr wd-hive-metastore-env.sh /tmp/fusion-upgrade/hive-configs cp -pdr wd-hive-metastore-memory.sh /tmp/fusion-upgrade/hive-configs cp -pdr wd-hive-site.xml /tmp/fusion-upgrade/hive-configs
-
Note where the wd-hive-metastore server and slave are installed as you will need to deploy the upgraded service to the same nodes.
-
Remove the old wd-hive-metastore stack from fs:
rm -rf /var/lib/ambari-server/resources/stacks/<DISTRO>/<VERSION>/services/WD_HIVE_METASTORE
-
Remove the old wd-hiveserver2 stack from fs:
rm -rf /var/lib/ambari-server/resources/stacks/<DISTRO>/<VERSION>/services/WD_HIVESERVER2_TEMPLATE
-
Copy the new wd-hive-metastore and wd-hiveserver2 stacks from /opt/wandisco/fusion-ui-server/ui/core_plugins/wd-hive/stack_packages/ to /var/lib/ambari-server/resources/stacks/<DISTRO>/<VERSION>/services/
-
Unpack the new
wd-hive-metastorestack inside the services/ directory. -
Unpack the new
wd-hiveserver2stack inside the services/ directory. -
Restart the Ambari server so it is aware of the new stacks:
service ambari-server restart
-
From Ambari server’s WD_HIVE_METASTORE summary page:
-
select STOP from the WD Metastore service actions and click the “confirm stop” button.
-
select DELETE from the WD Metastore service actions and confirm with "delete".
-
note that the delete action only works once the service is properly stopped.
-
From Ambari server’s WD_HIVESERVER2_TEMPLATE summary page:
select STOP from the WD HS2 Template service actions and click the “confirm stop” button.
select DELETE from the WD HS2 Template service actions and confirm with "delete".
ImportantThe delete action only really works once the service is properly stopped.
-
-
Upgrade the Fusion stack.
-
Remove the old Fusion stack from fs:
rm -rf /var/lib/ambari-server/resources/stacks/<DISTRO>/<VERSION>/services/FUSION
-
Copy the new Fusion stack from /opt/wandisco/fusion-ui-server/ui/stack_packages/ to /var/lib/ambari-server/resources/stacks/<DISTRO>/<VERSION>/services/
-
Unpack the new Fusion stack inside the services/ directory.
-
Restart the Ambari server so it is aware of the new stack:
service ambari-server restart
-
From Ambari server’s WANdisco Fusion summary page select ‘Delete Service’ from service actions.
-
Re-deploy the WANdisco Fusion stack. Make sure to install the Fusion client on all nodes.
-
Upgrade WD Hive if the service is installed. Re-deploy the new WD_HIVE_METASTORE and WD_HIVESERVER2_TEMPLATE stacks.
CriticalMake sure you re-deploy the wd-hive-metastore server and slave to the same node(s) where they were previously installed. Otherwise, the upgrade will fail.Upgrade the WD Hive plugin bits:
yum -y upgrade installer/resources/core-plugins/wd-hive/wd-hive-plugin-<DISTRO>-<VERSION>-<FUSION-VERSION>.noarch.rpm
Verify using your old configuration files that your WD Hive configuration has not changed. If it has, the changed properties need to be changed back manually in the Ambari manager.
-
Verify your Fusion configuration has not changed.
Use the back-up files you’ve created copies of to verify that your Fusion configuration has not changed. If it has, the changed properties need to be changed back manually in the Ambari manager.
-
Restart all services marked as requiring a restart on Ambari manager to distribute the new configuration.
-
Important! Ensure that all old windows are closed and the browser cache is cleared prior to starting the Fusion UI server. Once this step is complete, proceed with the start-up:
service fusion-ui-server start.
The UI server will now start.
-
Disable bypass
8. Cloud Installation
The following section covers the installation of WANdisco Fusion into a cloud / hybrid-cloud environment.
8.1. Amazon Installation
8.1.1. Usage Instructions
Seamlessly move transactional data at petabyte scale to Amazon S3 with no downtime and no disruption.
This guide will run you through the first steps for deploying WANdisco’s Fusion S3 Active Migrator. First, select the deployment type:
-
WD Fusion S3 Active Migrator 50TB
Usage Instructions for WANdisco Fusion S3 Active Migrator - 50TB
Version 1.2 on Amazon Linux 2015.03M -
WANdisco Fusion S3 Active Migrator - 200TB
Usage Instructions for WANdisco Fusion S3 Active Migrator - 200TB,
Version 1.2 on Amazon Linux 2015.03 -
WANdisco Fusion S3 Active Migrator - BYOL
Usage Instructions for WANdisco Fusion S3 Active Migrator - BYOL,
Version 1.2 on Amazon Linux 2015.03
8.1.2. WD Fusion S3 Active Migrator 50TB
Get started using WANdisco Fusion S3 Active Migrator in 3 easy steps:
Launch Fusion on AWS using the Cloud Formation Template.
Download WANdisco Cloud Formation Template (50TB)
Download the WD Fusion installer according to your requirements:
Fusion for LocalFileSystem:
-
Debian Linux: fusion-ui-server-localfs_deb_installer.sh
-
Other Linux: fusion-ui-server-localfs_rpm_installer.sh
Fusion for Cloudera and Hortonworks:
-
Debian Linux: fusion-ui-server_deb_installer.sh
-
Other Linux: fusion-ui-server_rpm_installer.sh
Fusion for MapR:
-
Debian Linux: fusion-ui-server-mapr_deb_installer.sh
-
Other Linux: fusion-ui-server-mapr_rpm_installer.sh
Fusion for Pivotal HD:
-
Debian Linux: fusion-ui-server-phd_deb_installer.sh
-
Other Linux: fusion-ui-server-phd_rpm_installer.sh
Install WD Fusion, onto your on-premise cluster.
See Quickstart Guide- Replicating LocalFileSystem to Amazon S3.
Connect WD Fusion to Amazon Web services, then set up replication
between your on-premise cluster and AWS.
See
Connect WD Fusion to Amazon Web Service.
8.1.3. WANdisco Fusion S3 Active Migrator - 200TB
Usage Instructions for WANdisco Fusion S3 Active Migrator - 200TB,
Version 1.2 on Amazon Linux 2015.03
Get started using WANdisco Fusion S3 Active Migrator in 3 easy steps:
Launch Fusion on AWS using the Cloud Formation Template.
Download
WANdisco Cloud Formation Template (200TB)
Download the WD Fusion installer according to your requirements:
8.1.4. Fusion for LocalFileSystem:
-
Debian Linux: fusion-ui-server-localfs_deb_installer.sh
-
Other Linux: fusion-ui-server-localfs_rpm_installer.sh
Fusion for Cloudera and Hortonworks:
-
Debian Linux: fusion-ui-server_deb_installer.sh
-
Other Linux: fusion-ui-server_rpm_installer.sh
Fusion for MapR:
-
Debian Linux: fusion-ui-server-mapr_deb_installer.sh
-
Other Linux: fusion-ui-server-mapr_rpm_installer.sh
Fusion for Pivotal HD:
-
Debian Linux: fusion-ui-server-phd_deb_installer.sh
-
Other Linux: fusion-ui-server-phd_rpm_installer.sh
Install WD Fusion, onto your on-premise cluster.
See Quickstart Guide - Replicating LocalFileSystem to Amazon S3.
Connect WD Fusion to Amazon Web services, then set up replication
between your on-premise cluster and AWS.
See
Quickstart Guide - Connect WD Fusion to Amazon Web Service.
8.1.5. WANdisco Fusion S3 Active Migrator - BYOL
Usage Instructions for WANdisco Fusion S3 Active Migrator - BYOL,
Version 1.2 on Amazon Linux 2015.03
Get started using WANdisco Fusion S3 Active Migrator in 3 easy steps:
Launch Fusion on AWS using the Cloud Formation Template.
-
If your on-premise network does not have direct connectivity from AWS:
Download WANdisco Cloud Formation Template (BYOL) -
If your on-premise network has direct connectivity from AWS:
Download WANdisco Cloud Formation Template (BYOL)
Login to the WANdisco Fusion user interface on your launched EC2 instance, port 8083, and follow the installation instructions: Quickstart Guide - Replicating LocalFileSystem to Amazon S3.
8.1.6. AWS Metering
Amazon metering is a new pricing model available to AWS EC2 instances that charges for usage based on Data under replication during a clock hour. This value is the total size of data contained in replicated directories rounded up to the nearest terabyte.
IAM Role
See Bare Bones EC2 deployments for the required IAM roles needed for setting up for metering when installing a basic EC2 instance, instead of the default CFT-based installation, through the Amazon market place.
Data under replication
This is defined as the total amount of data held in AWS in directories that are replicated, excluding those files that are excluded from replication through regex-based filtering. WD Fusion therefore measures the amount of data under replication each hour.
Pricing bands for data replication |
0-25TB: $0.04/hour per TB under replication per instance |
25-50TB: $0.03/hour per TB under replication per instance |
50-100TB: $0.025/hour per TB under replication per instance |
100-200TB: $0.022/hour per TB under replication per instance |
>200TB: $0.02/hour per TB under replication per instance |
Metering troubleshooting
Logging and persistence files
For the Fusion plugin to be able to recover its state upon restart we need to have persistence of meter data. This is split into 3 files: live meter readings, failed meter readings and audit data.
Unless specified in /etc/wandisco/fusion/plugins/aws-metering/metering.properties all of these files will be in /etc/wandisco/fusion/aws-metering
- meterAudit.json
-
Contains a record of all reports made to Amazon Web Services and is read by the UI side of the plugin to display the graphs as well as being readable by the user and support.
- meterFile.json
-
This encrypted file holds the requests for the hour time period. Once the hour is up the stored request logs are used to calculate the maximum amount of data transfer that took place within the hour, and this number used for working out the charging.
- meterFail.json
-
An encrypted file that holds any failed requests to AWS.
How WD Fusion handles failed usage recording
-
Failed requests are retried periodically.
-
Metering runs on clock hours, i.e. billing will apply on the hour, at 2pm for the hour between 1pm-2pm, rather than for an arbitrary 60-minute period.
-
Amazon does not allow the submission of billing reports that are over 3 hours old. Any reports that have failed to reach AWS and are over 3 hours old will be aggregated and submitted with the latest valid report.
-
If a WD Fusion instance fails to bill AWS for a 48 hour period, the service will become degraded.
|
License exception
If WD Fusion enters a license exception state due to failed metering records, you will need to restart Fusion on the metering node to recover operation.
|
Metering Graph
You can view a nodes metering activity on the Metering graph, located in the Settings section.
Read more about the AWS Metering Graph
8.1.7. Installing into Amazon S3/EMRFS
Pre-requisites
Before you begin an installation to an S3 cluster make sure that you have the following directories created and suitably permissioned. Examples:
${hadoop.tmp.dir}/s3
and
/tmp/hadoop-${user.name}
You can deploy to Amazon S3 using either the:
Known Issues using S3
Make sure that you read and understand the following known issues, taking action if they impact your deployment requirements.
Replicating large files in S3
In the initial release supporting S3 there is a problem transferring very large files that will need to be worked around until the next major release (2.7).
The problem only impacts users who are running clusters that include S3, either exclusively or in conjunction with other Hadoop data centers.
Workaround
|
Out of Memory issue in EMR 4.1.0
The WDDOutputStream can cause an out-of-memory error because its ByteArrayOutputStream can go beyond the memory limit.
|
Workaround
By default, EMR has a configuration in hadoop-env.sh that OnOutOfMemoryError it runs a "kill -9 <pid>" command. WDDOutputStream is supposed to handle this Error by flushing its buffer and clearing space
for more writing.
(Configurable via HADOOP_CLIENT_OPTS in hadoop-env.sh which sets client-side heap and just needs to be commented out).
Use Consistent View for EMR
File replication from EMR can result in a 0-byte file as the EMR filesystem by default can become inconsistent.
|
More about EMR Consistent View
EMRFS Files TrackedEMRFS Metadata |
To fix the issue, use one of the following two methods:
AWS Management Console
Tick the Consistent view checkbox on the File System Configuration panel.
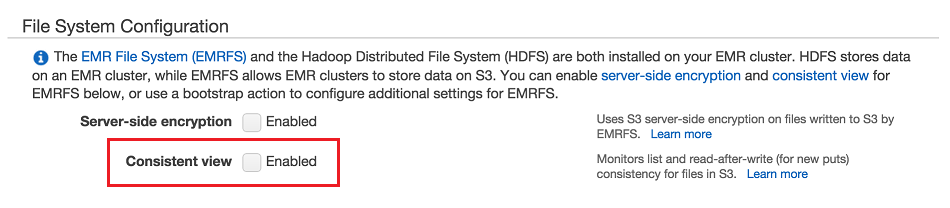
Via AWS CLI
In EMR client side, add configuration in /usr/share/aws/emr/emrfs/conf/emrfs-site.xml:
<property> <name>fs.s3.consistent</name> <value>true</value> </property>
|
unified config
In earlier versions of Fusion, IHC/Server/Client each had a custom core-site configuration. Now all services look at the same core-site, provided by the underlying FS, it isn’t possible to set consistency view specifically for IHC, so it must be set to be true for all.
|
S3 Silent Installation
You can complete an Amazon S3/EMRFS installation using the Silent Installation procedure, putting the necessary configuration in the silent_installer.properties as described in the previous section.
S3 specific settings
Environment Variables Required for S3 deployments:
-
FUSIONUI_MANAGER_TYPE=UNMANAGED_EMR
-
FUSIONUI_INTERNALLY_MANAGED_USERNAME
-
FUSIONUI_INTERNALLY_MANAGED_PASSWORD
-
FUSIONUI_FUSION_BACKEND_CHOICE
-
FUSIONUI_USER
-
FUSIONUI_GROUP
-
SILENT_PROPERTIES_PATH
silent_installer.properties File additional settings or specific required values listed here:
s3.installation.mode=true s3.bucket.name kerberos.enabled=false (or unspecified)
Example Installation
As an example (as root), running on the installer moved to /tmp.
# If necessary download the latest installer and make the script executable chmod +x /tmp/installer.sh # You can reference an original path to the license directly in the silent properties but note the requirement for being in a location that is (or can be made) readable for the $FUSIONUI_USER # The following is partly for convenience in the rest of the script cp /path/to/valid/license.key /tmp/license.key # Create a file to encapsulate the required environmental variables (example is for emr-4.0.0): cat <<EOF> /tmp/s3_env.sh export FUSIONUI_MANAGER_TYPE=UNMANAGED_EMR export FUSIONUI_INTERNALLY_MANAGED_USERNAME=admin export FUSIONUI_FUSION_BACKEND_CHOICE=emr-4.0.0':'2.6.0-amzn-0 export FUSIONUI_USER=hdfs export FUSIONUI_GROUP=hdfs export SILENT_PROPERTIES_PATH=/tmp/s3_silent.properties export FUSIONUI_INTERNALLY_MANAGED_PASSWORD=admin EOF # Create a silent installer properties file - this must be in a location that is (or can be made) readable for the $FUSIONUI_USER: cat <<EOF > /tmp/s3_silent.properties existing.zone.domain= existing.zone.port= license.file.path=/tmp/license.key server.java.heap.max=4 ihc.server.java.heap.max=4 fusion.domain=my.s3bucket.fusion.host.name fusion.server.dcone.port=6444 fusion.server.zone.name=twilight s3.installation.mode=true s3.bucket.name=mybucket induction.skip=false induction.remote.node=my.other.fusion.host.name induction.remote.port=8082 EOF # If necessary, (when $FUSIONUI_GROUP is not the same as $FUSIONUI_USER and the group is not already created) create the $FUSIONUI_GROUP (the group that our various servers will be running as): [[ "$FUSIONUI_GROUP" = "$FUSIONUI_USER" ]] || groupadd hadoop #If necessary, create the $FUSIONUI_USER (the user that our various servers will be running as): useradd hdfs # if [[ "$FUSIONUI_GROUP" = "$FUSIONUI_USER" ]]; then useradd $FUSIONUI_USER else useradd -g $FUSIONUI_GROUP $FUSIONUI_USER fi # silent properties and the license key *must* be accessible to the created user as the silent installer is run by that user chown hdfs:hdfs $FUSIONUI_USER:$FUSIONUI_GROUP /tmp/s3_silent.properties /tmp/license.key # Give s3_env.sh executable permissions and run the script to populate the environment . /tmp/s3_env.sh # If you want to make any final checks of the environment variables, the following command can help - sorted to make it easier to find variables! env | sort # Run installer: /tmp/installer.sh
S3 Setup through the installer
You can set up WD Fusion on an S3-based cluster deployment, using the installer script.
Follow this section to complete the installation by configuring WD Fusion on an S3-based cluster deployment, using the browser-based graphical user installer.
Open a web browser and point it at the provided URL. e.g
http://<YOUR-SERVER-ADDRESS>.com:8083/
-
In the first "Welcome" screen you’re asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows: Figure 39. Welcome screen
Figure 39. Welcome screen- Adding a new WD Fusion cluster
-
Select Add Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
-
Select Add to an existing Zone.
-
Run through the installer’s detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
 Figure 40. Environmental checks
Figure 40. Environmental checksOn clicking Validate the installer will run through a series of checks of your system’s hardware and software setup and warn you if any of WD Fusion’s prerequisites are not going to be met.
 Figure 41. Example check results
Figure 41. Example check resultsAddress any failures before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if the installation is only for evaluation purposes and not for production. However, when installing for production, you should address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
-
On the license screen, click Select a file to find your license file.
 Figure 42. Select your license file
Figure 42. Select your license file -
Upload the license file.
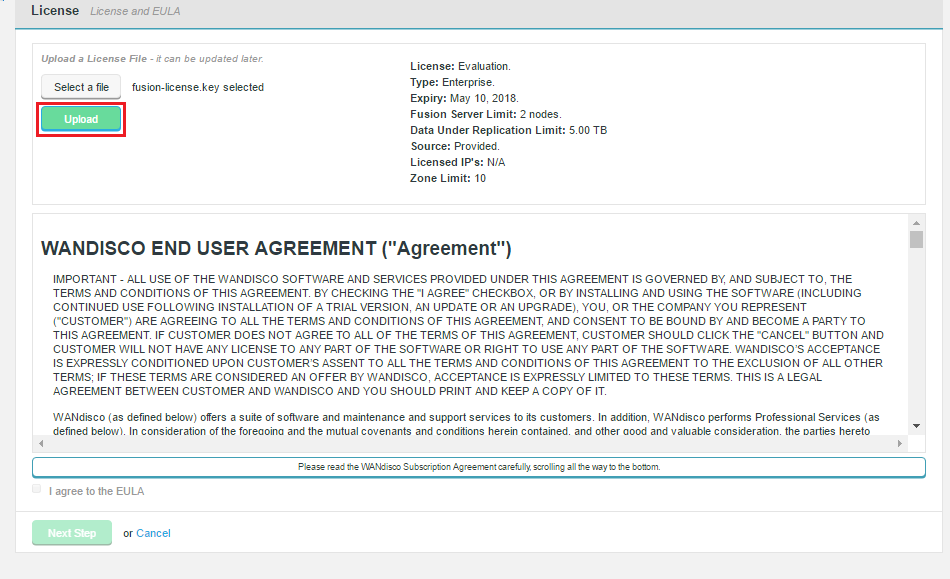 Figure 43. Upload your license file
Figure 43. Upload your license file -
The conditions of your license agreement will be presented in the top panel, including License Type, Expiry data, Name Node Limit and Data Node Limit.
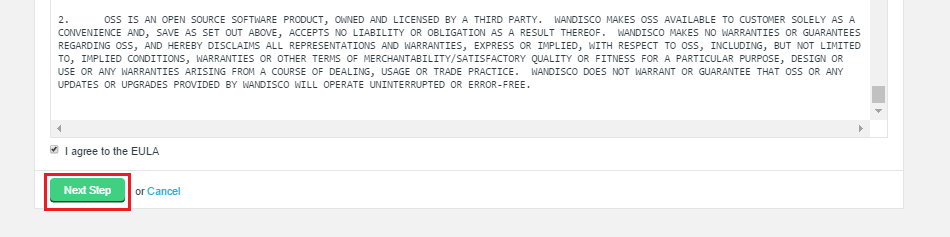 Figure 44. EULA agreement
Figure 44. EULA agreementVerify license and agree to subscription agreement.
Click on the I agree to the EULA to continue, then click Next Step.
-
Enter settings for the WD Fusion server.
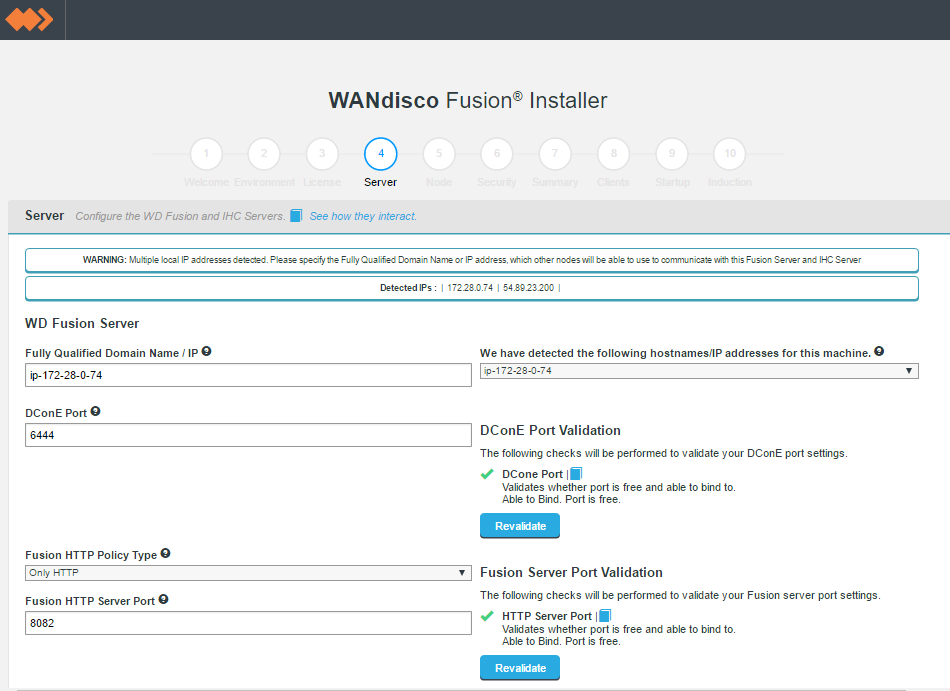 Figure 45. Enter settings for WD Fusion server
Figure 45. Enter settings for WD Fusion serverSee WD Fusion Server Settings for more information about what you need to enter.
 Figure 46. WD Fusion Server settings
Figure 46. WD Fusion Server settings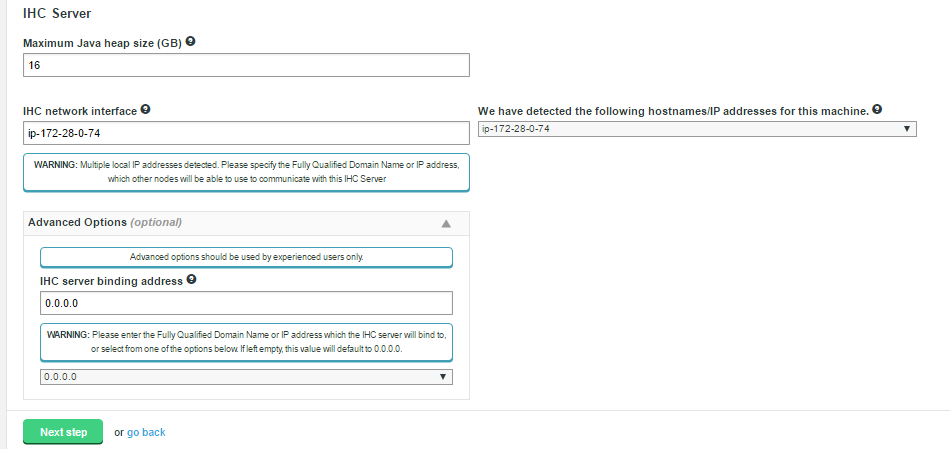 Figure 47. IHC Server
Figure 47. IHC Server -
In step 5 the Node Details are added.
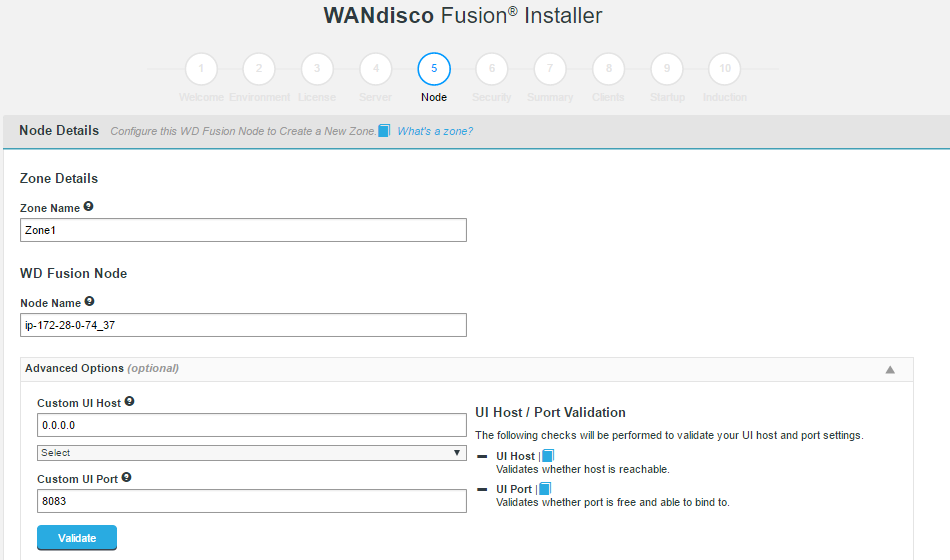 Figure 48. S3 Install
Figure 48. S3 Install
Node Information
- Fully Qualified Domain Name
-
The full hostname for the server.
- Node ID
-
A unique identifier that will be used by WD Fusion UI to identify the server.
- DConE Port
-
TCP port used by WD Fusion for replicated traffic.
- Zone Name
-
The name used to identify the zone in which the server operates.
S3 Bucket and core-site.xml Information
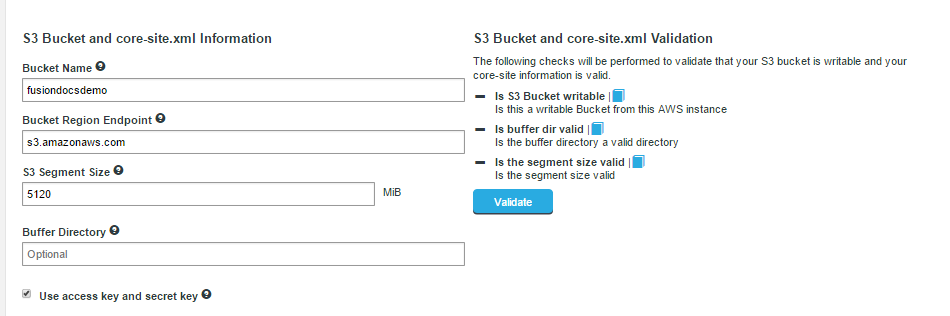
- Bucket Name
-
The name of the S3 Bucket that will connect to WD Fusion.
- Bucket Region Endpoint
-
This is the endpoint for your S3 API/Storage. On the S3 platform this will be based on the AWS Region in which your Bucket resides.
- S3 Segment Size
-
You can specify the S3 Segment Size. Very large files are broken down into segments. Between 5MB and 5 GB.
- Buffer Directory
-
Path to the directory where files are downloaded locally from IHC servers before they are uploaded to s3.
- Use access key and secret key
-
Additional details required if the S3 bucket is located in a different region. See Use access key and secret key.
- Use KMS with Amazon S3
-
Use an established AWS Key Management Server See Use KMS with Amazon S3.
Use access key and secret key
Tick this checkbox if you do not have permissions to access the S3 storage system, for example, incorrect IAM role permissions. This option will reveal additional entry fields:
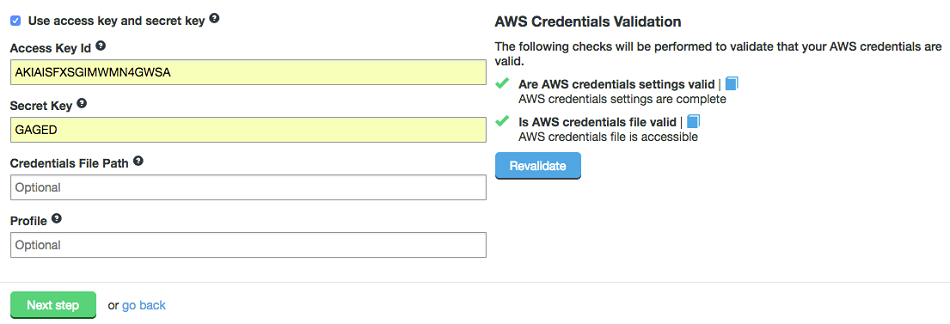
- Access Key Id
-
This is your AWS Access Key ID. Validation tests that there is a provided value, along with a valid secret key.
- Secret Key
-
This is the secret key that is used in conjunction with your Access Key ID to sign programmatic requests that are sent to AWS. Validation checks that the credentials file is accessible.
Click Validate to verify that the access key and secret key are accessible.
- Credentials File Path
-
Optional - Environmental variable that provides a path for the above noted credentials. If the path is not set, the default location will be used - typically ~/.aws/credentials.
The following environmental variable must also be exported.
export AWS_SHARED_CREDENTIALS_FILE=<location of credentials file on file system>
- Profile
-
Optional - AWS credential profiles allow you to share multiple sets of AWS security credentials between different tools like the AWS SDK for Java and the AWS CLI.
Credentials provider based on AWS configuration profiles. This provider vends AWSCredentials from the profile configuration file for the default profile, or for a specific, named profile.
Export
Use the following command to export the variable:
[hdfs@example01-vm1 .aws]$ export AWS_PROFILE=fusion [hdfs@example01-vm1 .aws]$ aws --endpoint-url=https://s3-api.us-example.domain.url.net s3 ls s3://vwbucket/repl1/
More about WDS Access Key ID and Secret Access Key
If the node you are installing is set up with the correct IAM role, then you won’t need to use the Access Key ID and Secret Key, as the EC2 instance will have access to S3.
However if IAM is not correctly set for the instance or the machine isn’t even in AWS then you need to provide both the Access Key ID and Secret Key.
Entered details are placed in core.site.xml.
Alternatively the AMI instance could be turned off. You could then create a new AMI based on it, then launch a new instance with the IAM based off of that AMI so that the key does not need to be entered.
"fs.s3.awsAccessKeyId" "fs.s3.awsSecretAccessKey"
Read Amazon’s documentation about Getting your Access Key ID and Secret Access Key.
Setting up AWS profiles
IAM roles are the default method we use for S3 authentication, they are specific to the AWS/S3 platform. However there are a growing number of hardware devices that come with S3-API front ends work independent of AMI infrastructure.
For these, we use the Access Key and Secret Key credentials; these are configured by running "aws configure" on the command line. This creates a .aws directory with a "credentials" file with the relevant keys, under a [default] section.
However, there is also the concept of "profiles", and you can store multiple different credentials for different profiles using the CLI command:
CLI
"aws configure --profile <profilename>". e.g.
aws --endpoint-url=https://s3-api.us-example.domain.url.net --profile fusion s3 ls s3://vwbucket/repl1/
This creates a new section in the credentials file like so:
[newprofilename] [nolan] aws_access_key_id = A******XYZ123ABCRFOA aws_secret_access_key = 77***********************XZ
Use KMS with Amazon S3

- KMS Key ID
-
This option must be selected if you are deploying your S3 bucket with AWS Key Management Service. Enter your KMS Key ID. This is a unique identifier of the key. This can be an ARN, an alias, or a globally unique identifier. The ID will be added to the JSON string used in the EMR cluster configuration.
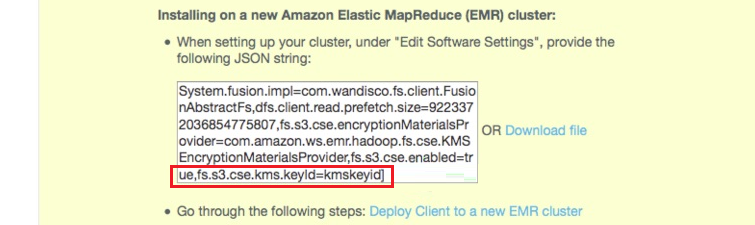
8.1.8. Core-Site.xml Information
- fs.s3.buffer.dir
-
The full path to a directory or multiple directories, separated by comma without space, that S3 will use for temporary storage. The install will check that the directory exists and that it will accept writes.
- hadoop.tmp.dir
-
The full path to a one or more directories that Hadoop will use for "housekeeping" data storage. The installer will check that the directories that you provide exists and is writable. You can enter multiple directories separate by comma without space.
S3 bucket validation
The following checks are made during installation to confirm that the zone has a working S3 bucket.
- S3 Bucket Valid
-
The S3 Bucket is checked to ensure that it is available and that it is in the same Amazon region as the EC2 instance on which WD Fusion will run. If the test fails, ensure that you have the right bucket details and that the bucket is reachable from the installation server (in the same region for a start).
- S3 Bucket Writable
-
The S3 Bucket is confirmed to be writable. If this is not the case then you should check for a permissions mismatch.
The following checks ensure that the cluster zone has the required temporary filespace:
S3 core-site.xml validation
- fs.s3.buffer.dir
-
Determines where on the local filesystem the S3 filesystem should store files before sending them to S3 (or after retrieving them from S3). If the check fails you will need to make sure that the property is added manually.
- hadoop.tmp.dir
-
Hadoop’s base for other temporary directory storage. If the check fails then you will need to add the property to the core-site.xml file and try to validate again.
These directories should already be set up on Amazon’s (ephemeral) EC2 Instance Store and be correctly permissioned.
-
The summary screen will now confirm all the details that you have entered so far.
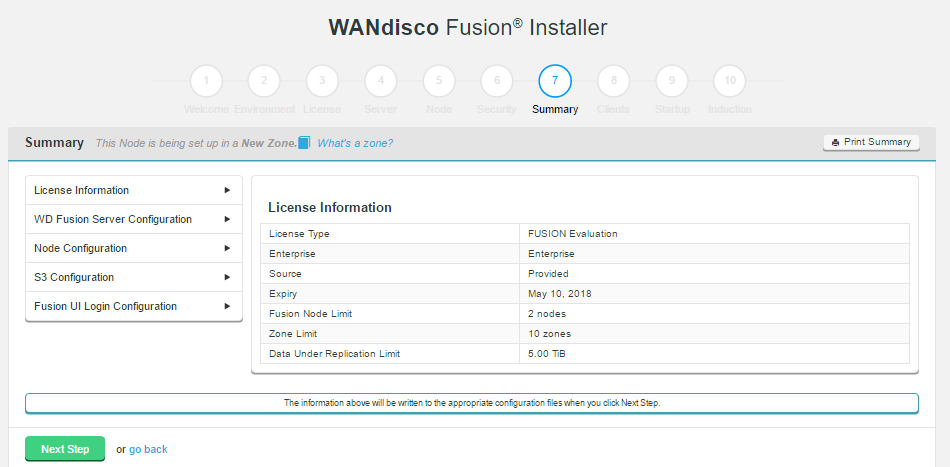 Figure 53. S3 Install details in the summary
Figure 53. S3 Install details in the summaryClick Next Step if you are sure that everything has been entered correctly.
-
You need to handle the WD Fusion client installations.
 Figure 54. S3/EMR InstallEnpoint limitations on s3 installer for non-AWS based s3 backends
Figure 54. S3/EMR InstallEnpoint limitations on s3 installer for non-AWS based s3 backendsCurrently an endpoint that is provided as a fully qualified hostname will be interpreted by the client as the hostname with the bucket name and a dot prepended like this:
http://bucket.hostname.com:8888/
The workaround for this is to make sure that the above address is mapped to wherever the s3 storage is located, either through the /etc/hosts file or some combination of iptable rules.
Note: Endpoints provided without a protocol will default to https, i.e. the client will attempt to connect over SSL (TLS). -
In this step the WD Fusion Server is started. Just click the Start WD Fusion button.
 Figure 55. S3/EMR Install
Figure 55. S3/EMR Install
-
SSL with AWS
When using SSL between Fusion nodes, you can create dedicated truststores. However, when connecting WD Fusion to external resources, such as AWS/Cloud nodes, the SSL connection will fail because these external nodes use CA certificates.
| When using SSL between Fusion and other nodes, such as cloud object stores, you need to update your truststores to include both the homemade certs and the Root authorities certs. |
Installing on a new Amazon Elastic MapReduce (EMR) cluster
These instructions apply during the set up of WD Fusion on a new AWS EMR cluster. This is the recommended approach, even if you already have an EMR cluster set up.
-
Log in to your EC2 console and select EMR Managed Hadoop Framework.
 Figure 56. EMR
Figure 56. EMR -
Click Create cluster. Enter the properties according to your cluster requirements.
 Figure 57. S3 New EMR cluster
Figure 57. S3 New EMR cluster -
Click Go to advanced options.
 Figure 58. S3 Install
Figure 58. S3 Install -
Click on the Edit software settings (optional) dropdown. This opens up a Change settings entry field for entering your own block of configuration, in the form of a JSON string.
 Figure 59. Software configuration
Figure 59. Software configurationEnter the JSON string provided in the installer screen.
Copy the JSON string, provided by the installer. e.g.
 Figure 60. JSON
Figure 60. JSONJSON string is stored in the settings screen
You can get the JSON string after the installation has completed by going to the Settings screen.
Example JSON string
classification=core-site,properties=[fusion.underlyingFs=s3://example-s3/,fs.fusion.server=52.8.156.64:8023,fs.fusion.impl=com.wandisco.fs.client.FusionHcfs,fs.AbstractFileSystem.fusion.impl=com.wandisco.fs.client.FusionAbstractFs,dfs.client.read.prefetch.size=9223372036854775807]
The JSON String contains the necessary WD Fusion parameters that the client will need:
- fusion.underlyingFs
-
The address of the underlying filesystem. In the case of ElasticMapReduce FS, the fs.defaultFS points to a local HDFS built on the instance storage which is temporary, with persistent data being stored in S3. Example: s3://wandisco.
- fs.fusion.server
-
The hostname and request port of the Fusion server. Comma-separated list of hostname:port for multiple Fusion servers.
- fs.fusion.impl
-
The Abstract FileSystem implementation to be used.
- fs.AbstractFileSystem.fusion.impl
-
The abstract filesystem implementation to be used.
-
Use the EMR Script tool on the Settings tab. Click Create script
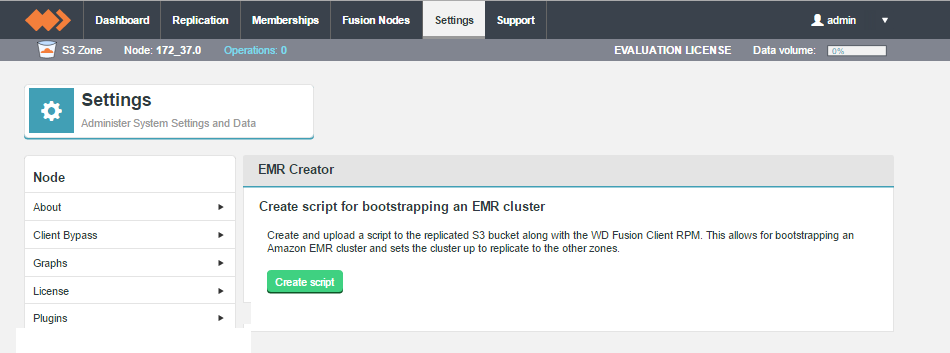 Figure 61. Create script
Figure 61. Create script -
This will automatically generate a configuration script for your AWS cluster and place the script onto your Amazon storage.
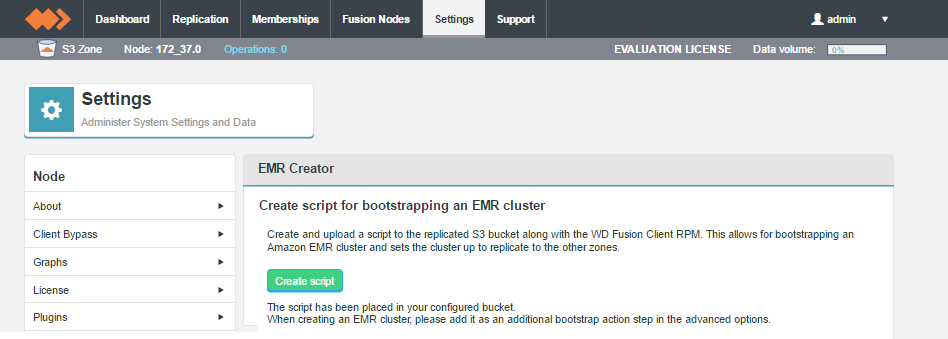 Figure 62. The script has been placed in your configured bucket
Figure 62. The script has been placed in your configured bucket -
Run through the Amazon cluster setup screens. In most cases you will run with the same settings that would apply without WD Fusion in place.
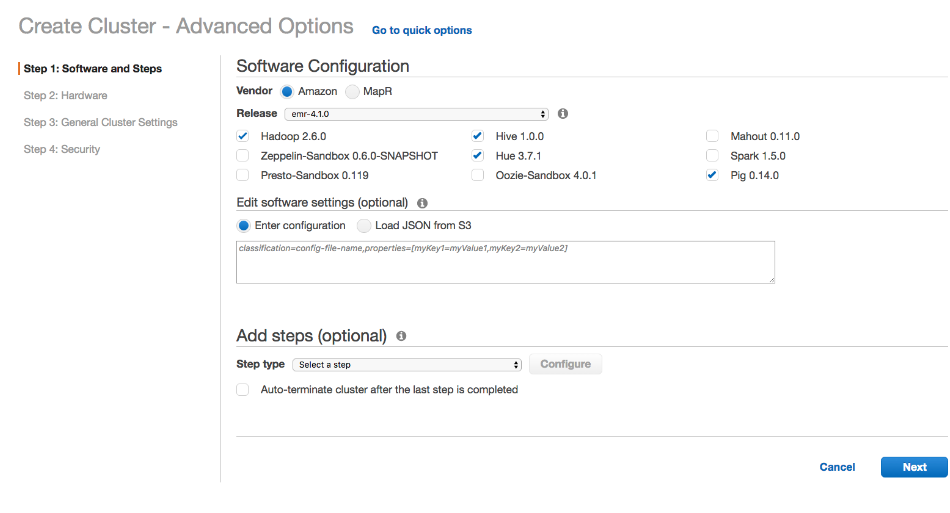 Figure 63. Cluster setup
Figure 63. Cluster setup -
In the Step 3: General Cluster Settings screen there is a section for setting up Bootstrap Actions.
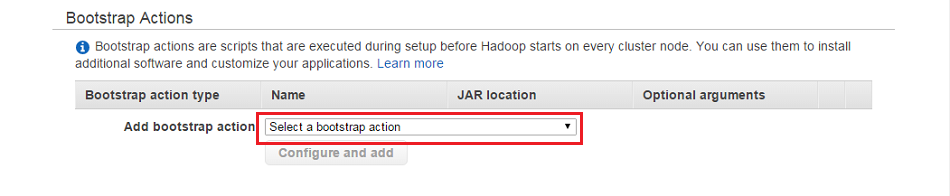 Figure 64. Bootstrap Actions
Figure 64. Bootstrap Actions -
In the next step, create a Bootstrap Action that will add the WD Fusion client to cluster creation. Click on the Select a bootstrap action dropdown.
-
Choose Custom Action, then click Configure and add.
 Figure 65. Select a bootstrap action
Figure 65. Select a bootstrap action -
Navigate to the EMR script, generated by WD Fusion in step 14. Enter the script’s location and leave the Optional arguments field empty.
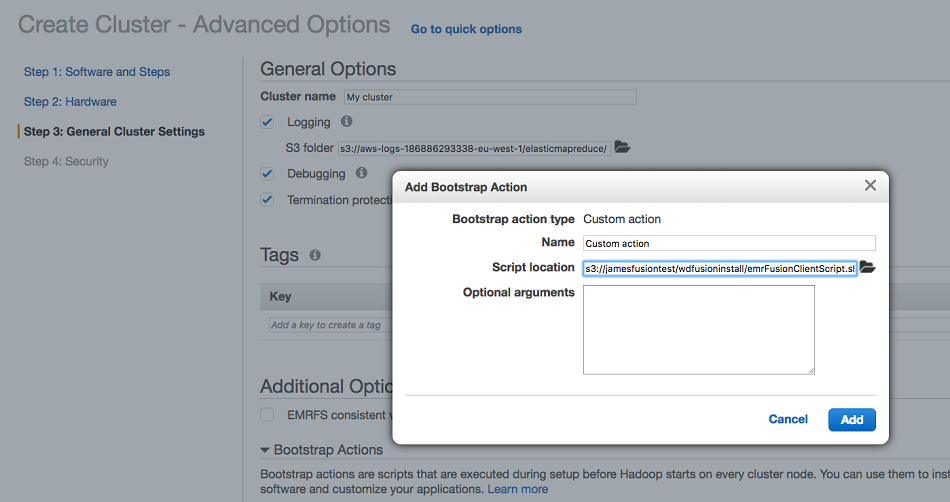 Figure 66. Add Bootstrap Action
Figure 66. Add Bootstrap Action -
Click Next to complete the setup.
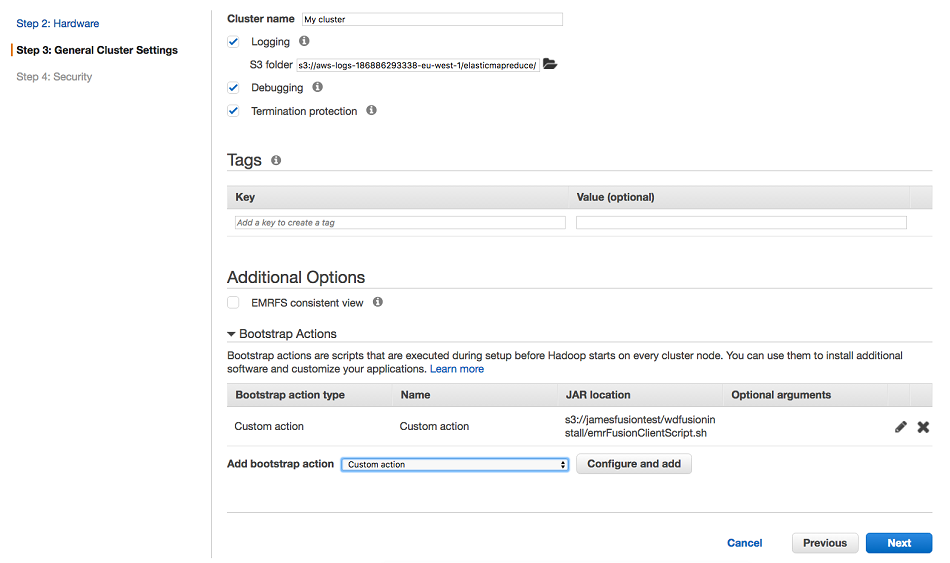 Figure 67. Custom action
Figure 67. Custom action -
Finally, click the Create cluster button to complete the AWS setup.
 Figure 68. Create cluster
Figure 68. Create cluster -
Return to the WD Fusion setup, clicking on Start WD Fusion.
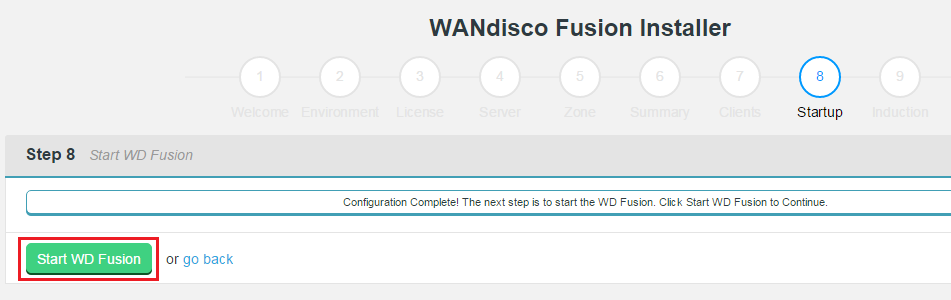 Figure 69. Start Fusion
Figure 69. Start Fusion
-
8.1.9. Installing on an existing Amazon Elastic MapReduce (EMR) cluster
We strongly recommend that you terminate your existing cluster and use the previous step for installing into a new cluster.
No autoscaling
This is because installing WD Fusion into an existing cluster will not benefit from AWS’s auto-scaling feature.
The configuration changes that you make to the core-site.xml file will not be included in automatically generated cluster nodes, as the cluster automatically grows you’d have to follow up by manually distributing the client configuration changes.
Two manual steps
Install the fusion client (the one for EMR) on each node and after scaling, modify the core-site.xml file with the following:
<property> <name>fusion.underlyingFs</name> <value>s3://YOUR-S3-URL/</value> </property> <property> <name>fs.fusion.server</name> <value>IP-HOSTNAME:8023</value> </property> <property> <name>fs.fusion.impl</name> <value>com.wandisco.fs.client.FusionHcfs</value> </property> <property> <name>fs.AbstractFileSystem.fusion.impl</name> <value>com.wandisco.fs.client.FusionAbstractFs</value> </property>
- fusion.underlyingFs
-
The address of the underlying filesystem. In the case of Elastic MapReduce FS, the
fs.defaultFSpoints to a local HDFS built on the instance storage which is temporary, with persistent data being stored in S3. Example:s3://wandisco. - fs.fusion.server
-
The hostname and request port of the Fusion server. Comma-separated list of hostname:port for multiple Fusion servers.
- fs.fusion.impl
-
The Abstract FileSystem implementation to be used.
- fs.AbstractFileSystem.fusion.impl
-
The abstract filesystem implementation to be used.
8.1.10. Known Issue running with S3
In WD Fusion 2.6.2 or 2.6.3, the first release supporting S3, there was a problem transferring very large files that needed to be worked around. If you are using this release in conjunction with Amazon’s S3 storage then you need to make the following changes:
WD Fusion 2.6.2/2.6.3/AWS S3 Workaround
Use your management layer (Ambari/Cloudera Manager, etc) to update the core-site.xml with the following property:
<property>
<name>dfs.client.read.prefetch.size</name>
<value>9223372036854775807</value>
</property>
<property>
<name>fs.fusion.push.threshold</name>
<value>0</value>
</property>
This second parameter “fs.fusion.push.threshold” becomes optional from version 2.6.3, onwards. Although optional, we still recommend that you use the "0" Setting. This property sets the threshold for when a client sends a push request to the WD Fusion server. As the push feature is not supported for S3 storage disabling it (setting it to "0") may remove some performance cost.
8.1.11. Known Issue when replicating data to S3 while not using the S3 Plugin
Take note that the Amazon DynamoDB NoSQL database holds important metadata about the state of the content that would be managed by EMR and Fusion in S3. Deleting or modifying this content on any level except the EMR filesystem libraries (e.g. by manually deleting bucket content) will result in that metadata becoming out of sync with the S3 content.
This can be resolved by either using the EMRFS CLI tool "sync" command, or by deleting the DynamoDB table used by EMRFS. See AWS’s documentation about EMRFS CLI Reference.
This is a manual workaround that should only be used when strictly necessary. Ideally, when using the EMRFS variant of Fusion to replicate with S3, you should not modify S3 content unless doing so via an EMR cluster.
S3 AMI Launch
This section covers the launch of WANdisco Fusion for S3, using Amazon’s Cloud Formation Template. What this will do is automatically provision the Amazon cluster, attaching Fusion to an on-premises cluster.
IMPORTANT: Amazon cost considerations.
Please take note of the following costs, when running Fusion from Amazon’s cloud platform:
AWS EC2 instances are charged per hour or annually.
WD Fusion nodes provide continuous replication to S3 that will translate into 24/7 usage of EC2 and will accumulate charges that are in line with Amazon’s EC2 charges (noted above).
When you stop the Fusion EC2 instances, Fusion data on the EBS storage will remain on the root device and its continued storage will be charged for. However, temporary data in the instance stores will be flushed as they don’t need to persist.
If the WD Fusion servers are turned off then replication to the S3 bucket will stop.
Prerequisites
There are a few things that you need to already have before you start this procedure:
-
Amazon AWS account. If you don’t have an AWS account, sign up through Amazon’s Web Services.
-
Amazon Key Pair for security. If you don’t have a Key Pair defined. See Create a Key Pair.
-
Ensure that you have clicked the Accept Terms button on the CFT’s download screen.
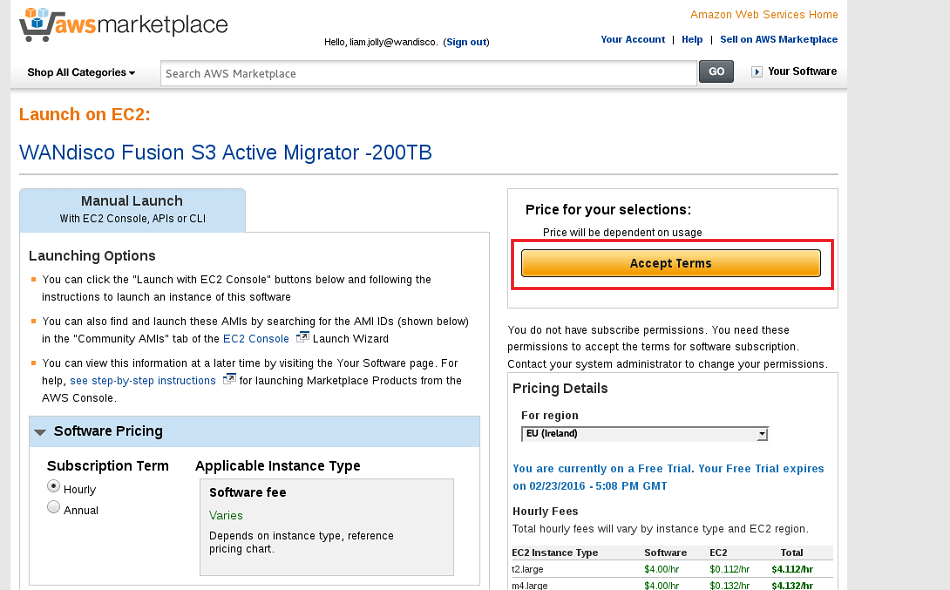
You must accept the terms for your specific version of Fusion
If you try to start a CFT without first clicking the Accept Terms button you will get an error and the CFT will fail. If this happens, go to the Amazon Marketplace, search for the Fusion download screen that correspond with the version that you are deploying, run through the screen until you have clicked the Accept Terms button. You can then successfully run the CFT.
Required IAM Roles
Here are a list of Identify and Access Management (IAM) roles that are required to be setup for a user to install Fusion on AWS without having used our CFT.
Within our CFT we create rules for S3 for validation of S3 buckets and also rules to allow modification of dynamoDB. You can use AWS managed policies to quickly get the permissions you require, though these permissions are very broad and may provide more access than is desired.
The 3 you need are:
-
AmazonS3FullAccess
-
AmazonEC2ReadOnlyAccess
-
AmazonDynamoDBFullAccess
Example Creation
The following example procedure would let you install WD Fusion without using our Cloud Formation Template (CFT) and would support the use of Multi-Factor Authentication (MFA).
-
Log onto the Amazon platform and create an IAM Policy.
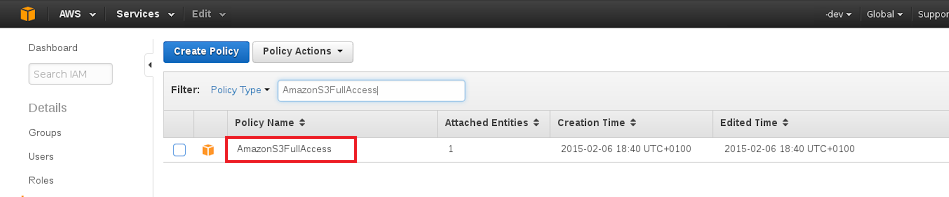 Figure 71. Create Policy
Figure 71. Create PolicyServices > IAM > Policies > Create Policy.
-
Give your policy a name and description. For policy document use the following;
{ "Version": "2012-10-17", "Statement": [ { "Sid": "Stmt1474466892000", "Effect": "Allow", "Action": [ "dynamodb:*" ], "Resource": [ "arn:aws:dynamodb:*:*:table/EmrFSMetadata" ] }, { "Sid": "Stmt1474467044000", "Effect": "Allow", "Action": [ "ec2:CreateTags", "ec2:DescribeHosts", "ec2:DescribeInstances", "ec2:DescribeTags" ], "Resource": [ "*" ] }, { "Sid": "Stmt1474467091000", "Effect": "Allow", "Action": [ "s3:ListAllMyBuckets" ], "Resource": [ "*" ] }, { "Sid": "Stmt1474467124000", "Effect": "Allow", "Action": [ "s3:GetBucketLocation", "s3:ListBucket", "s3:ListBucketMultipartUploads" ], "Resource": [ "arn:aws:s3:::<insert bucket name>" ] }, { "Sid": "Stmt1474467159000", "Effect": "Allow", "Action": [ "s3:DeleteObject", "s3:GetBucketLocation", "s3:GetObject", "s3:PutObject" ], "Resource": [ "arn:aws:s3:::<insert bucket name>/*" ] } ] }Just be sure to replace the <insert bucket here> with the name of the bucket you will ultimately be working with, in both locations shown above. Click create policy.
-
Create IAM Role
Services > IAM > Roles > Create New IAM Role
Give your role a name. -
Select Amazon EC2 when prompted, you will then have the list of IAM policies, you can filter it down to find the one that you created previously. Create the role.
-
Deploying the EC2 instance. As normal BUT when you are on the "Configure Instance" page you need to select your IAM role.
Bare Bones EC2 deployments
While the expected method for installing WD Fusion will be the use of a Cloud Formation Template through the Amazon marketplace, it is also possible to run a "bare bones" EC2 instance, running Fusion. In this case you need to add the following IAM roles so that it will work:
{
"Action": [
"aws-marketplace:MeterUsage"
],
"Effect": "Allow",
"Resource": "*"
},
8.2. Swift Installation
8.2.1. Installing into Openstack Swift storage
This section runs through the installation of WD Fusion into an Openstack environment using Swift storage.
We use Bluemix, the IBM cloud managed Swift solution, as an example but other implementations are available.
Currently this deployment is limited to an active-passive configuration that would be used to ingest data from your on-premises cluster to your Swift storage.
8.2.2. Pre-requisites
Before you begin an installation you need to have a Bluemix (or equivalent) account with container(s) set up. This guide runs through installing WD Fusion and using it with Bluemix, but not how to set up Bluemix.
Make sure that you have the following directories created and suitably permissioned. Examples:
|
Important! For installations to Swift storage, we currently only support Keystone 3.0. |
|
"JAVA_HOME could not be discovered" error
You need to ensure that the system user that is set to run Fusion has the JAVA_HOME variable set. Installation failures that result in a message "JAVA_HOME could not be discovered" are usually caused by the specific WAND_USER account not having JAVA_HOME set. In WD Fusion 2.10.x
From WD Fusion 2.11 |
8.2.3. Overview
The installation process runs through the following steps:
-
On-premises installation - installing a WD Fusion node on your cluster
-
Swift storage node installation - the second node can be installed onto a VM situated on OpenStack, or Bluemix.
-
Setting up replication - Configure the nodes to ingest data from the on-premises cluster to the OpenStack Swift storage.
-
Silent Installation - Notes on automating the installation process.
-
Parallel Repairs - Running initial repairs in parallel.
8.2.4. On-premise installation of WD Fusion for use with Swift
Follow the first few steps given in the On-premises installation guide.
Make sure that you use a Swift specific installer, for example fusion-ui-server-swt_rpm_installer.sh.
Once the fusion-ui-server has started, follow the steps below to configure WD Fusion with Swift through the browser.
8.2.5. Install Node for Swift storage
Follow this section to complete the installation by configuring WD Fusion on a server that will place data that is replicated from your on-premises cluster to your Bluemix/OpenStack Swift storage. This second node can also be on-premises or co-located with your OpenStack platform.
Open a web browser and point it at the provided URL. e.g
http://<YOUR-SERVER-ADDRESS>.com:8083/
-
In the first "Welcome" screen you’re asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows:- Adding a new WD Fusion cluster
-
Select Add Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
-
Select Add to an existing Zone.
Figure 72. Welcome screen
-
Run through the installer’s detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
Figure 73. Environmental checks -
On clicking Validate the installer will run through a series of checks of your system’s hardware and software setup and warn you if any of WD Fusion’s prerequisites are not going to be met.
Figure 74. Example check resultsAddress any failures before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if the installation is only for evaluation purposes and not for production. However, when installing for production, you should address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
-
Select your license file and upload it.
Figure 75. Upload your license fileThe conditions of your license agreement will be shown in the top panel.
-
In the lower panel is the EULA.
Figure 76. Verify license and agree to subscription agreementTick the checkbox I agree to the EULA to continue, then click Next Step.
-
Enter settings for the WD Fusion server. See WD Fusion Server for more information about what is entered during this step.
Figure 77. Server information -
Enter the settings for the IHC Server. See the on premise install section for more information about what is entered during this step.
Figure 78. IHC Server information -
Next, you will enter the settings for your new Node.
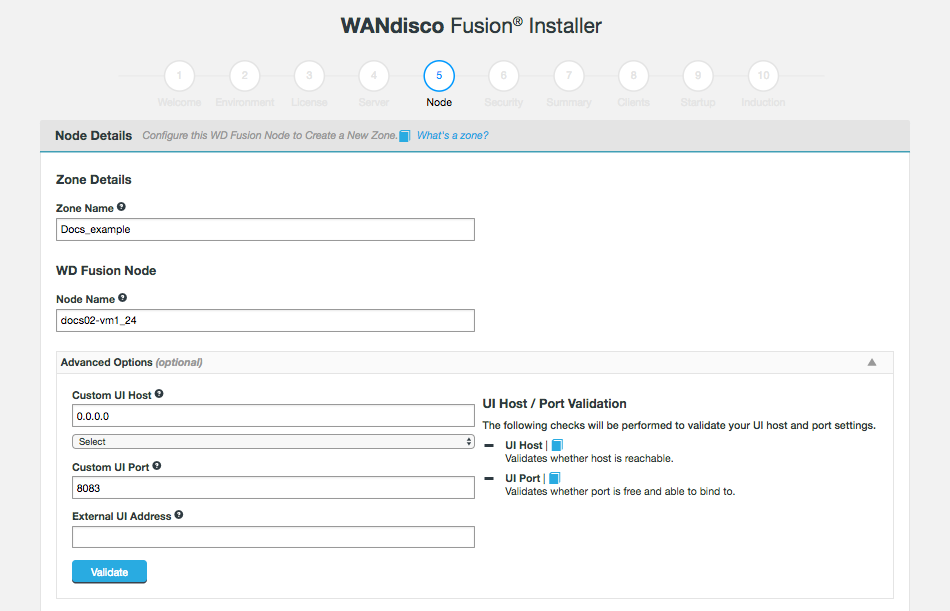 Figure 79. Zone information
Figure 79. Zone information- Zone Name
-
Give your zone a name to allow unique identification of a group of nodes.
- Node Name
-
A unique identifier that will help you find the node on the UI.
There are also advanced options but only use these if you fully understand what they do:
- Custom UI Host
-
Enter your UI host or select it from the drop down below.
- Custom UI Port
-
Enter the port number for the Fusion UI.
- External UI Address
-
The address external processes should use to connect to the UI on.
Once these details are added, click Validate.
-
In the lower panel enter your Swift information
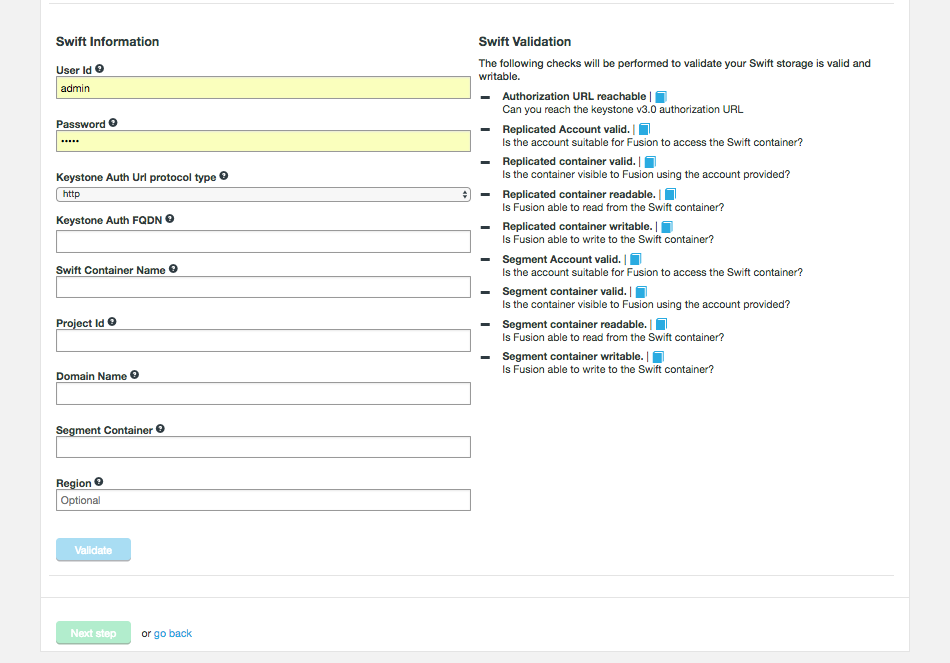 Figure 80. Swift Install Information
Figure 80. Swift Install InformationSome of the required information can be gathered from the Bluemix UI (or other Swift Implementation), in the Service Credentials section:
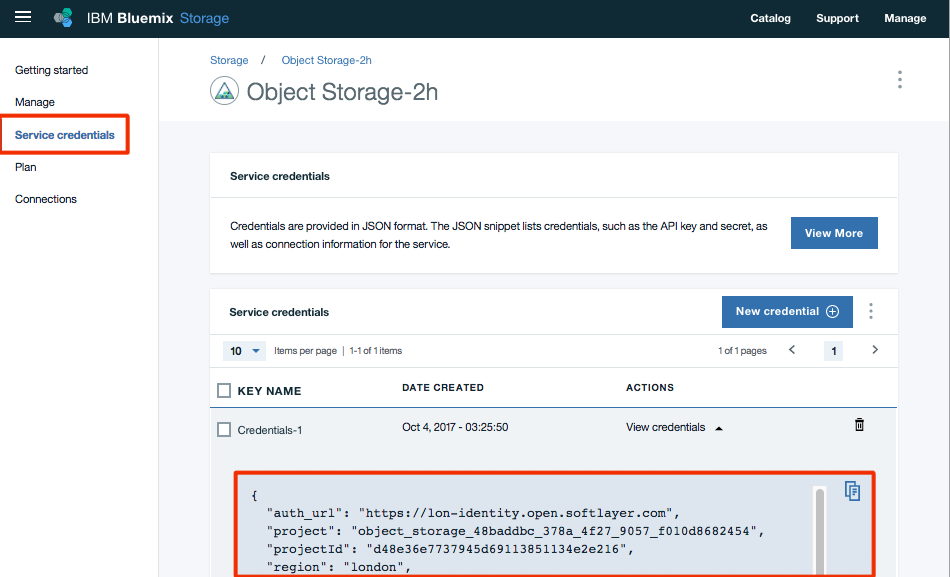 Figure 81. Bluemix Credentials
Figure 81. Bluemix Credentials- User ID
-
The unique ID for the Bluemix/Swift user.
- Password
-
The password for the Bluemix/Swift user.
Swift password changes
During installation, the Bluemix/Swift password is encrypted for use with WD Fusion. This process doesn’t require any further interaction except for the case where the Swift password is changed. If you change your Swift password you need to do the following:-
Open a terminal to the WD Fusion node and navigate to /opt/wandisco/fusion/server.
-
Run the following script:
./encrypt-password.sh Please enter the password to be encrypted
Enter your Bluemix/Swift password and press return:
> password eCefUDtgyYczh3wtX2DgKAvXOpWAQr5clfhXSm7lSMZOwLfhG9YdDflfkYIBb7psDg3SlHhY99QsHlmr+OBvNyzawROKTd/nbV5g+EdHtx/J3Ulyq3FPNs2xrulsbpvBb2gcRCeEt+A/4O9K3zb3LzBkiLeM17c4C7fcwcPAF0+6Aaoay3hug/P40tyIvfnVUkJryClkENRxgL6La8UooxaywaSTaac6g9TP9I8yH7vJLOeBv4UBpkm6/LdiwrCgKQ6mlwoXVU4WtxLgs4UKSgoNGnx5t8RbVwlrMLIHf/1MFbkOmsCdij0eLAN8qGRlLuo4B4Ehr0mIoFu3DWKuDw== [ec2-user@ip-172-29-0-158 server]$
-
Place the re-encrypted password in *core-site.xml* and *application.properties*.
-
- Auth URL
-
The URL required for authenticating against Swift.
- Swift Container Name
-
The name of the Swift storage container that Fusion will be connecting to.
- Project Id
-
The Bluemix project ID.
- Domain Name
-
The Swift Domain Name.
- Segment Container
-
The name of the Segment container. The Segment container is used where large files break Swift’s 5GB limit for object size. Objects that exceed 5GB are broken into segments and get stored in here.
- Region
-
The Swift Object Storage Region. Not to be confused with the Bluemix region.
Once you have entered this information click Validate.
The following Swift properties are validated:
- Authorization URL reachable
-
Can you reach the keystone v3.0 authorization URL
- Account valid
-
The installer checks that the Swift account details are valid. If the validation fails, you should recheck your Swift account credentials.
- Container valid
-
The installer confirms that a container with the provided details exists. If the validation fails, check that you have provided the right container name.
- Container readable
-
The container is checked to confirm that it can be read. If the validation fails, check the permissions on the container.
- Container writable
-
The container is checked to confirm that the container can be written to. If the validation fails, check the permissions on the container.
The installer checks that the Swift account details are valid for accessing the segment container. If the validation fails, you should recheck your Swift account credentials.
- Segment Container valid
-
The installer confirms that a segment container with the provided details exists. If the validation fails, check that you have provided the right segment container name.
- Segment Container readable
-
The container is checked to confirm that it can be read. If the validation fails, check the permissions on the segment container.
- Segment Container writable
-
The container is checked to confirm that the container can be written to. If the validation fails, check the permissions on the segment container.
- Segment Account writable
-
The Account is checked to confirm that it can be written to. If the validation fails, check the permissions on the segment account.
If everything is successfully validated, click Next step.
-
Authentication credentials that will be used to access the WD Fusion UI. When deploying WD Fusion under a Hadoop management layer such as Cloudera Manager or Ambari, you would use the same credentials as the said manager. In this case we’re running without a separate manager, so we need to provide our own username and password.
Figure 82. Security- Username
-
A username that will be used for accessing the WD Fusion.
- Password
-
The corresponding password for use with the username, when logging into the WD Fusion UI.
-
The summary screen lists all the configuration that has been entered so far, during the installation. You can check your entries by clicking on each category on the left-side menu. If it is all correct, click Next Step.
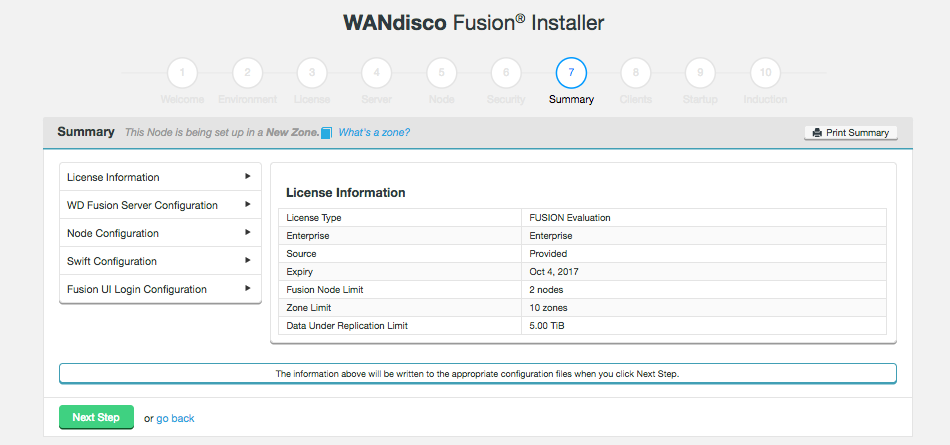 Figure 83. Summary
Figure 83. Summary -
You can ignore the next step. Click Next Step. This step is reserved for deployments where HDFS clients need to be installed. These are not required when using WD Fusion to replicate data into a cloud storage solution.
 Figure 84. Clients
Figure 84. Clients -
It’s now time to start up the WD Fusion server. Click Start WD Fusion.
 Figure 85. Startup
Figure 85. StartupThe WD Fusion server will now start up.
-
If you have existing nodes you can induct them now. If you would rather induct them later, click Skip Induction.
Induction will connect this second node to your existing "on-premises" node. When adding a node to an existing zone, users will be prompted for zone details at the start of the installer and induction will be handled automatically. Nodes added to a new zone will have the option of being inducted at the end of the install process where the user can add details of the remote node.
Figure 86. InductionIf you are inducting now, enter the following details then Click Start Induction.
- Fully Qualified Domain Name
-
The full address of the existing on-premises node.
- Fusion Server Port
-
The TCP Port on which the on-premises node is running. Default:8082.
8.2.6. Setting up replication
It’s now time to demonstrate data replication between the on-premises cluster and the Bluemix / Swift storage. First we need to perform a synchronization to ensure that the data stored in both zones is in exactly the same state.
Synchronization
The following guide covers the replication from on-premises to the Bluemix/Swift node.
-
Log in to the on-premises WD Fusion UI and click on the Replication tab. Then click + Create to set up a folder.
 Figure 87. Create replication rule
Figure 87. Create replication rule -
Click on the Create button to set up a rule.
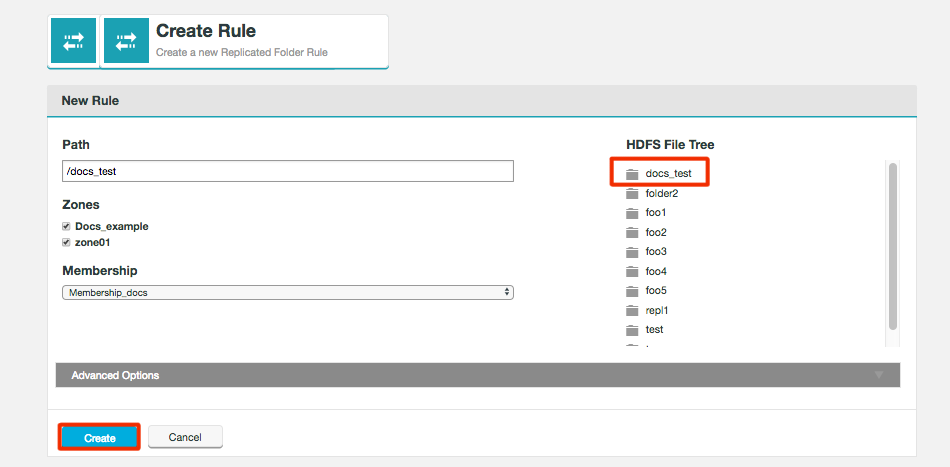 Figure 88. Create rule
Figure 88. Create ruleNavigate the File Tree, on the right-hand side of the New Rule panel and select the folder you wish to replicate. The selected folder will appear in the Path entry field. You can, instead, type or copy in the full path to the folder in the Path directory.
Next, select both zones from the Zones list and select the Membership.
More about Membership
Read about Membership in the WD Fusion User Guide - Managing Replication.Files not appearing in the File TreeIf you are using the Swift command line client to upload files it is possible to place a file in a subdirectory that isn’t mapped to the file system. While this works internally, folders that exist in this state will not be visible to WD Fusion and so cannot be replicated.
Workaround
If you do use the command line client then to ensure that folders are visible in the File Tree:-
Files must slash separated
-
There must be a trailing slash e.g.
swift upload [container name] [directory name]"/"
Click Create to continue.
-
-
When you first create the rule you may notice status messages indicating that the system is preparing for replication. Wait until all pending messages are cleared before moving to the next step.
-
Once set up it is likely that the file replicas between both zones will be in an inconsistent state, in that you will have files on the local (on-premises) zone that do not yet exist in the Swift store. Click on the Not checked button to open the Consistency Check screen.
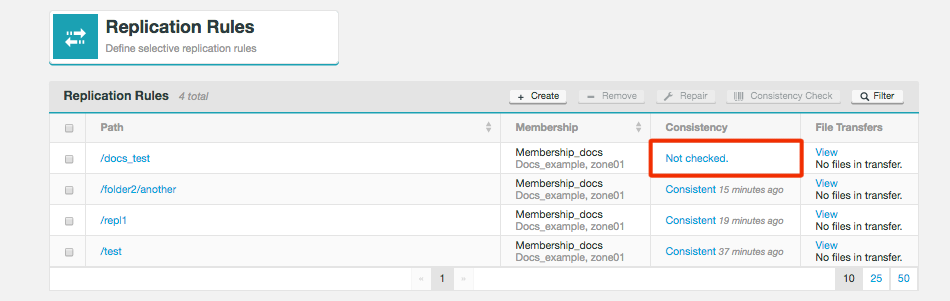 Figure 89. Consistency not yet checked
Figure 89. Consistency not yet checked -
Click Trigger new check to check for inconsistencies. The consistency report will appear once the check is complete. It shows the number of inconsistencies that need correction.
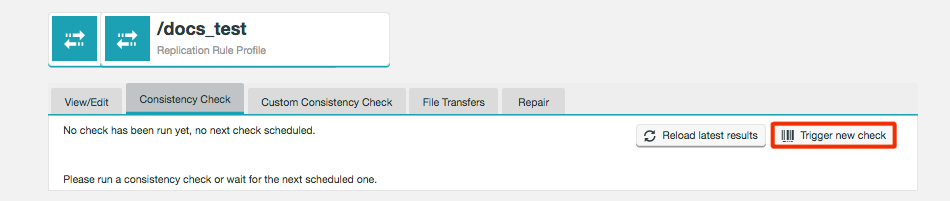 Figure 90. Trigger consistency check
Figure 90. Trigger consistency check -
We will use the Bulk resolve inconsistencies option here to repair but see Running initial repairs in parallel for more information on improving the performance of your first sync and resolving individual inconsistencies if you have a small number of files that might conflict between zones.
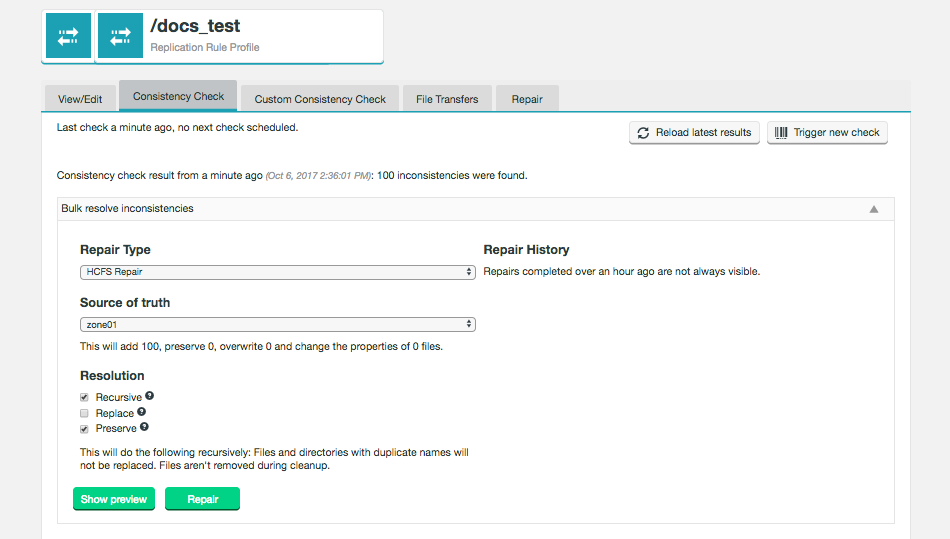 Figure 91. Resolve inconsistencies
Figure 91. Resolve inconsistenciesSelect your repair type and source of truth, in this case the current zone. Tick the appropriate resolution check boxes. Here we use Recursive and also Preserve so that files are not deleted if they don’t exist in the source zone. For more information see the Consistency check section.
Click Repair to begin the file transfer process. -
Now we need to verify the file transfers were successful. First, log in to the WD Fusion UI on the Swift/Bluemix cluster. Click on the Replication tab and in the File Transfers column, click the View link.
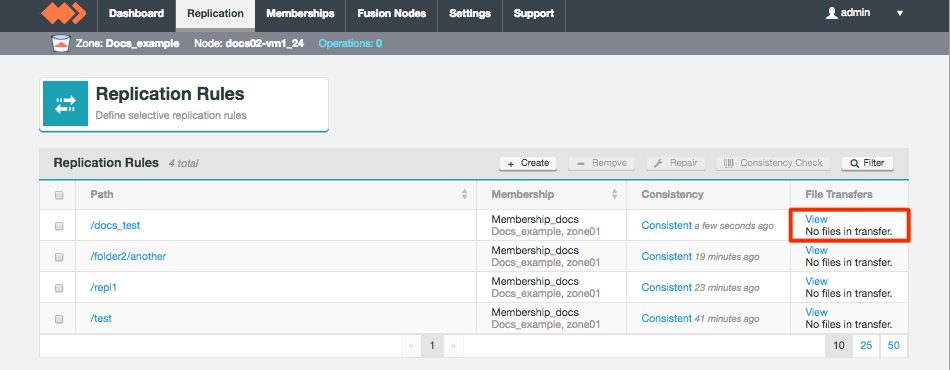 Figure 92. View transferred files
Figure 92. View transferred files -
By ticking the boxes for each status type, you can view files that are:
-
In progress
-
Incomplete
-
Complete
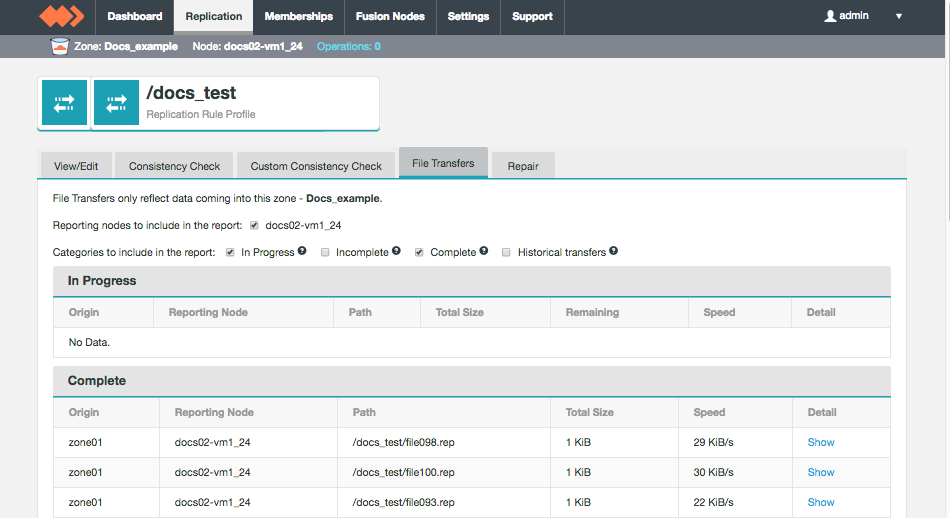 Figure 93. Transferred files
Figure 93. Transferred filesConfirm that all your files have transferred.
No transfers in progress?
You may not see files in progress if they are very small, as they tend to clear before the UI polls for in-flight transfers.
-
-
Congratulations! You have successfully installed, configured, replicated and monitored data transfer with WANdisco Fusion.
8.2.7. Swift Silent Installation
You can complete a Swift installation using the Silent Installation procedure, putting the necessary configuration in the swift_silent_installer.properties and swift_silent_installer_env.sh as described in the section that covers Silent Installation.
Swift-specific settings
The following environment variables required for Swift deployments.
############################### # Swift Configuration ############################### #Swift installation mode # REQUIRED for Swift Installations. Defaults to false swift.installation.mode=true #The Swift container name to use # REQUIRED for Swift installations. swift.containerName= #The Swift userID to use to use # REQUIRED for Swift installations. swift.userID= #The Swift password to use # REQUIRED for Swift installations. swift.password= #Use HTTPS with the swift auth url # REQUIRED for Swift installations. swift.useHttps=false #The Swift fully qualified domain name to use for authenticating access to the storage # REQUIRED for Swift installations. swift.auth.url= # The Swift domain name to use # REQUIRED, for Swift installations. swift.domainName= # The Swift project id to use # REQUIRED, for Swift installations. swift.projectId= # The Swift file segment container to use # REQUIRED, for Swift installations. swift.segment.container= # The Swift region to use # OPTIONAL for Swift installations. # swift.region # The Swift buffer directory to use # OPTIONAL for Swift installations, defaults to /tmp. # swift.buffer.dir= # The Swift to use # OPTIONAL for Swift installations, defaults to 5368709120 bytes, max 5368709120. # swift.segment.size= ############################### # Management Endpoint section ############################### #The type of Management Endpoint. management.endpoint.type=UNMANAGED_SWIFT
In the swift_silent_installer_env.sh:
-
FUSIONUI_INTERNALLY_MANAGED_USERNAME -
FUSIONUI_INTERNALLY_MANAGED_PASSWORD -
FUSIONUI_FUSION_BACKEND_CHOICE -
FUSIONUI_USER -
FUSIONUI_GROUP -
SILENT_PROPERTIES_PATH
Example Installation
As an example (as root), running on the installer moved to /tmp.
# If necessary download the latest installer and make the script executable chmod +x /tmp/installer.sh # You can reference an original path to the license directly in the silent properties but note the requirement for being in a location that is (or can be made) readable for the $FUSIONUI_USER # The following is partly for convenience in the rest of the script cp /path/to/valid/license.key /tmp/license.key # Create a file to encapsulate the required environmental variables: cat <<EOF> /tmp/swift_silent_installer_env.sh export FUSIONUI_MANAGER_TYPE=UNMANAGED_SWIFT export FUSIONUI_INTERNALLY_MANAGED_USERNAME=admin export FUSIONUI_FUSION_BACKEND_CHOICE= export FUSIONUI_USER=hdfs export FUSIONUI_GROUP=hdfs export SILENT_PROPERTIES_PATH=/tmp/swift_silent.properties export FUSIONUI_INTERNALLY_MANAGED_PASSWORD=admin EOF # Create a silent installer properties file - this must be in a location that is (or can be made) readable for the $FUSIONUI_USER: cat <<EOF > /tmp/swift_silent_installer_env.sh existing.zone.domain= existing.zone.port= license.file.path=/tmp/license.key server.java.heap.max=4 ihc.server.java.heap.max=4 fusion.domain=my.s3bucket.fusion.host.name fusion.server.dcone.port=6444 fusion.server.zone.name=twilight swift.installation.mode=true swift.container.name=container-name induction.skip=false induction.remote.node=my.other.fusion.host.name induction.remote.port=8082 EOF # If necessary, (when $FUSIONUI_GROUP is not the same as $FUSIONUI_USER and the group is not already created) create the $FUSIONUI_GROUP (the group that our various servers will be running as): [[ "$FUSIONUI_GROUP" = "$FUSIONUI_USER" ]] || groupadd hadoop #If necessary, create the $FUSIONUI_USER (the user that our various servers will be running as): useradd hdfs if [[ "$FUSIONUI_GROUP" = "$FUSIONUI_USER" ]]; then useradd $FUSIONUI_USER else useradd -g $FUSIONUI_GROUP $FUSIONUI_USER fi # silent properties and the license key *must* be accessible to the created user as the silent installer is run by that user chown hdfs:hdfs $FUSIONUI_USER:$FUSIONUI_GROUP /tmp/s3_silent.properties /tmp/license.key # Give s3_env.sh executable permissions and run the script to populate the environment . /tmp/s3_env.sh # If you want to make any final checks of the environment variables, the following command can help - sorted to make it easier to find variables! env | sort # Run installer: /tmp/installer.sh
8.2.8. Running checks and repairs
In the next step you should complete any necessary repairs to file consistency between your two clusters. Follow the steps provided in the following sections:
-
Running initial repairs in parallel
-
this will use the API to perform rapid repairs by running processes on multiple directories at the same time.
-
-
-
uses the Custom Consistency Check tool to select specific directories to check and repair.
-
|
Important: No repair to Swift
In version 2.10.3 or earlier, it wasn’t possible to run a consistency repair on files stored in a Swift Zone. This issue was fixed in WD Fusion 2.10.4.
|
8.2.9. How Swift handles large files
Swift containers can appear to have a file-size discrepancy, looking smaller than the sum of their stored files. The reason for this apparent discrepancy is given below.
Files that are smaller than the segment size of a container are, predictably, stored directly to the container - as would be expected. However, large files that are bigger than the container’s segment size are actually stored in a companion container that is used for segments and has the same name as the parent container with the suffix "_segments". Segmented files appear in the main container, although these are empty manifest objects that symlink to the segments that correspond to the file in question.
So, for measuring the actual volume of data stored in a Swift container, you must also take into account the size of the corresponding segment’s container.
Impact on Fusion replication
WD Fusion uses the same rules when replicating to Swift, and so provides configuration parameters for the ContainerName, SegmentContainerName and Segment Size for files uploaded via replication. Clearly, decreasing segmentSize for a container could increase the apparent storage size discrepancy, as more file content is actually stored in the segment container.
8.3. Microsoft Azure Installation
This section covers how WD Fusion can be used with Microsoft’s Cloud platform. Currently the following options are available:
-
Installing Fusion via the Azure marketplace - Azure - Install WD Fusion Server on HDInsight
-
Installing Fusion HDI App - Azure - HDInsight client installation
-
Installing Fusion onto Azure cloud (old method) - Azure On-premises Installation
|
Set fs.azure.enable.append.support
In core-site.xml you must set fs.azure.enable.append.support to true to be able to replicate files larger than 4MB.
|
8.3.1. Install WD Fusion Server on HDInsight
These instructions cover the set up of a WD Fusion server on Microsoft’s cloud-based Hadoop platform, HDInsight. This component is required for replicating data from on-premises to your Azure storage. If you intend to replicate in both directions, both to and from your cloud storage, you will also need to install the Fusion HDI App client.
In order to complete this procedure you will need an Azure subscription and familiarity with the Azure platform.
-
Find and select the WANdisco Fusion Server.
 Figure 94. Azure - Store
Figure 94. Azure - Store -
Under the Resource Manager deployment model, Click Create.
 Figure 95. Azure - Store
Figure 95. Azure - Store -
The first step is to enter the "Basic" settings that relate to your Azure platform.
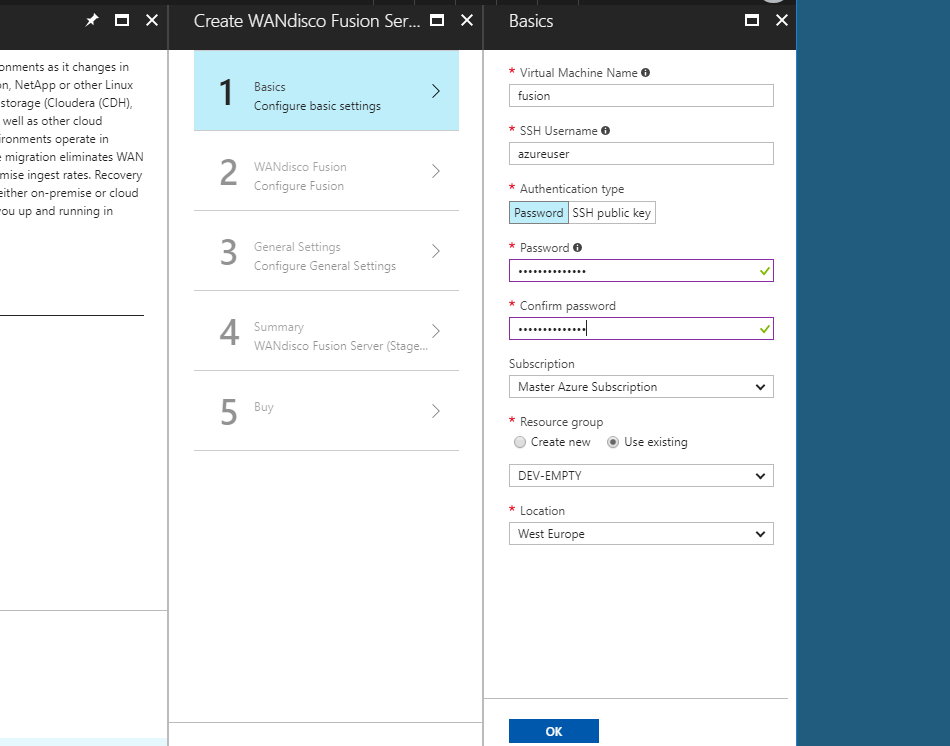 Figure 96. Azure - configure basic settings
Figure 96. Azure - configure basic settings- Virtual Machine Name
-
A name of the virtual machine that will be used to host WD Fusion server.
- SSH Username
-
SSH username for the virtual machine.
- Authentication type
-
Select the type of authentication that you wish to use: Password or SSH public key.
- Password
-
a password for use on the new VM.
- Confirm Password
-
Repeated entry of your password.
- SSH public key
-
In production you may prefer to use an SSH key. If you select SSH public key as your authentication type, enter your public key into this box. See below.
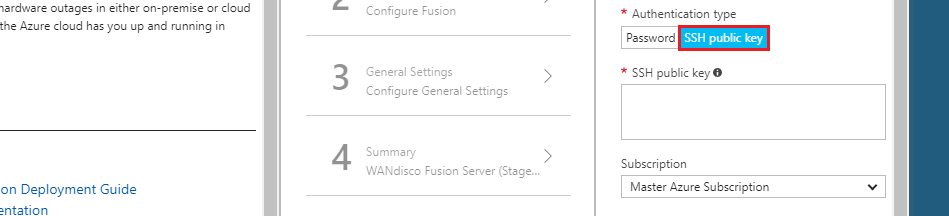 Figure 97. Azure - SSH public key
Figure 97. Azure - SSH public key - Subscripton
-
Select Master Azure Subscription.
- Resource group
-
Create new / Use existing.
- Location
-
West Europe.
Click OK
-
On the next panel you enter the details that relate to your WANdisco Fusion server settings.
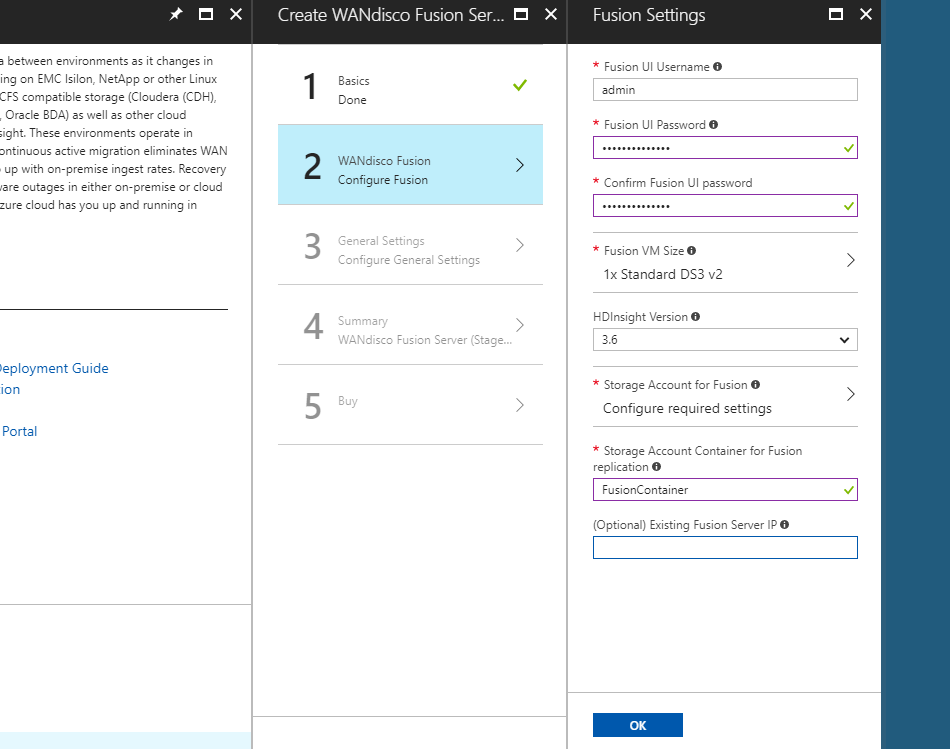 Figure 98. Azure - Configure Fusion
Figure 98. Azure - Configure Fusion- Fusion UI Username
-
Fusion UI administrator account name. "admin" by default.
- Fusion UI Password
-
Fusion UI password.
- Confirm Fusion UI Password
-
Repeat your entry of the password.
- Fusion VM Size
-
Virtual machine size for Fusion Server.
- HDInsight Version
-
Select HDInsight cluster version that you will be using with this WANdisco Fusion server. Currently, only 3.6.
- Storage Account for Fusion
-
Configure required settings for VM’s storage.
Figure 99. Azure - Storage Account - Storage Account Container for Fusion replication
-
Enter the name of the container o synchronize with, within the storage account selected above.
- (Optional) Existing Fusion Server IP
-
Hostname or IP of an existing Fusion Server node which the newly installed node will link/induct to (leave blank to skip automatic node linking/induction).
Click OK to continue.
-
Next, enter the General Settings.
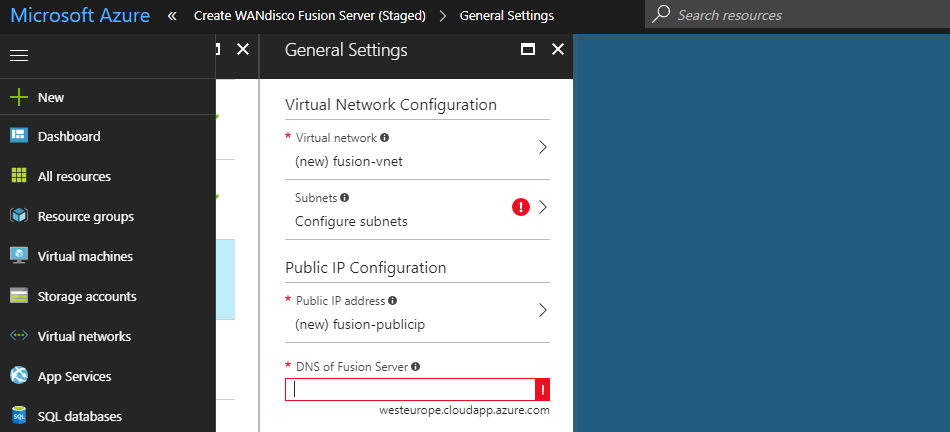 Figure 100. Azure - General Settings
Figure 100. Azure - General Settings -
Click on Configure subnets if you need to modify the default values.
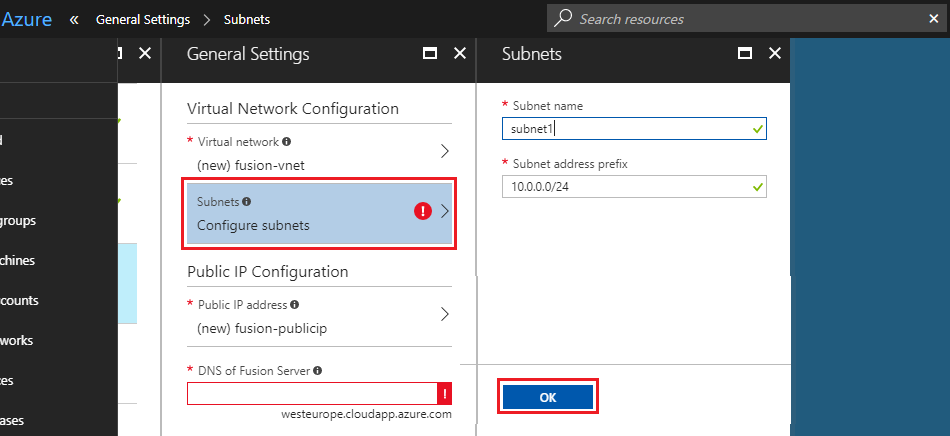 Figure 101. Azure - Subnets
Figure 101. Azure - Subnets- Subnet name
-
The name assigned to the subnet. the subnet name must be unique within the virtual network.
- Subnet address prefix
-
Single address prefix that makes up the subnet in CIDR notation. Must be a single CIDR block that is part of one of the VNet’s address spaces.
-
Complete the General settings by checking the Public IP Configuration and entering a valid subdomain name for the Fusion server’s DNS service.
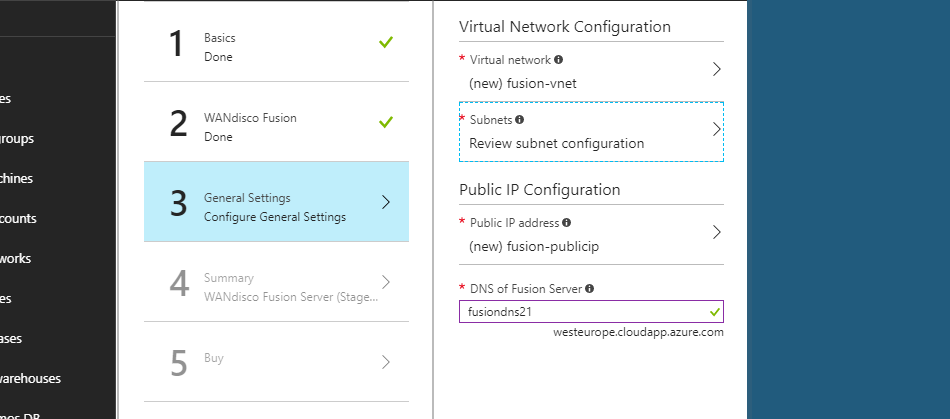 Figure 102. Azure - DNS of Fusion Server
Figure 102. Azure - DNS of Fusion Server -
The Summary will now show all the entries that you have provided so far. Click on OK to continue.
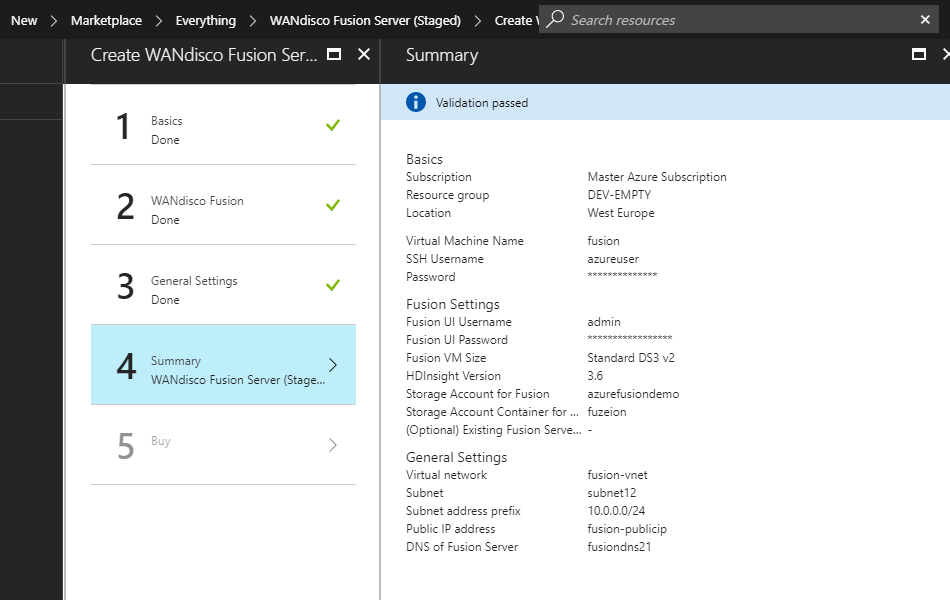 Figure 103. Azure - Summary
Figure 103. Azure - Summary -
On the next step you must read the terms of use and confirm acceptance but clicking on the Purchase button.
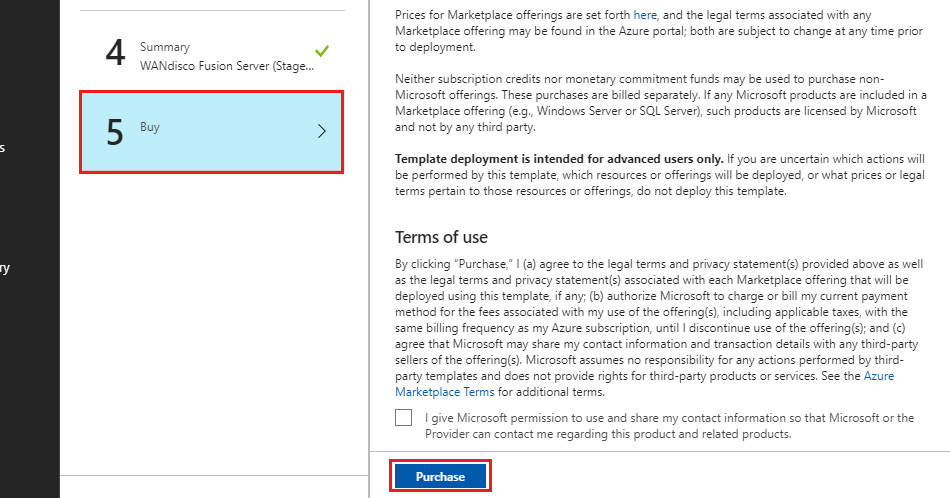 Figure 104. Azure - Buy
Figure 104. Azure - BuyThe installation is now complete.
8.3.2. HDInsight client installation
These instructions cover the installation of the Fusion Client for Ambari. This component is required for deployments that require active-active replication, where data changes that occur in the cloud must also be applied to the on-premises cluster.
|
Important!
You MUST use the same storage account and container that was selected when you installed the WD Fusion server.
|
-
From the Azure Market place, select WANdisco Fusion HDI app.
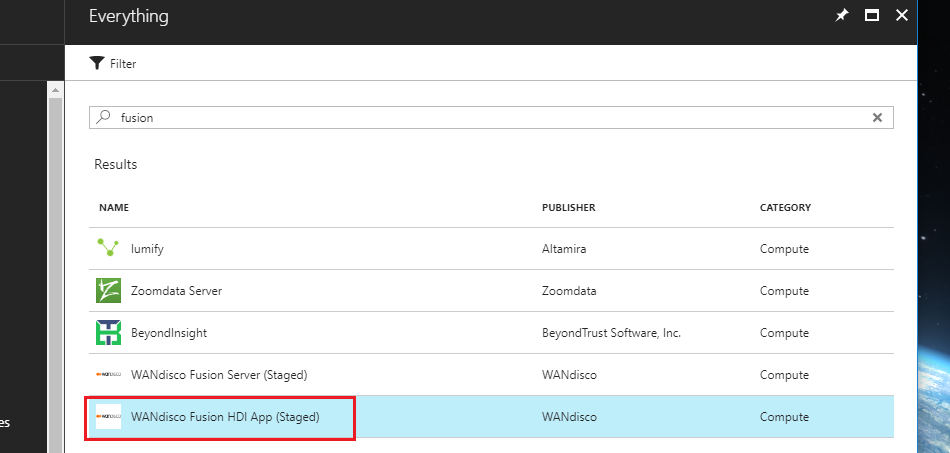 Figure 105. Azure - HDI App
Figure 105. Azure - HDI App -
The deployment model is loacked at Resource Manager. Click the Create button.
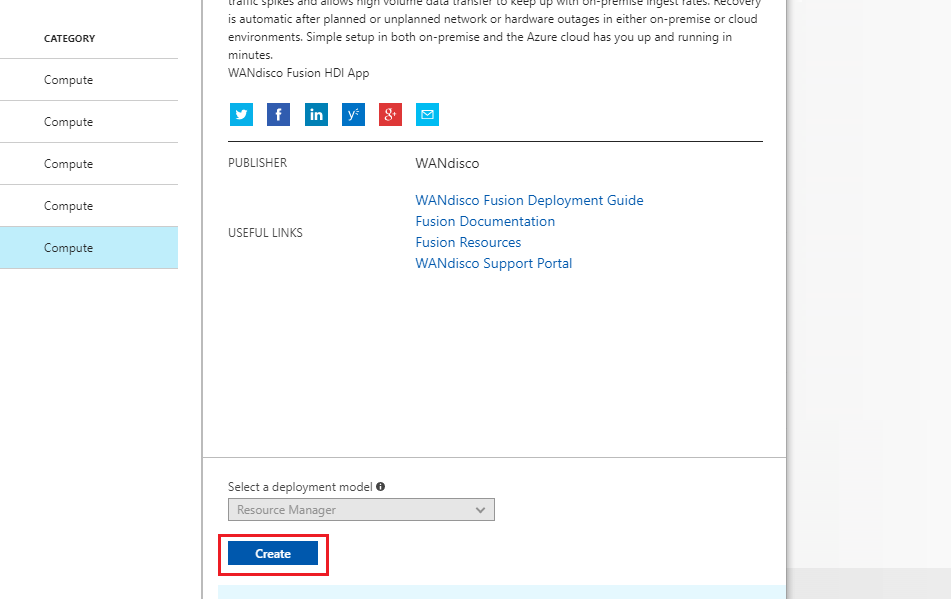 Figure 106. Azure - Resource Manager
Figure 106. Azure - Resource Manager -
The Basics panel will appear. Use the Quick create tab, filling the entry fields as follows:
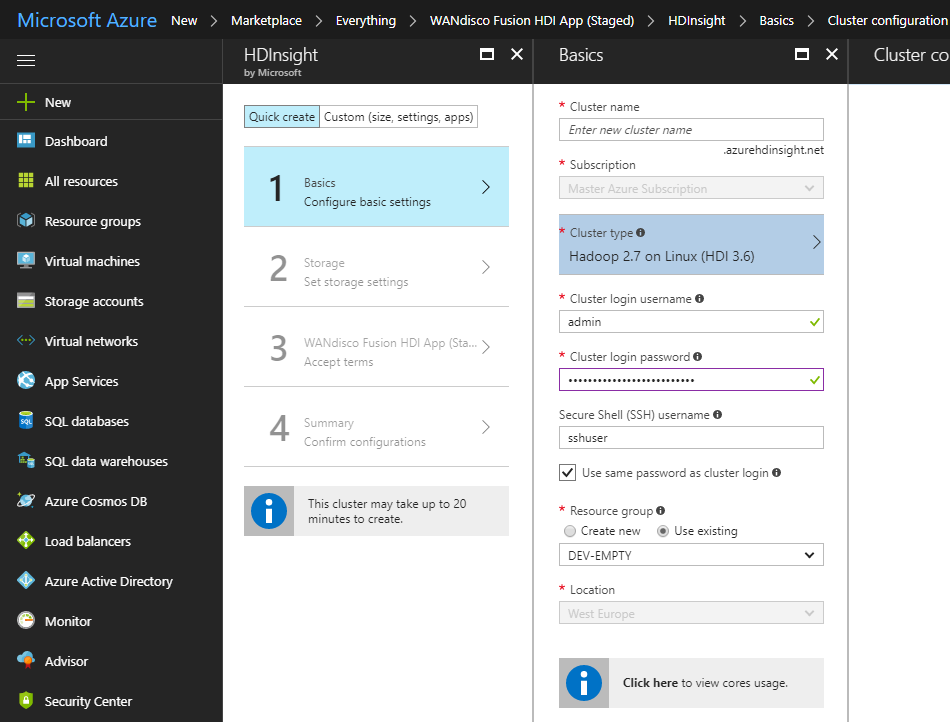 Figure 107. Azure - Basics
Figure 107. Azure - Basics- Cluster name
-
Give the Cluster a name.
- Subscription
-
Subscription is locked to the Master Azure Subscription.
- Cluster type
-
Select the Cluster type, e.g. Hadoop.
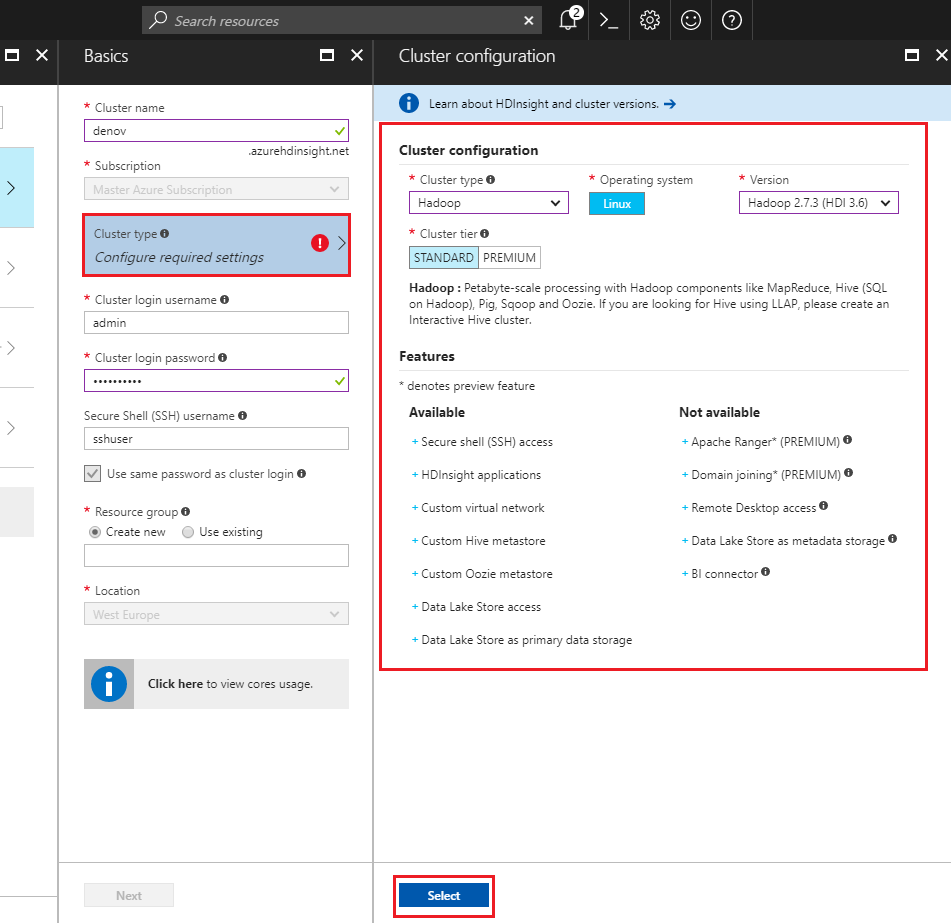 Figure 108. Azure - Cluster configuration
Figure 108. Azure - Cluster configuration - Cluster login username
-
Cluster login credentials can be used to submit jobs and log in to cluster dashboards.
- Cluster login password
-
The SSH password will expire in 70 days. To avoid this you can use an SSH public key instead.
- Secure Shell (SSH) Username
-
SSH credentials can be used to remotely access the cluster.
- User same password as cluster login (checkbox)
-
Sets the credentials to those used for the cluster.
- Resource Group
-
A resource group is a collection of resources that share the same lifecycl, premissions, and policies. In this case, select use existing, then pick an empty group from the dropdown.
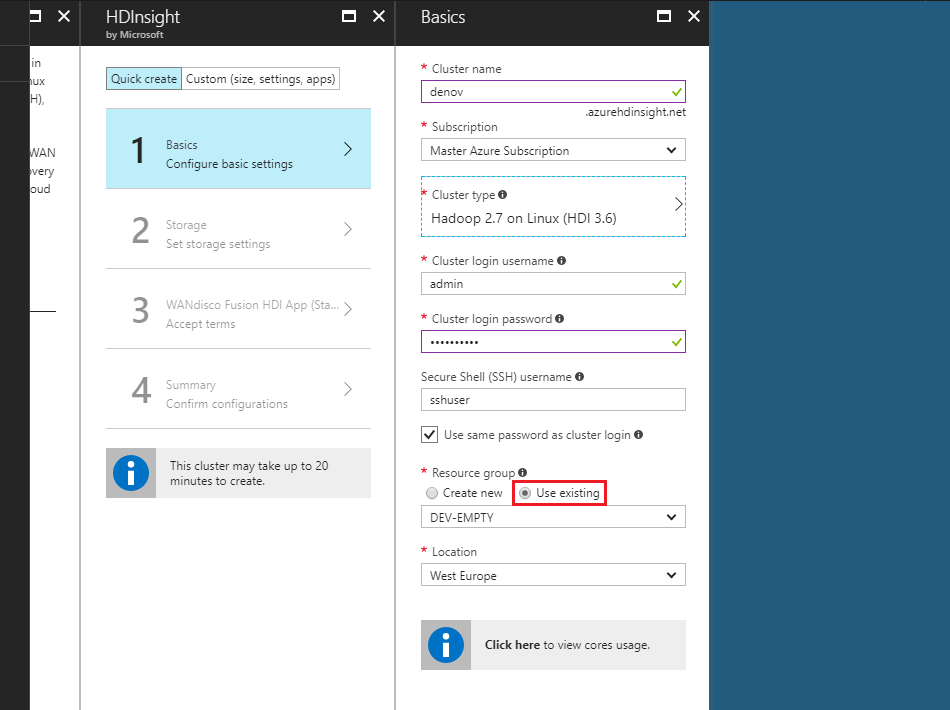 Figure 109. Azure - Resource group
Figure 109. Azure - Resource group - Location
-
The location setting ensures that, for compliance reasons, the cluster’s metadata is located in the appropriate reason.
-
This section covers the storage requirements for the cluster.
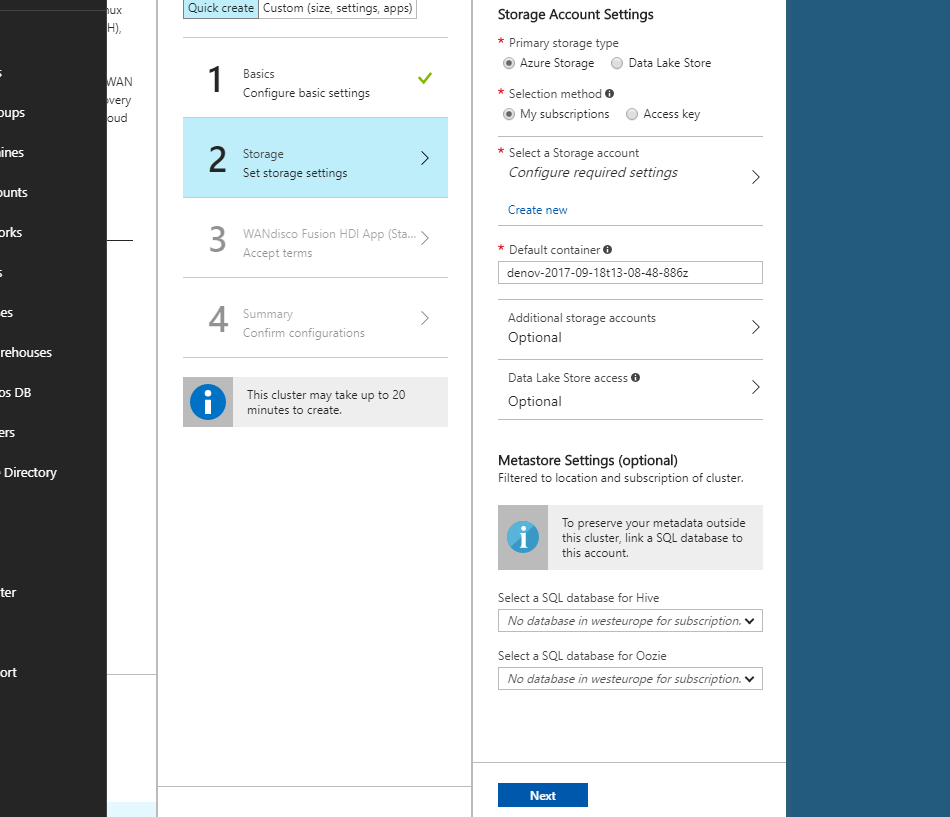 Figure 110. Azure - Storage Account Settings
Figure 110. Azure - Storage Account Settings- Primary storage type
-
Azure Storage.
- Selection method
-
Select My subscription.
- Select a Storage account
-
Click to select a storage account from a new panel.
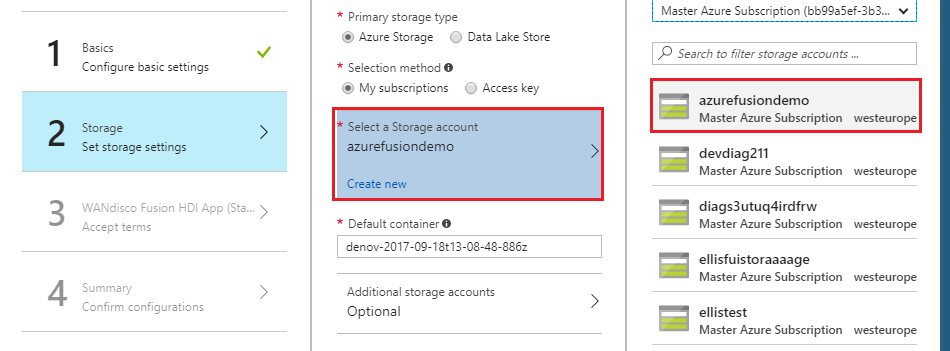 Figure 111. Azure - Select a Storage account
Figure 111. Azure - Select a Storage account
-
Check the rest of the cluster storage settings, then click Next.
 Figure 112. Azure - Storage Account Settings
Figure 112. Azure - Storage Account Settings -
In this step you need to accept the terms of use for the selected app. Click on the panel marked WANdisco Fusion HDI App (Staging).
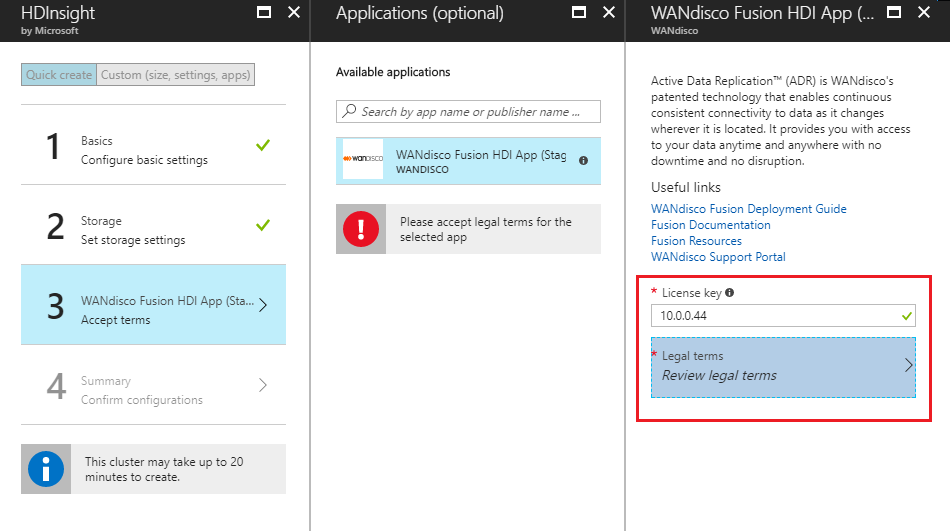 Figure 113. Azure - IP and Legal terms
Figure 113. Azure - IP and Legal terms- License key
-
This is the existing Fusion Server IP address or hostname. The Fusion server must be in the same VNet as this HDInsight cluster AND pointing to the same storage account and container.
-
Click on Legal terms, read the Terms of use and then click on Purchase.
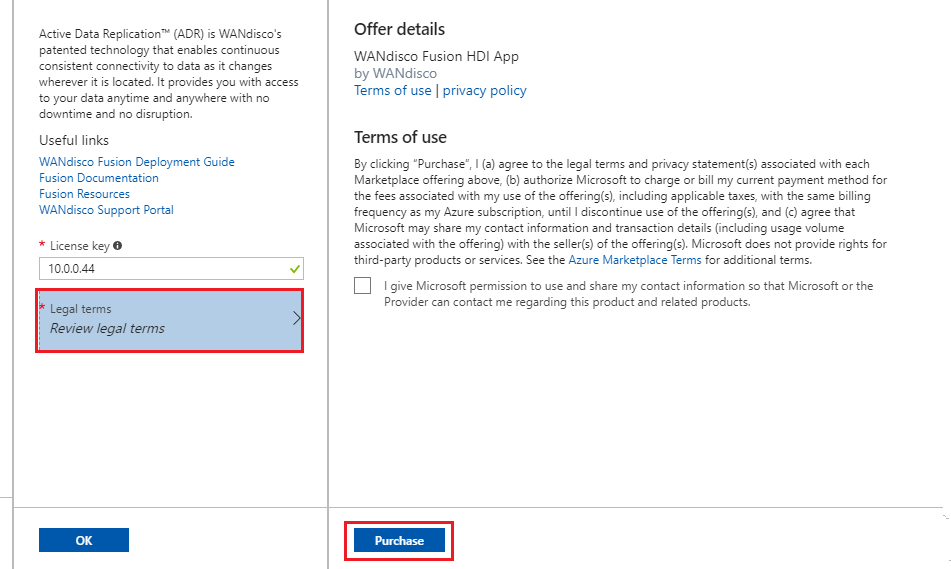 Figure 114. Azure - Purchase
Figure 114. Azure - PurchaseThe cluster will now build. Take note that the process may take up to 20 minutes to complete.
8.3.3. On-premises Installation
This section will run you through an installation of WANdisco’s Fusion to enable you to replicate on-premises data over to a Microsoft Azure object (blob) store.
|
Old installation method
The following installation method has been superseded. We recommend using the simpler, more up-to-date method described above. See WD Fusion Server on HDInsight.
|
This procedure assumes that you have already created all the key components for a deployment using a Custom Azure template. You will first need to create a virtual network, create a storage account, then start completing a template for a HDInsight cluster:
Prerequisites
Before starting the installation you will need access your Azure service and set up the following elements:
HDI Insights Cluster Security Groups
Introduction
In order for HDI clusters to provision and run, they have to be in a security group with inbound rules that allow Azure Management Services to access them (see Extend Azure HDInsight using an Azure Virtual Network).
|
Temporary requirement
The following procedure is required, since HDI clusters that you create now require a security group with settings that permit inbound connections from Azure Management Services. If these inbound connections are not configured, clusters will fail to provision.
|
The rules are different for different regions, so if you are in a different region you will need to look them up on that above article.
The following example shows the creation of a Security Group with the settings we need for West Europe, called AllowAzureManagementServices, and added to a subnet ()hdinsightsdefault) within the DEV-westeurope-vnet. For testing purposes, when creating your WD Fusion edgenode, you should add the edgenode and the HDInsights cluster to this subnet.
If you’ve already created your edgenode, you can add rules to the security group that its subnet uses.
Creating a Security Group
-
Find the Network Security Group page by clicking on More Services and searching for Network Security Groups.
 Figure 115. Network security groups
Figure 115. Network security groups -
Click + Add to add a new security group. Give it a name and use the "DEV" Resource group. The location should match the location of the vnet you’re attaching it to, and should match the location for the IPs you are allowing through for Azure management services.
 Figure 116. Add Network security groups
Figure 116. Add Network security groups -
Now go into your new security group and add inbound and outbound rules. You will notice if you click show defaults that are rules to prevent all traffic that is not on the vnet unless it is specifically allowed!
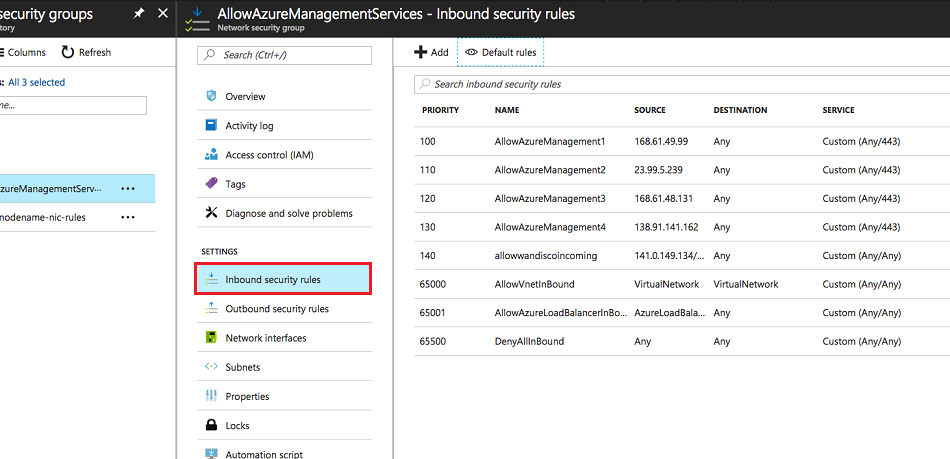 Figure 117. Inbound security rules
Figure 117. Inbound security rules -
Now add rules. With Azure, Microsoft recommends keeping priority numbers spaced out. Lower priority numbers means higher priority.
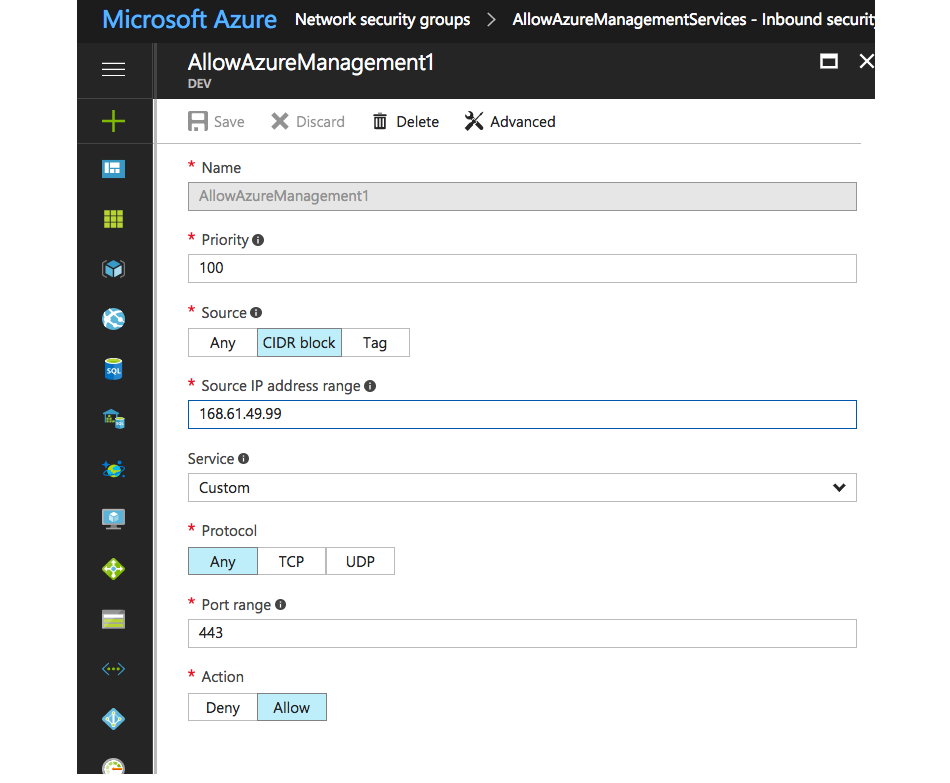 Figure 118. Allow Azure Management
Figure 118. Allow Azure Management
Set up storage
-
Log in to the Azure platform. Click Storage Accounts on the side menu.
 Figure 119. Storage Accounts
Figure 119. Storage Accounts -
Click Add.
-
Provide details for the storage account.
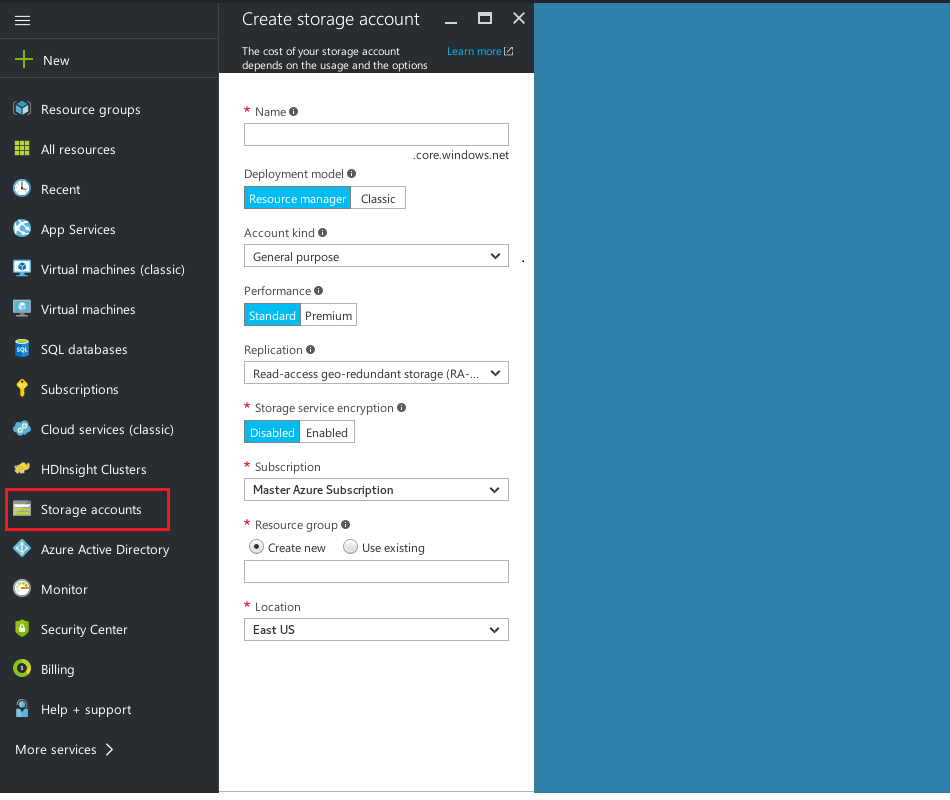 Figure 120. Add
Figure 120. Add- Name
-
The name of your storage container.
- Deployment model
-
Select Resource Manager
Unlike the Classic mode, the Resource manager mode uses the concept of resource group which is a container for resources that share a common lifecycle. Read more about Resource Manager Deployment Model. - Account Kind
-
General purpose
This kind of storage account provide storage for blobs, files, tables, queues and Azure virtual machine disks under a single account. - Replication
-
LRS
Locally redundant storage. - Access Tier
-
Hot
Hot storage is optimized for frequent access. - Storage service encryption
-
Disabled
- Subscription
-
Master Azure Subscription
- Resource Group
-
(Use existing) FusionRG-NEU
- Location
-
North Europe, etc.
Check your entries, then click Create.
-
Once created select your storage account. Select Blobs.
-
Select +Container.
 Figure 121. Container
Figure 121. Container -
Fill in the details for your container;
- Name
-
Enter a name for the container, e.g. "Container1"
- Access Type
-
Container.

Deploy the template
The next two steps complete the template deployment:
Deploy from link
Click to open up the Azure portal with the template already downloaded and in place. Azure portal
Deploy from the repository
This template can be fetched from the cloud-templates repo on gerrit, link here: https://wandiscopubfiles.blob.core.windows.net/wandiscopubfiles/edgeNodeTemplate.json

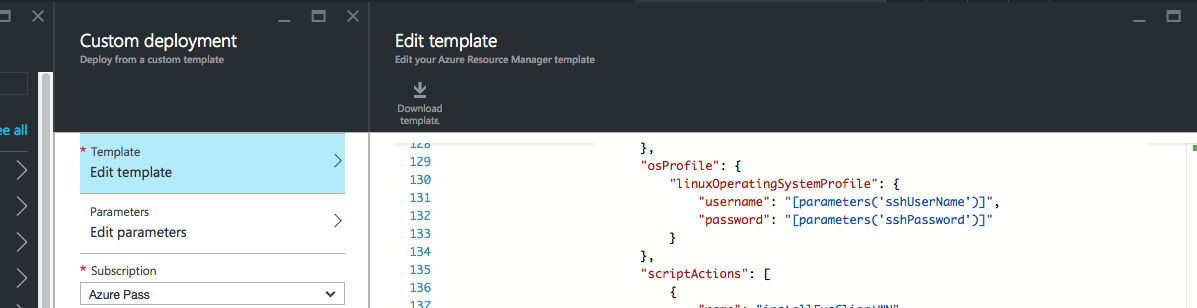
- LOCATION
-
The region your instance will ultimately belong to. example: East US
- FUSIONVERSION
-
2.10
- NODENAME
-
A name for the Node. example: Node1
- EXISTINGVNETRESOURCEGROUPNAME
-
An existing VNETResourceGroup your cluster will be deployed to. MasterEastUS-RG
- EXISTINGVNETNAME
-
The network your instance will be deployed to. Keep in mind to make this accessible to your on premise nodes you will need a specific network. EastUS-VNET
- EXISTINGSUBNETCLIENTSNAME
-
The subnet your instance will be deployed to. Keep in mind to make this accessible to your on premise nodes you will need a specific subnet. Subnet1
- SSHUSERNAME
-
The SSH details for your instance once deployed. CAN NOT BE ROOT OR ADMIN liamuser
- SSHPASSWORD
-
The password for the instance once deployed. Has to be at least 10 characters and must contain at least one digit, one non-alphanumeric character, and one upper or lower case letter. Wandisco99!
- EDGENODEVIRTUALMACHINESIZE
-
The size of the machine you want to use. Standard_A5
- NODEVHDSTORAGEACCOUNTNAME
-
The storage account that will be created for your instance. Can’t be an existing one. Has to be lower case. nodeteststorage
- AZURESTORAGEACCOUNTNAME
-
The name of the storage account you created, see above. mystorageaccount
- AZURESTORAGECONTAINERNAME
-
The container inside your storage account mycontainer
- AZURESTORAGEACCOUNTKEY
-
The storage key, Key1 for your storage account, see above. (A guid.)
- FUSIONADMIN
-
The username for your Fusion instance. admin (Default)
- FUSIONPASSWORD
-
The password for your Fusion instance admin (Default)
- FUSIONLICENSE
-
The URL for the Fusion license, the default is, https://wandiscopubfiles.blob.core.windows.net/wandiscopubfiles/license.key This license is a trial license that’s periodically updated by a Jenkins job.
- ZONENAME
-
The name of the Zone the Fusion instance is installed to. AzureCloud (Default)
- SERVERHEAPSIZE
-
The heap size of Fusion server. 4
- IHCHEAPSIZE
-
The heap size for the IHC server. 4
- INDUCTORNODEIP
-
The IP of the on premise node you want to induct to. (Optional)
Create a new resource group and accept legal terms
It is strongly recommended that you select the option to Create New for resource group. If you use existing it is harder to clean up unless you specifically made a resource group to which you will deploy.
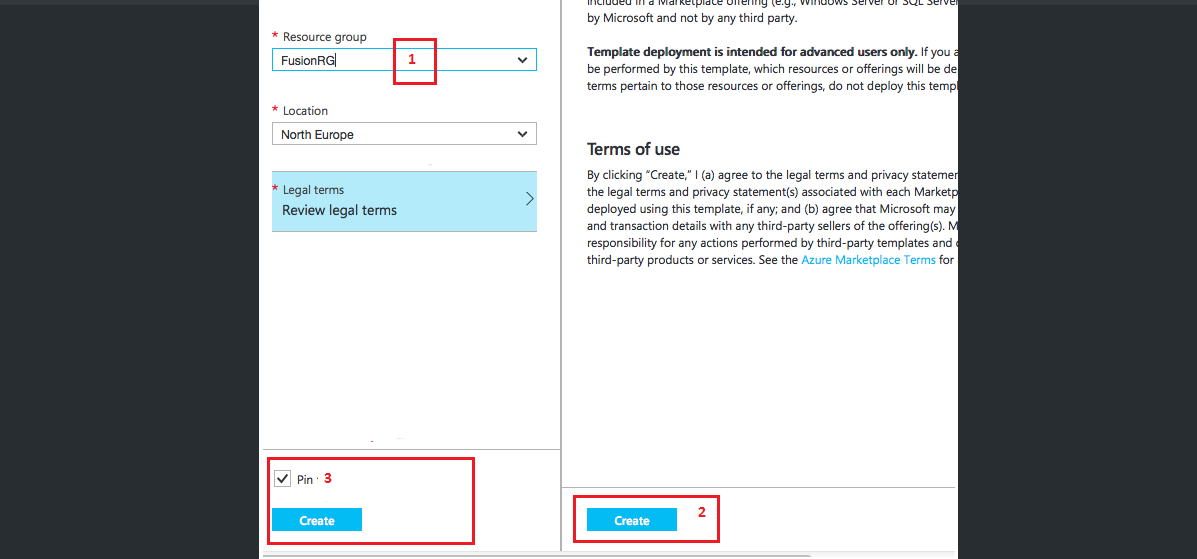
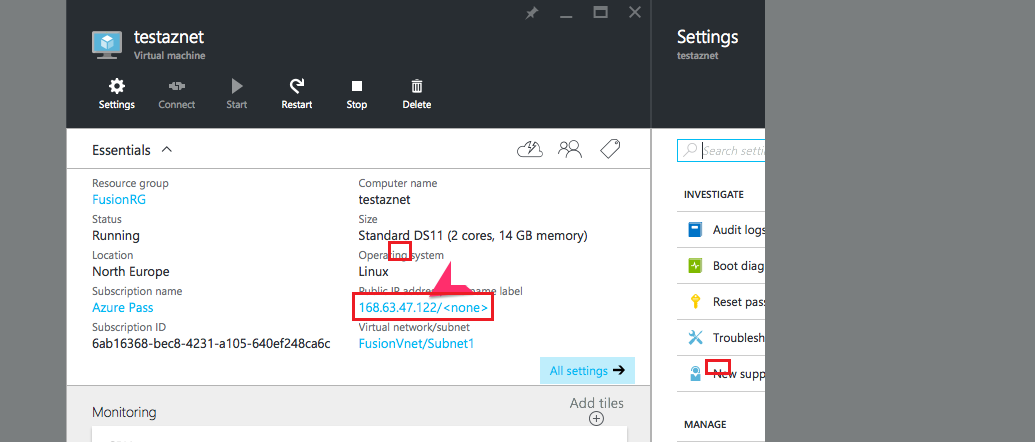
WD Fusion Installation
The next step is to install your WD Fusion nodes. For instruction on installing to your local file system, follow the On Premises installation guide. Below we take note of the elements that are specific to an MS Azure deployment:
MS Azure information
The following information is required during step 5 of the installer.
- Primary Access Key
-
When you create a storage account, Azure generates two 512-bit storage access keys, which are used for authentication when the storage account is accessed. By providing two storage access keys, Azure enables you to regenerate the keys with no interruption to your storage service or access to that service. The Primary Access Key is now referred to as Key1 in Microsoft’s documentation. You can get the KEY from the Microsoft Azure storage account: WD Fusion.
- WASB storage URI
-
This is the native URI used for accessing Azure Blob storage. E.g. wasb://
- Validate (button)
-
The installer will make the following validation checks:
- WASB storage URI
-
The URI will need to take the form:
wasb[s]://<containername>@<accountname>.blob.core.windows.net
- URI readable
-
Confirms that it is possible for WD Fusion to read from the Blob store.
- URI writable
-
Confirms that it is possible for WD Fusion to write data to the Blob store.
Azure (Fusion Clients installation)
-
In the next step you must complete the installation of the WD Fusion client package on all the existing HDFS client machines in the cluster. The WD Fusion client is required to support data WD Fusion’s replication across the Hadoop ecosystem. Download the client DEB file. Leave your browser session running while you do this, we’ve not finished with it yet.
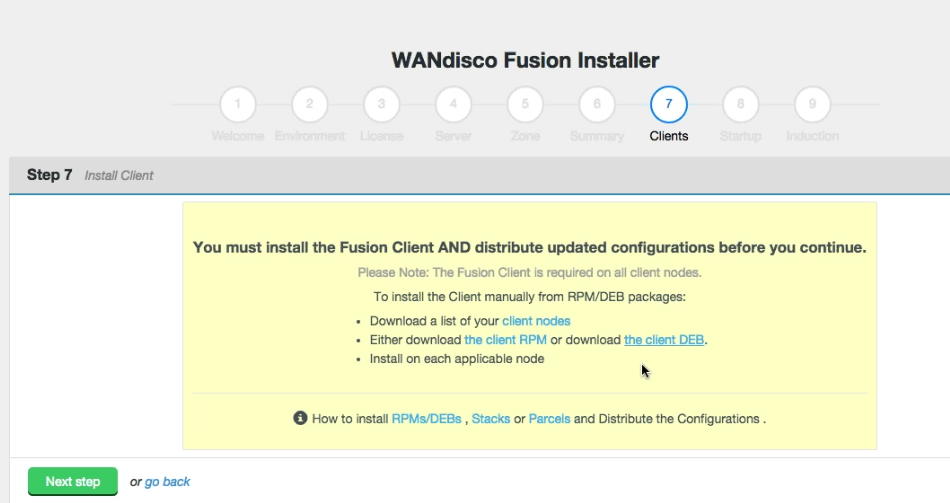 Figure 127. Client install 1 / Azure
Figure 127. Client install 1 / Azure -
Return to your console session. Download the client package "fusion-hdi-x.x.x-client-hdfs_x.x.x.deb".
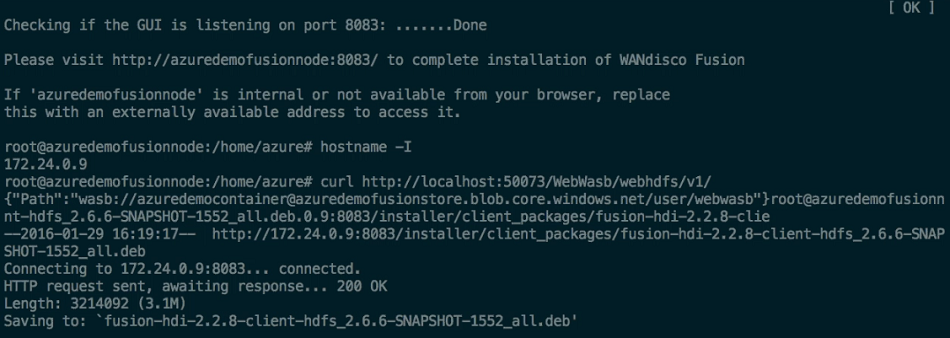 Figure 128. Client install 2 / Azure
Figure 128. Client install 2 / Azure -
Install the package on each client machine:
Figure 129. Client install 3 / Azuree.g.
dpkg -i fusion-hdi-x.x.x-client-hdfs.deb
 Figure 130. Client install 4 / Azure
Figure 130. Client install 4 / Azure
-
Once started we now complete the final step of installer’s configuration, Induction.
For this first node you will miss this step out, choosing to Skip Induction. For all the following node installations you will provide the FQDN or IP address and port of this first node. (In fact, you can complete induction by referring to any node that has itself completed induction.) . .
Follow this guide to set up WANdisco Fusion with Google Cloud platform.
8.4. Google Cloud Installation
This section will run you through an installation of WANdisco’s Fusion to enable you to replicate on-premises data over to Google Cloud Platform.
8.4.1. Connect WD Fusion with your Google Cloud Storage
To use WD Fusion with the Google Cloud Platform you first need to set up a VM. This guide assumes that you are already using Google Cloud and so have Bucket storage already set up. For more information see Google’s documentation.
-
Log into the Google Cloud Platform. Under VM instances in the Compute Engine section, click Create instance.
 Figure 131. VM Instances
Figure 131. VM Instances -
Set up suitable specifications for the VM.
 Figure 132. Create an instance
Figure 132. Create an instance- Machine type
-
2vCPUs recommended for evaluation.
- Boot disk
-
Click on the Change button and select Centos 7.
Increase Boot disk sizeEnsure that the boot disk size is sufficient.
 Figure 133. Boot disk info
Figure 133. Boot disk info - Identity and API access
-
Select 'Allow full access to all Cloud APIs'
- Firewall
-
Enable publicly available HTTP and HTTPS.
-
Expand the Management, disks, networking, SSH keys section and complete the following sections:
- Management
-
On the Management tab, scroll to the Metadata section:
-
Specify the key, in this case
startup-script-url -
Add the value. This is the url to the install script e.g. https://storage.googleapis.com/wandisco-public-bucket/installScript-2.10.5.sh, changing the version number accordingly.
 Figure 134. Metadata - install script
Figure 134. Metadata - install script- Networking
-
Select your Google Network VPC from the dropdown list and press Done.
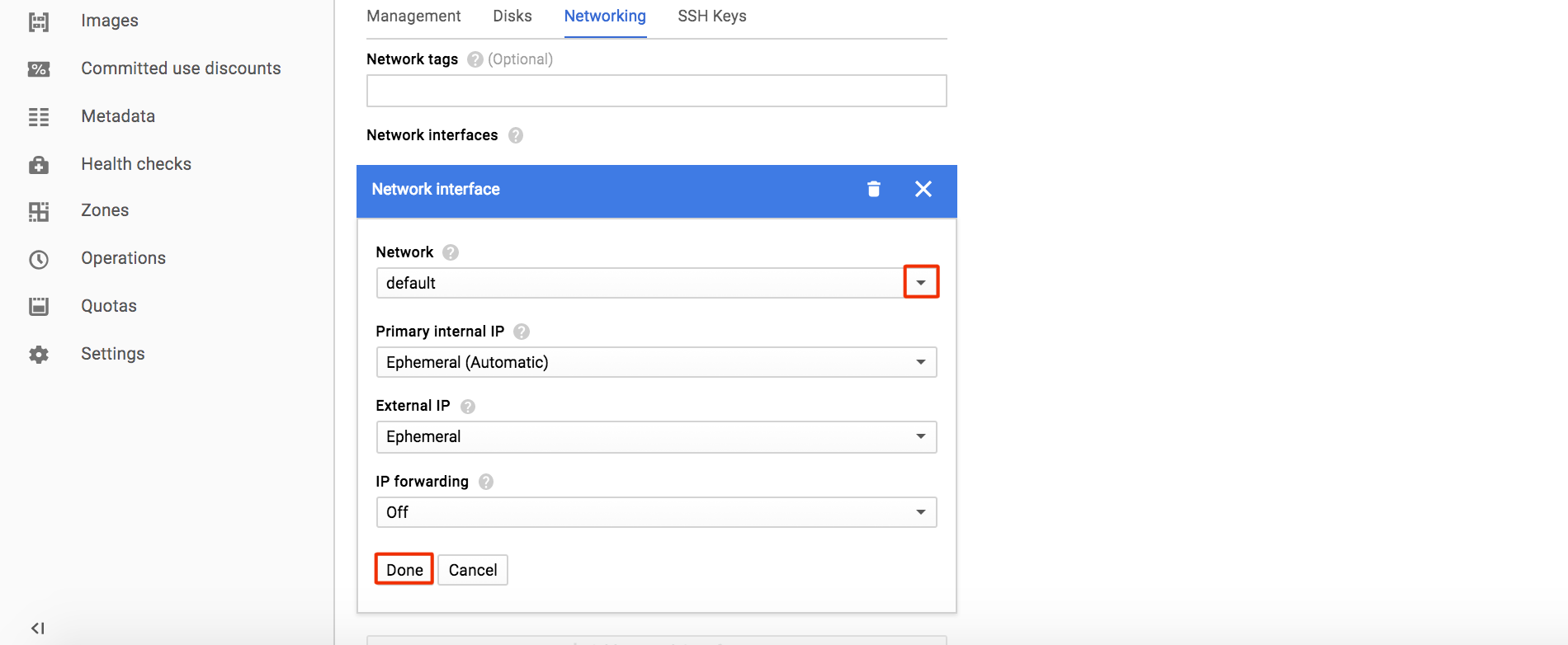 Figure 135. Network
Figure 135. Network
-
-
Click Create to create your VM instance.
-
When the instance is complete a green tick will appear on the VM Instances list.
 Figure 136. Network
Figure 136. Network -
Take note of the IP address of the instance. You will need this in the next step to access the UI for the WD Fusion installer. Your network configuration will determine if you need to use the internal or external IP.
8.4.2. Installation of WD Fusion for use with Google Cloud
Now you have created a VM on Google Cloud Platform you need to install WD Fusion at your on-premises location. This section just outlines the steps for the installer, for ore detailed information see the On premises installation section.
-
Open a browser and go to
http://your-server-IP:8083/to access the UI for your installer - this the IP noted in the previous step. -
In the "Welcome" screen you’re asked to choose between Create a new Zone and Add to an existing Zone.
Figure 137. WelcomeMake your selection as follows:
Adding a new WD Fusion cluster - Select Add Zone.
Adding additional WD Fusion servers to an existing WD Fusion cluster - Select Add to an existing Zone. -
Run through the installer’s detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
Figure 138. Installer screen -
On clicking validate the installer will run through a series of checks of your system’s hardware and software setup and warn you if any of WD Fusion’s prerequisites are missing.
Figure 139. Validation resultsAny element that fails the check should be addressed before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if only for evaluation purposes and not for production. However, when installing for production, you should address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
-
Upload the license file.
Figure 140. Installer screenThe conditions of your license agreement will be shown in the top panel.
-
In the lower panel is the EULA. Read through the EULA. When the scroll bar reaches the bottom you can click on the I agree to the EULA to continue, then click Next Step.
Figure 141. Verify license and agree to subscription agreement -
Enter settings for the WD Fusion server. For more detail on this section see here.
Figure 142. Fusion server settingsWD Fusion Server
- Fully Qualified Domain Name / IP
-
The full hostname for the server. This should be auto-filled from you Google Cloud information
- DConE Port
-
TCP port used by WD Fusion for replicated traffic. Validation will check that the port is free and that it can be bound to.
- Fusion HTTP Policy Type
-
Sets the policy for communication with the WD Fusion Core Server API.
- Fusion HTTP Server Port
-
The TCP port used for standard HTTP traffic. Validation checks whether the port is free and that it can be bound.
- Maximum Java heap size (GB)
-
Enter the maximum Java Heap value for the WD Fusion server. The minimum for production is 16GB but 64GB is recommended.
- Umask (currently 0022)
-
Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
-
Enter the settings for the IHC Server.
Figure 143. IHC Server details- Maximum Java heap size (GB)
-
Enter the maximum Java Heap value for the WD Inter-Hadoop Communication (IHC) server. The minimum for production is 16GB but 64GB is recommended.
- IHC network interface
-
The hostname for the IHC server. The hostname for the IHC server. It can be typed or selected from the dropdown on the right.
-
Next, you will enter the settings for your new Zone.
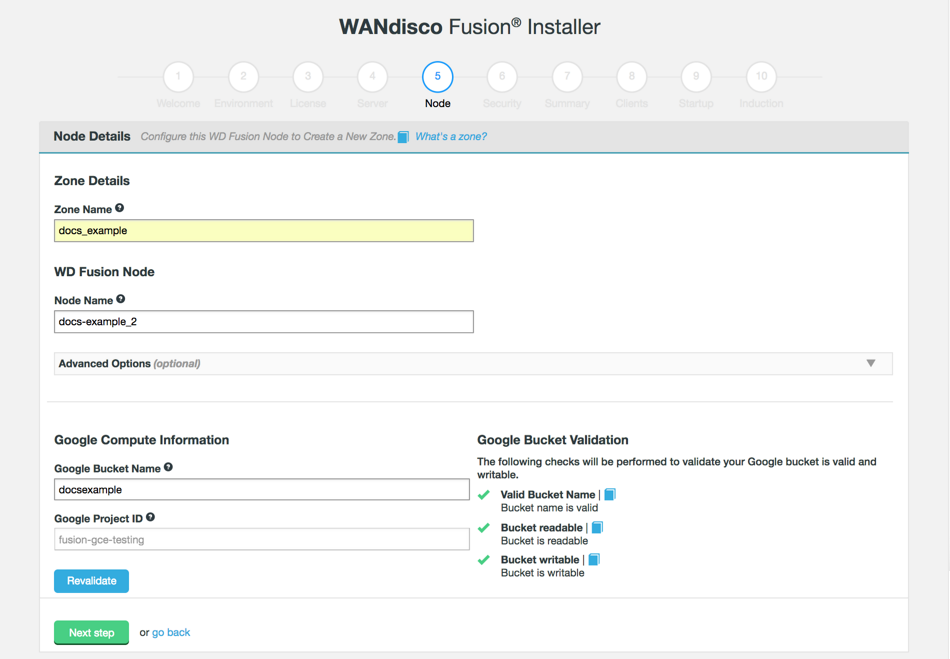 Figure 144. Step 5 - Zone information (Google Cloud deployment)
Figure 144. Step 5 - Zone information (Google Cloud deployment)Entry fields for zone properties:
- Zone Name
-
The name used to identify the zone in which the server operates.
- Node Name
-
The Node’s assigned name that is used in with the UI and referenced in the node server’s hostname.
-
In the lower panel complete the following Google specific information.
- Google Bucket Name
-
The name of the Google storage bucket that will be replicated. This field will auto-fill with the name given in the Google Cloud Platform set up.
- Google Project ID
-
The Google Project associated with the deployment. This field should auto-fill.
The following validation is completed against the settings:
-
The provided bucket matches with an actual bucket on the platform.
-
The provided bucket can be written to by WD Fusion.
-
The bucket can be read by WD Fusion.
-
Enter the security details applicable to your deployment.
Figure 145. "Security- Username
-
The username for the controlling account that will be used to access the WD Fusion UI.
- Password
-
The password used to access the WD Fusion UI.
- Confirm Password
-
A verification that you have correctly entered the above password.
-
At this stage of the installation you are provided with a complete summary of all of the entries that you have so far made. Go through the options and check each entry.
 Figure 146. Summary
Figure 146. SummaryOnce you are happy with the settings and all your WD Fusion clients are installed, click Deploy Fusion Server.
-
You can ignore the next step as there are no clients for this Cloud Platform. Click Next Step.
Figure 147. Clients -
Configuration is now complete. It’s now time to start up the WD Fusion server. Click Start WD Fusion to continue.
Figure 148. Startup -
If you have existing nodes you can induct them now. If you would rather induct them later, click Skip Induction.
Figure 149. Induction- Fully Qualified Domain Name
-
The fully qualified domain name of the node that you wish to connect to.
- Fusion Server Port
-
The TCP port used by the remote node that you are connecting to. 8082 is the default port.
-
8.4.3. Setting up replication
It’s now time to demonstrate data replication between the on-premises cluster and the Google bucket storage. First we need to perform a synchronization to ensure that the data stored in both zones is in exactly the same state. Follow this guide for replication from on-premises to Google Cloud.
-
Log in to the on-premises WD Fusion UI and click on the Replication tab. Then click + Create to set up a folder.
Figure 150. Create replication rule -
Click on the Create button to set up a rule.
Figure 151. Create ruleNavigate the File Tree, on the right-hand side of the New Rule panel and select the folder you wish to replicate. The selected folder will appear in the Path entry field. You can, instead, type or copy in the full path to the folder in the Path directory.
Next, select both zones from the Zones list and select the Membership.
More about Membership
Read about Membership in the WD Fusion User Guide - Managing Replication.Click Create to continue.
-
When you first create the rule you may notice status messages indicating that the system is preparing for replication. Wait until all pending messages are cleared before moving to the next step.
-
Once set up it is likely that the file replicas between both zones will be in an inconsistent state, in that you will have files on the local (on-premises) zone that do not yet exist in the Cloud. Click on the Not checked button to open the Consistency Check screen.
Figure 152. Consistency not yet checked -
Click Trigger new check to check for inconsistencies. The consistency report will appear once the check is complete. It shows the number of inconsistencies that need correction.
Figure 153. Trigger consistency check -
We will use the Bulk resolve inconsistencies option here to repair but see Running initial repairs in parallel for more information on improving the performance of your first sync and resolving individual inconsistencies if you have a small number of files that might conflict between zones.
Figure 154. Resolve inconsistenciesSelect your repair type and source of truth, in this case the current zone. Tick the appropriate resolution check boxes. Here we use Recursive and also Preserve so that files are not deleted if they don’t exist in the source zone. For more information see the Consistency check section.
Click Repair to begin the file transfer process. -
Now we need to verify the file transfers were successful. First, log in to the WD Fusion UI on the Google Cloud cluster. Click on the Replication tab and in the File Transfers column, click the View link.
Figure 155. View transferred files -
By ticking the boxes for each status type, you can view files that are:
-
In progress
-
Incomplete
-
Complete
Figure 156. Transferred filesConfirm that all your files have transferred.
No transfers in progress?
You may not see files in progress if they are very small, as they tend to clear before the UI polls for in-flight transfers.
-
-
Congratulations! You have successfully installed, configured, replicated and monitored data transfer with WANdisco Fusion.
8.4.4. Networking Guide for WANdisco Fusion Google Cloud
Setting up suitable network connectivity between your WD Fusion zones using your Google Cloud private network system can be difficult to understand and implement if you’re not very familiar with the networking part of the Google Cloud platform. This section of the appendix will give you all the information you need to make the best choices and right configuration for setting up network connectivity between your on-premises and Google Cloud environments.
WANdisco Fusion makes the replication of your on-premises data to Google cloud simple and efficient. It relies on network connectivity between the two environments, and because a typical on-premises data store will reside behind your firewall, you will need to plan the right approach for that connection.
The following sections give information on the requirements that your solution will need to meet, along with options for establishing communication between the environments. You can choose among those options, and perform simple testing to ensure that the configured solution meets all your needs for data replication with WANdisco Fusion.
See the Cloud Deployment Guide for more information about setting up connections between cloud and on-premises WD Fusion servers.
8.5. LocalFileSystem Installation
For most cloud deployments, a WD Fusion node must be installed within the customer’s local cluster for data replication into cloud-based storage.
8.5.1. Installer-based LocalFileSystem Deployment
The following procedure covers the installation and setup of WD Fusion deployed over the LocalFileSystem. This requires an administrator to enter details throughout the procedure. Once the initial settings are entered through the terminal session, the deployment to the LocalFileSystem is then completed through a browser.
Follow the first few steps given in the On-premises installation guide.
Make sure that you use the LocalFileSystem installer, for example fusion-ui-server-localfs_rpm_installer.sh.
Once the fusion-ui-server has started, follow the steps below to configure WD Fusion with Swift through the browser.
-
In the first "Welcome" screen you’re asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows:- Adding a new WD Fusion cluster
-
Select Add Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
-
Select Add to an existing Zone.
Figure 157. Welcome screen
-
Run through the installer’s detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
Figure 158. Environmental checks -
On clicking Validate the installer will run through a series of checks of your system’s hardware and software setup and warn you if any of WD Fusion’s prerequisites are not going to be met.
Figure 159. Example check resultsAddress any failures before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if the installation is only for evaluation purposes and not for production. However, when installing for production, you should address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
-
Select your license file and upload it.
Figure 160. Upload your license fileThe conditions of your license agreement will be shown in the top panel.
-
In the lower panel is the EULA.
Figure 161. Verify license and agree to subscription agreementTick the checkbox I agree to the EULA to continue, then click Next Step.
-
Enter settings for the WD Fusion server. See WD Fusion Server for more information about what is entered during this step.
Figure 162. Server information -
Enter the settings for the IHC Server. See the on premise install section for more information about what is entered during this step.
Figure 163. IHC Server information -
Next, you will enter the settings for your new Node.
Figure 164. Zone information- Zone Name
-
Give your zone a name to allow unique identification of a group of nodes.
- Node Name
-
A unique identifier that will help you find the node on the UI.
There are also advanced options but only use these if you fully understand what they do:
- Custom UI Host
-
Enter your UI host or select it from the drop down below.
- Custom UI Port
-
Enter the port number for the Fusion UI.
- External UI Address
-
The address external processes should use to connect to the UI on.
Once these details are added, click Validate.
Add an entry for the EC2 node in your host fileYou need to ensure that the hostname of your EC2 machine has been added to the /etc/hosts file of your LocalFS server node. I If you don’t do this then, currently you get an error when you start the node:Could not resolve Kerberos principal name: java.net.UnknownHostException: ip-10-0-100-72: ip-10-0-100-72" exception
-
Enter your security information.
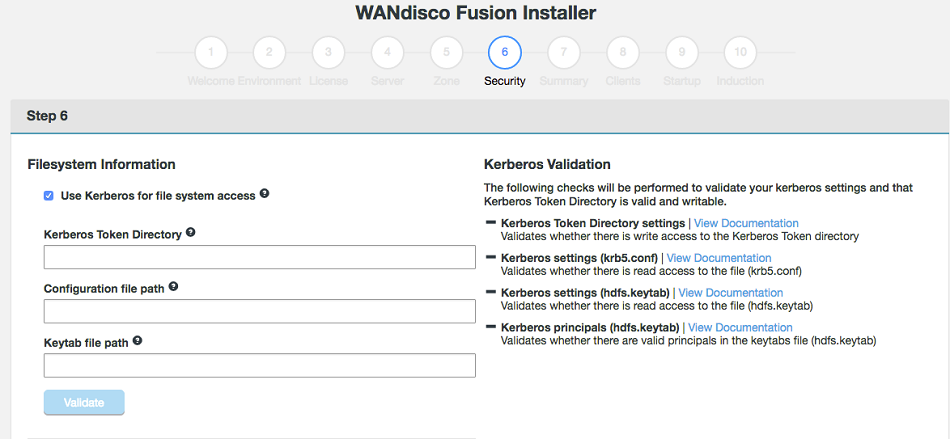 Figure 165. LocalFS installer - Security
Figure 165. LocalFS installer - Security- Use Kerberos for file system access
-
Tick this check-box to enable Kerberos authentication on the local filesystem.
- Kerberos Token Directory
-
This defines what the root token directory should be for the Kerberos Token field. This is only set if you are using LocalFileSystem with Kerberos and want to target the token creations within the NFS directory and not on just the actual LocalFileSystem. If left unset it will default to the original behavior; which is to create tokens in the /user/<username>/ directory.
The installer will validate that the directory given or that is set by default (if you leave the field blank), can be written to by WD Fusion.
- Configuration file path
-
System path to the Kerberos configuration file, e.g. /etc/krb5.conf
- Keytab file path
-
System path to your generated keytab file, e.g. /etc/krb5.keytab
Name and place the keytab where you likeThese paths and file names can be anything you like, providing they are the consistent with your field entries.
-
Review the summary. Click Validate to continue.
 Figure 166. LocalFS installer - Summary
Figure 166. LocalFS installer - Summary -
In the next step you must complete the installation of the WD Fusion client package on all the existing HDFS client machines in the cluster. The WD Fusion client is required to support data WD Fusion’s replication across the Hadoop ecosystem.
 Figure 167. LocalFS installer - Clients
Figure 167. LocalFS installer - ClientsIn this case, download the client RPM file. Leave your browser session running while you do this, we haven’t finished yet.
-
For localFS deployments, download the client RPM manually onto each client system, in the screenshot we use wget to copy the file into place.
 Figure 168. LocalFS installer - CLI download Clients
Figure 168. LocalFS installer - CLI download Clients -
It’s now time to start up the WD Fusion server. Click Start WD Fusion.
Figure 169. StartupThe WD Fusion server will now start up.
-
If you have existing nodes you can induct them now. If you would rather induct them later, click Skip Induction.
Induction will connect this second node to your existing "on-premises" node. When adding a node to an existing zone, users will be prompted for zone details at the start of the installer and induction will be handled automatically. Nodes added to a new zone will have the option of being inducted at the end of the install process where the user can add details of the remote node.
Figure 170. InductionIf you are inducting now, enter the following details then Click Start Induction.
- Fully Qualified Domain Name
-
The full address of the existing on-premises node.
- Fusion Server Port
-
The TCP Port on which the on-premises node is running. Default:8082
For the first node you will miss this step out. For all the following node installations you will provide the FQDN or IP address and port of this first node.
"Could not resolved Kerberos principal" errorYou need to ensure that the hostname of your EC2 machine has been added to the /etc/hosts file of your LocalFS server.
-
Log in to WD Fusion UI using the admin username and password that you provided during the installation.
 Figure 171. Post-induction login
Figure 171. Post-induction login -
The installation of your first node is now complete. You can find more information about working with the WD Fusion UI in the Admin section of this guide.
8.5.2. Notes on user settings
When using LocalFileSystem, you can only support 1 single user. This means when you configure the WD Fusion Server’s process owner, that process owner should also be the process owner of the IHC server, the Fusion UI server, and the client user that will be used to perform any puts.
|
Fusion under LocalFileSystem only supports 1 user
Again, Fusion under LocalFileSystem only supports 1 user (on THAT side; you don’t have to worry about the other DCs). To assist administrators the LocalFS RPM comes with Fusion and Hadoop shell, so that it is possible to run suitable commands from either. E.g.
|
hadoop fs -ls / fusion fs -ls /
Using the shell is required for replication.
8.6. Cloud Deployment Guide
The following section expands upon the various Cloud installation guides, providing information that will help with general issues
8.6.1. Guide for Networking between on-premises and Cloud
Setting up suitable network connectivity between your WD Fusion zones using your Cloud private network system can be difficult to understand and implement if you’re not very familiar with the networking part of the Cloud platform. This section will give you all the information you need to make the best choices and right configuration for setting up network connectivity between your on-premises and Cloud environments.
WANdisco Fusion makes the replication of your on-premises data to cloud simple and efficient. It relies on network connectivity between the two environments, and because a typical on-premises data store will reside behind your firewall, you will need to plan the right approach for connecting it to a cloud resource.
The following sections give information on the requirements that your solution will need to meet, along with options for establishing communication between the environments. You can choose among those options, and perform simple testing to ensure that the configured solution meets all your needs for data replication with WANdisco Fusion.
8.6.2. Networking in WANdisco Fusion
WANdisco Fusion is a distributed system, allowing multiple, separate storage systems to exchange data to replicate content. It includes a collection of services that communicate over the network, requiring the ability to establish and use TCP connections between one another.
Google Cloud
The Google Active Migrator includes components that are created and launched in a Virtual Private Cloud (VPC). Your on-premises WD Fusion components will need to establish connections with these VPC-resident services, and will also need to accept incoming connections from them.
You have many choices for how to establish connectivity between your on-premises environment and the Google Cloud-based Fusion node.
Regardless of your choice, you will need to ensure that your network connectivity meets the requirements defined in this document.
For information from VPC connectivity options, please refer to Using VPC Networks.
8.6.3. Unidirectional Networking
WD Fusion supports a feature that permits a switch in the direction of networking between the WD Fusion server and remote IHC servers. By default, network connections are created outbound to any remote IHC servers during data transfer. To overcome difficulties in getting data back through your organization’s firewalls, it is possible to have Fusion wait for and re-use inbound connections.
Only turn on Inbound connection if you are sure that you need the open your network to traffic from the IHC servers on remove nodes.
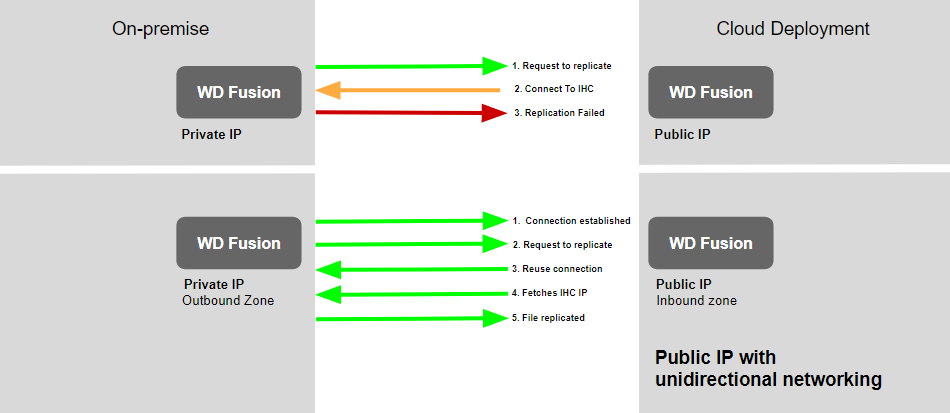
Inbound connection
When Inbound connection is selected, then you must ensure that WD Fusion server must be publicly visibile. To ensure this, you must enter a Fusion Server/Local IHC Public IP Adress.
|
Hostname cannot be changed after induction
Note that once a WD Fusion node has been inducted, it is no longer possible to change its hostname.
|
Outbound connection
The default network setting is Outbound connection, on the Networking Panel on the Settings Screen.
8.6.4. Ports
The diagram below shows the Fusion services and the ports they expose, that are used to replicate content between an on-premises local file system and Google Cloud.
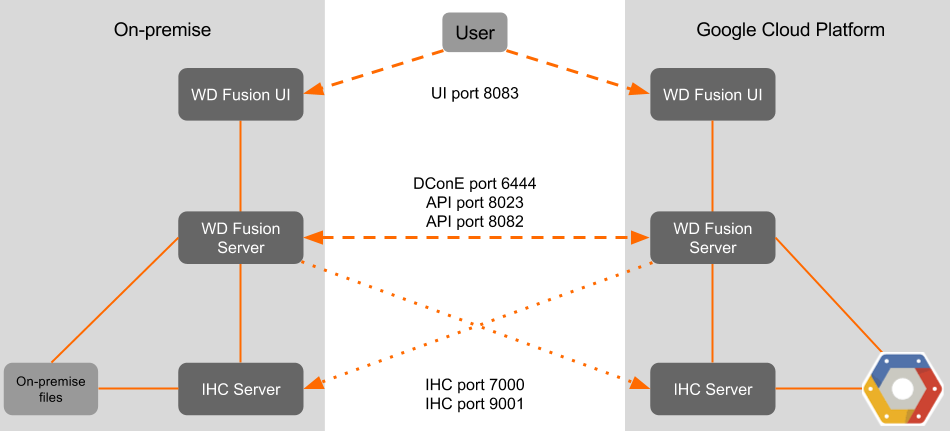
Take careful note of the need for TCP connections to be established in both directions between the hosts on which the Fusion and IHC servers execute. You need to allow incoming and outgoing TCP connections on ports:
- 6444
-
DCone port handles all co-ordination traffic that manages replication. It needs to be open between all WD Fusion nodes. Nodes that are situated in zones that are external to the data center’s network will require unidirectional access through the firewall.
- 8023
-
Port used by WD Fusion server to communicate with HCFS/HDFS clients. The port is generally only open to the local WD Fusion server, however you must make sure that it is open to edge nodes.
- 8082
-
REST port is used by the WD Fusion application for configuration and reporting, both internally and via REST API. The port needs to be open between all WD Fusion nodes and any systems or scripts that interface with WD Fusion through the REST API.
- 7000
-
7000 range, (exact port is determined at installation time based on what ports are available), used for data transfer between Fusion Server and IHC servers. Must be accessible from all WD Fusion nodes in the replicated system.
- 8083
-
Used to access the WD Fusion Administration UI by end users (requires authentication), also used for inter-UI communication. This port should be accessible from all Fusion servers in the replicated system as well as visible to any part of the network where administrators require UI access.
9. Administration Guide
This Admin Guide describes how to set up and use WANdisco’s WD Fusion.
9.1. Housekeeping
This section covers basic operations for running a WD Fusion deployment, including commands and tools that allow you to set up and maintain replicated directories.
9.1.1. Starting up
To start WD Fusion UI:
-
Open a terminal window on the server and log in with suitable file permissions.
-
Run the fusion-ui-server service from the /etc/init.d folder:
rwxrwxrwx 1 root root 47 Apr 10 16:05 fusion-ui-server -> /opt/wandisco/fusion-ui-server/bin/fusion-ui-server
-
Run the script with the start command:
[root@localhost init.d]# ./fusion-ui-server start Starting fusion-ui-server:. [ OK ]
WD Fusion starts. Read more about the fusion-ui-server init.d script.
-
Also you can invoke the service directly. e.g.
service fusion-ui-server stop/start
9.1.2. Shutting down
To shut down:
-
Open a terminal window on the server and log in with suitable file permissions.
-
Run the WD Fusion UI service, located in the init.d folder:
rwxrwxrwx 1 root root 47 Dec 10 16:05 fusion-ui-server -> /opt/wandisco/fusion-ui-server/bin/fusion-ui-server
-
Run the stop script:
[root@redhat6 init.d]# ./fusion-ui-server stop stopping fusion-ui-server: [ OK ] [root@redhat6 init.d]#
The process shuts down.
Shutdowns take some time
The shutdown script attempts to stop processes in order before completing, as a result you may find that (from WD Fusion 2.1.3) shutdowns may take up to a minute to complete.
9.1.3. init.d management script
The start-up script for persistent running of WD Fusion is in the /etc/init.d folder. Run the script with the help command to list the available commands:
[root@redhat6 init.d]# service fusion-ui-server help usage: ./fusion-ui-server (start|stop|restart|force-reload|status|version) start Start Fusion services stop Stop Fusion services restart Restart Fusion services force-reload Restart Fusion services status Show the status of Fusion services version Show the version of Fusion
Check the running status (with current process ID):
[root@redhat6 init.d]# service fusion-ui-server status Checking delegate:not running [ OK ] Checking ui:running with PID 17579 [ OK ]
Check the version:
[root@redhat6 init.d]# service fusion-ui-server version 1.0.0-83
9.2. Managing cluster restarts
WD Fusion’s replication system is deeply tied to the cluster’s file system (HDFS). If HDFS is shut down, the WD Fusion server will no longer be able to write to HDFS, stopping replication even if the cluster is brought back up.
To avoid replication problems:
-
Where possible, avoid doing a full shutdown. Instead, restart services to trigger a rolling restart of datanodes.
-
If a full shutdown is done, you should do a rolling restart off all WD Fusion nodes in the corresponding zone. A rolling restart ensures that you will keep the existing quorum.
9.3. Managing services through the WD Fusion UI
Providing that the UI service is running, you can stop and start WD Fusion through the Fusion Nodes tab.
9.4. WD Fusion UI login
The UI for managing WD Fusion can be accessed through a browser, providing you have network access and the port that the UI is listening on is not blocked.
http://<url-for-the-server>:<UI port>
e.g.
http://wdfusion-static-0.dev.organisation.com:8083/ui/
You should not need to add the /ui/ at the end, you should be redirected there automatically.
Log in using your Hadoop platform’s manager credentials.
9.4.1. Login credentials
Currently you need to use the same username and password that are required for your platform manager, e.g. Cloudera Manager or Ambari. In a future release we will separate WD Fusion UI from the manager and use a new set of credentials.
LDAP/Active Directory and WD Fusion login
If your Cloudera-based cluster uses LDAP/Active Directory to handle authentication then please note that a user that is added to an LDAP group will not automatically be assigned the corresponding Administrator role in the internal Cloudera Manager database. A new user is LDAP that is assigned an Admin role will, by default, not be able to log in to WD Fusion. To be allowed to log in, they must first be changed to an administrator role type from within Cloudera Manager.
No sync between CM and LDAP
There is no sync between Cloudera Manager and LDAP in either direction, so a user who loses their Admin privileges in LDAP will still be able to log in to WD Fusion until their role is updated in Cloudera Manager. You must audit WD Fusion users in Cloudera Manager.
Administrators will need to change any user in the Cloudera Manager internal database (from the Cloudera Manager UI) to the required access level for WD Fusion. Please note the warning given above, that changing access levels in LDAP will not be enough to change the admin level in WD Fusion.
9.4.2. Change Login credentials
You can change the user/password credentials using the following procedure:
-
Generate a new hash for your password using:
/opt/wandisco/fusion/server/encrypt-password.sh
-
On each Fusion server, edit /opt/wandisco/fusion-ui-server/properties/ui.properties and update the following properties with the new credentials:
manager.username manager.encrypted.password
-
Restart Fusion UI server, see init.d management script
[root@redhat6 init.d]# service fusion-ui-server restart
-
Repeat procedure for all WD Fusion server nodes in zone. Note that you can reuse the hash generated in step 1, you do not need to create a new one for each pass.
9.5. Authentication misalignment
There are four possible scenarios concerning how LDAP authentication can align and potentially misalign with the internal CM database:
- User has full access in CM, denied access in WD Fusion UI
-
-
User is in the Full Administrator group in LDAP
-
User is left as the default read-only in the internal Cloudera Manager database
-
- User has full access in CM, full access in WD fusion UI
-
-
User is in the Full Administrator group in LDAP
-
User is changed Full Administrator in the internal Cloudera Manager database
-
- User has read-only access in CM, denied access to WD Fusion UI
-
-
User is removed from the Full Administrator group in LDAP and added to the read-only group
-
User is left as the default read-only in the internal Cloudera Manager database
-
- User has read-only access to CM, Full access to WD Fusion UI
-
-
User is removed from the Full Administrator group in LDAP and added to the read-only group
-
User is set as Full Administrator in the internal Cloudera Manager database + Clearly this scenario represents a serious access control violation, administrators must audit WD Fusion users in Cloudera Manager.
-
9.5.1. Checking cluster status on the Dashboard
The WD Fusion UI dashboard provides a view of WD Fusion’s status. From the world map you can identify which data centers are experiencing problems, track replication between data centers or monitor the usage of system resources.
UI Dashboard will indicate if there are problems with WD Fusion on your cluster.
9.6. Server Logs Settings
The WD Fusion logs that we display in the WD Fusion UI are configured by properties in the ui.properties file.

9.6.1. WD Fusion UI Logs viewer
Using WD Fusion UI’s log viewer (View Logs):
-
Log in to the WD Fusion UI and click on the Fusion Nodes tab button. Then click on the Node on which you wish to view logs.
 Figure 180. Log viewer 1
Figure 180. Log viewer 1 -
Click on the View Logs link, under Fusion Server Logs in the *Local WD Fusion Server table:
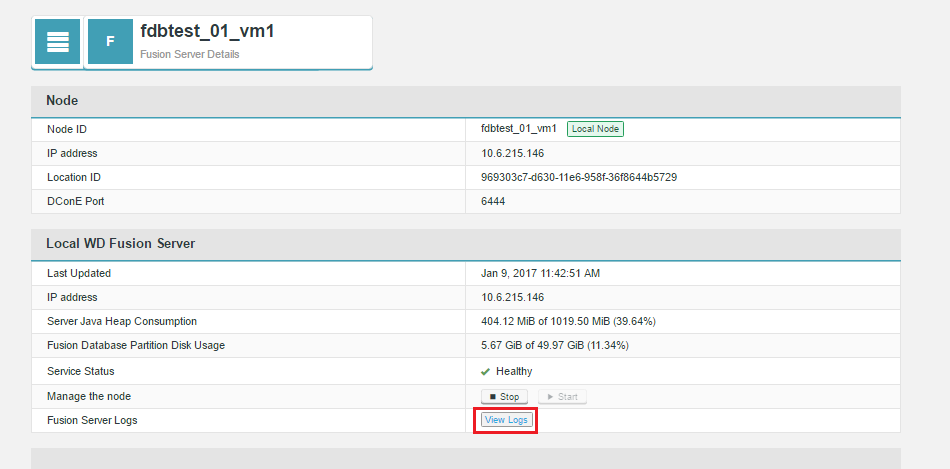 Figure 181. Log viewer 2
Figure 181. Log viewer 2 -
The View Logs screen lets you select from either WD Fusion or UI Server logs.
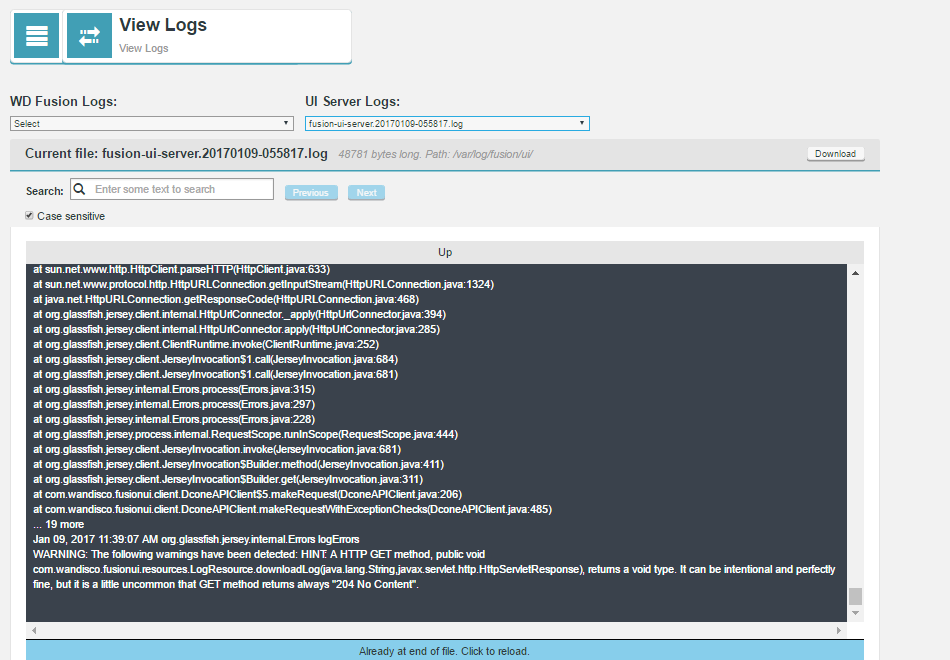 Figure 182. Log viewer 3
Figure 182. Log viewer 3
9.6.2. Default log paths:
Unless configured differently, WD Fusion logs should be written to the following locations:
logs.directory.fusion /var/log/fusion/server/ logs.directory.ihc /var/log/fusion/ihc logs.directory.uiserver /var/log/fusion/ui
9.6.3. Configure log directory
By default the log location properties are not exposed in the ui.properties file. If you need to update the UI server to look in different locations for the log files then you can add the following properties (in ui.properties). To be clear these entries do not set alternate locations for WD Fusion to write its logs, it only ensures that the UI server can still read the logs in the event that they are moved.:
- logs.directory.fusion
-
sets the path to the WD Fusion server logs.
- logs.directory.uiserver
-
sets the path to the UI server logs.
- logs.directory.ihc
-
sets the path to the ihc server logs.
The file is read by the UI server on start up so you will need to restart the server for changes to take affect. The ui.properties file
is not replicated between nodes so you must currently set it manually on each node.
9.6.4. Logging at startup
At startup the default log location is /dev/null. If there’s a problem before log4j has initialised this will result in important logs getting
lost. You can set the log location to a filespace that preserve early logging.
Edit fusion_env.sh adding paths to the following properties:
- SERVER_LOG_OUT_FILE
-
Path for WD Fusion server log output
- IHC_LOG_OUT_FILE
-
Path for IHC server log output
|
More about logging
For more information about WD Fusion’s logging, seeTroubleshooting - 2. Read logs |
9.7. Induction
Induction is the process used to incorporate new nodes into WANdisco’s replication system. The process is run at the end of a node installation, although it is also possible to delay the process, then use the + Induct link on the Fusion Nodes tab.
Use this procedure if you have installed a new node but did not complete its induction into your replication system at the end of the installation process.
-
Log in to one of the active nodes, clicking on the Fusion Nodes tab. Click the + Induct button.
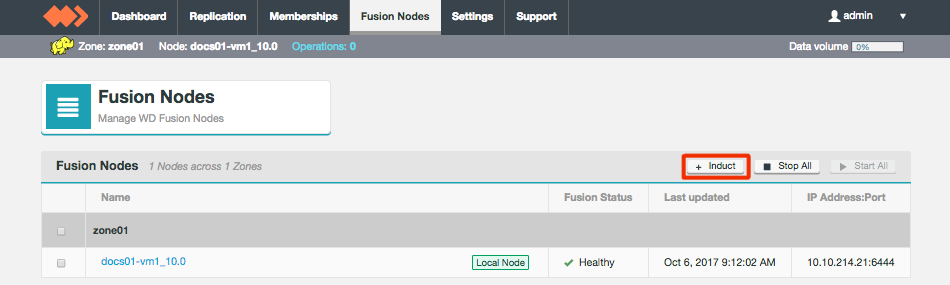 Figure 183. Induct node
Figure 183. Induct node -
Enter the fully qualified domain name of the new node that you wish to induct into your replication system.
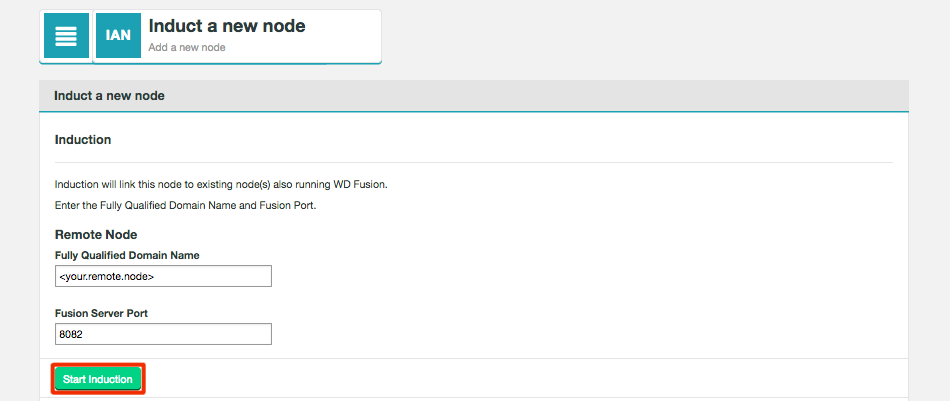 Figure 184. Remote node details
Figure 184. Remote node details- Fully Qualified Domain Name
-
The full domain name for the new node that you will induct into your replication system.
- Fusion Server Port
-
The TCP port used by the WD Fusion application for configuration and reporting, both internally and via REST API. The port needs to be open between all WD Fusion nodes and any systems or scripts that interface with WD Fusion through the REST API. Default is 8082.
Click Start Induction.
-
When the induction process completes you have the option to induct another node. The Fusion Node tab will refresh with the new node added to the list.
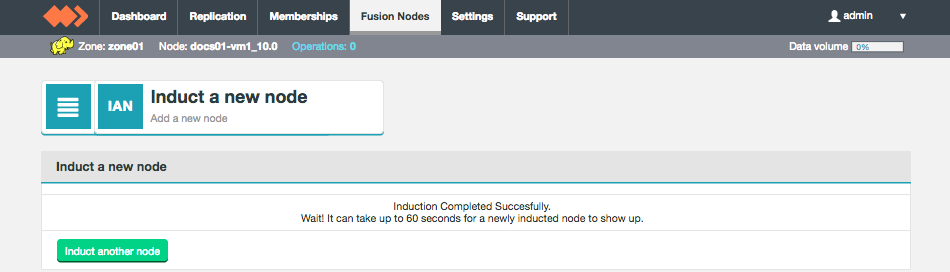 Figure 185. Induction complete
Figure 185. Induction complete
9.7.1. Induction Failure
The induction process performs some validation before running. If this validation failures you will quickly see a warning messages appear.
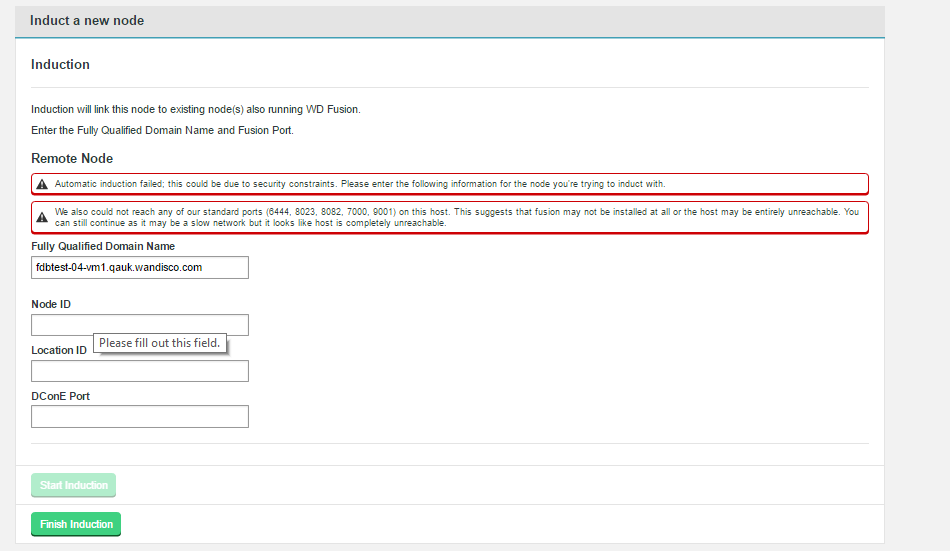
- Automatic Induction Failure
-
If the induction process can’t connect to the new node using the details provided, a failure will happen instantly. This could happen because of an error in the new node’s installation, however it could also be caused by the node being kerberized.
- We also could not reach any of our standard ports
-
If connections can’t be made on specific Fusion ports, they will be listed here. If none of the standard ports are reachable then you will be warned that this is the case.
- Fully Qualified Domain Name
-
The full hostname for the server.
- Node ID
-
A unique identifier that will be used by WD Fusion UI to identify the server.
- Location ID
-
This is the unique string (e.g. "db92a062-10ea-11e6-9df2-4ad1c6ce8e05") that appears on the Node screen (see below).
- DConE Port
-
The TCP port used by the replication system. It needs to be open between all WD Fusion nodes. Nodes that are situated in zones that are external to the data center’s network will require unidirectional access through the firewall.
10. Troubleshooting
This section details with how to diagnose and fix problems that many occur in deployment. It’s important that you check the Release Notes for any Known issues in the release that you are using. See Release Notes.
10.1. Troubleshooting Overview
-
Run Talkback then send the results to WANdisco’s support team
-
Common Problems
10.2. Read the logs
There are a number of log files that provide information that will be necessary in finding the cause of many problems.
The log files for WD Fusion are spread over three locations. Some processes contain more than one log file for the service. All pertinent log files are captured by running the WANdisco talkback shell script that is covered in the next section.
10.2.1. WD Fusion Server Logs
The logs on the WD Fusion server record events that relate to the data replication system.
- Log locations
-
/var/log/fusion/server - Primary log(s)
-
fusion-dcone.log.0-
this is the live log file for the running WD Fusion server process.
-
- Historical logs
-
The following logs are listed for completeness but are not generally useful for monitoring purposes.
fusion dcone.log.x-
the log file is rotated once its file size reaches 200MB. By default, the last 100 log files are stored. The "x" represents an incrementing number, starting at 1.
Filenames are appended with an incrementing number starting at 1.
Rotation is presently defaulted at 200MB with a retention of 100 files, although this can be customised.
fusion-server.log -
a log of the application-level events, such as kerberos authentication, license validation.
fusion-server.log.yyyy-mm-dd
log_out.log -
this is the output redirected from STDOUT and STDERR that invoked java. This is used to capture exceptions that occur before logging could start.
-
10.2.2. WD Fusion UI Server Logs
The WD Fusion user interface layer, responsible for handling interactions between the administrator, WD Fusion and the Hadoop Management layer.
- Log locations
-
/var/log/fusion/ui/ - Primary log(s)
-
fusion-ui.log - Historical logs
-
fusion-ui.log.x
The UI logs will contain errors such as failed access to the user interface, connectivity errors between the user interface and WD Fusion Server REST API and other syntax errors between the user interface and the WD Fusion server’s REST API and other syntax errors whilst performing administrative actions across the UI.
10.2.3. Inter-Hadoop Connect (IHC) Server Logs
Responsible for streaming files from the location of the client write to the WD Fusion server process in any remote cluster to which hadoop data is replicated.
- Log location
-
/var/log/fusion/ihc
/var/log/fusion/ihc/server- Primary log(s)
-
server/fusion-ihc-ZZZ-X.X.X.log-
The live IHC process log files. The components of the filename are as follows:
ZZZ - Hadoop distribution marker (hdp, cdh, phd, etc). This will be "hdp" for a Hortonworks integrated cluster.
X.X.X - A matching cluster version number. This will be "2.2.0" for a Hortonworks 2.2 cluster.
-
- Historical logs
-
server/fusion-ihc-ZZZ-X.X.X.log.yyy-mm-dd
log_out.log
This log file contains details of any errors by the process when reading from HDFS in the local cluster, such as access control violations, or network write errors when streaming to the WD Fusion server in any remote cluster.
10.2.4. WANdisco Fusion Client Logging
By default, the WANdisco Fusion client remains silent and will not provide an indication that it has been loaded or is in use by an application. For troubleshooting purposes, it can help to enable client logging to allow you to determine when the client is in effect. Client logging can be enabled by adding an entry to the cluster’s log4j.properties file similar to that below:
log4j.logger.com.wandisco.fs.client=INFO
Once enabled, client log information will be produced by default on the standard output. Either removing this entry, or setting the logging level for the WANdisco Fusion client library to "OFF" will restore default behavior with no client-side logging.
10.2.5. Log analysis
This is the standard format of the WANdisco log messages within Fusion. It includes an ISO8601 formatted timestamp of the entry, the log level / priority, followed by the log entry itself. Log levels we provide in order of severity (highest to lowest) that you may observe:
-
PANIC
-
SEVERE
-
ERROR
-
WARNING
-
INFO
For log analysis and reporting, logs with at the PANIC, SEVERE and ERROR levels should be investigated. The warning level messages indicate an unexpected result has been observed but one that hasn’t impacted the system’s continued operation. Additional levels may exist, but are used in cases when the logging level has been increased for specific debug purposes. At other times, other levels should be treated as informational (INFO).
10.2.6. Quickly picking out problems
One simple thing that can be done is to grep the log file for any instance of "exception" and/or "PANIC" - this will tell the administrator a great deal without much effort. Using something like:
cat /var/log/fusion/server/fusion-dcone.log.0 | egrep -i "exception|panic"
10.3. Talkback
Talkback is a bash script that is provided in your WD Fusion installation for gathering all the logs and replication system configuration that may be needed for troubleshooting problems. Should you need assistance from WANdisco’s support team, they will ask for an output from Talkback to begin their investigation.
10.3.1. Talkback location
You can find the talkback script located on the WD Fusion server’s installation directory:
$ cd /opt/wandisco/fusion/server/
You can run talkback as follows:
$ sudo talkback.sh
If a cluster has Kerberos security enabled (Talkback will detect this from WD Fusion’s configuration), you may be asked for Kerberos details needed to authenticate with the cluster.
You will be asked to complete the following details:
-
Location to store the talkback to. Suggest /tmp if acceptable disk space is available.
Reserve plenty of storage
Note, WD Fusion talkbacks can exceed 300MB compressed, but well over 10GB uncompressed (due to logs)./tmpmay or may not be suitable. -
Kerberos keytab location.
-
User to perform kinit with when obtaining kerberos ticket.
-
Whether you wish to perform a HDFS fsck, or not. Option 1 for yes, option 2 for no.
10.3.2. Running talkback
To run the talkback script, follow this procedure:
-
Log into the Fusion server. If you’re not logged in as root, use sudo to run the talkback script, e.g.
[vagrant@supp26-vm1 ~]$ sudo /opt/wandisco/fusion/server/talkback.sh ####################################################################### # WANdisco talkback - Script for picking up system & replicator # # information for support # ####################################################################### To run this script non-interactively please set following environment vars: ENV-VAR: FUSION_SUPPORT_TICKET Set ticket number to give to WANdisco support team FUSION_TALKBACK_DIRECTORY Set the absolute path directory where the tarball will be saved FUSION_KERBEROS_ENABLED Set to "true" or "false" FUSION_PERFORM_FSCK Set to "true" or "false" to perform a file system consistency check Which directory would you like the talkback tarball saved to? /tmp ===================== INFO ======================== The talkback agent will capture relevant configuration and log files to help WANdisco diagnose the problem you may be encountering. Retrieving current system state information Kerberos is enabled Kerberos is enabled. Please provide the absolute path to the keytab you wish to use to obtain a ticket: /etc/security/keytabs/hdfs.headless.keytab Please provide the corresponding username for the keytab located /etc/security/keytabs/hdfs.headless.keytab: hdfs Performing kinit as user: hdfs Gathering information from Fusion endpoints Protocol is: http Hostname is: supp26-vm1dddd Port is: 8082 retrieving details for node "supp26-vm0_2" retrieving details for node "supp25-vm1_59" retrieving details for node "supp25-vm0_61" retrieving details for node "supp26-vm1_20" Copying Fusion server log files, this can take several minutes. Copying Fusion IHC log files, this can take several minutes. Would you like to include hadoop fsck? This can take some time to complete and may drastically increase the size of the tarball. 1) Yes 2) No #? 2 Running sysinfo script to capture maximum hardware and software information... Gathering Summary info.... Gathering Kernel info.... Gathering Hardware info.... Gathering File-Systems info.... Gathering Network info.... Gathering Services info.... Gathering Software info.... Gathering Stats info.... Gathering Misc-Files info.... THE FILE sysinfo/sysinfo_supp26-vm1-20160428-132245.tar.gz HAS BEEN CREATED BY sysinfo tar: Removing leading `/' from member names TALKBACK COMPLETE --------------------------------------------------------------- Please upload the file: /tmp/talkback-201604281321-supp26-vm1.lcx.tar.gz to WANdisco support with a description of the issue. Note: do not email the talkback files, only upload them via ftp or attach them via the web ticket user interface. -------------------------------------------------------------- -
Follow the instructions for uploading the output on WANdisco’s support website.
10.4. Common problems
10.4.1. Moving objects between mismatched filesystems
If you move objects onto the distributed file system you must make sure that you use the same URI on both the originating and destination paths. Otherwise you’d see an error like this:
[admin@vmhost01-vm1 ~]$ hadoop fs -mv /repl2/rankoutput1 fusion:///repl2/rankoutput2/ 15/05/13 21:22:40 INFO client.FusionFs: Initialized FusionFs with URI: fusion:///, and Fs: hdfs://vmhost01-vm1.cluster.domain.com:8020. FileSystem: DFS[DFSClient[clientName=DFSClient_NONMAPREDUCE_-721726966_1, ugi=admin@DOMAIN.EXAMPLE (auth:KERBEROS)]] mv: `/repl2/rankoutput1': Does not match target filesystem
If you use the fusion:/// URI on both paths it will work, e.g.
[admin@vmhost01-vm1 ~]$ hadoop fs -mv fusion:///repl2/rankoutput1 fusion:///repl2/rankoutput1 15/05/13 21:23:27 INFO client.FusionFs: Initialized FusionFs with URI: fusion:///, and Fs: hdfs://vmhost01-vm1.cluster.domain.com:8020. FileSystem: DFS[DFSClient[clientName=DFSClient_NONMAPREDUCE_-1848371313_1, ugi=admin@DOMAIN.EXAMPLE (auth:KERBEROS)]]
Note that since the non-replicated directory doesn’t yet exist in ZONE2
it will get created without the files it contains on the originating
zone. _When running WD Fusion using the fusion:///, moving
non-replicated directory to replicated directory will not work unless
you use of the fusion:/// URI.
You can’t move files between replicated directories
Currently you can’t perform a straight move operation between two
separate replicated directories.
10.4.2. Handling file inconsistencies
WD Fusion’s replication technology ensures that changes to data are efficiently propagated to each zone. However, the replication system is optimized for maintaining consistency through transactional replication and is not designed to handle the initial synchronization of large blocks of data. For this requirement, we have the Consistency Check tool.
10.4.3. Transfer reporting
When looking at the transfer reporting, note that there are situations in which HFlush/early file transfer where transfer logs will appear incorrect. For example, the push threshold may appear to be ignored. This could happen if an originating file is closed and renamed before pulls are triggered by the HFlush lookup. Note that although this results in confusing logs, those logs are in fact correct; you would see only two appends, rather than the number determined by your push threshold - one in the very beginning, and one from the rename, which pulls the remainder of the file. What is happening is optimal; all the data is available to be pulled at that instant, so we might as well pull all of it at once instead of in chunks.
10.4.4. Fine-tuning Replication
WANdisco’s patented replication engine, DConE, can be configured for different use cases, balancing between performance and resource costs. The following section looks at a number of tunable properties that can be used to optimize WD Fusion for your individual deployment.
Increasing thread limit
WD Fusion processes agreements using a set number of threads, 20 by default, which offers a good balance between performance and system demands.
It is possible, in cases where there are many Copy agreements arriving at the same time, that all available threads become occupied by the Copy commands. This will block the processing of any further agreements.
You can set WD Fusion to reserve more threads, to protect against this type of bottleneck situation:
10.4.5. Increase executor.threads property
-
Make a backup copy of WD Fusion’s applications config file
/etc/wandisco/fusion/server/applications.properties, then open the original in your preferred text editor. -
Modify the property
executor.threads.Property
Description
Permitted Values
Default
Checked at…
executor.threads
The number of threads executing agreements in parallel.
1-Integer.MAX_VALUE
20
Startup
Don’t go aloneAny upward adjustment will clearly increase the resourcing costs. Before you make any changes to DConE properties, you should open up discussions with WANdisco’s support team. Applying incorrect or inappropriate settings to the replication system may result in hard to diagnose problems. -
Save your edited
applications.propertiesfile, then restart WD Fusion.
10.4.6. Tuning Writer Re-election
Only one WD Fusion node per zone is allowed to write into a particular replicated directory. The node that is assigned to do the writing is called the writer. See more about the role of the writer.
Should the current writer suddenly become unavailable, then a re-election process begins for assigning the role to one of the remaining nodes. Although the re-election process is designed to balance speed against and system resource usage, there may be deployments where the processing speed is critical. For this reason, the reelection timing can be tuned with the following system:
10.5. Tunable properties
- writerCheckPeriod
-
The period of time (in seconds) between writer check events. Default: 60.
- writerCheckMultiple
-
The number of check events that will fail before initiating an election. Default: 3.
10.5.1. Setting the writer re-election period
Period of time between a writer going off-line and another writer is elected and starts picking up = writerCheckPeriod * writerCheckMultiple. i.e.
the default is 3 minutes ( writerCheckPeriod 60s x writerCheckMultiple 3)
If you feel these default settings create cause the system to wait too long before kicking off a re-election then you can update them using an API call:
curl -X POST http://.../fusion/fs/properties/global?path=<mapped path>&writerCheckPeriod=<new period>&writerCheckMultiple=<new multiple>
You can adjust these properties to be optimal for your deployment. However, consider the following pointers:
-
Setting the properties so that the period is very short will ensure that if a writer is lost, a new writer will be brought into action so quickly that there should be no impact on replication. However, very short periods are likely to result in a larger number of false alarms, where writer re-elections are triggered unnecessarily.
-
Setting the properties so that the period is very long will ensure that a re-election only takes place if the current writer is really "out for the count", however, a long delay between the loss of the writer and a new writer picking up could be very detrimental in some situations, such as where very large numbers of small files are being replicated between zones.
10.6. Handling Induction Failure
In the event that the induction of a new node fails, here is a possible approach for manually fixing the problem using the API.
Requirements: A minimum of two nodes with a fusion server installed
and running, without having any prior knowledge about the other. This
can be verified by querying <hostname>:8082/fusion/nodes
10.6.1. Steps:
Generate an xml file (we’ll call it induction.xml) containing an
induction ticket with the inductors details (Generally the inductor port
should not change but this is the port that all DConE traffic uses. You
can find this in your application.properties file as application_port)
<inductionTicket>
<inductorNodeId>${NODE1_NODEID}</inductorNodeId>
<inductorLocationId>${NODE1_LOCATIONID}</inductorLocationId>
<inductorHostName>${NODE1_HOSTNAME}</inductorHostName>
<inductorPort>6789</inductorPort>
</inductionTicket>
Send the xml file to your inductee:
curl -v -s -X PUT -d@${INDUCTION.XML} -H "Content-Type: application/xml" http://${NODE2_HOSTNAME}:8082/fusion/node/${NODE2_IDENTITY}
10.6.2. MEMBERSHIP
Requirements: A minimum of two nodes that have been inducted.
Steps:
Generate an xml file (we’ll call it membership.xml) containing a
membership object. DConE supports various configuration of node roles
but for the time being the Fusion UI only supports
<Acceptor, Proposer, Learner> and <Proposer, Learner>. If you choose
to have an even number of <Acceptor, Proposer, Learner> nodes you must
specify a tiebreaker.
<membership>
<membershipIdentity>${MEANINGFUL_MEMBERSHIP_NAME}</membershipIdentity>
<distinguishedNodeIdentity>${NODE1_NODEID}</distinguishedNodeIdentity>
<acceptors>
<node>
<nodeIdentity>${NODE1_NODEID}</nodeIdentity>
<nodeLocation>${NODE1_LOCATIONID}</nodeLocation>
</node>
<node>
<nodeIdentity>${NODE2_NODEID}</nodeIdentity>
<nodeLocation>${NODE2_LOCATIONID}</nodeLocation>
</node>
</acceptors>
<proposers>
<node>
<nodeIdentity>${NODE1_NODEID}</nodeIdentity>
<nodeLocation>${NODE1_LOCATIONID}</nodeLocation>
</node>
<node>
<nodeIdentity>${NODE2_NODEID}</nodeIdentity>
<nodeLocation>${NODE2_LOCATIONID}</nodeLocation>
</node>
</proposers>
<learners>
<node>
<nodeIdentity>${NODE1_NODEID}</nodeIdentity>
<nodeLocation>${NODE1_LOCATIONID}</nodeLocation>
</node>
<node>
<nodeIdentity>${NODE2_NODEID}</nodeIdentity>
<nodeLocation>${NODE2_LOCATIONID}</nodeLocation>
</node>
</learners>
</membership>
Send the xml file to one of your nodes:
curl -v -s -X POST -d@${MEMBERSHIP.XML} -H "Content-Type: application/xml" http://${NODE_HOSTNAME}:8082/fusion/node/${NODE_IDENTITY}/membership
10.6.3. STATEMACHINE
Requirements: A minimum of two nodes inducted together and a membership created that contains them (you’ll want to make a note of the membership id of your chosen membership).
Steps:
Generate an xml file (we’ll call it statemachine.xml) containing a
fsMapping object.
<replicatedDirectory>
<uri>${URI_TO_BE_REPLICATED}</uri>
<membershipId>${MEMBERSHIP_ID}</membershipId>
<familyRepresentativeId>
<nodeId>$NODE1_ID</nodeId>
</familyRepresentativeId>
</replicatedDirectory>
Send the xml file to one of your nodes:
curl -v -s -X POST -d@${STATEMACHINE.XML} -H "Content-Type: application/xml" http://${NODE1_HOSTNAME}:8082/fusion/fs
10.7. Emergency bypass to allow writes to proceed
If WD Fusion is down and clients use the HDFS URI, then further writes will be blocked. The emergency bypass feature gives the administrator an option to bypass WD Fusion and write to the underlying file system, which will introduce inconsistencies between zones. This is suitable for when short-term inconsistency is seen as a lesser evil compared to blocked progress.
The inconsistencies can then be fixed later using the Consistency and Repair process(es). A client that is allowed to bypass to the underlying filesystem will continue to bypass for the duration of the retry interval. Long-running clients will automatically reload configurations at a hardcoded 60 second interval. Thus it is possible to disable and enable the bypass on-the-fly.
Don’t enable the Emergency bypass
We strongly recommend that you currently don’t use the bypass option. We’re investigating a possible issue where enabling the Emergency bypass
may cause application instability during periods of high activity.
10.8. Enable/disable emergency bypass via the UI
-
Log in to the Fusion UI and go to the Settings tab. Click Client Bypass Settings.
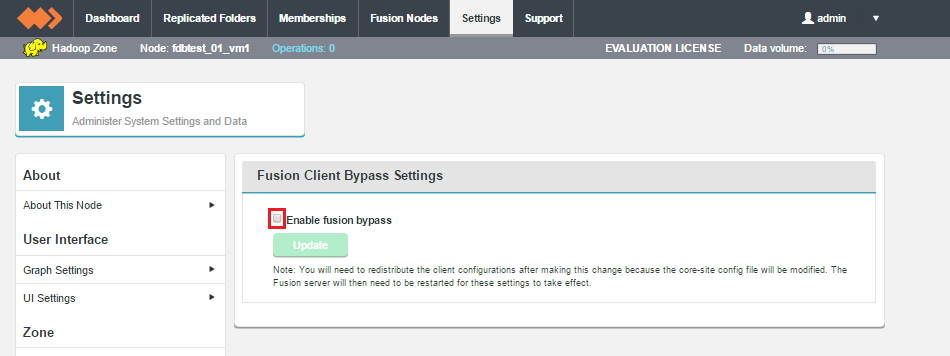 Figure 186. Client Bypass - step1
Figure 186. Client Bypass - step1 -
Tick the Enable fusion bypass checkbox. This will enable two entry fields for configuration:
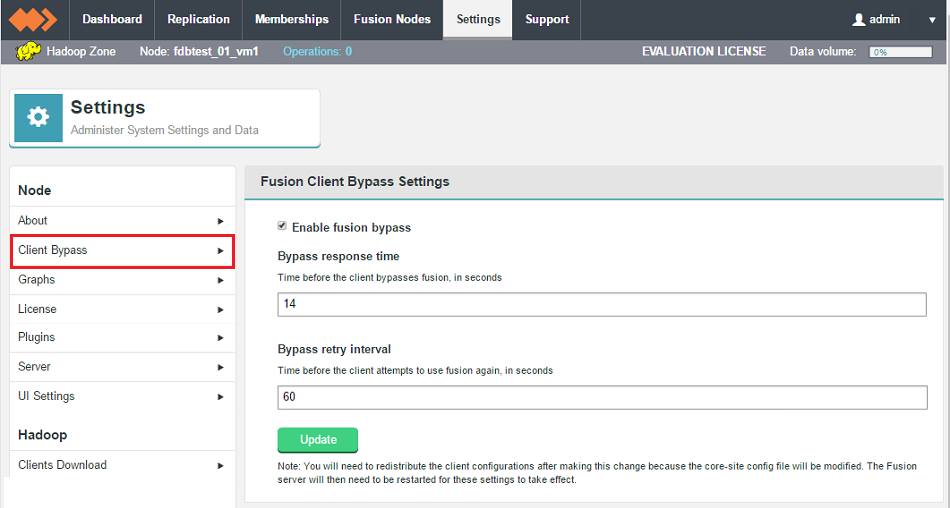 Figure 187. Client Bypass - step2
Figure 187. Client Bypass - step2- Bypass response time
-
The time (in seconds) that will pass before the client will bypass WD Fusion. Default: 14.
- Bypass retry interval
-
The time (in seconds) before the client attempts to use WD Fusion, again. Default: 60.
-
Click Update to save your changes.
10.9. Enable/disable emergency bypass via manual configuration change
In core-site.xml add the following properties:
<property> <name>fusion.client.can.bypass</name> <value>true or false; default is false</value> </property> <property> <name>fusion.client.bypass.response.secs</name> <value>integer number representing seconds; default is 14</value> </property> <property> <name>fusion.client.bypass.retry.interval.secs</name> <value>integer number representing seconds; default is 60</value> </property>
The properties are also listed in the Reference Section.
|
*Known Issue: Failed to install metastore service during fusion installation in HDP 2.4, 2.5
Example failure, during an Ambari-based installation. The error is caused by
the stack not being available via ambari-server.

|
Workaround
To fix this you need to ensure that only a single Ambari-server process
is running before doing the service ambari-server restart. To find the
ambari-server processes that are running you can use.
ps -aux | grep ambari-serverThen kill all the ambari-server processes by using
kill -9 [pid of process]then restart the ambari-server by using
service ambari-server restartAlso rerun the check to ensure you only have a single process running:
ps -aux | grep ambari-serverYou can then check in the Ambari UI if the WD Hive Metastore and WD Hiveserver2 Template services are available. If they are present then you will be ok to proceed with retrying to install the service via the installer.
10.10. Kerberos Troubleshooting
This section covers some recommended fixes for potential Kerberos problems.
10.10.1. Kerberos Error with MIT Kerberos 1.8.1 and JDK6 prior to update 27
Prior to JDK6 Update 27, Java fails to load the Kerberos ticket cache correctly when using MIT Kerberos 1.8.1 or later, even after a kinit.
The following exception will occur when attempting to access the Hadoop cluster.
WARN ipc.Client: Exception encountered while connecting to the server : javax.security.sasl.SaslException: GSS initiate failed [Caused by GSSException: No valid credentials provided (Mechanism level: Failed to find any Kerberos tgt)]
The workaround is:
-
Renew the local Kerberos ticket with "kinit -R". (This requires that the Kerberos ticket is renewable) This is fixed in JDK 6 Update 27 or later: http://www.oracle.com/technetwork/java/javase/2col/6u27bugfixes-444150.html
-
See: CCacheInputStream fails to read ticket cache files from Kerberos 1.8.1
Kerberos 1.8.1 introduced a new feature by which configuration settings can be stored in the ticket cache file using a special principal name.
10.10.2. Error "Can’t get Kerberso realm" when installing WD Fusion.
WD Fusion uses the settings that are written in the krb5.conf file to configure Kerberos. The default realm (default_realm) is one of the values that must be specified. If not, then the JVM will fallback by trying to get the default realm through DNS. If this fails, then you see the "Can’t get Kerberos realm" error message.
Workaround
The workaround is to properly configure the default_realm in krb5.con.
11. Uninstall WD Fusion
In cases where you need to remove WD Fusion from a system, use the following script:
/opt/wandisco/fusion-ui-server/scripts/uninstall.sh
-
The script is placed on the node during the installation process.
-
You must run the script as root or invoke sudo.
-
Running the script without using an additional option performs the following actions.
A default uninstall using the script:
-
Stops all WD Fusion related services
-
Uninstalls the WD Fusion, IHC and UI servers
-
Uninstalls any Fusion-related plugins (See Plugins)
-
Uninstalls itself.
After running the script you will need to:
11.2. Uninstall with config purge
Running the script with -p will also include the removal of any configuration changes that were made during the WD Fusion installation.
Reinstallation
Use the purge (-p) option in the event that you need to complete a fresh installation.
As the purge option will completely wipe your installation, there’s a backup option that can be run to back up your config files. Please note that the backup option is for recording final state/capturing logs for analysis. It isn’t practical for this option to be used to restore an installation.
11.3. Backup config/log files
Run the script with the -c option to back up your config and -l to back up WD Fusion logs. The files will be backed up to the following location:
/tmp/fusion_config_backup/fusion_configs-YYYYMMDD-HHmmss.tar.gz
Change the default save directory
You can change the locations that the script uses for these backups by adding the following environmental variables:
CONFIG_BACKUP_DIR=/path/to/config/backup/dir LOG_BACKUP_DIR=/path/to/log/backup/dir
11.4. Help
Running the script with -h outputs a list of options for the script.
[sysadmin@localhost ~]$ sudo /opt/wandisco/fusion-ui-server/scripts/uninstall.sh -h Usage: /opt/wandisco/fusion-ui-server/scripts/uninstall.sh [-c] [-l] [-p] [-d] -c: Backup config to '$CONFIG_BACKUP_DIR' (default: /tmp/fusion_config_backup). -d: Dry run mode. Demonstrates the effect of the uninstall without performing the requested actions. -h: This help message. -l: Backup logs to '$LOG_BACKUP_DIR' (default: /tmp/fusion_log_backup). -p: Purge config, log, data files, etc to leave a cleaned up system.
11.5. Uninstalling Fusion - Ambari
11.5.1. Through Terminal
-
Remove the packages on the WD Fusion Node.
yum remove -y “fusion-*”
-
Remove the jars, logs, configs.
rm -rf /opt/wandisco/ /etc/wandisco/ /var/run/fusion/ /var/log/fusion/
11.5.2. Through the Ambari UI
-
Click on Services, then HDFS. Next go to the Configs tab and then Advanced.
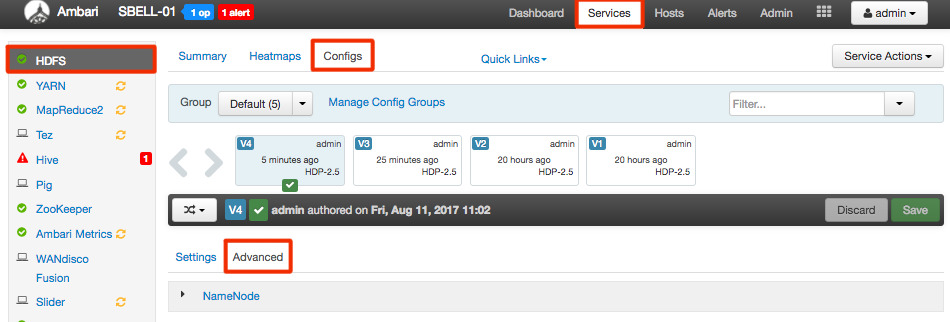
-
Scroll down until you come to the Custom core-site section.
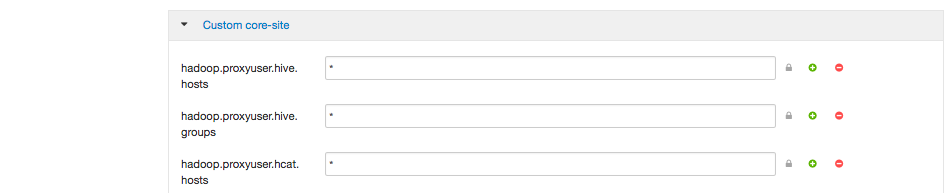
Remove all WD Fusion related elements, for example
fs.fusion.underlyingFsandfs.hdfs.impl. -
Save changes.

11.5.3. Clean WD Fusion HD
Go through the following steps before installing a new version of WD Fusion:
-
On the production cluster, run the following curl command to remove the service:
curl -su <user>:<password> -H "X-Requested-By: ambari" http://<ambari-server>:<ambari-port>/api/v1/clusters/<cluster-name>/services/FUSION -X DELETE
Replacing the following with your specific information:
-
<user>:<password> - login and password used for Ambari
-
<ambari-server>:<ambari-port> - the URL used to access Ambari UI
-
<cluster> refers to the cluster name - it can be seen at the very top next to the Ambari logo
-
-
On ALL nodes, run the corresponding package manager to remove the client package command. Firstly find your version using the command:
rpm -qa 'fusion*'
Then run the following command, using your version number:
yum remove fusion-hcfs-hdp-2.6.0-client-hdfs-2.10.3.el6-2477.noarch
-
Now go to the Ambari UI homepage and restart Hive.
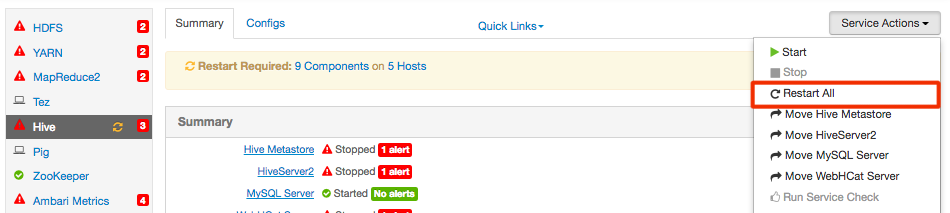
-
In terminal, remove all packages from clients if they exist.
yum remove -y fusion*client*.rpm
-
Restart services in Ambari.
-
Finally, in Ambari, make sure the following properties are removed from
core-site.xmlin the HDFS service:-
Fs.fusion.server -
Fs.hdfs.impl -
Fs.fusion.impl
-
11.6. Uninstalling Fusion - Cloudera
11.6.1. Through the Cloudera UI
-
From the Cloudera homepage click on hfds1 and then Configuration.
In the search box, search for Fusion.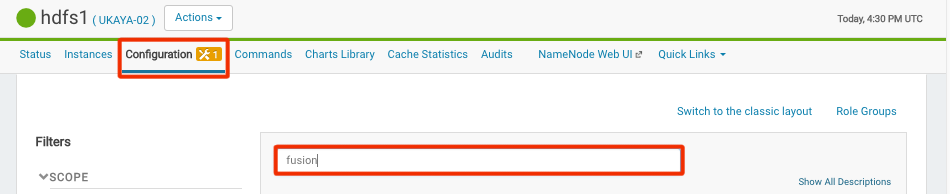
-
Remove all WD Fusion related elements and then save the changes.
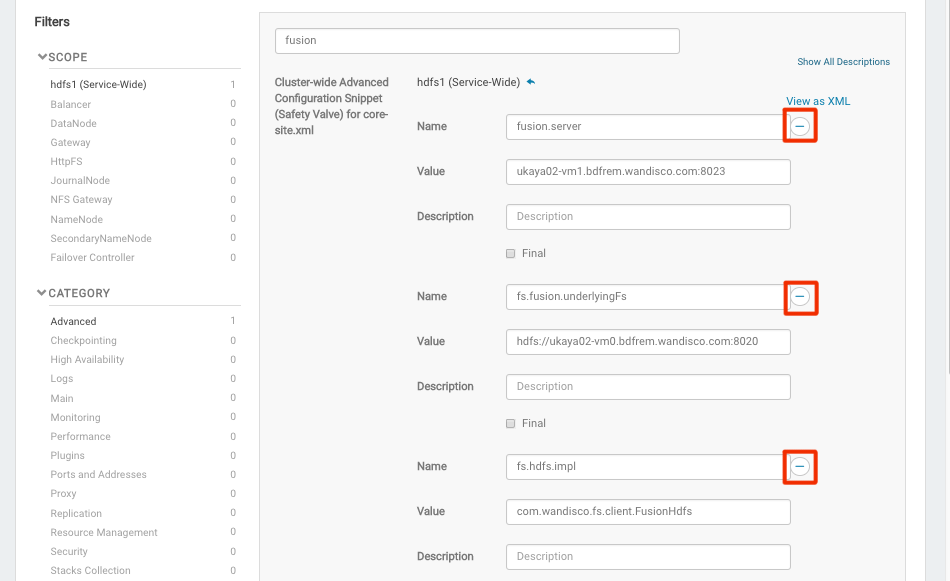
-
Stop the Cluster or Hosts that are still running Fusion.
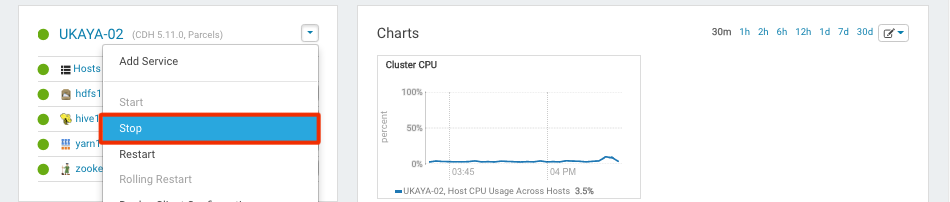
-
Now click on the Parcels icon.

-
Scroll down to FUSION and click Deactivate.

-
On the pop out, change to Deactivate only.
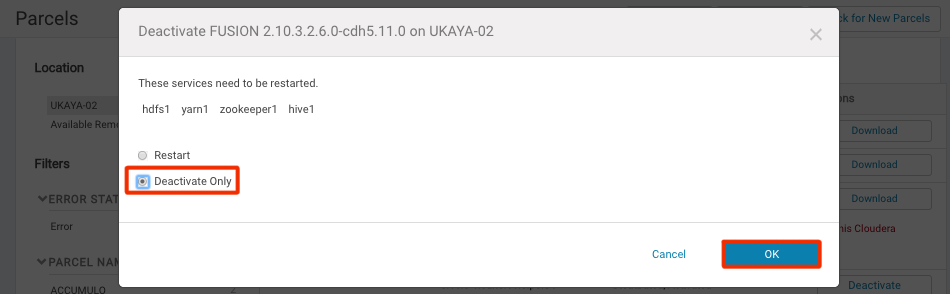
-
Now click Remove From Hosts.

Confirm the removal.
-
Start Clusters and Hosts that were stopped.
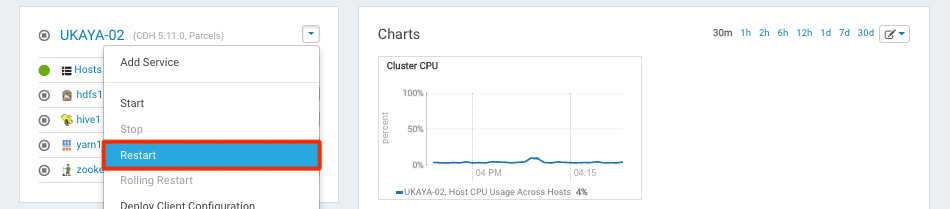
-
Restart services as necessary for configuration changes to go through. These will be highlighted by warnings in the UI.
12. Managing Replication
WD Fusion is built on WANdisco’s patented DConE active-active replication technology. DConE sets a requirement that all replicating nodes that synchronize data with each other are joined in a "membership". Memberships are coordinated groups of nodes where each node takes on a particular role in the replication system.
For more information about DConE and its different roles see the reference section’s chapter called A Paxos Primer.
12.1. Create a membership
Log in to the WD Fusion UI and click on the Membership tab. Click on the Create New tab. The New Membership window will open and will display the WD Fusion nodes organized by zone.
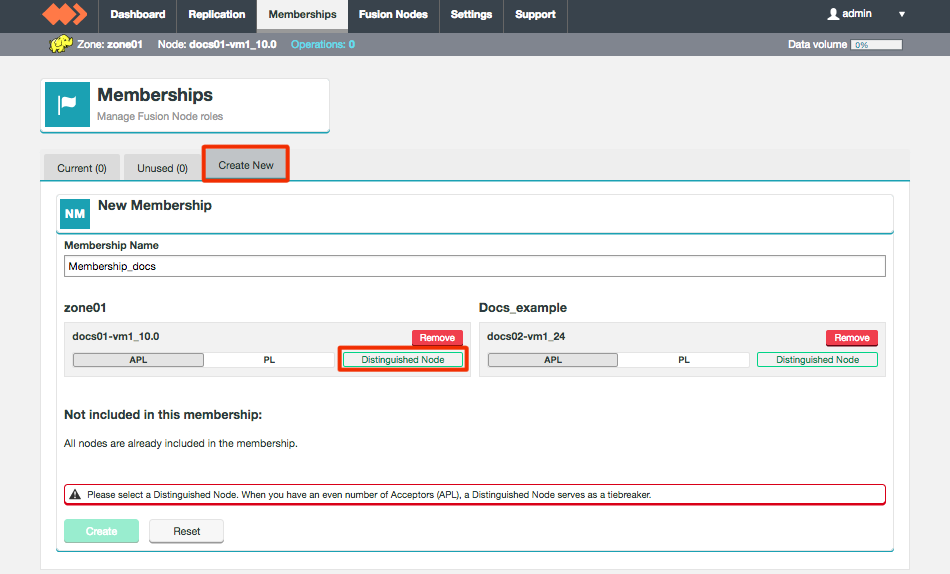
Give the new membership a name and configure it by selecting which nodes should be acceptors.
Acceptors vote on the ordering of changes.
Note: a membership with an even number of nodes requires that one of the nodes be upgraded to a Distinguished Node.
For some guidance on the best way to configure a membership read Create Resilient Memberships in the reference section.
Click Create to complete the operation. Click Cancel to discard the changes.
Identical memberships are not allowed
You will be prevented from creating more than 1 membership with a particular configuration.

12.2. Guide to node types
- APL
-
Acceptor - the node will vote on the order in which replicated changes will play out.
Proposer - the node will create proposals for changes that can be applied to the other nodes.
Learner - the node will receive replication traffic that will synchronize its data with other nodes. - PL
-
Proposer - the node will create proposals for changes that can be applied to the other nodes.
Learner - the node will receive replication traffic that will synchronize its data with other nodes. - Distinguished Node
-
*Acceptor * - the distinguished node is used in situations where there is an even number of nodes, a configuration that introduces the risk of a tied vote. The Distinguished Node’s bigger vote ensures that it is not possible for a vote to become tied.
12.3. Replicated Folders
WD Fusion allows selected folders within your hdfs file system to replicated to other data centers in your cluster. This section covers the set up and management of replicated folders.
12.3.1. Create a replicated folder
The first step in setting up a replicated folder is the creation of a target folder:
-
In each zone, create a directory in the hdfs file space. To avoid permission problems, ensure that the owning user/group are identical across the zones. Use Hadoop’s filesystem command to complete the tasks:
hadoop fs -mkdir /user/hiver hadoop fs -chown -R hiver:groupname /user/hiver
-
As user hdfs, run the following commands on each data center:
hadoop fs -mkdir /user/hiver/warehouse-replicated hadoop fs -chown hiver:hiver /user/hiver/warehouse-replicated
This ensures that the a universal system user has read/write access to the hdfs directory
warehouse-replicatedthat will be replicated through WD Fusion.
12.4. Create Rule
-
Once the folder is in place on all nodes, log in to WD Fusion’s UI on one of the WD Fusion nodes and click on the Replicated Folders tab.
-
Click on the + Create button.
 Figure 190. Create rule 1
Figure 190. Create rule 1 -
The replicated folder entry form screen will appear.
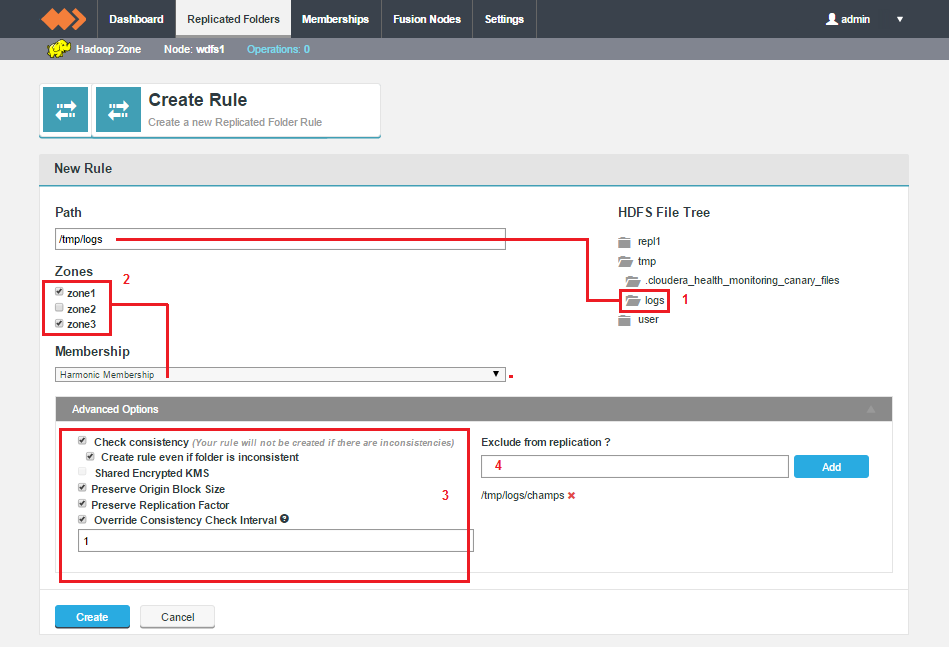 Figure 191. Create rule 2
Figure 191. Create rule 2Navigate the HDFS File Tree (1), on the right-hand side of the New Rule panel to select your target folder, created in the previous section. The selected folder will appear in the Path entry field. You can, instead, enter the full path to the folder in the Path directory.
Next, select two or more zones from the Zones list (2). You then select a Membership from the dropdown selector. If there’s no existing membership with the combination of Zones that you selected, then you will see the message:
There are no memberships available matching your criteria.
In this case you can create a new membership, see Create a membership and restart the Create Replicated Folder process.
-
You can now complete the creation of the Replicated folder by clicking on the Create button. However, there are some additional options available on the Advanced Options panel. Consider if you need to apply any Advanced Options for the folder.
Note that the allocated writer for this zone is listed under the a Advanced Options panel. This can be useful information in case you need to troubleshoot replication problems.
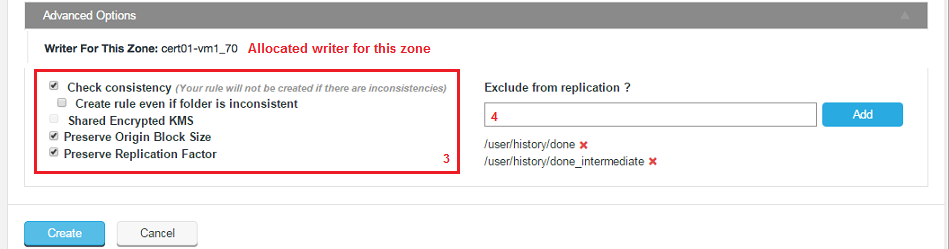
These include Preserve Origin Block Size, which is used for columnar storage formats such as parquet, Preserve Replication Factor which is used when want replica data to continue to use the replication factor that is set on its originating cluster, rather than the use the factor that applies on the new cluster.
Exclude from replication? lets you set an "exclude pattern" to indicate files and folders in your replicated folder that you don’t want to be replicated. If you apply any Advanced Options you need to click the Update button to make sure that they are applied.
The option Override Consistency Check Interval allows administrators to set a consistency check interval that is specific to the replicated folder space and different from the default value that is set in the Consistency Check section of the Settings tab.
12.4.1. Path interpretation
If the path contains a leading slash "/", we assume it is an absolute
path, if it contains no leading slash then we assume it is a relative
path and the root directory will be added to the beginning of the
exclusion.
-
If you didn’t complete a consistency check on the selected folder, you may do so now.
 Figure 193. Replicate to Zones
Figure 193. Replicate to Zones -
After the completion of a consistency check, the Consistency column will report the consistency status.
 Figure 194. Replicated folder status
Figure 194. Replicated folder status
12.5. View/Edit
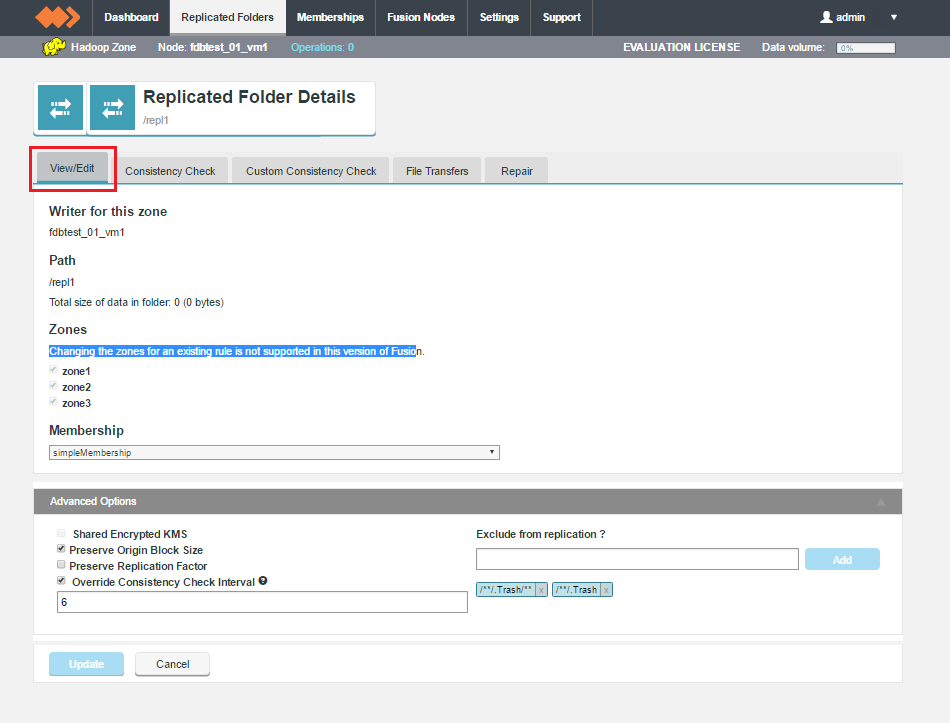
The View/Edit tab lets you make changes to selected properties of the Replicated Folder:
- Writer for this zone
-
Indicates which node is set to handle writes for this zone.
- Path
-
The file path for the replicated folder in question.
- Zones
-
The zones that are replicated between, for the corresponding folder.
- Membership
-
The membership used to define the replication.
- Advanced Options
-
Various advanced options that can be set for a replicated folder. See Advanced Options.
12.6. Consistency Check
The Consistency Check and Custom Consistency Check tabs provide means of checking the consistency of files (and their related metadata) that are stored in your replicated folders.
|
Username Translation
If any nodes that take part in a consistency check have the
Username Translation feature
enabled, then inconsistencies in the "user" field will be ignored.
|
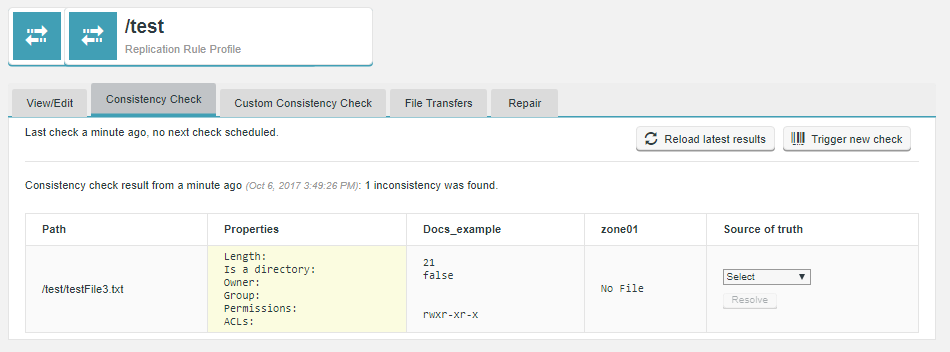
A status message appears at the top of the panel that indicates if and when a consistency check has recently been performed on this path.
You can click on Reload latest results to view the cached results from a previous check, or you can click Trigger new check to run a new check.
- Path
-
The path to the replicated folder currently being viewed for consistency.
- Properties
-
The system properties for the folder, including the following properties:
-
Length: - byte length of the file (in kilobytes)
-
Is a directory: - distinguishes files from directories (true or false)
-
Owner: - Owning system account
-
Group: - Associated system account group
-
Permissions: - File permissions applied to the element
-
ACLs: - Associated Access Control Lists for the element
-
- Zone columns
-
Columns will appear for each replicated zone that should contain a copy of the available metadata, as labeled in the Properties field.
- Source of truth
-
From the available zones, you must choose the one that represents the most up-to-date state.
- Resolve
-
Once you have selected from the available zones, click the Resolve button.
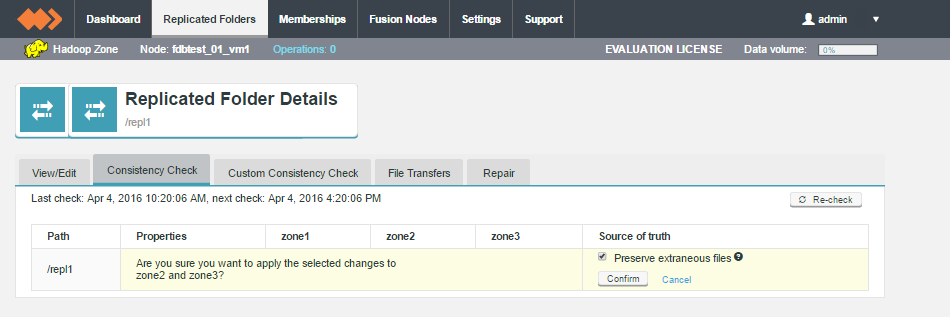
12.6.1. Performing a Consistency Check
There are three different ways of doing a Consistency Check:
Consistency Check by Checkbox
-
Select a Path from the Replication Rules table using the check box column.
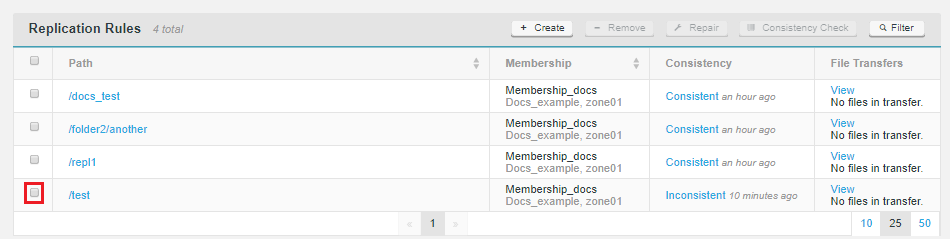 Figure 198. Consistency Check - Checkbox1
Figure 198. Consistency Check - Checkbox1 -
The rule-specific options on the top of the panel will no longer be greyed-out. Click on the Consistency Check button.
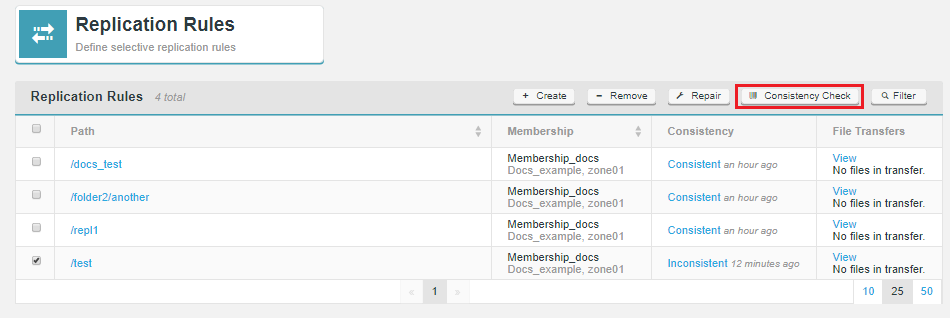 Figure 199. Consistency Check - Check
Figure 199. Consistency Check - Check -
The selected rule will now be checked in the background.
 Figure 200. Consistency Check - Await result
Figure 200. Consistency Check - Await resultThe results will appear in the Consistency column as either "Not Checked", "Consistent" or "Inconsistent". This result is also a link into the dedicated Consistency Check tab.
Consistency Check by Consistency link
You can go to to the Consistency Check tab by clicking on the consistency status link in the Consistency column.

You will see a confirmation message concerning your choice of repair. There is a checkbox that lets you choose to Preserve extraneous files, Click Confirm to complete the repair.
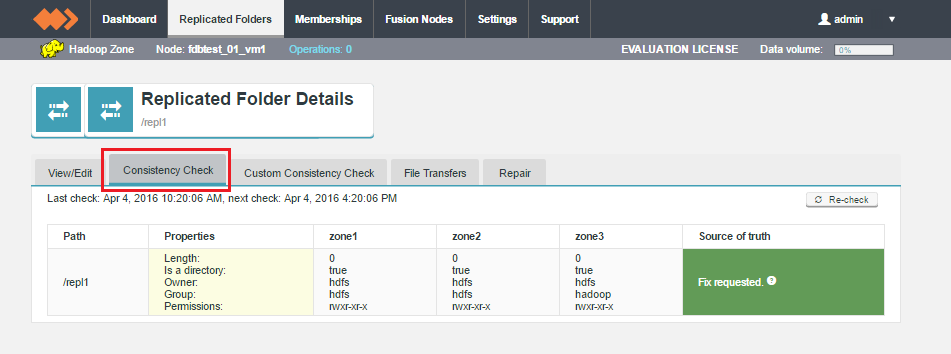
After clicking Confirm, you will get a rundown of the state of each zone, after the repair has been completed.

12.6.2. Custom Consistency Check
You can use the Fusion Web UI to selectively choose which files to repair in the UI when you have a small number of files that exists on both sides and a decision needs to be made as to which one is the source of truth.
-
In the UI on the Replicated Folders tab click the Inconsistent link in the Consistency column to get to the Consistency Report.
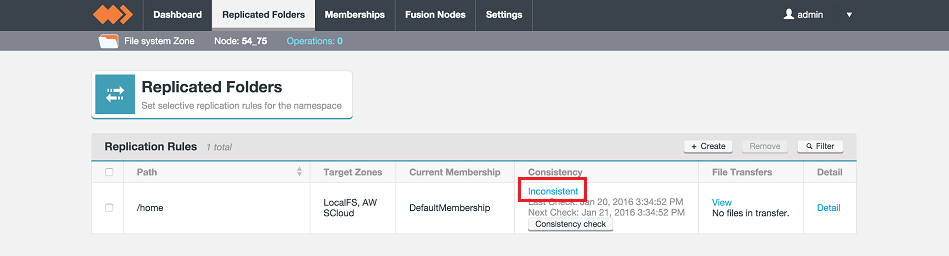 Figure 205. Replicated Folders
Figure 205. Replicated Folders -
If the list of files is small you’ll be presented with a list. If it is longer than 100 files you will need to click Show All Inconsistencies. Note that you can still bulk resolve these.
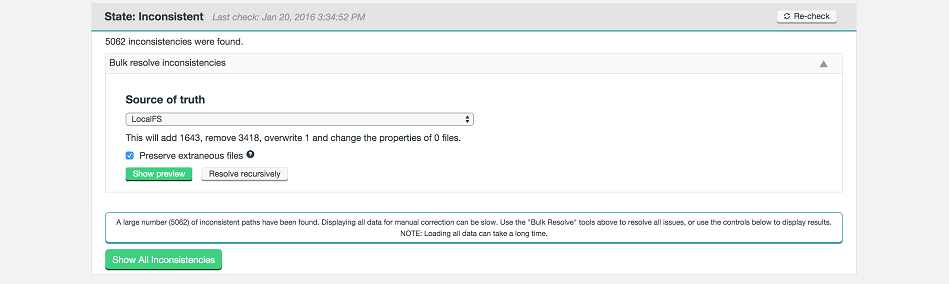 Figure 206. Show All Inconsistencies
Figure 206. Show All Inconsistencies -
For each file, you can choose the Zone that is the source and click resolve.
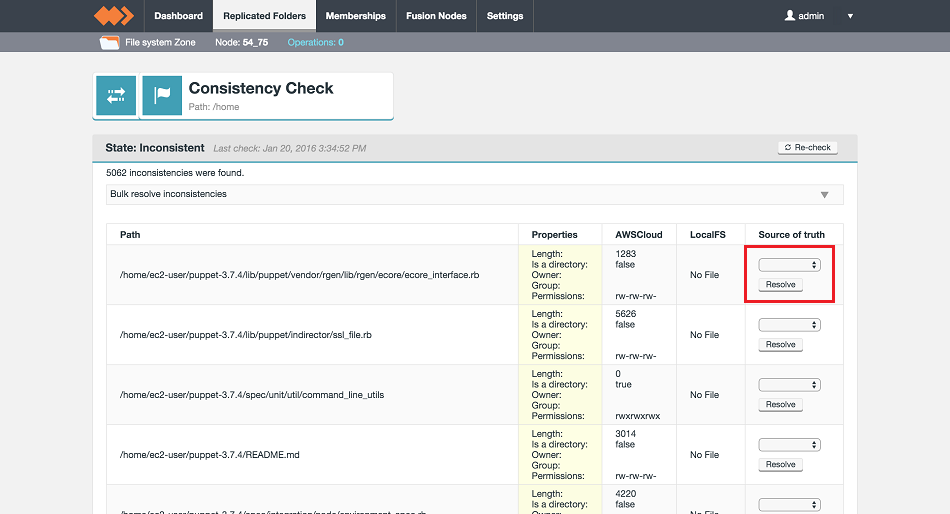 Figure 207. Choose a Zone
Figure 207. Choose a Zone -
You will be prompted with a confirmation button.
 Figure 208. LocalFS
Figure 208. LocalFS -
After clicking resolve, you will see a message Fix Requested. You can check the UI in the target zone file transfers if you want to verify the repair.
 Figure 209. Fix Requested
Figure 209. Fix Requested
12.7. File Transfers
The File Transfer panel shows the movement of data coming into the zone.
12.8. Repair
The repair tab provides a tool for repairing file inconsistencies between available zones. The repair tool provides three different types of repair operation, based on the option you select from the Repair Type dropdown.

- HCFS Repair
-
this is a consistency repair on the live Hadoop Compatible File System. This method is the most direct for making repairs, although running a repair will stop writes to the replicated folder in the local zone. The block is removed once the repair operation completes.
- Checkpoint Repair
-
this option uses the fsimage checkpoints created by Hadoop’s admin tool. The use of a snapshot from the nameode ensures that the local filesystem does not get locked during the repair.
- SnapDiff (NetApp)
-
The Snapdiff implementation of repair allows a repair to be driven by the use of the Netapp snapdiff API. The process for use of the snapdiff implementation of snapshot repair is detailed below. See Repair type SnapDiff (NetApp)
12.8.1. Repair type HCFS
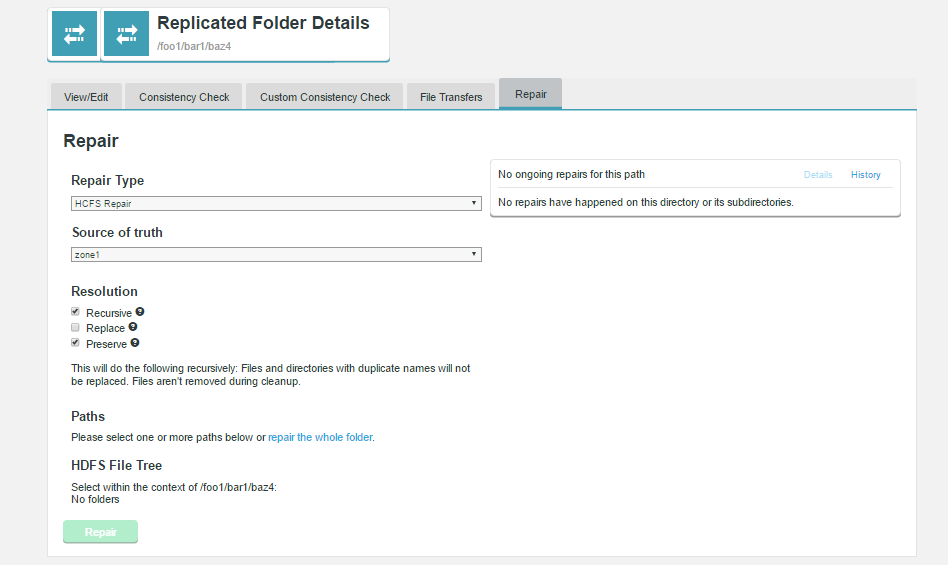
Run through the following procedure to perform a repair:
-
Select the Source of truth from the dropdown. This will flag one of the available zones as most up-to-date / most correct in terms of stored data.
-
Select from one of two Resolution types, Recursive or Preserve
- Recursive
-
If checkbox is ticked, this option will cause the path and all files under it to be made consistent. The default is true, but is ignored if the path represents a file.
- Preserve
-
If checkbox is ticked, when the repair is executed in a zone that is not the source zone, any data that exists in that zone but not the source zone will be retained and not removed. The default is false, i.e., to make all replicas of the path consistent by removing all data in the no-source zone(s) that does not exist in the source.
- path
-
The path for which the list of repairs should be returned. The default value is the root path, "/".
- recursive
-
If true, also get repairs done on descendants of path. This option is false by default.
- showAll
-
Whether or not to include past repairs for the same file. The options are "true" to show all repairs on the given path, and "false" to show only the last repair.
- sortField
-
The field by which the entries in the
RepairListDTOshould be sorted. The options are to sort by the "startTime" or "path" property. The default value is "path". - sortOrder
-
The order in which the entries should be sorted according to the sort field. The options are to sort in ASC (ascending) or DESC (descending) order.
- return
-
A RepairListDTO representing a list of repairs under path.
Command-line only
The Repair status tool is currently only available through the command-line. In the next release the functionality will be added to the Fusion UI.
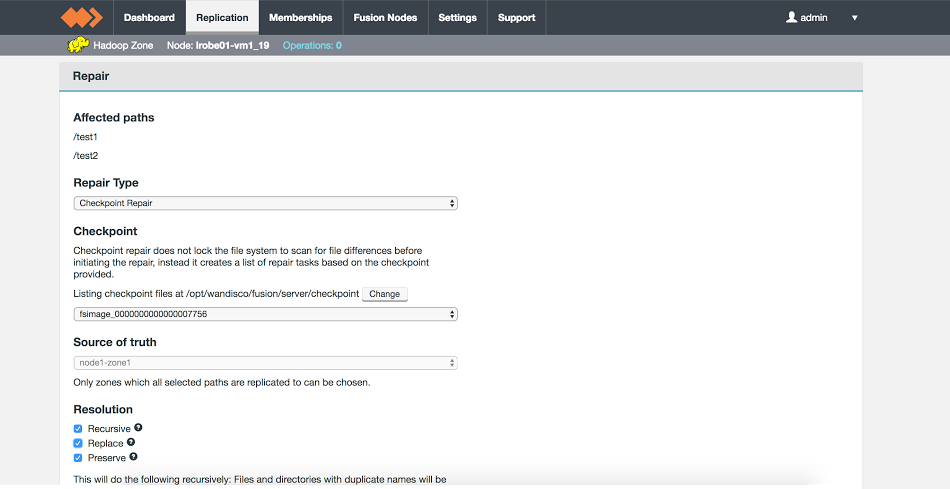
12.8.3. Repair type SnapDiff (NetApp)
SnapDiff is an internal Data ONTAP engine that quickly identifies the file and directory differences between two Snapshot copies. See What SnapDiff is.
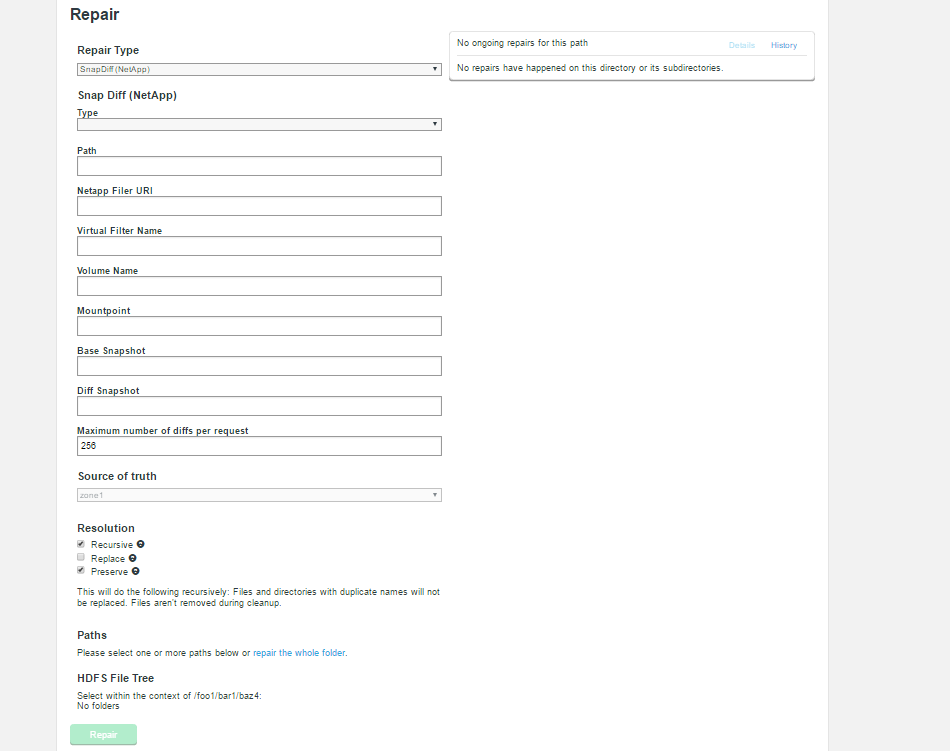
- Type
-
The type of repair that you wish to start. hdfs or ontap
- Path
-
The replicated system path.
- Netapp filter URI
-
The URI used for Natapp API traffic.
- Virtual Filter Name
-
A name provided for the virtual filter.
- Volume Name
-
Storage volume name.
- Mountpoint
-
Path where the volume is mounted on the underlying filesystem.
- Base Snapshot
-
Name of the base snapshot. Diffs are calculated as deltas between a base and diff snapshot
- Diff Snapshot
-
Name of the diff snapshot
- Maximum number of diffs per request
-
Max diffs returned per request. See MaxDiffs.
- Source of truth
-
The node on which the most correct/update data is stored.
- Resolution of truth
-
Mechanism that determines how the latest/most correct data is copied into place.
- Paths
-
Paths to replicated files.
- HDFS File Tree
-
Rendered view of the current file tree.
-
A user initiates a snapshot of the NFS content (externally to WD Fusion). This will be called the “base snapshot”.
-
Time passes, changes occur in that NFS file system.
-
The user initiates another snapshot of that content (externally to Fusion) - this will be called the “diff snapshot”.
-
The user invokes the snapshot repair API, including this information:
-
Required parameters:
HTTP authentication (user/password) in the header of the request. Ontap requires this to invoke their API.
- snapshotType
-
The type of repair that you wish to start. hdfs or ontap.
- path
-
Replicated path.
- endpoint
-
URI of the Netapp Filer serving Ontap requests.
- vfiler
-
Name of the virtual filer.
- volume
-
The exported volume.
- mountpoint
-
Path where the volume is mounted on the underlying filesystem.
- baseSnapshot
-
Name of the base snapshot. Diffs are calculated as deltas between a base and diff snapshot.
- diffSnapshot
-
Name of diff snapshot.
Optional parameters:
- recursive
-
Indicates whether subdirectories should be considered.
|
Non-Recursive requests in 2.10
In Fusion 2.10, if the recursive parameter is set to "false", the parameter is ignored. NetApp snapshots are ALWAYS recursive over a directory hierarchy. From 2.10.2 and beyond, an error code will be returned instead — it’s not a valid request for this API call.
|
- replace
-
Replace files/dirs of the same name on the receiving zone.
- preserve
-
If preserve == true, do not remove any files on the receiving zone that don’t exist on the source zone.
- maxDiffs
-
Max diffs returned per request. There is a hard limit of 256, unless an admin goes to the admin server and changes the registry keys:
|
To change maxDiff limit on the Netapp Filer:
Use the following steps.
|
system node run -node "nameofvserver" priv set advanced registry walk registry set options.replication.zapi.snapdiff.max_diffs SOMENUMBER
Example to invoke via curl:
curl --user admin:Ontap4Testing -v -X PUT 'http://172.30.1.179:8082/fusion/fs/repair/snapshot?snapshotPath=/tmp/snapshot1&snapshotType=ontap&path=/tmp/repl1/vol1&endpoint=https://172.30.1.200:443/servlets/netapp.servlets.admin.XMLrequest_filer&vfiler=svm_taoenv&volume=vol1&maxDiffs=256&mountpoint=/tmp/repl1/vol1&preserve=true&baseSnapshot=snap1&diffSnapshot=snap2'
-
The snapshot repair then executes as per the standard repair mechanism to update zones, but will only consider the information that has changed between the base and diff snapshots. The intention is for the base snapshot to reflect the known state of all zones at a prior point in time, and to use the difference between it and the diff snapshot for reconciliation. Non-source zones for snapshot repair with this mechanism trust that the difference between the base and diff snapshots is a true representation of the changes required.
The user interaction with Fusion should be similar to that offered for HDFS-based snapshot repair, with the addition of extra parameters for initiation of the snapshot repair. She should be presented with the option to select the type of the snapshot repair to be performed, and required input fields should adjust based on that indication. Validation of information provided is helpful, but not required for a first UI implementation. In particular, Fusion should not be responsible for storing or providing selection from a list of snapshot names (as these are generated externally).
12.8.4. Running initial repairs
If you have a large folder you can parallelize the initial repair using the Fusion API. This can be accomplished on a single file or a whole directory. Choosing a directory will push all files from the source to the target regardless of existence at the target.
Consider the following directory structure for a fusion replicated folder /home
/home /home/fileA /home/fileB /home/userDir1 /home/userDir2 /home/userDir3
We could run a bulk resolve in the UI against the /home directory, however, to provide parallelism of the repair operations we can use the Fusion API to issue repairs against each folder and the individual files in the /home folder.
Example - Multiple API Calls using curl
curl -X PUT "FUSION_NODE:8082/fusion/fs/repair?path=/home/userDir1&recursive=true&src=LocalFS" curl -X PUT "FUSION_NODE:8082/fusion/fs/repair?path=/home/userDir2&recursive=true&src=LocalFS" curl -X PUT "FUSION_NODE:8082/fusion/fs/repair?path=/home/userDir3&recursive=true&src=LocalFS" curl -X PUT "FUSION_NODE:8082/fusion/fs/repair?path=/home/fileA&recursive=false&src=LocalFS" curl -X PUT "FUSION_NODE:8082/fusion/fs/repair?path=/home/fileB&recursive=false&src=LocalFS"
This will spawn simultaneous repairs increasing the performance of the initial synchronization. This is especially helpful when you have small file sizes to better saturate the network.
For files, the recursive parameter is ignored
You can use the file transfers view in the Fusion UI on the OpenStack-replicating node to monitor the incoming files.
12.9. Configure Hadoop
Once WD Fusion has been installed and set up, you will need to modify your Hadoop applications so that when appropriate, they write to your replicated folder.

Configure Hadoop applications to write to the replicated file space.
12.10. Configure for High Availability Hadoop
If you are running Hadoop in a High Availability (HA) configuration then you should run through the following steps for WD Fusion:
-
Enable High Availability on your Hadoop clusters. See the documentation provided by your Hadoop vendor, i.e. - Cloudera or Hortonworks.
The HA wizard does not set the HDFS dependency on ZooKeeper
Workaround:-
Create and start a ZooKeeper service if one doesn’t exist.
-
Go to the HDFS service.
-
Click the Configuration tab.
-
In the Service-Wide category, set the ZooKeeper Service property to the ZooKeeper service.
-
-
Edit WD Fusion configuration element ‘fusion.underlyingFs’ to match the new nameservice ID in the cluster-wide
core-site.xmlin your Hadoop manager.
E.g, change:<property> <name>fusion.underlyingFs</name> <value>hdfs://vmhost08-vm0.cfe.domain.com:8020</value> </property>To:
<property> <name>fusion.underlyingFs</name> <value>hdfs://myCluster</value> </property> -
Click Save Changes to commit the changes.
-
If Kerberos security is installed make sure the configurations are there as well: Setting up Kerberos with WD Fusion.
-
You’ll need to restart all Fusion and IHC servers once the client configurations have been deployed.
12.11. Known issue on failover
Where High Availability is enabled for the NameNode and WD Fusion, when the client attempts to failover to the Standby NameNode it generates a stack trace that outputs to the console. As the WD Fusion client can only delegate the method calls to the underlying FileSystem object, it isn’t possible to properly report that the connection has been reestablished. Take care not to assume that a client has hung, it may, in fact, be in the middle of a transfer.
12.12. Reporting
The following section details with the reporting tools that WD Fusion currently provides.
12.12.1. Consistency Check
The consistency check mechanism lets you verify that replicated HDFS data is consistent between sites. Read about Handling file inconsistencies.
12.12.2. Consistency Checks through WD Fusion UI
|
Username Translation
If any nodes that take part in a consistency check have the
Username Translation feature
enabled, then inconsistencies in the "user" field will be ignored.
|
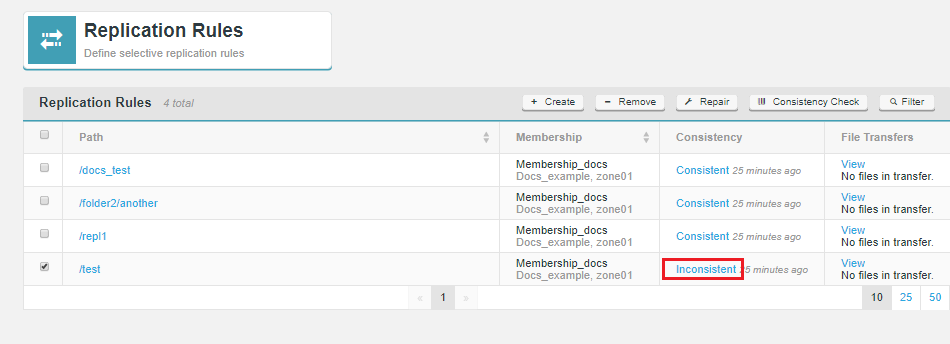
12.12.3. Consistency
- Consistency Status
-
A status which links to the consistency check report. It can report Check Pending, Inconsistent, Consistent or Unknown.
- Last Check
-
Shows the time and date of the check that produced the current status. By default, Consistency checks are not automatically run.
- Next Check
-
Shows the time and date of the next automatically scheduled Consistency Check. Remember, you don’t need to wait for this automatic check, you can trigger a consistency check at any time through the Consistency Check tool.
Click on the Consistency/Inconsistency link to get more information about the consistency check results for a selected path.
Read more about Consistency Check tool.
12.13. 4.3.2 File Transfer Report
As a file is being pulled into the local zone, the transfer is recorded in the WD Fusion server and can be monitored for progress.
Use the REST API filter by the replicated path and sort by ascending or descending "complete time" or "start time":
GET /fusion/fs/transfers?path=[path]&sortField=[startTime|completeTime]&order=[ascending|descending]
12.14. File transfer Report Output
Example output showing an in-progress and completed transfer:
<?xml version="1.0" encoding="utf-8" standalone="yes"?>
<fileTransfers>
<fileTransfer>
<startTime>1426020372314</startTime>
<elapsedTime>4235</elapsedTime>
<completeTime>1426020372434</completeTime>
<username>wandisco</username>
<familyRepresentativeId>
<nodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</nodeId>
<dsmId>93452fe3-c755-11e4-911e-5254001ba4b1</dsmId>
</familyRepresentativeId>
<file>/tmp/repl/isoDEF._COPYING_<;/file>
<remoteFs>hdfs://vmhost5-vm4.frem.wandisco.com:8020</remoteFs>
<origin>dc1<;/origin>
<size>4148166656</size>
<remaining>4014477312</remaining>
<bytesSec>3.3422336E7</bytesSec>
<percentRemaining>96.77714626516683</percentRemaining>
<state>in progress</state>
</fileTransfer>
<fileTransfer>
<startTime>1426019512082</startTime>
<elapsedTime>291678</elapsedTime>
<completeTime>1426019803760</completeTime>
<username>wandisco</username>
<familyRepresentativeId>
<nodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</nodeId>
<dsmId>93452fe3-c755-11e4-911e-5254001ba4b1</dsmId>
</familyRepresentativeId>
<file>/tmp/repl/isoABC</file>
<remoteFs>hdfs://vmhost5-vm4.frem.wandisco.com:8020</remoteFs>
<origin>dc1</origin>
<size>4148166656</size>
<remaining>0</remaining>
<bytesSec>1.4221733E7</bytesSec>
<percentRemaining>0.0</percentRemaining>
<state>complete</state>
</fileTransfer>
</fileTransfers>
12.15. Output key with data type
- Username
-
System user performing the transfer. (String)
- File name
-
Name of the file being transferred. (String)
- Remote FS
-
The file of the originating node. (URI)
- Origin
-
The file’s originating Zone. (String)
- Size
-
The cumulative size of data transferred. (Long)
- Appends
-
The number of appends that have been made to the file being transferred. (Long)
- AppendSize
-
The size of the latest append.
- Remaining
-
Remaining bytes still to be transferred for the latest append. (Long)
- Percent remaining
-
Percentage of the file still to be transferred. (Double)
- Bytes/Sec
-
The current rate of data transfer, i.e. Amount of file downloaded so far / elapsed download time. (Long)
- State
-
One of "in progress", "incomplete", "completed", "appending", "append complete", "deleted" or "failed". (TransferState)
In progress: means we are performing an initial pull of the file.
Appending: means data is currently being pulled and appended to the local file.
Append completed: means all available data has been pulled and appended to the local file, although more data could be requested later.
Note: files can be renamed, moved or deleted while we pull the data, in which case the state will become "incomplete".
When the remote file is closed and all of its data has been pulled, the state will then change to "Complete".
If a file is deleted while we are trying to pull the end state will be "deleted".
If the transfer fails the state will be "failed". - Start Time
-
The time when the transfer started. (Long)
- Elapsed Time
-
Time that has so far elapsed during the transfer. Once the transfer completes it is then a measure of the time between starting the transfer and completing. (Long)
- Complete Time
-
During the transfer this is an estimate for the complete time based on rate of through-put so far. Once the transfer completes this will be the actual time at completion. (Long)
- Delete Time
-
If the file is deleted then this is the time the file was deleted from the underlying filesystem. (Long)
12.15.1. Record retention
Records are not persisted and are cleared up on a restart. The log
records are truncated to stop an unbounded use of memory, and the
current implementation is as follows:
For each state machine, if there are more than 1,000 entries in its
list of transfers we remove the oldest transfers ,sorted by complete
time, which are in a terminal state ("completed", "failed" or "deleted")
until the size of the list is equal to 1,000. The check on the number of
records in the list is performed every hour.
12.15.2. Deleting memberships
It is currently not possible to delete memberships that are no longer required. Currently, removing memberships would potentially break the replication system.
12.15.3. Bandwidth management
For deployments that are run under an enterprise license, additional tools are available for monitoring and managing the amount of data transferred between zones.
Enterprise License only The Bandwidth Management tools are only enabled on clusters that are running on an Enterprise license. See the Deployment Checklist for details about License Types.
12.15.4. Overview
The bandwidth management tools provide two additional areas of functionality to support Enterprise deployments.
-
Limit the rate of outgoing traffic to each other zone.
-
Limit the rate of incoming traffic from each other zone.
Any applicable bandwidth limits are replicated across your nodes and applied on a per-zone basis.
Fusion Nodes - when Enterprise license is in use.
The Fusion Nodes screen will display current incoming traffic for the local zone. You will need to log in to the WD Fusion UI on a node within each Zone to see all incoming traffic levels.
12.15.5. Setting up bandwidth limits
Use this procedure to set up bandwidth limits between your zones
Click on the Set bandwidth limit button for each corresponding zone.

The Maximum bandwidth dialog will open. For each remote zone you can set a maximum Outgoing to and Incoming from values. Entered values are in Megabits per second. These are converted into Gigabytes per hour and displayed in brackets after each entry field.
Maximum bandwidth entry dialog.
- Outgoing to
-
The provided value will be used as the bandwidth limit for data coming from the target zone.
- Incoming from
-
As it is only possible to actually limit traffic at source, the Incoming from value is applied at the target zone as the Outgoing to limit for data being sent to the present zone.
When you have set your bandwidth values, click Update to apply these settings to your deployment.
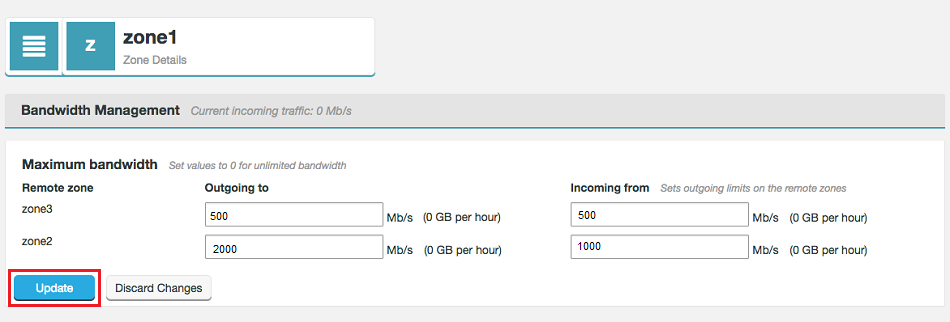
Maximum bandwidth entry dialog.
13. Settings
13.1. Change the UI Settings
You can change how you interact with WD Fusion UI through the browser:
13.1.1. Change UI ports
-
Log into the WD Fusion UI. Click on the Settings tab.
-
Click on UI Settings link on the side menu.
-
Enter a new HTTP Port or HTTP SSL.
 Figure 218. Settings - Fusion UI host and port
Figure 218. Settings - Fusion UI host and port -
Click Update. You may need to update the URL in your browser to account for the change you just made.
13.1.2. Use HTTPS Port
You can enable SSL encryption between the WD Fusion UI and your browser.
-
Before you enable use of HTTPS, ensure that all WD Fusion nodes/zones have been installed and configured (without using HTTPS for browser access). However, it is not necessary to have inducted the nodes or memberships.
|
Enable HTTPS on all nodes
If you don’t enable HTTPS on some nodes, some information, such as graph data will not be displayed.
|
-
Create a Key Store file using keytool, then save the file to a location on each node where the WD Fusion server can read it.
-
Log in to the WD Fusion UI. Click on the Settings tab.
-
Click on UI Settings link on the side menu.
-
Tick the Use HTTPS checkbox, then enter the following properties:
- HTTPS Port
-
The TCP port that will be used for the SSL traffic.
- Key Store
-
The security certificate repository.
- Key Store Password
-
Password that is set to protect the Key Store.
- Key Alias
-
An identifying name for the Key.
|
Important:
Check that you are using the correct Key Alias. Currently, if you use an alias that doesn’t exist in the keystore then the Fusion UI server will fail to start without warning. Improved error handling will be added in a later release.
|
- Trust Store
-
Is used to store certificates from trusted Certificate Authorities.
- Trust Store Password
-
The password that protects the Trust Store. Restart the node for the setting changes to take effect.
13.2. Enable SSL for WD Fusion
The following procedure is used for setting up SSL encryption for WD Fusion. The encryption will be applied between all components: Fusion servers, IHC servers and clients.
The procedure must be followed for each WD Fusion server in your replication system, in turn.
-
Log in to WD Fusion UI, click on the Settings tab.
-
Click the Enable SSL for WD Fusion checkbox.
-
Enter the details for the following properties:
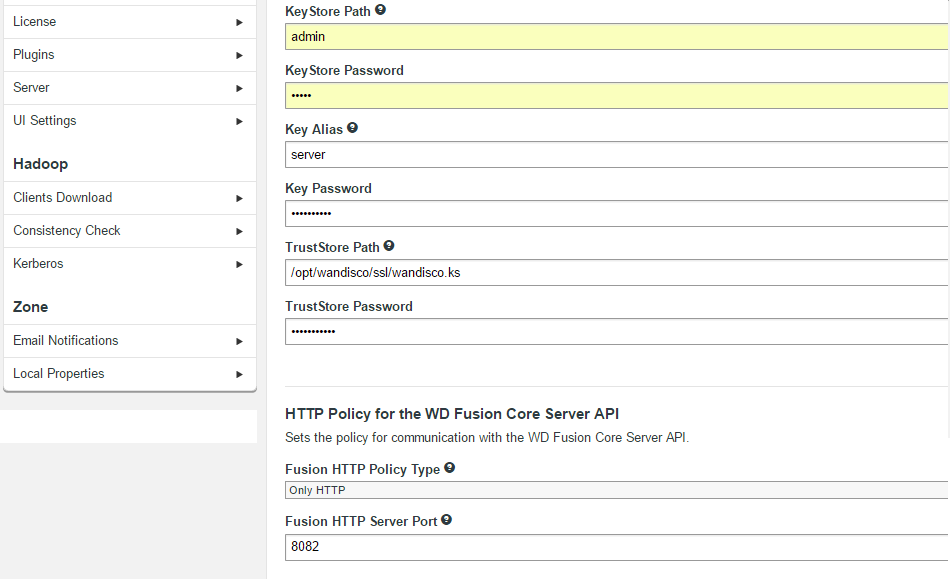
- KeyStore Path
-
Path to the keystore.
e.g. /opt/wandisco/ssl/keystore.ks - KeyStore Password
-
Encrypted password for the KeyStore.
e.g. * - Key Alias
-
The Alias of the private key.
e.g. WANdisco - Key Password
-
Private key encrypted password.
e.g. * - TrustStore Path
-
path to the TrustStore.
/opt/wandisco/ssl/keystore.ks - TrustStore Password
-
Encrypted password for the TrustStore.
e.g. *
-
Ensure that the HTTP Policy for the WD Fusion Core Server API is changed to match your SSL selection. Having enabled SSL, you need to change the HTTP Policy to Only HTTPS or Both HTTP and HTTPS.
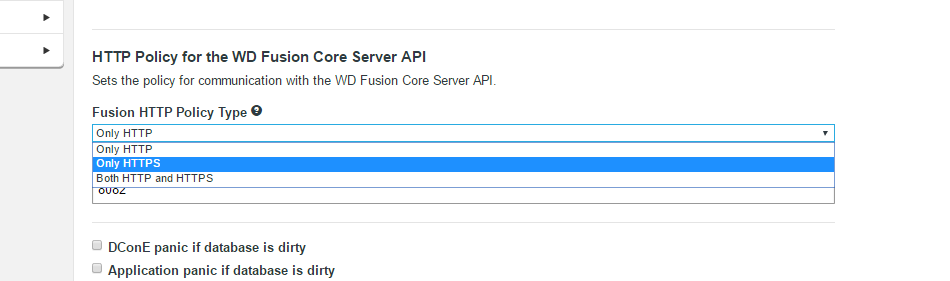
-
If applicable, edit the Fusion HTTP Server Port, default is 8082.
-
Click Update to save the settings. Repeat the steps for all WD Fusion servers.
13.3. Changing SSL Settings
If you disable SSL, you must also update the HTTP Policy for the WD Fusion Core Server API so that it is set to HTTP only.
Any changes that you make to the SSL settings must be applied, manually in the UI of every other WD Fusion node. Adding an update to the SSL settings will apply changes in the core-site file via the management endpoint (Cloudera Manager, Ambari, etc). You may be required to make manual changes to configuration files and restart some services.
|
Known Issue
Currently, the HTTP policy and
SSL settings both independently alter how
WD Fusion uses SSL, when they should be linked. You need to make sure
that your HTTP policy selection and the use of SSL (enabled in the next
section of the Installer) are in sync. If you choose either to the
policies that use HTTPS, then you must enable SSL. If you stick with
"Only HTTP" then you must ensure that you do not enable SSL. In a future
release these two settings will be linked so it will not be possible to
have contradictory settings.
|
13.3.1. Setting up SSL
What follows is a manual procedure for setting up SSL. In most cases it has been superseded by the above Fusion UI-driven method. If you make changed using the following method, you will need to restart the WD Fusion server in order for the changed to appear in on the Settings tab.
Create the keystores / truststores. Every Fusion Server and IHC server should have a KeyStore with a private key entry / certificate chain for encrypting and signing. Every Fusion Server and Fusion Client must also have a truststore for validating certificates in the path specific in “fusion.ssl.truststore”. The keystores and truststores can be the same file and may be shared amongst the processes.
Fusion Server configuration for SSL
To configure Server-Server or Server-Client SSL, enter the following
configurations to the application.properties file. e.g.
ssl.enabled=true ssl.key.alias=socketbox ssl.key.password=*********** ssl.keystore=/etc/ssl/key.store ssl.keystore.password=**************
Server-Server or Server-Client
Configure the keystore for each server:
| Key | Value | Default | File |
|---|---|---|---|
ssl.key.alias |
alias of private key/certificate chain in KeyStore. |
NA |
application.properties |
ssl.key.password |
encrypted password to key |
NA |
application.properties |
ssl.keystore |
path to Keystore |
NA |
application.properties |
ssl.keystore.password |
encrypted password to KeyStore. |
NA |
application.properties |
Server-to-Server or Server-to-IHC
Configure the truststore for each server:
| Key | Value | Default | File |
|---|---|---|---|
ssl.truststore |
Path to truststore |
Default |
application.properties |
ssl.truststore.password |
encrypted password to trust store |
Default |
application.properties |
Fusion client configuration Server-Client only
Configure the truststore for each client:
| Key | Value | Default | File |
|---|---|---|---|
fusion.ssl.truststore |
path to truststore |
NA |
core-site.xml |
fusion.ssl.truststore.password |
encrypted password for truststore |
NA |
core-site.xml |
fusion.ssl.truststore.type |
JKS, PCKS12 |
JKS |
core-site.xml |
IHC Server configuration (Server-IHC SSL only)
Configure the keystore for each IHC server:
| Key | Value | Default | File |
|---|---|---|---|
ihc.ssl.key.alias |
alias of private key/certificate chain in keystore |
NA |
.ihc |
ihc.ssl.key.password |
encrypted password to key |
NA |
.ihc |
ihc.ssl.keystore |
path to keystore |
NA |
.ihc |
ihc.ssl.keystore.password |
encrypted password to keystore |
NA |
.ihc |
ihc.ssl.keystore.type |
JKS, PCKS12 |
JKS |
.ihc |
Enable SSL:
The following configuration is used to turn on each type of SSL encryption:
| Type | Key | Value | Default | File |
|---|---|---|---|---|
Fusion Server - Fusion Server |
ssl.enabled |
true |
false |
application.properties |
Fusion Server - Fusion Client |
fusion.ssl.enabled |
true |
false |
core-site.xml |
Fusion Server - Fusion IHC Server |
fusion.ihc.ssl.enabled |
true |
false |
.ihc |
13.4. Enable SSL (HTTPS) for the WD Fusion Server
The manual steps (if you prefer not to use the UI settings server settings) for getting WD Fusion Server to support HTTPS connections:
You need to add the following property to application.properties.
| Type | Key | Value | Default | File |
|---|---|---|---|---|
Enable HTTPS support for Fusion core |
fusion.http.policy |
HTTP_ONLY, HTTPS_ONLY, BOTH_HTTP_HTTPS. If you enable HTTPS_ONLY, you need to make some matching changes to the WD Fusion UI server so that it is able to communicate with the core Fusion server. |
HTTP_ONLY |
application.properties |
13.4.1. Enable HTTPS for Fusion UI
Note that if you enable the Fusion Server to communicate over HTTPS-only, then you must also make the following changes so that the Fusion UI matches up:
target.ssl true target.port 443 (This is the port that Fusion Server uses for accepting REST requests, over HTTPS).
Advanced Options
|
Only apply these options if you fully understand what they do.
The following Advanced Options provide a number of low level
configuration settings that may be required for installation into
certain environments. The incorrect application of some of these
settings could cause serious problems, so for this reason we strongly
recommend that you discuss their use with WANdisco’s support team before
enabling them.
|
URI Selection
The default behaviour for WD Fusion is to fix all replication to the Hadoop Distributed File System / hdfs:/// URI. Setting the hdfs-scheme provides the widest support for Hadoop client applications, so some applications can’t support the available "fusion:///" URI or they can only run on HDFS. instead of the more lenient HCFS. Each option is explained below:
- Use HDFS URI with HDFS file system
-
The element appears in a radio button selector:
This option is available for deployments where the Hadoop applications support neither the WD Fusion URI nor the HCFS standards. WD Fusion operates entirely within HDFS.
This configuration will not allow paths with the fusion:/// uri to be used; only paths starting with hdfs:/// or no scheme that correspond to a mapped path will be replicated. The underlying file system will be an instance of the HDFS DistributedFileSystem, which will support applications that aren’t written to the HCFS specification.
- Use WD Fusion URI with HCFS file system
-
This is the default option that applies if you don’t enable Advanced
Options, and was the only option in WD Fusion prior to version 2.6.
When selected, you need to use fusion:// for all data that must be
replicated over an instance of the Hadoop Compatible File System. If
your deployment includes Hadoop applications that are either unable to
support the Fusion URI or are not written to the HCFS specification, this option will not work.
- Use Fusion URI with HDFS file system
-
This differs from the default in that while the WD Fusion URI is used to identify data to be replicated, the replication is performed using HDFS itself. This option should be used if you are deploying applications that can support the WD Fusion URI but not the Hadoop Compatible File System.
Benefits of HDFS.
The following advanced options provide a number of low level
configuration settings that may be required for installation into
certain environments. The incorrect application of some of these
settings could cause serious problems, so for this reason we strongly
recommend that you discuss their use with WANdisco’s support team
before enabling them.
- Use Fusion URI and HDFS URI with HDFS file system
-
This "mixed mode" supports all the replication schemes (
fusion://, hdfs:// and no scheme) and uses HDFS for the underlying file system, to support applications that aren’t written to the HCFS specification.
13.4.2. Setting up Node Location
WD Fusion is designed to fit into deployments that have far-flung data centers. The Node Location setting is used to identify where in the world the data center is situated, using standard global positioning system coordinates. These coordinates will be used by any connected WD Fusion nodes to correctly place the node’s location on the world map.
13.4.3. Set up email notifications
This section describes how to set up notification emails that will be triggered if one of the tracked system resources reaches a defined threshold.
|
Email notification is disabled by default.
You must complete the following steps before any messages will be sent.
|
Email Notification Settings are located in the Zone section of the settings.
Complete the following steps to enable email notification:
-
Enter your SMTP properties in the Server configuration tab.
-
Enter recipient addresses in the Recipients tab.
-
Tick the Enable check-box for each trigger-event for which you want an email notification sent out.
-
[Optionally] You can customize the messaging that will be included in the notification email message by adding your own text in the Templates tab.
13.5. Notification emails
The following triggers support email notification. See the Templates section for more information.
- Consistency Check Failing
-
Email sent if a consistency check fails.
- CPU Load Threshold Hit
-
Dashboard graph for CPU Load has reached. See Dashboard Graphs Settings.
- HDFS Usage Threshold Hit
-
Dashboard graph for Database partition disk usage has been reached. See Dashboard Graphs Settings.
- Java Heap Usage Threshold Hit
-
The system’s available Java Heap Threshold has been reached. See Dashboard Graphs Settings.
- License Expiring
-
The deployment’s WANdisco license is going to expire.
- Node Down
-
One of the Nodes in your deploy is down.
- Quorum Lost
-
One of the active replication groups is unable to continue replication due to the loss of one or more nodes.
13.5.1. Server config
The server config tab contains the settings for the SMTP email server that you will use for relaying your notification emails. You need to complete and check the provided details are correct first, before your notification emails can be enabled.
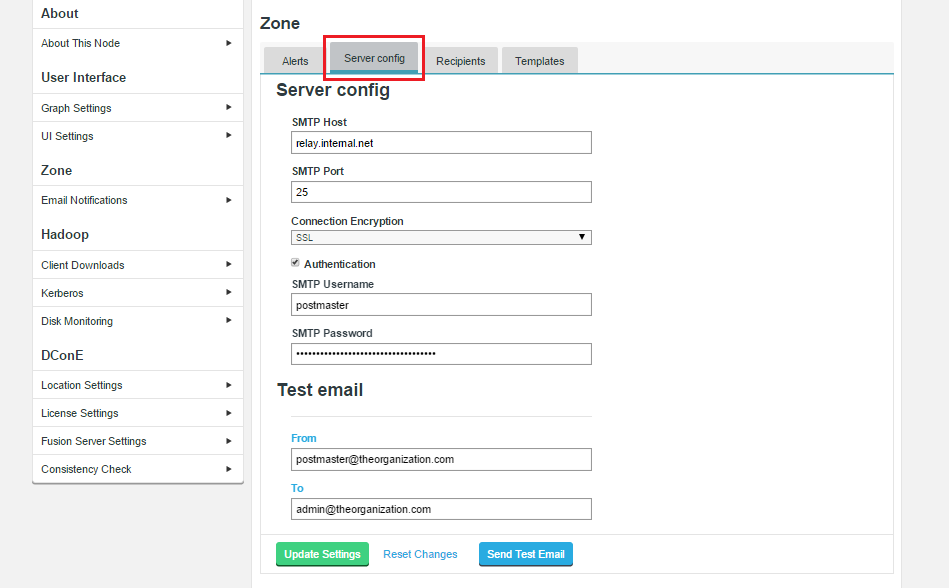
Email Notification Settings are located in the Zone section of the settings
- SMTP Host
-
The hostname or IP address for your email relay server.
- SMTP Port
-
The port used by your email relay service. SMTP default port is 25.
- Connection Encryption
-
Drop-down for choosing the type of encryption that the mail server uses, None, SSL or TLS are supported. If SSL or TLS are selected you should make sure that you adjust the SMTP port value, if required.
- Authentication
-
Checkbox for indicating that a username and password are required for connecting to the mail server. If you tick the checkbox additional entry fields will appear.
- SMTP Username
-
A username for connecting to the email server.
- SMTP Password
-
A password for connecting to the email server.
- From
-
Optional field for adding the sender email address that will be seen by to the recipient.
- To
-
Optional field for entering an email address that can be used for testing that the email setup will work.
- Update Settings
-
Button, click to store your email notification entries.
- Reset Changes
-
Reloads the saved settings, undoing any changes that you have made in the template that have not been saved.
- Send Test Email
-
Reloads the saved settings, undoing any changes that you have made in the template that have not been saved.
13.5.2. Recipients
The recipients tab is used to store one or more email addresses that can be used when sending out notification emails. You can enter any number of addresses, although you will still need to associate an entered address with a specific notification before it will be used. See Adding recipients
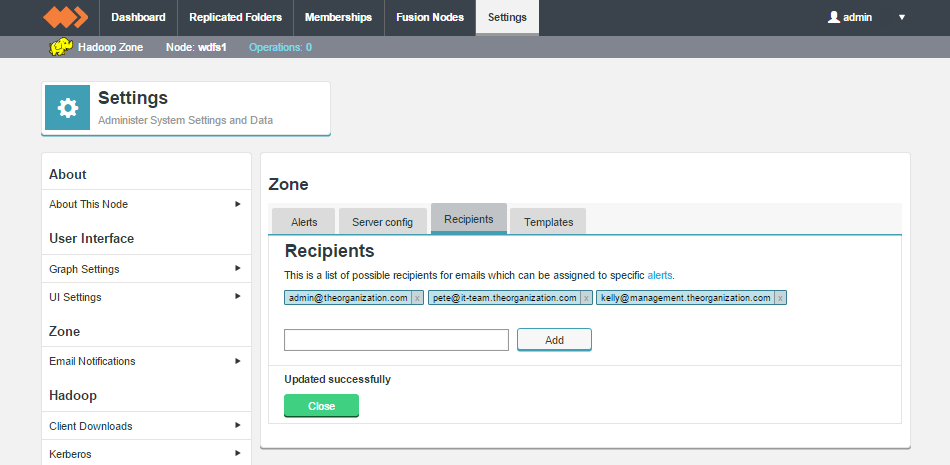
13.5.3. Adding recipients
-
Enter a valid email address for a recipient who should receive a notification email from WD Fusion.
-
Click the Add button.
You can repeat the procedure as many times as you like, you can send each different notification to a different recipient (by associating that recipient’s address with the particular trigger), or you can send a single notification email to multiple recipients (by associating multiple addresses with the notification email.
13.5.4. Enable Notification Emails
Once you have working server settings valid recipient email addresses you can start to enable notification emails from the Alerts tab.
-
Go to the Alerts tab and select a notification trigger for which you would like to send emails. For example Consistency Check Failing. Tick the Enabled checkbox.
If a trigger is not enabled, no email notification will ever be sent. Likewise, an enabled trigger will not send out notification emails unless recipients are added.  Figure 224. Email Notification Enabled
Figure 224. Email Notification Enabled -
From the Add More Recipients window, click on one or more of the recipients that you entered into the Recipients tab. Once you have finished selecting recipients, click Add.
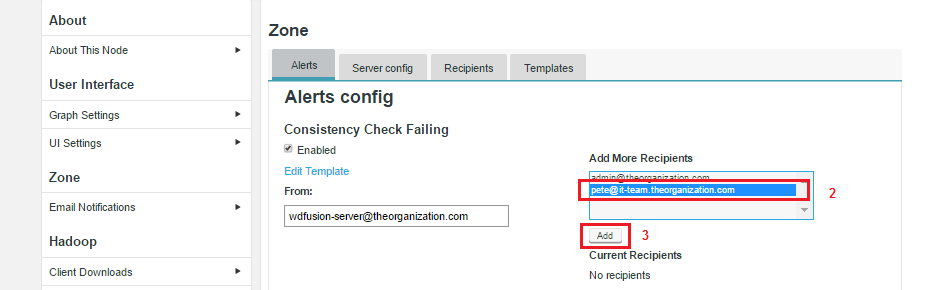 Figure 225. Email Notification Selected
Figure 225. Email Notification Selected -
The email notification is now set up. You can choose to change/add additional recipients, review or customize the messaging by clicking on the Edit Template link.
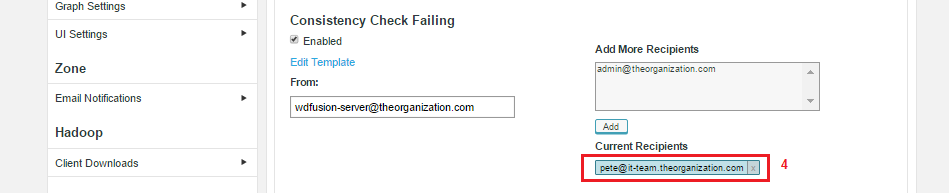 Figure 226. Email Notification - Add
Figure 226. Email Notification - Add
13.5.5. Templates
The Templates tab gives you access to the email default text, allowing you to review and customize with additional messaging.
Email templates
- Consistency Check Failing
-
This is the trigger system event for which the notification email will be sent.
- Subject
-
The email’s subject line. A default value is set for each of the triggers, however, you can reword these by changing the text in the template.
- Custom Message
-
This entry box lets you add your own messaging to the notification. This could be anything that might be useful to an on-duty administrator such as links to related documentation or contact details for the next level of support, etc.
- Message Body
-
The message body contains the fixed payload of the notification email; you can’t edit this element and it may contain specific error messaging taken from logs.
13.5.6. Example Notification Email
This is what an email notification looks like:
From: cluster-admin@organization.com> Date: Mon, Jan 4, 2016 at 3:49 PM Subject: WANdisco Fusion UI - Consistency Check Failing To: admin@organization.com Here is a custom message. - Custom messaging entered in the Template Consistency Check Failing triggered a watch event, any relevant error message will appear below. - Default Message The following directory failed consistency check: /repl1 - Specific error message ==================== NODE DETAILS ===================== Host Name : xwstest-01.your.organization.com IP address : 10.0.0.146 IP port : 6444 ------------------------------------------------------- Node Id : f5255a0b-bcfc-40c0-b2a7-64546f571f2a Node Name : wdfs1 Node status : LOCAL Node's zone : zone1 Node location : location1 Node latitude : 11.0 Node longitude: 119.0 ------------------------------------------------------- Memory usage : 0.0% Disk usage : 0.0% Last update : 2016.Jan.04 at 15:49:28 GMT Time Now : 2016.Jan.04 at 15:49:48 GMT ======================================================= - Standard footer
13.6. Setting up Kerberos
If the Hadoop deployment is secured using Kerberos you need to enable Kerberos in the WD Fusion UI. Use the following procedure:
Look to the security procedures of your particular form of Hadoop:
|
Before installing on Cloudera
Ensure that the Cloudera Manager database of Kerberos principals is up-to-date.
|
Running with unified or per-service
principle:
Unified
Some Hadoop platforms are Kerberized under a single hdfs user, this is
common in Cloudera deployments. For simplicity, this is what we
recommend.
-
Generate a keytab for each of your WD Fusion nodes using the hdfs service, for clarification the steps below present a manual setup:
ktadd -k fusion.keytab -norandkey hdfs/${hostname}@${krb_realm}Per-service
-
If your deployment uses separate principals for each HDFS service then you will need to set up a principal for WD Fusion.
-
On the KDC, using kadmin.local, create new principals for WD Fusion user and generate keytab file, e.g.:
> addprinc -randkey hdfs/${hostname}@${krb_realm} > ktadd -k fusion.keytab -norandkey hdfs/${hostname}@${krb_realm}
Copy the generated keytab to a suitable filesystem location, e.g.
/etc/wandisco/security/ on the WD Fusion server that will be
accessible to your controlling system user, "hdfs" by default.
*Note:* We don’t recommend storing the keytab in Hadoop’s own Kerberos
/etc/hadoop/conf, given that this is overwritten by the cluster
manager.
13.6.1. Setting up handshake tokens
By default, handshake tokens are created in the user’s working
directories, e.g. /user/jdoe. It is recommended that you create them
elsewhere, using the following procedure:
-
Open the
core-site.xmlfile and add the following property:<property> <name>fusion.handshakeToken.dir</name> <value>/some/token/dir</value> </property>fusion.handshakeToken.dir
This is the location where you want handshake tokens to be created for the cluster. E.G., If for DC1 you configure the "handshakeToken.dir" to be "/repl1/tokens/", then handshake tokens will be written in "/repl1/tokens/.fusion/.token_$USERNAME_$UUID" where
$USERNAMEis the username of the user connecting and$UUIDwill be a random UUID.
Important requirement: All WD Fusion system users must have read and write permissions for the location.
Important: Known issue running Teragen and Terasort
There are known problems running Teragen and Terasort with FusionHdfs
or FusionHcfs configurations. Some required directories are currently
missing and will cause Terasort to hang. You can work around the problem
by creating the following directories, then making sure that Yarn and
MapR users are added and that they have access to the directories. E.g.,
sudo -u hdfs hadoop fs -mkdir /user/yarn sudo -u hdfs hadoop fs -chown yarn /user/yarn sudo -u hdfs hadoop fs -mkdir /user/mapred sudo -u hdfs hadoop fs -chown mapred /user/mapred
13.6.2. Set up Kerberos single KDC with Ambari
The following procedures illustrate how to installing Kerberos, running with a single Key Distribution Center, under Ambari.
When to use kadmin.local and kadmin?
When performing the Kerberos commands in this procedure you can use
kadmin.local or kadmin depending on your access and account:
-
IF you can log onto the KDC host directly, and have root access or a Kerberos admin account: use the
kadmin.localcommand. -
When accessing the KDC from a remove host, use the
kadminfrom any host, run one of the following:$ sudo kadmin.local
or
$ kadmin
Before you start, download and install the Java Cryptographic Extension (JCE) Unlimited Strength Jurisdiction Policy Files 7. See Setup procedure.
13.6.3. WD Fusion installation step
During the WD Fusion Installation’s Kerberos step, set the configuration for an existing Kerberos setup.
13.6.4. Set up Kerberos single KDC on CDH cluster
The following procedures illustrate how to installing Kerberos, running with a single Key Distribution Center, under CDH.
13.6.5. Set up a KDC and Default Domain
When to use kadmin.local and kadmin?
When performing the Kerberos commands in this procedure you can use
kadmin.local or kadmin depending on your access and account:
-
IF you can log onto the KDC host directly, and have root access or a Kerberos admin account: use the
kadmin.localcommand. -
When accessing the KDC from a remove host, use the
kadminfrom any host, run one of the following:$ sudo kadmin.local
or
$ kadmin
13.6.6. Setup Procedure
-
Before you start, download and install the Java Cryptographic Extension (JCE) Unlimited Strength Jurisdiction Policy Files 7.
unzip UnlimitedJCEPolicyJDK7.zip -d /usr/jdk64/jdk1.7.0_67/jre/lib/security/
-
Install the Kerberos server:
yum install -y krb5-server krb5-libs krb5-auth-dialog krb5-workstation
-
Edit
/etc/krb5.confand replace "EXAMPLE.COM" with your realm. E.g.sed -i "s/EXAMPLE.COM/g" /etc/krb5.conf /var/kerberos/krb5kdc/kdc.conf /var/kerberos/krb5kdc/kadm5.acl
[logging] default = FILE:/var/log/krb5libs.log kdc = FILE:/var/log/krb5kdc.log admin_server = FILE:/var/log/kadmind.log [libdefaults] default_realm = DOMAIN.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true [realms] DOMAIN.COM = { kdc = host15-vm0.cfe.domain.com admin_server = host15-vm0.cfe.domain.com } [domain_realm] .wandisco.com = DOMAIN.COM wandisco.com = DOMAIN.COM -
Edit
/var/kerberos/krb5kdc/kdc.conf:[kdcdefaults] kdc_ports = 88 kdc_tcp_ports = 88 [realms] DOMAIN.COM = { #master_key_type = aes256-cts acl_file = /var/kerberos/krb5kdc/kadm5.acl dict_file = /usr/share/dict/words admin_keytab = /var/kerberos/krb5kdc/kadm5.keytab max_life = 24h 0m 0s max_renewable_life = 7d supported_enctypes = aes256-cts:normal aes128-cts:normal des3-hmac-sha1:normal arcfour-hmac:normal des-hmac-sha1:normal des-cbc-md5:normal des-cbc-crc:normal } -
Edit the
/var/kerberos/krb5kdc/kadm5.acland replace EXAMPLE.COM with your principle. -
To create a database, run
/usr/sbin/kdb5_util create -s
-
Start Kerberos service:
/sbin/service krb5kdc start /sbin/service kadmin start
-
Prepare your kerberos clients. Run
yum install -y krb5-libs krb5-workstation
Repeat this on all other machines in the cluster to make them kerberos workstations connecting to the KDC. E.g.
for i in {1..4}; do ssh root@vmhost17-nfs$i.cfe.domain.com 'yum install -y krb5-libs krb5-workstation';done -
Copy the /etc/krb5.conf file from the kerberos server node to all kerberos client nodes
for i in {1..5}; do scp /etc/krb5.conf root@vmhost17-vm$i.cfe.domain.com:/etc/;done -
Create a user on all nodes: useradd -u 1050 testuser
for i in {0..4}; do ssh root@vmhost17-nfs$i.cfe.domain.com 'useradd -u 1050 testuser';done -
Create principal and password for user (testuser):
[root@vmhost17-vm0 ~]# kadmin.local Authenticating as principal root/admin@DOMAIN.COM with password. kadmin.local: addprinc testuser/admin WARNING: no policy specified for testuser/admin@DOMAIN.COM; defaulting to no policy Enter password for principal "testuser/admin@DOMAIN.COM": Re-enter password for principal "testuser/admin@DOMAIN.COM": Principal "testuser/admin@DOMAIN.COM" created. kadmin.local: exit [root@vmhost01-vm1 ~]# su - testuser [testuser@vmhost01-vm1 ~]$ kinit Password for testuser/admin@DOMAIN.COM: [testuser@vmhost01-vm1 ~]$ klist Ticket cache: FILE:/tmp/krb5cc_519 Default principal: testuser/admin@DOMAIN.COM Valid starting Expires Service principal 04/29/15 18:17:15 04/30/15 18:17:15 krbtgt/DOMAIN.COM@DOMAIN.COM renew until 04/29/15 18:17:15
-
Then add:
Kadmin.local: addprinc hdfs@DOMAIN.COM
Create hdfs.keytab and move hdfs.keytab file in the /etc/cloudera-scm-server/ directory on the host where you are running the Cloudera Manager Server. Make sure that the hdfs.keytab file has
readable permissions for all users:
kadmin: xst -k hdfs.keytab hdfs@DOMAIN.COM mv hdfs.keytab /etc/cloudera-scm-server/ chmod +r /etc/cloudera-scm-server/ hdfs.keytab
13.6.7. Create a Kerberos Principal and Keytab File for the Cloudera Manager Server
The following sequence is an example procedure for creating the Cloudera Manager Server principal and keytab file for MIT Kerberos.
-
In the kadmin.local or kadmin shell, type in the following command to create the Cloudera Manager Service principal:
kadmin: addprinc -randkey cloudera-scm/admin@WANDISCO.COM
-
Create the Cloudera Manager Server
cmf.keytabfile:kadmin: xst -k cmf.keytab cloudera-scm/admin@DOMAIN.COM
Important:
The Cloudera Manager Server keytab file must be namedcmf.keytabbecause that name is hard-coded in Cloudera Manager.
13.6.8. Deploying the Cloudera Manager Server Keytab
After obtaining or creating the Cloudera Manager Server principal and keytab, follow these instructions to deploy them:
Move the cmf.keytab file to the /etc/cloudera-scm-server/. This is
the directory on the host where you are running the Cloudera Manager
Server.
$ mv cmf.keytab /etc/cloudera-scm-server/
Ensure that the cmf.keytab file is only readable by the Cloudera
Manager Server user account cloudera-scm.
sudo chown cloudera-scm:cloudera-scm /etc/cloudera-scm-server/cmf.keytab sudo chmod 600 /etc/cloudera-scm-server/cmf.keytab
Add the Cloudera Manager Server principal
(cloudera-scm/admin@DOMAIN.COM) to a text file named cmf.principal and
store the cmf.principal file in the /etc/cloudera-scm-server/
directory on the host where you are running the Cloudera Manager Server.
Make sure that the cmf.principal file is only readable by the Cloudera Manager Server user account cloudera-scm.
sudo chown cloudera-scm:cloudera-scm /etc/cloudera-scm-server/cmf.principal sudo chmod 600 /etc/cloudera-scm-server/cmf.principal
Note: For Single KDC copy cmf.keytab and cmf.principal to another CM
node:
scp /etc/cloudera-scm-server/cmf* vmhost17-vm0.bdfrem.wandisco.com:/etc/cloudera-scm-server/
13.7. Configure the Kerberos Default Realm in the Cloudera Manager Admin Console
-
In the Cloudera Manager Admin Console, select Administration > Settings.
-
Click the Security category, and enter the Kerberos realm for the cluster in the Kerberos Security Realm field that you configured in the
krb5.conffile. -
Click Save Changes.
13.8. Adding Gateway roles to all YARN hosts.
-
From the Services tab, select your YARN service.
-
Click the
Instancestab. -
Click
Add Rolesand chooseGateway role. -
Select
all hostsand clickInstall.
13.9. Enable Hadoop Security
You can do this by hand, see CM Enable Security.
13.10. Cloudera Manager Kerberos Wizard
After configuring kerberos, you now have a working Kerberos server and can secure the Hadoop cluster. The wizard will do most of the heavy lifting; you just have to fill in a few values.
-
To start, log into Cloudera Manager by going to
http://your_hostname:7180in your browser. The user ID and Password are the same as those used for accessing your Management Endpoint (Ambari or Cloudera Manager, etc.) or if you’re running without an manager, such as with a Cloud deployment, then they will be set in a properties file. -
There are lots of productivity tools here for managing the cluster but ignore them for now and head straight for the
Administration > Kerberoswizard. -
Click on the "Enable Kerberos" button.
-
Check each KRB5 Configuration item and select Continue.
 Figure 228. Kerberos config
Figure 228. Kerberos config -
The Kerberos Wizard needs to know the details of what the script configured. Fill in the entries as follows:
-
KDC Server Host KDC_hostname
-
Kerberos Security Realm: DOMAIN.COM
-
Kerberos Encryption Types: aes256-cts-hmac-sha1-96
Click Continue.
-
-
You want Cloudera Manager to manage the
krb5.conffiles in your cluster so, please check "Yes" and then select "Continue." -
Enter the credentials for the account that has permissions to create other listeners.
User: testuser@WANDISCO.COM Password: password for testuser@WANDISCO.COM
-
The next screen provides good news. It lets you know that the wizard was able to successfully authenticate.
-
On this step setup wizard will create Kerberos principals for each service in the cluster.
-
You’re ready to let the Kerberos Wizard do its work. You should select I’m ready to restart the cluster now and then click Continue.
-
Successfully enabled Kerberos. You now running a Hadoop cluster secured with Kerberos.
13.11. WD Fusion installation step
You should enter paths to /etc/krb5.conf file and to hdfs.keytab
file and then select principal hdfs.
13.11.1. Kerberos and HDP’s Transparent Data Encryption
There are some extra steps required to overcome a class loading error that occurs when WD Fusion is used with at-rest encrypted folders. Specifically, cluster config changes described as follows:
<property> <name>hadoop.kms.proxyuser.fusion.users</name> <value>*</value> </property> <property> <name>hadoop.kms.proxyuser.fusion.groups</name> <value>*</value> </property> <property> <name>hadoop.kms.proxyuser.fusion.hosts</name> <value>*</value> </property>
13.12. Setting up SSL encryption for DConE traffic
WD Fusion supports the use of Secure Socket Layer encryption (SSL) for securing its replication traffic. To enable this encryption you need to generate a keypair that must be put into place on each of your WD Fusion nodes. You then need to add some variables to the application.properties file.
-
Open a terminal and navigate to
<INSTALL_DIR>/etc/wandisco/config. -
Within
/configmake a new directory called ssl.mkdir ssl
-
Navigate into the new directory.
cd ssl
-
Copy your private key into the directory. If you don’t already have keys set up you can use JAVA’s keygen utility, using the command:
keytool -genkey -keyalg RSA -keystore wandisco.ks -alias server -validity 3650 -storepass <YOUR PASSWORD>
Read more about the Java keystore generation tool in the KB article - Using Java Keytool to manage keystores
Ensure that the system account that runs the WD Fusion server process has sufficient privileges to read the keystore files.
Java keytool options
Variable Name Description -genkey
Switch for generating a key pair (a public key and associated private key). Wraps the public key into an X.509 v1 self-signed certificate, which is stored as a single-element certificate chain. This certificate chain and the private key are stored in a new keystore entry identified by alias.
-keyalg RSA
The key algorithm, in this case RSA is specified.
wandisco.ks
This is file name for your private key file that will be stored in the current directory.
- alias server
Assigns an alias "server" to the key pair. Aliases are case-insensitive.
-validity 3650
Validates the keypair for 3650 days (10 years). The default would be 3 months.
- storepass <YOUR PASSWORD>
This provides the keystore with a password.
If no password is specified on the command, you’ll be prompted for it. Your entry will not be masked so you (and anyone else looking at your screen) will be able to see what you type.
Most commands that interrogate or change the keystore will need to use the store password. Some commands may need to use the private key password. Passwords can be specified on the command line (using the
-storepassand-keypassoptions).
However, a password should not be specified on a command line or in a script unless it is for testing purposes, or you are on a secure system.The utility will prompt you for the following information
What is your first and last name? [Unknown]: What is the name of your organizational unit? [Unknown]: What is the name of your organization? [Unknown]: What is the name of your City or Locality? [Unknown]: What is the name of your State or Province? [Unknown]: What is the two-letter country code for this unit? [Unknown]: Is CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown correct? [no]: yes Enter key password for <mykey> (RETURN if same as keystore password):
-
With the keystore now in place, you’ll now need to add variables to the application.properties
13.13. SSL DConE Encryption Variables for application.properties
| Variable Name | Example | Description |
|---|---|---|
ssl.enabled |
true |
Requires a "true" or "false" value. Clearly when the value is set to false, none of the other variables will be used. |
ssl.debug |
true |
Requires a "true" or "false" value. When set to true debugging mode is enabled. |
ssl.keystore |
./properties/wandisco.ks |
The path to the SSL private Keystore file that is stored in the node. By default this is called "wandisco.ks". |
ssl.key.alias |
wandisco |
The assigned alias for the key pair. Aliases are case-insensitive. |
ssl.keystore.password |
<a password> |
The SSL Key password. This is described in more detail in Setting a password for SSL encryption. |
ssl.truststore |
./properties/wandisco.ks |
The path to the SSL private truststore file that is stored in the node. By default this is called "wandisco.ks" because, by default the keystore and truststore are one and the same file, although it doesn’t have to be. |
ssl.truststore.password |
"bP0L7SY7f/4GWSdLLZ3e+ |
The truststore password. The password should be encrypted. |
Changes in any of these values require a restart of the DConE service. Any invalid value will restart the replicator and no DConE traffic will flow.
13.13.1. Setting the server key
In the keystore, the server certificate is associate with a key. By
default, we look for a key named server to validate the certificate.
If you use a key for the server with a different name, enter this in the
SSL settings.
13.13.2. SSL Troubleshooting
A complete debug of the SSL logging will be required to diagnose the problems. To capture the debugging, ensure that the variable debugSsl is set to "true".
To enable the logging of SSL implemented layer, turn the logging to FINEST for 'com.wandisco.platform.net' package.
13.14. Enable SSL for Hadoop Services
This section shows you how to enable SSL encryption for Hadoop’s native services such as HDFS, Yarn or MapReduce.
-
On ALL nodes create key directories:
/etc/security/serverKeys and /etc/security/clientKeys
-
On all nodes, create keystore files:
cd /etc/security/serverKeys keytool -genkeypair -alias $HOSTNAME -keyalg RSA -keysize 2048 -dname CN=$HOSTNAME,OU=Dev,O=BigData,L=SanRamon,ST=ca,C=us -keypass $PASSWORD -keystore $HOSTNAME.ks -storepass $PASSWORD
There’s further explanation of what these options do, see the key Java keytool options
-
On all nodes export the certificate public key to a certificate file:
cd /etc/security/serverKeys keytool -exportcert -alias $HOSTNAME -keystore $HOSTNAME.ks -rfc -file $HOSTNAME.crt -storepass $PASSWORD
-
On all nodes, import the certificate into truststore file:
cd /etc/security/serverKeys keytool -importcert -noprompt -alias $HOSTNAME -file $HOSTNAME.crt -keystore $HOSTNAME.trust -storepass $PASSWORD
-
Create a single truststore file containing the public key from all certificates (this will be for clients) start on node1:
cd /etc/security/serverKeys
Copy trust store file from current node to next one and redo all steps above.
-
From last node copy trust store, which has all certificates to all servers under
/etc/security/clientKeys/all.jks -
On all nodes, copy keystore to “service”.ks (e.g. hdfs.ks)
13.15. Keystores are used in two ways:
-
The keystore contains private keys and certificates used by SSL servers to authenticate themselves to SSL clients. By convention, such files are referred to as keystores.
-
When used as a truststore, the file contains certificates of trusted SSL servers, or of Certificate Authorities trusted to identify servers. There are no private keys in the truststore.
Most commonly, cert-based authentication is only done in one direction server→client. When a client also authenticates with a certificate this is called mutual authentication.
While all SSL clients must have access to a truststore, it is not always necessary to create and deploy truststores across a cluster. The standard JDK distribution includes a default truststore which is pre-provisioned with the root certificates of a number of well-known Certificate Authorities. If you do not provide a custom truststore, the Hadoop daemons load this default truststore. Therefore, if you are using certificates issued by a CA in the default truststore, you do not need to provide custom truststores. However, you must consider the following before you decide to use the default truststore:
If you choose to use the default truststore, it is your responsibility to maintain it. You may need to remove the certificates of CAs you do not deem trustworthy, or add or update the certificates of CAs you trust. Use the keytool utility to perform these actions.
13.15.1. Security Considerations
Keystores contain private keys. truststores do not. Therefore, security requirements for keystores are more stringent:
-
Hadoop SSL requires that truststores and the truststore password be stored, in plaintext, in a configuration file that- is readable by all.
-
Keystore and key passwords are stored, in plaintext, in a file that is readable only by members of the appropriate group.
These considerations should guide your decisions about which keys and certificates you will store in the keystores and truststores that you will deploy across your cluster.
Keystores should contain a minimal set of keys and certificates. Ideally you should create a unique keystore for each host, which would contain only the keys and certificates needed by the Hadoop SSL services running on the host. Usually the keystore would contain a single key/certificate entry. However, because truststores do not contain sensitive information you can safely create a single truststore for an entire cluster. On a production cluster, such a truststore would often contain a single CA certificate (or certificate chain), since you would typically choose to have all certificates issued by a single CA.
Important: Do not use the same password for truststores and keystores/keys. Since truststore passwords are stored in the clear in files readable by all, doing so would compromise the security of the private keys in the keystore.
13.15.2. SSL roles for Hadoop Services
| Service | SSL Role |
|---|---|
HDFS |
server and client |
MapReduce |
server and client |
YARN |
server and client |
HBase |
server |
Oozie |
server |
Hue |
client |
SSL servers load the keystores when starting up. Clients then take a copy of the truststore and uses it to validate the server’s certificate.
13.17. Before you begin
Ensure keystores/certificates are accessible on all hosts running HDFS, MapReduce or YARN. As these services also run as clients they also need access to the truststore. (As mentioned, it’s okay to put the truststores on all nodes as you can’t always determine which hosts will be running the relevant services.)
keystores must be owned by the hadoop group and have permissions 0440 (readable by owner and group). truststores must have permission 0444 (readable by all).
You’ll need to specify the absolute paths to keystore and truststore files - these paths need to be valid for all hosts - this translates into a requirement for all keystore file names for a given service to be the same on all hosts.
Multiple daemons running on a host can share a certificate. For example, in case there is a DataNode and an Oozie server running on the same host, they can use the same certificate.
13.18. Configuring SSL for HDFS
-
In Ambari, navigate to the HDFS service edit the configuration.
-
Type SSL into the search field to show the SSL properties.
-
Make edits to the following properties:
Property Description SSL Server Keystore File Location
Path to the keystore file containing the server certificate and private key.
SSL Server Keystore File Password
Password for the server keystore file.
SSL Server Keystore Key Password
Password that protects the private key contained in the server keystore.
-
If you don’t plan to use the default truststore, configure SSL client truststore properties:
Property Description Cluster-Wide Default SSL Client Truststore Location
Path to the client truststore file. This truststore contains certificates of trusted servers, or of Certificate Authorities trusted to identify servers.
Cluster-Wide Default SSL Client Truststore Password
Password for the client truststore file.
-
We recommend that you also enable web UI authentication for the HDFS service, providing that you have already secured the HDFS service. Enter web consoles in the search field to bring up Enable Authentication for HTTP Web-Consoles property. Tick the check box to enable web UI authentication.
Property Description Enable Authentication for HTTP Web-Consoles
Enables authentication for hadoop HTTP web-consoles for all roles of this service.
-
Now the necessary edits are complete, click Save Changes.
-
Follow the next section for setting up SSL for YARN/MapReduce.
13.19. Configuring SSL for YARN / MapReduce
Follow these steps to configure SSL for YARN or MapReduce services.
Navigate to the YARN or MapReduce service and click Configuration.
In the search field, type SSL to show the SSL properties.
Edit the following properties according to your cluster configuration:
| Property | Description |
|---|---|
SSL Server Keystore File Location |
Path to the keystore file containing the server certificate and private key. |
Enable Authentication for HTTP Web-Consoles |
Password for the server keystore file. |
SSL Server Keystore Key Password |
Password for the client truststore file. |
We recommend that you also enable web UI authentication for the HDFS service, providing that you have already secured the HDFS service. Enter web consoles in the search field to bring up Enable Authentication for HTTP Web-Consoles property. Tick the check box to enable web UI authentication.
| Property | Description |
|---|---|
Enable Authentication for HTTP Web-Consoles |
Enables authentication for hadoop HTTP web-consoles for all roles of this service. |
Click Save Changes.
Navigate to the HDFS service and in the search field, type Hadoop SSL Enabled. Click the value for the Hadoop SSL Enabled property and select the checkbox to enable SSL communication for HDFS, MapReduce, and YARN.
| Property | Description |
|---|---|
Hadoop SSL Enabled |
Enable SSL encryption for HDFS, MapReduce, and YARN web UIs, as well as encrypted shuffle for MapReduce and YARN. |
Restart all affected services (HDFS, MapReduce and/or YARN), as well as their dependent services.
14. WD Fusion Plugin: Hive Metastore
14.1. Introduction
The Hive Metastore plugin enables WD Fusion to replicate Hive’s metastore, allowing WD Fusion to maintain a replicated instance of Hive’s metadata and, in future, support Hive deployments that are distributed between data centers.

14.1.1. Release Notes
Check out the Hive Metastore Plugin Release Notes for the latest information. See Hive Metastore Plugin Release Notes.
14.1.2. Pre-requisites
Along with the default requirements that you can find on the WD Fusion Deployment Checklist, you also need to ensure that the Hive service is already running on your server. Installation will fail if the WD Fusion Plugin can’t detect that Hive is already running.
|
Limitation: Hive must be running at all zones
All zones within a membership must be running Hive in order to support replication.
We’re aware that this currently prevents the popular use case for replicating between on-premises clusters and s3/cloud storage, where Hive is not running.
We intend to remove the limitation in a future release.
|
14.1.3. Known Issues
-
Known Issue: Hive Metastore does not start with the same classpath as original metastore
-
Known Issue: Bug in HDP 2.5, beeline connections hang on quit due to token store issues
-
Known Issue: WD Fusion Hive Metastore plugin not installed locally to Hive Metastore
-
Known Issue: Cloudera/WD Hive Metastore deployments: manual copy of hive-site.xml required
-
Known Issue: Failed to install metastore service during fusion installation in IOP4.1 and IOP4.2
-
Known Issue: Running Apache Sentry with WANdisco Hive Metastore
-
Known Issue: Workaround for when Hive location URI doesn’t match defaultFS
|
Hive Metastore does not start with the same classpath as original metastore
During installation, the classpath is being amended by Hive so that the classpath is not the same as original metastore.
|
To ensure wd-hive has the same classpath as the original metastore to do following:
-
Copy the section below (taken from
/usr/hdp/current/hive-metastore/bin/hive)HCATALOG_JAR_PATH=/usr/hdp/2.5.3.0-37/hive-hcatalog/share/hcatalog/hive-hcatalog-core-1.2.1000.2.5.3.0-37.jar:/usr/hdp/2.5.3.0-37/hive-hcatalog/share/hcatalog/hive-hcatalog-server-extensions-1.2.1000.2.5.3.0-37.jar:/usr/hdp/2.5.3.0-37/hive-hcatalog/share/webhcat/java-client/hive-webhcat-java-client-1.2.1000.2.5.3.0-37.jar if [ -z "${HADOOP_CLASSPATH}" ]; then export HADOOP_CLASSPATH=${HCATALOG_JAR_PATH} else export HADOOP_CLASSPATH=${HADOOP_CLASSPATH}:${HCATALOG_JAR_PATH} fi -
Paste it into
/etc/wandisco/hive/wd-hive-metastore-env.sh. -
Once this has been done do a restart.
|
MySQL Memory Leak
While testing, a potential memory leak was found when running Hive Metastore Plugin using MYSQL as the backend database. The out of memory errors appear to be caused by MYSQL’s BoneCP databased connection pooling.
|
Workaround:
To avoid possible out of memory errors, insert the following line into hive-site.xml
datanucleus.connectionPoolingType=dbcp
After adding the line, restart the fusion-server service.
|
Known Issue: ON HDP2.5, beeline connections hang on quit due to token store issues |
This problem has been fixed in HDP 2.5.3
The issue in question doesn’t actually stop the metastore from starting - however, the null-pointer/IOException that happens because of the missing token does take the current instance of the metastore down, but it does so when shutdown is called (and subsequently cancel_token).
This prevents beeline connections from closing properly outside of the service level timeout.
This causes the service to appear red as the standard heartbeat for the vanilla metastore is a beeline connection.
Using beeline connections will not close immediately in the usual manner (i.e. through the !quit command), they will only close once the !quit command has timed out. (users may also choose to ctrl-c out of the beeline shell if they choose)
To lessen the pain of this issue, customers may choose to modify the beeline timeout to be more snappy (hive.server2.idle.operation.timeout appears to be the most suitable timeout for this)
In order to get the service "healthy" again, the customer can also modify the heartbeat timeout to be greater than the beeline timeout (check.command.timeout is the property for this).
|
Known Issue: bigsql-sync.jar must be included in the wd-hive-metastore classpath or the server will not start properly. There are 2 options available for meeting this requirement: |
-
If the jar is available on the wd-hive-metastore node, create a symlink via:
cd /opt/wandisco/wd-hive-metastore
ln -s /usr/ibmpacks/current/bigsql/bigsql/lib/java/bigsql-sync.jar bigsql-sync.jar-
If the jar is not available then copy the jar from a node that has it to:
/opt/wandisco/wd-hive-metastore|
Known Issue: WD Fusion Hive Metastore plugin not installed locally to
Hive Metastore If WD Fusion Hive Metastore is not installed to the same server as the Hive metastore, then you need to complete the following workaround: |
-
Log in to kadmin.local or kadmin on the host machine running wd-hive-metastore.
-
In kadmin use
addprinc -randkey hive/<WD-hive-metstore-hostname>@<REALM> addprinc -randkey HTTP/<WD-hive-metstore-hostname>@<REALM> xst -norandkey -k hive.keytab hive/<WD-hive-metstore-hostname>@<REALM> HTTP/<WD-hive-metstore-hostname>@<REALM>
-
Exit kadmin
-
Check the keytab has the correct entries by using
klist -e -k -t hive.keytab
Move the keytab into place:
sudo mv hive.keytab /etc/wandisco/hive/
-
Make sure the keytab is readable by the hive user by using:
sudo chown hive:hive /etc/wandisco/hive/hive.keytab chmod +r /etc/wandisco/hive/hive.keytab
-
Now restart Fusion server using:
service fusion-server restart
-
Now restart the Hive Metastore:
restart the Wd-hive-metastore service using your Hadoop manager
-
Now restart the HiveServer2 service via using your Hadoop manager (i.e. Ambari)
-
Connect to beeline again.
|
Known Issue: HDP deployments and Hive Metastore port
Currently, you can’t run the standard Hive Metastore service on the same
host as the wd-hive-metastore service, because HDP uses the
hive.metastore.uris parameter to set the port for the standard Hive Metastore service. |
See Hortonworks Documentation about
Hive Service Ports
HDP uses the hive.metastore.uris parameter to set the Hive Metastore port. Without the WD Hive Template installed, the HiveServer2 service would use an embedded metastore service and not the separate Hive Metastore service. When this is the case we can’t support running standard Hive Metastore and the wd-hive-metastore on the same host when using a HDP distribution. We recommend that you stop Hive Metastore when using WD Hive on HDP, and to be clear, even if the
wd-hive-metastore service is deployed onto another host then the standard Hive Metastore service port will be changed by our configuration of hive.metastore.uris.
|
Known Issue: Cloudera/WD Hive Metastore deployments: manual copy of hive-site.xml required
If WD Hive Metastore is installed onto a Cloudera-based cluster and the
WD Hive Metastore is being installed on a host other than the WD Fusion
server then after the install is complete the admin must complete these
steps:
|
Copy the config file from
/etc/wandisco/hive/hive-site.xml
to the same location on the target host.
Restart the WD-HIVE service using Cloudera Manager.
|
Known Issue: Failed to install metastore service during fusion installation in IOP4.1 and IOP4.2
Example failure, during IBM BigInsights installation. The error is caused by
the stack not being available via ambari-server. The error has also been seen in Ambari-based installations.
|
Workaround
To fix this you need to ensure that only a single Ambari-server process
is running before doing the service ambari-server restart. To find the
ambari-server processes that are running you can use.
ps -aux | grep ambari-server
Then kill all the ambari-server processes by using
kill -9 [pid of process]
then restart the ambari-server by using
service ambari-server restart
Also rerun the check to ensure you only have a single process running:
ps -aux | grep ambari-server
You can then check in the Ambari UI if the WD Hive Metastore and WD Hiveserver2 Template services are available. If they are present then you will be ok to proceed with retrying to install the service via the installer.
|
Important: Running Apache Sentry with WANdisco Hive Metastore
Apache Sentry, the role-based authz module, currently can not support Hive Metastore High Availability:
Apache Sentry does not currently support Hive metastore HA https://issues.apache.org/jira/browse/SENTRY-872.
|
When running Sentry on a CDH cluster that uses a WANdisco Hive metastore, we mimic the Hive metastore HA. This means that it has two metastore clients sending updates, which the cluster can’t handle — only one of the metastores will be able to send and receive correct authz updates to the Sentry server.
The resulting problem can be seen by looking into the Sentry log file. If presented with two metastore clients, will have entries similar to the below - this shows it receiving an update to sequence number 5 from one client, and an update to sequence number from another; obviously it can’t resolve this and so repeats indefinitely.
The Sentry log, if presented with two metastore clients, will have entries similar to the below - this shows it receiving an update to sequence number 5 from one client, and an update to sequence number from another; obviously it can’t resolve this and so repeats indefinitely.
2017-05-26 14:15:51,575 WARN org.apache.sentry.hdfs.SentryPlugin: Recieved Authz Path FULL update [5].. 2017-05-26 14:15:52,464 WARN org.apache.sentry.hdfs.SentryPlugin: Recieved Authz Path FULL update [11]..
If left long enough, one of the log sequences will indicate that it has become stuck, e.g. the "connected" metastore is able to proceed, while theother metastore is unable to progress:
2017-06-06 21:00:11,181 WARN org.apache.sentry.hdfs.SentryPlugin: Recieved Authz Path FULL update [5].. 2017-06-06 21:00:11,895 WARN org.apache.sentry.hdfs.SentryPlugin: Recieved Authz Path FULL update [19476]..
Solution:
In Clusters using Sentry, the original mestastore must be stopped. Sentry should then be restarted, and then our WD-metastore started. If at any point a cluster ends up with two metastores running (whether wd-metastores or not) the same process needs to be followed:
-
stop all running metastores
-
restart Sentry
-
start desired metastore
This issue is not specific to WANdisco and would occur in any scenario that involves two or more metastores being run in paralllel.
Workaround for when Hive location URI doesn’t match defaultFS
In the case where a Hive location URI doesn’t match defaultFs and thus triggers an apparent inconsistency on default Hive DB, the offending locationURI can be updated by using the hive metatool command, i.e.
hive --service metatool
For instance,
hive --service metatool --listFSRoot
shows all the locationURIs in the metastore. You can then observe which are out of date, and run:
hive --service metatool -updateLocation <new-loc> <old-loc>
To update the location to the current defaultFs.
14.2. Installation procedure
The following sections cover how to install WD Fusion with the Hive Plugin, the first covers the Ambari platform, followed by the procedure for installing to a Cloudera platform.
Ensure you have read all known issues before beginning installation.
14.2.1. Ambari-based Installation
-
Download the installer fusion-ui-server-hdp-hive_rpm_installer.sh from WANdisco’s FD website. You need the appropriate one for your platform.
-
In this version of Hive Metastore, the Hive Metastore plugin is provided as a full blown installer that installs WD Fusion with Hive Metastore replication plugin already built-in.
-
Ensure the downloaded files are executable and run the installer.
./fusion-ui-server-hdp-hive_rpm_installer.sh
-
The installer will first perform a check for the system’s JAVA_HOME variable.
Installing WD Fusion Verifying archive integrity... All good. Uncompressing WANdisco Fusion........................ :: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### ##### Welcome to the WANdisco Fusion installation You are about to install WANdisco Fusion version 2.10.4 Do you want to continue with the installation? (Y/n)Enter Y to continue.
-
The installer checks that both Perl and Java are installed on the system.
Checking prerequisites: Checking for perl: OK Checking for java: OK
-
The installer asks you to confirm which TCP port will be used for accessing the WD Fusion web UI, the default is "8083".
Which port should the UI Server listen on? [8083]:
-
Now specify the platform version you are using.
Please specify the appropriate platform from the list below: [0] hdp-2.2.x [1] hdp-2.3.x [2] hdp-2.4.x [3] hdp-2.5.x [4] hdp-2.6.0/hdp-2.6.1 [5] hdp-2.6.2+ Which fusion platform do you wish to use?
Installing HDP-2.6.xIf you are using HDP-2.6.x ensure you specify the correct platform version - version 2.6.0 and 2.6.1 need a separate installer to 2.6.2 and above. -
Next, you set the system user, group for running the application.
We strongly advise against running Fusion as the root user. For default setups, the user should be set to 'hdfs'. However, you should choose a user appropriate for running HDFS commands on your system. Which user should Fusion run as? [hdfs] Checking 'hdfs' ... ... 'hdfs' found. Please choose an appropriate group for your system. By default HDP uses the 'hadoop' group. Which group should Fusion run as? [hadoop] Checking 'hadoop' ... ... 'hadoop' found.
You should press enter to go with the defaults.
-
You will now be shown a summary of the settings that you have provided so far:
Installing with the following settings: User and Group: hdfs:hadoop Hostname: <your.fusion.hostname> Fusion Admin UI Listening on: 0.0.0.0:8083 Fusion Admin UI Minimum Memory: 128 Fusion Admin UI Maximum memory: 512 Platform: hdp-2.5.0 (2.7.3.2.5.0.0-1245) Fusion Server Hostname and Port: <your.fusion.hostname>:8082 Do you want to continue with the installation? (Y/n)
Enter Y unless you need to make changes to any of the settings.
-
The installation will now complete:
Installing hdp-2.5.0 server packages: fusion-hcfs-hdp-2.5.0-server-2.10.4_SNAPSHOT.el6-2510.noarch.rpm ... Done fusion-hcfs-hdp-2.5.0-ihc-server-2.10.4_SNAPSHOT.el6-2510.noarch.rpm ... Done Installing plugin packages: wd-hive-plugin-hdp-2.5.0-2.10.4_SNAPSHOT-741.noarch.rpm ... Done Installing fusion-ui-server package: fusion-ui-server-2.10.4-592.noarch.rpm ... Done Adding the user hdfs to the hive group if the hive group is present. Starting fusion-ui-server: [ OK ] Checking if the GUI is listening on port 8083: .....Done Please visit http://<your.fusion.hostname.com>:8083/ to complete installation of WANdisco Fusion If <your.fusion.hostname.com> is internal or not available from your browser, replace this with an externally available address to access it.
-
Once the installation has completed, you need to configure the WD Fusion server using the browser based UI. Open a browser and enter the provided URL, or IP address.
-
Follow this section to complete the installation by configuring WD Fusion using a browser-based graphical user interface.
Silent Installation
For large deployments it may be worth using Silent Installation option.Open a web browser and point it at the provided URL. e.g
http://<your.fusion.hostname>.com:8083/
-
In the first "Welcome" screen you’re asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows: Figure 230. Welcome
Figure 230. Welcome- Adding a new WD Fusion cluster
-
Select Add Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
-
Select Add to an existing Zone.
High Availability for WD Fusion / IHC Servers
It’s possible to enable High Availability in your WD Fusion cluster by adding additional WD Fusion/IHC servers to a zone. These additional nodes ensure that in the event of a system outage, there will remain sufficient WD Fusion/IHC servers running to maintain replication.
Add HA nodes to the cluster using the installer and choosing to Add to an existing Zone. A new node name will be assigned but you can chose a label is preferred.
In this example we create a New Zone.
-
Run through the installer’s detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
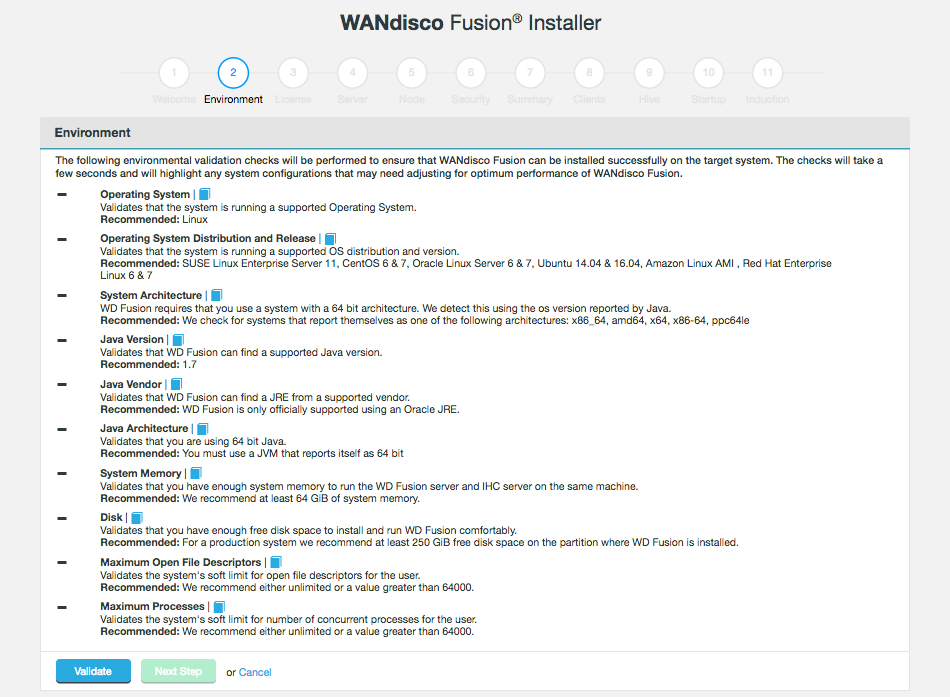 Figure 231. Environmental checks
Figure 231. Environmental checks -
On clicking Validate the installer will run through a series of checks of your system’s hardware and software setup and warn you if any of WD Fusion’s prerequisites are missing.
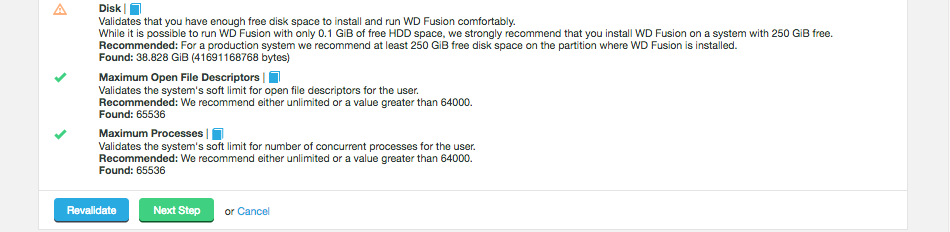 Figure 232. Example check results
Figure 232. Example check resultsAny element that fails the check should be addressed before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if only for evaluation purposes and not for production. However, when installing for production, you should address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
-
Select your license file and upload it.
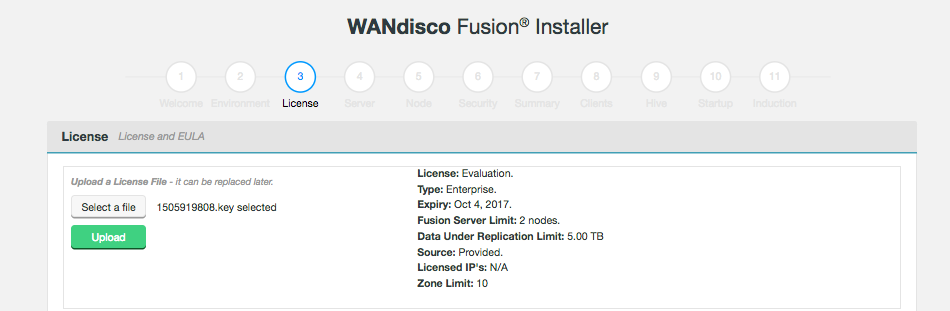 Figure 233. Upload your license file
Figure 233. Upload your license fileThe conditions of your license agreement will be shown in the top panel.
-
In the lower panel is the EULA.
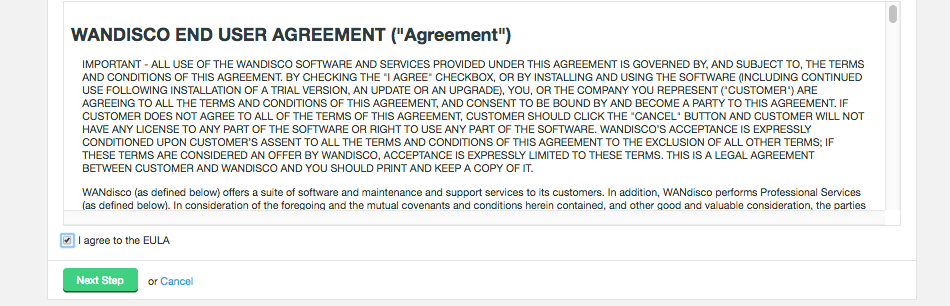 Figure 234. Verify license and agree to subscription agreement.
Figure 234. Verify license and agree to subscription agreement.Tick the checkbox I agree to the EULA to continue, then click Next Step.
-
Enter settings for the WD Fusion server.
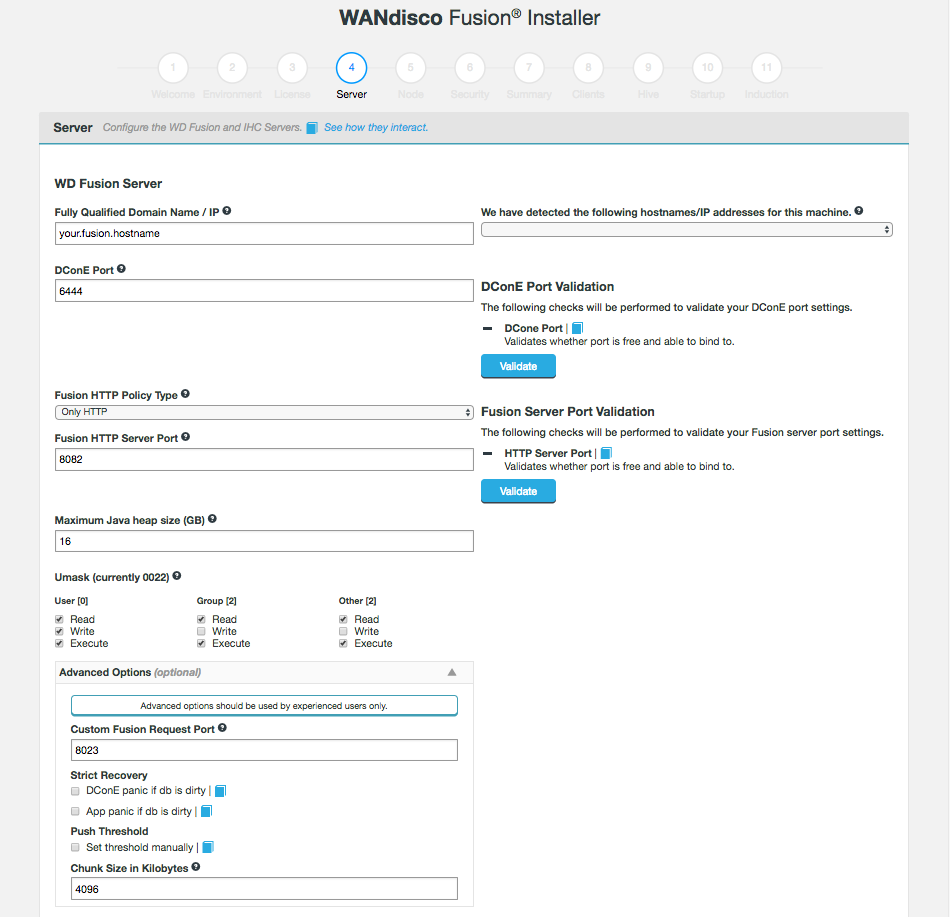 Figure 235. Enter settings
Figure 235. Enter settings
You may need to click Validate after entering your ports.
WD Fusion Server
- Maximum Java heap size (GB)
-
Enter the maximum Java Heap value for the WD Fusion server. The minimum for production is 16GB but 64GB is recommended.
- Umask (currently 022)
-
Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
Advanced options
|
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments.
The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco’s support team before enabling them.
|
- Custom Fusion Request Port
-
The port the Fusion server will use to listen to requests from Fusion clients. The default is 8023 but you can change it in case it is assigned elsewhere, e.g. Cloudera’s Headlamp debug server also uses it.
- Strict Recovery
-
Two advanced options are provided to change the way that WD Fusion responds to a system shutdown where WD Fusion was not shutdown cleanly. Currently the default setting is to not enforce a panic event in the logs, if during startup we detect that WD Fusion wasn’t shutdown. This is suitable for using the product as part of an evaluation effort. However, when operating in a production environment, you may prefer to enforce the panic event which will stop any attempted restarts to prevent possible corruption to the database.
- DConE panic if dirty (checkbox)
-
This option lets you enable the strict recovery option for WANdisco’s replication engine, to ensure that any corruption to its prevayler database doesn’t lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
- App Integration panic if dirty (checkbox)
-
This option lets you enable the strict recovery option for WD Fusion’s database, to ensure that any corruption to its internal database doesn’t lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
- Push Threshold
-
See explanation of the Push Threshold.
- Chunk Size
-
The size of the 'chunks' used in file transfer.
Enable SSL for WD Fusion
Tick the checkbox to enable SSL between the Fusion core components.

- KeyStore Path
-
System file path to the keystore file.
e.g. /opt/wandisco/ssl/keystore.ks - KeyStore Password
-
Encrypted password for the KeyStore.
- Key Alias
-
The Alias of the private key.
e.g. WANdisco - Key Password
-
Private key encrypted password.
- TrustStore Path
-
System file path to the TrustStore file.
/opt/wandisco/ssl/keystore.ks - TrustStore Password
-
Encrypted password for the TrustStore.
IHC Server
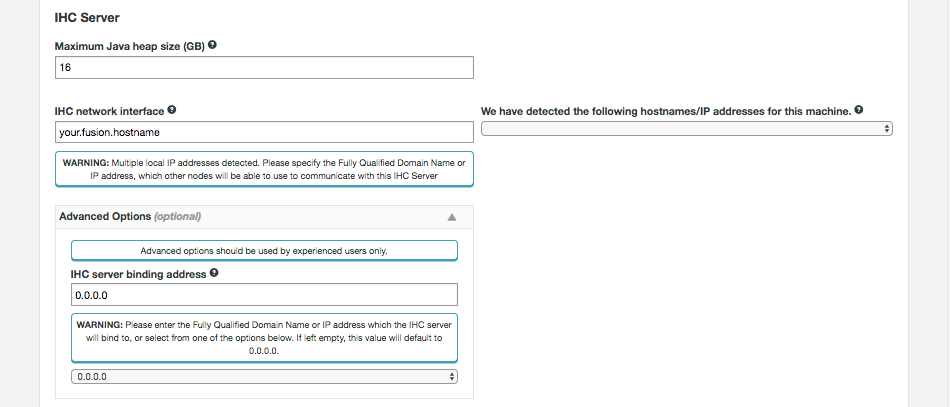
- Maximum Java heap size (GB)
-
Enter the maximum Java Heap value for the WD Inter-Hadoop Communication (IHC) server. The minimum for production is 16GB but 64GB is recommended.
- IHC network interface
-
The hostname for the IHC server. It can be typed or selected from the dropdown on the right.
Advanced Options (optional)
- IHC server binding address
-
In the advanced settings you can decide which address the IHC server will bind to. The address is optional, by default the IHC server binds to all interfaces (0.0.0.0), using the port specified in the
ihc.serverfield.
Once all settings have been entered, click Next step.
-
Next, you will enter the settings for your new Zone.
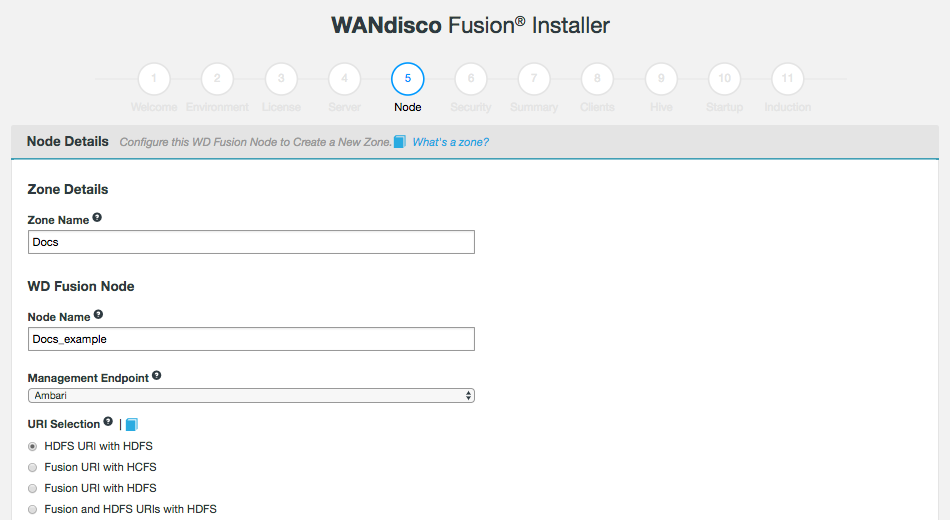
Zone and Node Information
- Zone Name
-
Give your zone a name to allow unique identification of a group of nodes.
- Node Name
-
A unique identifier that will help you find the node on the UI.
- Management Endpoint
-
Select the Hadoop manager that you are using, i.e. Ambari. The selection will trigger the entry fields for your selected manager.
14.2.2. Advanced Options
| Only apply these options if you fully understand what they do. The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments. The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco’s support team before enabling them. |
URI Selection
The default behavior for WD Fusion is to fix all replication to the Hadoop Distributed File System / hdfs:/// URI. Setting the hdfs-scheme provides the widest support for Hadoop client applications, since some applications can’t support the available "fusion:///" URI they can only use the HDFS protocol. Each option is explained below:
- Use HDFS URI with HDFS file system
-
 Figure 239. Option A
Figure 239. Option A
This option is available for deployments where the Hadoop applications support neither the WD Fusion URI or the HCFS standards. WD Fusion operates entirely within HDFS.
This configuration will not allow paths with the fusion:// URI to be used; only paths starting with hdfs:// or no scheme that correspond to a mapped path will be replicated. The underlying file system will be an instance of the HDFS DistributedFileSystem, which will support applications that aren’t written to the HCFS specification.
- Use WD Fusion URI with HCFS file system
-
 Figure 240. Option B
Figure 240. Option BWhen selected, you need to use fusion:// for all data that must be replicated over an instance of the Hadoop Compatible File System. If your deployment includes Hadoop applications that are either unable to support the Fusion URI or are not written to the HCFS specfication, this option will not work.
MapR deployments
Use this URI selection if you are installing into a MapR cluster.
- Use Fusion URI with HDFS file system
-
 Figure 241. Option B
Figure 241. Option BThis differs from the default in that while the WD Fusion URI is used to identify data to be replicated, the replication is performed using HDFS itself. This option should be used if you are deploying applications that can support the WD Fusion URI but not the Hadoop Compatible File System.
- Use Fusion URI and HDFS URI with HDFS file system
-
 Figure 242. Option D
Figure 242. Option DThis "mixed mode" supports all the replication schemes (fusion://,
hdfs://and no scheme) and uses HDFS for the underlying file system, to support applications that aren’t written to the HCFS specification.
Advanced Options
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments.
The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco’s support team before enabling them.
You will need to validate your ports after entering values.
- Custom UI Host
-
Enter your UI host or select it from the drop down below.
- Custom UI Port
-
Enter the port number for the Fusion UI.
- External UI Address
-
The address external processes should use to connect to the UI on.
-
In the lower panel you now need to configure the Ambari manager. Once you have entered the information click Validate.
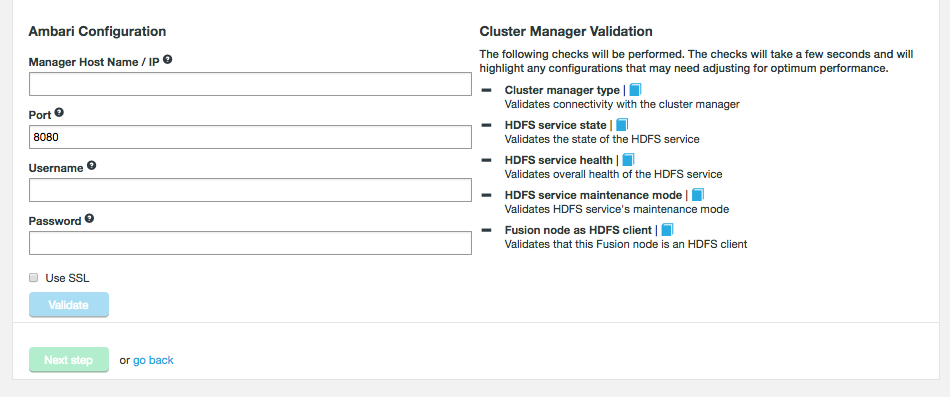
- Manager Host Name /IP
-
The FQDN for the server the manager is running on.
- Port
-
The TCP port the manager is served from. The default is 8080.
- Username
-
The username of an account that runs the manager. This account must have admin privileges on the Management endpoint.
- Password
-
The password that corresponds with the above username.
- SSL
-
Tick the SSL checkbox to use
httpsin your Manager Host Name and Port. You may be prompted to update the port if you enable SSL.
Ambari Configuration Validation
- Cluster manager type
-
Validates connectivity with the cluster manager.
- HDFS service state
-
Validates the state of the HDFS service.
- HDFS service health
-
Validates the overall health of the HDFS service.
- HDFS service maintenance mode
-
Validates HDFS service’s maintenance mode.
- Fusion node as HDFS client
-
Validates that this Fusion node is a HDFS client.
|
Authentication without a management layer
WD Fusion normally uses the authentication built into a cluster’s management layer, i.e. Ambari’s username and password are required to log in to WD Fusion.
However, in Cloud-based deployments, such as Amazon’s S3, there is no management layer.
In this situation, WD Fusion adds a local user to WD Fusion’s ui.properties file, either during the silent installation or through the command-line during an installation.
|
-
Enter Kerberos security details, if applicable to your deployment.
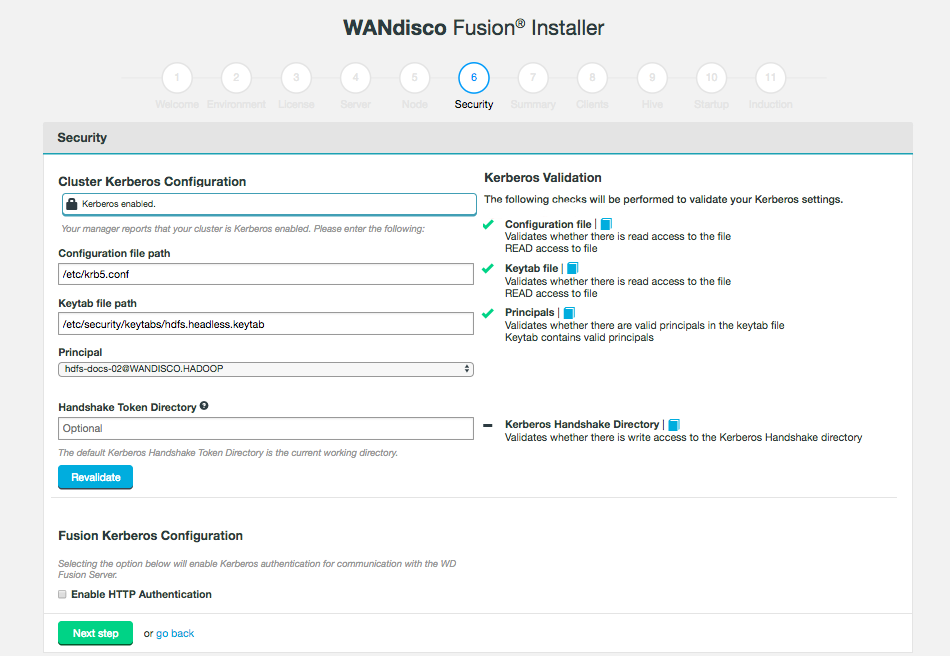
Click Validate to confirm that your settings are valid. Once validated, click Next step.
Enabling Kerberos authentication on WD Fusion’s REST API
When a user has enabled Kerberos-authentication on their REST API, they must kinit before making REST calls, and enable GSS-Negotiate authentication.
To do this with curl, the user must include the "--negotiate" and "-u:" options, like so:
curl --negotiate -u: -X GET "http://${HOSTNAME}:8082/fusion/fs/transfers"
See Setting up Kerberos for more information about Kerberos setup.
-
The summary shows all of your installation settings. If you spot anything that needs to be changed you can click on the go back link.
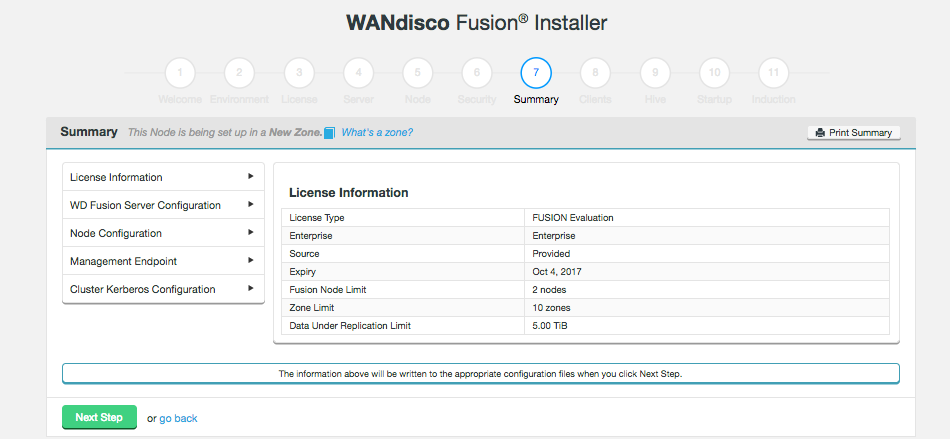 Figure 243. Summary
Figure 243. SummaryOnce you are happy with the settings and all your WD Fusion clients are installed, click Next Step.
-
In the next step you need to place the WD Fusion client packages on the manager node and distribute to all nodes in the cluster.
 Figure 244. Client installations
Figure 244. Client installationsFollow the on-screen instructions for downloading the Client Package. This requires you to go to your Ambari UI.
Client package location
Packages for all platforms can be found here:/opt/wandisco/fusion-ui-server/ui/client_packages /opt/wandisco/fusion-ui-server/ui/stack_packages /opt/wandisco/fusion-ui-server/ui/parcel_packages
-
Confirm the installation.
 Figure 245. Confirm client installations
Figure 245. Confirm client installations -
Now configure the Hive Metastore Plugin by following the on-screen instructions.
 Figure 246. Hive plugin - substep 1.
Figure 246. Hive plugin - substep 1. -
You can confirm the services are in place by looking on the Ambari UI under Add Services but do not enable it using the Ambari UI.
 Figure 247. Hive plugin - Ambari
Figure 247. Hive plugin - AmbariWhen you have confirmed that the files are in place, on the Fusion installer screen, click Next.
-
Keytab management has been added to our Hive services, this necessitates the use of Kadmin credentials during the install. You need to add the required information and then click Update.
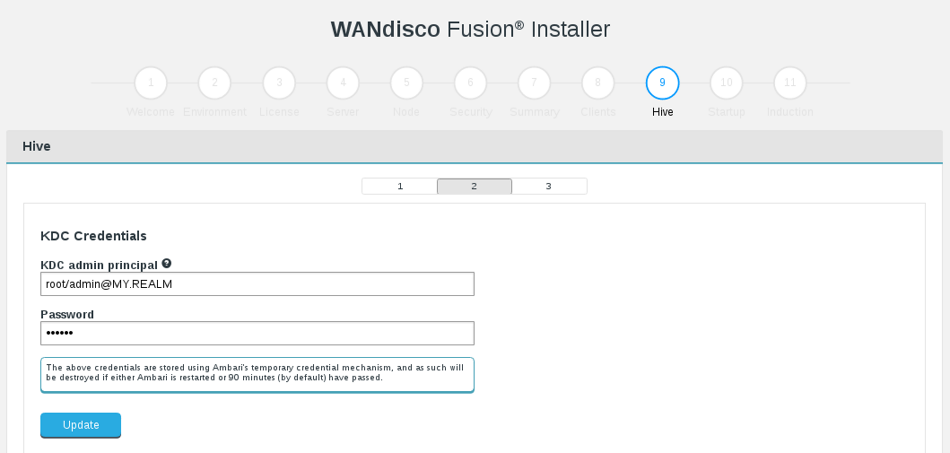 Figure 248. Hive plugin - Kadmin
Figure 248. Hive plugin - Kadmin- Kadmin Principal
-
A KDC administrator principal used for the keytab.
- Password
-
The password for the KDC Principal entered above.
Kerberos not managed by AmbariIf you are using Kerberos on your cluster but it is not being managed by Ambari you will need to manage your principals and keytabs manually.Ambari installationThe above credentials are stored using Ambari temporary credentials mechanism, and as such will be destroyed if either Ambari is restarted or after 90 minutes have passed.
-
Now the installer performs some basic validation. Click Validate.
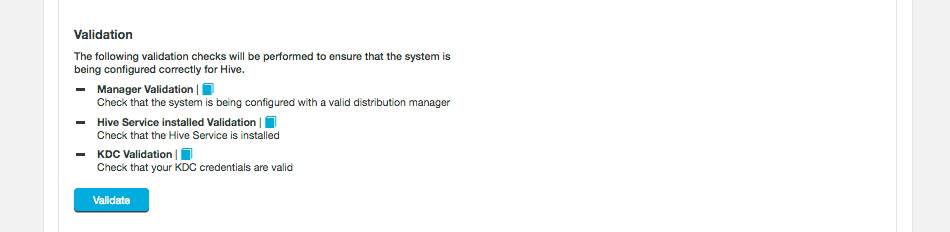 Figure 249. Hive plugin - Ambari
Figure 249. Hive plugin - AmbariThe credentials are validated in terms of the following properties:
- Manager Validation
-
Checks that the system is being configured with valid distribution manager support. Should this validation check fail, you would need to check that you have entered the right Manager details.
- Hive Service installation Validation
-
The installer will check that Hive is running on the server. Should the validation check fail, you should check that Hive is running.
- KDC Validation
-
Check that your KDC credentials are valid.
-
In the lower panel input the information for Hive configuration.
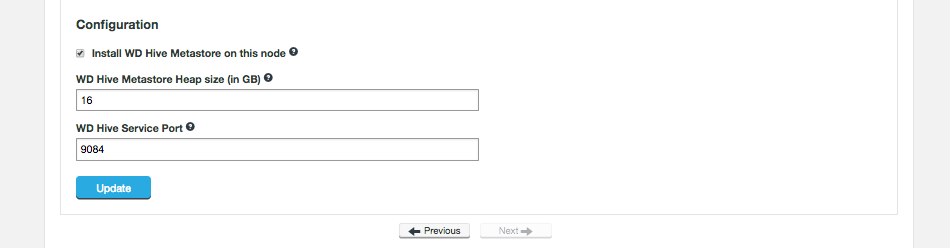 Figure 250. Hive plugin - Configuration
Figure 250. Hive plugin - Configuration- Install WD Hive Metastore on this node
-
Tick the checkbox to confirm it is the node you are currently on that the WD Hive Metastore should be installed on.
- WD Hive Metastore Heap size
-
Enter the maximum heap size in GB.
- WD Hive Service Port
-
Enter the value for the Hive Service port. Note that this is not the same as the Hive Metastore Port. The default is 9084.
Click Update and then Next.
Known Issue:You must provide a hostname, not an IP address. Currently, an IP address is not enough to verify the presence of the service. We will add support for IP addresses once we have identified a workable method for validating it with the manager.
-
The next step gives a summary and handles the plugin’s installation. Click Start Install.
 Figure 251. Hive plugin - Ambari
Figure 251. Hive plugin - Ambari- Metastore Service Install
-
This step handles the installation of the WD Hive Metastore Service into Ambari.
- Hive Metastore Template Install
-
Install the WANdisco Hive Metastore Service Template on Ambari.
- Update Hive Configuration
-
Updates the URIs for Hive connections in Ambari.
- Restart Hive Service
-
Restarts Hive Service in Ambari. Note this process can take several minutes to complete. Please don’t make any changes or refresh your installer’s browser session.
- Configure Hive Configuration Files
-
Symlink the Hive configuration file into the Fusion Hive Metastore plugin.
- Restart WD Hive Metastore Service
-
Restarts Hive Metastore Service in Ambari. Note this process can take several minutes to complete.
When installation is complete, click Next.
-
Configuration is now complete. Click Start WD Fusion.
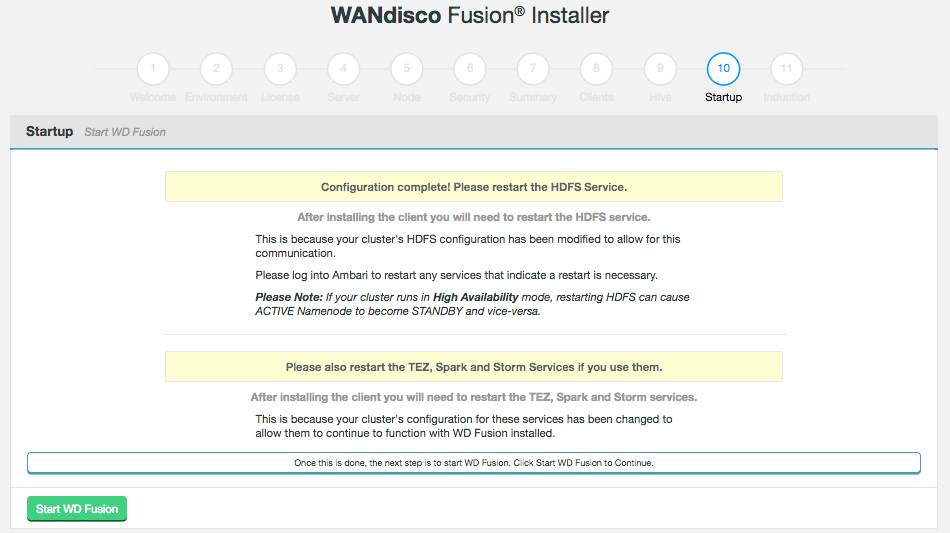 Figure 252. Hive Metastore plugin installation summary
Figure 252. Hive Metastore plugin installation summary -
If you have existing nodes you can induct them now. If you would rather induct them later, click Skip Induction.
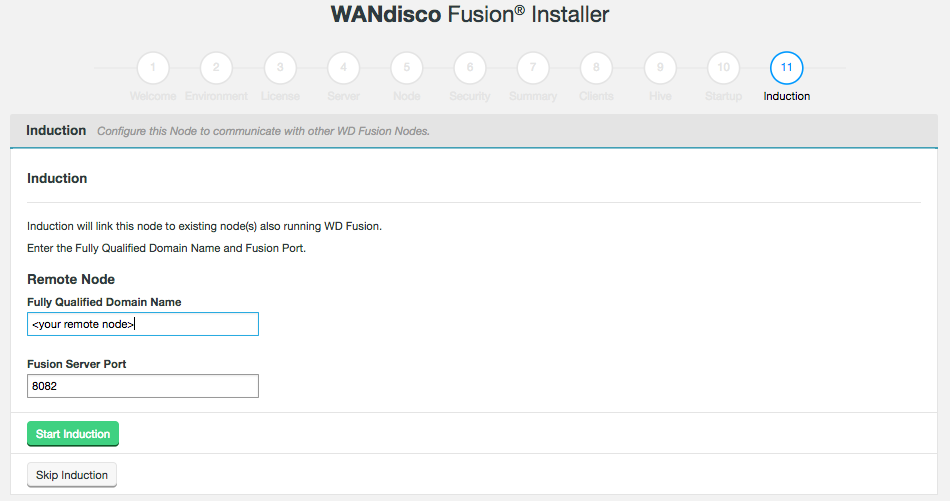 Figure 253. Node Induction
Figure 253. Node Induction
14.2.3. Cloudera-based installation
This section covers the installation of WD Fusion with WANdisco’s Hive Plugin, on a Cloudera CDH platform.
|
Known Issue: Cloudera-based deployments
If you are installing on a node other than Fusion install then when installing the Hive Metastore plugin, you must create the folder /etc/wandisco/hive on the Metastore host you specified above.
This folder must have owner hive:hive and the Hive user must have read-write permissions for this location.
|
-
Download the installer e.g. fusion-ui-server-cdh-hive_rpm_installer.sh from WANdisco’s FD website. You need the appropriate one for your platform.
-
In this version of Hive Metastore, the Hive Metastore plugin is provided as a full blown installer that installs WD Fusion with Hive Metastore replication plugin already built-in.
-
Ensure the downloaded files are executable and run the installer.
./fusion-ui-server-cdh-hive_rpm_installer.sh
-
The installer will first perform a check for the system’s JAVA_HOME variable.
Installing WD Fusion Verifying archive integrity... All good. Uncompressing WANdisco Fusion........................ :: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### ##### Welcome to the WANdisco Fusion installation You are about to install WANdisco Fusion version 2.10.4-584 Do you want to continue with the installation? (Y/n)Enter "Y" to continue.
-
The installer checks that both Perl and Java are installed on the system.
Checking prerequisites: Checking for perl: OK Checking for java: OK
-
The installer asks you to confirm which TCP port will be used for accessing the WD Fusion web UI, the default is "8083".
Which port should the UI Server listen on? [8083]:
-
Now specify the platform version you are using.
Please specify the appropriate platform from the list below: [0] cdh-5.3.x [1] cdh-5.4.x [2] cdh-5.5.x [3] cdh-5.6.x [4] cdh-5.7.x [5] cdh-5.8.x [6] cdh-5.9.x [7] cdh-5.10.x [8] cdh-5.11.x Which WD Fusion platform do you wish to use?
Known issue: Permission error when using CDH 5.11.xWD Fusion 2.10.3 adds support for CDH 5.11.0. If you deploy on CDH 5.11.0, you must ensure that all Cloudera scripts in the directory/usr/lib64/cmf/service/csdare permissioned to be executable (chmod +x).Without this change WD-Hive Metastore may not restart successfully, the
stderr.log, it would show:exec /usr/lib64/cmf/service/csd/graceful_stop_role.sh /usr/lib64/cmf/service/csd/csd.sh: line 44: /usr/lib64/cmf/service/csd/graceful_stop_role.sh: Permission denied /usr/lib64/cmf/service/csd/csd.sh: line 44: exec: /usr/lib64/cmf/service/csd/graceful_stop_role.sh: cannot execute: Permission denied
-
Next, you set the system user group for running the application.
We strongly advise against running Fusion as the root user. For default CDH setups, the user should be set to 'hdfs'. However, you should choose a user appropriate for running HDFS commands on your system. Which user should Fusion run as? [hdfs] Checking 'hdfs' ... ... 'hdfs' found. Please choose an appropriate group for your system. By default CDH uses the 'hdfs' group. Which group should Fusion run as? [hdfs] Checking 'hdfs' ... ... 'hdfs' found.
You should press enter to go with the default "hdfs".
-
You will now be shown a summary of the settings that you have provided so far:
Installing with the following settings: Installation Prefix: /opt/wandisco User and Group: hdfs:hdfs Hostname: <your.fusion.hostname> WD Fusion Admin UI Listening on: 0.0.0.0:8083 WD Fusion Admin UI Minimum Memory: 128 WD Fusion Admin UI Maximum memory: 512 Platform: cdh-5.10.0 (2.6.0-cdh5.10.0) WD Fusion Server Hostname and Port: <your.fusion.hostname>:8082 Do you want to continue with the installation? (Y/n)
Enter "Y" unless you need to make changes to any of the settings.
-
The installation will now complete:
Installing cdh-5.10.0 server packages: fusion-hcfs-cdh-5.10.0-server-2.10.4_SNAPSHOT.el6-2508.noarch.rpm ... Done fusion-hcfs-cdh-5.10.0-ihc-server-2.10.4_SNAPSHOT.el6-2508.noarch.rpm ... Done Installing plugin packages: wd-hive-plugin-cdh-5.10.0-2.10.4_SNAPSHOT-737.noarch.rpm ... Done Installing fusion-ui-server package: fusion-ui-server-2.10.4-584.noarch.rpm ... Done Adding the user hdfs to the hive group if the hive group is present. Starting fusion-ui-server: [ OK ] Checking if the GUI is listening on port 8083: .......Done Please visit <your.fusion.hostname> to complete installation of WANdisco Fusion If <your.fusion.hostname> is internal or not available from your browser, replace this with an externally available address to access it.
-
Once the installation has completed, you need to configure the WD Fusion server using the browser based UI. Open a browser and enter the provided URL, or IP address.
http://<your.fusion.hostname>.com:8083/
-
Follow this section to complete the installation by configuring WD Fusion using a browser-based graphical user interface.
Silent Installation
For large deployments it may be worth using Silent Installation option. -
In the first "Welcome" screen you’re asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows:
Figure 254. Welcome- Adding a new WD Fusion cluster
-
Select Add Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
-
Select Add to an existing Zone.
High Availability for WD Fusion / IHC Servers
It’s possible to enable High Availability in your WD Fusion cluster by adding additional WD Fusion/IHC servers to a zone. These additional nodes ensure that in the event of a system outage, there will remain sufficient WD Fusion/IHC servers running to maintain replication.
Add HA nodes to the cluster using the installer and choosing to Add to an existing Zone, using a new node name. A new node name will be assigned but you can chose a label is preferred.
In this example we create a New Zone.
-
Run through the installer’s detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
Figure 255. Environmental checks -
On clicking Validate the installer will run through a series of checks of your system’s hardware and software setup and warn you if any of WD Fusion’s prerequisites are missing.
Figure 256. Example check resultsAny element that fails the check should be addressed before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if only for evaluation purposes and not for production. However, when installing for production, you should address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
-
Select your license file and upload it.
Figure 257. Upload your license fileThe conditions of your license agreement will be shown in the top panel.
-
In the lower panel is the EULA.
Figure 258. Verify license and agree to subscription agreement.Tick the checkbox I agree to the EULA to continue, then click Next Step.
-
Enter settings for the WD Fusion server.
Figure 259. WD Fusion Server
You may need to click Validate after entering your ports.
WD Fusion Server
- Maximum Java heap size (GB)
-
Enter the maximum Java Heap value for the WD Fusion server. The minimum for production is 16GB but 64GB is recommended.
- Umask (currently 022)
-
Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
Advanced options
|
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments.
The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco’s support team before enabling them.
|
- Custom Fusion Request Port
-
The port the Fusion server will use to listen to requests from Fusion clients. The default is 8023 but you can change it in case it is assigned elsewhere, e.g. Cloudera’s Headlamp debug server also uses it.
- Strict Recovery
-
Two advanced options are provided to change the way that WD Fusion responds to a system shutdown where WD Fusion was not shutdown cleanly. Currently the default setting is to not enforce a panic event in the logs, if during startup we detect that WD Fusion wasn’t shutdown. This is suitable for using the product as part of an evaluation effort. However, when operating in a production environment, you may prefer to enforce the panic event which will stop any attempted restarts to prevent possible corruption to the database.
- DConE panic if dirty (checkbox)
-
This option lets you enable the strict recovery option for WANdisco’s replication engine, to ensure that any corruption to its prevayler database doesn’t lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
- App Integration panic if dirty (checkbox)
-
This option lets you enable the strict recovery option for WD Fusion’s database, to ensure that any corruption to its internal database doesn’t lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
- Push Threshold
-
See explanation of the Push Threshold.
- Chunk Size
-
The size of the 'chunks' used in file transfer.
Enable SSL for WD Fusion
Tick the checkbox to enable SSL between the Fusion core components.
- KeyStore Path
-
System file path to the keystore file.
e.g. /opt/wandisco/ssl/keystore.ks - KeyStore Password
-
Encrypted password for the KeyStore.
- Key Alias
-
The Alias of the private key.
e.g. WANdisco - Key Password
-
Private key encrypted password.
- TrustStore Path
-
System file path to the TrustStore file.
/opt/wandisco/ssl/keystore.ks - TrustStore Password
-
Encrypted password for the TrustStore.
IHC Server
- Maximum Java heap size (GB)
-
Enter the maximum Java Heap value for the WD Inter-Hadoop Communication (IHC) server. The minimum for production is 16GB but 64GB is recommended.
- IHC network interface
-
The hostname for the IHC server. It can be typed or selected from the dropdown on the right.
Advanced Options (optional)
- IHC server binding address
-
In the advanced settings you can decide which address the IHC server will bind to. The address is optional, by default the IHC server binds to all interfaces (0.0.0.0), using the port specified in the
ihc.serverfield.
Once all settings have been entered, click Next step.
-
Next, you will enter the settings for your new Zone.
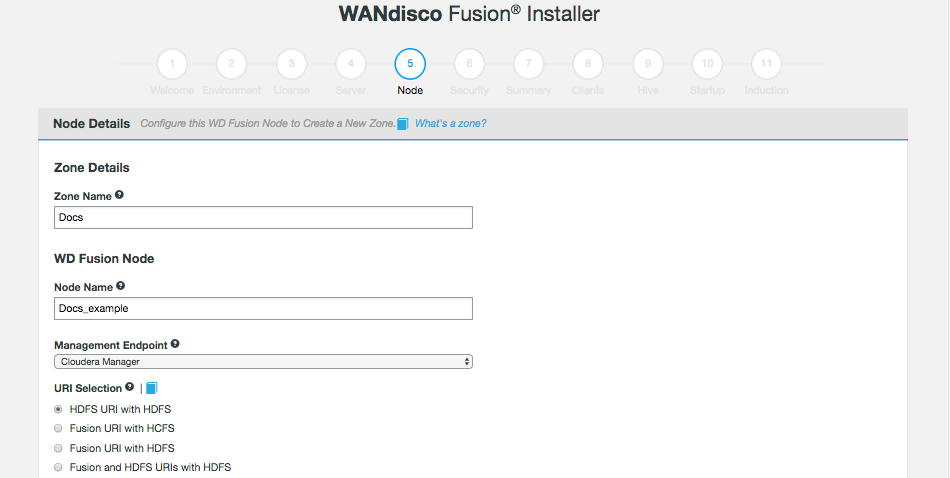 Figure 262. New Zone
Figure 262. New Zone
Zone and Node Information
Entry fields for zone properties.
- Zone Name
-
Give your zone a name to allow unique identification of a group of nodes.
- Node Name
-
A unique identifier that will help you find the node on the UI.
Induction failure
If induction fails, attempting a fresh installation may be the most straight forward cure, however, it is possible to push through an induction manually, using the REST API. See Handling Induction Failure. - Management Endpoint
-
Select the Hadoop manager that you are using, i.e. Cloudera Manager. The selection will trigger the entry fields for your selected manager.
URI Selection
The default behavior for WD Fusion is to fix all replication to the Hadoop Distributed File System / hdfs:/// URI. Setting the hdfs-scheme provides the widest support for Hadoop client applications, since some applications can’t support the available "fusion:///" URI they can only use the HDFS protocol. Each option is explained below:
- Use HDFS URI with HDFS file system
-
Figure 263. URI Option A
This option is available for deployments where the Hadoop applications support neither the WD Fusion URI or the HCFS standards. WD Fusion operates entirely within HDFS.
This configuration will not allow paths with the fusion:// URI to be used; only paths starting with hdfs:// or no scheme that correspond to a mapped path will be replicated. The underlying file system will be an instance of the HDFS DistributedFileSystem, which will support applications that aren’t written to the HCFS specification.
- Use WD Fusion URI with HCFS file system
-
Figure 264. URI Option B
When selected, you need to use fusion:// for all data that must be replicated over an instance of the Hadoop Compatible File System. If your deployment includes Hadoop applications that are either unable to support the Fusion URI or are not written to the HCFS specification, this option will not work.
MapR deployments
Use this URI selection if you are installing into a MapR cluster. - Use Fusion URI with HDFS file system
-
Figure 265. URI Option C
This differs from the default in that while the WD Fusion URI is used to identify data to be replicated, the replication is performed using HDFS itself. This option should be used if you are deploying applications that can support the WD Fusion URI but not the Hadoop Compatible File System.
- Use Fusion URI and HDFS URI with HDFS file system
-
Figure 266. URI Option D
This "mixed mode" supports all the replication schemes (fusion://,
hdfs://and no scheme) and uses HDFS for the underlying file system, to support applications that aren’t written to the HCFS specification.
Advanced Options
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments.
The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco’s support team before enabling them.
You will need to validate your ports after entering values.
- Custom UI Host
-
Enter your UI host or select it from the drop down below.
- Custom UI Port
-
Enter the port number for the Fusion UI.
- External UI Address
-
The address external processes should use to connect to the UI on.
-
In the lower panel you now need to configure the Cloudera manager. Once you have entered the information click Validate.
Figure 267. Validation- Manager Host Name /IP
-
The FQDN for the server the manager is running on.
- Port
-
The TCP port the manager is served from. The default is 8080.
- Username
-
The username of an account that runs the manager. This account must have admin privileges on the Management endpoint.
- Password
-
The password that corresponds with the above username.
- SSL
-
Tick the SSL checkbox to use
httpsin your Manager Host Name and Port. You may be prompted to update the port if you enable SSL.Authentication without a management layerWD Fusion normally uses the authentication built into a cluster’s management layer, i.e. the Cloudera Manager username and password are required to log in to WD Fusion. However, in Cloud-based deployments, such as Amazon’s S3, there is no management layer. In this situation, WD Fusion adds a local user to WD Fusion’s ui.properties file, either during the silent installation or through the command-line during an installation.
-
Enter Kerberos security details, if applicable to your deployment.
Figure 268. SecurityClick Validate to confirm that your settings are valid. Once validated, click Next step.
Enabling Kerberos authentication on WD Fusion’s REST API
When a user has enabled Kerberos-authentication on their REST API, they must kinit before making REST calls, and enable GSS-Negotiate authentication. To do this with curl, the user must include the "--negotiate" and "-u:" options, like so:curl --negotiate -u: -X GET "http://${HOSTNAME}:8082/fusion/fs/transfers"See Setting up Kerberos for more information about Kerberos setup.
-
The summary shows all of your installation settings. If you spot anything that needs to be changed you can click on the go back link.
Figure 269. SummaryOnce you are happy with the settings and all your WD Fusion clients are installed, click Next Step.
-
In the next step you need to place the WD Fusion client parcel on the manager node and distribute to all nodes in the cluster.
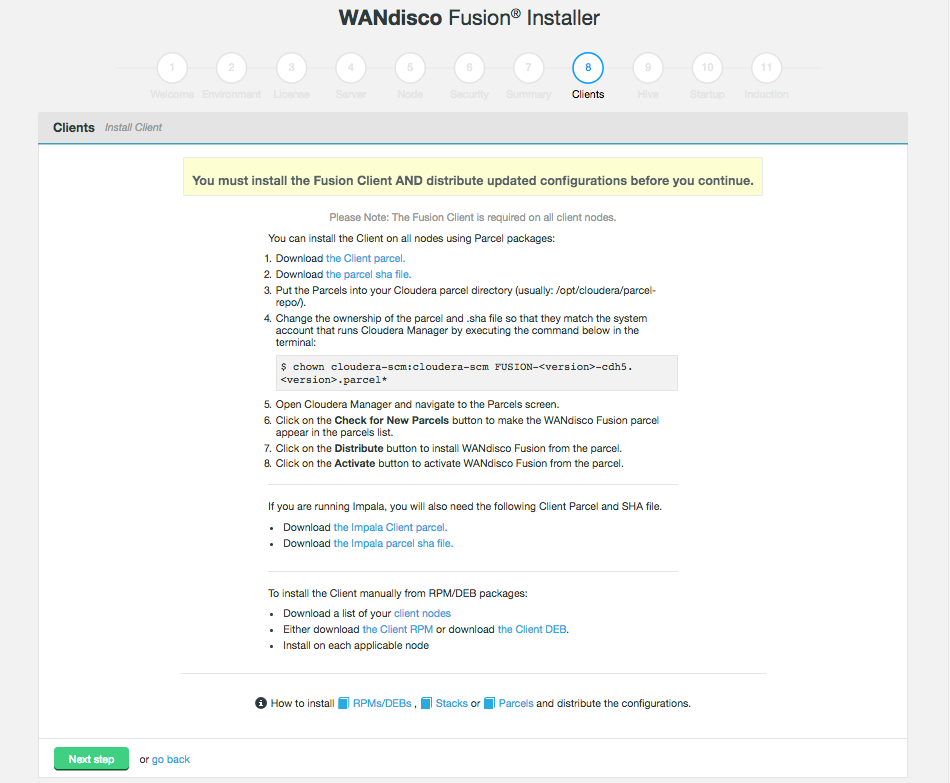 Figure 270. Client installations
Figure 270. Client installationsFollow the on-screen instructions for downloading the Client Parcel. This requires you to go to your Cloudera Manager.
Client package location
Packages for all platforms can be found here:/opt/wandisco/fusion-ui-server/ui/client_packages /opt/wandisco/fusion-ui-server/ui/stack_packages /opt/wandisco/fusion-ui-server/ui/parcel_packages
-
Confirm the installation.
Figure 271. Confirm client installations -
Now configure the Hive Metastore Plugin by following the on-screen instructions.
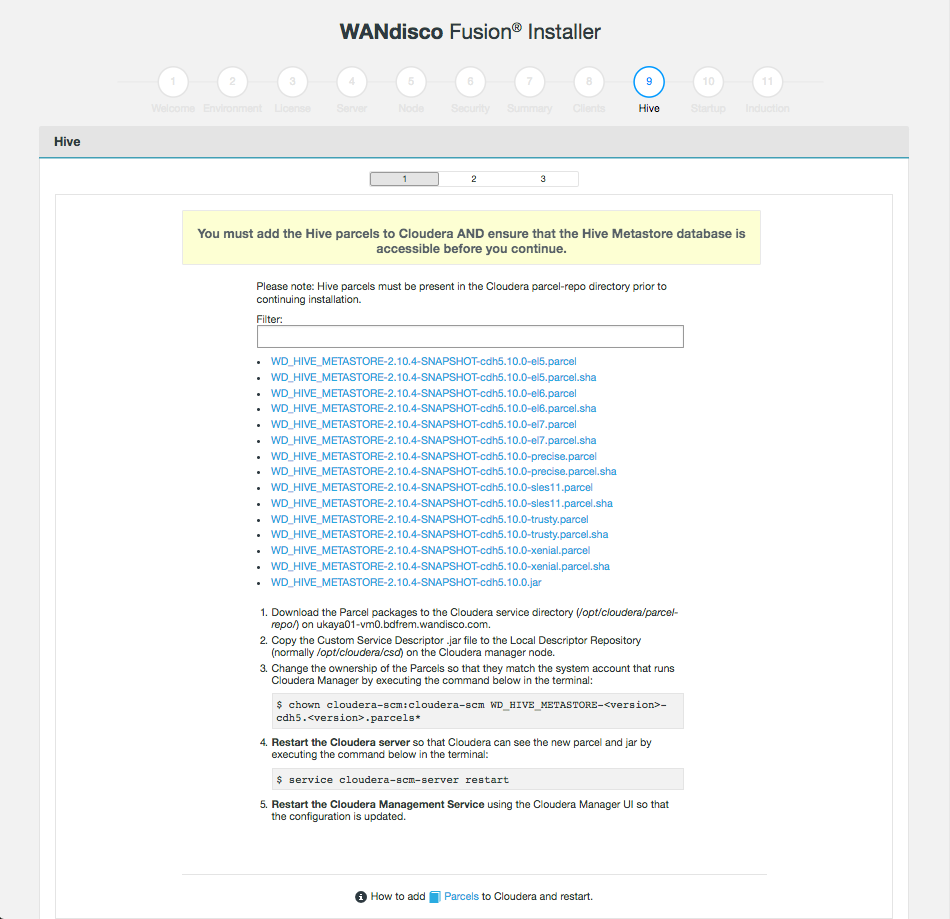 Figure 272. Hive plugin - substep 1
Figure 272. Hive plugin - substep 1When completed click Next.
-
If you check Cloudera Manager, providing the new parcel is in place, you will see it listed.
Important:You should see that the package for WD Hive Metastore is now listed through Cloudera. Do NOT enable the package at this time. WD Hive Metastore needs to be installed through steps that appear later. -
Now the installer performs some basic validation. Click Validate.
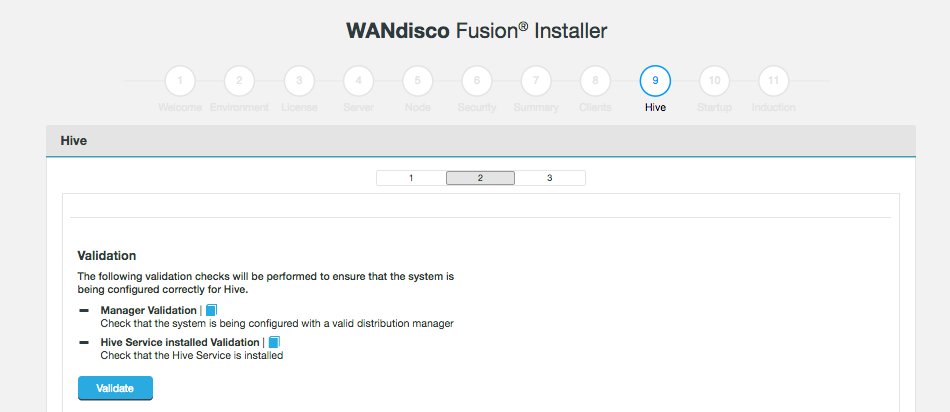 Figure 273. Hive plugin - Validation
Figure 273. Hive plugin - Validation- Manager Validation
-
Checks that the system is being configured with valid distribution manager support. In this example, "Cloudera" should be detected. Should this validation check fail, you would need to check that you have entered the right Manager details.
- Hive Service installed Validation
-
The installer will check that Hive is running on the server. Should the validation check fail, you should check that Hive is running.
-
In the lower panel input the information for Hive configuration.
Figure 274. Hive plugin - Configuration- Install WD Hive Metastore on this node
-
Tick the checkbox to confirm it is the node you are currently on that the WD Hive Metastore should be installed on.
- WD Hive Metastore Heap size
-
Enter the maximum heap size in GB.
- WD Hive Service Port
-
Enter the value for the Hive Service port. Note that this is not the same as the Hive Metastore Port. The default is 9084.
Click Update and then Next.
-
The next step gives a summary and handles the plugin’s installation. Click Start Install.
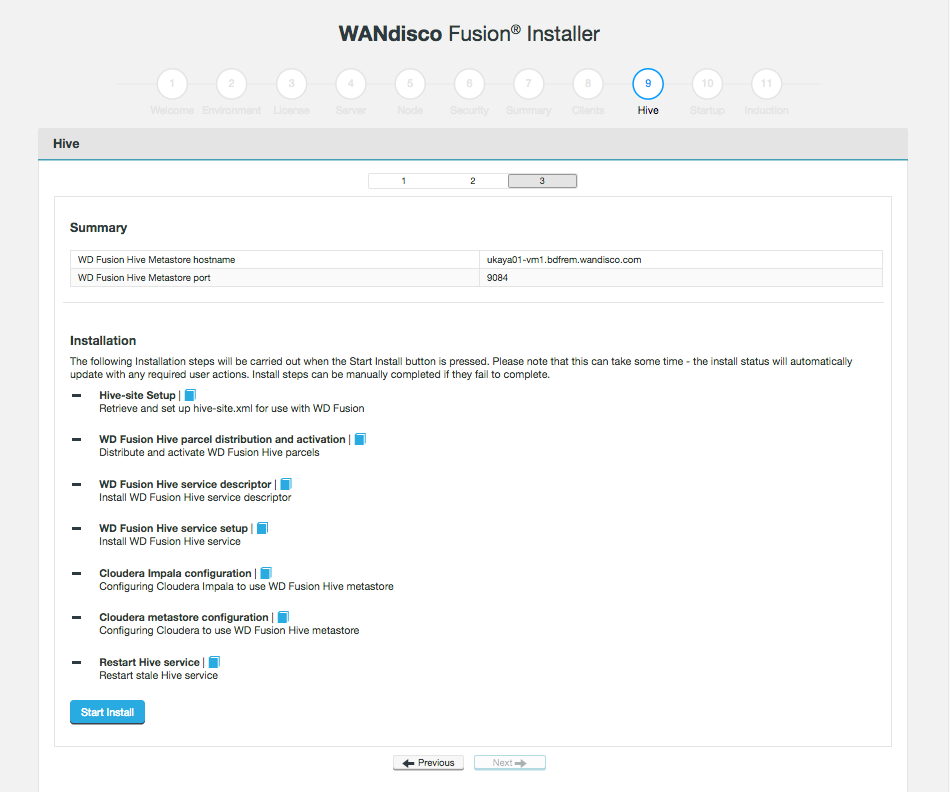 Figure 275. Hive Metastore plugin installation
Figure 275. Hive Metastore plugin installation- Hive-site Setup
-
Retrieve and setup hive-site.xml for use with WD-Fusion.
- Fusion Hive parcel distribution and activation
-
Distribute and activate Fusion Hive parcels.
- WD Fusion Hive service descriptor
-
Install Fusion Hive service descriptor.
- WD Fusion Hive service setup
-
Install WD Fusion Hive service
- Cloudera Impala configuration
-
Configuring Cloudera Impala to use WD Fusion Hive metastore.
- Cloudera metastore configuration
-
Configuring Cloudera to use WD Fusion Hive metastore.
- Restart Hive service
-
Restarts stale Hive service. Note this process can take several minutes to complete.
When you have confirmed that the files are in place, on the installer screen, click Next.
-
Configuration is now complete. Click Start WD Fusion.
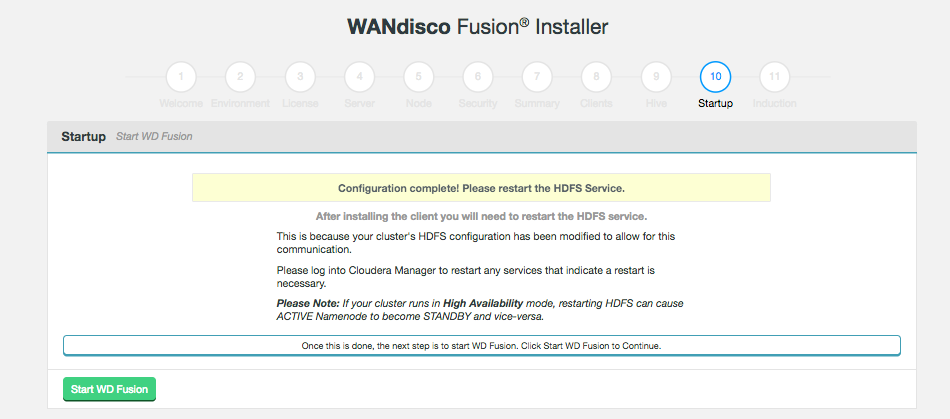 Figure 276. Hive Metastore plugin installation summary
Figure 276. Hive Metastore plugin installation summary -
If you have existing nodes you can induct them now. If you would rather induct them later, click Skip Induction.
Figure 277. Node Induction
14.3. Installing on a Kerberized cluster
The Installer lets you configure WD Fusion to use your platform’s Kerberos implementation. You can find supporting information about how WD Fusion handles Kerberos in the Admin Guide, see Setting up Kerberos.
14.3.1. Configuring Kerberos principals for Hive Metastore plugin
You need to configure kerberos principals for the wd-hive-metastore and hive fusion plugin to use. All these steps need to be carried out with reference to the host where the wd-hive-metastore and fusion services are running.
For reference
See Cloudera’s documentation on
Create and Deploy the Kerberos Principals and Keytab Files.
14.3.2. Kerberos Procedure
-
Replace
fusion-server.wandisco.comwith the actual FQDN name for your wd-hive-metastore host. -
Log in to
kadmin.localorkadminon the host machine running wd-hive-metastore. -
In kadmin use:
addprinc -randkey hive/fusion-server.wandisco.com@WANDISCO.HADOOP
-
In kadmin use:
addprinc -randkey HTTP/fusion-server.wandisco.com@WANDISCO.HADOOP
-
In kadmin use:
xst -k hive.service.keytab hive/fusion-server.wandisco.com@WANDISCO.HADOOP HTTP/fusion-server.wandisco.com@WANDISCO.HADOOP
-
Exit kadmin.
-
Check the keytab has the correct entries by using.
klist -e -k -t hive.service.keytab
-
Use:
sudo mv hive.service.keytab /etc/security/keytabs/
-
Make sure the keytab is readable by the hive user by using.
sudo chown hive:hadoop /etc/wandisco/hive.service.keytab sudo chmod +r /etc/wandisco/hive.service.keytab
-
And then add:
<property> <name>hive.metastore.kerberos.keytab.file</name> <value>/etc/security/keytabs/hive.service.keytab</value> </property> -
Now restart Fusion server using service fusion-server restart.
-
Restart the wd-hive-metastore service via CM.
-
Restart the hiveServer2 service via CM.
-
Reconnect to beeline again. Remember you need to perform a kinit before starting beeline using that nodes keytab and hive principal. You may also need to make a change to the
hive-site.xml:<property> <name>hive.metastore.kerberos.keytab.file</name> <value>hive.service.keytab</value> </property>to
<property> <name>hive.metastore.kerberos.keytab.file</name> <value>/etc/wandisco/hive/hive.servce.keytab</value> </property>All connections using beeline should use the same connection string regardless of the node that is being used - always use your hiveserver2 host’s FQDN, e.g.:
!connect jdbc:hive2://your.server.url:10000/default;principal=hive/principle.server.com@WANDISCO.HADOOP
even if connecting on the principle server itself.
14.3.3. Secure Impersonation
Normally the Hive user has superuser permissions on the hiveserver2 and
hive metastore nodes. If you are installing into a different nodes,
corresponding proxyuser parameters should also be updated in
core-site.xml and kms-site.xml
Set up a proxy user on the NameNode, adding the following properties to
core-site.xml on the applicable NameNode(s).
<property>
<name>hadoop.proxyuser.$USERNAME.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.$USERNAME.groups</name>
<value>*</value>
</property>
- hadoop.proxyuser.$USERNAME.hosts
-
Defines hosts from which client can be impersonated. $USERNAME, the superuser who wants to act as a proxy to the other users, is usually set as system user “hdfs”. These values are captured by the installer, which can apply these values automatically.
- hadoop.proxyuser.$USERNAME.groups
-
A list of groups whose users the superuser is allowed to act as proxy. Including a wildcard (*), which will mean that proxies of any users are allowed. For example, for the superuser to act as proxy to another user, the proxy actions must be completed on one of the hosts that are listed, and the user must be included in the list of groups. Note that this can be a comma separated list or the noted wildcard (*).
14.4. Impala configuration change
When running Impala/Hive with Fusion, you must make the following configuration changed. If you don’t make these changes, the wrong host and port information will be associated with our replacement front-end service.
You must add the hive.metastore.uris property to the following Hive Advanced snippets (one for catalog server, one for Daemons) in Impala in order to override the uris setting incorrectly pushed by Ambari from the metastore.port parameter.
- Catalog Server Hive Advanced Configuration Snippet (Safety Valve)
-
The Hive Metastore uris hostname and port (9084 is our default)
e.g.
<property> <name>hive.metastore.uris</name> <value>thrift://an-example-host.supp:9084</value> </property>
- Impala Daemon Hive Advanced Configuration Snippet (Safety Valve)
-
The Hive Metastore uris hostname and port (9084 is our default).
e.g.
<property> <name>hive.metastore.uris</name> <value>thrift://an-example-host.supp:9084</value> </property>
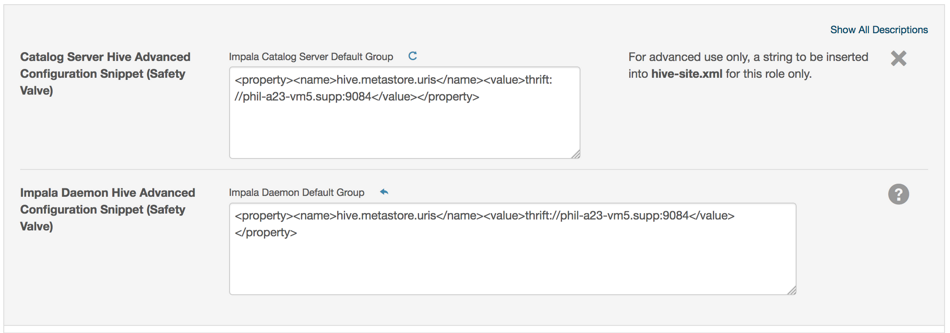 Figure 278. Advanced snippet changes
Figure 278. Advanced snippet changes
14.5. High Availability with Hive
It’s possible to set up High Availability by enabling multiple WD Fusion nodes to connect to the Hive Metastore. For a basic setup, use the following procedure:
14.5.1. Install on your first node
Follow the instructions for a regular Fusion-Hive installation provided in the installation guide - 2. Installation
14.5.2. Install on your second node:
-
Select Add to existing zone (give the address of the first WD Fusion node).
-
Continue with the installation as you did on your first WD Fusion node until you reach the Hive setup screens.
-
On the first Hive screen, add the address of the Metastore server associated with your first Fusion node (this will require changing the default) and clicking update.
-
Proceed to the next screen.
-
Skip the next screen as the Fusion-Hive stacks / parcels are already installed.
-
Transfer /etc/wandisco/fusion/server/hive-site.xml from your first Fusion node to /etc/wandisco/fusion/server/hive-site.xml on this node.
-
Click the Install button to launch the installation process.
-
When prompted, proceed to the end of the UI installer.
14.6. Hive Plugin Technical Glossary
14.6.1. Hive
Hive is a Hadoop-specific data warehouse component. It provides facilities to abstract a structured representation of data in Hadoop’s file system. This structure is presented as databases containing tables that are split into partitions. Hive can prescribe structure onto existing Hadoop data, or it can be used to create and manage that data.
It uses an architecture that includes a "metastore", which provides the interface for accessing all metadata for Hive tables and partitions. The metastore is the component that persists the structure information of the various tables and partitions in the warehouse, including column and column type information, the serializers and deserializers necessary to read and write data and the location of any corresponding Hadoop files where the data is stored.
Hive offers a range of options for the deployment of a metastore:
As a metastore database:
-
Local/embedded metastore database (Derby)
-
Remote metastore database
As a metastore server:
-
Local/embedded metastore server
-
Remote metastore server
In remote mode, the metastore server is a Thrift service. In embedded mode, the Hive client connects directly to the underlying database using JDBC. Embedded mode supports only a single client session, so is not used normally for multi-user product environments.
WANdisco’s implementation of a replicated Hive metastore supports deployments that use a remote metastore server. As tools exist that use interfaces to the metastore other than the thrift interface, the implementation does not just proxy that interface.
14.6.2. WANdisco Hive Metastore
The WANdisco Hive Metastore can act as a replacement or complement for the standard Hive Metastore, and provides two components:
-
A plugin for Fusion that allows for the coordination of Hive Metastore activities, and a replacement Hive Metastore implementation that delegates the coordination of activities to the plugin in order that they can be performed in a consistent manner across multiple deployments of the Metastore.
-
A replacement Hive Metastore implementation that delegates the coordination of activities to the plugin in order that they can be performed in a consistent manner across multiple deployments of the Metastore.
The resulting system ensures that Hive metadata can be made consistent across multiple Hadoop clusters, and by performing that coordination in conjunction with actions performed against the Hadoop file system, also ensures that this consistency applies to Hive-resident metadata and any corresponding files where Hive table/partition data is stored.
The following diagram provides a simplified view of how WANdisco’s Hive Metastore plugin interfaces between your Hive deployment and WD Fusion.
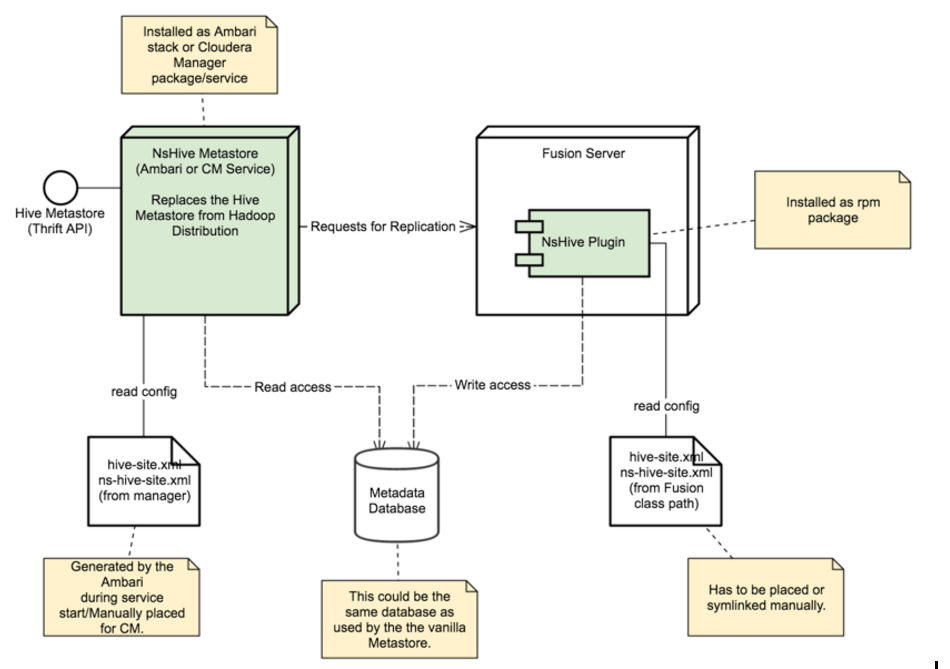
The WANdisco Hive Metastore (NsHive Metastore in the diagram above) can replace the standard Hive Metastore from the Hadoop distribution, or run alongside that Metastore. It provides all the functionality of the standard Hive Metastore, but adds interaction with WANdisco Fusion when coordination and replication is required (i.e. for activities that result in writes against the metadata database used by Hive). Different versions of the Hive Metastore are supported.
Hive Metastore replication in a nutshell
-
WANdisco runs its own Metastore server instance that replaces the default server.
-
WANdisco only replicates write operation against the metastore database.
-
The WD Hive Metastore Plugin sends proposals into the WD Fusion core.
-
WD Fusion uses the Hive Metastore plugin to communicate, directly with the metastore database.
14.6.3. Overview of Release
The WANdisco Hive Metastore provides functionality for the replication of Hive metadata and underlying table data as a plugin.
This section of the user guide describes the plugin’s functionality, behaviour and user experience.
Core Use Case
The functionality will address the core use case of interacting with Hive as a data warehouse technology in environments where active-active replication of Hive information is required, including underlying table data. Changes made to Hive metadata and data are replicated between multiple participating Hadoop clusters.
Restrictions
All files that hold the data for a given Hive table need to exist under a single root directory that can be replicated using Fusion. This is because there is a need for a single Deterministic State Machine (DSM) to coordinate the activities of metadata changes with underlying table/partition content.
This limitation may be removed if/when Fusion adds the ability to coordinate multiple otherwise independent DSMs.
Replacement of Metastore implementation
In order to coordinate all actions across multiple Metastore servers, the current solution replaces each standard Metastore server with a minimally-modified version of it, as provided by WANdisco. If selected portions of Hive metadata require replication, the WANdisco Hive Metastore can operate in addition to the standard Metastore server.
14.6.4. Metastore Version
The Hive Metastore differs in implementation across versions. The WANdisco Hive Metastore provides versions to match Hive 0.13, 0.14, 1.1.0 and 1.2.1.
The Metastore version used by all participating replicated instances must match. Future versions of the Replicated Hive Metastore may allow replication between different versions of Hive.
Functionality Not Addressed
The following functionality does not exist in the 1.0 release of the WANdisco Hive Metastore:
-
Hive transactions are not supported.
-
Hive SQL Standard Based Authorization (which provides column-level access control granularity) is not supported, because this mode requires that HiveServer2 runs an embedded metastore.
-
Replication between different versions of Hive not supported (some combinations might work, but will need to be specifically tested).
-
Table directories have to be under the database directory (or at least in the same replicated directory as the database).
-
Limitations related to known Hive issues:
-
HIVE-2573: Create Function is not replicated
-
HIVE-10719: Alter rename table does not rename the table
-
14.6.5. Core Functionality Provided
Metadata Replication
Changes made to Hive metadata are replicated between multiple participating Hadoop clusters, by coordinating all write operations that will affect the metastore database, and ensuring that these operations are performed in a consistent manner across all WANdisco Hive Metastore instances within a Fusion membership.
14.7. Consistency Check and Repair
WD Fusion has a dedicated tool for checking for inconsistencies between the hive metastore data between all zones for any given replicated folder/location that maps to a database or table within the hive metastore.
The Hive Metastore Consistency Check features as a tab on the Replicated Rule screen for directories that contain Hive Metastore data.
The functionality of consistency check and repair provides the means to:
-
Check for inconsistencies between the hive metastore data across all zones for any given replicated folder/location that maps to a database or table within the hive metastore.
-
Identify which metastore data is inconsistent i.e which tables are missing from a database or which columns are different/missing in a table.
-
Allow the user to select a zone as the source of truth and then repair the metastore data based on that version of the metastore data.
Assumptions made for the operation of this feature include:
-
This feature will only cover checking and repairing the hive metastore data and not any inconsistencies in the data within the replicated folder. This will be the responsibility of the Fusion Server.
Key facilities of this feature are:
-
Provide the ability to request and return the current version of the database metadata for a particular location/replicated folder from each node within the membership of the supplied replicated folder / location.
-
Provide the ability to compare the current database metadata of all the nodes/zones and to create a list of inconsistencies, if any. This list of inconsistencies will need to be displayed to the user in the same way as inconsistencies in the files / sub folders of a replicated folder are currently displayed.
-
Provide the ability to accept a "source of truth" for each inconsistency and the ability to propose to change the data on all other nodes to match this "source of truth". Provide support for "bulk" proposals so that all inconsistencies can be repair via a single proposal if they share the same "source of truth".
Provide the ability to manage the CC&R process. This could be replaced by functionality in the Fusion Plugin ADK at a future date.
14.7.1. Example Consistency Check and Repair
-
On the Hive Consistency tab, click into a Hive meta store data directory. Click on Consistency Check All.
 Figure 281. Hive Metastore Consistency - Choose context
Figure 281. Hive Metastore Consistency - Choose context -
Check for inconsistencies in the context window. Select each element in term.
 Figure 282. Hive Metastore Consistency - review consistency states
Figure 282. Hive Metastore Consistency - review consistency statesThe Detailed view provides a description of any inconsistencies, for example calling out if the chosen context is only present on one cluster.
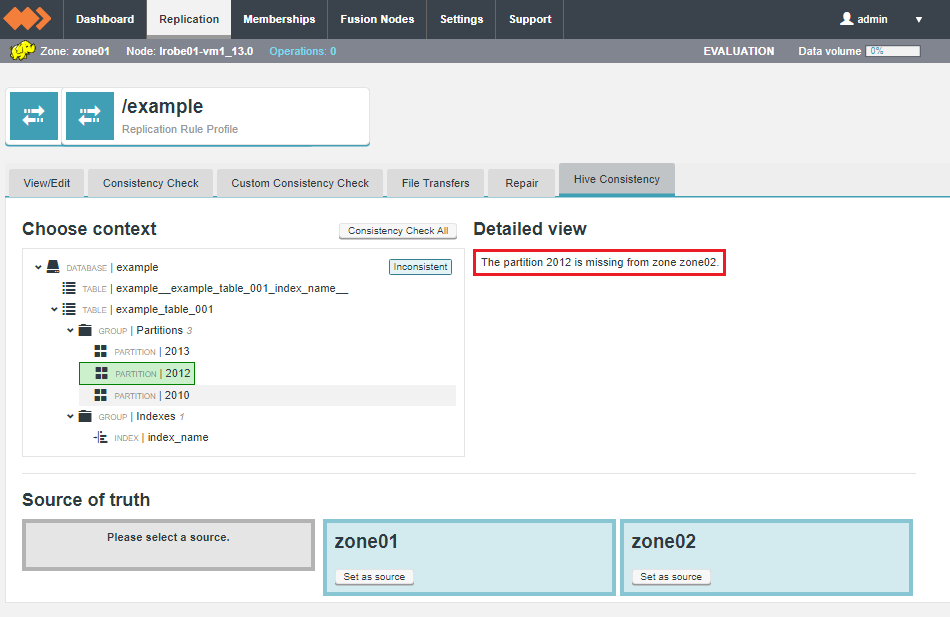 Figure 283. Hive Metastore Consistency - Detailed view
Figure 283. Hive Metastore Consistency - Detailed view -
For each contents you can run through the Source of truth, choosing which cluster contains the correct state.
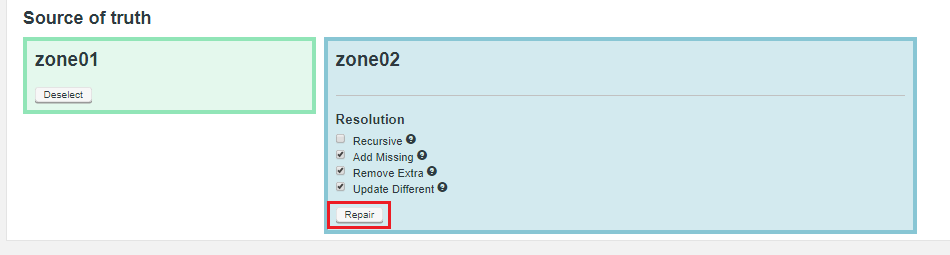 Figure 284. Hive Metastore Consistency - Repair
Figure 284. Hive Metastore Consistency - RepairOnce a Zone is selected, you can make a repair to make the chosen data consistent across the zones. The following options are available:
- Recursive
-
When selected, the repair works through the metadata hierarchy (Database/Table/Group/Partition, etc) fixing inconsistencies all the way through. If left unticked then the repair will not apply only at the selected context, no deeper.
- Add Missing
-
When selected, the repair will replicate any metadata artefacts found at the Source of truth onto the other zones.
- Remove Extra
-
When selected, the repair will remove metadata artefacts from the other zones, if they do not appear on the Source of truth zone. If unticked, such elements will not be touched during a repair.
- Update Different
-
When selected, the repair will update all metadata objects on the other zones that differ from the source of truth. It will not touch any objects that only exist on one side of the repair.
Note that these options differ from those offered on the main Repair tool. These options apply only to metadata, while Fusions main repair tool applies to the files themselves.
Click Repair to start the repair process.
-
Once you start a repair the process will run automatically until complete.
 Figure 285. Hive Metastore Consistency - Repair triggered
Figure 285. Hive Metastore Consistency - Repair triggeredAfter completing a consistency repair, consider rerunning a consistency check to verify that everything was fixed as expected.
14.8. Testing Hive Metastore Replication
Here are some examples for testing basic functionality of the WAN Hive Metastore. They cover connection, creation of a replicated database, population of temporary table data, populating partitions of a table, creating inconsistent data to test consistency check and repair functionality.
14.8.1. How to start beeline and connect to Hive
You can use the hdfs user to prevent any permission issues:
-
As the hdfs user start beeline on the master node -
beeline
-
Connect to the hive metastore using the following command -
!connect jdbc:hive2://hiveserver2_host:10000 hdfs
-
You don’t need a password here, so press enter.
14.8.2. How to create a replicated database within Hive
-
Using the hdfs user create a new hdfs folder on both clusters as a home for your test databases.
hdfs dfs -mkdir -p /hive/databases
-
Within the Fusion UI create a new replicated folder for /hive/databases.
-
Start beeline and connect as above.
-
To create your new test database enter the following command.
CREATE DATABASE test_01 LOCATION '/hive/databases/test_01';
where test_01 is the database name you want to use.
-
To check the database has been created and replicated you will need to connect to beeline on the master node of the other cluster using the instructions above, making sure to use the correct hiveserver2_host for that cluster. Then on both clusters use: SHOW DATABASES; This should display the default database and the new database you just created.
14.8.3. How to create and populate the temporary table
-
This example assumes that you have a test data file containing a single string per line, placed in
/usr/local/share/installers/Batting.csv.
-
Start beeline and connect as above if you are not already connected.
-
Set the test database you want to use for this test data.
USE test_01;
-
Create the temporary table for the batting data
create table temp_batting (col_value STRING);
-
Now load the test data into the temp_batting table:
LOAD DATA LOCAL INPATH '/usr/local/share/installers/Batting.csv' OVERWRITE INTO TABLE temp_batting;
This should replicate to the data to the second cluster for you. You need to replace the location of the uploaded Batting.csv file.
-
To see the loaded data you can use
SELECT * FROM temp_batting LIMIT 100;
14.9. How to create and populate a table with partitions with data from the
above temp_batting table
-
Start beeline and connect as above if you are not already connected.
-
Set the test database you want to use for this test table using
USE test_01;
-
Create the new empty table partitioned by year
create table batting (player_id STRING,runs INT) PARTITIONED BY(year INT);
-
Now load the new table with data from the temp_batting table by
insert overwrite table batting PARTITION(year) SELECT regexp_extract(col_value, '^(?:([^,]*),?){1}', 1) player_id, regexp_extract(col_value, '^(?:([^,]*),?){9}', 1) run, regexp_extract(col_value, '^(?:([^,]*),?){2}', 1) year from temp_batting; -
The above step may take a little while because it has to create a mapreduce job to process the data.
-
To see that the table has been populated with data run
SELECT * FROM batting WHERE year='2000' LIMIT 100;
14.9.1. How to create inconsistent or missing data for testing CC and repair
-
Create a new folder in HDFS for the location of your database on both clusters.
hdfs dfs -mkdir /testing
Warning
Do not add this folder to Fusion as a replicated folder. -
On one of the clusters connect to beeline and create your test database.
CREATE DATABASE testing_01 LOCATION '/testing/testing_01';
-
Select this new database
USE testing_01;
-
Create a table within this database
create table temp_batting (col_value STRING);
-
Now load the test data into the temp_batting table
LOAD DATA LOCAL INPATH '/usr/local/share/installers/Batting.csv' OVERWRITE INTO TABLE temp_batting;
You need to replace the location of the Batting.csv file.
-
Create the new empty table
create table batting (player_id STRING,runs INT, year INT);
-
Now load the new table with data from the temp_batting table
insert overwrite table batting SELECT regexp_extract(col_value, '^(?:([^,]*),?){1}', 1) player_id, regexp_extract(col_value, '^(?:([^,]*),?){9}', 1) run, regexp_extract(col_value, '^(?:([^,]*),?){2}', 1) year from temp_batting; -
Now add the '/testing' folder to Fusion as a replicated folder with the same membership of the two zones you created earlier.
-
Both the HDFS and the hive metastore data will be inconsistent so you will be able to test consistency check and repair functionality.
-
To create inconsistent data you will need to create the database and tables with whatever changes you want to make them inconsistent before adding the location of the database to Fusion.
14.10. Hive Database cache
When deployed with large numbers of Hive databases, it’s possible that the the Fusion UI can become unresponsive. From Fusion 2.10.3 there’s a reload delay set to 30 seconds, which militates against UI performance problems. This delay period is editable:
JAVA_OPTS='-Dwd.hive.database.reload.delay=30'
The delay is set in the Java options.
This is a delay so the next reload will start the required number of seconds after the previous reload has finished. So if the reload take 9 seconds and you set the delay to 10 seconds then it will appear to reload every 19 seconds.
|
Where’s the new database?
New databases will not appear in the WD Fusion UI until the cache has reloaded, so the default could be lowered for smaller installations.
|
14.11. Removing the Hive Plugin from deployment
How you remove the Hive plugin from your cluster depends on which platform you are using. Please follow the appropriate procedure.
14.11.1. Removing Hive WD Plugin - Ambari
To remove the Hive plugin when using Ambari follow the instructions below.
Removing the plugin through the UI
These screenshots are taken using HDP2.5/Ambari2.4.1.0, there might be some slight differences if you are using a different version.
-
Click on Services, then Hive. Next go to the Configs tab and then Advanced.
 Hive advanced config
Hive advanced config -
Scroll down until you come to the Custom hive-site section. Change the properties
fs.file.impl.disable.cacheandfs.hdfs.impl.disable.cachefrom false to true.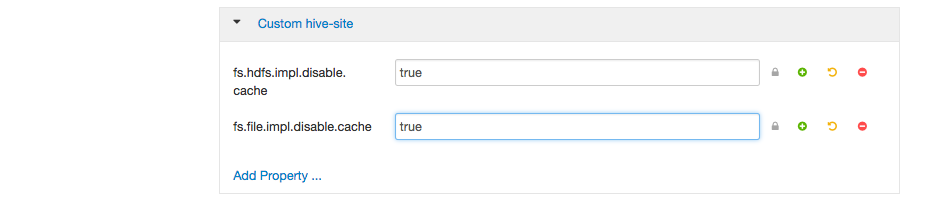
Alternatively, you can search for these properties using the filter.
-
Scroll back up to the section General. Change the property
hive.metastore.uristo its original value. You need to updatehive.metastore.urisfrom pointing to the wd-hive-metastore to the appropriate hive metastore (whichever node you installed it on).
Then, using the filter, find all other instances ofhive.metastore.urisand remove them, only the one in General should remain.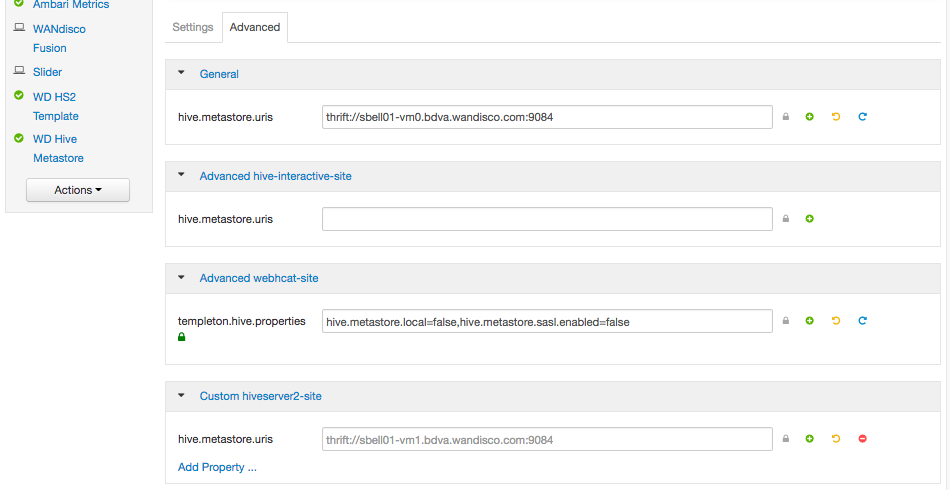
-
Now save these changes.
And confirm changes.
-
Click on Services, then WD HS2 Template. Next go to the Configs tab and then Advanced.
-
Scroll down to the Custom wd-hiveserver2-config section and add a new property.

This property needs to be added in Bulk property add mode and should be called
wd.hiveserver2.template.revert=true.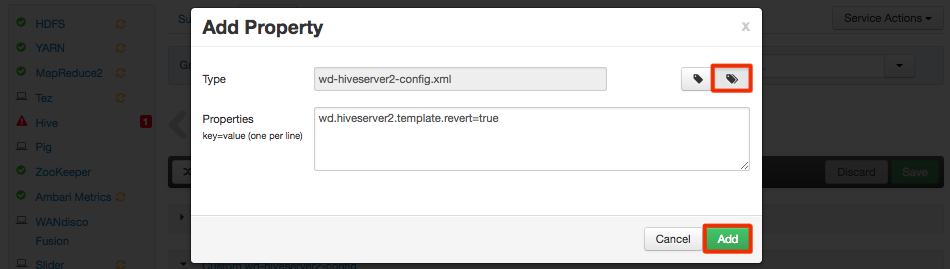
-
Again, save your changes.
-
Next, you need to stop the base Hive metastore. To do this go to the Ambari homepage, then click Services and Hive. On the Summary page click on Hive Metastore.

Now Stop all Components from the Host Actions drop down.
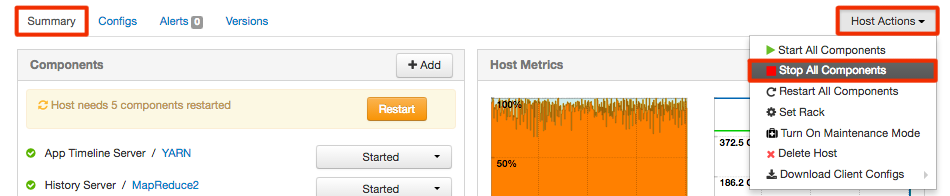
-
Restart services to deploy changes.
-
Restart the WD Hive server2 (HS2) Template by, in the Services list, clicking on WD HS2 Template, and then Restart from the Service Actions drop down list.
-
Also restart Hiveserver2 from the Summary tab.

-
WD Hive components should now be stopped. Removal can now occur from the Ambari API.
Removing the plugin using terminal
These commands are correct for HDP 2.5.3.0 with Ambari 2.4.1.0., and HDP 2.6.0.3 with Ambari 2.5.0.3. If you are using a different version then they may differ slightly.
In the commands below you will need to replace the following:
-
login:password- your details to log in to the Ambari UI -
AMBARI_SERVER_HOST- the host url -
<cluster-name>- cluster name e.g. SBELL-01-
Run the following curl command to show existing services
curl -v -u login:password -X GET http://$HOSTNAME:8080/api/v1/clusters/$DC_NAME/services
-
Stop the WD Hive Metastore
curl -u login:password -H "X-Requested-By: ambari" -X PUT -d '{"RequestInfo":{"context":"Stop Service"},"Body":{"ServiceInfo":{"state":"INSTALLED"}}}' http://AMBARI_SERVER_HOST:8080/api/v1/clusters/<cluster-name>/services/WD_HIVE_METASTORE -
Stop the WD Hiveserver2 template
curl -u login:password -H "X-Requested-By: ambari" -X PUT -d '{"RequestInfo":{"context":"Stop Service"},"Body":{"ServiceInfo":{"state":"INSTALLED"}}}' http://AMBARI_SERVER_HOST:8080/api/v1/clusters/<cluster-name>/services/WD_HIVESERVER2_TEMPLATE -
Remove the WD Metastore - MUST BE REMOVED HERE - HIVESERVER2 Template depends on the metastore
curl -v -u login:password -H "X-Requested-By: ambari" -X DELETE http://AMBARI_SERVER_HOST:8080/api/v1/clusters/<cluster-name>/services/WD_HIVE_METASTORE
-
Remove the Hiveserver2 Template
curl -u login:password -H "X-Requested-By: ambari" -X DELETE http://AMBARI_SERVER_HOST:8080/api/v1/clusters/<cluster-name>/services/WD_HIVESERVER2_TEMPLATE
-
Now go to the Ambari UI. When you refresh it, the WD Hive services should have gone.
-
Now go to terminal on the node on which WD Hive Metastore was installed. To find the correct package name, use the command:
rpm -qa 'wd-hive-metastore*'
This will return e.g.
wd-hive-metastore-hdp-2.6.0-2.10.3-738.noarch
Then run the following command, using your specific package name:rpm -e wd-hive-metastore-hdp-2.6.0-2.10.3-738.noarch
This should return the message
WANdisco Hive Metastore uninstalled successfully -
Now remove the Metastore plugin from the Fusion Nodes.
To find the correct package name, use the command:rpm -qa 'wd-hive-plugin*'
This will return e.g.
wd-hive-plugin-ibm-4.1-2.9.3-595.noarch
Then run the following command, using your specific package name:rpm -e wd-hive-plugin-ibm-4.1-2.9.3-595.noarch
This should return the message
WANdisco Hive Metastore Plugin uninstalled successfully -
All other Fusion server, IHC, UI and Client removal steps are now valid. These can be found here.
-
14.11.2. Removing Hive WD Plugin - Cloudera
To remove the Hive plugin when using Cloudera follow the instructions below.
Removing the plugin through the UI
-
Click on hive1 from the Cloudera homepage.
-
Then, on the Configuration tab, click on Advanced in the Categories section.
-
Scroll down to Hive Service Advanced Configuration Snippet (Safety Valve) for hive-site.xml.
Change the propertyhive.metastore.uristo its original value. You need to updatehive.metastore.urisfrom pointing to the wd-hive-metastore to the appropriate hive metastore (whichever node the you installed it on).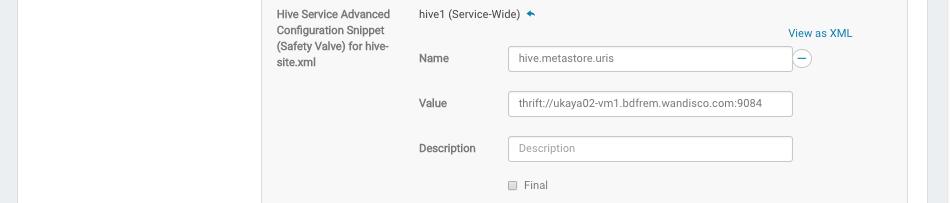
Then save changes.

-
Next, stop the WD Hive Metastore.
From the homepage click on WD Hive Metastore. Then select Stop from the Actions dropdown list.
Confirm you want to stop the WD Hive Metastore.
-
Now click on the Parcels icon.
-
Scroll down to WD_HIVE_METASTORE and click Deactivate.

-
On the pop out, change to Deactivate only.
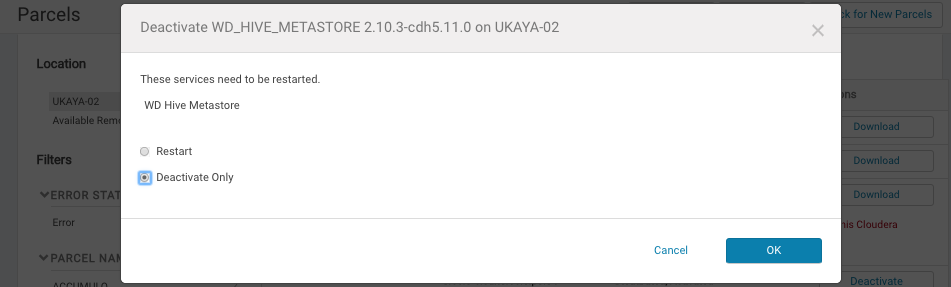
-
Now click Remove From Hosts.

Confirm the removal.
-
Return to the Cloudera homepage and click on WD Hive Metastore. Then click on the Instances tab.
On this page check the WD Hive Metastore Service box.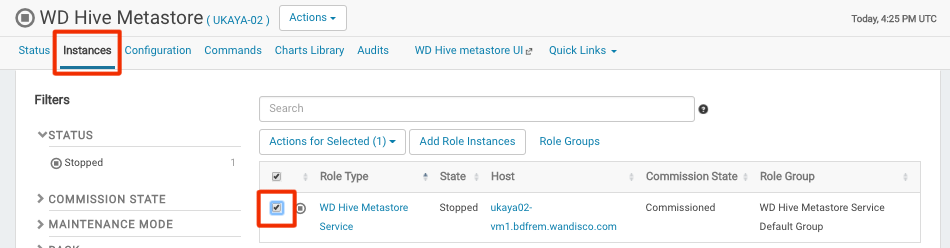
-
Delete the service from the Actions for Selected dropdown list.
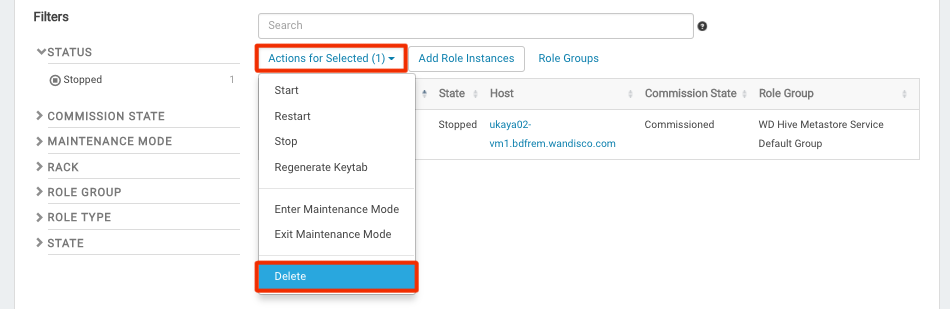
-
On the Cloudera homepage, click on the dropdown list next to WD Hive Metastore. Click Delete.
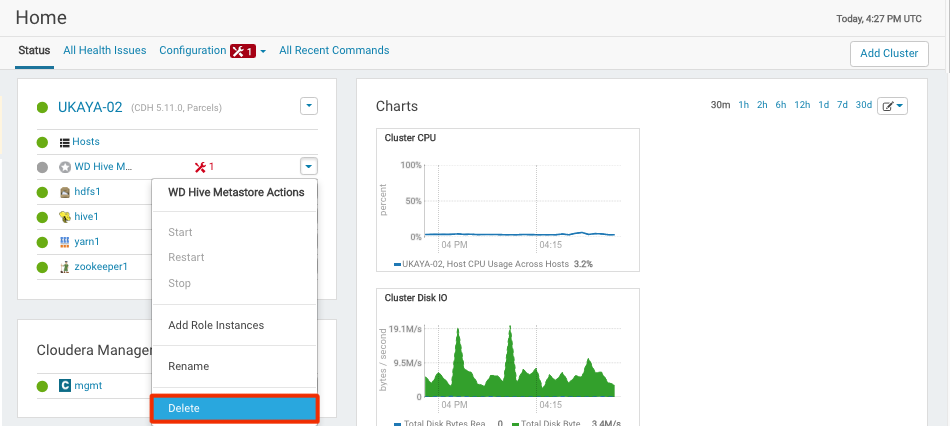
15. Reference Guide
The reference guide contains a number of technical articles and primers that will give you an understanding of the basics and some of the inner workings of WD Fusion’s replication system. There’s also a walk-through of the screens available in WD Fusion’s UI. For specific instruction on how to perform a particular task, you should instead view the Admin Guide.
15.1. What is WANdisco Fusion
WANdisco Fusion (WD Fusion) shares data between two or more clusters. Shared data is replicated between clusters using DConE, WANdisco’s proprietary coordination engine. This isn’t a spin on mirroring data, every cluster can write into the shared data directories and the resulting changes are coordinated in real-time between clusters.
15.2. 100% Reliability
Paxos-based algorithms enable DConE to continue to replicate even after brief networks outages, data changes will automatically catch up once connectivity between clusters is restored.
Below the coordination stream, actual data transfer is done as an asynchronous background process and doesn’t consume MapReduce resources.
15.3. Replication where and when you need
WD Fusion supports Selective replication, where you control which data is replicated to particular clusters, based on your security or data management policies. Data can be replicated globally if data is available to every cluster or just one cluster.
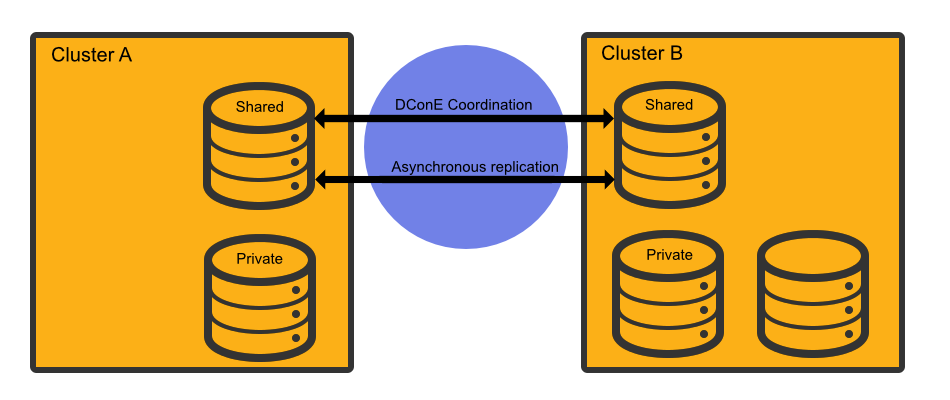
15.4. The Benefits of WANdisco Fusion
-
Ingest data to any cluster, sharing it quickly and reliably with other clusters. Removing fragile data transfer bottlenecks, and letting you process data at multiple places improving performance and getting you more utilization from backup clusters.
-
Support a bimodal or multimodal architecture to enable innovation without jeopardizing SLAs. Perform different stages of the processing pipeline on the best cluster. Need a dedicated high-memory cluster for in-memory analytics? Or want to take advantage of an elastic scale-out on a cheaper cloud environment? Got a legacy application that’s locked to a specific version of Hadoop? WANdisco Fusion has the connections to make it happen. And unlike batch data transfer tools, WANdisco Fusion provides fully consistent data that can be read and written from any site.
-
Put away the emergency pager. If you lose data on one cluster, or even an entire cluster, WANdisco Fusion has made sure that you have consistent copies of the data at other locations.
-
Set up security tiers to isolate sensitive data on secure clusters, or keep data local to its country of origin.
-
Perform risk-free migrations. Stand up a new cluster and seamlessly share data using WANdisco Fusion. Then migrate applications and users at your leisure, and retire the old cluster whenever you’re ready.
15.5. Fusion Architecture
15.5.1. WD Fusion Example Workflow
The following diagram presents a simplified workflow for WD Fusion, which illustrates a basic use case and points to how WANdisco’s distributed coordination engine (DConE) is implemented to overcome the challenges of coordination.
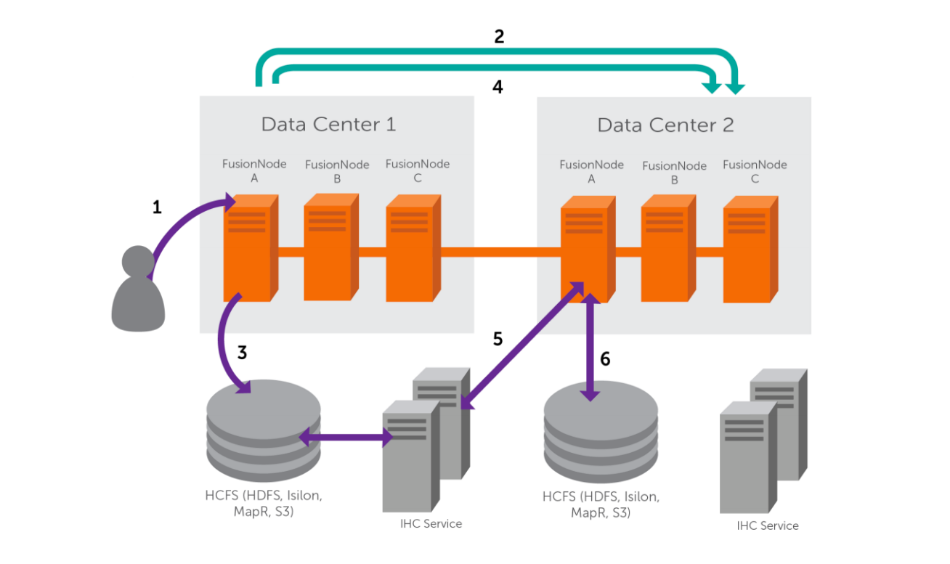
-
User makes a request to create or change a file on the cluster.
-
WD Fusion coordinates File Open to the external cluster.
-
File is added to underlying storage.
-
WD Fusion coordinates at configurable write increments and File Close with other clusters (see membership).
-
WD Fusion server at remote cluster pulls data from IHC server on source cluster.
-
WD Fusion server at remote site writes data to its local cluster.
15.6. A Primer on Paxos
Replication networks are composed of a number of nodes, each node takes on one of a number of roles:
15.6.1. Acceptors (A)
The Acceptors act as the gatekeepers for state change and are collected into groups called Quorums. For any proposal to be accepted, it must be sent to a Quorum of Acceptors. Any proposal received from an Acceptor node will be ignored unless it is received from each Acceptor in the Quorum.
15.6.2. Proposers (P)
Proposer nodes are responsible for proposing changes, via client requests, and aims to receive agreement from a majority of Acceptors.
15.6.3. Learners (L)
Learners handle the actual work of replication. Once a Client request has been agreed on by a Quorum the Learner may take the action, such as executing a request and sending a response to the client. Adding more learner nodes will improve availability for the processing.
15.6.4. Distinguished Node
It’s common for a Quorum to be a majority of participating Acceptors. However, if there’s an even number of nodes within a Quorum this introduces a problem: the possibility that a vote may tie. To handle this scenario a special type of Acceptor is available, called a Distinguished Node. This machine gets a slightly larger vote so that it can break 50/50 ties.
15.7. Paxos Node Roles in DConE
When setting up your WD Fusion servers they’ll all be Acceptors, Proposers and Learners. In a future version of the product you’ll then be able to modify each WD Fusion server’s role to balance between resilience and performance, or to remove any risk of a tied vote.
15.8. Creating resilient Memberships
WD Fusion is able to maintain HDFS replication even after the loss of WD Fusion nodes from a cluster. However, there are some configuration rules that are worth considering:
15.8.1. Rule 1: Understand Learners and Acceptors
The unique Active-Active replication technology used by WD Fusion is an evolution of the Paxos algorithm, as such we use some Paxos concepts which are useful to understand:
-
Learners:
Learners are the WD Fusion nodes that are involved in the actual replication of Namespace data. When changes are made to HDFS metadata these nodes raise a proposal for the changes to be made on all the other copies of the filesystem space on the other data centers running WD Fusion within the membership.
Learner nodes are required for the actual storage and replication of hdfs data. You need a learner node where ever you need to store a copy of the shared hdfs data.
-
Acceptors:
All changes being made in the replicated space at each data center must be made in exactly the same order. This is a crucial requirement for maintaining synchronization. Acceptors are nodes that take part in the vote for the order in which proposals are played out.
Acceptor Nodes are required for keeping replication going. You need enough Acceptors to ensure that agreement over proposal ordering can always be met, even after accounting for possible node loss. For configurations where there are a an even number of Acceptors it is possible that voting could become tied. For this reason it is possible to make an Acceptor node into a tie-breaker which has slightly more voting power so that it can outvote another single Acceptor node.
15.8.2. Rule 2: Replication groups should have a minimum membership of three learner nodes
Two-node clusters (running two WD Fusion servers) are not fault tolerant, you should strive to replicate according to the following guideline:
-
The number of learner nodes required to survive population loss of N nodes = 2N+1
where N is your number of nodes.So in order to survive the loss of a single WD Fusion server equipped datacenter you need to have a minimum of 2x1+1= 3 nodes
In order to keep on replicating after losing a second node you need 5 nodes.
15.8.3. Rule 3: Learner Population - resilience vs rightness
-
During the installation of each of your nodes you may configure the Content Node Count number, this is the number of other learner nodes in the replication group that need to receive the content for a proposal before the proposal can be submitted for agreement.
Setting this number to 1 ensures that replication won’t halt if some nodes are behind and have not received replicated content yet. This strategy reduces the chance that a temporary outage or heavily loaded node will stop replication, however, it also increases the risk that namenode data will go out of sync (requiring admin-intervention) in the event of an outage.
15.8.4. Rule 4: 2 nodes per site provides resilience and performance benefits
Running with two nodes per site provides two important advantages.
-
Firstly it provides every site with a local hot-backup of the namenode data.
-
Enables a site to load-balance namenode access between the nodes which can improve performance during times of heavy usage.
-
Providing the nodes are Acceptors, it increases the population of nodes that can form agreement and improves resilience for replication.
15.9. Replication Frequently Asked Questions
What stops a file replication between zones from failing if an operation such as a file name change is done on a file that is still transferring to another zone?
Operations, such as a rename only affects metadata, so long as the file’s underlying data isn’t changed, the operation to transfer the file will complete. Only then will the rename operation play out. When you start reading a file for the first time you acquire all the block locations necessary to fulfil the read, at this point metadata changes won’t halt the transfer of the file to another zone.
15.10. Agreement recovery in WD Fusion
This section explains why when monitoring replication recovery, it may be possible to see a brief delay and seemingly out-of-order delivery of proposals at the catching-up node.
In the event that the WAN link between clusters is temporarily dropped, it may be noticed that when the link returns, there’s a brief delay before the reconnected zones are back in sync and it may appear that recovery is happening with agreements being made out of order, in terms of the global sequence numbers (GSNs) associated with each agreement.
This behaviour can be explained as follows:
-
The "non-writer" nodes review the GSNs to determine which agreements the current writer has processed and which agreements they can remove from their own store, where they are kept in case the writer node fails and they have to take over.
-
When a new writer is elected, the presence/absence of a particular GSN tells the new writer which agreements can be skipped. There may be gaps in this sequence as not all proposals are filesystem operations. For example, writer and leader election proposals are not filesystem operations, therefore their GSNs are not written to the underlying filesystem.
15.10.1. Why are proposals seemingly being delivered out-of-order?
This is related and why you will see gsn’s written "out-of-order" in the filesystem. Internally within Fusion "non-interfering" agreements are processed in parallel so we can increase throughout and the global sequence is not blocked on operations that may take a long time, such as a large file copy.
15.10.2. Example
Consider the following global sequence, where /repl1 is the replicated directory:
1. Copy 10TB file to /repl1/dir1/file1
2. Copy 10TB file to /repl1/dir2/file1
3. Chown /repl/dir1
Agreements 1. and 2. may be executed in parallel since they do not interfere with one-another. However, agreement 3. must wait for agreement 1 to complete before it can be applied to the filesystem. If agreement 2 completes before 1 then its gsn will be recorded before the preceding agreement and look on the surface like out-of-order delivery of GSNs.
15.10.3. Under the hood
DConE’s Output Proposal Sequence (OPS) delivers agreed values in strict sequence, one-at-a-time, to an application. Applying these values to the application state in the sequence delivered by the OPS ensures the state is consistent with other replicas at that point in the sequence. However, an optimization can be made: if two or more values do not interfere with one another (see below for definition of 'interfere') they may be applied in parallel without adverse effects. This parallelization has several benefits, for example:
-
It may increase the rate of agreed values applied to the application state if there are many non-interfering agreements;
-
It avoids an agreement that takes a long time to complete (such as a large file transfer) from blocking later agreements that aren’t dependent on that agreement having completed.
16. WD Fusion Configuration
This section lists the available configuration for WD Fusion’s component applications. You should take care when making any configuration changes on your clusters.
16.1. WD Fusion Server
WD Fusion server configuration is stored in three files:
/etc/wandisco/fusion/server/application.properties
Property |
Description |
Permitted Values |
Default |
Checked at… |
|
Sets the name of the node. |
Valid node name |
NA |
Startup |
|
This is the hostname used in reporting the address. |
Valid hostname |
NA |
Startup |
|
The port DConE uses for communication |
1 – 65535 |
6444 |
Startup |
|
If set to true and the DConE system database was not shut down 'cleanly' (i.e., the prevaylers weren’t closed) then on restart the server will not start. |
true or false |
true |
Startup |
|
If set to true and the application integration database was not shut down 'cleanly' (i.e., the prevaylers weren’t closed) then on restart the server will not start. |
true or false |
true |
Startup |
|
Hostname used for binding opened ports for DConE, the requests and REST. While DConE has logic which will default the value to 0.0.0.0, WD Fusion does not set a default, so the property must be specified. |
A valid hostname or IP |
None - It must be specified |
Startup |
|
The zone where the Fusion server is located |
Any String |
None - It must be present |
Startup |
|
The directory DConE will use for persistence |
Any existing path |
None - It must be present |
Startup |
|
The number of threads executing agreements in parallel (since 2.10+ where repair.threads were introduced, this is total number of repair and agreement execution threads) |
1 – reasonable max number of threads as allowed per platform (taking into account other threads) |
25 (default was "20" prior to version 2.10) |
Startup |
|
Number of executor threads dedicated for repair only. These are the ones which will do the work for repairing and nothing else. |
1 - less then executor.threads |
5 |
Startup |
|
(slightly misleading name) Maximum number of outstanding files that a single repair will have scheduled for execution at any given time. If this limit is reached, it will wait for some to complete, before scheduling mode. This is a mechanism to allow multiple parallel repairs to zip together. E.g. if repair with 1000 files arrives and then another with 10, if the one with 1000 scheduled them all, the short 10file repair would have to wait. With this limit, only first 10 of 1000 are scheduled on rolling basis. So when the other repair arrives, it can schedule it’s 10 and they will start sharing the executors evenly. This should be set to value equal or a bit larger then repair.threads. |
1 - MAX_INTEGER |
10 |
Startup |
|
The decoupler the Fusion server will use. |
dcone, disruptor, simple |
disruptor |
Startup |
|
Determines the transfer protocol(s) to be supported by Fusion Server. |
HTTP_ONLY, HTTPS_ONLY, BOTH_HTTP_HTTPS |
HTTP_ONLY |
Startup |
|
The wait strategy to use when the disruptor is selected for fusion.decoupler. |
blocking, busy.spin, lite.blocking, sleeping, yielding |
yielding |
Startup |
|
The port the Fusion HTTP server will use. |
1 – 65535 |
8082 |
Startup |
|
The port Fusion clients will use. |
1 – 65535 |
8023 |
Startup |
|
The transport the Fusion server should use. |
EPOLL, NIO, OIO |
NIO |
Startup |
|
The size of the "chunks" used in a file transfer (in bytes). Used as input to Netty' ChunkedStream. |
1 – Integer.MAX_VALUE |
4096 |
When each pull is initiated |
|
Whether boxcars should be used. |
true or false |
false |
Startup |
|
The path to the license file. |
A valid path to a license key. |
/etc/wandisco/server/license.key |
On each periodic license check. |
|
The maximum number of times to retry an agreed request. |
1 – Integer.MAX_VALUE |
180 When executing an agreed request |
|
|
The port remote ihc servers should. connect to when the zone is Inbound. |
1 – Integer.MAX_VALUE |
8024 |
Startup |
|
The sleep time (milliseconds) in between retries of an agreed request. |
1 – Long.MAX_VALUE (notice the capital L, make sure to put this in) |
1000L |
When executing an agreed request. |
|
Whether Fusion Server - Fusion Server, Fusion Server - IHC Server, and Fusion Server - Fusion Client communications should all use SSL. (In 2.8 and beyond, this property ONLY enables Fusion Server - Fusion Server SSL.) |
true or false |
false |
Startup |
|
Alias of private key / certificate chain used to encrypt communications by server. |
alias of a keystore entry |
None - required if server-server or server-client SSL is enabled |
Startup |
|
Encrypted password of key entry |
Password encrypted using password-encryptor.sh |
None |
Startup |
|
Location of key store containing key entry |
Absolute path to key store. |
None - required if server-server or server-client SSL is enabled. |
Startup |
|
Encrypted password of key store |
Password encrypted using password-encryptor.sh |
None |
Startup |
|
Location of trust store used to validate certificates sent by other Fusion Servers or IHC servers |
Absolute path to trust store |
None - required if server-server or server-IHC SSL is enabled |
Startup |
|
Encrypted password of trust store |
Password encrypted using password-encryptor.sh |
None |
Startup |
|
If Fusion Server - IHC communications should use SSL (the Fusion-server part of config). |
true/false |
false |
|
|
15000 |
|||
|
Location of a directory in the replicated filesystem to which Fusion server will write information about replicated directories for clients to read. It should be non-replicated location, readable by all users and writable by Fusion user. + For it to work, there needs to be the same thing configured for client’s in their core-site.xml |
/etc/hadoop/conf/core-site.xml
|
fs. prefix removal Please take note that in WD Fusion 2.8 many of the properties in the following table have had the fs. prefix removed. The fs. is now used exclusively for filesystem specific properties. |
Property |
Description |
|
|
Enables authentication on the REST API |
|
|
Type of authentication used. |
"simple" (for simple authentication) or "kerberos" (for kerberos authentatication) |
|
If type is "simple", whether anonymous API calls are allowed. If set to false, users must append a query parameter at the end of their URL "user.name=$USER_NAME" |
|
|
If type is "kerberos", the principal the fusion server will use to log in with. The name of the principal must be "HTTP". |
'*' (Putting simply an asterisk will cause the filter to pick up any
principal found in the keytab that is of the form |
|
If type is "kerberos", the path to a keytab that contains the principal specified. |
|
|
Path to a readable secret file. File is used to authenticate cookies. |
|
|
A property targeted at FileSystems that do not support appends (e.g. S3, Azure). When set to the default "false" the Fusion server will ignore incoming HFlushRequests. The "fs." prefix has been removed as the property may not be specific to FileSystems in future. |
|
Property that sets the state of authorization. |
||
|
The read-writers config dictates which user is allowed to make write REST calls (e.g. DELETE, PATCH, POST, and PUT). Read-writers have both RW-permissions. |
|
|
Users who have read-only permission. They are unable to do all of the calls noted in the read.writers entry, above. |
|
|
The core filter reads a new local property which specifies proxy
principals - this is the remote user principal that the UI will
authenticate as. The value for the property should be set to the user
part of the UI kerberos credential, e.g. |
|
|
Enables or disables the ability for the client to bypass to underlying filesystem without waiting for a response from WD Fusion. |
|
|
If true, the Fusion client will coordinate open() operations (which is used when an application opens a file for read). See Fusion Client OpenRequests coordination |
|
|
Sets how long the client will wait for a response from Fusion for before bypassing to underlying. |
integer (seconds) |
|
Sets how long to keep bypassing for once a client has been forced to bypass for the first time. |
|
|
The directory path where backups will reside. Unless intended to replicate, ensure that this is a non-replicated directory so backup files only exist on this datacenter. |
|
|
The period of time that a client maintains the cache of Replicated Directories. After the period, the client will clear its cache, connect to a fusion-server, and build a new cache of Replicated Directories. |
|
|
This property enables administrators to handle user-mapping between
replicated folders. This consists off a comma-separated list of regex
rules. Each rule consists of a username (from an incoming request)
separated from a translated pattern by a "/". See
further explanation |
|
|
Location from which clients should try to read information about replicated directories, before contacting Fusion server. (FUS-3121) It’s necessary to configure the same in server’s application.properties, so that it generates the necessary data. |
hdfs://nn/shared/fusionDirExchange |
|
Metadata.cleanup Removes the metadata files generated during a repair. |
true or false |
16.2. Username Translations
16.2.1. Example
<property>
<name>fusion.username.translations</name>
<value>hdp-(.*)/cdh-$1,([A-Z]*)-([0-9]*)-user/usa-$2-$1</value>
</property>
In the data center where the fusion.username.translations property is
set, when a request comes in, it will check the username of the request
against each listed pattern, and if the username matches that pattern,
an attempt is made to translate using the listed value. If, during a
check, none of the rules are found to match, we default to the username
of the request, with no attempt to translate it.
Furthermore, the user translation will iterate over the list of translations and use the first match. Once a match is made, no further translation is attempted.
Looking at the example translation rules:
hdp-(.*)/cdh-$1,([A-Z]*)-([0-9]*)-user/usa-$2-$1
Notice here that we have two rules:
-
hdp-(.*)/cdh-$1
-
()-([0-9])-user/usa-$2-$1
To reiterate, we expect the following in the property:
-
Rules are comma separated.
-
Patterns and translations are separated by "/".
-
Patterns and translations don’t contain "/".
-
White spaces should be accounted for in code, but are discouraged.
|
"user" field inconsistencies are ignored
If any nodes that take part in a consistency check have the Username
Translation feature enabled, then inconsistencies in the "user" field
will be ignored.
|
For the above config example, assume a createRequest comes in with the following usernames:
Username: ROOT-1991-user
-
We will check against the first pattern, hdp-(.*), and notice it doesn’t match.
-
We will check against the second pattern, ()-([0-9])-user, and notice it matches.
-
Attempt to translate the username using usa-$2-$1.
-
Username is translated to usa-1991-ROOT.
-
Create is done on the underlying filesystem using username, usa-1991-ROOT.
Username: hdp-KPac
We will check against the first pattern, hdp-(.*), and notice it matches.
-
Attempt to translate the username using cdh-$1.
-
Username is translated to cdh-KPac.
Create is done on the underlying filesystem using username, cdh-KPac.
Username: hdfs
-
We will check against the first pattern, hdp-(.*), and notice it doesn’t match.
-
We will check against the second pattern, ()-([0-9])-user, and notice it doesn’t match.
-
Username is left as hdfs. Create is done on the underlying filesystem using username, hdfs.
Because these are config properties, any data center can have any set of rules. They must be identical across fusion-servers that occupy the same zone but do not have to be identical across data centers.
See more about enabling Kerberos authentication on WD Fusion’s REST API.
16.3. Kerberos Settings
When Kerberos is enabled on the underlying cluster, Fusion Server and IHC need to have the following defined in their /etc/hadoop/conf/core-site.xml files.
Property |
Description |
Permitted Values |
Default |
Checked at… |
fs.fusion.keytab |
The absolute location of the readable keytab file. |
/etc/security/keytabs/fusion.service.keytab |
None - must be present if FileSystem cluster configured for Kerberos. |
Startup |
fs.fusion.principal |
The name of the fusion principal found in the keytab file. Used for Kerberos login purposes since a keytab can contain multiple principals. |
"fusion/_HOST@${KERBEROS_REALM}" |
None - must be present if "fs.fusion.keytab" is defined. |
Startup |
fs.fusion.principal |
The name of the fusion principal found in the keytab file. Used for Kerberos login purposes since a keytab can contain multiple principals. |
"fusion/_HOST@${KERBEROS_REALM}" |
None - must be present if "fs.fusion.keytab" is defined. |
Startup |
fusion.handshakeToken.dir |
Path to the handshake directory. Fusion will attempt to write to this directory to verify that the user has the proper Kerberos credentials to write to the underlying file system. |
/user/hdfs/ |
Varies per file system. For HDFS, it is the user’s home directory. |
On processing a client request. |
16.4. IHC Server
The Inter-Hadoop Communication Server is configured from a single file located at:
/etc/wandisco/fusion/ihc/server/{distro}/{version string}.ihc.
Property |
Description |
Permitted Values |
Default |
|
|
The hostname and port the IHC server will listen on. |
String:[1 - 65535] |
None - must be present |
|
The transport the IHC server should use. |
|
OIO, NIO, EPOLL |
NIO |
|
|
The address the ihc server will bind to. Equivalent of DConE’s communication.hostname. May not be specified. If not specified, will be "0.0.0.0:port". In all cases the port should be identical to the port used in the ihc.server address (above). |
String:[1 - 65535] |
0.0.0.0:port |
|
|
Signifies that WD Fusion server - IHC communications should use SSL encryption. |
true, false |
false |
|
Encrypted password of trust store |
|
Password encrypted using password-encryptor.sh |
None |
|
|
Alias of private key / certificate chain used to encrypt communications by IHC Server. |
alias of a keystore entry |
None - required if Server-IHC SSL is enabled |
|
|
Encrypted password of key entry |
Password encrypted using password-encryptor.sh |
None |
|
Location of key store containing key entry |
|
Absolute path to key store |
None - required if Server-IHC SSL is enabled |
|
|
Format of trust store |
JKS, PCKS12, etc. |
JKS |
|
|
The host and port for the web server, used when the fusion.ihc.http.policy is equal to HTTP_ONLY or BOTH_HTTP_HTTPS. |
String:[1 - 65535] |
0.0.0.0:9001 |
|
The host and port for the web server, used when the
|
|
String:[1 - 65535] |
0.0.0.0:8001 |
Startup |
16.5. IHC Network configuration
The following is a description of how IHC servers are added to the replication system from WD Fusion 2.9:
-
The IHC servers are configured with the addresses of the WD Fusion servers that inhabit the same zone.
-
Periodically, the IHC servers ping the WD Fusion servers using these stored addresses.
-
The WD Fusion servers will announce the IHC servers that have pinged them.
IHC servers in standard configuration should have the address of all WD
Fusion servers, since the core-sites.xml property fusion.server lists
them all. This is important because only the Writer node in each zone
will confirm the existence of IHCs that have pinged it. Other Fusion
Servers don’t. Therefore the IHC has to talk to all Fusion servers in
the zone in order to be flagged as available.
The same method used in Hadoop to handle namenode and datanode connections. The datanode is configured with the namenode’s address and uses the address to contact the namenode and indicate its availability. If the namenode doesn’t hear from the datanode within a set period, the namenode assumes that the datanode is offline.
|
Note: If the property was missing from the file during initialization then it is possible that the IHC server will fail to make a connection to the WD Fusion server, causing replication to stall. If a restart of the cluster fixes the problem this may indicate that a necessary restart isn’t happening which may result in IHC servers running with outdated configuration. |
16.6. WD Fusion Client
Client configuration is handled in
/etc/hadoop/conf/core-site.xml
Property |
Description |
Permitted Values |
Default |
|
|
The Abstract FileSystem implementation to be used. |
See comment 1 below |
None |
Startup |
|
Max number of times to attempt to connect to a Fusion server before failing over (in the case of multiple Fusion servers). |
Any integer |
3 |
Startup |
|
The FileSystem implementation to be used. |
See comment 1 below |
None |
Startup |
|
The number of bytes the client will write before sending a push request to the Fusion server indicating bytes are available for transfer. |
0 - Long.MAX_VALUE. (If the threshold is 0, pushes are disabled) |
The block size of the underlying filesystem |
Startup |
|
The hostname and request port of the Fusion server. Comma-separated list of hostname:port for multiple Fusion servers. |
String:[1 – 65535] (Comma-separated list of Fusion servers) |
None - must be present |
Startup |
|
The transport the FsClient should use. |
EPOLL, NIO, OIO |
NIO |
Startup |
fs.fusion.underlyingFs |
The address of the underlying filesystem |
Often this is the same as the fs.defaultFS property of the underlying hadoop. However, in cases like EMRFS, the fs.defaultFS points to a local HDFS built on the instance storage which is temporary, with persistent data being stored in S3. Our customers are likely to use the S3 storage as the fs.fusion.underlyingFs. |
None - must be present |
Startup |
|
The name of the implementation class for the underlying file system specified with fs.fusion.underlyingFs |
Fusion expects particular implementation classes to be associated with common URI schemes used by Hadoop clients when accessing the file system (e.g. s3://, file://, hdfs://, etc.) If your cluster is configured to use alternative implementations classes for the scheme configured in fs.fusion.underlyingFs, you need to specify the name of the implementation for the underlying file system with this item. You also need to specify the implementation if using a URI scheme that is not one of those known to the defaults here. |
There is a default per scheme: |
Startup |
|
The DistributedFileSystem implementation to be used. |
See comment 1 below |
None |
Startup |
|
If Fusion Server - Fusion Client communications should use SSL. |
true, false |
false |
|
|
Location of trust store used to validate certificates sent by Fusion Servers. |
Absolute path to trust store file |
None - must be present if server-client SSL enabled |
Startup |
|
Encrypted password of trust store. |
Password encrypted using password-encryptor.sh |
None |
Startup |
|
Format of trust store |
JKS, PCKS12, etc. |
JKS |
Startup |
|
If true, bypasses the request to the underlying filesystem after retrying. |
true/false |
false |
Everytime a request is submitted. |
|
If true, the Fusion client will coordinate open() operations (which is used when an application opens a file for read). |
true or false |
false |
Every time open() is called. |
|
Determines, in seconds, how long the client will wait for a fusion server to handle the request. |
Time in seconds. |
14 |
Startup |
|
Rather than just have the client try over and over this could cause some extreme slowness during a down fusion server, so instead, after client switched to a fusionless operation, all operations that follow would be fusionless until this time passed and which time the client would use fusion again. |
Time in seconds |
60 |
Everytime a fusion client attempts to connect to a fusion server. |
|
The directory path where backups will reside. Unless intended to replicate, ensure that this is a non-replicated directory so backup files only exist on this datacenter. |
Path |
/fusion/backup/ |
Startup |
|
If true, enables backup on this datacenter. On every delete, rather than the file being removed, it will be moved to a timestamped directory within fusion.backup.dir. |
true/false |
false |
Startup |
|
A class that implements BackupStrategy that is the strategy of how backups are handled. |
class that implements BackupStrategy (i.e |
NoBackupStrategy.class |
Startup |
|
If true, the Fusion server will pull data when it receives an HFlush request from another zone. |
true/false |
true |
When an HFlushRequest is received |
|
A list of username translations that dictate what username is used for operations coming from other datacenters. Example: fusion.username.translations= "datacenterA/datacenterB,dcA/dcB" If datacenterA did a create with "datacenterA" as a user, datacenterB would translate to "datacenterB" before applying the create. If there are multiple translations, they need to be comma-separated. |
Comma separated strings of the format <expected>/<translated>. |
None |
Requests from other datacenters. |
|
Location from which clients should try to read information about replicated directories, before contacting Fusion server. (FUS-3121) It’s necessary to configure the same in server’s application.properties, so that it generates the necessary data. |
hdfs://nn/shared/fusionDirExchange |
none |
startup |
16.6.1. Usage Guide
There’s a fixed relationship between the type of deployment and some of the Fusion Client parameters. The following table describes this relationship:
| Configuration | fs.fusion.impl |
fs.AbstractFileSystem.fusion.impl |
fs.hdfs.impl |
|---|---|---|---|
Use of fusion:/// with HCFS |
com.wandisco.fs.client.FusionHcfs |
com.wandisco.fs.client.FusionAbstractFs |
Blank |
Use of fusion:/// with HDFS |
com.wandisco.fs.client.FusionHdfs |
com.wandisco.fs.client.FusionAbstractFs |
Blank |
Use of hdfs:/// with HDFS |
Blank |
Blank |
com.wandisco.fs.client.FusionHdfs |
Use of fusion:/// and hdfs:/// with HDF |
com.wandisco.fs.client.FusionHdfs |
com.wandisco.fs.client.FusionAbstractFs |
com.wandisco.fs.client.FusionHdfs |
16.7. LocalFileSystems
We’ve introduced FusionLocalFs for LocalFileSystems using WD Fusion.
This is necessary because there are a couple of places where the system
expects to use a Local File System.
Configuration |
|
|
|
LocalFileSystems (See below) |
com.wandisco.fs.client.FusionLocalFs |
com.wandisco.fs.client.FusionLocalFs |
com.wandisco.fs.client.FusionLocalFs |
Therefore, for LocalFileSystems, users should set their
fs.<parameter>.impl configuration to
*com.wandisco.fs.client.FusionLocalFs*.
16.8. Usage
-
Set
fs.file.impltoFusionLocalFs, (then any file:/// command will go through FusionLocalFs) -
Set
fs.fusion.impltoFusionLocalFs, (then any fusion:/// command will go through FusionLocalFs).Further more, a user can now set any scheme to any
Fusion*Fsand when running a command with that scheme, it will go through thatFusion*Fs. e.g., -
Set
fs.orange.implto FusionLocalFs, (then any oranges:/// command will go through FusionLocalFs). -
Set
fs.lemon.implto FusionHdfs, (then any lemon:/// command will go through FusionHdfs).
16.9. Fusion Client OpenRequests coordination
In WD Fusion 2.10, OpenRequests from clients are no longer coordinated operations, since OpenRequests are read-only their coordination adds unnecessary traffic.
16.9.1. Failsafe
If the operation of any applications is affected by this change, it is possible to make OpenRequests coordinated again by changing the WD Fusion Client property fusion.client.coordinate.read to "true".
16.10. System Usage Graphs
The dashboard provides running monitors for key system resources.

On nodes that have data limits on their product license, there’s a graph that displays the volume of replicated data, as a percentage of the license limit.
This graph tracks the percentage of configured Java Heap space that is currently in use across the cluster.
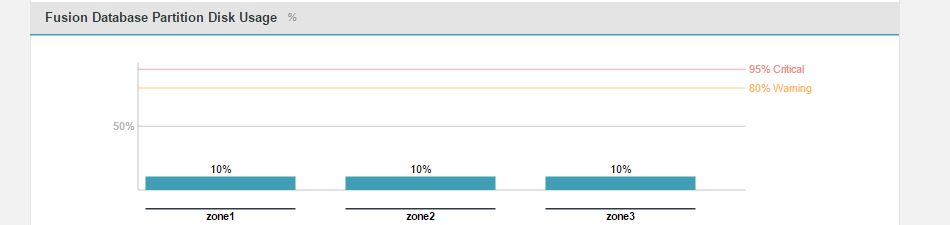
This graph measures the percentage of available storage in the partition that hosts the WD Fusion installation.
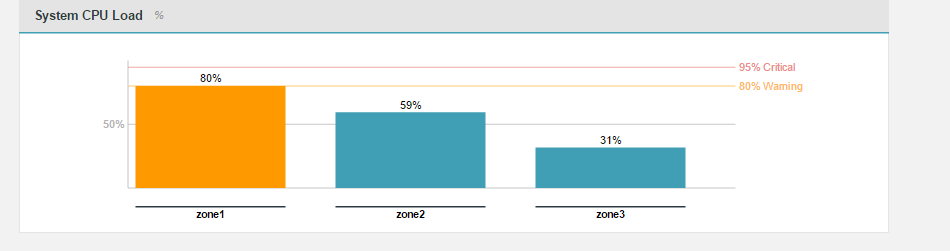
This graph tracks the current percentage load on the cluster’s processors.
16.11. CPU Graph clarification
We display CPU load averages. Low values indicate that the system’s processor(s) have unused capacity. Above the warning threshold (80% by default) available capacity starts to run out. Note that the number that drives the graph is between 0 and 1, and so already takes multi-core systems into consideration.
16.12. Replicated Rules
The Replicated Folders screen lists those folders in the cluster’s hdfs space that are set for replication between WD Fusion nodes.
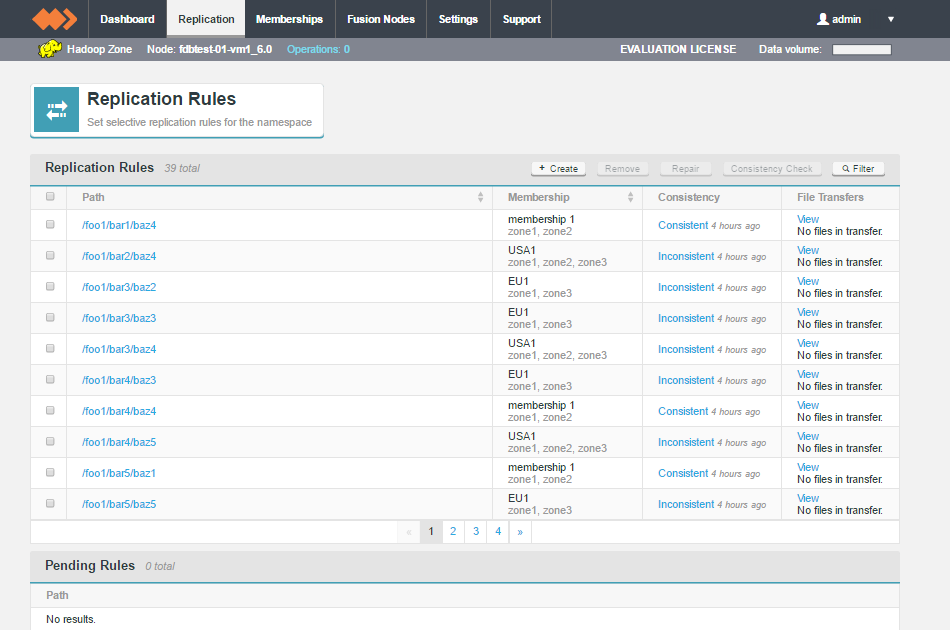
- Replication Rules
-
Lists all active replicated folders, currently running on the node.
- Pending Rules
-
Replicated folders that have been added but have not yet been established across all nodes. In most situations, pending rules will eventually move up to the Replication Rules table.
- Failed Rules
-
In rare situations, a replicated folder creation will be rejected because of a file inconsistency between nodes. In such cases, the Failure will be reported in the Failed Rules table.
16.13. Filtering
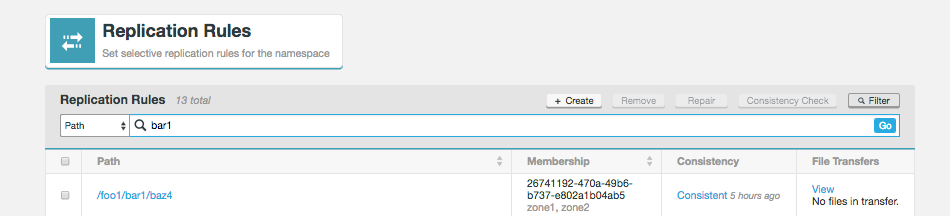
In deployments that use large numbers of rules, You can use the filter tool to focus on specific sets of rules. Filtering by Path, Membership or Consistency.
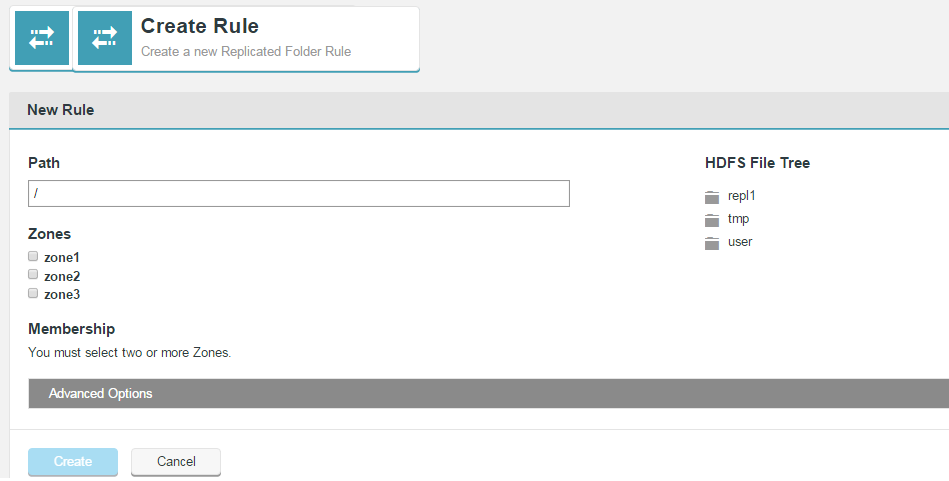
16.15. Advanced Options
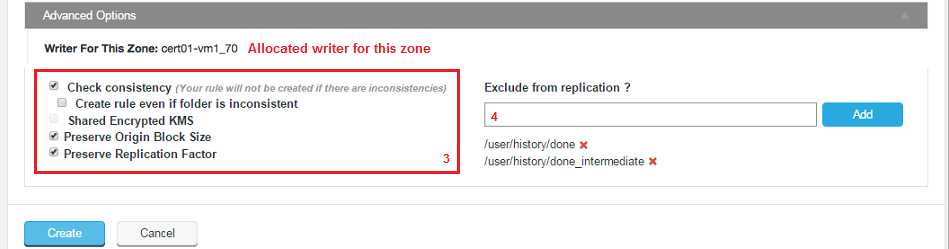
The Advanced Options provide additional control for replicated folders.
This identifies which node is assigned as the writer for this node. See the glossary for an explanation of The role of the writer.
Check consistency (Your rule will not be created if there are inconsistencies)
Use this option to perform a consistency check before creating the replicated folder space. The check must succeed in order for the rule to be applied. If you want to perform the check but not enforce consistency see the next checkbox.
- Create rule even if folder is inconsistent
-
The replication space is added, even if it has been found to be inconsistent between nodes. This option lets you create new replicated folders and then remedy consistencies.
- Shared Encrypted KMS
-
In deployments where multiple zones share a command KMS server, then enable this parameter to specify a virtual prefix path.
- Preserve Origin Block Size
-
The option to preserve the block size from the originating file system is required when Hadoop has been set up to use a columnar storage solution such as Apache Parquet. If you are using a columnar storage format in any of your applications then you should enable this option to ensure that each file sits within the same HDFS block.
- Preserve Replication Factor
-
By default, data that is shared between clusters will follow the local cluster’s replication rules rather than preserve the replication rules of the originating cluster. When this option is enabled, the replication factor of the originating cluster is preserved.
|
Example
Data in Zone A which has a replication factor of 3 is replicated to Zone
B, which has a replication factor of 5. When Preserve Replication
Factor is enabled this replica of the data in Zone B will continue to
use a replication factor of 3 rather than use Zone B’s native
replication factor of 5.
|
16.15.1. Exclude from replication?
You can select files or file system locations that will be excluded from
replication across your clusters and will not show up as inconsistent
when a consistency check is run on the file system.
This feature is used to remove housekeeping and temporary system files
that you don’t want clogging up the replication traffic. The entry field
will accept specific paths and files or a glob pattern (sets of
filenames with wildcard characters) for paths or files.
16.15.2. Default Exclusions
The following glob patterns are automatically excluded from replication:
/**/.fusion, /**/.fusion/**
-
Fusion directories store WD Fusion’s housekeeping files, it should always be excluded in the global zone properties (even after update)
/**/.Trash, /**/.Trash/**
-
Trash directories are excluded by default but it can be removed if required.
Example
Requirement: exclude all files in the replicated directory with the
"norep_" prefix from replication.
Folder structure:
/repl1/rep_a /repl1/norep_b /repl1/subfolder/rep_c /repl1/subfolder1/norep_d /repl1/subfolder2/rep_e /repl1/subfolder2/norep_e
Required rule:
**/norep_*
-
Pattern does not need to be an absolute path, e.g. /repl1/subfolder2/no_rep_3, patterns are automatically treated as relative to the replicated folder, e.g. /subfolder/no_rep_3
-
Take care when adding exclusion rules as there is currently no validation on the field.
17. Web UI Reference Guide
The following section takes a look at each screen that is available in the WD Fusion UI.
17.1. Dashboard
The Dashboard gives you an overview of your WD Fusion deployment’s status.
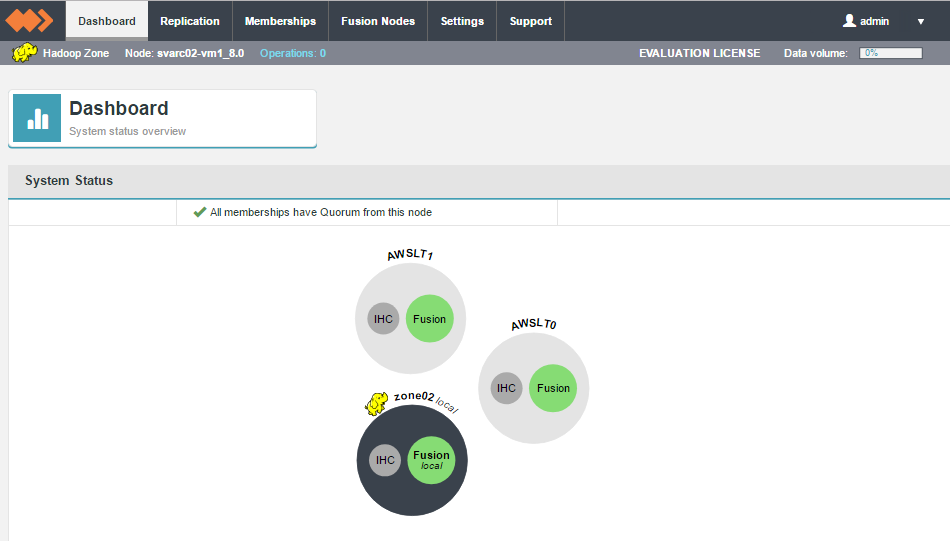
17.1.1. Header

- Zone Type
-
The type of deployment is identified by this leader which shows you the type of file system being replicated. E.g.
-
Hadoop Zone
-
File system Zone
-
S3
-
- Node
-
The name of the node that you are viewing
- Operations
-
Number of pending operations.
- License Status
-
Shows the type of license in use. Evaluation or Production.
- Data volume
-
For deployments that are licensed based on a volume of transferred replicated data, this bar graph displays the volume of used data transfer, as a percentage value. The actual value of Data Under Replication Limit can be viewed in the License screen under the Settings tab.
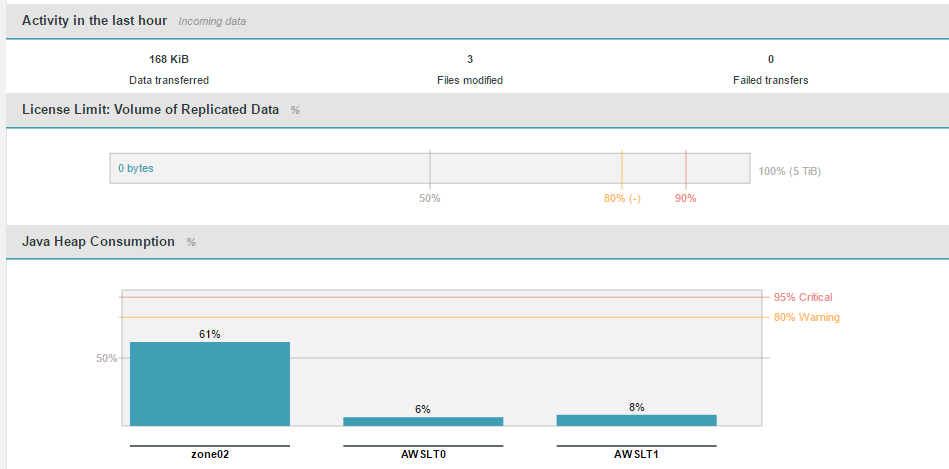
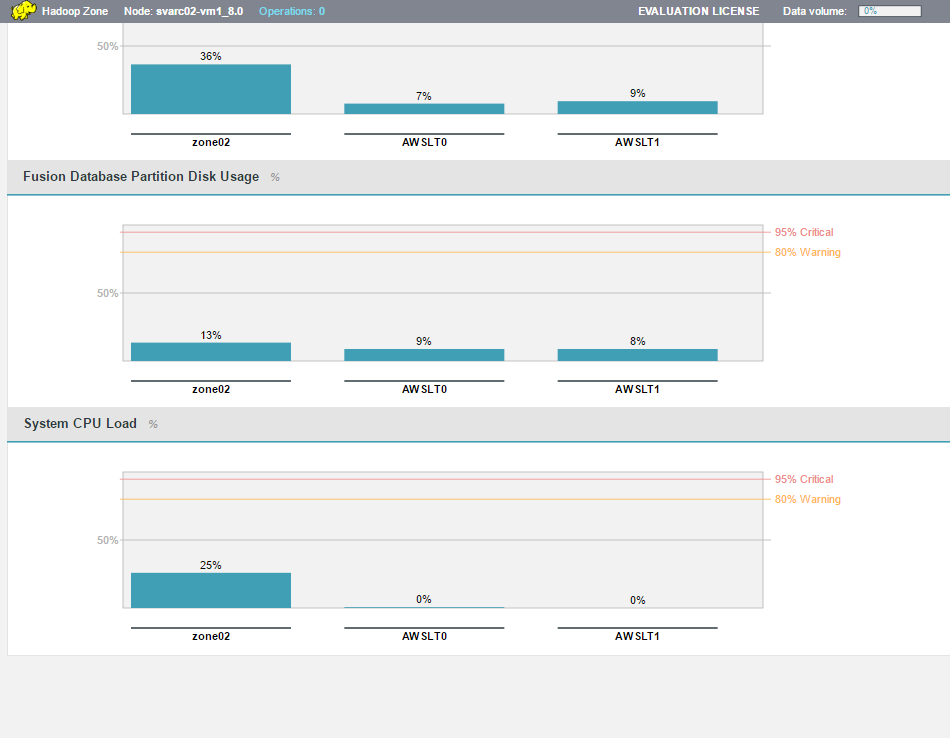
17.3. Node
17.3.2. About This Node
The About This Node panel shows the version information for the underlying Hadoop deployment as well as the WD Fusion server and UI components:
- Fusion UI Version
-
The current version of the WD Fusion UI.
- Fusion Build Number
-
The specific build for this version of the WD Fusion UI.
- Hadoop Version
-
The version of the underlying Hadoop deployment.
- WD Fusion Version
-
The version of the WD Fusion replicator component.
- WD Fusion Uptime
-
The time elapsed system the WD Fusion system last booted up.
- Cluster Manager
-
The management application used with the underlying Hadoop.
17.3.3. Client Bypass Settings
The emergency bypass feature gives the administrator an option to bypass WD Fusion and write to the underlying file system, which will introduce inconsistencies between zones. This is suitable for when short-term inconsistency is seen as a lesser evil compared to blocked progress.
For an explanation about how to use this feature, see Emergency bypass to allow writes to proceed.
17.3.4. Graph Settings
The graphs that are displayed on the WD Fusion dashboard can be modified so that they use different thresholds for their "Warning" and "Critical" levels. By default, warn triggers at 80% usage and critical triggers at 90% or 95%.
- Warning
-
At the warn level, the need for administrator intervention is likely, although the state should have no current impact on operation. On a breach, there is the option for WD Fusion to send out an alerting email, providing that you have configured the email notification system. See Set up email notifications.
- Critical
-
At the critical level, the need for administrator intervention may be urgent, especially if the breach concerns partition usage where reaching 100% will cause the system to fail and potentially result in data corruption. On a breach, there is the option for WD Fusion to send out an alerting email, providing that you have configured the email notification system. See Set up email notifications.
- License Data Limit
-
This corresponds with the dashboard graph "License Limit: Volume of Replicated Data". The graph tracks the percentage of replicated data permitted by the current license. Enter your own values for the "Warn" trigger and "Critical" trigger. Defaults: Warn 80%, Critical 90%.
- CPU
-
This corresponds with the dashboard graph "System CPU Load", it tracks usage in terms of percentage of available cycles. Defaults: Warn 80%, Critical 95%.
- Memory
-
This corresponds with the dashboard graph "Java Heap Consumption" which tracks the amount of JAVA heap currently in use, based on the Maximum Heap Settings that were applied during the installation. Defaults: Warn 80%, Critical 95%.
- Disk
-
This corresponds with the dashboard graph "Fusion Database Partition Disk Usage". This graph measures the percentage of the available partition specifically being used by WD Fusion. The monitor is important because exhausting the available storage will cause WD Fusion to fail and potentially could result in corruption to the internal prevayler database. Defaults: Warn 80%, Critical 95%.
17.3.6. Support
The support tab contains links and details that may help you if you run into problems using WD Fusion.
17.3.7. License Settings
The License Settings panel gives you a summary of the server’s license status.
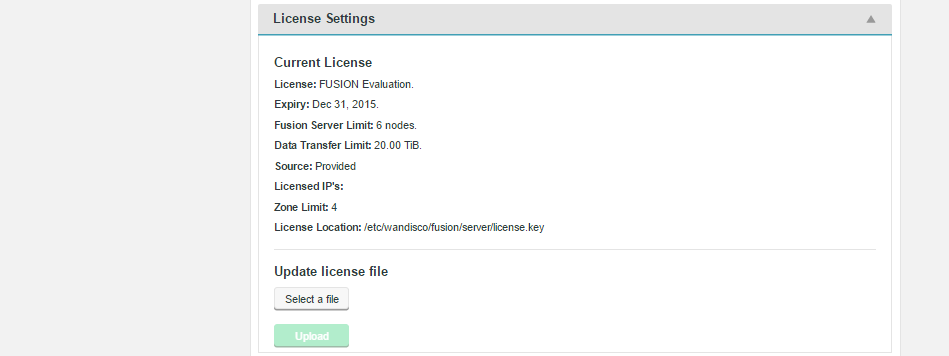
- License
-
Type of license employed. (Evaluation or Production)
- Expiry
-
Date on which the license will expire — at which point a new license will be required.
- Fusion Server Limit
-
Maximum number of WD Fusion server (Nodes) across all zones included under the license.
- Data Transfer Limit
-
The maximum amount of replicated data (TB) permitted by the license.
- Source
-
The origin of the license. Provided or Downloaded.
- Licensed IPs
-
Machine IP addresses that are covered under the license.
- Zone Limit
-
The maximum number of zones supported under the license.
- License Location
-
Location of the license key on the server’s file system.
17.3.8. Log Settings
Defines the log directories of the Fusion Core Server, Fusion IHC Server and Fusion UI. The Fusion user must have full permissions on these directories.
- Fusion Core Server Log Directory
-
Sets the directory for the core server log files. For more information, see Server Logs
- Fusion IHC Server Log Directory
-
Sets the directory for the IHC server log files. For more information see Inter-Hadoop Connect (IHC) Server Logs
- Fusion UI Log Directory
-
Sets the directory for the UI server log files. For more information see WD Fusion UI Server Logs
After updating this setting it will be necessary to restart some services for the change to take effect.
Directories associated with previous values will be left in place; it is the user’s responsibility to organize the removal or clean up of these directories if this is required.
17.3.9. Plugins
The Plugins screen lists the versions of all installed Plugins in the deployment.
- Fusion Core
-
Lists plugins that modify WD Fusion’s core. Currently Fusion’s Hadoop Compatible File System is registered as a plugin. Note that this is built into the product and doesn’t need to be installed.
- UI Server
-
Lists plugins that modify the UI Server. There are currently no UI Server plugins available.
- UI Client
-
Lists UI Client plugins.
17.3.10. Server Settings
The server settings give you control over traffic encryption between WD Fusion and IHC servers.
- Enable SSL for WD Fusion (checkbox)
-
Tick to enable the WD Fusion server to encrypt traffic using SSL. See below for additional settings that appear if you enable SSL.
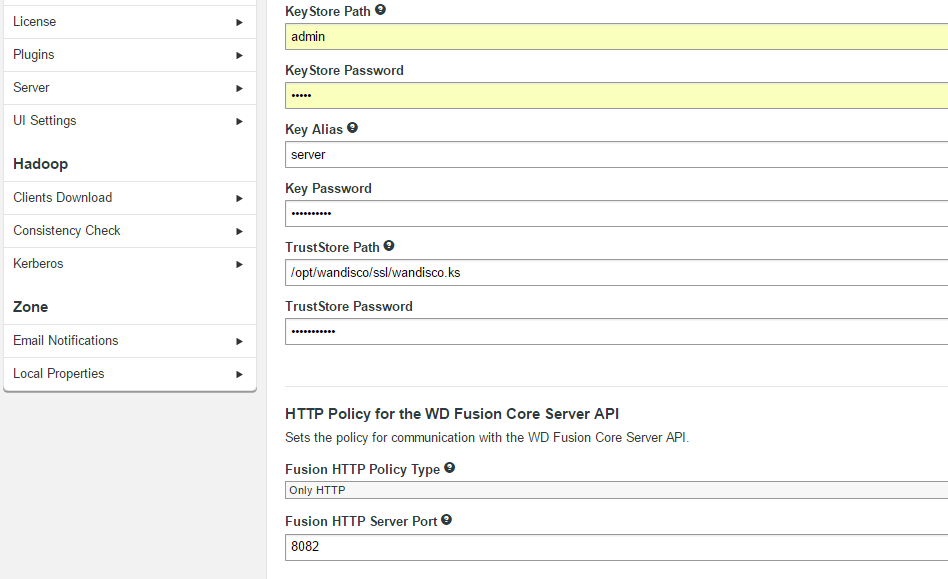
- KeyStore Path
-
Path to the keystore.
- KeyStore Password
-
Encrypted password for the KeyStore.
- Key Alias
-
The Alias of the private key.
- Key Password
-
Private key encrypted password.
- TrustStore Path
-
path to the TrustStore.
- TrustStore Password
-
Encrypted password for the TrustStore.
Changes must be applied to all servers
Changes to SSL settings require the same changes to be made manually in the UI of every other WD Fusion node. Updating will also make changes in
core-site file via the management endpoint. You will need to push out configs and restart some services.
- DConE panic if dirty (checkbox)
-
This option lets you enable the strict recovery option for WANdisco’s replication engine, to ensure that any corruption to its prevayler database doesn’t lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
- App Integration panic of dirty (checkbox)
-
This option lets you enable the strict recovery option for WD Fusion’s database, to ensure that any corruption to its internal database doesn’t lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
Configuration changes
These options set the following properties in
/etc/hadoop/conf/core-site.xml
fusion.ssl.enabled=true fusion.ihc.ssl.enabled=true
This ensures that both WD Fusion server and the IHC server traffic is secured using SSL. The properties, as defined in the WD Fusion Configuration are repeated below:
Property |
Description |
Permitted Values |
Default |
Checked at… |
fs.fusion.ssl.enabled |
If Client-WD Fusion server communications use SSL encryption. |
true, false |
false |
Startup |
ihc.ssl.enabled |
Signifies that WD Fusion server - IHC communications should use SSL encryption. |
true, false |
false |
Startup |
Setting a password for SSL encryption
Use our provided bash script for generating a password. Run the script at the command line, enter a plaintext password, the script then generates and outputs the encrypted version of the entry:
[root@vmhost01-vm3 fusion-server]# ./encrypt-password.sh Please enter the password to be encrypted > ******** btQoDMuub7F47LivT3k1TFAjWSoAgM7DM+uMnZUA0GUet01zwZl7M8zixVZDT+7l0sUuw6IqGse9kK0TiDuZi0eSWreeW8ZC59o4R15CCz0CtohER7O3uUzYdHaW6hmT+21RaFkUF5STXXHcwdflwq4Zgm+KdUXKF/8TrgEVqT854gci1KQyk+2TKSGtGbANg12LplEre3DEGoMFOpy2wXbwO5kGOQM07bZPjsDkJmAyNwERg0F3k2sebbuGmz4VSAY1NTq4djX1bVwMWoPwcuiQXLwWLgfrGZDHaT+Cm88vRUsYaK2CDlZI4C7r+Lkkm/U4F/M6TFLGT6ZFlB+xRQ==
URI Selection
The default behaviour for WD Fusion is to handle all replication using the Hadoop Distributed File System via the hdfs:/// URI. Selecting the HDFS-scheme provides the widest support for Hadoop client applications, since some applications can’t support the available fusion:/// URI or they can only run on HDFS instead of the less strict HCFS. Each option is explained below:
- Use HDFS URI with HDFS file system
-
This option is available for deployments where the Hadoop applications support neither the WD Fusion URI or the HCFS standards.
WD Fusion operates entirely within HDFS. This configuration will not allow paths with the fusion:// URI to be used; only paths starting with hdfs:// or no scheme that correspond to a mapped path will be replicated. The underlying file system will be an instance of the HDFS DistributedFileSystem, which will support applications that aren’t written to the HCFS specification.
- Use WD Fusion URI with HCFS file system
-
This is the default option that applies if you don’t enable Advanced Options, and was the only option in WD Fusion prior to version 2.6.
When selected, you need to use fusion:// for all data that must be replicated over an instance of the Hadoop Compatible File System. If your deployment includes Hadoop applications that are neither able to support the Fusion URI, nor are written to the HCFS specification, then this option will not work.
- Use Fusion URI with HDFS file system
-
This differs from the default in that while the WD Fusion URI is used to identify data to be replicated, the replication is performed using HDFS itself.
This option should be used if you are deploying applications that can support the WD Fusion URI but not the Hadoop Compatible File System.
- Use Fusion URI and HDFS URI with HDFS file system
-
image::wdfusion_uri_optionD.png[URI Option D,title="Option D"]
This "mixed mode" supports all the replication schemes (fusion://, hdfs:// and no scheme) and uses HDFS for the underlying file system, to support applications that aren’t written to the HCFS specification.
Set Push Threshold Manually

The feature exposes the configuration property
fs.fusion.push.threshold, stored in the core-site.xml file. It
provides administrators with a means of making a small performance
improvement, useful in a small number of cases. When enabled in
the UI the entry displays as "Required".
You can enter your own value (in bytes) and click the Update button.
Amazon cloud deployments
For cloud deployments, ensure the property is disabled (unticked) or set to zero "0". This will disable HFLUSH which is suitable because appends are not supported for S3 storage.
17.3.11. UI Settings
Settings that control the TPC Port and hostname used by the WD Fusion server.
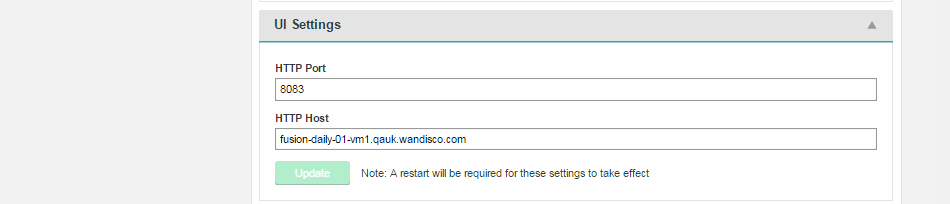
- HTTP Port
-
Port used to access WD Fusion UI.
- HTTP Host
-
Hostname of the WD Fusion UI.
Restart required
Any change that you make will require a restart of the WD Fusion server
in order for it to be applied.
17.4. AWS Settings
This section covers the Amazon Web Services settings that are available through WD Fusion’s UI. Note that the AWS section will only appear in deployments that connect to a suitable S3 storage bucket.
17.4.1. AWS About
- S3 Bucket Name
-
The name of your S3 storage bucket that you are connecting to.
- Amazon S3 Encryption
-
Indicates if you are using Amazon’s own encryption, showing as "true" or "false"
If you run with the S3 Plugin, the following Properties will display instead:
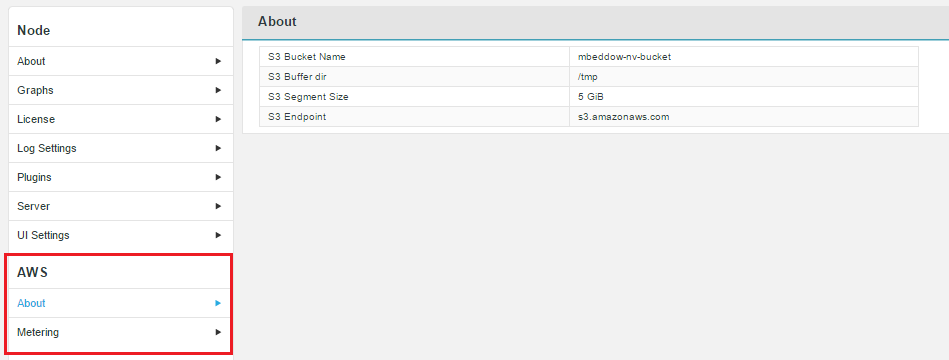
- S3 Bucket Name
-
The name of your S3 storage bucket that you are connecting to.
- S3 Buffer dir
-
The local directory used to handle S3 buffered data.
- S3 Segment Size
-
The size of the S3 segment. Between 5 MB and 5 GB.
- S3 Endpoint
-
The endpoint used to connect to your S3 Bucket.
17.4.2. Credentials
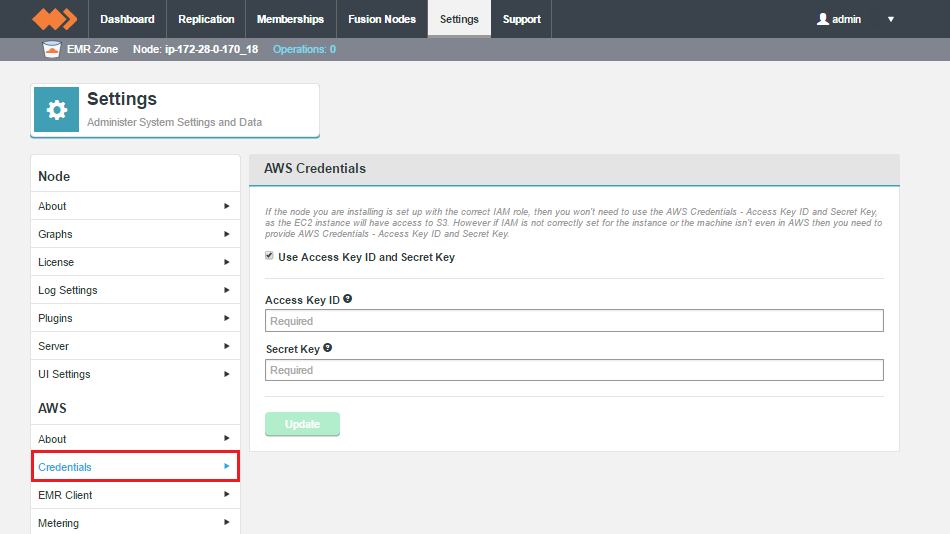
If the node you are installing is set up with the correct IAM role, then you won’t need to use the following AWS Credentials, as the EC2 instance will have access to S3.
However if IAM is not correctly set for the instance or the machine isn’t even in AWS then you need to provide AWS Credentials:
- Access Key ID
-
This is your AWS Access Key ID. Validation tests that there is a provided value, along with a valid secret key.
- Secret Key
-
This is the secret key that is used in conjunction with your Access Key ID to sign programmatic requests that are sent to AWS. Validation checks that the credentials file is accessible.
Read more on how to Use access key and secret key.
17.4.3. EMR Client
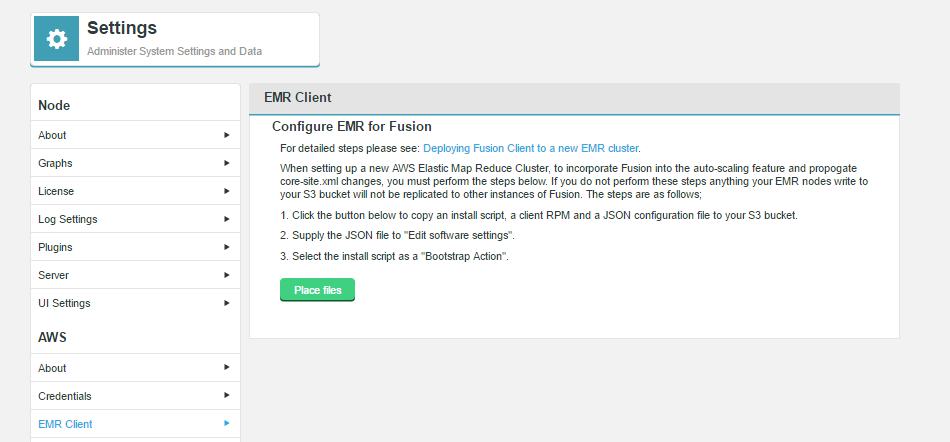
The EMR client panel provides a copy of the configuration instructions that are provided during the WD Fusion installation, in case you need to complete account for changes to your EMR cluster.
Configure EMR for Fusion
For detailed steps please see: Deploying Fusion Client to a new EMR cluster.
When setting up a new AWS Elastic Map Reduce Cluster, to incorporate Fusion into the auto-scaling feature and propagate core-site.xml changes, you must perform the steps below. If you do not perform these steps anything your EMR nodes write to your S3 bucket will not be replicated to other instances of Fusion. The steps are as follows;
-
Click the "Place files" button below to copy an install script, a client RPM and a JSON configuration file to your S3 bucket.
-
Supply the JSON file to "Edit software settings".
-
Select the install script as a "Bootstrap Action".
17.4.4. Metering
The Metering panel is available for deployments that use the Metering payment option. See AWS Metering.
The provides a guide to the following data:
- Metered time
-
The billing increment, e.g. 1pm-2pm. Indicated as a timestamp (UTC) for when we attempted to send the bill to AWS.
- Billed data under replication
-
This is the highest transfer in the hour, which is used so as to account for possible data deletion which would reduce the apparent billable transferred data.
- Status
-
Indicates whether the metering event has been successfully billed or not. Displays "success" or "failed".
- Detail
-
Shows you the submission history, e.g. if a metering report was submitted twice and then succeeded on a third attempt, the detail will show _2 failed then 1 successful attempt to send the bill.
17.5. Hadoop
17.5.1. Client Downloads
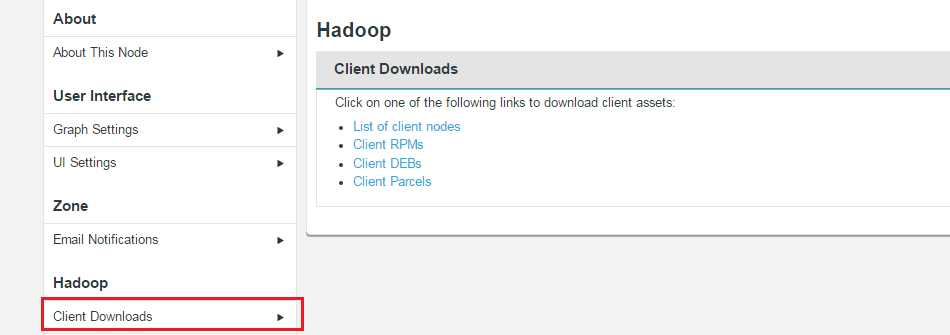
The client applications required to talk to WD Fusion are provided here. The client packages are provided during installation, they’re listed in the Settings section in case they are required again, after installation is complete.
- List of client nodes
-
This link goes to a list of nodes on the platform.
- Client RPMs
-
This is a link to the RPMs.
- Client DEBs
-
Link to Debian Package files, for use with Ubuntu deployments.
- Client Parcels
-
(Available on a Cloudera platform) Link to the client in Cloudera’s parcel package format.
|
WARNING
Please take note that, on some very rare occasions, the distribution of Cloudera’s parcel files may fail. We continue to investigate the cause of the problem, which appears to accur if the client parcel installation is not completed during the installation of WD Fusion, but has been left until after the installation, instead. We always recommend getting your client files installed during step 8 of the installer journey.
Workaround: |
- Client Stacks
-
(Available on a Hortonworks platform) Link to the client in Hortonworks Stack format.
17.5.2. Consistency Check
The consistency check options provide administrators with additional tunable properties concerning the tool for validating that all replica data is synchronized.
Default Check Interval
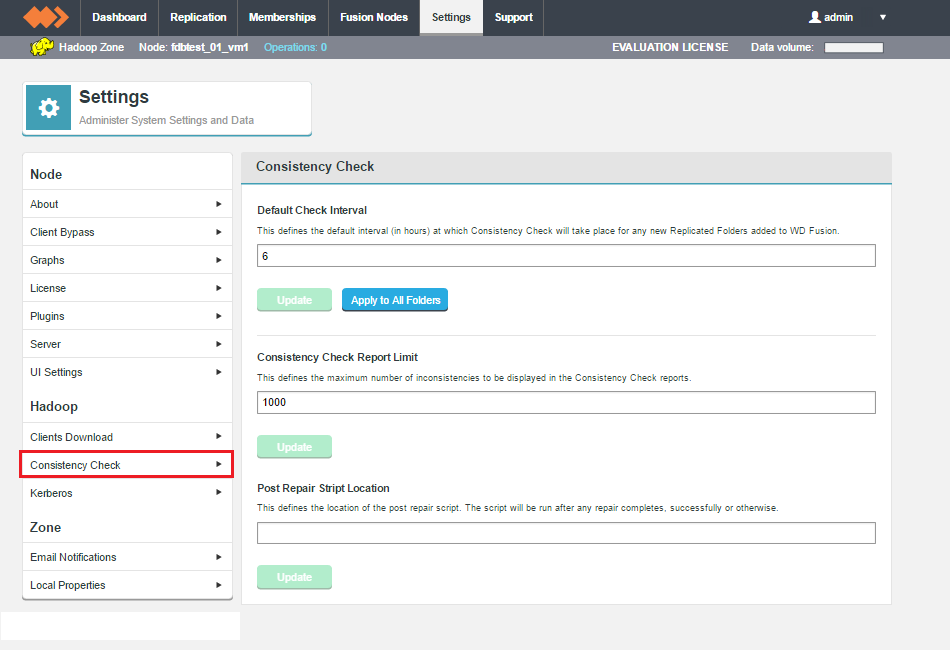
This lets you set the default amount of time that is allowed to pass before a new replicated folder is checked for consistency between replicas. The default value is 24 hours. It’s possible to set a different value for each specific replicated folder, using the Advanced Options available when setting up or editing a Replicated Folder.
- Default Check Interval
-
The entered value must be an integer between 1 and 24, representing number of hours before a consistency check will automatically take place.
- Save
-
Click the save button to store the entered value and use it for all replicated folders that don’t have their own set interval, using the Override the Consistency Check interval Advanced Option.
- Apply to All
-
This button lets you for a new default value onto all replicated folders, even those that have specified an override (noted above).
17.5.3. Kerberos
WD Fusion supports Kerberized environments, supporting the use of an established Kerberos Key Distribution Center (KDC) and realms.
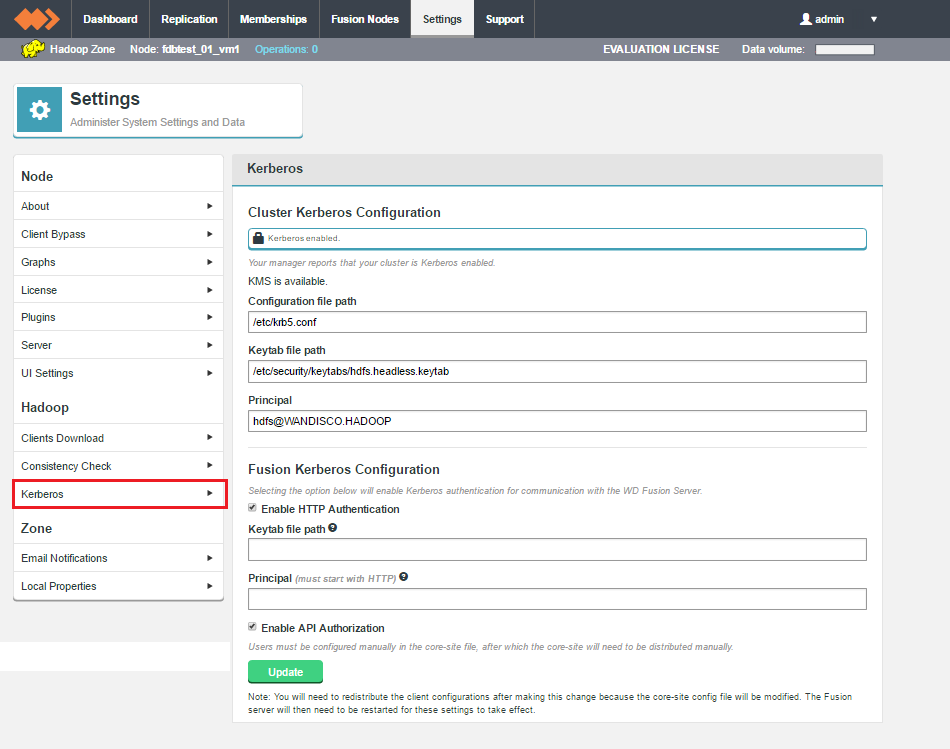
Cluster Kerberos Configuration
- Kerberos enabled
-
The Hadoop manager is poled to confirm that Kerberos is enabled and active,
- Handshake Token Directory
-
This is an optional entry. It defines what the root token directory should be for the Kerberos Token field. This is set if you want to target the token creations within the NFS directory and not on just the actual LocalFileSystem. If left unset it will default to the original behaviour; which is to create tokens in the /user/<username>/ directory.
- Configuration file path
-
Path to the current configuration file.
- Keytab file path
-
Path to the Keytab file.
Click the Validate button to have your entries checked by the installer.
Fusion Kerberos Configuration
Tick the Enable HTTP Authentication check-box to use Kerberos authentication for communication with the WD Fusion server.
Click Next step to continue or go back to return to the previous screen.
The remaining panels in step 6 detail all of the installation settings. All your license, WD Fusion server, IHC server and zone settings are shown. If you spot anything that needs to be changed you can click on the go back link.
17.6. Zone
Settings that apply between different zones. See Zones.
17.6.1. Email Notifications
The Email Notification let you set up system emails that can be triggered is a particular system event occurs.
Email notification lets you set up notification emails that can be sent from the WD Fusion server if there’s a system event that requires administrator attention. For more information about setting up email notifications, see Set up email notifications
17.6.2. Networking
- Networking direction between Fusion Server and IHC server
-
Defines whether or not the WD Fusion server proactively creates outbound connections to remote IHC servers during data transfer, It will otherwise tell the server to wait for and re-use inbound connections. Important: When set to inbound, the WD Fusion server must have a publicly visible hostname.
Select:
- Outbound connection
-
The default value, meaning when the Fusion server transfers data it will create an outbound connection to the IHC server.
- Inbound connection
-
The Fusion server will transfer data over an inbound connection from a remote IHC server. This is the option to be used in AWS since the on-premises Fusion servers cannot accept incoming connections.
17.6.3. Replication
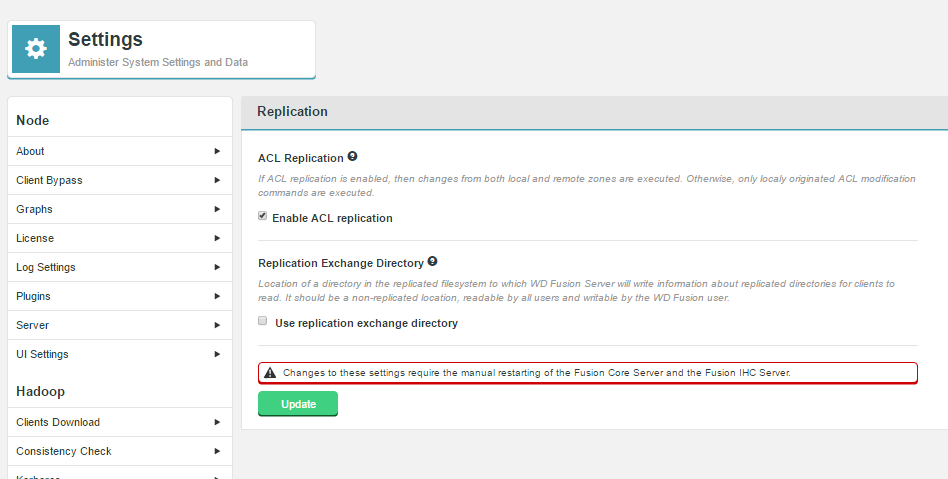
- ACL Replication
-
If ACL replication is enabled, then changes from both local and remote zones are executed, Otherwise, only locally originated ACL modification commands are executed.
- Enable ACL replication
-
Checkbox (ticked by default)
- Replication Exchange Directory
-
Location of a directory in the replicated filesystem to which WD Fusion Server will write information about replicated directories for clients to read. It should be a non-replicated location, readable by all users and writable by the WD Fusion user.
- Use replication exchange directory
-
Checkbox (unticked by default)
17.8. KMS
The status of the KMS (Key Management Service) is presented here. KMS is an encryption keystore, providing network users with keys required to decrypt data-at-rest. To be clear, KMS is not a function of Kerberos, and is functional without Kerberos, however, Kerberos is employed to provide HTTP SPNEGO authentication to the REST API.
|
Read about Hadoop Key Management System
See Hadoop Key Management System
|
- Configuration file path
-
Path to the Kerberos configuration file, e.g.
krb5.conf. - Keytab file path
-
Path to the generated keytab.
- Principle
-
Principle for the keytab file.
17.9. Fusion Kerberos Configuration
Selecting the option below will enable Kerberos authentication for communication with the WD Fusion Server.
- Enable Kerberos on WD Fusion
-
Check-box to enable Kerberos authentication
- Keytab file path
-
Path to the generated keytab.
- Principle
-
Principle for the keytab file.
- Enable Authorization
-
The check-box is used to enable support for Authorization, within WD Fusion, which enables administrators to allow two levels of access; full user access and read-only access, where a user does not have authorization to make changes to data. This checkbox is only visible if Kerberos core authentication has been enabled and configured.
For auditing purposes, every time an unauthorized request is made, the WD Fusion server will log the user and attempted request.
Manually distribute client configuration.
You will need to redistribute the client configurations after making
this change because the core-site.xml config file will be modified.
The WD Fusion server will then need to be restarted for these settings
to take effect.
Enabling Authorization sets up some default values, the UI will add
the "fusionUISystem" user automatically when Authorization is enabled
as well as adding the correct proxy principal. All other users need to
be configured manually. but you will still need to ensure that
configuration is applied manually, to match your deployment’s specific
needs.
See the authorization properties, as
written to the core-site.xml file.
Now whenever the Fusion UI wants to make a REST call on behalf of
another user, they’ll include a header (tentatively called
proxy.user.name) with the real user. Example curl call:
curl --negotiate -u: -H "proxy.user.name: bob" hostname:8082/fusion/fs
- File system path
-
Enter the full path of the system directory that will be monitored for disk usage.
- Severity level
-
Select a system log severity level (Severe, Warning, Info or Debug) that will correspond with the Disk Capacity Threshold.
| Assigning a monitor with Severe level will impact operation should its trigger Disk Capacity Threshold be met. The affected WD Fusion will immediately shut down to protect its file system from corruption. Ensure that Severe level monitors are set up with a threshold that corresponds with serious risk. Set the threshold too low and you may find WD Fusion nodes are shutdown needlessly. |
- Disk Capacity Threshold (bytes)
-
The maximum amount of data that can be consumed by the selected system path before the monitor sends an alert message to the log file.
- Message
-
A human-readable message that will be sent to the log at the point that the Disk Capacity Threshold is reached.
18. REST API Guide
18.1. API Overview
WD Fusion offers increased control and flexibility through a RESTful (REpresentational State Transfer) API.
Below are listed some example calls that you can use to guide the construction of your own scripts and API driven interactions.
|
API documentation is still in development:
Note that the API documentation is incomplete and requires clarification
of available endpoints.
|
Note the following:
-
All calls use the base URI:
http(s)://<server-host>:8082/fusion/<resource>
-
The internet media type of the data supported by the web service is application/xml.
-
The API is hypertext driven, using the following HTTP methods:
Type |
Action |
POST |
Create a resource on the server |
GET |
Retrieve a resource from the server |
PUT |
Modify the state of a resource |
DELETE |
Remove a resource |
18.1.1. Unsupported operations
As part of Fusion’s replication system, we capture and replicate some "write" operations to an underlying DistributedFileSYstem/FileSystem API. However, there remain some variants of some write operations that are not currently replicated. These exceptions are noted below:
| Operation | Description |
|---|---|
While the mkdirs operation is replicated, mkdir (without the "s") is not. This special "mkdir" method fails if parent dir is missing. we don’t replicate this one. |
|
The DistributedFileSystem replicates the base operation but not its variant
|
|
This is in FileSystem, where the implementation defaults to another method without the |
|
Fusion does not support the truncate command. If run, the filesystem will become inconsistent between clusters. |
|
The |
18.2. Examples
The following examples illustrate some simple use cases, most are direct calls through a web browser, although for deeper or interactive examples, a curl client may be used.
18.2.1. Mount point information
http://<WDFUSION.URL.COM>:8082/fusion/
Calling the mount point output:
Output
<application>
<applicationLocation>.</applicationLocation>
<beaconPeriod>1000</beaconPeriod>
<DConePort>6789</DConePort>
<databaseLocation>/opt/fusion-server/dcone/db</databaseLocation>
<httpPort>8082</httpPort>
<httpsPort>0</httpsPort>
<sslEnabled>false</sslEnabled>
</application>
18.2.2. List all replicated paths
http://<WDFUSION.URL.COM>:8082/fusion/fs
Output
<fsMap>
<replicatedDirectory>
<uri>/repl1</uri>
<membershipId>simpleMembership</membershipId>
<familyRepresentativeId>
<nodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</nodeId>
<dsmId>9bc8170e-e70d-11e4-95f9-ae4369cdbb06</dsmId>
</familyRepresentativeId>
<consistency>
<state>UNKNOWN</state>
<lastCheck>0</lastCheck>
<nextCheck>1429587297002</nextCheck>
</consistency>
<isLeader>true</isLeader>
<isWriter>true</isWriter>
<gsn>407</gsn>
</replicatedDirectory>
</fsMap>
18.2.3. Return a specific replicated path
http://fdbtest-01-vm1.qauk.wandisco.com:8082/fusion/fs?path=<[PATH NAME]
Output
<replicatedDirectory> <uri>/foo1/bar1/baz4</uri> <membershipId>bf0bf386-a878-4205-a16e-8b7f258ab1b0</membershipId> <familyRepresentativeId> <nodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</nodeId> <dsmId>b911c0a9-24ad-11e7-9ba2-fea140f240c9</dsmId> </familyRepresentativeId> <consistencyReport> <state>INCONSISTENT</state> <lastCheckResult>INCONSISTENT</lastCheckResult> <taskId>0c77a086-24e0-11e7-b2f3-fea140f240c9</taskId> <lastCheckTaskId>0c77a086-24e0-11e7-b2f3-fea140f240c9</lastCheckTaskId> <lastCheck>1492593040812</lastCheck> <nextCheck>1492614640812</nextCheck> </consistencyReport> <leader> <nodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</nodeId> <dsmId>b911c0a9-24ad-11e7-9ba2-fea140f240c9</dsmId> </leader> <isLeaderElected>true</isLeaderElected> <isLeader>true</isLeader> <writer> <nodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</nodeId> <dsmId>b911c0a9-24ad-11e7-9ba2-fea140f240c9</dsmId> </writer> <isWriterElected>true</isWriterElected> <isWriter>true</isWriter> <gsn>1174</gsn> <transfersInProgress>0</transfersInProgress> </replicatedDirectory>
18.2.5. Show tasks
http://wdfusion8.ec2.wandisco.com:8082/fusion/tasks
Output
<tasks>
<task xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="membershipProposalTaskDTO">
<taskId>8391e4c7-e803-11e4-b2f1-c62bbea4984d</taskId>
<timeCreated>1429606251844</timeCreated>
<creatorNodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</creatorNodeId>
<timeUpdated>1429606252381</timeUpdated>
<isDone>true</isDone>
<aborted>false</aborted>
<properties>
<entry>
<key>TASK_TYPE</key>
<value>MEMBERSHIP_PROPOSAL_TASK_TYPE</value>
</entry>
</properties>
<previousTask xsi:nil="true"/>
<message>
6ea76f8d-e803-11e4-b2f1-c62bbea4984d, membershipId: simpleMembership, dsmId: 8391e4c8-e803-11e4-b2f1-c62bbea4984d, uri: /repl1
</message>
</task>
<task xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="beaconTaskDTO">
<taskId>6ea76f8d-e803-11e4-b2f1-c62bbea4984d</taskId>
<timeCreated>1429606216697</timeCreated>
<creatorNodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</creatorNodeId>
<timeUpdated>1429606216804</timeUpdated>
<isDone>true</isDone>
<aborted>false</aborted>
<properties>
<entry>
<key>TASK_TYPE</key>
<value>CREATE_MEMBERSHIP_TASK_TYPE</value>
</entry>
</properties>
<previousTask xsi:nil="true"/>
<message>
CreateDistributedMembershipRequest New memberships:[Identity: simpleMembership Distinguished node: wdfs1@location1 Role: acceptor Node: wdfs1@location1 Node: wdfs2@location2 Role: learner Node: wdfs1@location1 Node: wdfs2@location2 Role: proposer Node: wdfs1@location1 Node: wdfs2@location2] TaskId 6ea76f8d-e803-11e4-b2f1-c62bbea4984d sent by Node wdfs1@location1
</message>
</task>
<task xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="ecosystemCommittedTaskDTO">
<taskId>59ae52ca-e803-11e4-88e6-c228c4f805ee</taskId>
<timeCreated>1429606182362</timeCreated>
<creatorNodeId>6ea76f8d-e803-11e4-b2f1-c62bbea4984d</creatorNodeId>
<timeUpdated>1429606184504</timeUpdated>
<isDone>true</isDone>
<aborted>false</aborted>
<properties>
<entry>
<key>induction.final.task.id</key>
<value>59ae52c9-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>TASK_TYPE</key>
<value>induction.commit.task</value>
</entry>
<entry>
<key>induction.identity</key>
<value>59ae52c1-e803-11e4-88e6-c228c4f805ee</value>
</entry>
</properties>
<previousTask>5a305481-e803-11e4-b2f1-c62bbea4984d</previousTask>
</task>
<task xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="membershipProposalTaskDTO">
<taskId>5a7d3c05-e803-11e4-b2f1-c62bbea4984d</taskId>
<timeCreated>1429606182867</timeCreated>
<creatorNodeId>6ea76f8d-e803-11e4-b2f1-c62bbea4984d</creatorNodeId>
<timeUpdated>1429606183518</timeUpdated>
<isDone>true</isDone>
<aborted>false</aborted>
<properties>
<entry>
<key>induction.commit.task.id</key>
<value>59ae52ca-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>inductor.start.task.id</key>
<value>59ae52c7-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>TASK_TYPE</key>
<value>induction.new.learner.task</value>
</entry>
</properties>
<previousTask>5a305481-e803-11e4-b2f1-c62bbea4984d</previousTask>
<message>
AddNewNodesToEcosystem. taskId: 5a7d3c05-e803-11e4-b2f1-c62bbea4984d, creatorNodeId: 6ea76f8d-e803-11e4-b2f1-c62bbea4984d, newMembershipId: ECO-MEMBERSHIP-59addd8f-e803-11e4-88e6-c228c4f805ee, dsmId: ECO-DSM-24f8d34b-e803-11e4-b2f1-c62bbea4984d, newLearnerNodeIds: 4ea76f8d-g803-41e4-v2f1-r62bbea4944d
</message>
</task>
<task xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="beaconTaskDTO">
<taskId>5a305481-e803-11e4-b2f1-c62bbea4984d</taskId>
<timeCreated>1429606182362</timeCreated>
<creatorNodeId>6ea76f8d-e803-11e4-b2f1-c62bbea4984d</creatorNodeId>
<timeUpdated>1429606182888</timeUpdated>
<isDone>true</isDone>
<aborted>false</aborted>
<properties>
<entry>
<key>induction.commit.task.id</key>
<value>59ae52ca-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>inductor.start.task.id</key>
<value>59ae52c7-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>TASK_TYPE</key>
<value>induction.create.new.membership</value>
</entry>
</properties>
<previousTask>59ae52c7-e803-11e4-88e6-c228c4f805ee</previousTask>
<nextTasks>59ae52ca-e803-11e4-88e6-c228c4f805ee</nextTasks>
<nextTasks>5a7d3c05-e803-11e4-b2f1-c62bbea4984d</nextTasks>
<message>
CreateEcosystemMembership. taskId: 5a305481-e803-11e4-b2f1-c62bbea4984d, inductionIdentity: 59ae52c1-e803-11e4-88e6-c228c4f805ee, inductorIdentity: wdfs1, membership: Identity: ECO-MEMBERSHIP-59addd8f-e803-11e4-88e6-c228c4f805ee Distinguished node: wdfs1@location1 Role: acceptor Node: wdfs1@location1 Node: wdfs2@location2 Role: learner Node: wdfs1@location1 Node: wdfs2@location2 Role: proposer Node: wdfs1@location1 Node: wdfs2@location2, nodesInfo: [NodeInfo. nodeIdentity: eac94420-8bd1-40db-8e0d-3f6ccede00d5, nodeName: wdfs1, location: [Location: Identity:location1], ecosystemDsmId: ECO-DSM-24f8d34b-e803-11e4-b2f1-c62bbea4984d, ecosystemMembershipId: ECO-MEMBERSHIP-wdfs1, eventRoutes: [EventRoute:fusion-daily-01-vm1.qauk.wandisco.com:6789], NodeInfo. nodeIdentity: eac94420-8bd1-40db-8e0d-3f6ccede00d5, nodeName: wdfs2, location: [Location: Identity:location2], ecosystemDsmId: ECO-DSM-48b2c9fd-e803-11e4-88e6-c228c4f805ee, ecosystemMembershipId: ECO-MEMBERSHIP-wdfs2, eventRoutes: [EventRoute:fusion-daily-02-vm1.qauk.wandisco.com:6789]], inductionConfiguration: InductionConfiguration{inductorConfig={}, inducteeConfig={}, mergedConfig={}, new seed=59b9019c-e803-11e4-b2f1-c62bbea4984d}, commitTaskId: 59ae52ca-e803-11e4-88e6-c228c4f805ee
</message>
</task>
<task xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:type="dsmProposalTaskDTO">
<taskId>59ae52c7-e803-11e4-88e6-c228c4f805ee</taskId>
<timeCreated>1429606182053</timeCreated>
<creatorNodeId>6ea76f8d-e803-11e4-b2f1-c62bbea4984d</creatorNodeId>
<timeUpdated>1429606182433</timeUpdated>
<isDone>true</isDone>
<aborted>false</aborted>
<properties>
<entry>
<key>induction.inductee.nodes.info</key>
<value>
[NodeInfo. nodeIdentity: eac94420-8bd1-40db-8e0d-3f6ccede00d6, nodeName: wdfs2, location: [Location: Identity:location2], ecosystemDsmId: ECO-DSM-48b2c9fd-e803-11e4-88e6-c228c4f805ee, ecosystemMembershipId: ECO-MEMBERSHIP-wdfs2, eventRoutes: [EventRoute:fusion-daily-02-vm1.qauk.wandisco.com:6789]]
</value>
</entry>
<entry>
<key>induction.final.task.id</key>
<value>59ae52c9-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>induction.commit.task.id</key>
<value>59ae52ca-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>inductor.membership.id</key>
<value>ECO-MEMBERSHIP-wdfs1</value>
</entry>
<entry>
<key>inductor.identity</key>
<value>wdfs1</value>
</entry>
<entry>
<key>induction.eco.system.membership.id</key>
<value>
ECO-MEMBERSHIP-59addd8f-e803-11e4-88e6-c228c4f805ee
</value>
</entry>
<entry>
<key>inductee.membership.id</key>
<value>ECO-MEMBERSHIP-wdfs2</value>
</entry>
<entry>
<key>inductee.identity</key>
<value>wdfs2</value>
</entry>
<entry>
<key>remote.inductor.baton.beacon.task.id</key>
<value>59ae52c5-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>TASK_TYPE</key>
<value>INDUCTION_TASK</value>
</entry>
<entry>
<key>inductor.prepare.asm.id</key>
<value>59ae52c6-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>inductee.location.id</key>
<value>location2</value>
</entry>
<entry>
<key>induction.start.task.id</key>
<value>59ad1a3e-e803-11e4-88e6-c228c4f805ee</value>
</entry>
<entry>
<key>induction.identity</key>
<value>59ae52c1-e803-11e4-88e6-c228c4f805ee</value>
</entry>
</properties>
<previousTask xsi:nil="true"/>
<nextTasks>5a305481-e803-11e4-b2f1-c62bbea4984d</nextTasks>
<message>
PrepareInductorBaton[InductionBaton{taskId=59ae52c7-e803-11e4-88e6-c228c4f805ee, inductionIdentity=59ae52c1-e803-11e4-88e6-c228c4f805ee, dsmId=ECO-DSM-24f8d34b-e803-11e4-b2f1-c62bbea4984d, nodesInfo=[NodeInfo. nodeIdentity: eac94420-8bd1-40db-8e0d-3f6ccede00d5, nodeName: wdfs2, location: [Location: Identity:location2], ecosystemDsmId: ECO-DSM-48b2c9fd-e803-11e4-88e6-c228c4f805ee, ecosystemMembershipId: ECO-MEMBERSHIP-wdfs2, eventRoutes: [EventRoute:fusion-daily-02-vm1.qauk.wandisco.com:6789]], asmIdentity=59ae52c6-e803-11e4-88e6-c228c4f805ee}]
</message>
<dsmId>ECO-DSM-24f8d34b-e803-11e4-b2f1-c62bbea4984d</dsmId>
</task>
</tasks>
18.2.7. Show Nodes
http://<WDFUSION.URL.COM>:8082/fusion/nodes
Output
<nodes>
<node>
<nodeIdentity>eac94420-8bd1-40db-8e0d-3f6ccede00d4</nodeIdentity>
<locationIdentity>location1</locationIdentity>
<isLocal>true</isLocal>
<isUp>true</isUp>
<isStopped>false</isStopped>
<lastStatusChange>1429606531682</lastStatusChange>
<attributes>
<attribute>
<key>eco.system.dsm.identity</key>
<value>ECO-DSM-24f8d34b-e803-11e4-b2f1-c62bbea4984d</value>
</attribute>
<attribute>
<key>node.name</key>
<value>wdfs1</value>
</attribute>
<attribute>
<key>eco.system.membership</key>
<value>
ECO-MEMBERSHIP-59addd8f-e803-11e4-88e6-c228c4f805ee
</value>
</attribute>
</attributes>
</node>
<node>
<nodeIdentity>eac94420-8bd1-40db-8e0d-3f6ccede00d5</nodeIdentity>
<locationIdentity>location2</locationIdentity>
<isLocal>false</isLocal>
<isUp>true</isUp>
<isStopped>false</isStopped>
<lastStatusChange>1429606531699</lastStatusChange>
<attributes>
<attribute>
<key>eco.system.dsm.identity</key>
<value>ECO-DSM-24f8d34b-e803-11e4-b2f1-c62bbea4984d</value>
</attribute>
<attribute>
<key>node.name</key>
<value>wdfs2</value>
</attribute>
<attribute>
<key>eco.system.membership</key>
<value>
ECO-MEMBERSHIP-59addd8f-e803-11e4-88e6-c228c4f805ee
</value>
</attribute>
</attributes>
</node>
</nodes>
18.2.8. Show replicated directories
http://<WDFUSION.URL.COM>:8082/fusion/fs
Show a specific replicated directory
http://<WDFUSION.URL.COM>:8082/dcone/fs?path=/repl1
Add another replicated directory
Create a file called stateMachine.xml for use as payload in the REST API call. Note: membershipId should point to an existing membership:
stateMachine.xml
<replicatedDirectory>
<uri>/repl1</uri>
<membershipId>simpleMembership</membershipId>
<familyRepresentativeId>
<nodeId>f5255a0b-bcfc-40c0-b2a7-64546f571f2a</nodeId>
</familyRepresentativeId>
</replicatedDirectory>
curl call to add it:
curl -v -X POST -d@./stateMachine.xml -H "Content-Type: application/xml" http://<WDFUSION.URL.COM>:8082/fusion/fs
18.2.9. Remove a directory from replication
curl -X DELETE http://<WDFUSION.URL.COM>:8082/fusion/fs?path=/repl1
18.2.10. Remove a node from WD Fusion
The following procedure uses the REST API to remove a node from your WD Fusion enabled cluster.
-
Create an XML file called removal.xml for use as a payload to be delivered to the replicated system using a curl command. The file should contain the following snippet:
<nodes> <node> <nodeIdentity>${NODE_ID}</nodeIdentity> <locationIdentity>${LOCATION_ID}</locationIdentity> </node> </nodes>- NODE_ID
-
The node ID, autogenerated string created for each node during installation, E.g. "eac94420-8bd1-40db-8e0d-3f6ccede00d4".
- LOCATION_ID
-
The location ID of the node that you want to remove from the ecosystem.
You can view these properties by pointing your browser at the node that you want to remove, using the following port and path:
http://<WDFUSION.URL.COM>:8082/fusion/nodes
The curl should be constructed as follows:
curl -u <username>: <password> -X PUT -d @"$removal.xml" --header 'Content-Type: application/xml' http://<WDFUSION.URL.COM>:8082/fusion/node/${LOCAL_NODE_ID}/removenodes
18.2.11. Consistency Check
You can trigger consistency checks through:
curl -v -X POST http://<WDFUSION.URL.COM>:8082/fusion/fs/check?path=/folder_name
Take the taskId returned in the content-location header and view the report with (e.g.)
http://wdfusion2.com:8082/fusion/fs/check/b911241f-c430-11e4-9486-0ebe9eaaf785
The task can also be viewed as usual:
http://<WDFUSION.URL.COM>:8082/dcone/task/b911241f-c430-11e4-9486-0ebe9eaaf785
18.2.12. Writers and Leaders
-
The writer is the "elected leader" for the state machine replicas in a zone, and the leader is the "elected leader" for the entire set of state machine replicas.
-
There are as many writers as there are zones, but only one leader — like a local leader vs global leader.
18.2.13. Repair Status
Gets a list of repairs done or being on done on this zone. Its important to note that this information exists in the node that is or was doing the repair, not the "source-of-truth" or proposing zone.
<host>:8082/fusion/fs/repairs
| Status | Description | Default Value |
|---|---|---|
path |
The path for which the list of repairs should be returned. If null, we will get all repairs. |
null |
showAll |
Whether or not to include past repairs for the same file. The options are true to show all repairs on the given path, and false to show only the last repair. |
false |
sortField |
The field by which the repairs should be sorted. The options are to sort by the startTime, completeTime or path. |
startTime |
sortOrder |
The order in which the entries should be sorted according to the sort field. The options are to sort in ascending (ASC) or descending (DESC) order. |
DESC |