| SSL encryption: |
Basics
WD Fusion supports SSL for any or all of the three channels of communication: Fusion Server - Fusion Server, Fusion Server - Fusion Client, and Fusion Server - IHC Server.
keystore
A keystore (containing a private key / certificate chain) is used by an SSL server to encrypt the communication and create digital signatures.
truststore
A truststore is used by an SSL client for validating certificates sent by other servers. It simply contains certificates that are considered "trusted". For convenience you can use the same file as both the keystore and the truststore, you can also use the same file for multiple processes.
Enabling SSL
Follow these steps to enable SSL: Enable HTTPS
License Model
WD Fusion is supplied through a licensing model based on the number of nodes and data transfer volumes. WANdisco generates a license file matched to your agreed usage model. If your usage pattern changes or if your license period ends then you need to renew your license. See License renewals
- Evaluation license
- To simplify the process of pre-deployment testing, WD Fusion is supplied with an evaluation license (also known as a "trial license"). This type of license imposes limits of usage:
| Source |
Time limit |
No. fusion servers |
No. of Zones |
Replicated Data |
Plugins |
Specified IPs |
| Website |
14 days |
1-2 |
1-2 |
5TB |
No |
No |
- Production license
- Customers entering production need a production license file for each node. These license files are tied to the node's IP address. In the event that a node needs to be moved to a new server with a different IP address customers should contact WANdisco's support team and request that a new license be generated. Production licenses can be set to expire or they can be perpetual.
| Source |
Time limit |
No. fusion servers |
No. of Zones |
Replicated Data |
Plugins |
Specified IPs |
| FD |
variable (default: 1 year) |
variable (default: 20) |
variable (default: 10) |
variable (default: 20TB) |
Yes |
Yes, machine IPs are embedded within the license |
- Unlimited license
-
For large deployments, Unlimited licenses are available, for which there are no usage limits.
License renewals
- The WD Fusion UI provides a warning message whenever you log in.
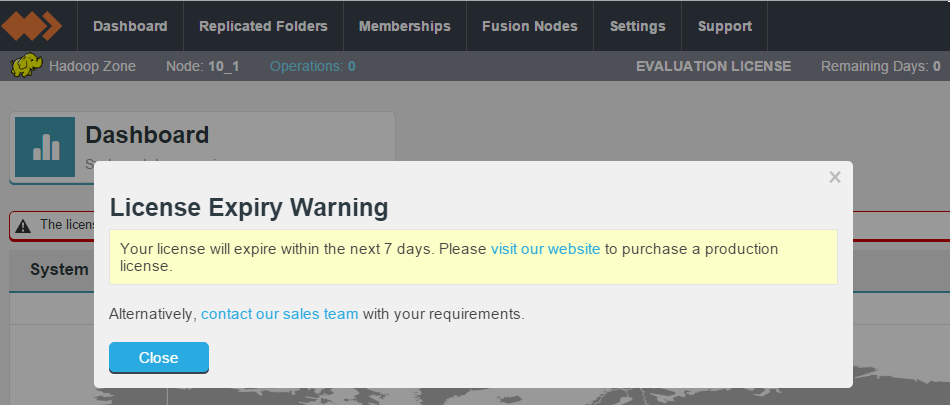
Zone information.
- A warning also appears under the Settings tab on the license Settings panel. Follow the link to the website.
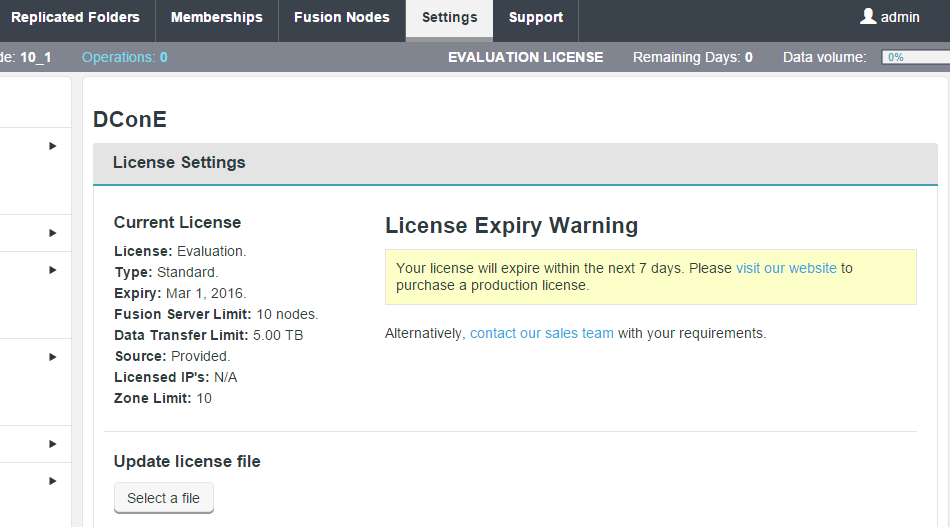
Zone information.
- Complete the form to set out your requirements for license renewal.
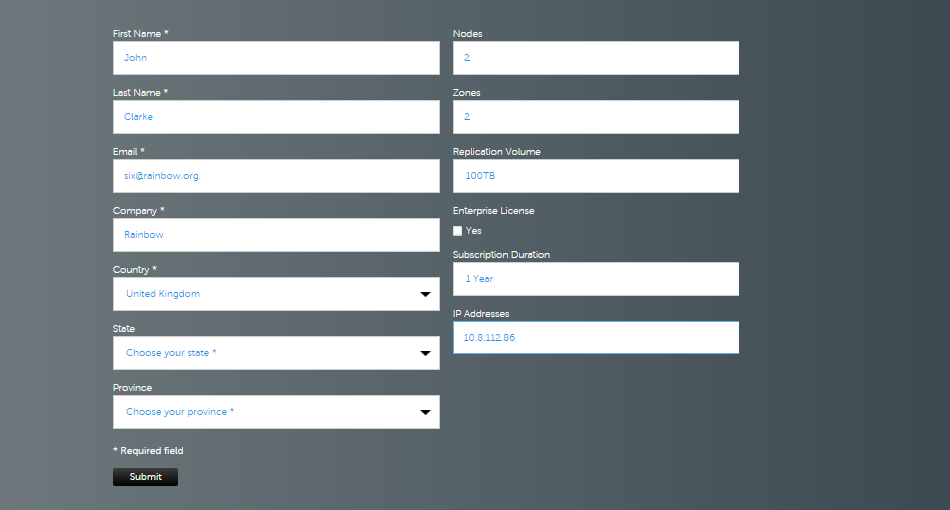
Zone information.
2.1.3 Supported versions
This table shows the versions of Hadoop and Java that we currently support:
| Distribution: |
Console: |
JRE: |
| Apache Hadoop 2.5.0 |
|
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
| HDP 2.1 / 2.2 / 2.3 / 2.4 |
Ambari 1.6.1 / 1.7 / 2.1
Support for EMC Isilon 7.2.0.1 and 7.2.0.2 |
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
| CDH 5.2.0 / 5.3.0 / 5.4 / 5.5 / 5.6 / 5.7 |
Cloudera Manager 5.3.x, 5.4.x, 5.5.x, 5.6.x and 5.7.x
Support for EMC Isilon 7.2.0.1 and 7.2.0.2 |
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
| Pivotal HD 3.0, 3.4 |
Ambari 1.6.1 / 1.7
|
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
| MapR 4.0.x, 4.1.0, 5.0.0 |
Ambari 1.6.1 / 1.7
|
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
| Amazon S3 |
|
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
| IOP (BigInsights) 4.0 / 4.1 |
Ambari 1.7 (with IOP 4.0) / 2.1 (with IOP 4.1)
|
Oracle JDK 1.7 / 1.8 or OpenJDK 7 |
Supported applications
Supported Big Data applications my be noted here, as we complete testing:
| Application: |
Version Supported: |
Tested with: |
| Syncsort DMX-h: |
8.2.4. |
See Knowledge base |
2.2 Final Preparations
We'll now look at what you should know and do as you begin the installation.
Time requirements
The time required to complete a deployment of WD Fusion will in part be based on its size, larger deployments with more nodes and more complex replication rules will take correspondingly more time to set up. Use the guide below to help you plan for for deployments.
- Run through this document and create a checklist of your requirements. (1-2 hours).
- Complete the WD Fusion installation (about 20 minutes per node, or 1 hour for a test deployment).
- Complete client installations and complete basic tests (1-2 hours).
Of course, this is a guideline to help you plan your deployment. You should think ahead and determine if there are additional steps or requirements introduced by your organization's specific needs.
Network requirements
See the deployment checklist for a list of the TCP ports that need to be open for WD Fusion.
Running WD Fusion on multihomed servers
The following guide runs through what you need to do to correctly configure a WD Fusion deployment if the nodes are running with multiple network interfaces.
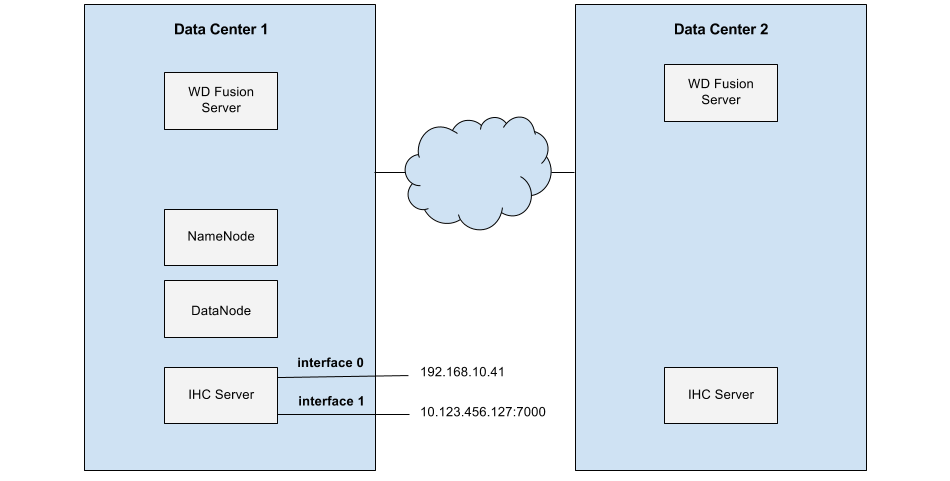
Servers running on multiple networks.
Example:
10.123.456.127 is the public IP Address of the IHC for DC1 and 192.168.10.41 is the private IP address.
The public IP address is configured in two places, both in DC1:
- /etc/wandisco/ihc (for the IHC process) in the IHC machine.
Flow
- A file is created in Data Center 1n (DC1). A Client writes the Data.
- Periodically, after the data is written, a proposal is sent by the WD Fusion Server in Data Center 1 telling the WD Fusion server in Data Center 2 (DC2) to pull the new file.
- Fusion Server in DC2 gets this agreement, connects to 10.123.456.127:7000 and pulls the data.
Getting Connected to the right interface
- Stop all WD Fusion services.
- Reconfigure your IHCs to your preferred address in
/etc/wandisco/ihc/ and /etc/wandisco/fusion.ihc for each IHC node.
- Restart all services
Further discussion
You can read more about setting up on multihomed servers in the Deployment section for Oracle DBA: Operating in a multihomed environment
Kerberos Security
If you are running Kerberos on your cluster you should consider the following requirements:
- Kerberos is already installed and running on your cluster
- Fusion-Server is configured for Kerberos as described in Setting up Kerberos.
Kerberos Configuration before starting the installation
Before running the installer on a platform that is secured by Kerberos, you'll need to run through the following steps:
Setting up Kerberos.
Warning about mixed Kerberized / Non-Kerberized zones
In deployments that mix kerberized and non-kerberized zones it's possible that permission errors will occur because the different zones don't share the same underlying system superusers. In this scenario you would need to ensure that the superuser for each zone is created on the other zones.
For example, if you connect a Zone that runs CDH, which has superuser 'hdfs" with a zone running MapR, which has superuser 'mapr', you would need to create the user 'hdfs' on the MapR zone and 'mapr' on the CDH zone.
Kerberos Relogin Failure with Hadoop 2.6.0 and JDK7u80 or later
Hadoop Kerberos relogin fails silently due to HADOOP-10786. This impacts Hadoop 2.6.0 when JDK7u80 or later is used (including JDK8).
Users should downgrade to JDK7u79 or earlier, or upgrade to Hadoop 2.6.1 or later.
Manual instructions
See the Knowledge Base for instructions on setting up manual Kerberos settings. You only need these in special cases as the steps have been handled by the installer. See Manual Updates for WD Fusion UI Configuration.
See the Knowledge Base for instructions on setting up auth-to-local permissions, mapping a Kerberos principal onto a local system user. See Setting up Auth-to-local.
Clean Environment
Before you start the installation you must ensure that there are no existing WD Fusion installations or WD Fusion components installed on your elected machines. If you are about to upgrade to a new version of WD Fusion you must first make sure that you run through the removal instructions provided in the Appendix - Cleanup WD Fusion.
Ensure HADOOP_HOME is set in the environment
Where the hadoop command isn't in the standard system path, administrators must ensure that the HADOOP_HOME environment variable is set for the root user and the user WD fusion will run as, typically hdfs.
When set, HADOOP_HOME must be the parent of the bin directory into which the Hadoop scripts are installed.
Example: if the hadoop command is:
/opt/hadoop-2.6.0-cdh5.4.0/bin/hadoop
then HADOOP_HOME must be set to /opt/cloudera/parcels/CDH-5.4.5-1.cdh5.4.5.p0.7/bin/hadoop.
Installer File
You need to match WANdisco's WD Fusion installer file to each data center's version of Hadoop. Installing the wrong version of WD Fusion will result in the IHC servers being misconfigured.
License File
After completing an evaluation deployment, you will need to contact WANdisco about getting a license file for moving your deployment into production.
2.3 Running the installer
Below is the procedure for getting set up with the installer. Running the installer only takes a few minutes while you enter the neccessary settings, however, if you wish to handle installations without the need for a user having to manually enter the settings you can use the use the Silent Installer.
Starting the installation
Use the following steps to complete an installation using the installer file. This requires an administrator to enter details throughout the procedure. Once the initial settings are entered through the terminal session, the installation is then completed through a browser or alternatively, using a Silent Installation option to handle configuration programatically.
- Open a terminal session on your first installation server. Copy the WD Fusion installer script into a suitable directory.
- Make the script executable, e.g.
chmod +x fusion-ui-server-<version>_rpm_installer.sh
- Execute the file with root permissions, e.g.
sudo ./fusion-ui-server-<version>_rpm_installer.sh
- The installer will now start.
Verifying archive integrity... All good.
Uncompressing WANdisco Fusion..............................
:: :: :: # # ## #### ###### # ##### ##### #####
:::: :::: ::: # # # # ## ## # # # # # # # # #
::::::::::: ::: # # # # # # # # # # # # # #
::::::::::::: ::: # # # # # # # # # # # ##### # # #
::::::::::: ::: # # # # # # # # # # # # # # #
:::: :::: ::: ## ## # ## # # # # # # # # # # #
:: :: :: # # ## # # # ###### # ##### ##### #####
Welcome to the WANdisco Fusion installation
You are about to install WANdisco Fusion version 2.4-206
Do you want to continue with the installation? (Y/n) y
The installer will perform an integrity check, confirm the product version that will be installed, then invite you to continue. Enter "Y" to continue the installation.
- The installer performs some basic checks and lets you modify the Java heap settings. The heap settings apply only to the WD Fusion UI.
Checking prerequisites:
Checking for perl: OK
Checking for java: OK
INFO: Using the following Memory settings:
INFO: -Xms128m -Xmx512m
Do you want to use these settings for the installation? (Y/n) y
The installer checks for Perl and Java. See the Installation Checklist for more information about these requirements. Enter "Y" to continue the installation.
- Next, confirm the port that will be used to access WD Fusion through a browser.
Which port should the UI Server listen on? [8083]:
- Select the Hadoop version and type from the list of supported platforms:
Please specify the appropriate backend from the list below:
[0] cdh-5.2.0
[1] cdh-5.3.0
[2] cdh-5.4.0
[3] cdh-5.5.0
[4] hdp-2.1.0
[5] hdp-2.2.0
[6] hdp-2.3.0
Which fusion backend do you wish to use? 3
You chose hdp-2.2.0:2.6.0.2.2.0.0-2041
MapR/Pivotal availability
The MapR/PHD versions of Hadoop have been removed from the trial version of WD Fusion in order to reduce the size of the installer for most prospective customers. These versions are run by a small minority of customers, while their presence nearly doubled the size of the installer package. Contact WANdisco if you need to evaluate WD Fusion running with MapR or PHD.
Additional available packages
[1] mapr-4.0.1
[2] mapr-4.0.2
[3] mapr-4.1.0
[4] mapr-5.0.0
[5] phd-3.0.0
MapR requirements
URI
MapR needs to use WD Fusion's native "fusion:///" URI, instead of the default hdfs:///. Ensure that during installation you select the Use WD Fusion URI with HCFS file system URI option.
Superuser
If you install into a MapR cluster then you need to assign the MapR superuser system account/group "mapr" if you need to run WD Fusion using the fusion:/// URI.
See the requirement for MapR Client Configuration.
See the requirement for MapR impersonation.
When using MapR and doing a TeraSort run, if one runs without the simple partitioner configuration, then the YARN containers will fail with a Fusion Client ClassNotFoundException. The remedy is to set "yarn.application.classpath" on each node's yarn-site.xml. FUI-1853
- The installer now confirms which system user/group will be applied to WD Fusion.
We strongly advise against running Fusion as the root user.
For default HDFS setups, the set to 'hdfs'. However, you should choose a user appropriate for running HDFS commands on your system.
Which user should Fusion run as? [hdfs]
Checking 'hdfs' ...
... 'hdfs' found.
Please choose an appropriate group for your system. By default HDP uses the 'hadoop' group.
Which group should Fusion run as? [hadoop]
Checking 'hadoop' ...
... 'hadoop' found.
The installer does a search for the commonly used account and group, assigning these by default.
- Check the summary to confirm that your chosen settings are appropriate:
Installing with the following settings:
User and Group: hdfs:hadoop
Hostname: node04-example.host.com
Fusion Admin UI Listening on: 0.0.0.0:8083
Fusion Admin UI Minimum Memory: 128
Fusion Admin UI Maximum memory: 512
Platform: hdp-2.3.0 (2.7.1.2.3.0.0-2557)
Manager Type AMBARI
Manager Host and Port: :
Fusion Server Hostname and Port: node04-example.host.com:8082
SSL Enabled: false
Do you want to continue with the installation? (Y/n) y
You are now given a summary of all the settings provided so far. If these settings are correct then enter "Y" to complete the installation of the WD Fusion server.
- The package will now install
Installing hdp-2.1.0 packages:
fusion-hdp-2.1.0-server-2.4_SNAPSHOT-1130.noarch.rpm ...
Done
fusion-hdp-2.1.0-ihc-server-2.4_SNAPSHOT-1130.noarch.rpm ...
Done
Installing fusion-ui-server package
Starting fusion-ui-server:[ OK ]
Checking if the GUI is listening on port 8083: .....Done
- The WD Fusion server will now start up:
Please visit http://<YOUR-SERVER-ADDRESS>.com:8083/ to access the WANdisco Fusion
If 'http://<YOUR-SERVER-ADDRESS>.com' is internal or not available from your browser, replace this with an externally available address to access it.
Installation Complete
[root@node05 opt]#
At this point the WD Fusion server and corresponding IHC server will be installed. The next step is to configure the WD Fusion UI through a browser or using the silent installation script.
Configure WD Fusion through a browser
Follow this section to complete the installation by configuring WD Fusion using a browser-based graphical user interface.
Open a web browser and point it at the provided URL. e.g
http://<YOUR-SERVER-ADDRESS>.com:8083/
- In the first "Welcome" screen you're asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows:
- Adding a new WD Fusion cluster
- Select Add Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
- Select Add to an existing Zone.
High Availability for WD Fusion / IHC Servers
It's possible to enable High Availability in your WD Fusion cluster by adding additional WD Fusion/IHC servers to a zone. These additional nodes ensure that in the event of a system outage, there will remain sufficient WD Fusion/IHC servers running to maintain replication.
Add HA nodes to the cluster using the installer and choosing to Add to an existing Zone, using a new node name.
Configuration for High Availability
When setting up the configuration for a High Availability cluster, ensure that fs.defaultFS, located in the core-site.xml is not duplicated between zones. This property is used to determine if an operation is being executed locally or remotely, if two separate zones have the same default file system address, then problems will occur. WD Fusion should never see the same URI (Scheme + authority) for two different clusters.
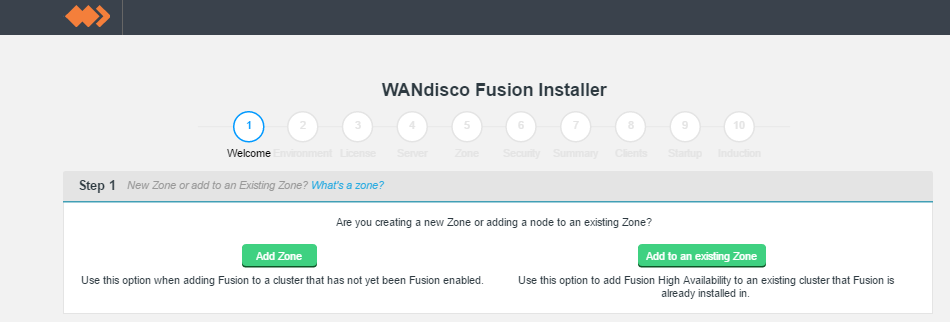
Welcome.
- Run through the installer's detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
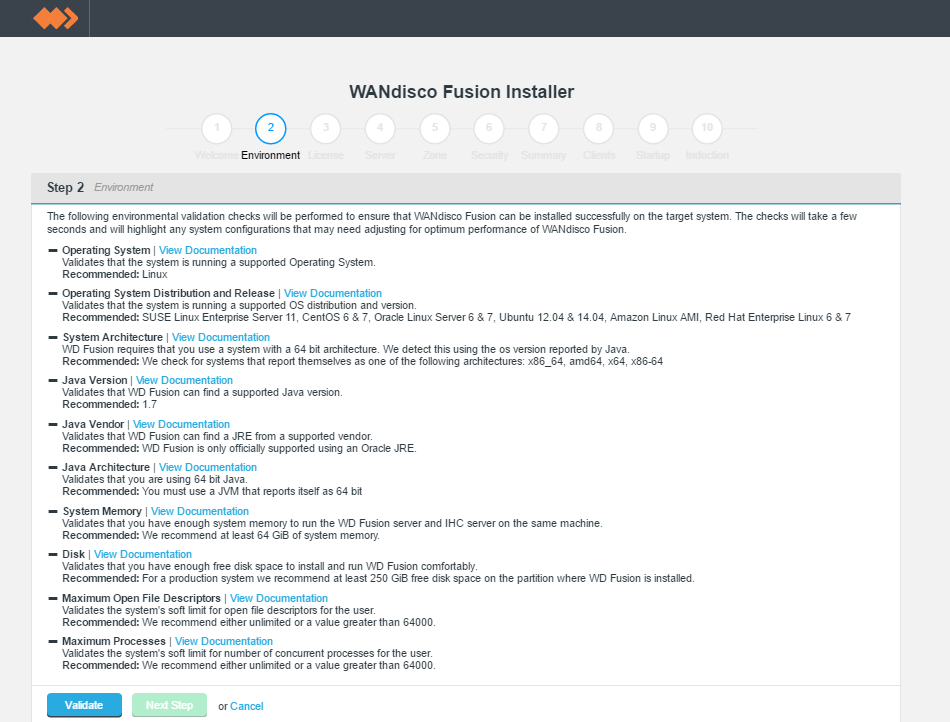
Environmental checks.
On clicking validate the installer will run through a series of checks of your system's hardware and software setup and warn you if any of WD Fusion's prerequisites are missing.

Example check results.
Any element that fails the check should be addressed before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if the installation is only for evaluation purposes and not for production. However, when installing for production, you should also address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
- Upload the license file.
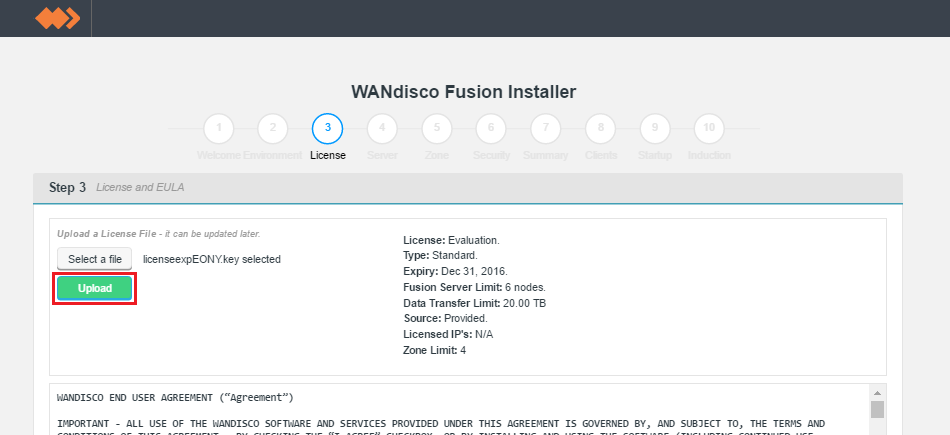
Upload your license file.
- The conditions of your license agreement will be presented in the top panel, including License Type, Expiry data, Name Node Limit and Data Node Limit.
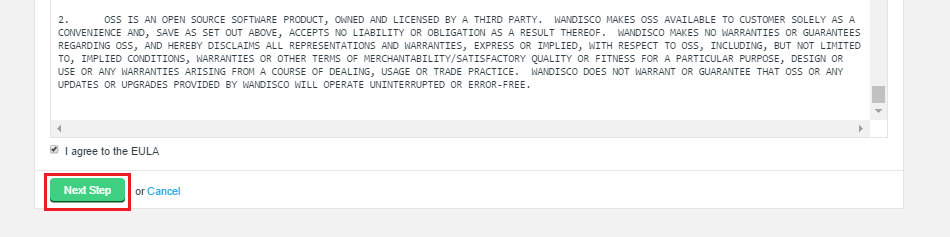
Verify license and agree to subscription agreement.
Click on the I agree to the EULA to continue, then click Next Step.
- Enter settings for the WD Fusion server.
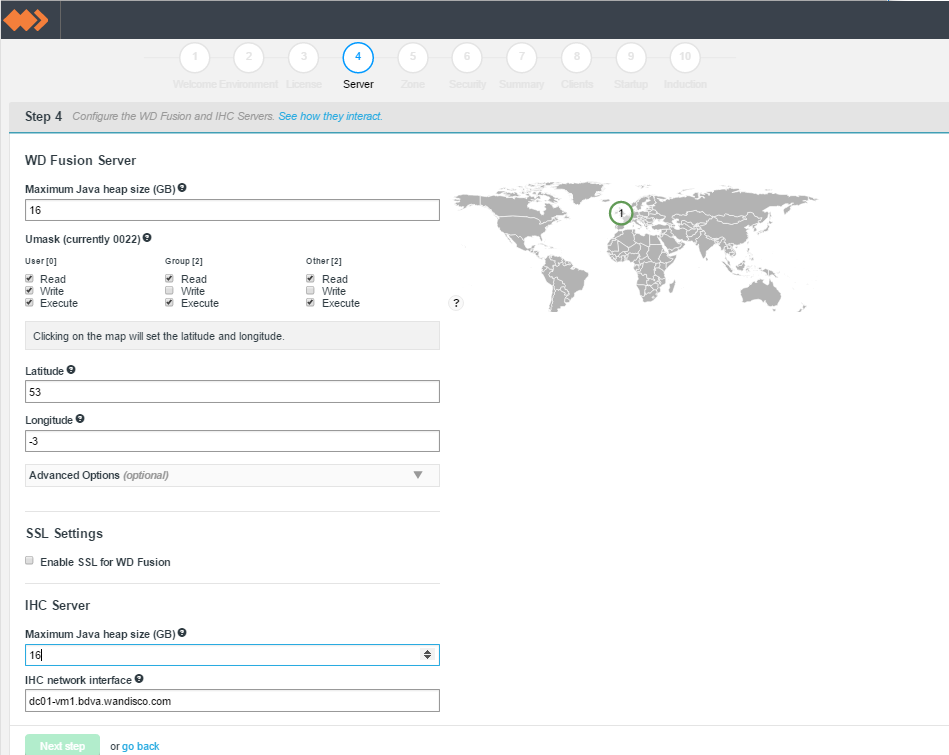
screen 4 - Server settings
WD Fusion Server
- Maximum Java heap size (GB)
- Enter the maximum Java Heap value for the WD Fusion server.
- Umask (currently 022)
- Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
- Latitude
- The north-south coordinate angle for the installation's geographical location.
- Longitude
- The east-west coordinate angle for the installation's geographical location. The latitude and longitude is used to place the WD Fusion server on a global map to aid coordination in a far-flung cluster.
Alternatively, you can click on global map to locate the node.
Advanced options
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments. The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco's support team before enabling them.
- Custom UI hostname
- Lets you set a custom hostname for the Fusion UI, distinct from the communication.hostname which is already set as part of the install and used by WD Fusion nodes to connect to the Fusion server.
- Custom UI Port
- Lets to change WD Fusion UI's default port, in case it is assigned elsewhere, e.g. Cloudera's headamp debug server also uses it.
- Strict Recovery
- See explanation of the Strict Recovery Advanced Options.
Enable SSL for WD Fusion
Tick the checkbox to enable SSL

- KeyStore Path
- System file path to the keystore file.
e.g. /opt/wandisco/ssl/keystore.ks
- KeyStore Password
- Encrypted password for the KeyStore.
e.g. ***********
- Key Alias
- The Alias of the private key.
e.g. WANdisco
- Key Password
- Private key encrypted password.
e.g. ***********
- TrustStore Path
- System file path to the TrustStore file.
/opt/wandisco/ssl/keystore.ks
- TrustStore Password
- Encrypted password for the TrustStore.
e.g. ***********
IHC Server
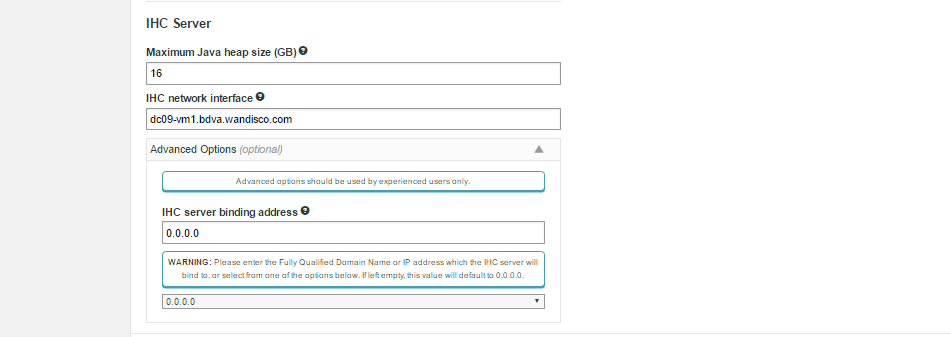
IHC Settings
- Maximum Java heap size (GB)
- Enter the maximum Java Heap value for the WD Inter-Hadoop Communication server.
- IHC network interface
- The hostname for the IHC server.
Advanced Options (optional)
- IHC server binding address
- In the advanced settings you can decides which address the IHC server will bind to. The address is optional, by default the IHC server binds to all interfaces (0.0.0.0), using the port specified in the
ihc.server field. In all cases the port should be identical to the port used in the ihc.server address. i.e. /etc/wandisco/fusion/ihc/server/cdh-5.4.0/2.6.0-cdh5.4.0.ihc
or /etc/wandisco/fusion/ihc/server/localfs-2.7.0/2.7.0.ihc
Once all settings have been entered, click Next step.
- Next, you will enter the settings for your new Zone.
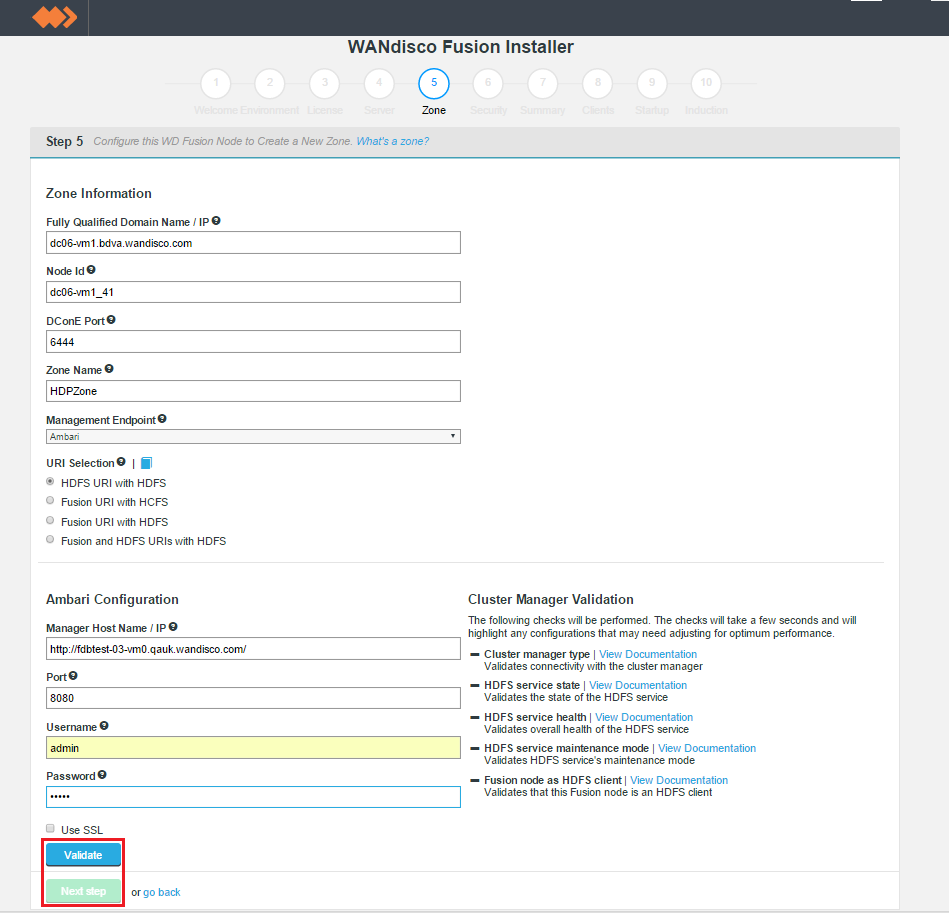
New Zone
Zone Information
Entry fields for zone properties
- Fully Qualified Domain Name
- the full hostname for the server.
- Node ID
- A unique identifier that will be used by WD Fusion UI to identify the server.
- Location Name (optional)
- A location name that can quickly identify where the server is located.
Induction failure
If induction fails, attempting a fresh installation may be the most straight forward cure, however, it is possible to push through an induction manually, using the REST API. See Handling Induction Failure.
Known issue with Location names
You must use different Location names /Node IDs for each zone. If you use the same name for multiple zones then you will not be able to complete the induction between those nodes.
- DConE Port
- TCP port used by WD Fusion for replicated traffic.
- Zone Name
- The name used to identify the zone in which the server operates.
- Management Endpoint
- Select the Hadoop manager that you are using, i.e. Cloudera Manager, Ambari or Pivotal HD. The selection will trigger the entry fields for your selected manager:
Advanced Options
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments. The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco's support team before enabling them.
URI Selection
The default behavior for WD Fusion is to fix all replication to the Hadoop Distributed File System / hdfs:/// URI. Setting the hdfs-scheme provides the widest support for Hadoop client applications, since some applications can't support the available "fusion:///" URI they can only use the HDFS protocol. Each option is explained below:
- Use HDFS URI with HDFS file system

This option is available for deployments where the Hadoop applications support neither the WD Fusion URI or the HCFS standards. WD Fusion operates entirely within HDFS.
This configuration will not allow paths with the fusion:// uri to be used; only paths starting with hdfs:// or no scheme that correspond to a mapped path will be replicated. The underlying file system will be an instance of the HDFS DistributedFileSystem, which will support applications that aren't written to the HCFS specification.- Use WD Fusion URI with HCFS file system
-

When selected, you need to use fusion:// for all data that must be replicated over an instance of the Hadoop Compatible File System. If your deployment includes Hadoop applications that are either unable to support the Fusion URI or are not written to the HCFS specfication, this option will not work.
MapR deployments
Use this URI selection if you are installing into a MapR cluster.
- Use Fusion URI with HDFS file system

This differs from the default in that while the WD Fusion URI is used to identify data to be replicated, the replication is performed using HDFS itself. This option should be used if you are deploying applications that can support the WD Fusion URI but not the Hadoop Compatible File System.- Use Fusion URI and HDFS URI with HDFS file system

This "mixed mode" supports all the replication schemes (fusion://, hdfs:// and no scheme) and uses HDFS for the underlying file system, to support applications that aren't written to the HCFS specification.
Fusion Server API Port
This option lets you select the TCP port that is used for WD Fusion's API.
Strict Recovery
Two advanced options are provided to change the way that WD Fusion responds to a system shutdown where WD Fusion was not shutdown cleanly. Currently the default setting is to not enforce a panic event in the logs, if during startup we detect that WD Fusion wasn't shutdown. This is suitable for using the product as part of an evaluation effort. However, when operating in a production environment, you may prefer to enforce the panic event which will stop any attempted restarts to prevent possible corruption to the database.
- DConE panic if dirty (checkbox)
- This option lets you enable the strict recovery option for WANdisco's replication engine, to ensure that any corruption to its prevayler database doesn't lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
- App Integration panic of dirty (checkbox)
- This option lets you enable the strict recovery option for WD Fusion's database, to ensure that any corruption to its internal database doesn't lead to further problems. When the checkbox is ticked, WD Fusion will log a panic message whenever WD Fusion is not properly shutdown, either due to a system or application problem.
<Hadoop Management Layer> Configuration
This section configures WD Fusion to interact with the management layer, which could be Ambari or Cloudera Manager, etc.
- Manager Host Name /IP
- The full hostname or IP address for the working server that hosts the Hadoop manager.
- Port
- TCP port on which the Hadoop manager is running.
- Username
- The username of the account that runs the Hadoop manager.
- Password
- The password that corresponds with the above username.
- SSL
- (Checkbox) Tick the SSL checkbox to use
https in your Manager Host Name and Port. You may be prompted to update the port if you enable SSL but don't update from the default http port.
Authentication without a management layer
WD Fusion normally uses the authentication built into your cluster's management layer, i.e. the Cloudera Manager username and password are required to login to WD Fusion. However, in Cloud-based deployments, such as Amazon's S3, there is no management layer. In this situation, WD Fusion adds a local user to WD Fusion's ui.properties file, either during the silent installation or through the command-line during an installation.
Should you forget these credentials, see Reset internally managed password
- Enter security details, if applicable to your deployment.
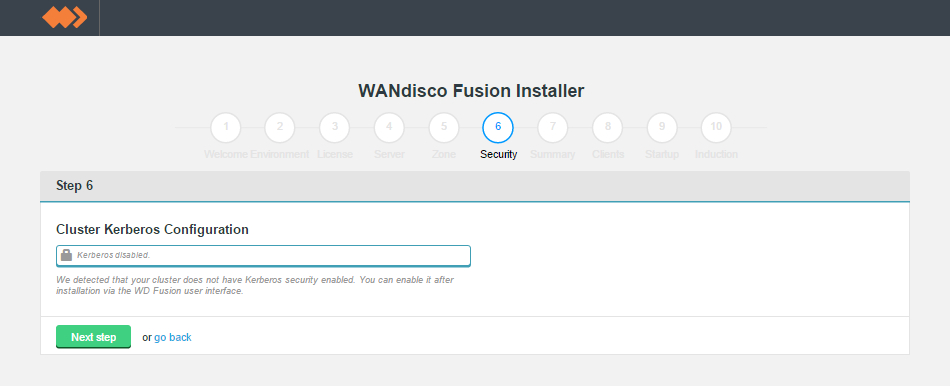
Kerberos Configuration
In this step you also set the configuration for an existing Kerberos setup. If you are installing into a Kerberized cluster, include the following configuration.
Enabling Kerberos authentication on WD Fusion's REST API
When a user has enabled Kerberos-authentication on their REST API, they must kinit before making REST calls, and enable GSS-Negotiate authentication. To do this with curl, the user must include the "-negotiate" and "-u:" options, like so:
curl --negotiate -u: -X GET "http://${HOSTNAME}:8082/fusion/fs/transfers"
See Setting up Kerberos for more information about Kerberos setup.
- Click Validate to confirm that your settings are valid. Once validated, click Next step.
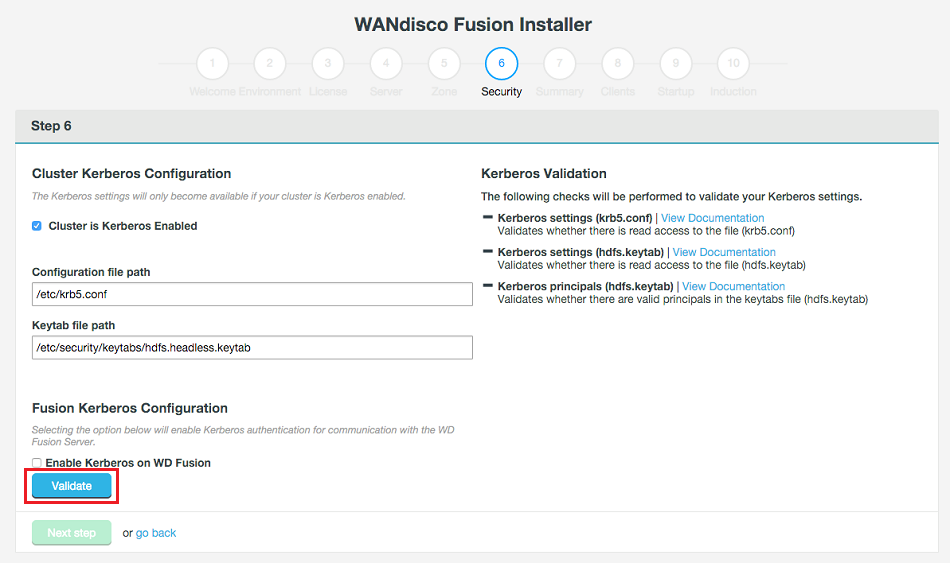
Zone information.
- The remaining panels in step 6 detail all of the installation settings. All your license, WD Fusion server, IHC server and zone settings are shown. If you spot anything that needs to be changed you can click on the go back
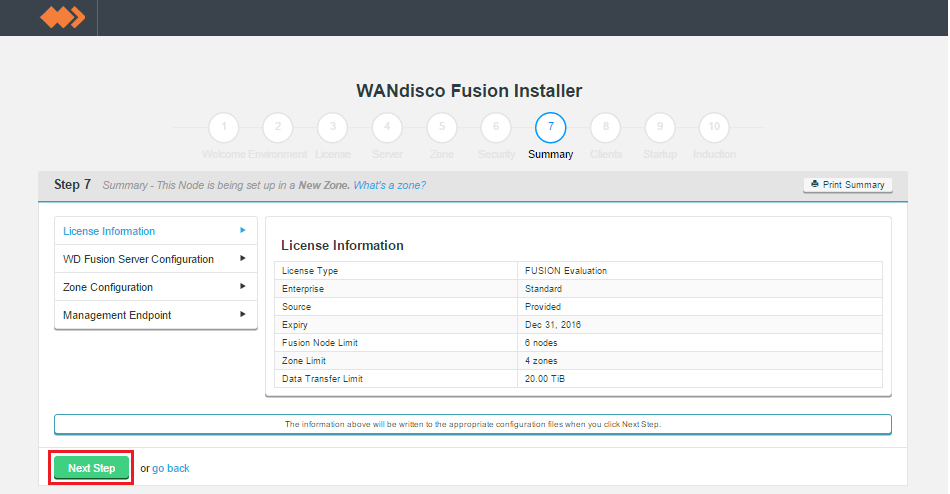
Summary
Once you are happy with the settings and all your WD Fusion clients are installed, click Deploy Fusion Server.
WD Fusion Client Installation
- In the next step you must complete the installation of the WD Fusion client package on all the existing HDFS client machines in the cluster. The WD Fusion client is required to support data WD Fusion's replication across the Hadoop ecosystem.
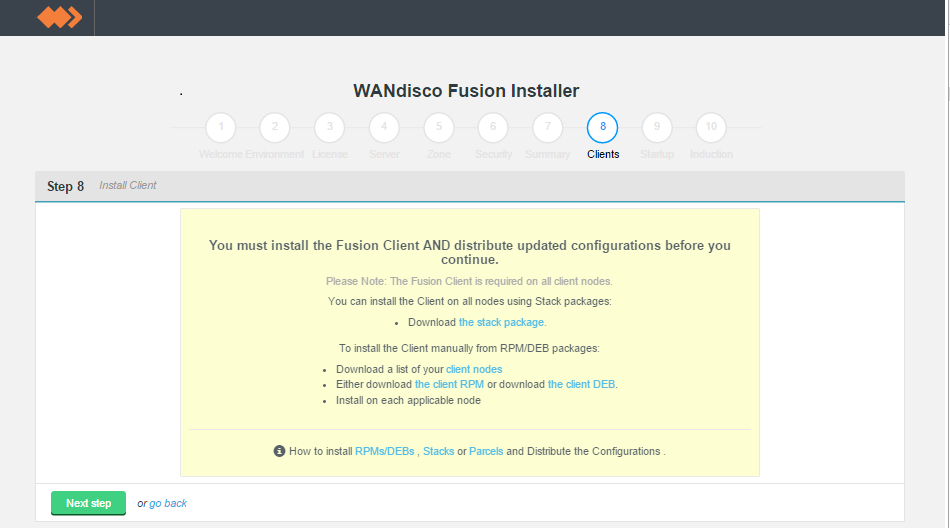
Client installations.
The installer supports three different packaging systems for installing Clients, regular RPMs, Parcels for Cloudera and HDP Stack for Hortonworks/Ambari.
client package location
You can find them in your installation directory, here:
/opt/wandisco/fusion-ui-server/ui/client_packages
/opt/wandisco/fusion-ui-server/ui/stack_packages
/opt/wandisco/fusion-ui-server/ui/parcel_packages
RPM / DEB Packages
client nodes
By client nodes we mean any machine that is interacting with HDFS that you need to form part of WD Fusion's replicated system. If a node is not going to form part of the replicated system then it won't need the WD Fusion client installed. If you are hosting the WD Fusion UI package on a dedicated server, you don't need to install the WD Fusion client on it as the client is built into the WD Fusion UI package. Note that in this case the WD Fusion UI server would not be included in the list of participating client nodes.
Important! If you are installing on Ambari 1.7 or CHD 5.3.x
Additionally, due to a bug in Ambari 1.7, and an issue with the classpath in CDH 5.3.x, before you can continue you must log into Ambari/Cloudera Mananger and complete a restart of HDFS, in order to re-apply WD Fusion's client configuration.
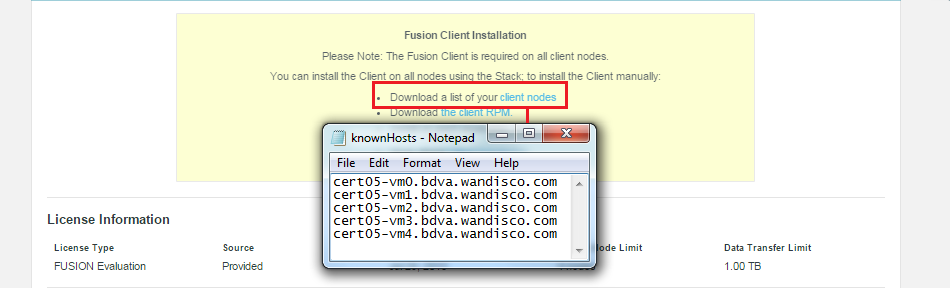
Example clients list
For more information about doing a manual installation, see Fusion Client installation for regular RPMs.
To install with the Cloudera parcel file, see: Fusion Client installation with Parcels.
For Hortonwork's own proprietary packaging format: Fusion Client installation with HDP Stack.
- The next step starts WD Fusion up for the first time. You may receive a warning message if your clients have not yet been installed. You can now address any client installations, then click Revalidate Client Install to make the warning go away. If everything is setup correctly you can click Start WD Fusion.
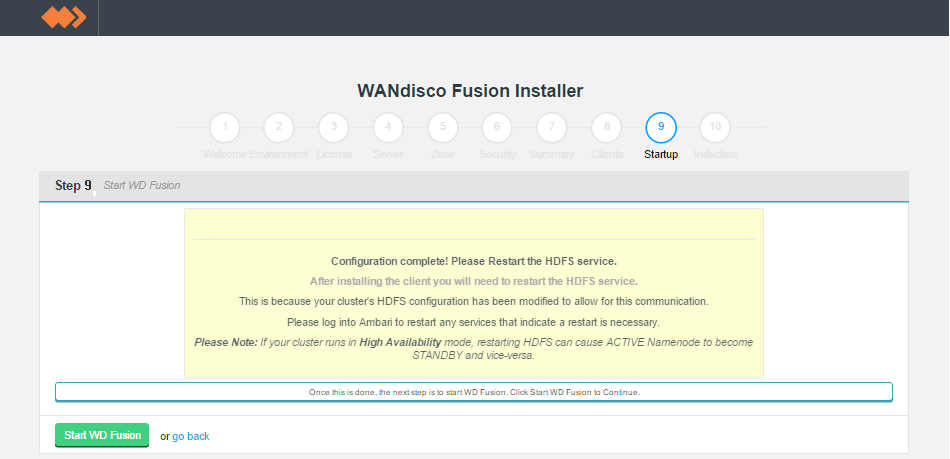 Skip or start.
- If you are installing onto a platform that is running Ambari (HDP or Pivotal HD), once the clients are installed you should login to Ambari and restart any services that are flagged as waiting for a restart. This will apply to MapReduce and YARN, in particular.
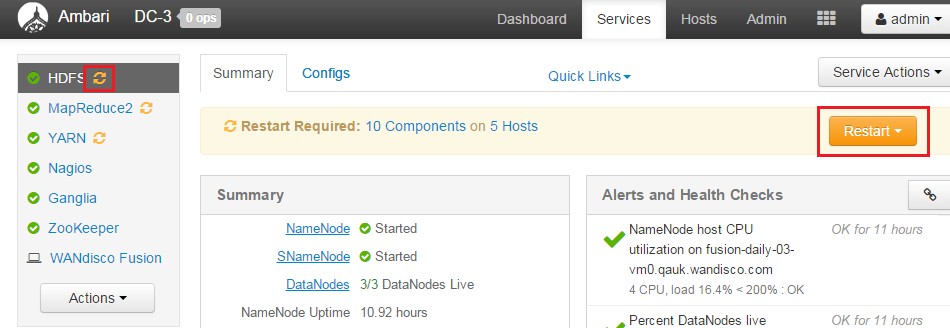
restart to refresh config
- If you are running Ambari 1.7, you'll be prompted to confirm this is done.

Confirm that you have completed the restarts
Important! If you are installing on Ambari 1.7 or CHD 5.3.x
Additionally, due to a bug in Ambari 1.7, and an issue with the classpath in CDH 5.3.x, before you can continue you must log into Ambari/Cloudera Mananger and complete a restart of HDFS, in order to re-apply WD Fusion's client configuration.
First WD Fusion node installation
When installing WD Fusion for the first time, this step is skipped. Click Skip Induction.
Second and subsequent WD Fusion node installations into an existing zone
When adding a node to an existing zone, users will be prompted for zone details at the start of the installer and induction will be handled automatically. Nodes added to a new zone will have the option of being inducted at the end of the install process where the user can add details of the remote node.
Induction failure due to HADOOP-11461
There's a known bug in Jersey 1.9, covered in HADOOP-11461 which can result in the failure of WD Fusion's induction.
Workaround:
- Open the file
/etc/wandisco/fusion/server/log4j.properties in an editor.
- Add the following property:
log4j.logger.com.sun.jersey.server.wadl.generators.WadlGeneratorJAXBGrammarGenerator=OFF
- Save the file and retry the induction.
Known issue with Location names
You must use different Location names /IDs for each zone. If you use the same name for multiple zones then you will not be able to complete the induction between those nodes.
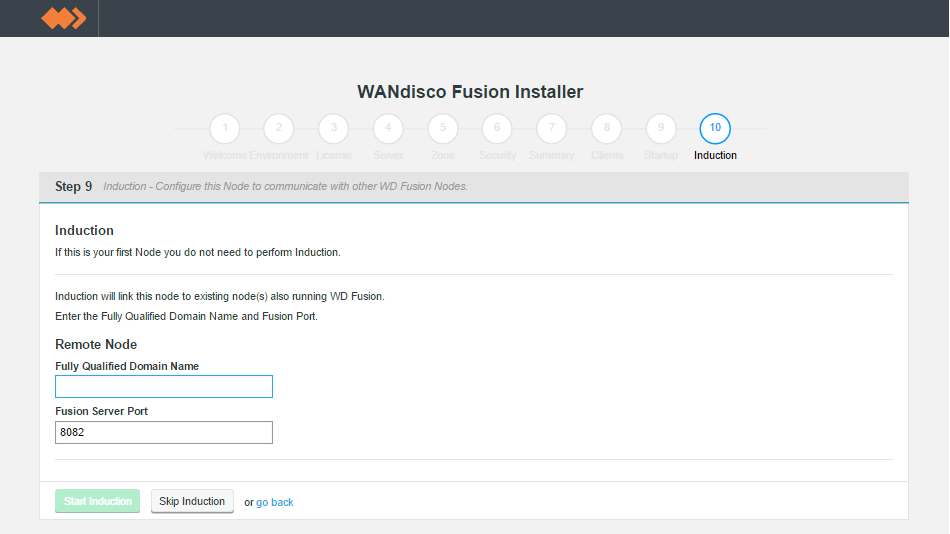
Induction.
- Once the installation is complete you will get access to the WD Fusion UI, once you log in using your Hadoop manager username and password.
WD Fusion UI
2.4 Configuration
Once WD Fusion has been installed on all data centers you can proceed with setting up replication on your HDFS file system. You should plan your requirements ahead of the installation, matching up your replication with your cluster to maximise performance and resilience. The next section will take a brief look at a example configuration and run through the necessary steps for setting up data replication between two data centers.
Replication Overview

Example WD Fusion deployment in a 3 data center deployment.
In this example, each one of three data centers ingests data from it's own datasets, "Weblogs", "phone support" and "Twitter feed". An administrator can choose to replicate any or all of these data sets so that the data is replicated across any of the data centers where it will be available for compute activities by the whole cluster. The only change required to your Hadoop applications will be the addition of a replication specific URI, and this will only be a requirement if you are using HCFS rather than the native HDFS protocal.
Setting up Replication
The following steps are used to start replicating hdfs data. The detail of each step will depend on your cluster setup and your specific replication requirements, although the basic steps remain the same.
- Create a membership including all the data centers that will share a particular directory. See Create Membership
- Create and configure a Replicated Folder. See Replicated Folders
- Perform a consistency check on your replicated folder. See Consistency Check
- Configure your Hadoop applications to use WANdisco's protocol. See Configure Hadoop for WANdisco replication
- Run Tests to validate that your replicated folder remains consistent while data is being written to each data center. See Testing replication
You can't move files between replicated directories
Currently you can't perform a straight move operation between two separate replicated directories.
Installing on a Kerberized cluster
The Installer lets you configure WD Fusion to use your platform's Kerberos implementation. You can find supporting information about how WD Fusion handles Kerberos in the Admin Guide, see Setting up Kerberos.
2.5 Deployment
The deployment section covers the final step in setting up a WD Fusion cluster, where supported Hadoop applications are plugged into WD Fusion's synchronized distributed namespace. It won't be possible to cover all the requirements for all the third-party software covered here, we strongly recommend that you get hold of the corresponding documenation for each Hadoop application before you work through these procedures.
2.5.1 Hive
This guide integrates WD Fusion with Apache Hive, it aims to accomplish the following goals:
- Replicate Hive table storage.
- Use fusion URIs as store paths.
- Use fusion URIs as load paths.
- Share the Hive metastore between two clusters.
Prerequisites
- Knowledge of Hive architecture.
- Ability to modify Hadoop site configuration.
- WD Fusion installed and operating.
Replicating Hive Storage via fusion:///
The following requirements come into play if you have deployed WD Fusion using with its native fusion:/// URI. In order to store a Hive table in WD Fusion you specify a WD Fusion URI when creating a table. E.g. consider creating a table called log that will be stored in a replicated directory.
CREATE TABLE log(requestline string) stored as textfile location 'fusion:///repl1/hive/log';
Note: Replicating table storage without sharing the Hive metadata will create a logical discrepancy in the Hive catalog. For example, consider a case where a table is defined on one cluster and replicated on the HCFS to another cluster. A Hive user on the other cluster would need to define the table locally in order to make use of it.
Exceptions
Hive from CDH 5.3/5.4 does not work with WD Fusion, (because of HIVE-9991). To get it working with CDH 5.3 and 5.4. you need to modify the default Hive file system setting. In Cloudera Manager, add the following property to hive-site.xml:
<property>
<name>fs.defaultFS</name>
<value>fusion:///</value>
</property>
This property should be added in 3 areas:
- Service Wide
- GateWay Group
- Hiveserver2 group
Replicated directories as store paths
It's possible to configure Hive to use WD Fusion URIs as output paths for storing data, to do this you must specify a Fusion URI when writing data back to the underlying Hadoop-compatible file system (HCFS). For example, consider writing data out from a table called log to a file stored in a replicated directory:
INSERT OVERWRITE DIRECTORY 'fusion:///repl1/hive-out.csv' SELECT * FROM log;
Replicated directories as load paths
In this section we'll describe how to configure Hive to use fusion URIs as input paths for loading data.
It is not common to load data into a Hive table from a file using the fusion URI. When loading data into Hive from files the core-site.xml setting fs.default.name must also be set to fusion, which may not be desirable. It is much more common to load data from a local file using the LOCAL keyword:
LOAD DATA LOCAL INPATH '/tmp/log.csv' INTO TABLE log;
If you do wish to use a fusion URI as a load path, you must change the fs.defaultFS setting to use WD Fusion, as noted in a previous section. Then you may run:
LOAD DATA INPATH 'fusion:///repl1/log.csv' INTO TABLE log;
Sharing the Hive metastore
Advanced configuration - please contact WANdisco before attempting
In this section we'll describe how to share the Hive metastore between two clusters. Since WANdisco Fusion can replicate the file system that contains the Hive data storage, sharing the metadata presents a single logical view of Hive to users on both clusters.
When sharing the Hive metastore, note that Hive users on all clusters will know about all tables. If a table is not actually replicated, Hive users on other clusters will experience errors if they try to access that table.
There are two options available.
Hive metastore available read-only on other clusters
In this configuration, the Hive metastore is configured normally on one cluster. On other clusters, the metastore process points to a read-only copy of the metastore database. MySQL can be used in master-slave replication mode to provide the metastore.
Hive metastore writable on all clusters
In this configuration, the Hive metastore is writable on all clusters.
- Configure the Hive metastore to support high availability.
- Place the standby Hive metastore in the second data center.
- Configure both Hive services to use the active Hive metastore.
Performance over WAN
Performance of Hive metastore updates may suffer if the writes are routed over the WAN.
Hive metastore replication
There are three strategies for replicating Hive metastore data with WD Fusion:
Standard
For Cloudera CDH: See Hive Metastore High Availability.
For Hortonworks/Ambari: High Availability for Hive Metastore.
Manual Replication
In order to manually replicate metastore data ensure that the DDLs are placed on two clusters, and perform a partitions rescan.
2.5.2 Impala
Prerequisites
- Knowledge of Impala architecture.
- Ability to modify Hadoop site configuration.
- WD Fusion installed and operating.
Impala Parcel
Also provided in a parcel format is the WANdisco compatible version of Cloudera's Impala tool:
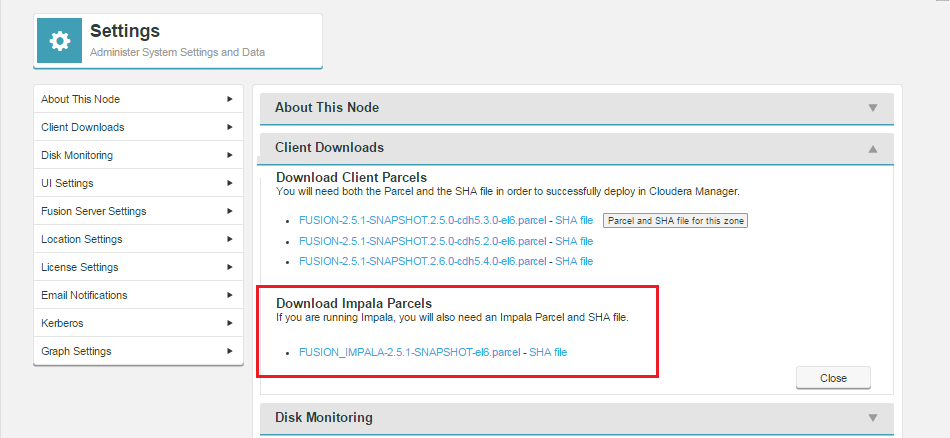
Ready to distribute.
Follow the same steps described for installing the WD Fusion client, downloading the parcel and SHA file, i.e.:
- Have cluster with CDH installed with parcels and Impala.
- Copy the
FUSION_IMPALA parcel and SHA into the local parcels repository, on the same node where Cloudera Manager Services is installed, this need not be the same location where the Cloudera Manager Server is installed. The default location is at: /opt/cloudera/parcel-repo, but is configurable. In Cloudera Manager, you can go to the Parcels Management Page -> Edit Settings to find the Local Parcel Repository Path. See Parcel Locations.
FUSION_IMPALA should be available to distribute and activate on the Parcels Management Page, remember to click Check for New Parcels button.
- Once installed, restart the cluster.
- Impala reads on Fusion files should now be available.
Parcel Locations
By default local parcels are stored on the Cloudera Manager Server:/opt/cloudera/parcel-repo. To change this location, follow the instructions in Configuring Server Parcel Settings.
The location can be changed by setting the parcel_dir property in /etc/cloudera-scm-agent/config.ini file of the Cloudera Manager Agent and restart the Cloudera Manager Agent or by following the instructions in Configuring the Host Parcel Directory.
Don't link to /usr/lib/
The path to the CDH libraries is /opt/cloudera/parcels/CDH/lib instead of the usual /usr/lib. We strongly recommend that you don't link /usr/lib/ elements to parcel deployed paths, as some scripts distinguish between the two paths.
Setting the CLASSPATH
In order to get Impala compatible with the Fusion HDFS proxy, the user needs to include a small configuration change in their Impala service through Cloudera Manager. In Cloudera Manager, the user needs to add an environment variable in the section Impala Service Environment Advanced Configuration Snippet (Safety Valve),
AUX_CLASSPATH='colon-delimited list of all the Fusion client jars'
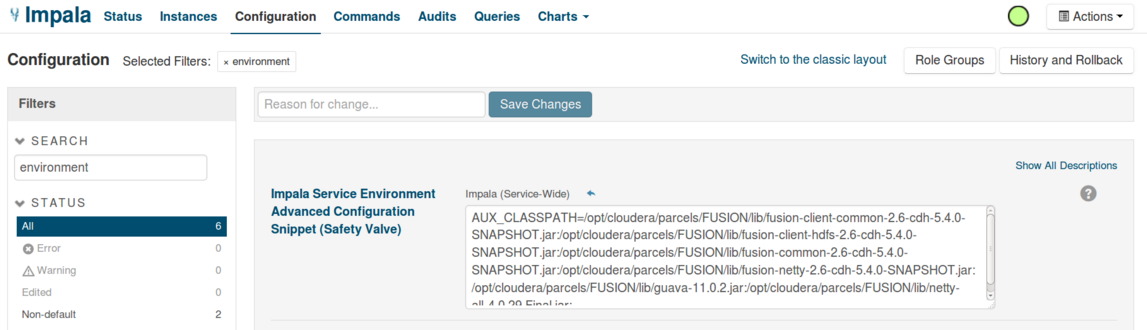
Classpath configuration for WD Fusion.
Query a table stored in a replicated directory
Support from WD Fusion v2.3 - v2.5
Impala does not allow the use of non-HDFS file system URIs for table storage. If you are running with WD Fusion 2.5 or earlier, you need to work around this. WANdisco Fusion 2.3 comes with a client program See Impala Parcel that will support reading data from a table stored in a replicated directory. From WD Fusion 2.6, it becomes possible to replicate directly over HDFS using the hdfs:/// URI.
2.5.3 Oozie
The Oozie service can function with Fusion, running without problem with Cloudera CDH. Under Hortonworks HDP we saw failures in terms of FusionHdfs class not being found. Run the following workaround after completing the WD Fusion installation:
- Go into Oozie lib directory
cd /usr/hdp/current/oozie-server/oozie-server/webapps/oozie/WEB-INF/lib
- Create symlink for fusion client jars
ln -s /usr/hdp/{hdp_version}/hadoop/lib/fusion* .
ln -s /usr/hdp/{hdp_version}/hadoop/lib/netty-all-4* .
ln -s /usr/hdp/{hdp_version}/hadoop/lib/bcprov-jdk15on-1.52.jar .
- Restart the oozie sevice and fusion services.
2.5.4 Oracle: Big Data Appliance
Each node in an Oracle:BDA deployment has multiple network interfaces, with at least one used for intra-rack communications and one used for external communications. WD Fusion requires external communications so configuration using the public IP address is required instead of using host names.
Prerequisites
- Knowledge of Oracle:BDA architecture and configuration.
- Ability to modify Hadoop site configuration.
Required steps
Operating in a multi-homed environment
Oracle:BDA is built on top of Cloudera's Hadoop and requires some extra steps to support multi-homed network environment.
Procedure
- Complete a standard installation, following the steps provided in the Installation Guide. Retrieve and use the public interface IP addresses for the nodes that will host the WD Fusion and IHC servers.
- Once the installation is completed you need to set up WD Fusion for a multi-homed environment, first edit WD Fusion's properties file (/opt/wandisco/fusion-server/application.properties). Create a backup of the file, then add the following line at the end:
communication.hostname=0.0.0.0
Resave the file.
- Next we need to update the IHC servers so that they will also use the public IP addresses rather than hostnames. The specific number and names of the configuration files that you need to update will depend on the details of your installation. If you run both WD Fusion server and IHCs on the same server you can get a view of the files with the following command:
tree /etc/wandisco
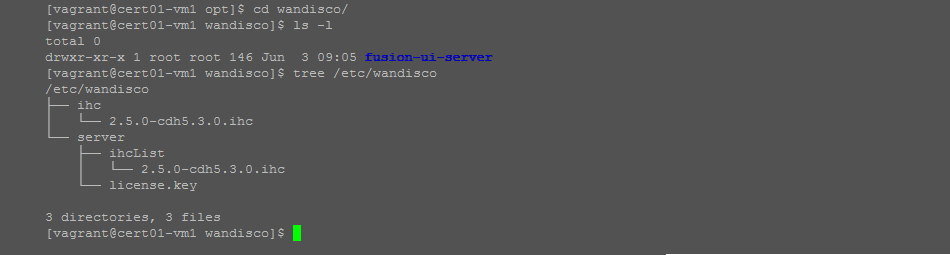
View of the WD Fusion configuration files.
- Edit each of the revealed config files. In the above example there are two instances of
2.5.0-cdh5.3.0.ihc that will need to be edited:
#Fusion Server Properties
#Wed Jun 03 10:14:41 BST 2015
ihc.server=node01.obda.domain.com\:7000
http.server=node01.obda.domain.com\:9001
In each case you should change the addresses so that they use the public IP addresses instead of the hostnames.
Troubleshooting
If you suspect that the multi-homed environment is causing difficulty, verify that you can communicate to the IHC server(s) from other data centers. For example, from a machine in another data center, run:
nc <IHC server IP address>:<IHC server port>
If you see errors from that command, you must fix the network configuration.
Running Fusion with Oracle BDA 4.2 / CDH 5.5.1
There's a known issue concerning configuration and the Cloudera Navigator Metadata Server classpath.
Error message:
2016-04-19 08:50:31,434 ERROR com.cloudera.nav.hdfs.extractor.HdfsExtractorShim [CDHExecutor-0-CDHUrlClassLoader@3bd4729d]: Internal Error while extracting
java.lang.RuntimeException: java.lang.ClassNotFoundException: Class com.wandisco.fs.client.FusionHdfs not found
at org.apache.hadoop.conf.Configuration.getClass(Configuration.java:2199)
...
There's no clear way to override the fs.hdfs.impl setting just for the Navigator Metadata server, as is required for running with WD Fusion.
Fix Script
Use the following fix script to overcome the problem:
CLIENT_JARS=$(for i in $(ls -1 /opt/cloudera/parcels/CDH/lib/hadoop/client/*.jar | grep -v jsr305 | awk '{print $NF}' ) ; do echo -n $i: ; done)
NAVIGATOR_EXTRA_CLASSPATH=/opt/wandisco/fusion/client/lib/*:/opt/cloudera/parcels/CDH/lib/hadoop/lib/jetty-*.jar:$CLIENT_JARS
echo "NAVIGATOR_EXTRA_CLASSPATH=$NAVIGATOR_EXTRA_CLASSPATH" > ~/navigator_env.txt
The environment variables are provided here - navigator_env.txt
You need to put this in the configuration for the Cloudera Management Service under "Navigator Metadata Server Environment Advanced Configuration Snippet (Safety Valve)". This modification currently needs to be applied whenever you upgrade or downgrade WD Fusion.
2.5.5 Apache Tez
Apache Tez is a YARN application framework that supports high performance data processing through DAGs. When set up, Tez uses its own tez.tar.gz containing the dependencies and libraries that it needs to run DAGs. For a DAG to access WD Fusion's fusion:/// URI it needs our client jars:
Configure the tez.lib.uris property with the path to the WD Fusion client jar files.
...
<property>
<name>tez.lib.uris</name>
# Location of the Tez jars and their dependencies.
# Tez applications download required jar files from this location, so it should be public accessible.
<value>${fs.default.name}/apps/tez/,${fs.default.name}/apps/tez/lib/</value>
</property>
...
Tez with Hive
In order to make Hive with Tez work, you need to append the Fusion jar files in tez.cluster.additional.classpath.prefix under the Advanced tez-site section:
tez.cluster.additional.classpath.prefix = /opt/wandisco/fusion/client/lib/*
e.g.

Tez configuration.
Running Hortonworks Data Platform, the tez.lib.uris parameter defaults to /hdp/apps/${hdp.version}/tez/tez.tar.gz.
So, to add Fusion libs, there are two choices:
Option 1: Delete the above value, and instead have a list including the path where the above gz unpacks to, and the path where Fusion libs are.
or
Option 2: Unpack the above gz, repack with WD Fusion libs and re-upload to HDFS.
Note that both changes are vulnerable to a platform (HDP) upgrade.
2.5.6 Apache Ranger
Apache Ranger is another centralized security console for Hadoop clusters, a preferred solution for Hortonworks HDP (whereas Cloudera prefers Apache Sentry).
While Apache Sentry stores its policy file in HDFS, Ranger uses its own local MySQL database, which introduces concerns over non-replicated security policies.
Ranger also applies its policies to the ecosystem via java plugins into the ecosystem components - the namenode, hiveserver etc. In testing, the WD Fusion client has not experienced any problems communicating with Apache Ranger-enabled platforms (Ranger+HDFS).
Ensure that the hadoop system user, typically hdfs, has permission to impersonate other users.
...
<property>
<name>hadoop.proxyuser.hdfs.users</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hdfs.groups</name>
<value>*</value>
</property>
...
2.5.6 Solr
Apache Solr is a scalable search engine that can be used with HDFS. In this section we cover what you need to do for Solr to work with a WD Fusion deployment.
Minimal deployment using the default hdfs:// URI
Getting set up with the default URI is simple, Solr just needs to be able to find the fusion client jar files that contain the FusionHdfs class.
- Copy the Fusion/Netty jars into the classpath. Please follow these steps on all deployed Solr servers. For CDH5.4 with parcels, use these two commands:
cp /opt/cloudera/parcels/FUSION/lib/fusion* /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib
cp /opt/cloudera/parcels/FUSION/lib/netty-all-*.Final.jar /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib
- Restart all Solr Servers.
-
Solr is now successfully configured to work with WD Fusion.
Minimal deployment using the WANdisco "fusion://" URI
This is a minimal working solution with Solr on top of fusion.
Requirements
Solr will use a shared replicated directory.
- Symlink the WD Fusion jars into Solr webapp
cd /opt/cloudera/parcels/CDH/lib/solr/webapps/solr/WEB-INF/lib
ln -s /opt/cloudera/parcels/FUSION/lib .
ln -s /opt/cloudera/parcels/FUSION/lib/netty-all-4* .
- Restart Solr
- Create instance configuration
$ solrctl instancedir --generate conf1
- Edit conf1/conf/solrconfig.xml and replace solr.hdfs.home in directoryFactory definition with actual fusion:/// uri, like
fusion:///repl1/solr
- Create solr directory and set solr:solr permissions on it.
$ sudo -u hdfs hdfs dfs -mkdir fusion:///repl1/solr
$ sudo -u hdfs hdfs dfs -chown solr:solr fusion:///repl1/solr
- Upload configuration to zk
vvvvvvv$ solrctl instancedir --create conf1 conf1
- Create collection on first cluster
$ solrctl collection --create col1 -c conf1 -s 3
--For cloudera fusion.impl.disable.cache = true should be set for Solr servers.
(don't set this options cluster-wide, that will stall the WD Fusion server with an unbounded number
of client connections).
2.5.8 Flume
This set of instructions will set up Flume to ingest data via the fusion:/// URI.
- Edit the configuration, set "
agent.sources.flumeSource.command" to the path of the source data.
- In the case of the above TestRail case, it is the last few lines of the DConE Log file. Set "agent.sinks.flumeHDFS.hdfs.path" to the replicated directory of one of the DCs. Make sure it begins with
fusion:/// to push the files to Fusion and not hdfs.
Prerequisites
- Create a user in both the clusters '
useradd -G hadoop <username>'
- Create user directory in hadoop fs '
hadoop fs -mkdir /user/<username>'
- Create replication directory in both DC's '
hadoop fs -mkdir /fus-repl'
- Set permission to replication directory '
hadoop fs -chown username:hadoop /fus-repl'
- Install and configure WD Fusion
Flume with HDP
If running Flume on HDP/Ambari, replace:
/usr/hdp/current/hadoop-hdfs/lib/*
with
mapreduce.application.classpath
Setting up Flume through Cloudera Manager
If you want to set up Flume through Cloudera Manager follow these steps:
- Download the client in the form of a parcel and the parcel.sha through the UI.
- Put the parcel and .sha into
/opt/cloudera/parcel-repo on the Cloudera Managed node.
- Go to the UI on the Cloudera Manager node. On the main page, click the small button that looks like a gift wrapped box and the FUSION parcel should appear (if it doesn't, try clicking Check for new parcels and wait a moment)
- Install, distribute, and activate the parcel.
- Repeat steps 1-4 for the second zone.
- Make sure membership and replicated directories are created for sharing between Zones.
- Go onto Cloudera Manager's UI on one of the zones and click Add Service.
- Select the Flume Service. Install the service on any of the nodes.
- Once installed, go to Flume->Configurations.
- Set 'System User' to 'hdfs'
- Set 'Agent Name' to 'agent'
- Set 'Configuration File' to the contents of the flume.conf configuration.
- Restart Flume Service
- Selected data should now be in Zone1 and replicated in Zone2
- To check data was replicated, open a terminal onto one of the DCs and become
hdfs user, e.g. su hdfs, and run
hadoop fs -ls /repl1/flume_out"
- On both Zones, there should be the same FlumeData file with a long number. This file will contain the contents of the source(s) you chose in your configuration file.
2.5.9 Spark
It's possible to deploy WD Fusion with Apache's high-speed data processing engine if you consider the following points:
HDP
For HDP, in Spark configuration,spark.driver.extraClassPath is provided for extra libraries one may need with Spark.
-
Go to Spark -> Configs -> Custom spark-defaults and add the following:
Key: spark.driver.extraClassPath
Value: /opt/wandisco/fusion/client/lib/*
Without this, you will hit a ClassNotFoundException from com.wandisco.fs.client.FusionHdfs.
CDH
There is a known issue where Spark is not picking up Hive-Site.xml, See Hadoop configuration is not localised when submitting job in yarn-cluster mode (Fixed in version 1.4).
You need to manually add it in by either:
- Copy
/etc/hive/conf/hive-site.xml into /etc/spark/conf.
or
- Do one of the following, depending on which deployment mode you are running in:
Client - set HADOOP_CONF_DIR to /etc/hive/conf/ (or the directory where hive-site.xml is located).
Cluster - add --files=/etc/hive/conf/hive-site.xml (or the path for hive-site.xml) to the spark-submit script.
-
For CDH-5.3 with parcel install we found that we also need to do the following steps:
- Go to Cloudera-Manager -> Advanced Configuration Snippets
- Search for "env.sh"
- Under "Gateway Client Environment Advanced Configuration Snippet (Safety Valve) for hadoop-env.sh" add the following:
HADOOP_CLASSPATH=/opt/cloudera/parcels/FUSION-2.6.1-SNAPSHOT.2.5.0-cdh5.3.0/lib/*:$HADOOP_CLASSPATH:
- Deploy configs and restart services.
Using the FusionUri
The fusion:/// URI has a known issue where it complains about "Wrong fs". For now Spark is only verified with FusionHdfs going through the hdfs:/// URI.
2.5.10 HBase (Cold Back-up mode)
It's possible to run HBase in a cold-back-up mode across multiple data centers using WD Fusion, so that in the event of the active HBase node going down, you can bring up the HBase cluster in another data centre, etc. However, there will be unavoidable and considerable inconsistency between the lost node and the awakened replica. The following procedure should make it possible to overcome corruption problems enough to start running HBase again, however, since the damage dealt to underlying filesystem might be arbitrary, it's impossible to account for all possible corruptions.
Requirements
For HBase to run with WD Fusion, the following directories need to be created and permissioned, as shown below:
| platform |
path |
permission |
| CDH5.x |
/user/hbase |
hbase:hbase |
| HDP2.x |
/hbase
/user/hbase |
hbase:hbase
hbase:hbase |
Procedure
The steps below provide a method of handling a recovery using a cold back-up. Note that multiple HMaster/region servers restarts might be needed for certain steps, since hbck command generally requires master to be up, which may require fixing filesystem-level inconsistencies first.
- 1. Delete all
recovered.edits folder artifacts from possible log splitting for each table/region. This might not be strictly necessary, but could reduce the numbers of errors observed during startup.
hdfs dfs -rm /apps/hbase/data/data/default/TestTable/8fdee4924ac36e3f3fa430a68b403889/recovered.edits
- Detect and clean up (quarantine) all corrupted HFiles in all tables (including system tables -
hbase:meta and hbase:namespace). Sideline option forces hbck to move corrupted HFiles to a special .corrupted folder, which could be examined/cleanup up by admins:
hbase hbck -checkCorruptHFiles -sidelineCorruptHFiles
- Attempt to rebuild corrupted table descriptors based on filesystem information:
hbase hbck -fixTableOrphans
- General recovery step - try to fix assignments, possible region overlaps and region holes in HDFS - just in case:
hbase hbck -repair
- Clean up ZK. This is particularly necessary if hbase:meta or hbase:namespace were messed up (note that exact name of ZK znode is set by cluster admin)
hbase zkcli rmr /hbase-unsecure
- Final step to correct metadata-related errors
hbase hbck -metaonly
hbase hbck -fixMeta
2.5.11 Apache Phoenix
The Phoenix Query Server provides an alternative means for interaction with Phoenix and HBase. When WD Fusion is installed, the Phoenix query server may fail to start. The following workaround will get it running with Fusion.
-
Grab the client jar files as a colon separated string, like so, and set phoenix_class_path equal to this within the phoenix_utils.py file:
/opt/wandisco/fusion/client/lib/fusion-client-hdfs-${VERSION}.jar:/opt/wandisco/fusion/client/lib/fusion-client-common-${VERSION}.jar:/opt/wandisco/fusion/client/lib/fusion-netty-${VERSION}.jar:/opt/wandisco/fusion/client/lib/netty-all-4.0.23.Final.jar:/opt/wandisco/fusion/client/lib/guava-11.0.2.jar:/opt/wandisco/fusion/client/lib/fusion-common-${VERSION}.jar
- Change the Java construction command to look like the one below by appending the
phoenix_class_path to it:
java_cmd = '%(java)s -cp ' + hbase_config_path + os.pathsep + phoenix_utils.phoenix_queryserver_jar + os.pathsep + phoenix_utils.phoenix_class_path + \
2.5.12 Deploying WD Fusion into a LocalFileSystem
Installer-based LocalFileSystem Deployment
The following procedure covers the installation and setup of WD Fusion deployed over the LocalFileSystem. This requires an administrator to enter details throughout the procedure. Once the initial settings are entered through the terminal session, the deployment to the LocalFileSystem is then completed through a browser.
- Open a terminal session on your first installation server. Copy the WD Fusion installer script into a suitable directory.
- Make the script executable, e.g.
chmod +x fusion-ui-server-<version>_rpm_installer.sh
- Execute the file with root permissions, e.g.
sudo ./fusion-ui-server-<version>_rpm_installer.sh
- The installer will now start. You will be asked if you wish to continue with the installation. Enter Y to continue.
LocalFS figure 1.
- The installer performs some basic checks and lets you modify the Java heap settings. The heap settings apply only to the WD Fusion UI.
INFO: Using the following Memory settings for the WANDISCO Fusion Admin UI process:
INFO: -Xms128m -Xmx512m
Do you want to use these settings for the installation? (Y/n) y
The default values should be fine for evaluation, although you should review your system resource requirements for production. Enter Y to continue.
LocalFS figure 2.
- Select the localfs platform and then enter a username and password that you will use to login to the WD Fusion web UI.
Which port should the UI Server listen on [8083]:
Please specify the appropriate platform from the list below:
[0] localfs-2.7.0
Which Fusion platform do you wish to use? 0
You chose localfs-2.7.0:2.7.0
Please provide an admin username for the Fusion web ui: admin
Please provide an admin password for the Fusion web ui: ************
LocalFS figure 3.
- Provide a system user account for running WD Fusion. Following the on-screen instructions, you should set up an account called 'fusion' when running the default LocalFS setup.
We strongly advise against running Fusion as the root user.
For default LOCALFS setups, the user should be set to 'fusion'. However, you should choose a user appropriate for running HDFS commands on your system.
Which user should fusion run as? [fusion] fusion
Click Enter to accept 'fusion' or enter another suitable system account.
- Now choose a suitable group, again 'fusion' is the default.
Please choose an appropriate group for your system. By default LOCALFS uses the 'fusion' group.
Which group should Fusion run as? [fusion] fusion
- You will get a summary of the all the configuration that you have so far entered. Give it a check before you continue.
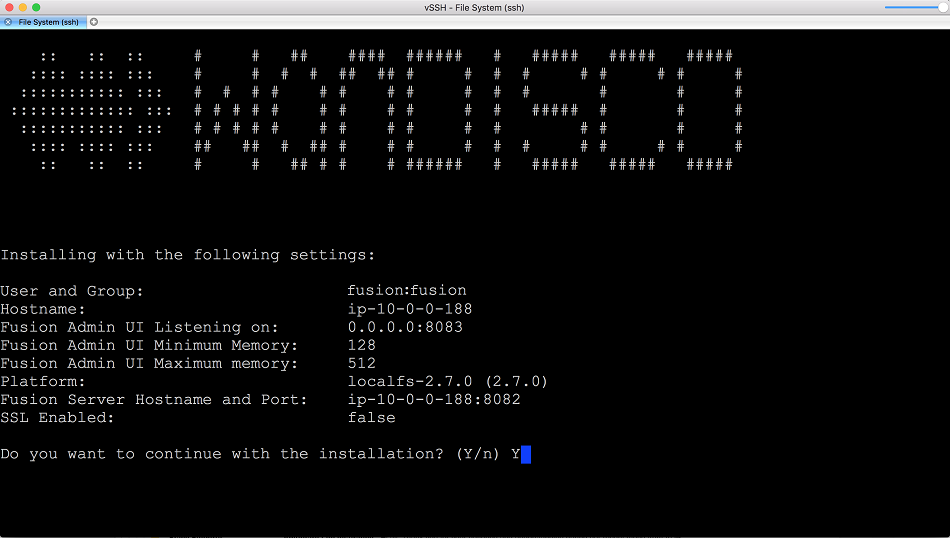
LocalFS figure 6.
- The installation process will complete. The final configuration steps will not be done over the web UI. Follow the on-screen instructions for where to point your browser, i.e. http://your-server-IP:8083/
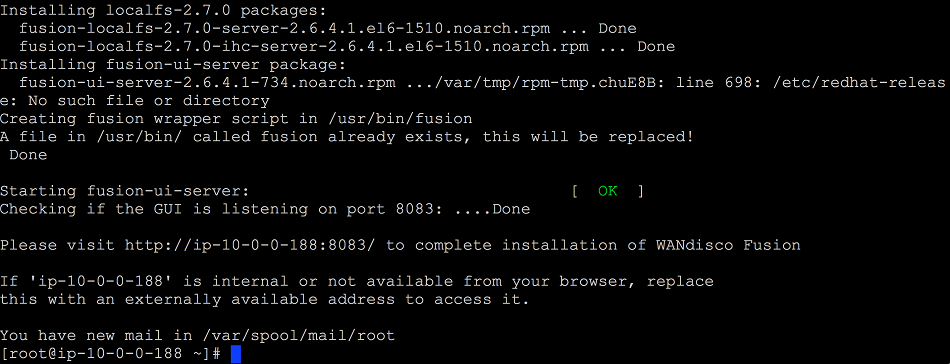
LocalFS figure 7.
- In the first "Welcome" screen you're asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows: Add Zone
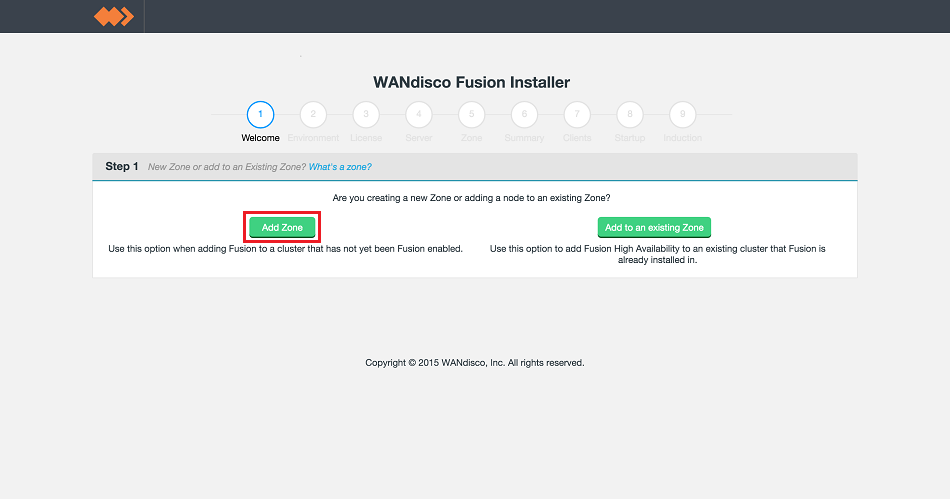
LocalFS figure 8.
- Adding a new WD Fusion cluster
- Select Add Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
- Select Add to an existing Zone.
- Run through the installer's detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
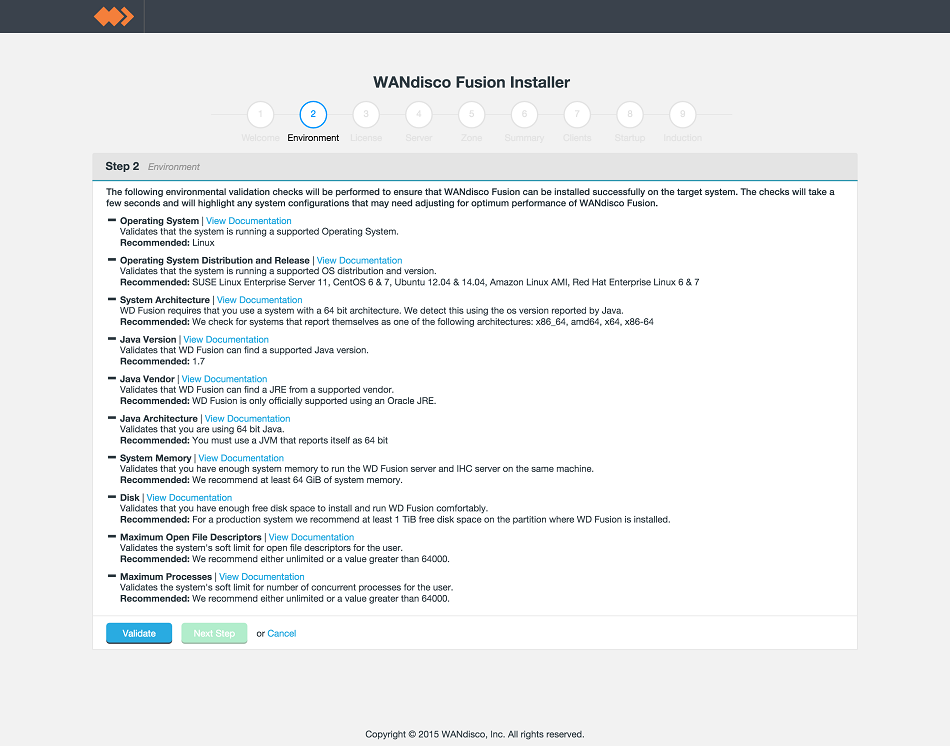
LocalFS figure 9.
- On clicking Validate, any element that fails the check should be addressed before you continue the installation.
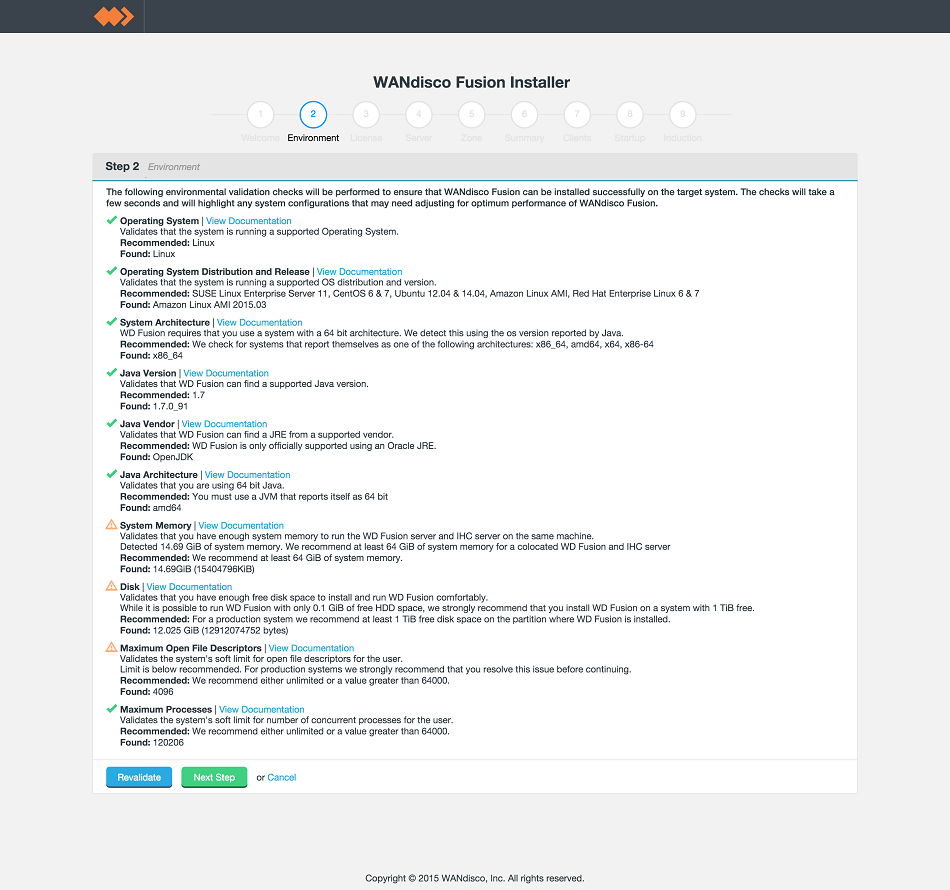
LocalFS figure 10.
Warnings may be ignored for the purposes of completing the installation, especially if the installation is only for evaluation purposes and not for production. However, when installing for production, you should also address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating. Click Next Step to continue.
- Click on Select file and then navigate to the license file provided by WANdisco.
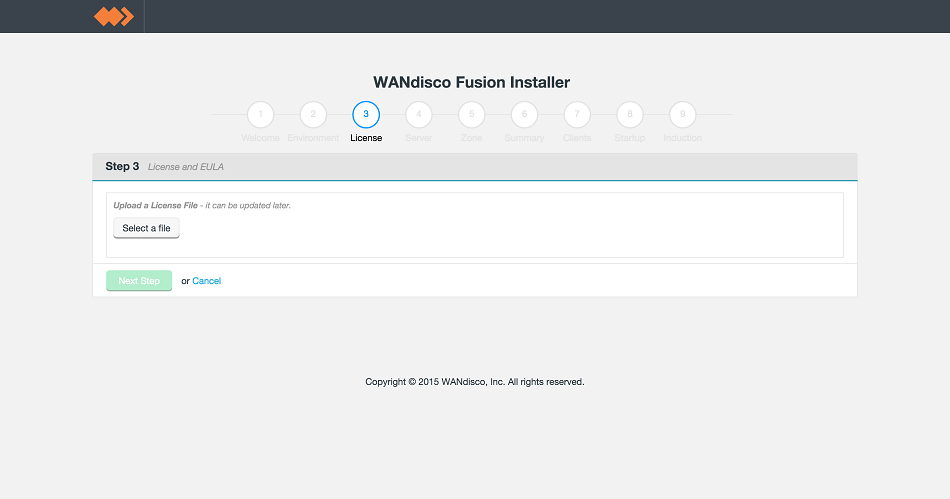
LocalFS figure 11.
- Click on Upload to validate the license file.
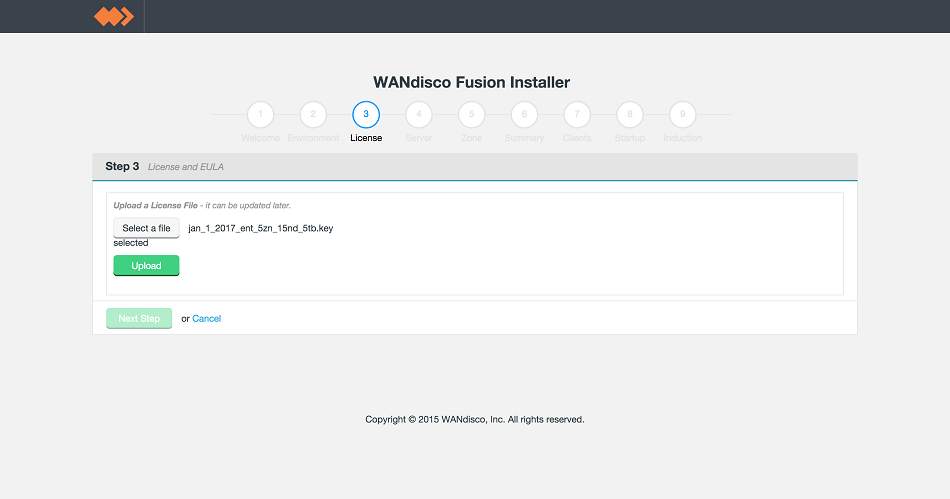
LocalFS figure 12.
- Providing the license file is validated successfullly, you will see a summary of what features are provided under the license.
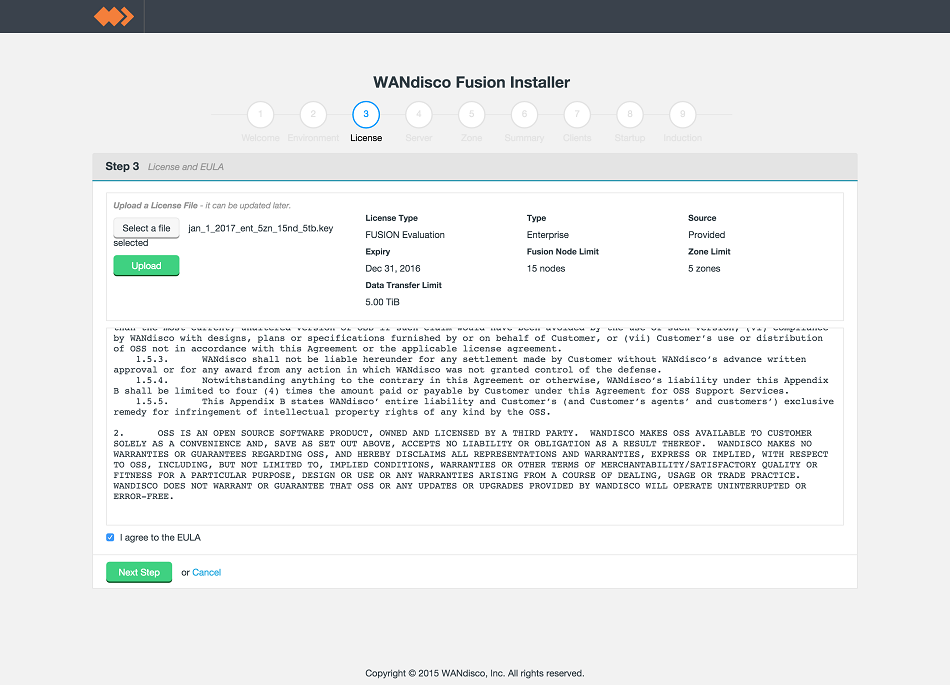
LocalFS figure 13.
Click on the I agree to the EULA to continue, then click Next Step.
- Enter settings for the WD Fusion server.

LocalFS figure 14 - Server settings
WD Fusion Server
- Fusion Server Max Memory (GB)
- Enter the maximum Java Heap value for the WD Fusion server. We recommend that for production you should top out with at least 16GB.
- Umask (currently 022)
- Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
- Latitude
- The north-south coordinate angle for the installation's geographical location.
- Longitude
- The east-west coordinate angle for the installation's geographical location. The latitude and longitude is used to place the WD Fusion server on a global map to aid coordination in a far-flung cluster.
Advanced options
Only apply these options if you fully understand what they do.
The following advanced options provide a number of low level configuration settings that may be required for installation into certain environments. The incorrect application of some of these settings could cause serious problems, so for this reason we strongly recommend that you discuss their use with WANdisco's support team before enabling them.
- Custom UI hostname
- Lets you set a custom hostname for the Fusion UI, distinct from the communication.hostname which is already set as part of the install and used by WD Fusion nodes to connect to the Fusion server.
- Custom UI Port
- Lets to change WD Fusion UI's default port, in case it is assigned elsewhere, e.g. Cloudera's headamp debug server also uses it.
IHC Server
- Maximum Java heap size (GB)
- Enter the maximum Java Heap value for the WD Inter-Hadoop Communication server. We recommend that for production you should top out with at least 16GB.
- IHC Network Interface
- The address on which the IHC (Inter-Hadoop Connect) server will be located on.
Once all settings have been entered, click Next step.
- Next, you will enter the settings for your new Zone.
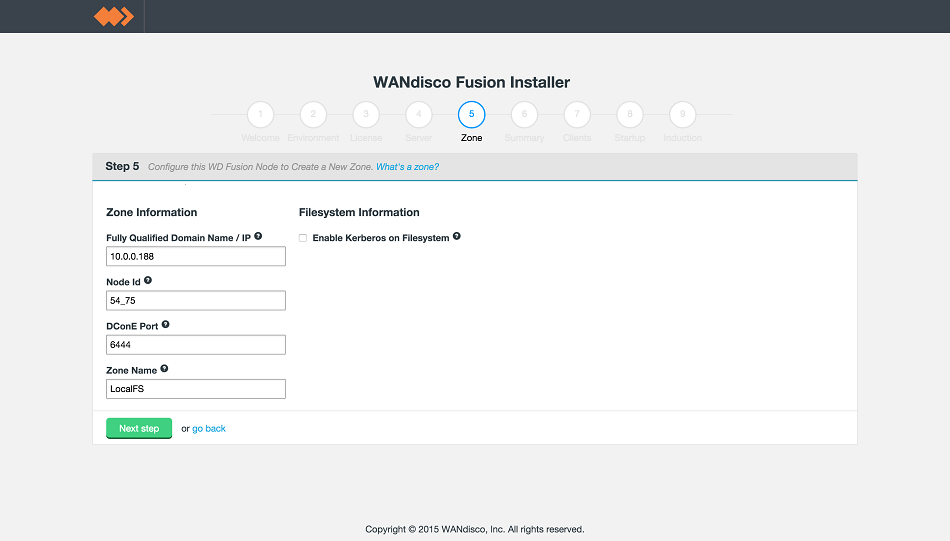
LocalFS figure 15.
Zone Information
Entry fields for zone properties
- Fully Qualified Domain Name
- the full hostname for the server.
- Node ID
- A unique identifier that will be used by WD Fusion UI to identify the server.
- DConE Port
- TCP port used by WD Fusion for replicated traffic.
- Zone Name
- The name used to identify the zone in which the server operates.
Add an entry for the EC2 node in your host file
You need to ensure that the hostname of your EC2 machine has been added to the /etc/hosts file of your LocalFS server node. If you don't do this then, currently you get an error when you start the node:
Could not resolve Kerberos principal name: java.net.UnknownHostException: ip-10-0-100-72: ip-10-0-100-72" exception
File System Information
Configuration for the local file system:
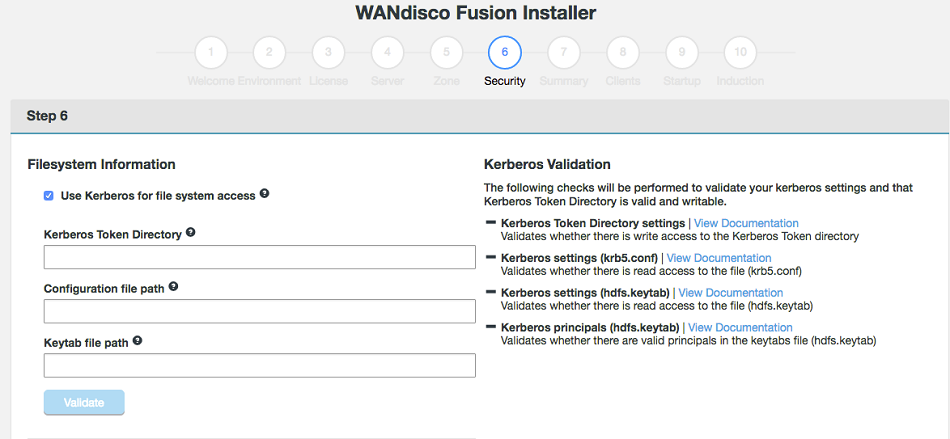
- Use Kerberos for file system access:
- Tick this check-box to enable Kerberos authentication on the local filesystem.
- Kerberos Token Directory
-
This defines what the root token directory should be for the Kerberos Token field. This is only set if you are using LocalFileSystem with Kerberos and want to target the token creations within the NFS directory and not on just the actual LocalFileSystem. If left unset it will default to the original behavior; which is to create tokens in the /user/<username>/ directory.
The installer will validate that the directory given or that is set by default (if you leave the field blank), can be written to by WD Fusion.
- Configuration file path
- System path to the Kerberos configuration file, e.g.
/etc/krb5.conf
- Keytab file path
- System path to your generated keytab file, e.g.
/etc/krb5.keytab
Name and place the keytab where you like
These paths and file names can be anything you like, providing they are the consistent with your field entries.
- Review the summary. Click Validate to continue.
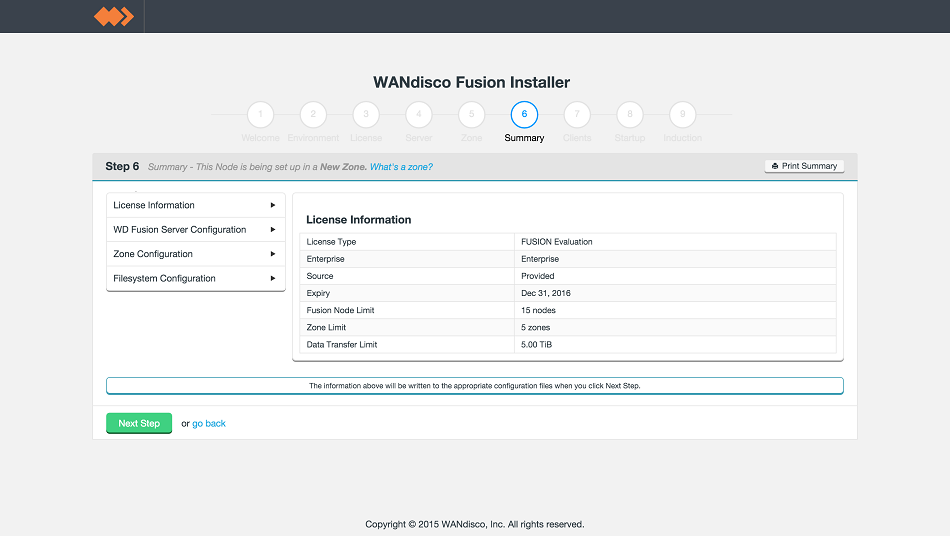
LocalFS figure 16.
- In the next step you must complete the installation of the WD Fusion client package on all the existing HDFS client machines in the cluster. The WD Fusion client is required to support data WD Fusion's replication across the Hadoop ecosystem.
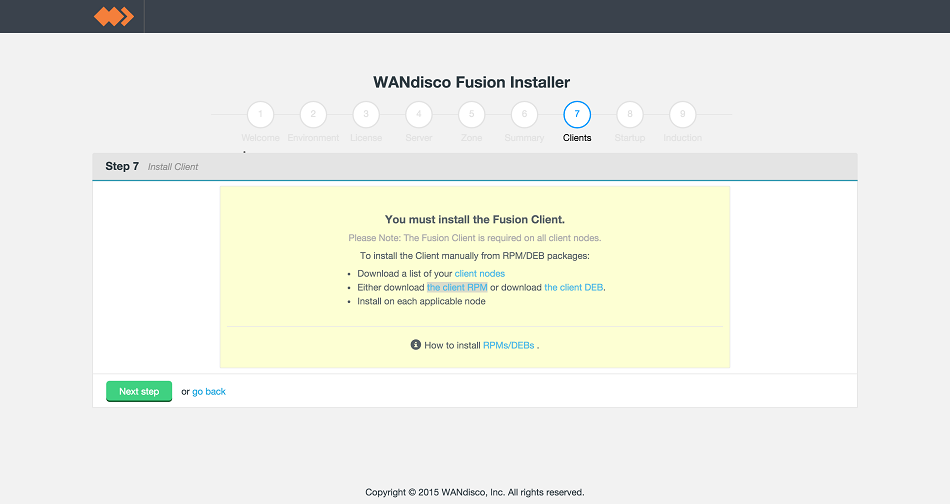
LocalFS figure 17.
In this case, download the client RPM file. Leave your browser session running while you do this, we haven't finished yet.
- For localFS deployments, download the client RPM manually onto each client system, in the screenshot we use
wget to copy the file into place.
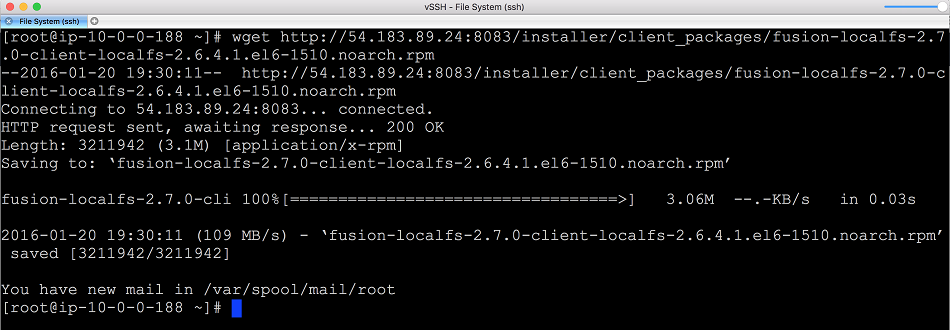
LocalFS figure 18.
- Ensure that the client install file has suitable permissions to run. Then use your package manager to install the client.
yum install -y fusion-localfs-2.7.0-client-localfs-2.6.4.1.e16-1510.noarch.rpm
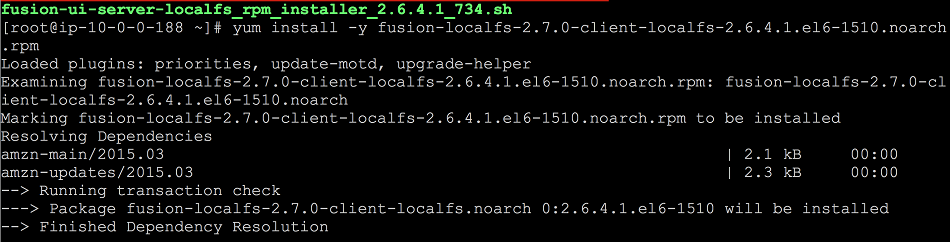
LocalFS figure 19.
- Once the client has successfully installed you will see a verification message.
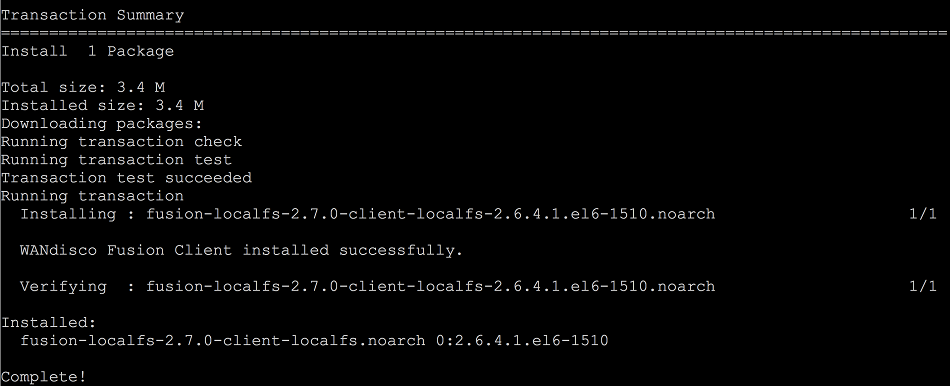
LocalFS figure 20.
- It's now time to return to the browser session and startup WDFusion UI for the first time. Click Start WD Fusion.
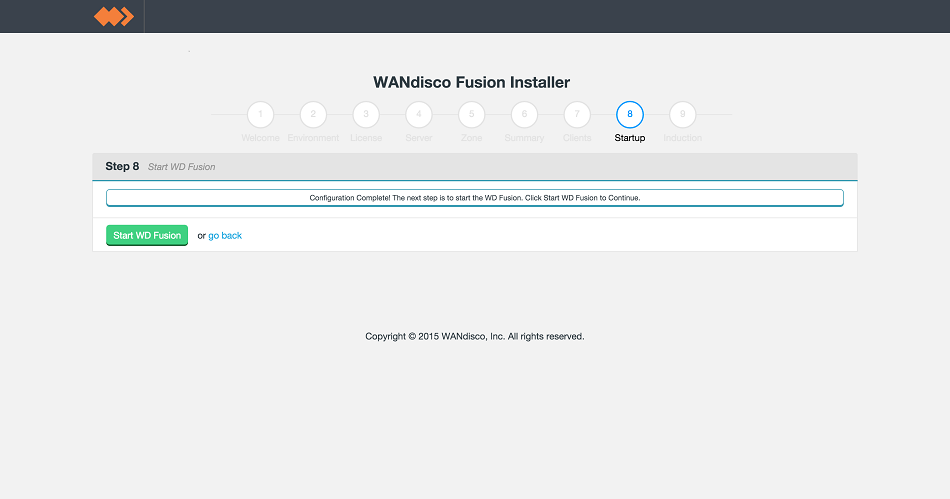
LocalFS figure 21.
- Once started we now complete the final step of installer's configuration steps, Induction.
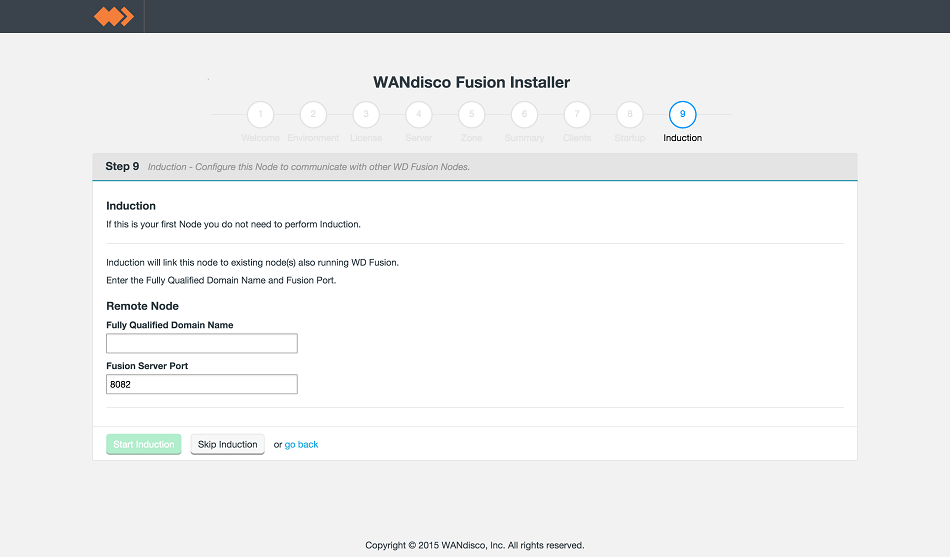
LocalFS figure 22.
For the first node you will miss this step out. For all the following node installations you will provide the FQDN or IP address and port of this first node. (In fact you can complete induction by referring to any node that has itself completed induction.)
"Could not resolved Kerberos principal" error
You need to ensure that the hostname of your EC2 machine has been added to the /etc/hosts file of your LocalFS server.
- Login to WD Fusion UI using the admin username and password that you provided during the installation. See step 6.
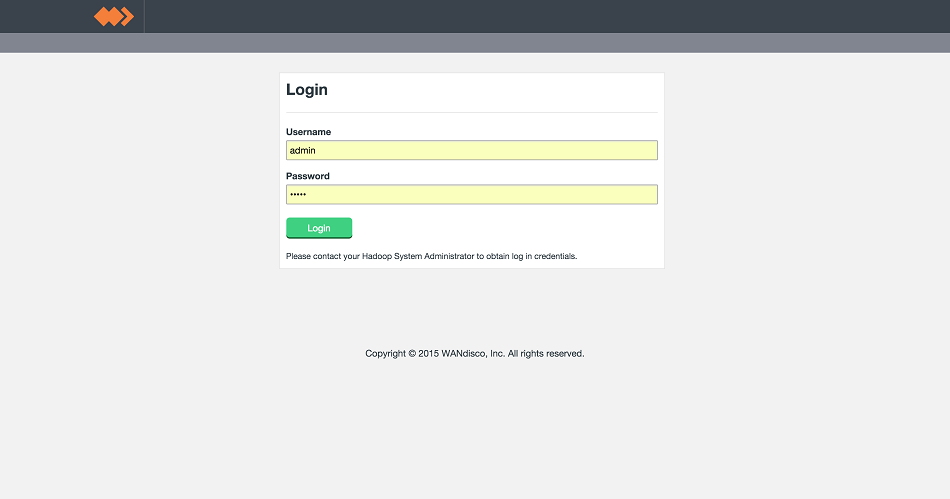
LocalFS figure 23.
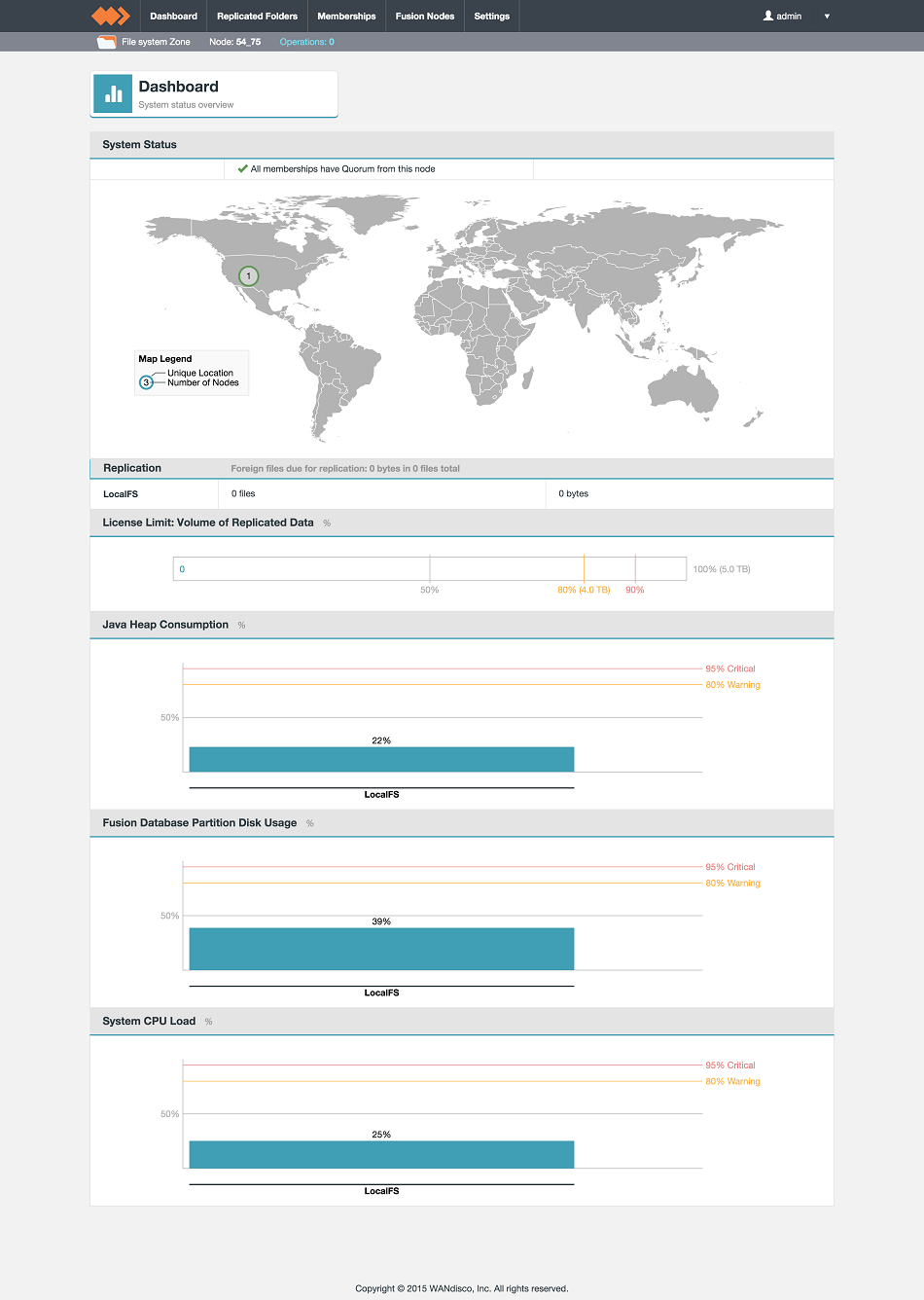
- The installation of your first node is now complete. You can find more information about working with the WD Fusion UI in the Admin section of this guide.
LocalFS figure 24.
Manual installation
The following procedures covers the hands-on approach to installation and basic setup of a deployment that deploys over the LocalFileSystem. For the vast majority of cases you should use the previous Installer-based LocalFileSystem Deployment procedure.
Non-HA Local filesystem setup
- Start with the regular WD Fusion setup. You can go through either the installation manually or using the installer.
- When you select the
$user:$group you should pick a master user account that will have complete access to the local directory that you plan to replicate. You can set this manually by modifying etc/wandisco/fusion-env.sh setting FUSION_SERVER_GROUP to $group and FUSION_SERVER_USER to $user.
- Next, you'll need to configure the
core-site.xml, typically in /etc/hadoop/conf/, and override "fs.file.impl" to "com.wandisco.fs.client.FusionLocalFs", "fs.defaultFS" to "file:///", and "fusion.underlyingFs" to "file:///". (Make sure to add the usual Fusion properties as well, such as "fusion.server").
- If you are running with fusion URI, (via "fs.fusion.impl"), then you should still set the value to "
com.wandisco.fs.client.FusionLocalFs".
- If you are running with Kerberos then you should also override "
fusion.handshakeToken.dir" to point to some directory that will exist within the local directory you plan to replicate to/from. You should also make sure to have "fs.fusion.keytab" and "fs.fusion.principal" defined as usual.
- Ensure that the local directory you plan to replicate to/from alreadly exists. If not, create it and give it 777 permissions or create a symlink (locally) that will point to the local path you plan to replicate to/from.
- For ex., if you want to replicate /repl1/ but don't want to create a directory on your root level, you can create a symlink to repl1 on your root level and point it to wherever you want to actually be your replicated directory. In the case of using NFS, it should be used to point to /mnt/nfs/.
- Set-up an NFS.
Be sure to point your replicated directory to your NFS mount, either directly or using a a symlink.
HA local file system setup
- Install Fusion UI, Server, IHC, and Client (for LocalFileSystem) on every node you plan to use for HA.
- When you select the
$user:$group you should pick a master user account that will have complete access to the local directory that you plan to replicate. You can set this manually by modifying /etc/wandisco/fusion-env.sh setting FUSION_SERVER_GROUP to $group and FUSION_SERVER_USER to $user.
- Next, you'll need to configure the core-site.xml, typically in /etc/hadoop/conf/, and override "
fs.file.impl" to "com.wandisco.fs.client.FusionLocalFs", "fs.defaultFS" to "file:///", and "fusion.underlyingFs" to "file:///". (Make sure to add the usual Fusion properties as well, such as "fs.fusion.server").
- If you are running with fusion URI, (via "fs.fusion.impl"), then you should still set the value to "
com.wandisco.fs.client.FusionLocalFs".
- If you are running with Kerberos then you should also override "
fusion.handshakeToken.dir" to point to some directory that will exist within the local directory you plan to replicate to/from. You should also make sure to have "fs.fusion.keytab" and "fs.fusion.principal" defined as usual.
- Ensure that the local directory you plan to replicate to/from alreadly exists. If not, create it and give it 777 permissions or create a symlink (locally) that will point to the local path you plan to replicate to/from.
- For ex., if you want to replicate /repl1/ but don't want to create a directory on your root level, you can create a symlink to repl1 on your root level and point it to wherever you want to actually be your replicated directory. In the case of using NFS, it should be used to point to /mnt/nfs/.
- Now follow a regular HA set up, making sure that you copy over the core-site.xml and fusion-env.sh everywhere so all HA nodes have the same configuration.
- Create the replicated directory (or symlink to it) on every HA node and chmod it to 777.
Notes on user settings
When using LocalFileSystem, you can only support 1 single user. This means when you configure the WD Fusion Server's process owner, that process owner should also be the process owner of the IHC server, the Fusion UI server, and the client user that will be used to perform any puts.
Fusion under LocalFileSystem only supports 1 user
Again, Fusion under LocalFileSystem only supports 1 user (on THAT side; you don't have to worry about the other DCs). To assist administrators the LocalFS RPM comes with Fusion and Hadoop shell, so that it is possible to run suitable commands from either. E.g.
hadoop fs -ls /
fusion fs -ls /
Using the shell is required for replication.
2.6 Appendix
The appendix section contains extra help and procedures that may be required when running through a WD Fusion deployment.
Environmental Checks
During the installation, your system's environment is checked to ensure that it will support WANdisco Fusion, the Environment checks are intended to catch basic compatibility issues, especially those that may appear during an early evaluation phase. The checks are not intended to replace carefully running through the Deployment Checklist.
| Operating System: |
The WD Fusion installer verifies that you are installing onto a system that is running on a compatible operating system.
See the Operating system section of the Deployment Checklist, although the current supported distributions of Linux are listed here:
Supported Operating Systems
- RHEL 6 x86_64
- RHEL 7 x86_64
- Oracle Linux 6 x86_64
- Oracle Linux 7 x86_64
- CentOS 6 x86_64
- CentOS 7 x86_64
- Ubuntu 12.04LTS
- Ubuntu 14.04LTS
- SLES 11 x86_64
Architecture:
|
| Java: |
The WD Fusion installer verifies that the necessary Java components are installed on the system.The installer checks:
- Env variables:
JRE_HOME, JAVA_HOME and runs the which java command.
- Version: 1.7/1.8 recommended. Must be at least 1.7.
- Architecture: JVM must be 64-bit.
- Distribution: Must be from Oracle. See Oracle's Java Download page.
For more information about JAVA requirements, see the Java of the Deployment Checklist. |
Kerberos Relogin Failure with Hadoop 2.6.0 and JDK7u80 or later
Hadoop Kerberos relogin fails silently due to HADOOP-10786. This impacts Hadoop 2.6.0 when JDK7u80 or later is used (including JDK8).
Users should downgrade to JDK7u79 or earlier, or upgrade to Hadoop 2.6.1 or later.
| ulimit: |
The WD Fusion installer verifies that the system's maximum user processes and maximum open files are set to 64000.
For more information about setting, see the File descriptor/Maximum number of procesesses limit on the Deployment Checklist.
|
| System memory and storage |
WD Fusion's requirements for system resources are split between its component parts, WD Fusion server, Inter-Hadoop Communication servers (IHCs) and the WD Fusion UI, all of which can, in principle be either collocated on the same machine or hosted separately.
The installer will warn you if the system on which you are currently installing WD Fusion is falling below the requirement. For more details about the RAM and storage requirements, see the Memory and Storage sections of the Deployment Checklist.
|
| Compatible Hadoop Flavour |
WD Fusion's installer confirms that a compatible Hadoop platform is installed. Currently, it takes the Cluster Manager detail provided on the Zone screen and polls the Hadoop Manager (CM or Ambari) for details. The installation can only continue if the Hadoop Manager is running a compatible version of Hadoop.
See the Deployment Checklist for Supported Versions of Hadoop
|
| HDFS service state: |
WD Fusion validates that the HDFS service is running. If it is unable to confirm the HDFS state a warning is given that will tell you to check the UI logs for possible errors.
See the Logs section for more information.
|
| HDFS service health |
WD Fusion validates the overall health of the HDFS service. If the installer is unable to communicate with the HDFS service then you're told to check the WD Fusion UI logs for any clues. See the Logs section for more information.
|
| HDFS maintenance mode. |
WD Fusion looks to see if HDFS is currently in maintenance mode. Both Hortonworks and Ambari support this mode for when you need to make changes to your Hadoop configuration or hardware, it supresses alerts for a host, service, role or, if required, the entire cluster.
|
| WD Fusion node running as a client |
We validate that the WD Fusion server is configured as a HDFS client.
|
Fusion Client installation with RPMs
The WD Fusion installer doesn't currently handle the installation of the client to the rest of the nodes in the cluster. You need to go through the following procedure:
- In the Client Installation section of the installer you will see line "Download a list of your client nodes" along with links to the client RPM packages.

RPM package location
If you need to find the packages after leaving the installer page with the link, you can find them in your installation directory, here:
/opt/wandisco/fusion-ui-server/ui/client_packages
- If you are installing the RPMs, download and install the package on each of the nodes that appear on the list from step 1.
- Installing the client RPM is done in the usual way:
rpm -i <package-name>
Install checks
HDP2.1/Ambari 1.6: Start services after installation
When installing clients via RPM into HDP2.1/Ambari 1.6., ensure that you restart services in Ambari before continuing to the next step.
Fusion Client installation with DEB
Debian not supported
Although Ubuntu uses Debian's packaging system, currently Debian itself is not supported. Note: Hortonworks HDP does not support Debian.
If you are running with an Ubuntu Linux distribution, you need to go through the following procedure for installing the clients using Debian's DEB package:
- In the Client Installation section of the installer you will see the link to the list of nodes here and the link to the client DEB package.
DEB package location
If you need to find the packages after leaving the installer page with the link, you can find them in your installation directory, here:
/opt/wandisco/fusion-ui-server/ui/client_packages
- To install WANdisco Fusion client, download and install the package on each of the nodes that appear on the list from step 1.
- You can install it using
sudo dpkg -i /path/to/deb/file
followed by
sudo apt-get install -f
Alternatively, move the DEB file to /var/cache/apt/archives/ and then run apt-get install <fusion-client-filename.deb>
.
Fusion Client installation with Parcels
For deployments into Cloudera clusters, clients can be installed using Cloudera's own packaging format: Parcels.
Installing the parcel
- Open a terminal session to the location of your parcels repository, it may be your Cloudera Manager server, although the location may have been customized. Ensure that you have suitable permissions for handling files.
- Download the appropriate parcel and sha for your deployment.
wget "http://fusion.example.host.com:8083/ui/parcel_packages/FUSION-<version>-cdh5.<version>.parcel"
wget "http://node01-example.host.com:8083/ui/parcel_packages/FUSION-<version>-cdh5.<version>.parcel.sha"
- Change the ownership of the parcel and .sha files so that they match the system account that runs Cloudera Manager:
chown cloudera-scm:cloudera-scm FUSION-<version>-cdh5.<version>.parcel*
- Move the files into the server's local repository, i.e.
mv FUSION-<version>-cdh5.<version>.parcel* /opt/cloudera/parcel-repo/
- Open Cloudera Manager and navigate to the Parcels screen.
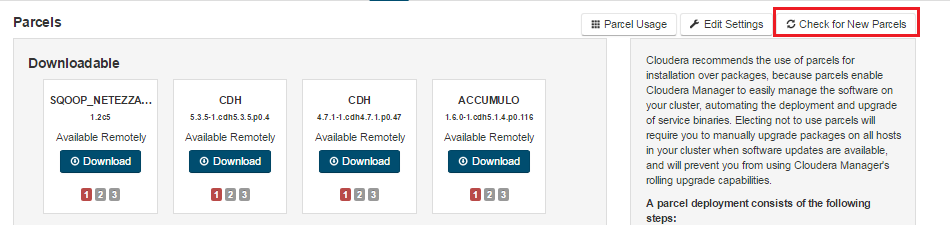
New Parcels check.
- The WD Fusion client package is now ready to distribute.
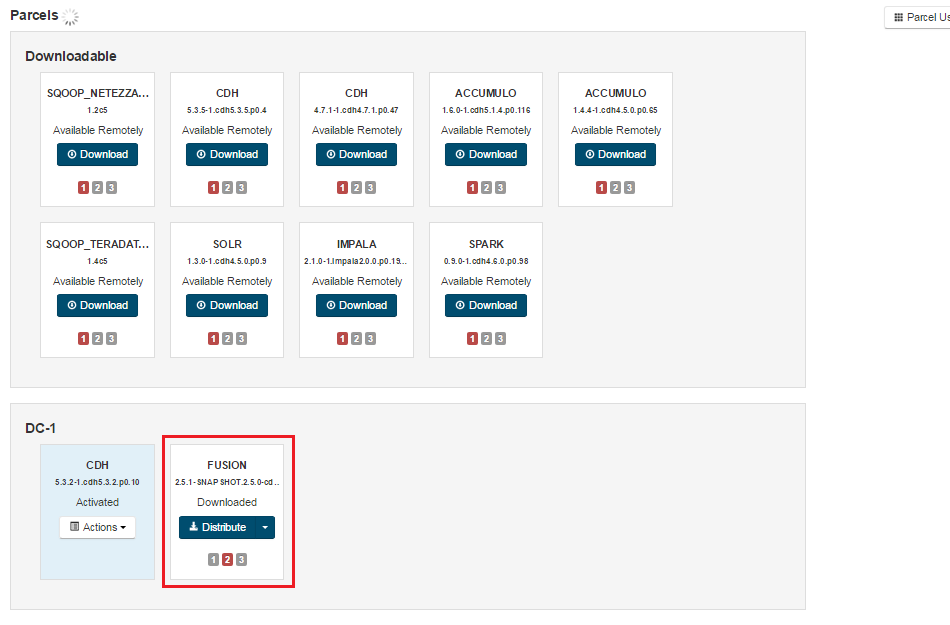
Ready to distribute.
- Click on the Distribute button to install WANdisco Fusion from the parcel.

Distribute Parcels.
- Click on the Activate button to activate WANdisco Fusion from the parcel.

Distribute Parcels.
- The configuration files need redeploying to ensure the WD Fusion elements are put in place correctly. You will need to check Cloudera Manager to see which processes will need to be restarted in order for the parcel to be deployed. Cloudera Manager provides a visual cue about which processes will need a restart.
Important
To be clear, you must restart the services, it is not sufficient to run the "Deploy client configuration" action.
Restarts.
WD Fusion uses Hadoop configuration files associated with the Yarn Gateway service and not HDFS Gateway. WD Fusion uses config files under /etc/hadoop/conf and CDH deploys the Yarn Gateway files into this directory.
Replacing earlier parcels?
If you are replacing an existing package that was installed using a parcel, once the new package is activated you should remove the old package through Cloudera Manager. Use the Remove From Host button.

Remove from the host.
Installing HttpFS with parcels
HttpFS is a server that provides a REST HTTP gateway supporting all HDFS File System operations (read and write). And it is interoperable with the webhdfs REST HTTP API.
While HttpFS runs fine with WD Fusion, there is an issue where it may be installed without the correct class paths being put in place, which can result in errors when running Mammoth test scripts.
Example errors
Running An HttpFS Server Test -- accessing hdfs directory info via curl requests
Start running httpfs test
HTTP/1.1 401 Unauthorized
Server: Apache-Coyote/1.1
WWW-Authenticate: Negotiate
Set-Cookie: hadoop.auth=; Path=/; Expires=Thu, 01-Jan-1970 00:00:00 GMT; HttpOnly
Content-Type: text/html;charset=utf-8
Content-Length: 997
Date: Thu, 04 Feb 2016 16:06:52 GMT
HTTP/1.1 500 Internal Server Error
Server: Apache-Coyote/1.1
Set-Cookie: hadoop.auth="u=oracle&p=oracle/bdatestuser@UATBDAKRB.COM&t=kerberos&e=1454638012050&s=7qupbmrZ5D0hhtBIuop2+pVrtmk="; Path=/; Expires=Fri, 05-Feb-2016 02:06:52 GMT; HttpOnly
Content-Type: application/json
Transfer-Encoding: chunked
Date: Thu, 04 Feb 2016 16:06:52 GMT
Connection: close
{"RemoteException":{"message":"java.lang.ClassNotFoundException: Class com.wandisco.fs.client.FusionHdfs not found","exception":"RuntimeException","javaClassName":"java.lang.RuntimeException"}}
Workaround
Once the parcel has been installed and HDFS has been restarted, the HttpFS service must also be restarted. Without this follow-on restart you will get missing class errors. This impacts only the HttpFS service, rather than the whole HDFS subsystem.
Fusion Client installation with HDP Stack / Pivotal HD
For deployments into Hortonworks HDP/Ambari cluster, version 1.7 or later. Clients can be installed using Hortonwork's own packaging format: HDP Stack. This approach always works for Pivotal HD.
Ambari 1.6 and earlier
If you are deploying with Ambari 1.6 or earlier, don't use the provided Stacks, instead use the generic RPMs.
Ambari 1.7
If you are deploying with Ambari 1.7, take note of the requirement to perform some necessary restarts on Ambari before completing an installation.
Ambari 2.0
When adding a stack to Ambari 2.0 (any stack, not just WD Fusion client) there is a bug which causes the YARN parameter yarn.nodemanager.resource.memory-mb to reset to a default value for the YARN stack. This may result in the Java heap dropping from a manually-defined value, back to a low default value (2Gb). Note that this issue is fixed from Ambari 2.1.
Upgrading Ambari
When running Ambari prior to 2.0.1, we recommend that you remove and then reinstall the WD Fusion stack if you perform an update of Ambari. Prior to version 2.0.1, an upgraded Ambari refuses to restart the WD Fusion stack because the upgrade may wipe out the added services folder on the stack.
If you perform an Ambari upgrade and the Ambari server fails to restart , the workaround is to copy the WD Fusion service directory from the old to the new directory, so that it is picked up by the new version of Ambari, e.g.:
cp -R /var/lib/ambari-server/resources/stacks_25_08_15_21_06.old/HDP/2.2/services/FUSION /var/lib/ambari-server/resources/stacks/HDP/2.2/services
Again, this issue doesn't occur once Ambari 2.0.1 is installed.
HDP 2.3/Ambari 2.1.1 install
There's currently a problem that can block the installation of the WD Fusion client stack. If the installation of the client service gets stuck at the "Customize Service" step, you may need to use a workaround:
- If possible, restart the sequence again, if the option is not available, because the Next button is disabled, or it doesn't work try the next workaround.
- Try installing the client RPMs.
- Install the WD Fusion client service manually, using the Ambari API.
e.g.
Install & Start the service via Ambari's API
Make sure the service components are created and the configurations attached by making a GET call, e.g.
http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/services/<service-name>
1. Add the service
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/services -d '{"ServiceInfo":{"service_name":"FUSION"}}'
2. Add the component
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/services/FUSION/components/FUSION_CLIENT -X POST
3. Get a list of the hosts
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/hosts/
4. For each of the hosts in the list, add the FUSION_CLIENT component
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/hosts/<host-name>/host_components/FUSION_CLIENT -X POST
5. Install the FUSION_CLIENT component
curl -u <username>:<password> -H "X-Requested-By: ambari" http://<ambari-server-host>:8080/api/v1/clusters/<cluster-name>/services/FUSION/components/FUSION_CLIENT -X PUT -d '{"ServiceComponentInfo":{"state": "INSTALLED"}}'
Installing the WANdisco service into your HDP Stack
- Download the service from the installer client download panel, or after the installation is complete, from the client packages section on the Settings screen.
- The service is a gz file (e.g. fusion-hdp-2.2.0-2.4_SNAPSHOT.stack.tar.gz) that will expand to a folder called /FUSION.
-
For HDP,
Place this folder in /var/lib/ambari-server/resources/stacks/HDP/<version-of-stack>/services.
Pivotal HD,
In the case of a Pivotal HD deployment, place in one of the following or similar folders:
/var/lib/ambari-server/resources/stacks/PHD/<version-of-stack>/services, or /var/lib/ambari-server/resources/stacks/<distribution>/<version-of-stack>/services.
- Restart the ambari-server
service ambari-server restart
- After the server restarts, go to + Add Service.
Add Service.
- Choose Service, scroll to the bottom.
Scroll to the bottom of the list.
- Tick the WANdisco Fusion service checkbox. Click Next.

Tick the WANdisco Fusion service checkbox.
- Datanodes and node managers are automatically selected. You must ensure that all servers are ticked as "Client", by default only the local node is ticked. Then click Next.
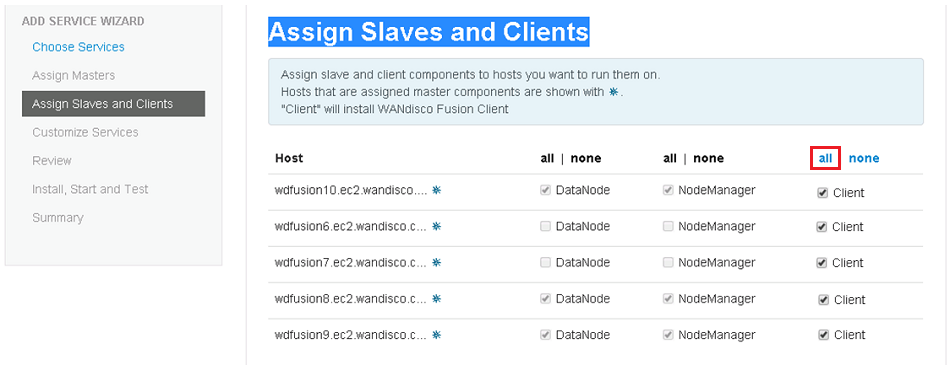
Assign Slaves and Clients. Add all the nodes as "Client"
- Deploy the changes.
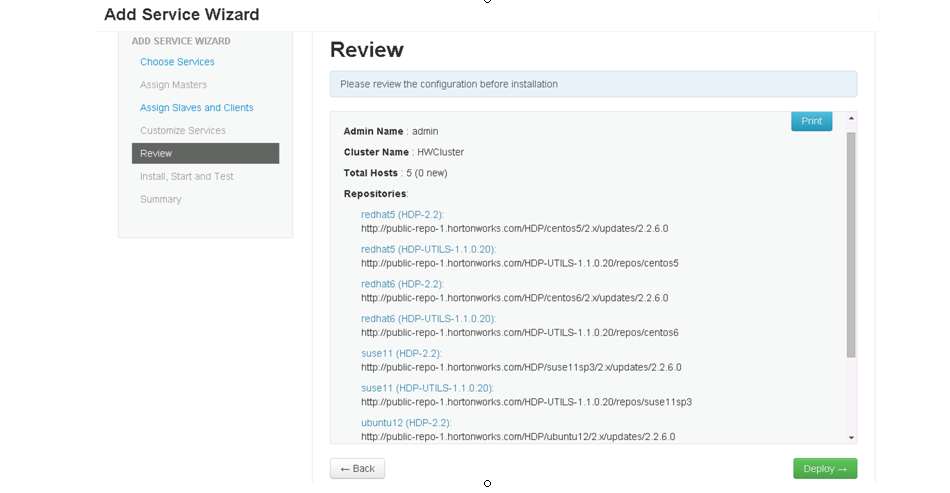
Deploy.
- Install, Start and Test.
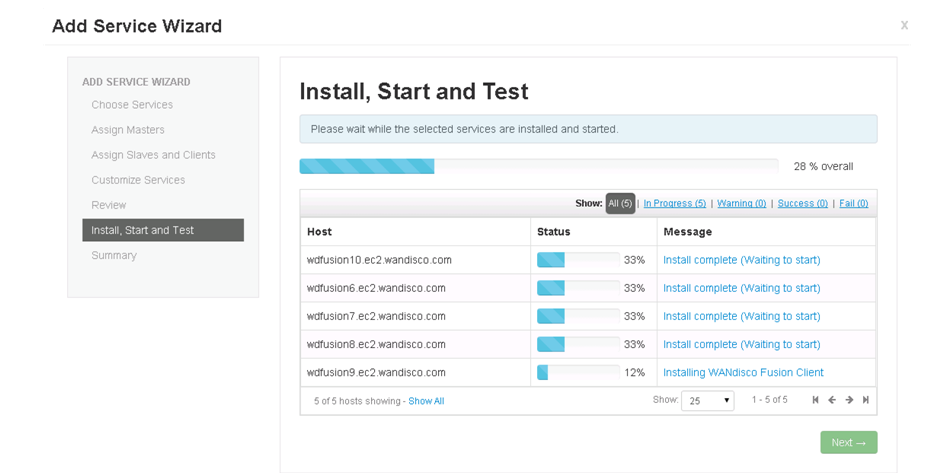
Install, start and test.
- Review Summary and click Complete.
Review.
Known bug (AMBARI-9022) Installation of Services can remove Kerberos settings
During the installation of services, via stacks, it is possible that Kerberos configuration can be lost. This has been seen to occur on Kerberized HDP2.2 clusters when installing Kafka or Oozie. Kerberos configuration in the core-site.xml file was removed during the installation which resulted in all HDFS / Yarn instances being unable to restart.
You will need to reapply your Kerberos settings in Ambari, etc.
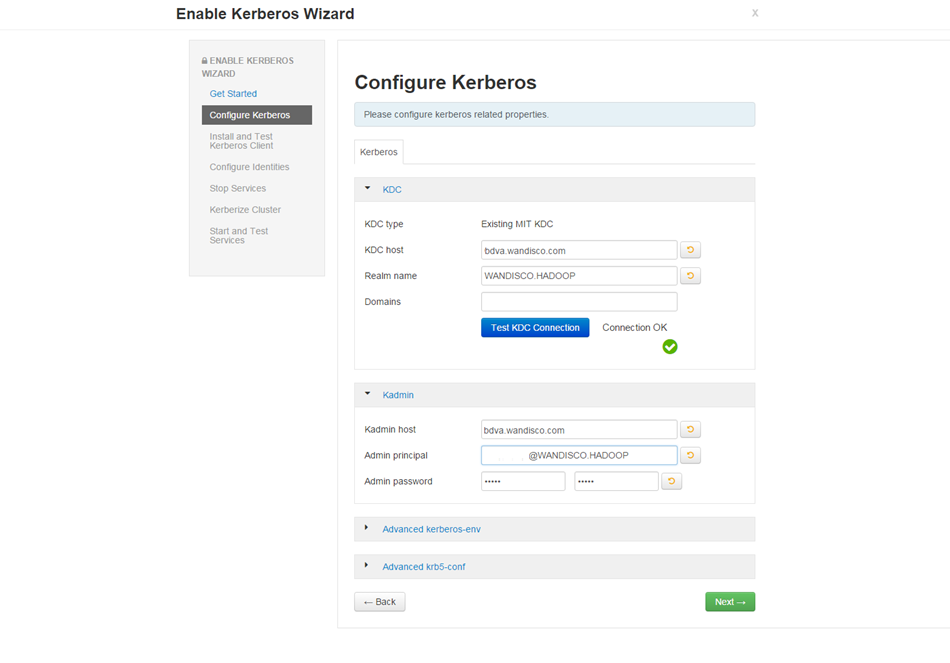
Kerberos re-enabled
For more details, see AMBARI-9022.
MapR Client Configuration
On MapR clusters, you need to copy WD Fusion configuration onto all other nodes in the cluster:
- Open a terminal to your WD Fusion node.
- Navigate to
/opt/mapr/hadoop/<hadoop-version>/etc/hadoop.
- Copy the
core-site.xml and yarn-site.xml files to the same location on all other nodes in the cluster.
- Now restart HDFS, and any other service that indicates that a restart is required.
MapR Impersonation
Enable impersonation when cluster security is disabled
Follow these steps on the client to configure impersonation without enabling cluster security.
- Enable impersonation for all relevant components in your ecosystem. See the MapR documentation - Component Requirements for Impersonation.
- Enable impersonation for the MapR core components:
The following steps will ensure that MapR will have the necessary permissions on your Hadoop cluster:
- On each client system on which you need to run impersonation:
Removing WANdisco Service
If you are removing WD Fusion, maybe as part of a reinstallation, you should remove the client packages as well. Ambari never deletes any services from the stack it only disables them. If you remove the WD Fusion service from your stack, remember to also delete fusion-client.repo.
[WANdisco-fusion-client]
name=WANdisco Fusion Client repo
baseurl=file:///opt/wandisco/fusion/client/packages
gpgcheck=0
For instructions for the cleanup of Stack, see Host Cleanup for Ambari and Stack
Cleanup WD Fusion HD
The following section is used when preparing to install WD Fusion on system that already has an earlier version of WD Fusion installed. Before you install an updated version of WD Fusion you need to ensure that components and configurartion for an earlier installation have been removed. Go through the following steps before installing a new version of WD Fusion:
- On the production cluster, run the following Curl to remove the service:
Curl -su <user>:<password> -H "X-Requested-By: ambari" http://<ambari-server>:<ambari-port>/api/v1/clusters/<cluster>/services/FUSION -X DELETE
- On ALL nodes, run the corresponding package manager to remove the client package command, e.g.
yum remove fusion-hdp-x.x.x-client
- Remove all remnant Fusion directories from services/. These left-over files can cause problems if you come to reinstall, so it is worth doing a check of places like /var/lib/ambari-agent/ and /opt/wandisco/fusion. Ensure the removal of /etc/yum.repos.d/fusion-client.repo, if it is left in place it will prevent the next installation of WD Fusion.
Uninstall WD Fusion
There's currently no uninstall function for our installer, so the system will have to be cleaned up manually.
If you used the unified installer then use the following steps:
To uninstall all of WD Fusion:
- Remove the packages on the WD Fusion node:
yum remove -y "fusion-*"
- Remove the jars, logs, configs:
rm -rf /opt/wandisco/ /etc/wandisco/ /var/run/fusion/ /var/log/fusion/
Cloudera Manager:
- Go to "Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml"
- Delete all Fusion-related content
- Remove WD Fusion parcel
- Restart services
Ambari
- Got to HDFS -> Configs -> Advanced -> Custom core-site
- Delete all WD Fusion-related elements
- Remove stack (See Removing WANdisco Service.
- Remove the package from all clients, e.g.
yum remove -y fusion*client*.rpm
- Restart services
Properties that you should delete from the core-site
For a complete uninstallation, remove the following properties from the core-site.xml:
- fs.fusion.server (If removing a single node from a zone, remove just that node from the property's value, instead).
- fs.hdfs.impl (its removal ensures that this native hadoop class is used, e.g.
org.apache.hadoop.hdfs.DistributedFileSystem).
- fs.fusion.impl
Reinstalling fusion server only
If you reinstall the fusion-server without also reinstalling the fusion-ui-server, then you should restart the fusion-ui-server service to ensure the correct function of some parts of the UI. If the service is not restarted then you may find that the dashboard graphs stop working properly, along with the UI's Stop/start controls. e.g. run:
[root@redhat6 init.d]# service fusion-ui-server restart
2.7 Silent Installation
The "Silent" installation tools are still under development, although, with a bit of scripting, it should now be possible to automate WD Fusion node installation. The following section looks at the provided tools, in the form of a number of scripts, which automate different parts of the installation process.
Overview
The silent installation process supports two levels:
- Unattended installation handles just the command line steps of the installation, leaving the web UI-based configuration steps in the hands of an administrator. See 2.7.1 unattended installation.
- Fully Automated also includes the steps to handle the configuration without the need for user interaction. See 2.8.2 Fully Automated installation.
2.7.1 Unattended Installation
Use the following command for an unattended installation where an administrator will complete the configuration steps using the browser UI.
sudo FUSIONUI_USER=x FUSIONUI_GROUP=y FUSIONUI_FUSION_BACKEND_CHOICE=z ./fusion-ui-server_rpm_installer.sh
Set the environment
There are a number of properties that need to be set up before the installer can be run:
- FUSIONUI_USER
- User which will run WD Fusion services. This should match the user who runs the hdfs service.
- FUSIONUI_GROUP
- Group of the user which will run Fusion services. The specified group must be one that FUSIONUI_USER is in.
Check FUSIONUI_USER is in FUSIONUI_GROUP
Perform a check of your chosen user to verify that they are in the group that you select.
> groups hdfs
hdfs : hdfs hadoop
- FUSIONUI_FUSION_BACKEND_CHOICE
- Should be one of the supported package names, as per the following list:
- cdh-5.2.0:2.5.0-cdh5.2.0
- cdh-5.3.0:2.5.0-cdh5.3.0
- cdh-5.4.0:2.6.0-cdh5.4.0
- cdh-5.5.0:2.6.0-cdh5.5.0
- hdp-2.1.0:2.4.0.2.1.5.0-695
- hdp-2.2.0:2.6.0.2.2.0.0-2041
- hdp-2.3.0:2.7.1.2.3.0.0-2557
- mapr-4.0.1:2.4.1-mapr-1408
- mapr-4.0.2:2.5.1-mapr-1501
- mapr-4.1.0:2.5.1-mapr-1503
- mapr-5.0.0:2.7.0-mapr-1506
- phd-3.0.0:2.6.0.3.0.0.0-249
- emr-4.0.0:2.6.0-amzn-0 - Additional restrictions apply to this option, used for Elastic MapReduce on Amazon S3.
- emr-4.1.0:2.6.0-amzn-1
You don't need to enter the full package name.
You no longer need to enter the entire string, only up to the colon, e.g., enter "cdh-5.2.0" instead of
"cdh-5.2.0:2.5.0-cdh5.2.0"
This mode only automates the initial command line installation step, the configuration steps still need to be handled manually in the browser steps.
Example:
sudo FUSIONUI_USER=hdfs FUSIONUI_GROUP=hadoop FUSIONUI_FUSION_BACKEND_CHOICE=hdp-2.3.0 ./fusion-ui-server_rpm_installer.sh
2.7.2 Fully Automated Installation
This mode is closer to a full "Silent" installation as it handles the configuration steps as well as the installation.
Properties that need to be set:
- SILENT_CONFIG_PATH
- Path for the environmental variables used in the command-line driven part of the installation. The paths are added to a file called silent_installer_env.sh.
- SILENT_PROPERTIES_PATH
- Path to 'silent_installer.properties' file. This is a file that will be parsed during the installation, providing all the remaining paramaters that are required for getting set up. The template is annotated with information to guide you through making the changes that you'll need.
Take note that parameters stored in this file will automatically override any default settings in the installer.
- FUSIONUI_USER
- User which will run Fusion services. This should match the user who runs the hdfs service.
- FUSIONUI_GROUP
- Group of the user which will run Fusion services. The specified group must be one that FUSIONUI_USER is in.
- FUSIONUI_FUSION_BACKEND_CHOICE
- Should be one of the supported package names, as per the following list:
- FUSIONUI_UI_HOSTNAME
- The hostname for the WD Fusion server.
- FUSIONUI_UI_PORT
- Specify a fusion-ui-server port (default is 8083)
- FUSIONUI_TARGET_HOSTNAME
- The hostname or IP of the machine hosting the WD Fusion server.
- FUSIONUI_TARGET_PORT
- The fusion-server port (default is 8082)
- FUSIONUI_MEM_LOW
- Starting Java Heap value for the WD Fusion server.
- FUSIONUI_MEM_HIGH
- Maximum Java Heap.
- FUSIONUI_UMASK
- Sets the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
- FUSIONUI_INIT
- Sets whether the server will start automatically when the system boots. Set as "1" for yes or "0" for no
Cluster Manager Variables are deprecated
The cluster manager variables are mostly redundant as they generally get set in different processes though they currently remain in the installer code.
FUSIONUI_MANAGER_TYPE
FUSIONUI_MANAGER_HOSTNAME
FUSIONUI_MANAGER_PORT
- FUSIONUI_MANAGER_TYPE
- "AMBARI", "CLOUDERA", "MAPR" or "UNMANAGED_S3". This setting can still be used but it is generally set at a different point in the installation now.
Editing tips
Follow these points when updating the silent_installer_properties file.
- Avoid excess space characters in settings.
- Induction:
When there is no existing WD Fusion server to induct to you must set "induction.skip=true".
- When you do have a server to induct to, either leave it commented out or explicitly set "
induction.skip=false" and provide both "induction.remote.node" and "induction.remote.port" settings for an existing node. The port in question would be for the fusion-server (usually 8082)
.
- New Zone/Existing Zone and License:
If both existing.zone.domain and existing.zone.port are provided this is considered to be an Existing Zone installation. The port in question here is the fusion-ui-server port (usually 8083). In this case, some settings will be taken from the existing server including the license. Otherwise, this is the New Zone installation mode.
In this mode license.file.path must point to a valid license key file on the server.
- Validation Skipping:
There are three flags that allow for the skipping of validations for situations where this may be appropriate. Set any of the following to false to skip the validation step:
- validation.environment.checks.enabled
- validation.manager.checks.enabled
-
Note manager validation is currently not available for S3 installs
- validation.kerberos.checks.enabled
-
Note kerberos validation is currently not available for S3 installs
If this part of the installation fails it is possible to re-run the silent_installer part of the installation by running:
/opt/wandisco/fusion-ui-server/scripts/silent_installer_full_install.sh /path/to/silent_installer.properties
Uninstall WD Fusion UI only
This procedure is useful for UI-only installatons:
sudo yum erase -y fusion-ui-server
sudo rm -rf /opt/wandisco/fusion-ui-server /etc/wandisco/fusion/ui
To UNINSTALL Fusion UI, Fusion Server and Fusion IHC Server (leaving any fusion clients installed):
sudo yum erase -y "fusion-*-server"
sudo rm -rf /opt/wandisco/fusion-ui-server /etc/wandisco/fusion/ui
2.8 Installing into Amazon S3/EMRFS
Pre-requisites
Before you begin an installation to an S3 cluster make sure that you have the following directories created and suitably permissioned. Examples:
${hadoop.tmp.dir}/s3
and
/tmp/hadoop-${user.name}
You can deploy to Amazon S3 using either the:
Known Issues using S3
Make sure that you read and understand the following known issues, taking action if they impact your deployment requirements
Replicating large files in S3
In the initial release supporting S3 there is a problem transferring very large files that will need to be worked around until the next major release (2.7). The problem only impacts users who are running clusters that include S3, either exclusively or in conjunction with other Hadoop data centers.
Workaround
Use your management layer (Ambari/Cloudera Manager, etc) to update the core-site.xml with the following property:
<property>
<name>dfs.client.read.prefetch.size</name>
<value>9223372036854775807</value>
</property>
<property>
<name>fs.fusion.push.threshold</name>
<value>0</value>
</property>
This change forces the IHC Server on the serving zone to retrieve all blocks at once, rather than in 10 block intervals.
Out of Memory issue in EMR 4.1.0
The WDDOutputStream can cause an out-of-memory error because its ByteArrayOutputStream can go beyond the memory limit.
Workaround
By default, EMR has a configuration in hadoop-env.sh that OnOutOfMemoryError it runs a "kill -9 <pid>" command. WDDOutputStream is supposed to handle this Error by flushing its buffer and clearing space for more writing. (Configurable via HADOOP_CLIENT_OPTS in hadoop-env.sh; which sets client-side heap and just needs to be commented out)
Use your management layer (Ambari/Cloudera Manager, etc) to update the core-site.xml with the following property:
<property>
<name>fs.fusion.push.threshold</name>
<value>0</value>
</property>
This change will disable HFLUSH which is not required, given that S3 can't support appends.
S3 Silent Installation
You can complete an Amazon S3/EMRFS installation using the Silent Installation procedure, putting the necessary configuration in the silent_installer.properties as described in the previous section.
S3 specific settings
Environment Variables Required for S3 deployments:
- FUSIONUI_MANAGER_TYPE=UNMANAGED_S3
- FUSIONUI_INTERNALLY_MANAGED_USERNAME
- FUSIONUI_INTERNALLY_MANAGED_PASSWORD
- FUSIONUI_FUSION_BACKEND_CHOICE
- FUSIONUI_USER
- FUSIONUI_GROUP
- SILENT_PROPERTIES_PATH
silent_installer.properties File additional settings or specific required values listed here:
s3.installation.mode=true
s3.bucket.name
kerberos.enabled=false (or unspecified)
Example Installation
As an example (as root), running on the installer moved to /tmp.
# If necessary download the latest installer and make the script executable
chmod +x /tmp/installer.sh
# You can reference an original path to the license directly in the silent properties but note the requirement for being in a location that is (or can be made) readable for the $FUSIONUI_USER
# The following is partly for convenience in the rest of the script
cp /path/to/valid/license.key /tmp/license.key
# Create a file to encapsulate the required environmental variables (example is for emr-4.0.0):
cat <<EOF> /tmp/s3_env.sh
export FUSIONUI_MANAGER_TYPE=UNMANAGED_S3
export FUSIONUI_INTERNALLY_MANAGED_USERNAME=admin
export FUSIONUI_FUSION_BACKEND_CHOICE=emr-4.0.0':'2.6.0-amzn-0
export FUSIONUI_USER=hdfs
export FUSIONUI_GROUP=hdfs
export SILENT_PROPERTIES_PATH=/tmp/s3_silent.properties
export FUSIONUI_INTERNALLY_MANAGED_PASSWORD=admin
EOF
# Create a silent installer properties file - this must be in a location that is (or can be made) readable for the $FUSIONUI_USER:
cat <<EOF > /tmp/s3_silent.properties
existing.zone.domain=
existing.zone.port=
license.file.path=/tmp/license.key
server.java.heap.max=4
ihc.server.java.heap.max=4
server.latitude=54
server.longitude=-1
fusion.domain=my.s3bucket.fusion.host.name
fusion.server.dcone.port=6444
fusion.server.zone.name=twilight
s3.installation.mode=true
s3.bucket.name=mybucket
induction.skip=false
induction.remote.node=my.other.fusion.host.name
induction.remote.port=8082
EOF
# If necessary, (when $FUSIONUI_GROUP is not the same as $FUSIONUI_USER and the group is not already created) create the $FUSIONUI_GROUP (the group that our various servers will be running as):
[[ "$FUSIONUI_GROUP" = "$FUSIONUI_USER" ]] || groupadd hadoop
#If necessary, create the $FUSIONUI_USER (the user that our various servers will be running as):
useradd hdfs
# if [[ "$FUSIONUI_GROUP" = "$FUSIONUI_USER" ]]; then
useradd $FUSIONUI_USER
else
useradd -g $FUSIONUI_GROUP $FUSIONUI_USER
fi
# silent properties and the license key *must* be accessible to the created user as the silent installer is run by that user
chown hdfs:hdfs $FUSIONUI_USER:$FUSIONUI_GROUP /tmp/s3_silent.properties /tmp/license.key
# Give s3_env.sh executable permissions and run the script to populate the environment
. /tmp/s3_env.sh
# If you want to make any final checks of the environment variables, the following command can help - sorted to make it easier to find variables!
env | sort
# Run installer:
/tmp/installer.sh
S3 Setup through the installer
You can set up WD Fusion on an S3-based cluster deployment, using the installer script.
Follow this section to complete the installation by configuring WD Fusion on an S3-based cluster deployment, using the browser-based graphical user installer.
Open a web browser and point it at the provided URL. e.g
http://<YOUR-SERVER-ADDRESS>.com:8083/
- In the first "Welcome" screen you're asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows:
- Adding a new WD Fusion cluster
- Select Add Zone.
- Adding additional WD Fusion servers to an existing WD Fusion cluster
- Select Add to an existing Zone.
Welcome screen.
- Run through the installer's detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
Environmental checks.
On clicking validate the installer will run through a series of checks of your system's hardware and software setup and warn you if any of WD Fusion's prerequisites are not going to be met.
Example check results.
Address any failures before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if the installation is only for evaluation purposes and not for production. However, when installing for production, you should address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
- Upload the license file.
Upload your license file.
- The conditions of your license agreement will be presented in the top panel, including License Type, Expiry data, Name Node Limit and Data Node Limit.
Verify license and agree to subscription agreement.
Click on the I agree to the EULA to continue, then click Next Step.
- Enter settings for the WD Fusion server. See WD Fusion Server for more information about what is entered during this step.
Screen 4 - Server settings
- In step 5 the zone information is added.
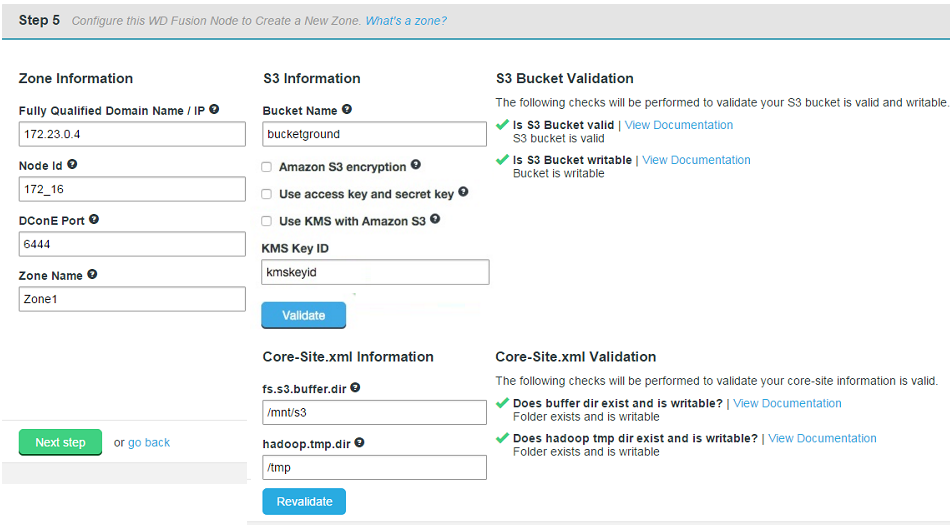
S3 Install
Zone Information
- Fully Qualified Domain Name
- the full hostname for the server.
- Node ID
- A unique identifier that will be used by WD Fusion UI to identify the server.
- DConE Port
- TCP port used by WD Fusion for replicated traffic.
- Zone Name
- The name used to identify the zone in which the server operates.
S3 Information
- Bucket Name
- The name of the S3 Bucket that will connect to WD Fusion.
- Amazon S3 encryption
-
- Tick to set your bucket to use AWS's built in data protection.
- Use access key and secret key
-
Additional details required if the S3 bucket is located in a different region. See Use access key and secret key.
- Use KMS with Amazon S3
- Use an established AWS Key Management Server See Use KMS with Amazon S3.
-
Use access key and secret key Tick this checkbox if your S3 bucket is located in a different region. This option will reveal additional entry fields:
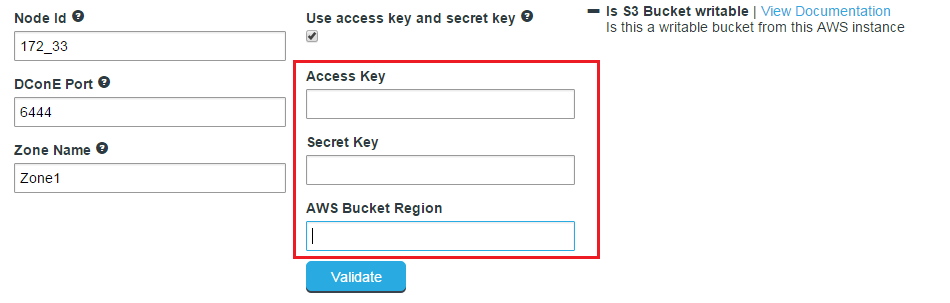
keys and Bucket
- Access Key
- This is your AWS Access Key ID.
- Secret Key
- This is the the secret key that is used in conjunction with your Access Key ID to sign programmatic requests that are sent to AWS.
- AWS Bucket Region
- Select the Amazon region for your S3 bucket. This is required if you need data to move between AWS regions which is blocked by default.
More about WDS Access Key ID and Secret Access Key
If the node you are installing is set up with the correct IAM role, thene you won't need to use the Access Key ID and Secret Key, as the EC2 instance will have access to S3. However if IAM is not correctly set for the instance or the machine isn't even in AWS then you need to provide both the Access Key ID and Secret Key.
Entered details are placed in core.site.xml.
Alternatively the AMI instance could be turned off. You could then create a new AMI based on it, then launch a new instance with the IAM based off of that AMI so that the key does not need to be entered.
"fs.s3.awsAccessKeyId"
"fs.s3.awsSecretAccessKey"
Read Amazon's documentation about Getting your Acess Key ID and Secret Access Key.
Use KMS with Amazon S3

KMS Key ID
This option must be selected if you are deploying your S3 bucket with AWS Key Management Service. Enter your KMS Key ID. This is a unique identifier of the key. This can be an ARN, an alias, or a globally unique identifier. The ID will be added to the JSON string used in the EMR cluster configuration.
KMS ID Key reference
Core-Site.xml Information
- fs.s3.buffer.dir
- The full path to a directory or multiple directories, separated by comma without space, that S3 will use for temporary storage. The install will check that the directory exists and that it will accept writes.
- hadooop.tmp.dir
- The full path to a one or more directories that Hadoop will use for "housekeeping" data storage. The installer will check that the directories that you provide exists and is writable. You can enter multiple directories separate by comma without space.
S3 bucket validation
The following checks are made during installation to confirm that the zone has a working S3 bucket.
| S3 Bucket Valid: |
The S3 Bucket is checked to ensure that it is available and that it is in the same Amazon region as the EC2 instance on which WD Fusion will run. If the test fails, ensure that you have the right bucket details and that the bucket is reachable from the installation server (in the same region for a start).
|
| S3 Bucket Writable: |
The S3 Bucket is confirmed to be writable. If this is not the case then you should check for a permissions mismatch.
|
The following checks ensure that the cluster zone has the required temporary filespace:
S3 core-site.xml validation
| fs.s3.buffer.dir |
Determines where on the local filesystem the S3 filesystem should store files before sending them to S3 (or after retrieving them from S3). If the check fails you will need to make sure that the property is added manually.
|
| hadoop.tmp.dir |
Hadoop's base for other temporary directory storage. If the check fails then you will need to add the property to the core-site.xml file and try to validate again.
|
These directories should already be set up on Amazon's (ephemeral) EC2 Instance Store and be correctly permissioned.
- The summary screen will now confirm all the details that you have entered so far.
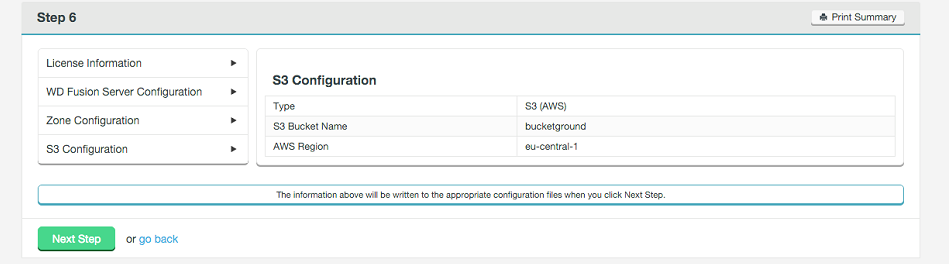
S3 Install details in the summary
Click Next Step if you are sure that everything has been entered correctly.
- In step 7 you need to handle the WD Fusion client installations.
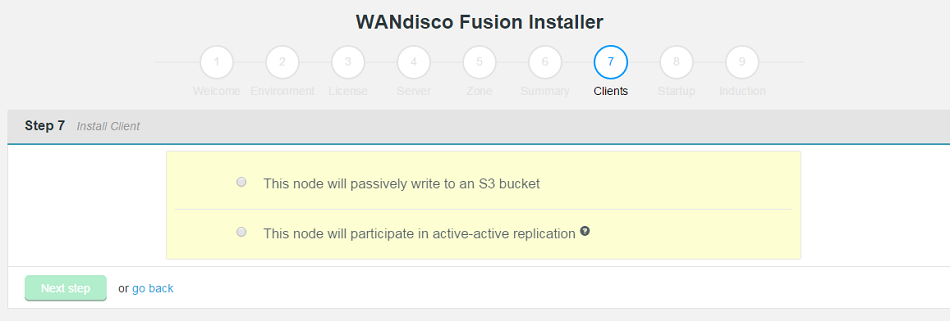
S3 Install
This step first asks you to confirm whether the node that you are installing will participate in Active-Active replication. If, instead the node will only ingest data to S3 then you don't need to install the WD Fusion client and can click on Next Step.
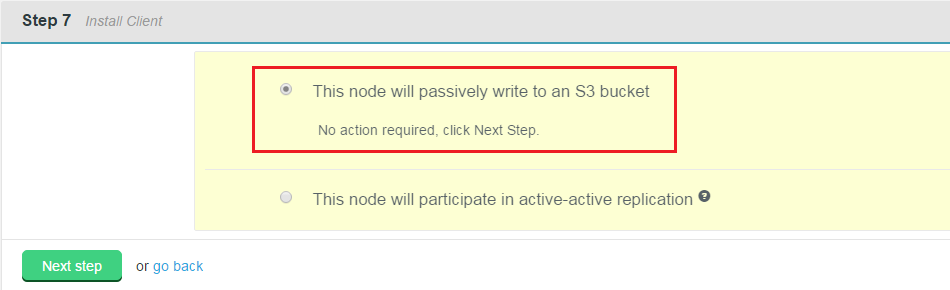
Client installation not required. Proceed to the next step.
For deployments where data will come back to the node through the EMR cluster then you should select This node will participate in active-active replication.

Client installation for S3
The installer covers two methods:
- Installing on a new Amazon Elastic MapReduce (EMR) cluster
- Installing on an existing Amazon EMR Cluster Not recommended
Installing on a new Amazon Elastic MapReduce (EMR) cluster
These instructions apply during the set up of WD Fusion on a new AWS EMR cluster. This is the recommended approach, even if you already have an EMR cluster set up.
- Login to your EC2 console and select EMR Managed Hadoop Framework.
S3 Install
- Click Create cluster. Enter the properties according to your cluster requirements.
S3 New EMR cluster
- Click Go to advanced options.
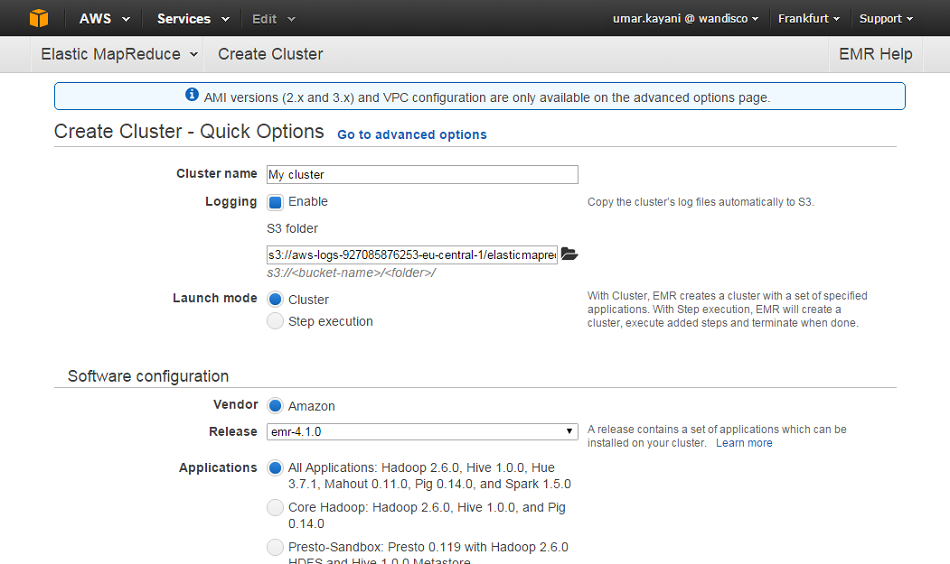
S3 Install
- Click on the Edit software settings (optional) dropdown. This opens up a Change settings entry field for entering your own block of configuration, in the form of a JSON string.
Enter the JSON string provided in the installer screen.
Copy the JSON string, provided by the installer. e.g.

JSON
JSON string is stored in the settings screen
You can get the JSON string after the installation has completed by going to the Settings screen.
Example JSON string
classification=core-site,properties=[fusion.underlyingFs=s3://example-s3/,fs.fusion.server=52.8.156.64:8023,fs.fusion.impl=com.wandisco.fs.client.FusionHcfs,fs.AbstractFileSystem.fusion.impl=com.wandisco.fs.client.FusionAbstractFs,dfs.client.read.prefetch.size=9223372036854775807]
The JSON String contains the necessary WD Fusion parameters that the client will need:
- fusion.underlyingFs
- The address of the underlying filesystem. In the case of Elastic MapReduce FS, the fs.defaultFS points to a local HDFS built on the instance storage which is temporary, with persistent data being stored in S3. Example: s3://wandisco
- fs.fusion.server
- The hostname and request port of the Fusion server. Comma-separated list of hostname:port for multiple Fusion servers.
- fs.fusion.impl
- The Abstract FileSystem implementation to be used.
- fs.AbstractFileSystem.fusion.impl
- The abstract filesystem implementation to be used.
- You need to take the client RPM and install script from the WD Fusion installer, make appropriate edits to the install script (more on that, below) and place them onto the S3 storage.
Install script location
A copy of the install_emr_client.sh script is stored within the following location within a WD Fusion installation:
/opt/wandisco/fusion-ui-server/ui/user_scripts/install_emr_client.sh
s3://<bucketName>/install_emr_client.sh
s3://<bucketName>/fusion-emr-x.x.x-client-dhfs-2.x.x.noarch.rpm
Install script edits
Here's an example of the install script, you'll need to plug in your own system paths:
#!/bin/bash
set -e
function usage() {
cat <<-EOF
usage: $0 S3_URI_OF_FUSION_CLIENT_RPM [ADDITIONAL_AWS_OPTIONS]
EOF
}
if [ "$#" -lt 1 ]; then
usage
exit -1
fi
TMP_DIR="/tmp"
RPM_LOCATION="${1}"
if ! [[ "${RPM_LOCATION}" =~ s3://[^/]+/.+ ]]; then
echo "${RPM_LOCATION} is not a valid S3 file location" >&2
usage
exit -1
fi
shift
ADDITIONAL_OPT="$@"
RPM_NAME=$(basename ${RPM_LOCATION})
CLIENT_INSTALL_DIR="/opt/wandisco/fusion/client/lib"
HADOOP_LIB_DIR="/usr/lib/hadoop/lib"
sudo aws ${ADDITIONAL_OPT} s3 cp "${RPM_LOCATION}" "${TMP_DIR}"
sudo yum install -y "${TMP_DIR}/${RPM_NAME}"
if [ -z $(which hadoop 2>/dev/null) ]; then
sudo mkdir -p "${HADOOP_LIB_DIR}"
sudo ln -s ${CLIENT_INSTALL_DIR}/* ${HADOOP_LIB_DIR}
fi
Key
- ${RPM_LOCATION}
- File path to the WD Fusion package, e.g.
s3://wandisco-s3/fusionInstall/
- ${ADDITIONAL_OPT}
- Any additional options that you need to run. For example, a region, if you are pointing to a different region, e.g.
--region zone1-us-west1.
- ${TMP_DIR}
- Path to the
fs.s3.buffer.dir ephemeral storage.
- ${RPM_NAME}
- The WD Fusion package name, e.g.
fusion-emr-4.1.0-client-hdfs-2.6.3.el6-1466.noarch.rpm
- ${HADOOP_LIB_DIR}
- Path to the Hadoop Lib directory, e.g.
/usr/lib/hadoop/lib/
- ${CLIENT_INSTALL_DIR}
- Path to the WD Fusion client install directory, e.g.
/opt/wandisco/fusion/client/lib/
Note the option refererence to "region". This option must be invoked if the corresponding S3 bucket is located on different region from the EC2 instance on which the command is run. It's also possible to tack the region onto the end of a command, e.g.
./install_emr_client.sh s3://wandisco-s3/fusionInstall/fusion-emr-4.1.0-client-hdfs-2.6.3.el6-1466.noarch.rpm --region us-w-1
- In the next step, create a Bootstrap Action that will add the WD Fusion client to cluster creation. Click on the Select a bootstrap action dropdown.
S3 Install
- Choose Custom Action, then click Configure and add.

S3 Install
- Complete the Add Bootstrap Action form.
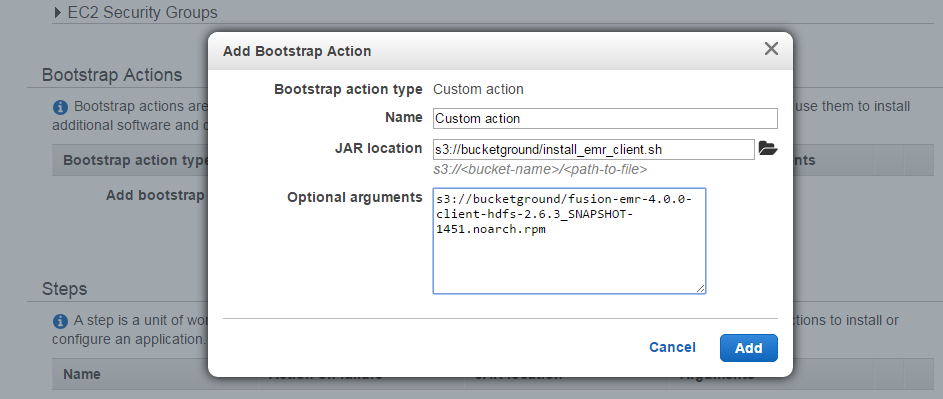
Add Bootstrap Action
In the JAR location you need to include the S3 path to the emr install script, i.e. install_emr_client.sh
In the Optional arguments add the S3 path to the WD fusion client RPM file. Remember to add the region, if necessary.
Click Add to store the action.
- Confirm that the custom Bootstrap Action has been added.
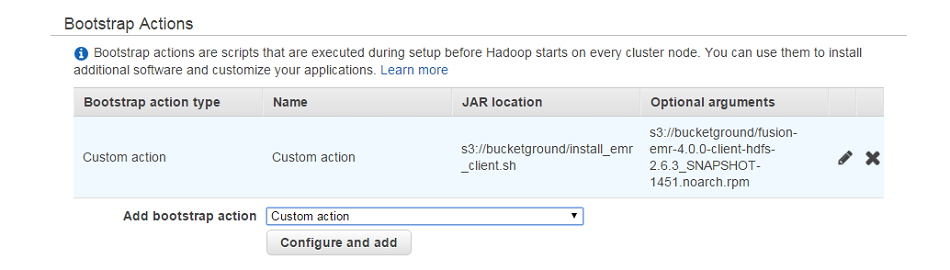
Confirm action
- Finally, click the Create cluster button to complete the AWS set up.

Create cluster
- Return to the WD Fusion setup, clicking on Start WD Fusion.
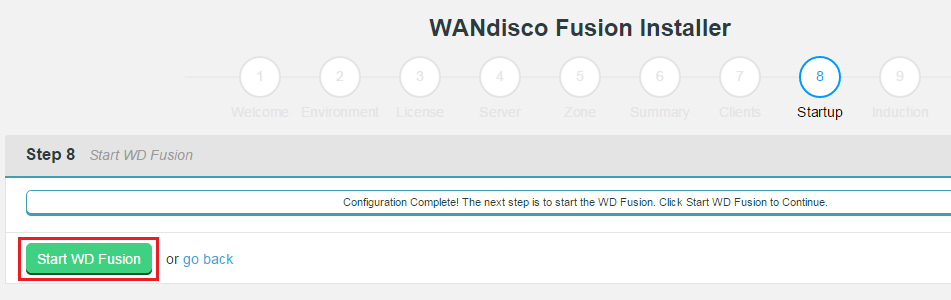
Deploy server
Installing on an existing Amazon Elastic MapReduce (EMR) cluster
We strongly recommend that you terminate your existing cluster and use the previous step for installing into a new cluster.
No autoscaling
This is because installing WD Fusion into an existing cluster will not benefit from AWS's auto-scaling feature. The configuration changes that you make to the core-site.xml file will not be included in automatically generated cluster nodes, as the cluster automatically grows you'd have to follow up by manually distributing the client configuration changes.
Two manual steps
Install the fusion client (the one for EMR) on each node and after scaling, modify the core-site.xml file with the following:
<property>
<name>fusion.underlyingFs</name>
<value>s3://YOUR-S3-URL/</value>
</property>
<property>
<name>fs.fusion.server</name>
<value>IP-HOSTNAME:8023</value>
</property>
<property>
<name>fs.fusion.impl</name>
<value>com.wandisco.fs.client.FusionHcfs</value>
</property>
<property>
<name>fs.AbstractFileSystem.fusion.impl</name>
<value>com.wandisco.fs.client.FusionAbstractFs</value>
</property>
- fusion.underlyingFs
- The address of the underlying filesystem. In the case of Elastic MapReduce FS, the fs.defaultFS points to a local HDFS built on the instance storage which is temporary, with persistent data being stored in S3. Example: s3://wandisco
- fs.fusion.server
- The hostname and request port of the Fusion server. Comma-separated list of hostname:port for multiple Fusion servers.
- fs.fusion.impl
- The Abstract FileSystem implementation to be used.
- fs.AbstractFileSystem.fusion.impl
- The abstract filesystem implementation to be used.
Known Issue running with S3
In WD Fusion 2.6.2 or 2.6.3, the first release supporting S3, there was a problem transferring very large files that needed to be worked around. If you are using this release in conjuction with Amazon's S3 storage then you need to make the following changes:
WD Fusion 2.6.2/2.6.3/AWS S3 Workaround
Use your management layer (Ambari/Cloudera Manager, etc) to update the core-site.xml with the following property:
<property>
<name>dfs.client.read.prefetch.size</name>
<value>9223372036854775807</value>
</property>
<property>
<name>fs.fusion.push.threshold</name>
<value>0</value>
</property>
This second parameter "fs.fusion.push.threshold" becomes optional from version 2.6.3, onwards. Although optional, we still recommend that you use the "0" Setting. This property sets the threshold for when a client sends a push request to the WD Fusion server. As the push feature is not supported for S3 storage disabling it (setting it to "0") may remove some performance cost.
S3 AMI Launch
This section covers the launch of WANdisco Fusion for S3, using Amazon's Cloud Formation Template. What this will do is automatically provision the Amazon cluster, attaching Fusion to an on-premises cluster.
IMPORTANT: Amazon cost considerations.
Please take note of the following costs, when running Fusion from Amazon's cloud platform:
- AWS EC2 instances are charged per hour or annually.
- WD Fusion nodes provide continuous replication to S3 that will translate into 24/7 usage of EC2 and will accumulate charges that are in line with Amazon's EC2 charges (noted above).
- When you stop the Fusion EC2 instances, Fusion data on the EBS storage will remain on the root device and its continued storage will be charged for. However, temporary data in the instance stores will be flushed as they don't need to persist.
- If the WD Fusion servers are turned off then replication to the S3 bucket will stop.
Prerequisites
There are a few things that you need to already have before you start this procedure:
- Amazon AWS account. If you don't have an AWS account, sign up through Amazon's Web Services.
- Amazon Key Pair for security. If you don't have a Key Pair defined. See Create a Key Pair.
- Ensure that you have clicked the Acept Terms button on the CFT's Amazon store page. E.g.
You must accept the terms for your specific version of Fusion
If you try to start a CFT without first clicking the Accept Terms button you will get an error and the CFT will fail. If this happens, go to the Amazon Marketplace, search for the Fusion download screen that correspond with the version that you are deploying, run through the screen until you have clicked the Accept Terms button. You can then successfully run the CFT.
Launch procedure
- Login to your AWS account and navigate to the awsmarketplace. Locate the WANdisco's
Fusion products. For the purpose of this guide we'll deploy the WANdisco Fusion S3 Active Migrator - BYOL, search for WANdisco using the search field.
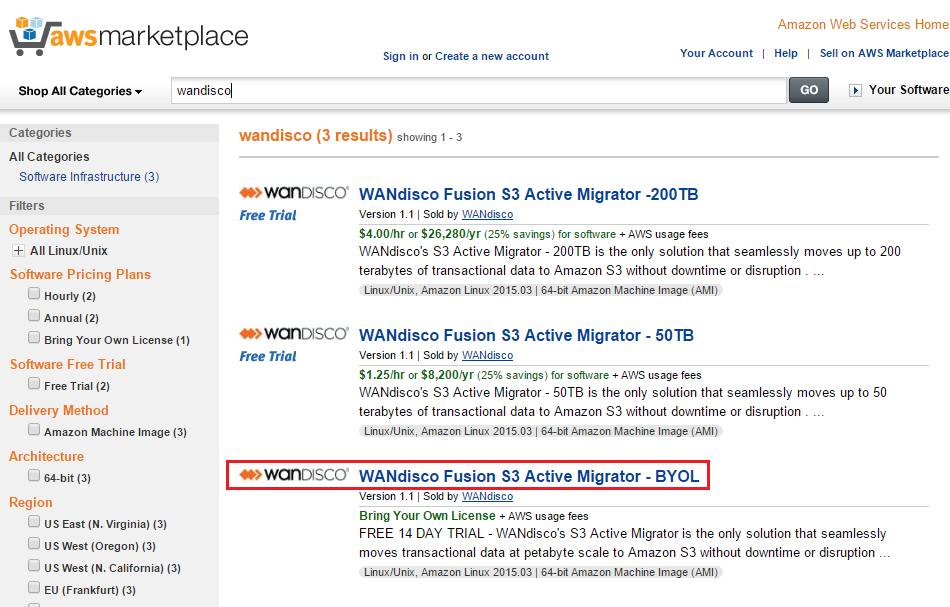
LocalFS figure 25.
Ensure that you download the appropriate version
The BYOL (Bring Your Own License) version requires that you purchase a license, seperately, from WANdisco. You can get set up immediately with a trial license, but you may prefer to run with one of the versions which come with built-in license, based on usage; 200TB or 50TB. Each version has its own download page and distinct Cloud Formation Template, so make sure that you get the one that you need.
- On the Select Template screen, select the option Specify an Amazon S3 template URL, entering the URL for WANdisco's template. For example:
https://s3.amazonaws.com/wandisco-public-files/Fusion-Cluster.template
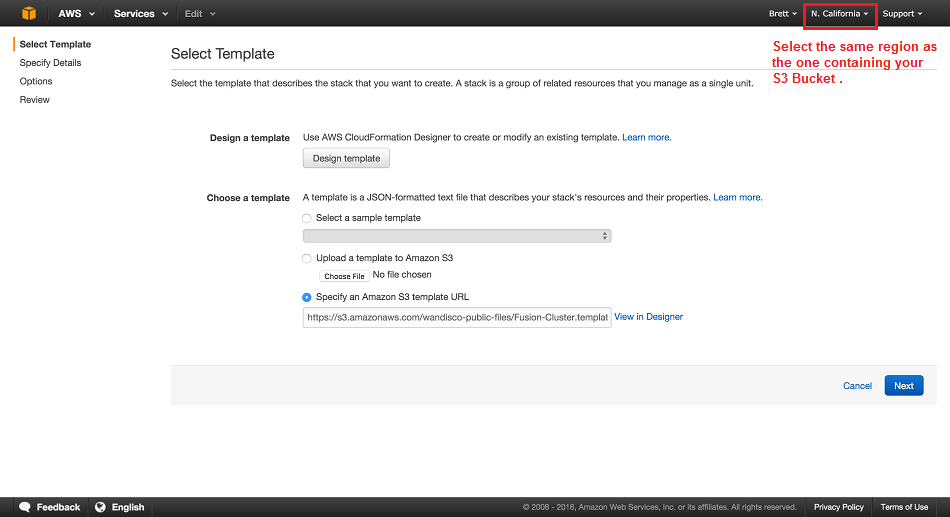
Amazon CFT Screen 1.
Ensure that you select the right Region (top-right on the Amazon screen). This must be set to the same region that hosts your S3 Bucket. Click Next to move to the next step.
- You now specify the parameters for the cluster.
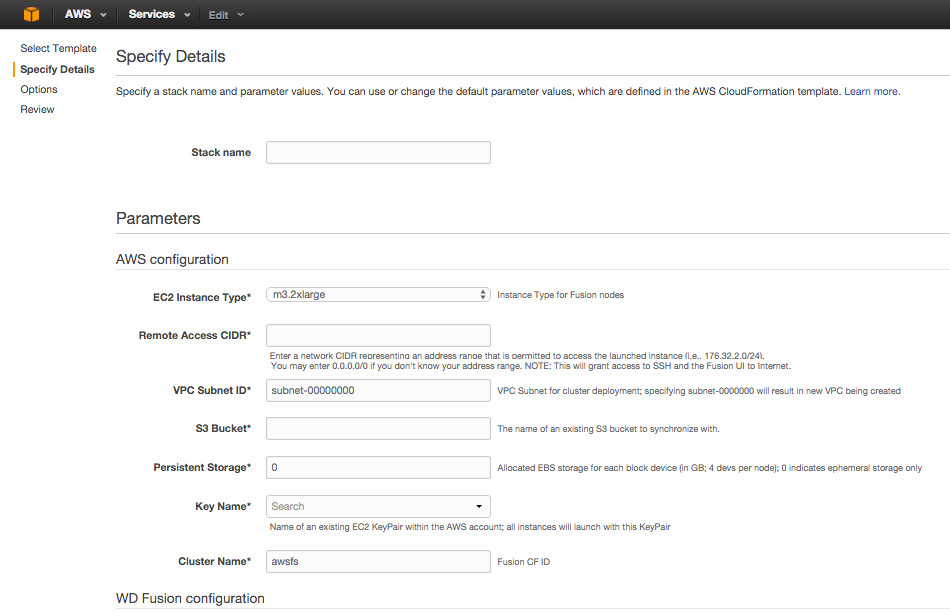
Amazon CFT Screen 2 - AWS Parameters
Enter the following details:
AWS configuration
- Stack name
- This is a label for your cluster that Amazon will use for reference. Give the cluster a meaningful name, e.g. FusionStack.
- Remote Access CIDR*
- An optional CIDR address for assigning access to the cluster. If you don't know the address you need you can use the range 0.0.0.0/0 which will open up a brand new virtual private cloud. It's recommended that you edit this later to lock down access.
- VPC Subnet ID *
- Entering addressing for your virtual private cloud. In this example we want to connect to an existing existing VPC, going into the settings and capturing its subnet ID. If you already have an on-premises cluster that you are connecting to then you are probably going to have a subnet to reference.
- S3Bucket *
- Enter the name of your Amazon S3 bucket, setting up permissions so that the we can only talk to the specified bucket.
- Persistent Storage *
- Use this field to add additional storage for your cluster. In general use, you shouldn't need to add any more storage, you can rely on the memory in the node plus the ephemeral storage.
- KeyName *
- Enter the name of the exiting EC2 KeyPair within your AWS account, all instances will launch with this KeyPair.
- Cluster Name *
- The WD Fusion CF identifier, in the example, awsfs
The * noted at the end of some field names indicate a required field that must be completed.
The next block of configuration is specific to the WD Fusion product:
WD Fusion configuration
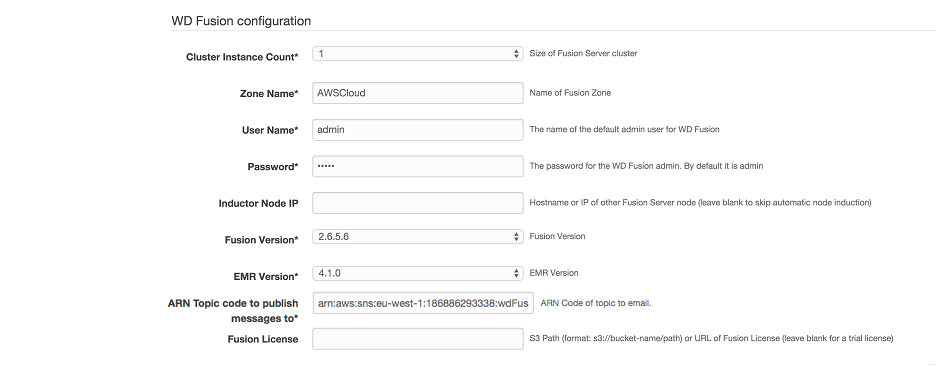
Amazon CFT Screen 3 - WD Fusion Parameters
- Cluster Instance Count*
- Enter the number of WD Fusion instances (1-3) that you'll launch. e.g. "2" This value is driven by the needs of the cluster, either for horizontal scaling, continuous availability of the WD Fusion service, etc. (dropdown)
- Zone Name *
- The logical name that you provide for your zone. e.g. awsfs
- User Name *
- Default username for the WD Fusion UI is "admin".
- Password *
- Default password for the WD Fusion UI is "admin".
- Inductor Node IP
- This is the hostname or IP address for an existing WD Fusion node that will be used to connect the new node into a membership.
How to get the IP address of an existing WD Fusion Node:
- Log into the WD Fusion UI.
- On the Fusion Nodes tab, click on the link to the existing WD Fusion Node.
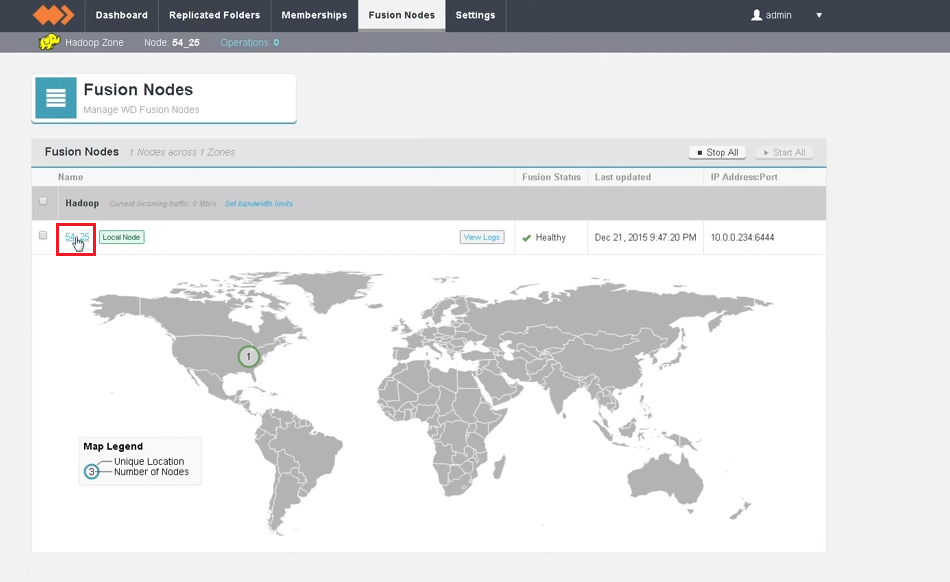
- Get the IP address from the Node information screen.
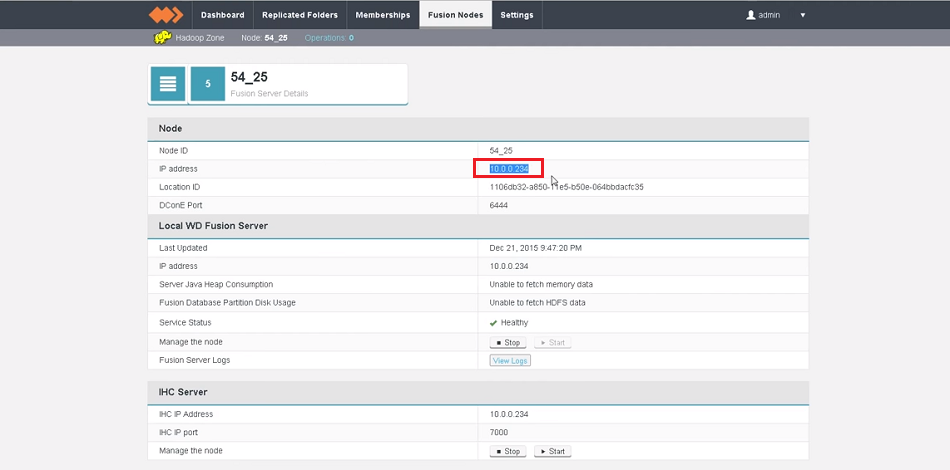
- Fusion Version *
- Select the version of WD Fusion that you are running. (Dropdown) e.g. 2.6.4.
- EMR Version *
- Select the version of Elastic MapReduce that you are running. (Dropdown)
- ARN Topic code to publish messages to *
- ARN Code to topic to email. If you set up an SNS service you can add an ARN code here to receive a notification when CFT completes succesfully. This oculd be an email, SMS message or various other message types supported by AWS SNS service.
- Fusion License
- This is a path to your WD Fusion license file. If you don't specify the path to a license key you will automatically get a trial license.
The * noted at the end of some field names indicate a required field that must be completed.
S3 Security configuration for WD Fusion
- KMSKey
- ARN for KMS Encryption Key ID. You can leave the field blank to disable KMS encryption.
- S3ServerEncryption
- Enable server-side encryption on S3 with a "Yes", otherwise leave as "No".
Click Next.
- On the next screen you can add options, such as Tags for resources in your stack, or Advanced elements.
We recommend that you disable the setting Rollback on failure. This ensures that if there's a problem when you deploy, the log files that you would need to diagnose the cause of the failure don't get wiped as part of the rollback.
LocalFS figure 35.
Click Next.
- You will now see a review of the template settings, giving you a chance to make sure that all settings are correct for your launch.

At the end, take note of any Capabilities notices and finally tick the checkbox for I acknowledge that this template might cause AWD CloudFormation to create IAM (Identity and Access Management) resources. Click Create or click Previous to navigate back to make any changes.

- The creation process will start. You'll see the Stack creation process running.
- You will soon see the stack creation in progress and can follow the individual creation events.
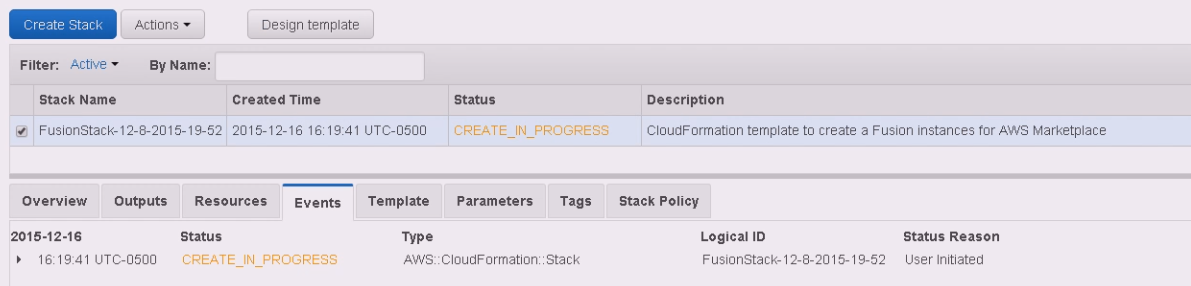 This template will create your set number of WD Fusion servers, pre-install them to the point where they're ready to be inducted into on premises cluster.
This template will create your set number of WD Fusion servers, pre-install them to the point where they're ready to be inducted into on premises cluster.
- Your WD Fusion servers will now be set up, connecting your on-premises Hadoop to your AWS cloud storage.
Default Username and Password
The WANdisco AMI creates a node for which the login credentials are:
- Username:
- admin
- Password:
- password
IMPORTANT: Reset the password using the following procedure.
Reset internally managed password
WD Fusion normally uses the authentication built into your cluster's management layer, i.e. the Cloudera Manager username and password are required to login to WD Fusion. However, in Cloud-based deployments, such as Amazon's S3, there is no management layer. In this situation, WD Fusion adds a local user to WD Fusion's ui.properties file. In this scenario, if you need to reset the internal password for any reason follow these instructions:
Password Reset Procedure: in-situ
- Stop the UI server.
- Invoke the reset runner:
JAVA_HOME/bin/java" -cp APPLICATION_ROOT/fusion-ui-server.jar com.wandisco.nonstopui.authn.ResetPasswordRunner -p NEW_PASSWORD -f PATH_TO_UI_PROPERTIES_FILE
- Start the UI server. e.g.
service fusion-ui-server start
If you fail to provide these arguments the reset password runner will prompt you.
Password Reset Procedure: AMI
Note that if you reset your password you will also need to update it on your Amazon IAMs.
Removing the stack
You can remove the WD Fusion deployment simply by removing the stack. See Delete Stack.
IMPORTANT: After deleting the stack you will need to manually remove the associated EC2 instance. Previously this wasn't required as the instance was attached to an autoscaling group. Instances are now removed from the autoscaling group because the replication system doesn't yet support dynamic scaling.
2.9 Installing WD Fusion into Microsoft Azure
This section will run you through an installation of WANdisco's Fusion to enable you to replicate on-premises data over to a Microsoft Azure object (blob) store.
This procedure assumes that you have already created all the key components for a deployment using a Custom Azure template. You will first need to create a virtual network, create a storage account, then start completing a template for a HDInsight cluster:
- Log in to the Azure portal, create a Custom deployment. On the Edit template panel, click Edit parameters
MS Azure - WD Fusion Parameters 01
Template properties
- Subscription
- This is your MS Azure account plan.
- Resource Group (string)
- Your existing Azure resource group that you are deploying to.
- Location (string)
- The geographical location of your cloud.
- Legal terms
- Review and agree with Microsoft's terms for using Azure.
Parameters
- EXISTINGVNETRESOURCEGROUPNAME (string)
- Enter a name of an existing VNS Group Name.
- EXISTINGSUBNETCLIENTSNAME (string)
- Enter a name of an existing subnet client.
- SSHUSERNAME (string)
- Your SSH Username, used to remotely access the the cluster and edge node vm machine.
- EDGENODEVIRTUALMACHINESIZE (string)
- Select the size of your edge node virtual machine.
- Continue to enter the required field values.
Azure - WD Fusion Parameters 02
- AZURESTORAGECONTAINERNAME
- The name of your storage container.
- AZURESTORAGEBLOBKEY
- The access key for your BLOB storage.
- FUSIONADMIN
- The admin username that you'll use to access WD Fusion's UI.
- FUSIONPASSWORD
- The password for accessing WD Fusion's UI.
- FUSIONVERSION
- The version of WD Fusion that you will be running with. E.g 2.6.
- FUSIONLICENSE
- The WANdisco license key file path.
- ZONENAME
- The name that you give to the Fusion zone.
- SERVERLATITUDE
- The latitude for the WD Fusion server's location.
- SERVERLONGITUDE
- The longitude for the WD Fusion server's location.
- IHCHEAPSIZE
- The IHC Server's allocated Maximum Heap (in GB).
- INDUCTORNODEIP
- The IP Address of the Inductor Node. You'll need to get this from an existing WD Fusion server.
- Confirm that you agree to Microsoft's terms and conditions, then click Create.
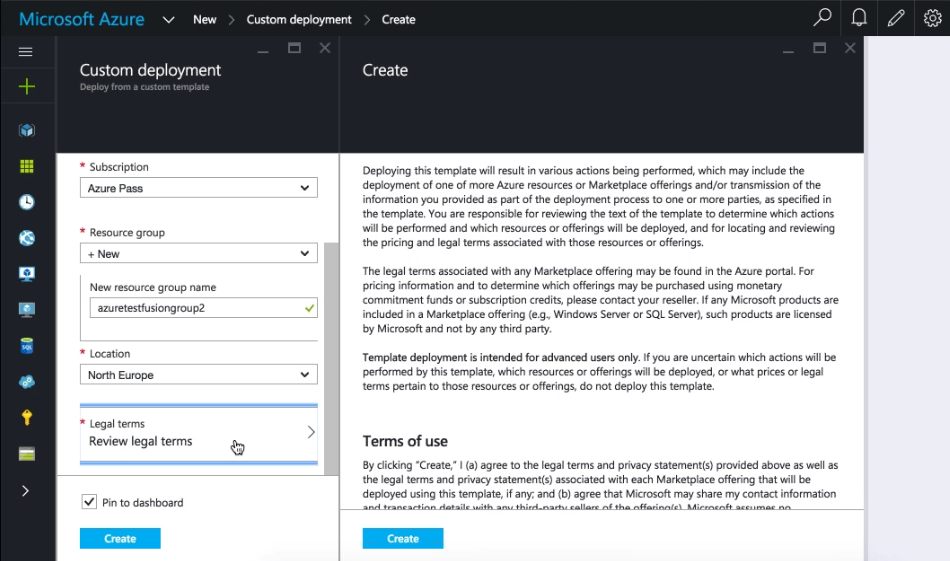
MS Azure MS Azure - Ts&Cs
WD Fusion Installation
In this next stage, we'll install WD Fusion
- Download the installer script to the WD Fusion server. Open a terminal session, navigate to the installer script, make it executable and then run it, i.e.
chmod +x fusion-ui-server_hdi_deb_installer.sh
sudo ./fusion-ui-server_hdi_deb_installer.sh
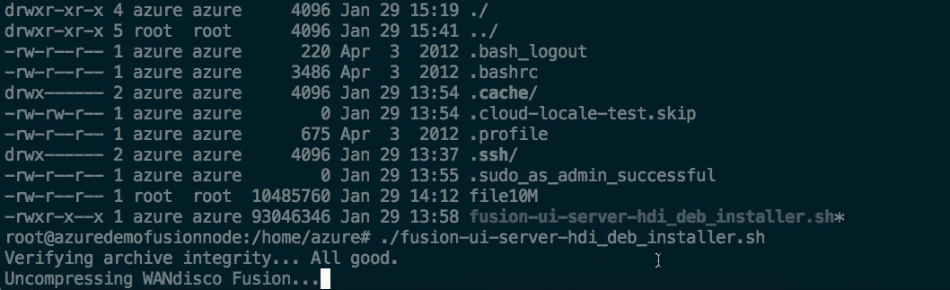
MS Azure - WD Fusion Installation 01
- Enter "Y" and press return.
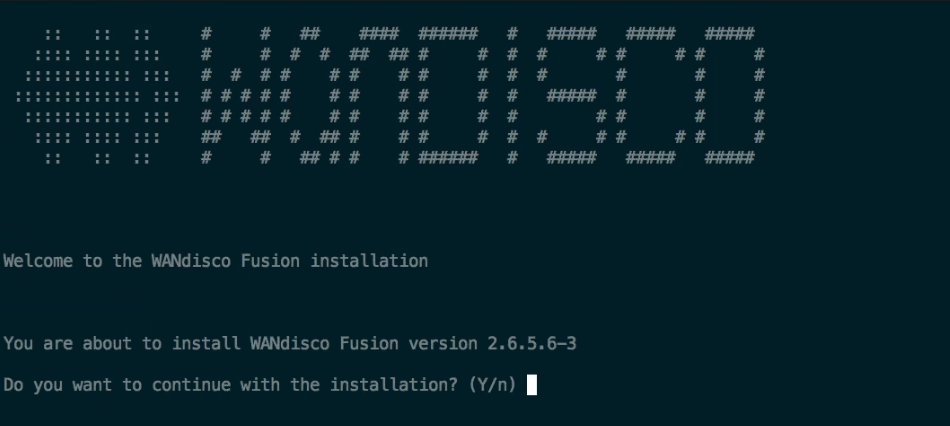
MS Azure - WD Fusion Installation 01
- Enter the system user that will run WD Fusion, e.g. "hdfs".
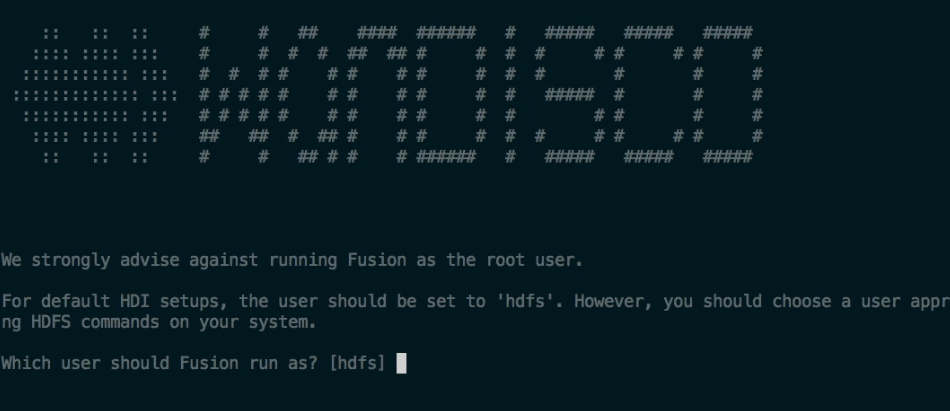
MS Azure - WD Fusion Installation 01
- Enter the group under which WD Fusion will be run. By default HDI uses the "hadoop" group.
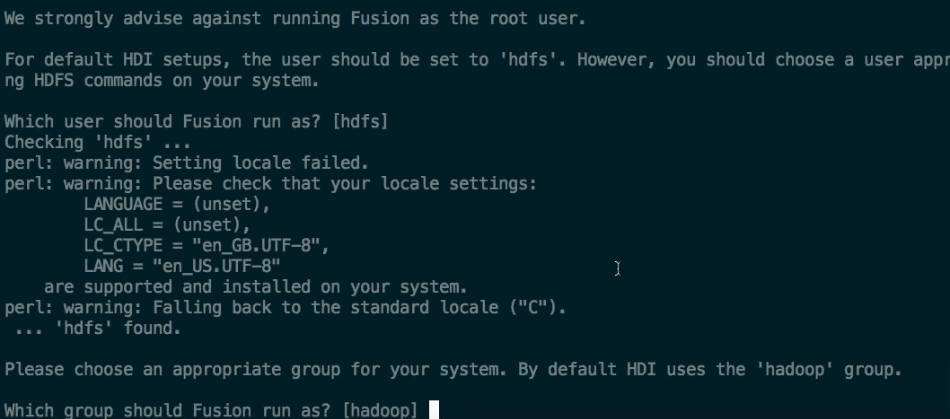
MS Azure - WD Fusion Installation 01
- The installer will now check that WD Fusion is running over the default web UI port, 8083.
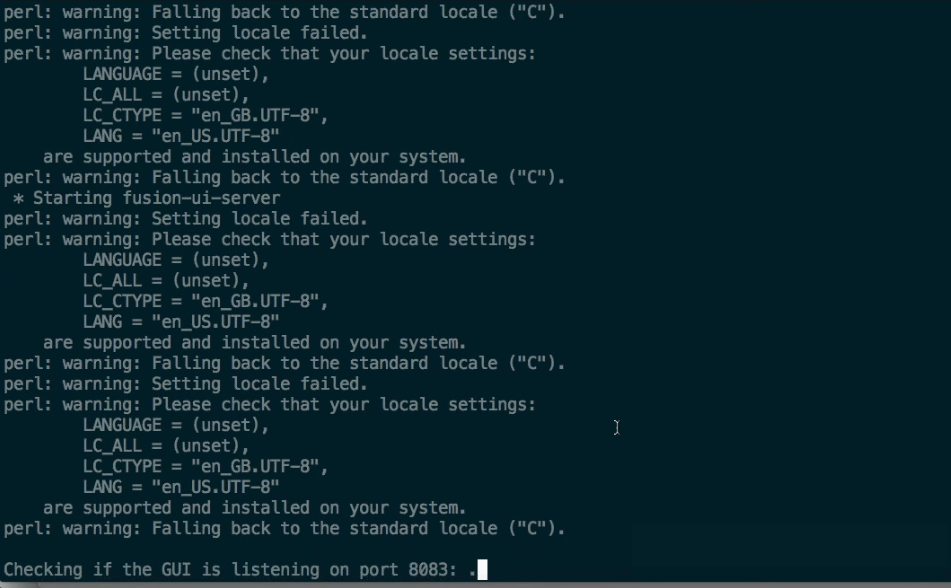
MS Azure - WD Fusion Installation 01
- Point your browser at the WD Fusion UI.
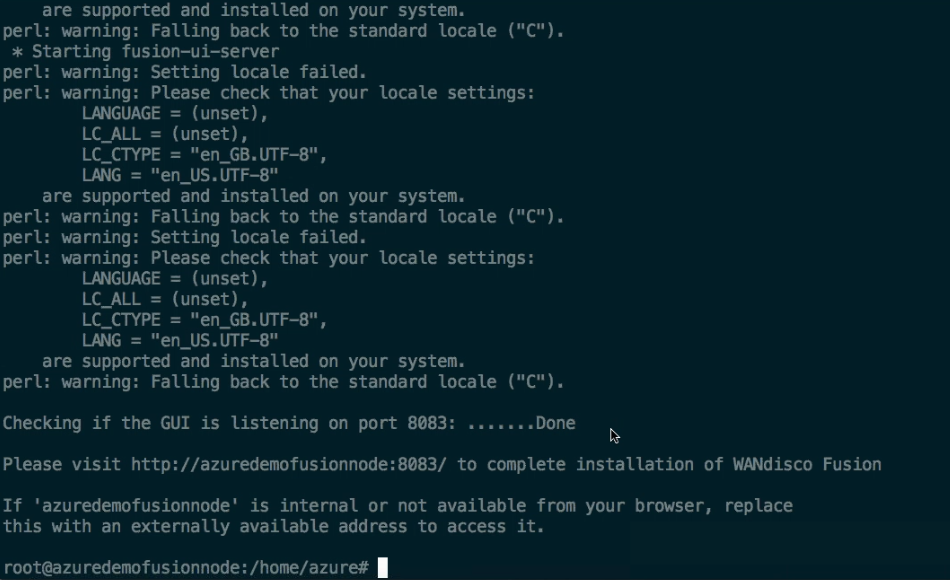
MS Azure - WD Fusion Installation 01
- You will be taken to the Welcome screen of the WD Fusion installer. For a first installation you select Add Zone.
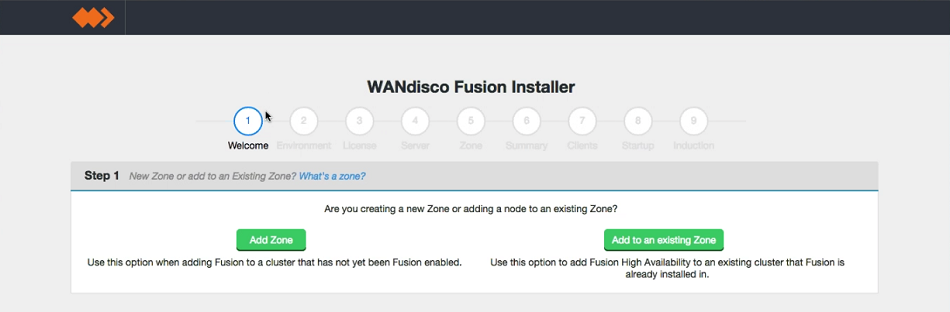
MS Azure - WD Fusion Installation 01
- Run through the installer's detailed Environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the Appendix.
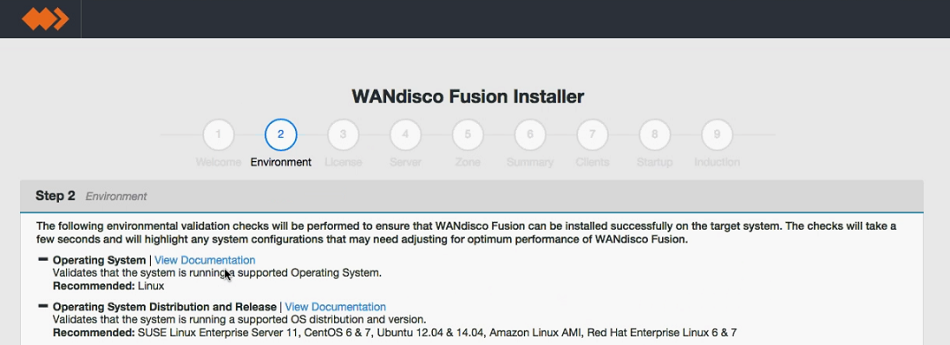
MS Azure - WD Fusion Installation 01
On clicking validate the installer will run through a series of checks of your system's hardware and software setup and warn you if any of WD Fusion's prerequisites are missing.
- Any element that fails the check should be addressed before you continue the installation. Warnings may be ignored for the purposes of completing the installation, especially if the installation is only for evaluation purposes and not for production. However, when installing for production, you should also address all warnings, or at least take note of them and exercise due care if you continue the installation without resolving and revalidating.
Click Next Step to continue the installation.

MS Azure - WD Fusion Installation 01
- Click on Select a file, navigate to your WANdisco Fusion license file.
MS Azure - WD Fusion Installation 01
- Click Upload.
MS Azure - WD Fusion Installation 01
- The license properties are presented. along with the WD Fusion End User License Agreement. Click the checkbox to agree, then click Next Step.
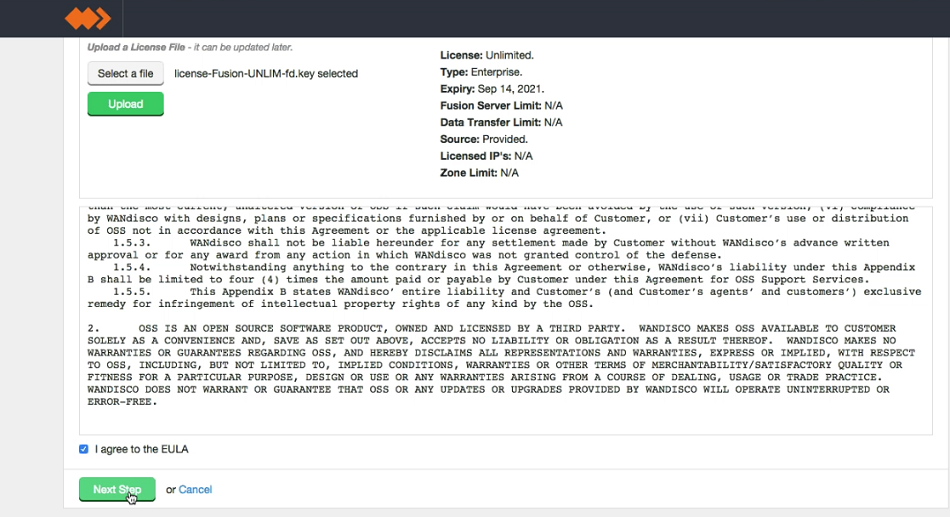
MS Azure - WD Fusion Installation 01
- Enter settings for the WD Fusion server.
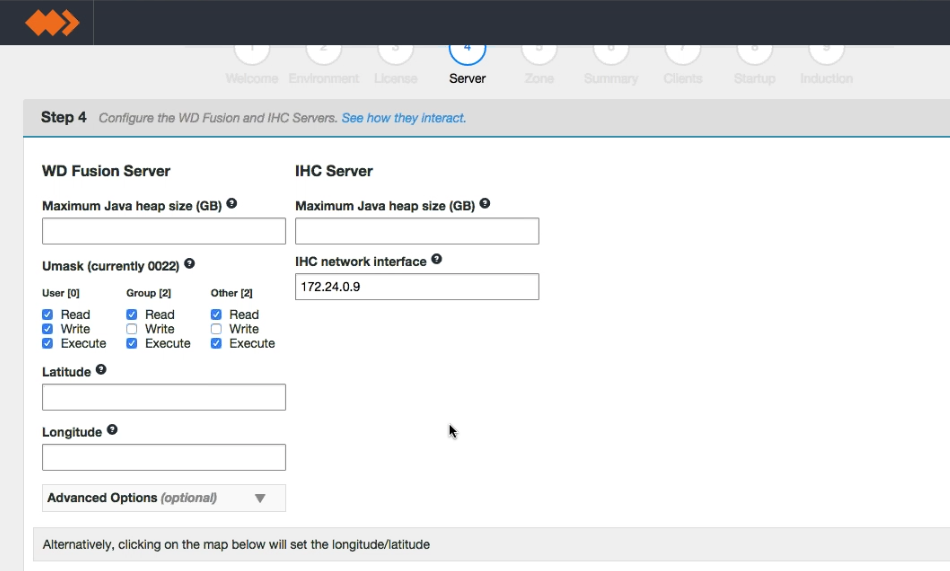
MS Azure - WD Fusion Installation 01
WD Fusion Server
- Fusion Server Max Memory (GB)
- Enter the maximum Java Heap value for the WD Fusion server. We recommend that for production you should top out with at least 16GB.
Recommendation
For the purposes of our example installation, we've entered 2GB. We recommend that you allocate 70-80% of the server's available RAM.
Read more about Server hardware requirements.
- Umask (currently 022)
- Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
- Latitude
- The north-south coordinate angle for the installation's geographical location.
- Longitude
- The east-west coordinate angle for the installation's geographical location. The latitude and longitude is used to place the WD Fusion server on a global map to aid coordination in a far-flung cluster.
IHC Server
IHC Settings
- Maximum Java heap size (GB)
- Enter the maximum Java Heap value for the WD Inter-Hadoop Communication server. We recommend that for production you should top out with at least 16GB.
- IHC Network Interface
- The address on which the IHC (Inter-Hadoop Connect) server will be located on.
Once all settings have been entered, click Next step.
- In this step you enter Fusion's Zone information and some important Microsoft Asure properties:
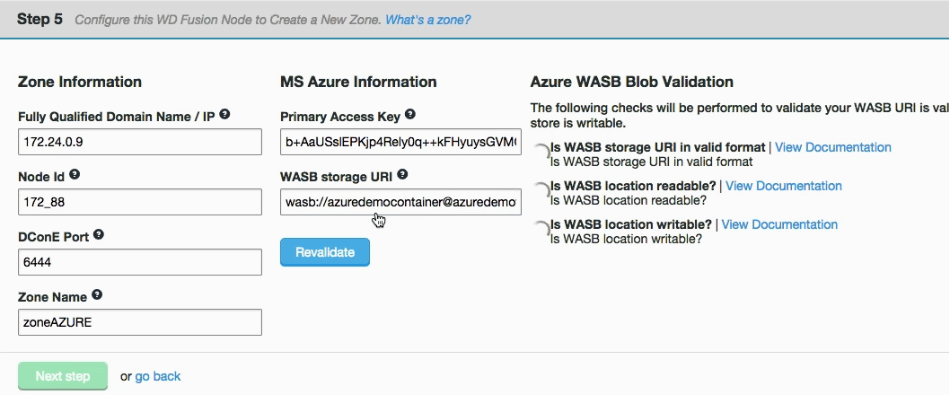
MS Azure - WD Fusion Installation 01
Zone Information
- Fully Qualified Domain Name
- Full hostname for the server.
- Node ID
- A unique identifier that will be used by WD Fusion UI to identify the server.
- DConE Port
- TCP port used by WD Fusion for replicated traffic.
- Zone Name
- Name used to identify the zone in which the server operates.
MS Azure Information
- Primary Access Key
- When you create a storage account, Azure generates two 512-bit storage access keys, which are used for authentication when the storage account is accessed. By providing two storage access keys, Azure enables you to regenerate the keys with no interruption to your storage service or access to that service. The Primary Access Key is now referred to as Key1 in Microsoft's documentation. You can get the KEY from the Microsoft Azure storage account:

- WASB storage URI
- this is the native URI used for accessing Azure Blob storage. E.g.
wasb://
- Validate (button)
-
The installer will make the following validation checks:
- WASB storage URI:
- The URI will need to take the form:
wasb[s]://<containername>@<accountname>.blob.core.windows.net
- URI readable
- Confirms that it is possible for WD Fusion to read from the Blob store.
- URI writable
- Confirms that it is possible for WD Fusion to write data to the Blob store.
- You now get a summary of your installation. Run through and check that everything is correct. Then click Next Step.
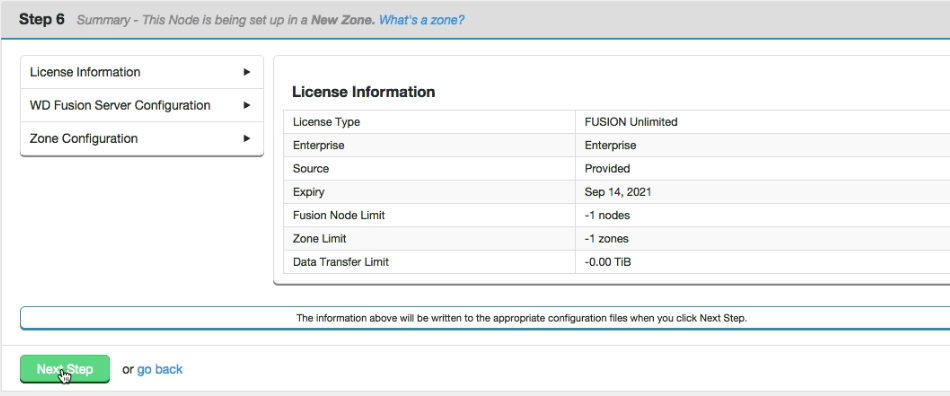
MS Azure - WD Fusion Installation 01
- In the next step you must complete the installation of the WD Fusion client package on all the existing HDFS client machines in the cluster. The WD Fusion client is required to support data WD Fusion's replication across the Hadoop ecosystem. Download the client DEB file. Leave your browser session running while you do this, we've not finished with it yet.
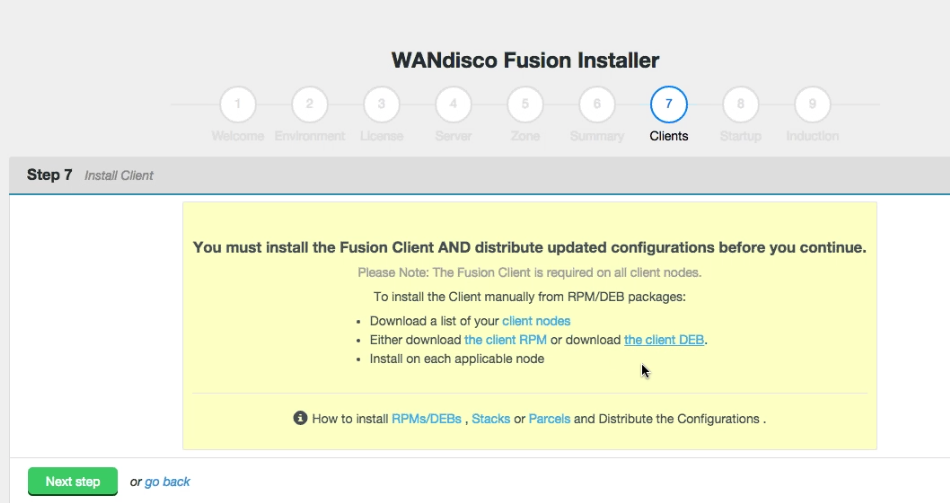
MS Azure - WD Fusion Installation 01
- Return to your console session. Download the client package "fusion-hdi-x.x.x-client-hdfs_x.x.x.deb".
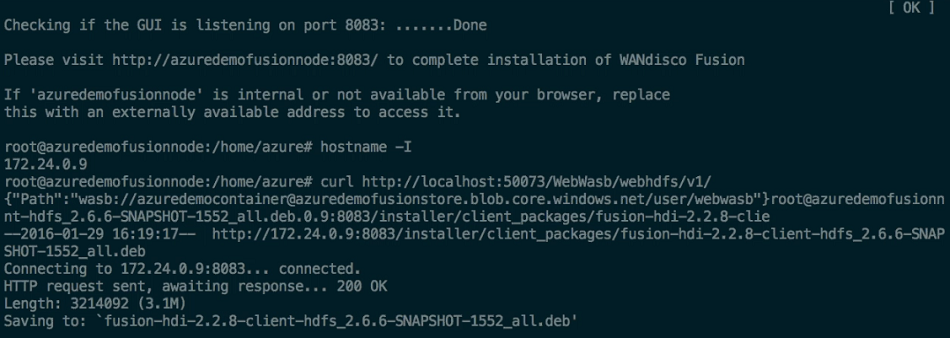
MS Azure - WD Fusion Installation 01
- Install the package on each client machine:

MS Azure - WD Fusion Installation 01
e.g.
dpkg -i fusion-hdi-x.x.x-client-hdfs.deb

MS Azure - WD Fusion Installation 01
- Return to the WD Fusion UI. Click Next Step, then click Start WD Fusion.
MS Azure - WD Fusion Installation 01
- Once started we now complete the final step of installer's configuration, Induction.
For this first node you will miss this step out, choosing to Skip Induction. For all the following node installations you will provide the FQDN or IP address and port of this first node. (In fact, you can complete induction by referring to any node that has itself completed induction.)
What is induction?
Multiple instances of WD Fusion join together to form a replication network or ecosystem. Induction is the process used to connect each new node to an existing set of nodes.
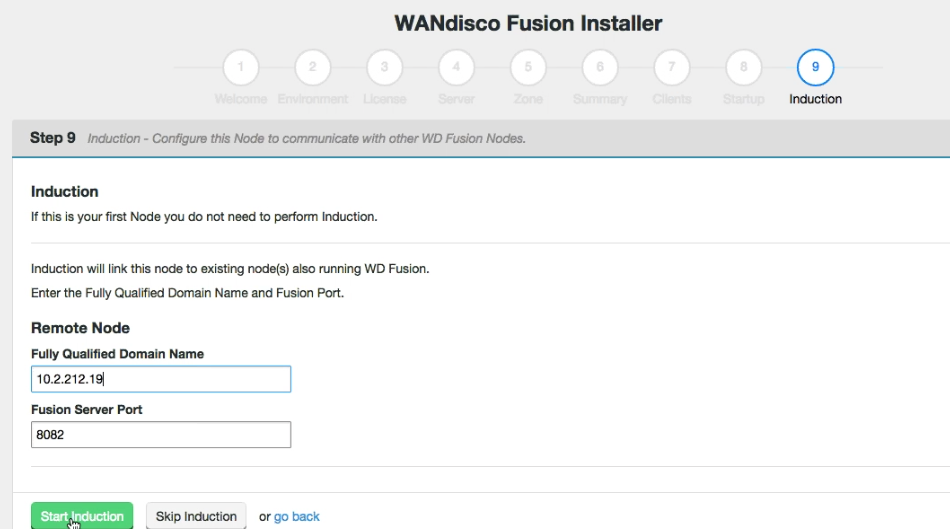
MS Azure - WD Fusion Installation 01
- Once you have completed the installation of a second node in your on-premises zone, you will be able to complete induction so that both zones are aware of each other.
MS Azure - WD Fusion Installation 01
- Once induction has been completed you will see bashboard status for each inducted zone. Click on Membership.
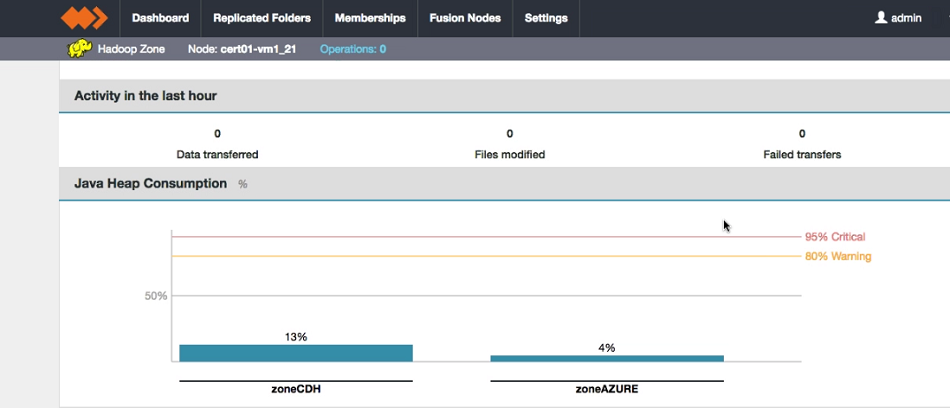
MS Azure - WD Fusion Installation 01
- Click on the Create New tab. The "New Membership" window will open that will display the WD Fusion nodes organized by zone.
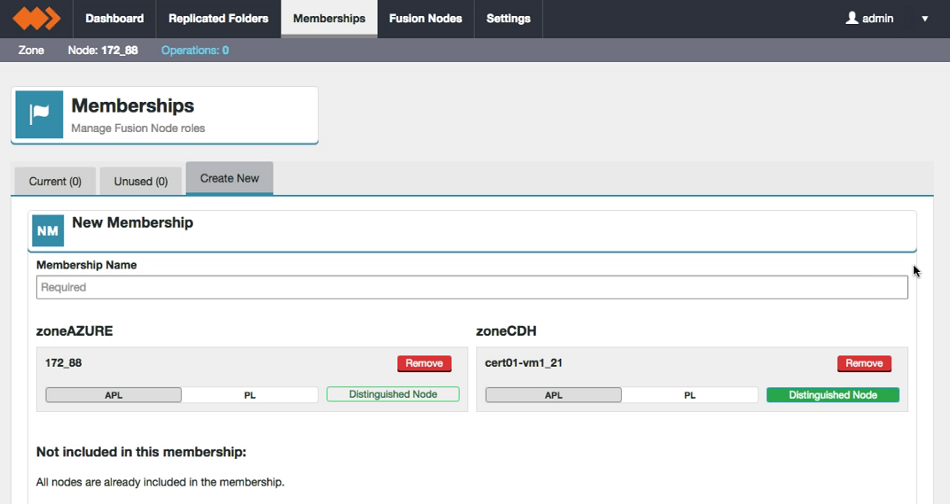
MS Azure - WD Fusion Installation 01
In this example we make the on-premises CDH server the Distinguished Node, as we'll be copying data to the cloud, in an Active-Passive configuration. Click Create.
For advise on setting up memberships, see Creating resilient Memberships.
- Next, click on the Replicated Folders tab. Click + Create.
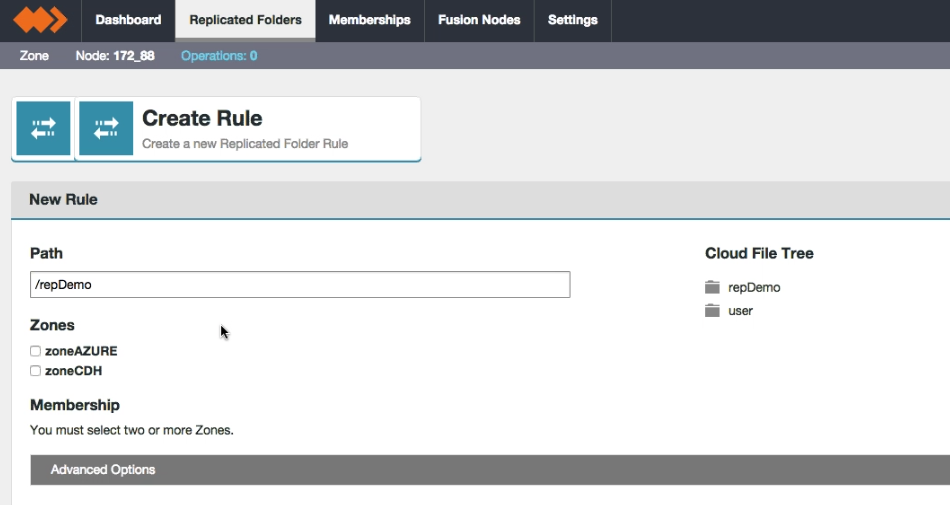
MS Azure - WD Fusion Installation 01
2.10 Installing WD Fusion into Google Cloud Platform
This section will run you through an installation of WANdisco's Fusion to enable you to replicate on-premises data over to Google's Cloud platform.
- Log into the Google Cloud Platform. Under VM instances, click Create instance.
Google Compute - WD Fusion Installation 01
- Set up suitable specification for the VM.
Google Compute - WD Fusion Installation 01
- Machine type
- 2vCPUs recommended for evaluation.
- Boot disk
- Click on the Change button and select Centos6.7.
- Firewall
- Enable publically available HTTP and HTTPS.
- Management, disk, networking, access & security options
-
There are two options here:
Specify the start up script, you have two options:
Set up networking:
- Click on Network
- Select fusion-gcw (our VPC)
- Project Access, Tick the checkbox "Allow API access to all Google Cloud services in the same project".
Google Compute - WD Fusion Installation 01
- Click on the Management tab.

Google Compute - WD Fusion Installation 01
- Under Metadata add the following key:
Google Compute - WD Fusion Installation 01
- startup-script-url
- https://storage.googleapis.com/wandisco-public-bucket/installScript.sh (see sample code)
Click Add item
- Click on the Networking tab.
Google Compute - WD Fusion Installation 01
- Network
- Your Google network VPC, e.g. fusion-gce.
- Click Create.
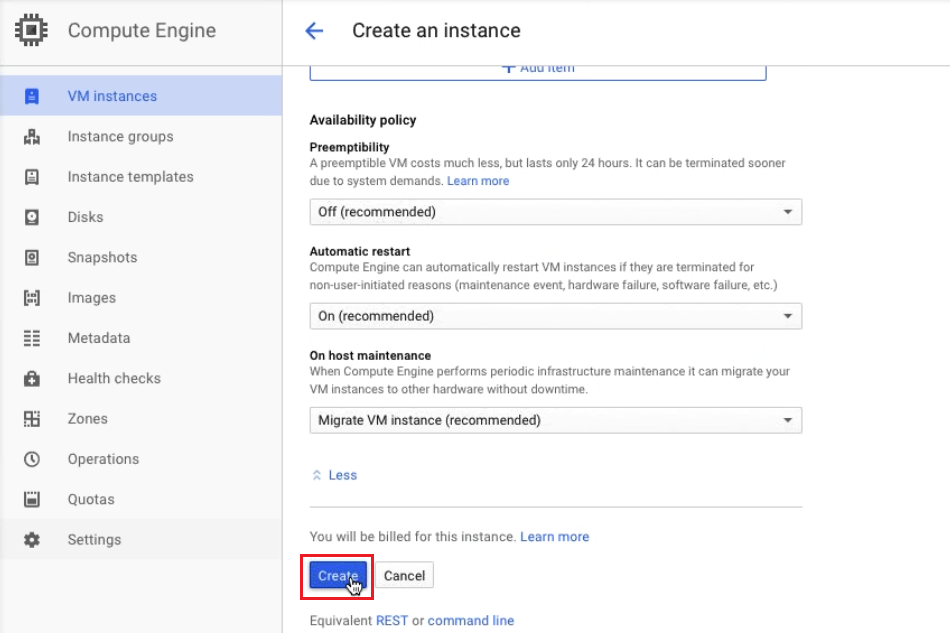
Google Compute - WD Fusion Installation 01
- There will be a brief delay while the instance is set up. You will see the VM instances panel that shows the VM system activity.
Google Compute - WD Fusion Installation 01
- When the instance is complete, click on it.

Google Compute - WD Fusion Installation 01
- You will see the management screen for the instance.
Google Compute - WD Fusion Installation 01
- Make a note of the internal IP address, it should look like
172.25.0.x.
Google Compute - WD Fusion Installation 01
Configuration
WD Fusion is now installed. Next, we'll complete the basic configuration steps using the web UI.
- In the first "Welcome" screen you're asked to choose between Create a new Zone and Add to an existing Zone.
Make your selection as follows: Add Zone
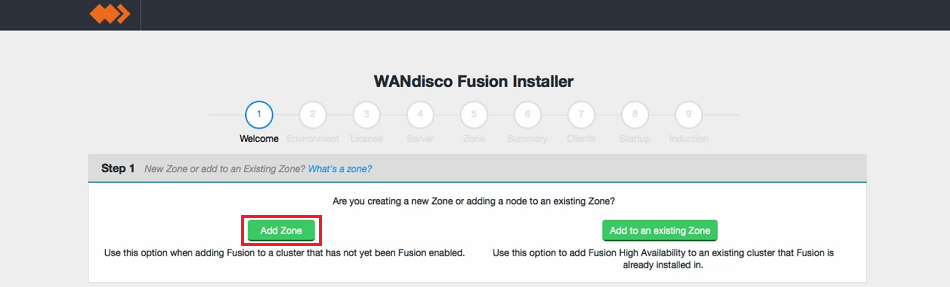
Google Compute - WD Fusion Installation 01
- Run through the installer's detailed environment checks. For more details about exactly what is checked in this stage, see Environmental Checks in the User Guide's Appendix.
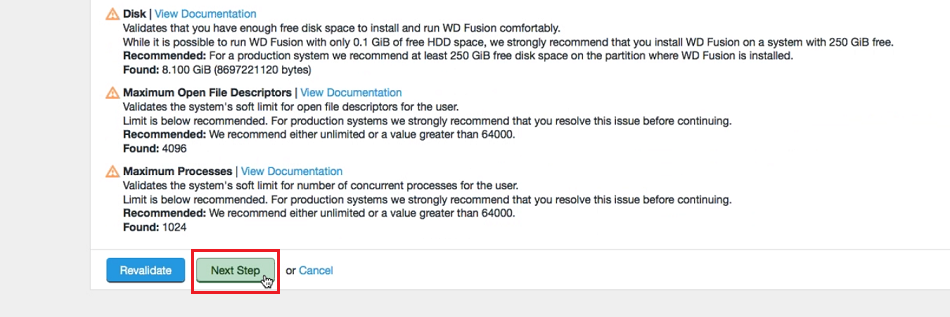
Google Compute - WD Fusion Installation 01
On clicking Validate, any element that fails the check should be addressed before you continue the installation.
- Click on Select file and then navigate to the license file provided by WANdisco.
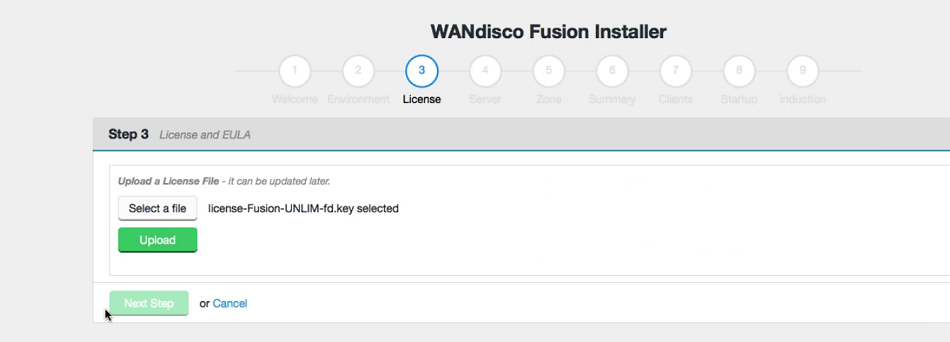
Google Compute - WD Fusion Installation 01
- Enter settings for the WD Fusion server.
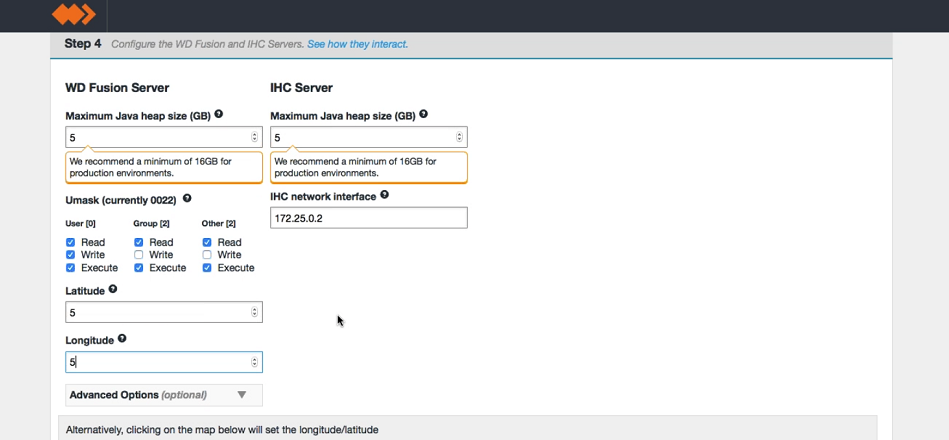
Google Compute - WD Fusion Installation 01
WD Fusion Server
- Fusion Server Max Memory (GB)
- Enter the maximum Java Heap value for the WD Fusion server. We recommend that for production you should top out with at least 16GB.
- Umask (currently 022)
- Set the default permissions applied to newly created files. The value 022 results in default directory permissions 755 and default file permissions 644. This ensures that the installation will be able to start up/restart.
- Latitude
- The north-south coordinate angle for the installation's geographical location.
- Longitude
- The east-west coordinate angle for the installation's geographical location. The latitude and longitude is used to place the WD Fusion server on a global map to aid coordination in a far-flung cluster.
IHC Server
- Maximum Java heap size (GB)
- Enter the maximum Java Heap value for the WD Inter-Hadoop Communication server. We recommend that for production you should top out with at least 16GB.
- IHC Network Interface
- The address on which the IHC (Inter-Hadoop Connect) server will be located on.
Once all settings have been entered, click Next step.
- Next, you will enter the settings for your new Zone. You are going to need the name of the Google Bucket, you can check this on your Google Cloud Storage screen.
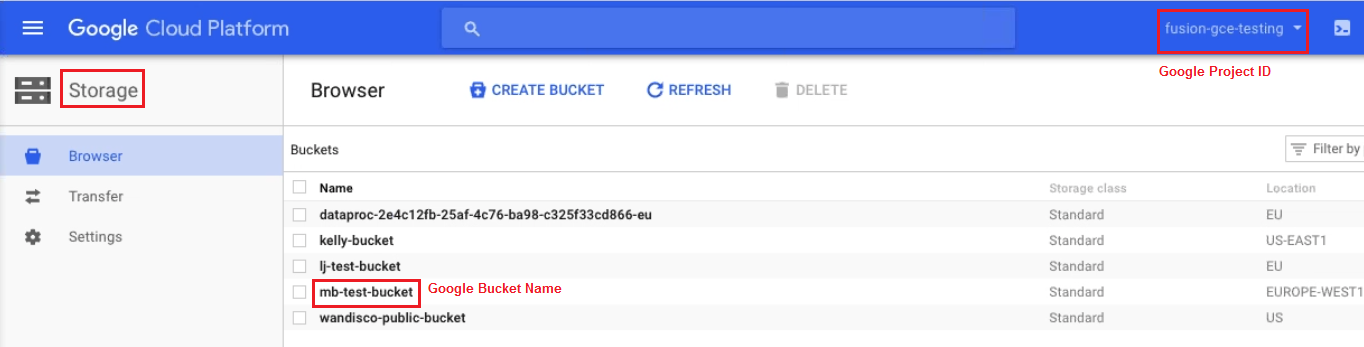
Google Compute - Get the name of your bucket
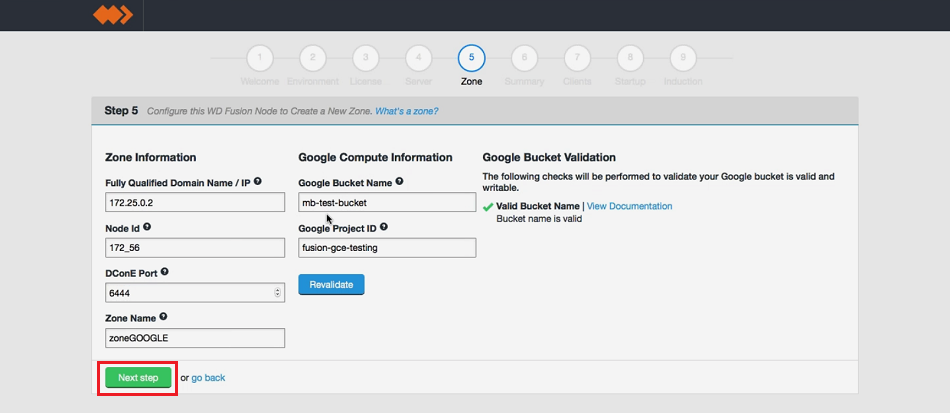
Zone Information
Entry fields for zone properties
- Fully Qualified Domain Name
- Full hostname for the server.
- Node ID
- A unique identifier that will be used by WD Fusion UI to identify the server.
- DConE Port
- TCP port used by WD Fusion for replicated traffic.
- Zone Name
- Name used to identify the zone in which the server operates.
Google Compute Information
Entry fields for Google's platform information.
- Google Bucket Name
- The name of the Google storage bucket that will be replicated.
- Google Project ID
- The Google Project associated with the deployment.
The following validation is completed against the settings:
- the provided bucket matches with an actual bucket on the platform.
- the provided bucket can be written to by WD Fusion.
- the bucket can be read by WD Fusion.
- Review the summary. Click Next Step to continue.
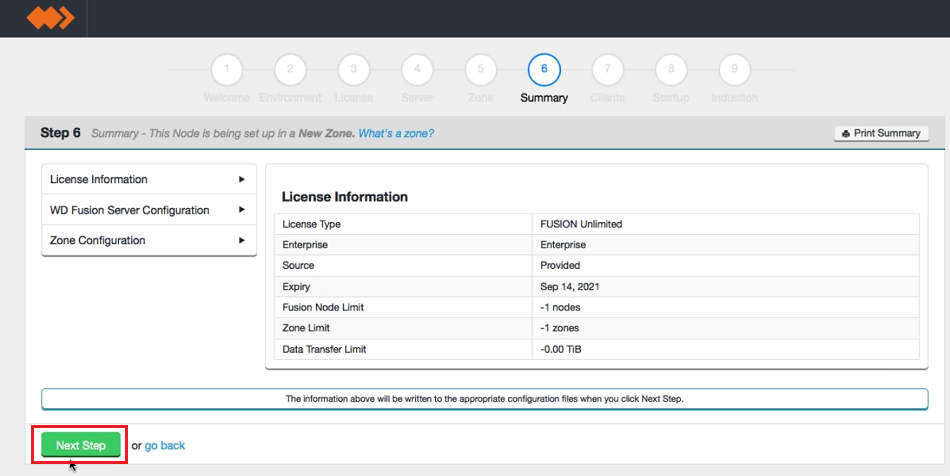
Google Compute - WD Fusion Installation 01
- The next step of the installer can be ignored as it handles the installation of the Fusion client which are not required for a Google cloud deployment. Click Next step.
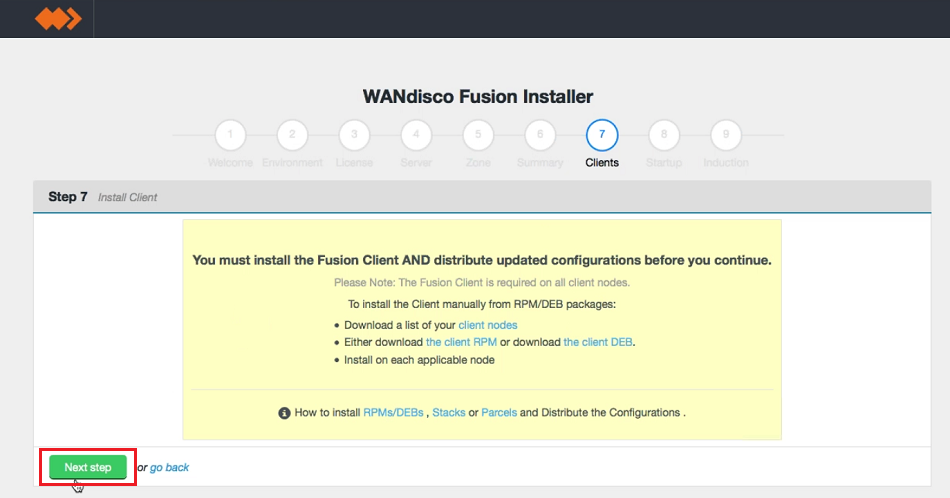
Google Compute - WD Fusion Installation 01
- It's now time to return to start up WDFusion UI for the first time. Click Start WD Fusion.
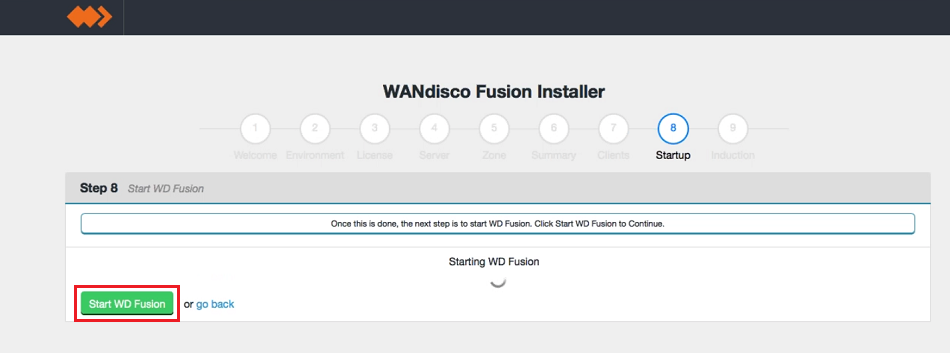
Google Compute - WD Fusion Installation 01
- Once started we now complete the final step of installer's configuration, Induction.
For this first node you will miss this step out, click Skip Induction.For all the following node installations you will provide the FQDN or IP address and port of this first node. (In fact, you can complete induction by referring to any node that has itself completed induction.)
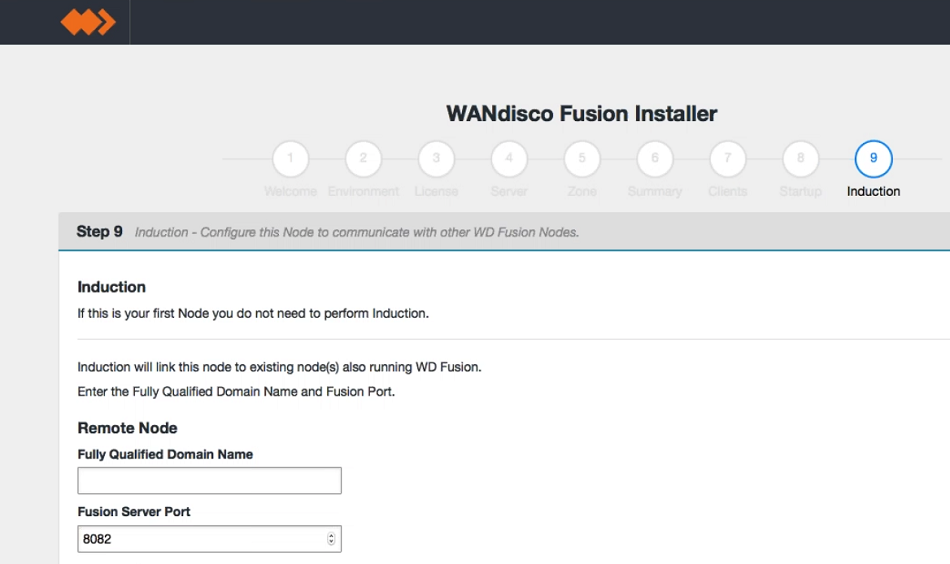
Google Compute - WD Fusion Installation 01
- Click Complete Induction.
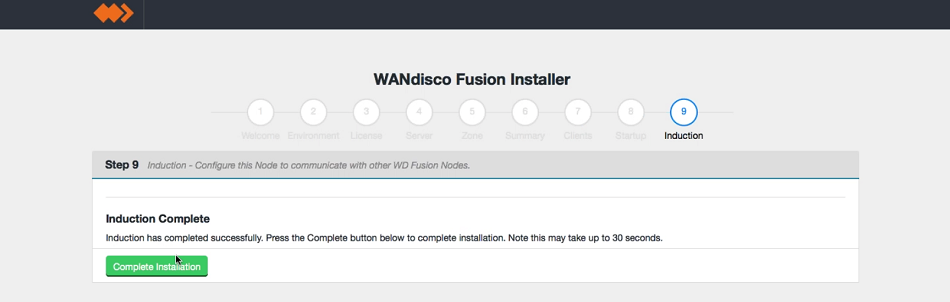
Google Compute - WD Fusion Installation 01
- You will now see the admin UI's Dashboard. You can immediately see that the induction was successful as both zones will appear in the dashboa rds
Google Compute - WD Fusion Installation 01
Demonstration
Setting up data replication
It's now time to demonstrate data replication between the on-premises cluster and the Google bucket storage. First we need to perform a synchronization to ensure that the data stored in both zones is in exactly the same state.
Synchronization
You can synchronize data in both directions:
- Synchronize from on-premises to Google's zone
- Login to the on-premises WD Fusion UI.
- Synchronize from Google Cloud to the on-premises zone
- Login to the WD Fusion UI in AWS.
- Synchronize in both directions (because the data already exists in locations)
- Login to either Fusion UI.
The remaining guide covers the replication from on-premises to Google Cloud, although the procedure for synchronizing in the opposite direction is effectively the same.
- Login to the on-premises WD Fusion UI and click on the Replicated Folders tab.
Google Cloud - Fusion installation figure 09.
- Click on the Create button to set up a folder on the local system.
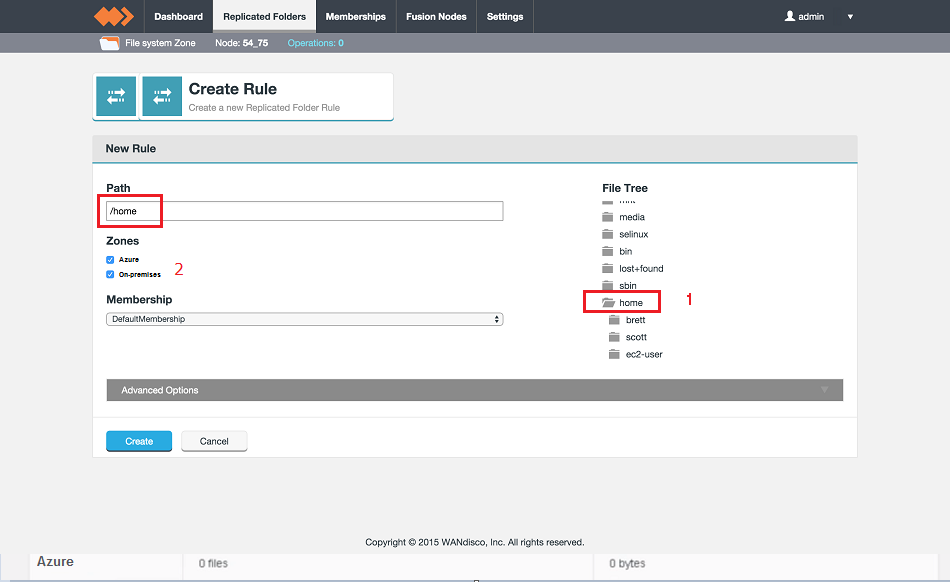
Google Cloud - Fusion installation figure 10.
Navigate the HDFS File Tree (1), on the right-hand side of the New Rule panel to select your target folder, created in the previous step. The selected folder will appear in the Path entry field. You can, instead, type or copy in the full path to the folder in the Path directory.
Next, select both zones from the Zones list (2). You can leave the default membership in place. This will replicate data between the two zones.
Click Create to continue.
- When you first create the folder you may notice status messages for the folder indicating that the system is preparing the folder for replication. Wait until all pending messages are cleared before moving to the next step.
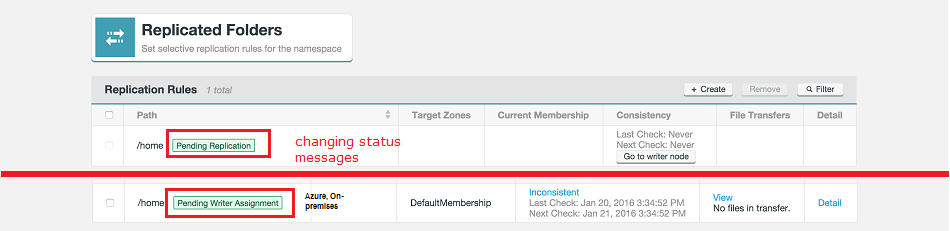
Google Cloud - Fusion installation figure 11.
- Now that the folder is set up it is likely that the file replicas between both zones will be in an inconsistent state, in that you will have files on the local (on-premises) zone that do not yet exist in the WASB store. Click on the Inconsistent link in the Fusion UI to address these.
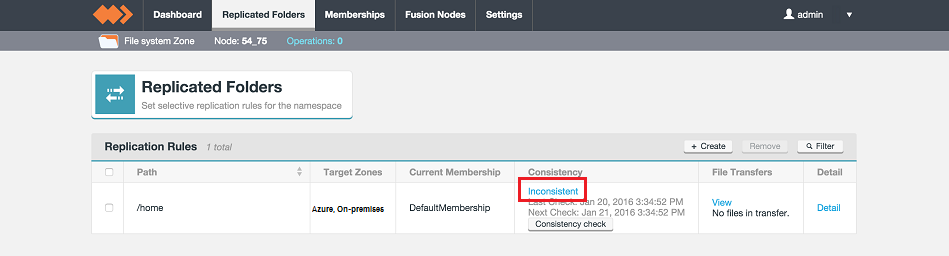
Google Cloud - Fusion installation figure 12.
The consistency report will show you the number of inconsistencies that need correction. We will use bulk resolve to do the first replication.
See the Appendix for more information on improving performance of your first synch and resolving individual inconsistencies if you have a small number of files that might conflict between zones - Running initial repairs in parallel
- Click on the dropdown selector entitled Bulk resolve inconsistencies to display the options that determine synch direction. Choose the zone that will be used for the source files. Tick the check box Preserve extraneous file so that files are not deleted if they don't exist in the source zone. The system will begin the file transfer process.
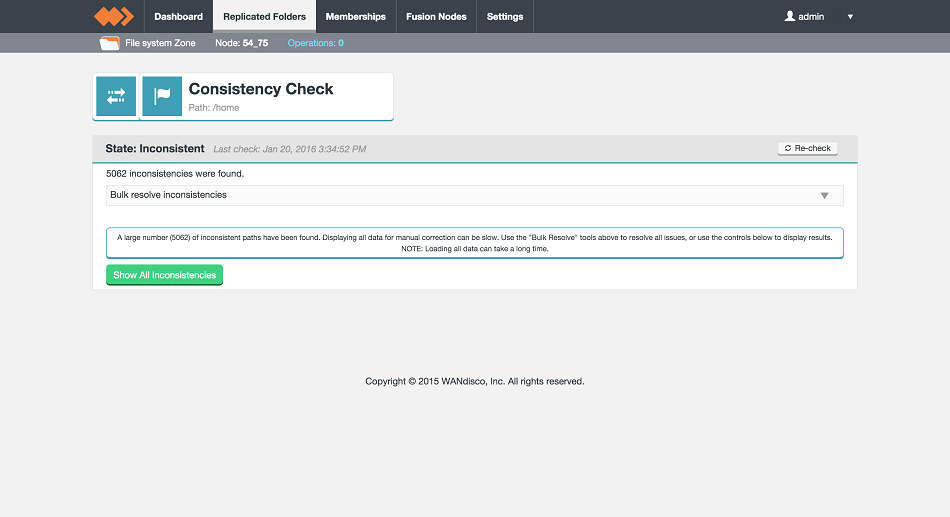
Google Cloud - Fusion installation figure 13.
- We will now verify the file transfers. Login to the WD Fusion UI on the HDI instance. Click on the Replicated Folders tab. In the File Transfers column, click the View link.
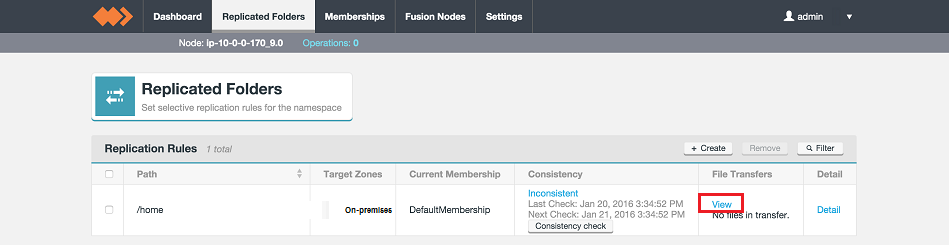
Google Cloud - Fusion installation figure 14.
By checking off the boxes for each status type, you can report on files that are:
- In progress
- Incomplete
- Complete
No transfers in progress?
You may not see files in progress if they are very small, as they tend to clear before the UI polls for in-flight transfers.
- Congratulations! You have successfully installed, configured, replicated and monitored data transfer with WANdisco Fusion.
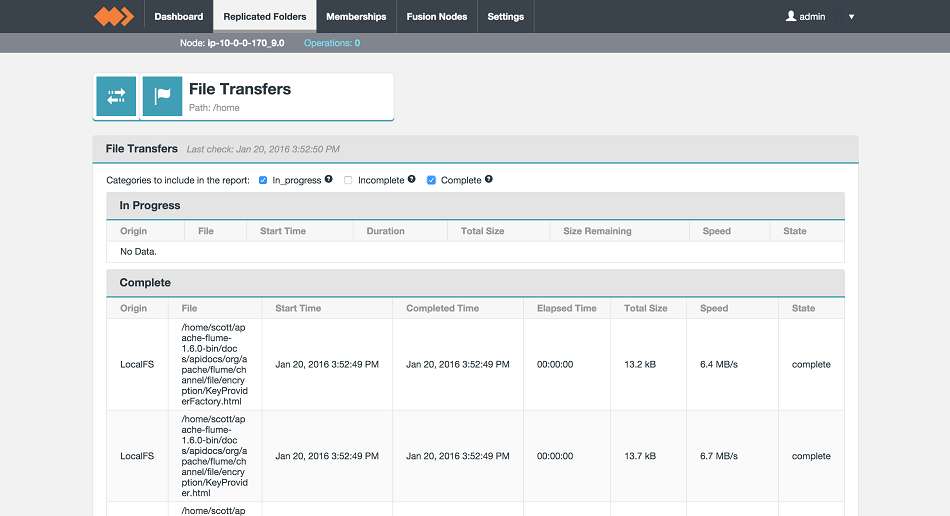
Google Cloud - Fusion installation figure 15.
|