APPENDIX
1. Beginner's Guide to SVN
1.1 So, what's SVN?
SVN is a version control system, a software toolset that helps people to manage changes that are made to collections of shared files. Even when we work alone, most of us will make use of some form of version control, although often crude and inconsistent - such as when we use an application's SAVE AS and cook up a new file name to distinguish the new version from the old. Without version control systems, collaboration (especially in software development) quickly devolves into a horrible mess as different contributors make change to the same files, overwriting or just mangling each others work.
VCS not SCM
There's a specialist form of version control system (called a Configuration Management system) designed specifically for handling software development. Although SVN is most often used for software development it remains a mainstream version control system that is ready to handle files and documents of pretty much any type, and is occasionally put to novel use, such as managing backups, shared todo lists and even in the writing of collaborative fiction.
Version Control Gives You:
- Backup and restore
All changes are recorded and available for retrieval. If you make a mess when changing a file you can get back to the unspoilt version of the file with minimal time and effort. - Synchronization
When you work from a SVN repository, you are always working with the latest version. - Logging changes
Changes made through SVN can be documented with messaging that help someone to understand why changes were made. - Playing in the sandbox
SVN's ability to guard against damaging changes lets you try big risky changes, safe in the knowledge that should you cause a mess, it's easy to go back to the good old stable trunk. - Branching and merging
Development need not take a linear path. With SVN it's possible to manage multiple version of files at the same time.
SVN Gives You:
SVN was originally written by a group of CVS (Concurrent Versioning System) users who were frustrated by CVS's drawbacks. They designed SVN to build on CVS's stengths, while avoiding its limitations. So when people talk about SVN's key features, they are usually talking about the things it does that CVS can't do.
-
Changes to repositories are true atomic operations
Don't worry, there's no radioactivity, that's atomic in the original Greek meaning, as in 'indivisible'. When a change is committed to a SVN repository it is either fully completed or not done at all. This transactional approach to changes is important for maintaining consistency and protecting against corruption. -
Files can't hide from SVN.
You can rename them, move them or even remove them and SVN will still track their history. - It's the size of the change in the file, not the size of the file in the change
It's a key property of the SVN repository model that the cost of an operation is proportional to the amount of change, not the size of the file that is changing. -
Branching and tagging are cheap operations
Branches and tags are both handled using a "copy" operation. A copy takes up a small, fixed amount of space. Any copy is effectively a tag. Committing to a copy automatically makes it a branch. -
Efficient handling of binary files
SVN handles binary using a diffing algorithm. So just like with text files, it can store successive revisions of a binary file without having to store a full copy of the file for each revision. -
SVN supports and versions symbolic links
A versioned symbolic link appears as a true symbolic link. On platforms that that don't support them (pre-Vista Windows) they behave like normal files, but SVN treats the link target as editable.
1.2 How SVN works
SVN uses an approach to versioning called Copy-Modify-Merge which has some big advantages over earlier systems that usually locked files when they were edited to ensure that two people couldn't change a file at the same time. With Copy-Modify-Merge any number of people can make a change to a file at the same time without problem. Each person takes a copy of the file from the repository, this is called a Working Copy and is a snapshot of the file from the latest revision. Changes are always made to this working copy, and when the editor is ready to share the changes, the file is committed back to the repository, where it is given a new revision number.
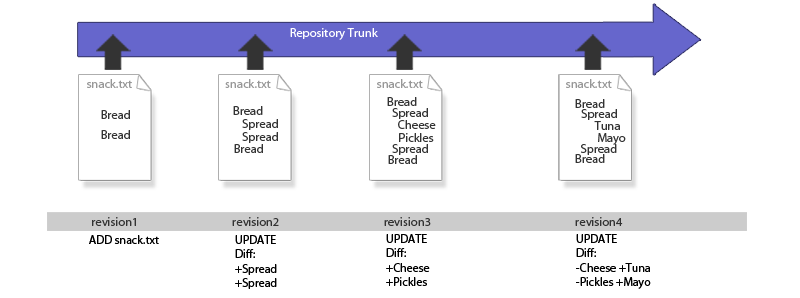
A file is added to the repository and undergoes a series of changes.
Each time the file is changed and committed to the repository it generates a new snapshot of the file. However, this snapshot is not a full copy of the file, instead it is a diff, which only contains a description of what has changed in the file. The above illustration shows how the changing state of snack.txt is recorded as series of additions and subtractions. No matter what changes are made, or when they are made, it will be possible to recreate any revision by applying the appropriate diffs.
Revision numbers are global, not file specific
The above illustration may give the impression that the revision number is specific to the file, as in snack.txt. In SVN this is not the case as the revision number reflects any changes that are made within the entire file system. So it's not really revision 5 of snack.txt, more precisely it is the version of snack.txt that appears in revision 5 of the repository, even if it is the only change that was made in revision 5.
Conflicting changes
So, what does happen when two people make a change to the same file? How does SVN handle conflicting changes? We'll run through an example situation, illustrated below.
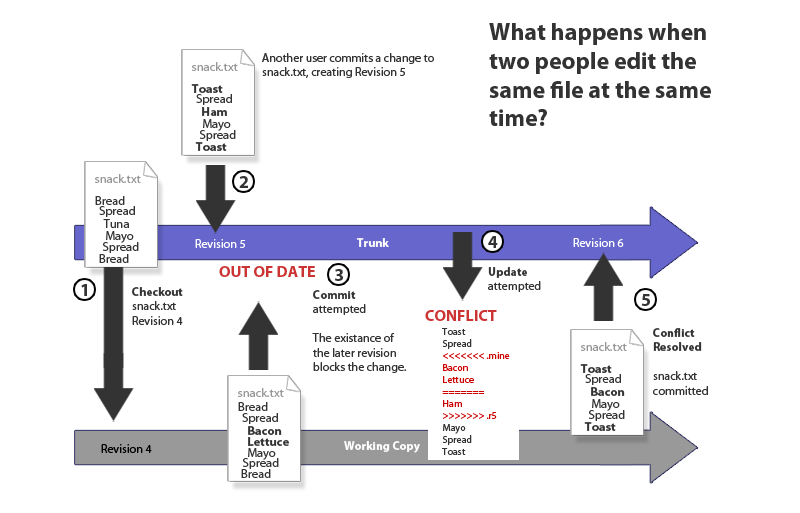
Using SVN means your food fights leave an audit trail...
- 1. We checkout a file, snack.txt from the repository, the latest version is Revision 4. The file contains a list of sandwich ingredients. We edit the working copy of the file with our own sandwich preferences.
- 2. Our colleague, Debs, is already working on snack.txt and commits changes that turn the sandwich into a toastie in revision 5.
- 3. Having completed our edit of the file, we try to commit our changes, but the commit is rejected because SVN identified that our revision is out of date, and if our changes are committed, the changes that Debs made in revision 5 will be overwritten.
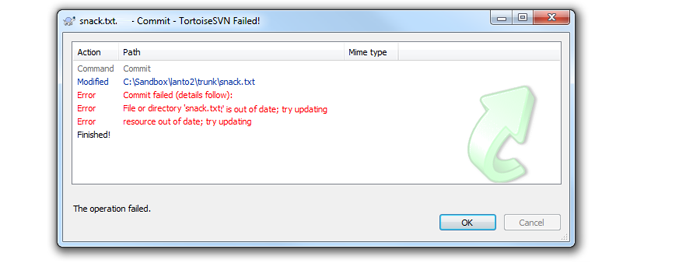
What an out of date error looks like on the Tortoise SVN client (on Windows).
- 4. We attempt an update, this downloads revision 5 of snack.txt and attempts to merge it with our working copy. If the changes between the two versions are in different places within the file there's a good chance that the update will successfully merge the version of the file with revision 5. Unfortunately, in this case the changes can't be merged because the changes happen in the same place. Fear not! We're using Tortoise, the Windows SVN client which provides some useful tools for dealing with the conflict.
Tip
When SVN detects a conflict it creates 3 temporary files:
file.mine (your current working copy)
file.rOldRev (the file at the revision before your changes were made)
file.rNewRev (the file as it is in the latest revision in the repository)
SVN also annotates the original file to show the conflicts within the file (illustrated in the image below).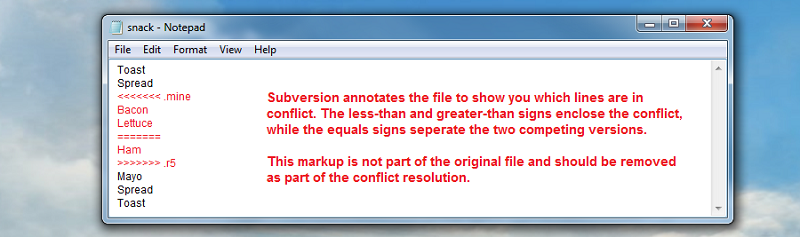
How a conflicted file is tagged to aid editing.
- 5. The conflicted file can now be edited so that both sets of changes are included, or whatever solution is best. Either way, SVN helped stop the loss of work, breaking of files and potential fisticuffs at dawn. In this case, snack.txt is kept as a toastie but is given a mutually agreeable filling.
Tip
After a conflicted file has been fixed, you tell SVN that the conflict has been resolved. SVN will then delete the three temp files and allow the file to be updated or committed.
Conflicts rarely occur if you remember to do an update of your local copy before making any changes.
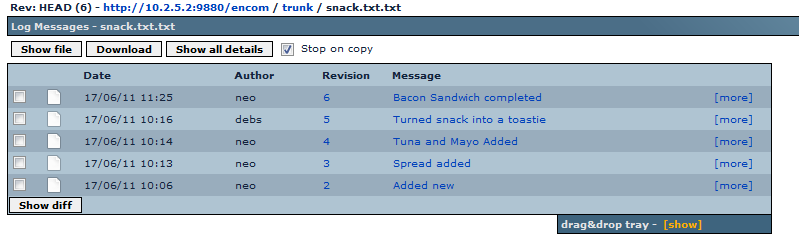
The log view of snack.txt showing the changes over.
1.3 Directory structure
SVN doesn't force you to organize your files in any particular way, although there is a best practise for how to keep SVN repository files. This isn't essential, but as the term 'best practise' suggests, everyone agrees this is a good way to work - especially those who started out by ignoring it and ended up in a mess.

A repository created with the recommended directory structure.
.svn
Prior to SVN 1.7, every directory in a working copy contains a administrative directory called .svn. The files in each administrative directory help SVN recognize which files contain unpublished changes, and which files are out of date with respect to others' work. There's never any good reason for entering the directory and making any manual changes - just leave it alone.
SVN 1.7 contains a rewritten Working Copy Library (called WC:NG). This does away with seperate .svn directories, using instead a single .svn directory located in the repository's main directory.
Alert
Don't delete or change anything in the .svn directory! SVN depends on it to manage your working copy. If you accidentally remove the .svn subdirectory, the easiest way to fix the problem is to remove the entire directory (a normal system deletion, not svn delete), then do an svn update from a parent directory. The SVN client will pull in a fresh copy of the directory you've deleted, along with a new .svn folder.
Trunk
The trunk directory is for current development code. The name is a reference to a growing trunk of a tree, not a place to store your spare tyres. This is where your current release code should be stored. It's best not to muddy the Trunk directory with revisions or release names.
http://10.2.5.2:9880/encom/trunk
Branches
Growing off the trunk are your branches. Branches, like the branches of a tree are "offshoots" of the trunk. The idea is to use branches to work on significant changes, variations of code, without causing disruption to the current release code.
Bug fixing on a branch.
A major bug might be fixed on a branch created for this purpose. This allows for bug fixing changes to be worked on without the potential for disrupting other work going on in the trunk/development branches.
"Toe in the water" branches
It's common to use a branch as a code "sandbox" when you want to try a new technology out. If everything gets broken, you can walk away, with no risk to the working code, but if the experiment works out, it can be easily merged back into the trunk.
http://10.2.5.2:9880/encom/branches/R1.02 http://10.2.5.2:9880/encom/branches/soapflax
Tags
Finally there are tags. Tags work like branches, but are not meant to be developed. Instead, they are code milestones, giving you a snapshot of the code at specific points in its history.
http://10.2.5.2:9880/encom/tags/version1.03
Tagging Bugfix / development branches
When you create a code or bug fix branch it's useful to create a tag of the code before the changes are made (called the "PRE" tag) and a tag after the bugfix or code change has been made (called the "POST" tag).
http://10.2.5.2:9880/encom/tags/PRE_authchange_bug9343 http://10.2.5.2:9880/encom/tags/POST_authchange_bug9343
A Typical SVN project
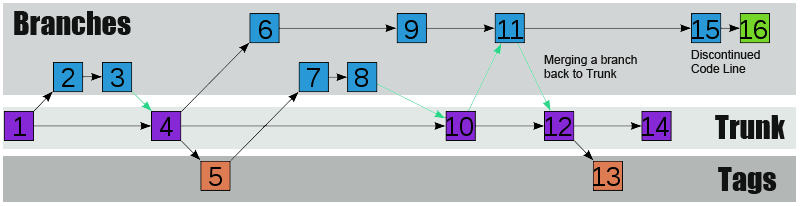
An illustration of how a SVN Repository evolves using branching, tagging and a code trunk.
Alert
SVN itself makes no distinction between tags and branches. It won't stop you from committing changes to tags or fixing major bugs on the trunk, it's important that you are aware of this so you can guard against mistakes. A benefit of using a SVN client such as TortoiseSVN is that they add a lot of useful functionality that helps you guard against errors.
2. Setting up SSL Key pair
SVN MultiSite Plus supports the use of Secure Socket Layer encrytion (SSL) for securing network traffic. Currently you need to run through the setup during the initial installation. If you plan to use SSL you need to run through the following steps before starting the SVN MultiSite Plus installation.
Using stronger and faster encryption
Java's default SSL implementation is intentionally weak so as to avoid the import regulations associated with stronger forms of encryption. However stronger algorithms are available to install, placing the legal responsibility for compliance with local regulation on the user.
See Oracle's page on the Import limits of Cryptographic Algorithms.
If you need stronger algorithms, I.E., AES which supports 256-bit keys, then you can download JCE Unlimited Strength Jurisdiction Policy Files that can be installed with your JDK/JRE.
See Java Cryptography Extension (JCE) Unlimited Strength Jurisdiction Policy Files 7
- 1. Create a new directory in which to store your key files, this directory can be placed anywhere, although in this example we'll store them within the svn-replicator file structure: open a terminal and navigate to
<INSTALL_DIR>/svn-replicator/config. - 2. From within the
/configfolder make a new directory called ssl.
-rw-rw-r-- 1 wandisco wandisco 5 Dec 5 13:53 setup.pid [User@Fed11-2 config]$ mkdir ssl
- 3. Go into the new directory.
cd ssl
- 4. Copy your private key into the directory. If you don't already have keys set up you can use JAVA's keygen utility, using the command:
keytool -genkey -keyalg RSA -keystore wandisco.ks -alias server -validity 3650 -storepass <YOUR PASSWORD>
Knowledgebase
Read more about the Java keystore generation tool in the KB article - Using Java Keytool to manage keystores- -genkey
- Switch for generating a key pair (a public key and associated private key). Wraps the public key into an X.509 v1 self-signed certificate, which is stored as a single-element certificate chain. This certificate chain and the private key are stored in a new keystore entry identified by alias.
- -keyalg RSA
- The key algorithm, in this case RSA is specified.
- wandisco.ks
- This is file name for your private key file that will be stored in the current directory.
- - alias server
- Assigns an alias "server" to the key pair. Aliases are case-insensitive.
- -validity 3650
- Validates the keypair for 3650 days (10 years). The default would be 3 months
- - storepass <YOUR PASSWORD>
- This provides the keystore with a password.
If no password is specified on the command, you'll be prompted for it. Your entry will not be masked so you (and anyone else looking at your screen) will be able to see what you type.
Most commands that interrogate or change the keystore will need to use the store password. Some commands may need to use the private key password. Passwords can be specified on the command line (using the
-storepassand-keypassoptions).
However, a password should not be specified on a command line or in a script unless it is for testing purposes, or you are on a secure system.
The utility will prompt you for the following information
What is your first and last name? [Unknown]: What is the name of your organizational unit? [Unknown]: What is the name of your organization? [Unknown]: What is the name of your City or Locality? [Unknown]: What is the name of your State or Province? [Unknown]: What is the two-letter country code for this unit? [Unknown]: Is CN=Unknown, OU=Unknown, O=Unknown, L=Unknown, ST=Unknown, C=Unknown correct? [no]: yes
Enter key password for <mykey> (RETURN if same as keystore password): - 5. With the keystore now in place, the setup will pick the file up if you provide the relevant details during the installation process.
Changes in these value require a restart. Any invalid value will restart the replicator and no DConE traffic will flow.
SSLv3 is support (though not enforced). If your browser setting has SSLv3 disabled, you will get a handshake error message. If it has both SSLv3 and TLS enabled, then, depending on the browser, it will try to switch from TLS to SSLv3 during the handshake. If you receive a handshake error message in your browser, make sure that TLS is disabled and only SSLv3 is enabled. All current browsers support SSLv3.
3.1 Setting the server key
In the keystore, the server certificate is associate with a key. By default, we look for a key named server to validate the certificate. If you use a key for the server with a different name, enter this in the SSL settings.
3.2 SSL Troubleshooting
A complete debug of the SSL logging will be required to diagnose the problems. To capture the debugging, run the java process with:
'-Djavax.net.debug=all' flag.
To enable the logging of SSL implemented layer, turn the logging to FINEST for 'com.wandisco.platform.net' package.
4. Hook Scripts
Hooks are script that are triggered by specific repository events, such as the creation of a new revision or the modification of an unversioned property. As such they're very useful for SVN administrators who want to have more control over their repository environment.
For example, with the use of a Post-commit hook it is possible to send an email to announce that a new revision has been created.
Tip
Generally we advise that hooks should be set up the same on all sites, although this is not a requirement for replication and there are some situations where you may wish to be selective about where hooks fire.
Hooks need to be executable by the appropriate system account
Any hook that you intend to fire on a particular node will need to be suitably permissioned to execute. e.g.
chmod+x post-commit
Types of hooks
| Hook | How to Integrate with WANdisco |
| start-commit | Standard Subversion implementation. |
| pre-commit | This becomes the pre-replication hook. |
| post-commit | Standard Subversion implementation. See the following section called Replicated Post-Hooks for when you need post-commit hooks to fire on multiple nodes, rather than just on the initiating node. |
| pre-revprop-change | Standard Subversion implementation. |
| post-revprop-change | Standard Subversion implementation. |
| post-lock | Standard Subversion implementation. |
| Pre-unlock | Standard Subversion implementation. |
| Post-unlock | Standard Subversion implementation. |
Running Hooks with SVN MultiSite Plus
Deploying SVN MultiSite Plus should have minimal impact on how hook scripts run on a deployment.
Pre-commit hooks
Wandisco's modified version of the FSFS libraries will intercept commits after any pre-commit hooks have run, so pre-commit hooks run on the initiating node, at the Apache/SVNserve level, rather than from within the replicator. SVN MultiSite Plus never needs to deal with a failed pre-commit hook because the error is captured before the it can touch WANdisco's FSFSWD library.
Post-commit Hooks
The replicator completes a commit on the originating node by invoking a Java Native Inferface(JNI) function. A successful commit causes the post-commit to run on the node. Again, repository changes occur but the hooks are not run on the other nodes, only on the node on which the repository change was originated.
Replicated Post-commit Hooks
There are lots of scenarios where it is essential that a post-commit hook runs on other nodes, not just the node on which it is initially triggered, for example - running continous build servers that are triggered by post-commit hooks.
In order to support these situations there's a method for ensuring that Post-commit Hooks are triggered on some or all other nodes.
repl-post-commit
Hooks that start with the prefix "repl-" are recognised and picked up by WANdisco's replicator. When run locally, the replicator will trigger them on all other nodes in which they are placed. You can exclude nodes by not including a "repl-" version of the hook.
Hook scripts that are replicated are run in the following temp directory which will be created on each applicable node:
/opt/wandisco/svn-multisite-plus/replicator/hooks/tmp
The usual requirements for running hook scripts still apply, the hook must be executable for the system user.
Limitations
Replication of post-commit hooks is straight forward, however other post-hooks, such as post-revprop-change may carry arguments, such as "username" to which replicated hook scripts won't have access (the replicator is working below the authn layer). In situations where "USER" is needed, we implant the value "UNKNOWN" in order to ensure that the hook doesn't error.