4. Technical Guide
4.1 Benefits of running with Git MultiSite
This guide runs through everything you need to know to get Git MultiSite deployed. First we'll cover all the things that you need to have in place before you install. We'll then cover a standard installation and setup. Finally we'll look at some possible problems you might experience with some troubleshooting tips.
LAN-speed Performance Dramatically Shortens Development Cycles and Reduces Cost
- WANdisco’s patented replication technology, Distributed Coordination Engine (DConE), fulfills Git’s distributed promise for developers at every location.
- Every developer pushes to a local master repository for maximum performance.
- Peer-to-peer architecture with no single point of failure eliminates the performance and scalability bottleneck of a central master repository server.
- Enables global collaboration – no geographic limitations.
- New nodes can be added on the fly to support new locations or increased load.
- Immediate active-active replication eliminates WAN latency and ensures repositories are always in sync, enabling fast conflict resolution.
- Developers at remote sites no longer hold back commits until the end of the day/week as they may have in the past due to poor network performance.
- Update conflicts and other problems are found and fixed as they occur, so less time is spent on QA and rework.
Zero Downtime and Zero Data Loss
- WANdisco's unique replication technology turns distributed repositories into replicated peers, providing continuous hot-backup by default.
- Every Git MultiSite node is fully replicated and writable, providing an out-of-the-box High Availability / Disaster Recovery (HA/DR) solution.
- Recovery is automatic after a server outage (planned or unplanned), eliminating lost productivity during maintenance or server crashes. In addition, the risk of human error from manual recovery procedures is completely eliminated.
Enables Continuous Availability for Global Software Development
- WANdisco's unique replication technology turns Git repositories distributed over a WAN into replicated peers, providing continuous hot-backup by default, as part of normal operation.
- Hot deploy features make it possible to add new Git repositories to a multi-site implementation, or take existing servers offline for maintenance without interrupting usage for other sites.
- When new repositories are added, or existing servers are brought back online they automatically sync with others.
Easy to Administer
- All sites can be administered from a single location.
- New replicated and fully readable and writeable Git nodes can be quickly set up with no custom coding.
- Built-in self-healing capabilities make disaster recovery automatic without any administrator involvement.
No Retraining Required
- Git functionality does not change with Git MultiSite – no proprietary back-ends.
- No retraining required – developers and administrators continue using the tools they're familiar with.
4.2 How Git MultiSite Works
Git MultiSite provides a toolset for replicating Git repository data in a manner that can maximise performance and efficiency whilst minimising network and hardware resources requirements. The following examples provide you with a starting point for deciding on the best means to enable replication across your development sites.
Replication Model
Per-Repository Replication
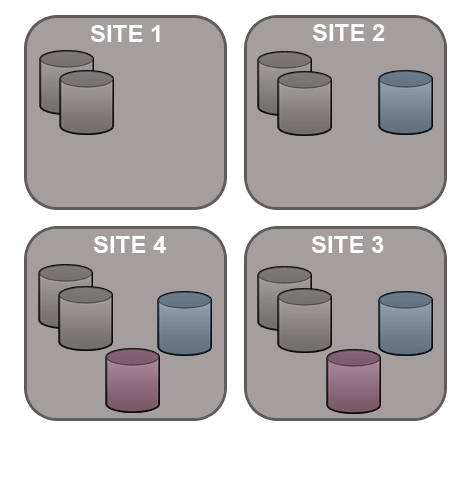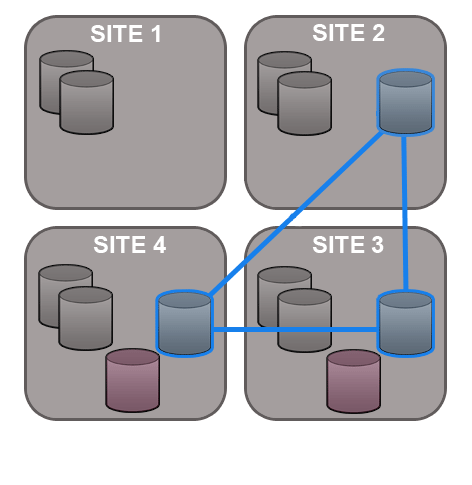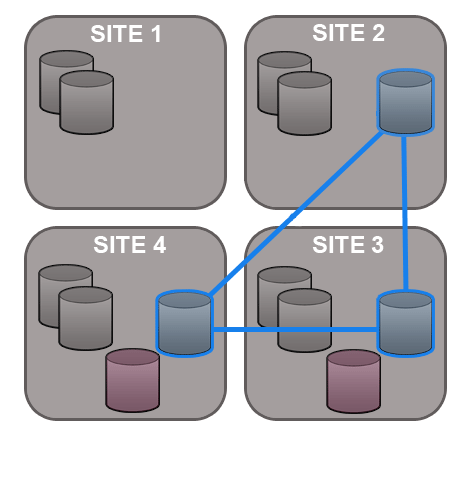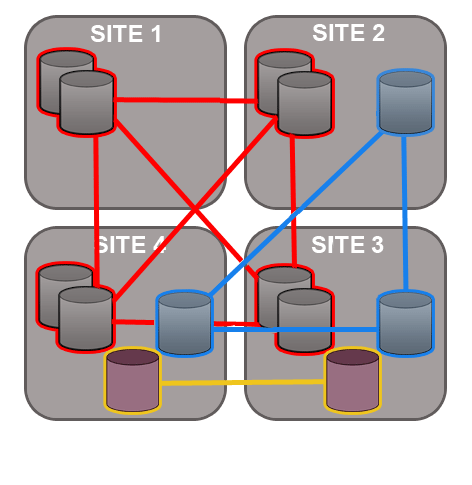
Git MultiSite is able to replicate on a per-repository basis. This way each site can host different sets of repositories and replicate repositories this means that you can have different repositories replicate as part of different replication groups.
Dynamic Membership Evolution
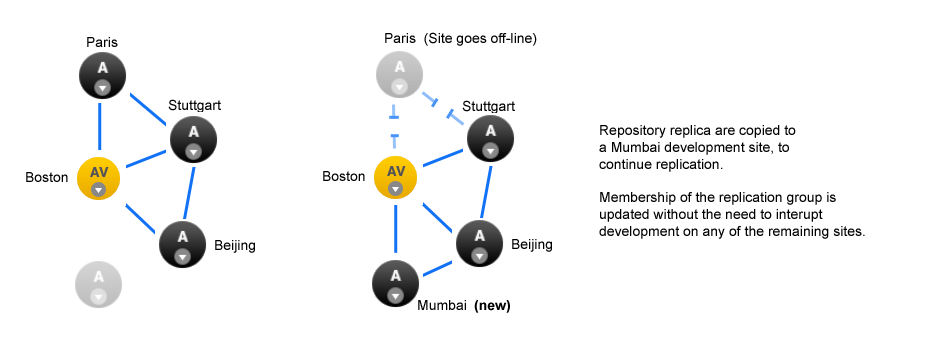
No need for a synchronized stop - Git MultiSite allows replication groups to change their membership on-the-fly.
A repository can only replicate to a single replication group at any one time, although it is possible to move between replication groups as required - this can now be done on-the-fly, sites can be added or deleted without the need to pause all replication (with a synchronized stop)
Git MultiSite offers a great deal of flexibility in how repository data is replicated. Before you get started it's a good idea to map out which repositories at which locations you want to replicate.
4.3 Creating resilient Replication Groups
Git MultiSite is able to maintain repository replication (and availability) even after the loss of nodes from a replication group. However, there are some configuration rules that are worth considering:
Rule 1: Understand Learners and Acceptors
The unique Active-Active replication technology used by MultiSite is an evolution of the Paxos algorithm, as such we use some Paxos concepts which are useful to understand:
Learners:
Learners are the nodes that are involved in the actual replication of repository data. When changes are made on the local repository copy these nodes raise a proposal for the changes to be made on all the other copies.
Learner Nodes are required for the actual storage and replication of repository data. You need a learner node at any location where users are working or where you wish to store hot-backups of repositories
Types of Nodes that are learners: Active, Passive
Acceptors:
All changes being made on each repository in exactly the same order is a crucial requirement for maintaining synchronization. Acceptors are nodes that take part in the vote for the order in which proposals are played out.
Acceptor Nodes are required for keeping replication going. You need enough Acceptors to ensure that agreement over proposal ordering can always be met, even accounting for possible node loss. For configurations where there are a an even number of Acceptors it is possible that voting could become tied. For this reason it is possible to make a voter node into a tie-breaker which has slightly more voting power so that it can outvote another single voter node.
Types of nodes that are Acceptors: Voter Only
Nodes that are both an Acceptor and Learner: Active Voter, Passive Voter
Rule 2: Replication groups should have a minimum membership of three learner nodes
Two-node replication groups are not fault tolerant, you should strive to replicate according to the following guideline:
The number of voters required to survive population loss of N voter nodes = 2N+1 where N is the number of failed voter nodes.
So in order to survive the loss of a single voter node you need to have a minimum of 2x1+1= 3 voter nodes
In order to keep on replicating after losing a second voter node you need 5 voter nodes.
Rule 3: Learner Population - resilience vs rightness
During the installation of each of your nodes you are asked to provide a Content Node Count number, this is the number of other learner nodes in the replication group that need to receive the content for a proposal before the proposal can be submitted for agreement.
Setting this number to 1 ensures that replication won't halt if some nodes are behind and have not received replicated content yet. This strategy reduces the chance that a temporary outage or heavily loaded node will stop replication, however, it also increases the risk that repositories will go out of sync (requiring admin-intervention) in the event of an outage.
Rule 4: 2 nodes per site provides resilience and performance benefits
Running with two nodes per site provides two important advantages.
Firstly it provides every site with a local hot-backup of the repository data.
Enables a site to load-balance repository access between the nodes which can improve performance during times of heavy usage.
Providing the nodes are Voters, it increases the voter population and improves resilience for replication.
4.4 Available Node Types
Each replication group consists of a number of sites and a selection of repositories that will be replicated.
There are now some different types of nodes:
 Active Node
Active Node- An Active Node has users who are actively committing to Git repositories, which results in the generation of proposals that are replicated to the other sites. However, it plays no part in getting agreement on the ordering of transactions.
 Active Voter
Active Voter- An Active Voter is an Active Node that also votes on the order that transactions are played out. In a replication group with a single Active Voter, it alone decides on ordering. If there's an even number of Active Voters, theres a problem because there's the possibility that the vote will hang with no overall winner.
- Passive
- A node on which repositories receive updates from other sites, but doesn't permit any changes to its replicas from clients - effectively making its repositories read-only. Passive nodes are ideal for use in providing hot-backup.
- Passive Voter
-
A passive node that also takes part in the vote for transaction ordering agreement.
- Voter
-
A Voter-only node doesn't store repository data, it's only purpose is to accept transactions and cast of vote on transaction ordering. Voter-only nodes add resilience to a replication group as they increase the likelyhood that enough nodes are available to make agreement on transaction ordering
Use for:- Dedicated servers for Continuous Integration servers
- Sharing code with partners or sites that won't be allowed to commit changes back
- In addition, these nodes could help with HA as they add another voter to a site.
 Tiebreaker
Tiebreaker- The Tie-breaker site is an active node that only votes when the votes are evenly split, causing a deadlock. The tie-breaker therefore gets the casting vote.
 Helper
Helper- When adding a new site to an existing replication group you will select an existing site from which you will manually copy or rsync the applicable repository data. This existing site enters the 'helper' mode in which the same relevant repositories will be read-only until they have been synced with the new site. BY relevant we mean that they are replicated in the replication group in which the new site is being added.
 New
New- When a site is added to an existing replication group it enters an 'on-hold' state until repository data has been copied across. Until the process of adding the repository data is complete, New sites will be read-only. Should you leave the Add a Site process before it has completed you will need to manually remove the read-only state from the repository
Acceptors, Proposers and Learners?
The table below shows which node roles are acceptors, proposers or learners.
| Node Type | Acceptor | Proposer | Learner |
|---|---|---|---|
| Active (A) | N | Y | Y |
| Active Voter (AV) | Y | Y | Y |
| Passive (P) | N | N | Y |
| Passive Voter (PV) | Y | N | Y |
| Voter Only (V) | Y | N | N |
Key
Learners are either Active or Passive nodes:
Learns proposals from other nodes and takes action accordingly. Updates repositories based on proposal (replication).
Proposers are Active nodes:
To be able to commit to the node the node must be able to make proposals.
Acceptors are Voters:
Accepts proposals from other nodes and whether or not to process or not (ordering/achieve quorum).
4.5 Disk Usage and Replicated Pushes
If a file, or set of files, is repeatedly added and removed in Git, the node that is pushed to will store the changes using deltas, resulting in only minor changes to the repository's size.
If the change is replicated by a push, then it is possible that new blobs will be stored when the file(s) are re-added to the system, meaning the repository size will increase roughly by the size of the files(s) added multiplied by the number of additions.
Garbage collection (either routine automated housekeeping or manual git gc usage) will reduce the amount of disk space used, to roughly that of the node the changes were originally pushed to.
If a repo is cloned, rather than pushed, the usage will also reflect the lower figure.
4.6 Working with non-ASCII character sets
Commands such as git status use a different method of displaying non-ASCII characters.
To see the characters rather than escape codes (such as \266) use the following setting on your git client:
git config core.quotepath falseSee the man git-config page for more details.
4.7 Content Distribution Policy
WANdisco's replication protocol separates replication traffic into two streams, the coordination stream which handles agreement between voter nodes and the content distribution stream through which repository changes are passed to all other nodes (that is "learner" nodes that store repository replicas).
Git MultiSite provides a number of tunable settings that let you apply different policies to content distribution. By default, content distribution is set up to prioritize reliability. You can, instead, set it to prioritize speed of replication. Alternatively you can apply a policy that prioritizes delivery of content to voter nodes. These policies can be applied on a per-site, per-repository and replication group basis providing a fine level of control providing that you take care to set things up properly.
Changing Content Distribution Policy
In order to set the policy, you need to make a manual edit to Git MultiSite's Application properties file:
/opt/wandisco/git-multisite/replicator/properties/application.propertiesChanges require a restart:
Changing the current strategy requires the modification of properties files that the replicator only reads at start-up. As a result any changes to strategy require that the replicator be restarted before the change will be applied.
Editable Content Distribution Properties
content.push.policy=faster
content.min.learners.required=true
content.learners.count=1Above is an example Content Distribution Policy. We'll breakdown what each of the settings does:
content.push.policy
This property sets the priority for Content Distribution. It can have one of three options which set the following behavior. Each option tells MultiSite to use a different calculation for relating replication agreement to the actual delivery of replicated data.
"reliable" Policy:
Replication can continue if content available to a sufficient number of learners ( the value of content.learner.count, not including the node itself)
Reliable is the default setting for the policy. Content must be delivered to a minimum number of nodes, the value of the property (content.min.learners.required, for a proposal to be accepted - which will allow replication to continue.
Reliable because it greatly reduces the risk that a proposal will be accepted when the corresponding content cannot be delivered (due to a LAN outage etc). This policy is less likely to provide good performance because replication is kept on hold until content has been successfully distributed to a greater number of nodes than would be the case under the "faster" policy.
Setting the corresponding "content.learner.count" value
- This value is the number of learners (exluding the originating node) to which content is delivered before a proposal will be raised for agreement.
- If content.min.learners.required is false then the system will automatically lower content.learner.count to ensure that replication can continue om the event of a loss of node(s).
- If the value is higher than the number of available nodes then Git MultiSite is notified of the failure and the value is dropped further, ( based on 'content.min.learners.required').
- If content.min.learners.required is true the then Git MultiSite is notified of a failure to summon enough voters for agreement - content.leaner.count is automatically dropped again (to equal one less than the number of available learners), or if that's no longer possible, a failure is reported.
Setting the corresponding "content.min.learners.required" value
For "reliable" policy that offers the upmost reliability, set this to "true".
true enforces the requirement
When content.min.learners.required is set to "true" Git MultiSite will not lower the content.learner.count in light of insufficient learner nodes being available.
Example:
content.learner.count=5, content.min.learners.required=trueAfter an outage there are now only 4 learner nodes in the replication group - replication will be halted because there aren't enough available learners to validate a content distribution check.
content.learner.count=5, content.min.learners.required=falseAfter an outage there are now only 4 learner nodes in the replication group - replication will not be halted because Git MultiSite will automatically drop the count to ensure that it doesn't exceed the total number of learners in the group.
"acceptors" Policy:
Voting can commence if content is delivered to 50% of voters (acceptors), include self if a voter
Content push policy only deals with delivering content to voters. This policy is ideal if you have a small number of voters. You don't want replication to continue until you have confirmed that at least half the voters have the corresponding payload. This policy supports a "follow-the-sun" approach to replication where the voter status of nodes changes each day to correspond with the locations where most development is being done. This ensures that the sites with the most development activity will get the best commit performance.
Setting the corresponding "content.learner.count" value
For "Acceptors" policy this is ignored.
Setting the corresponding "content.min.learners.required" value
For "Acceptors" policy this is ignored - learners do not factor into the policy, only voters (acceptors).
"faster" Policy:
Replication can continue if content available to x learners (not including self) OR [delivered to half the voters, including self if its a voter] where x = content.learner.count
Setting the policy to 'faster' lowers the requirement for successful content distribution so that replication can continue when fewer nodes (than under the reliable policy) have received the payload for the proposal. 50% of voters (acceptors) must receive the content. It's faster because if there's a slow or intermittent connection somewhere on the WAN, it wouldn't delay agreement/ slow down replication. It is less reliable because it increases the possibility that the ordering of a proposal can be agreed upon, only for the corresponding content to not get delivered. The result would be a break in replication.
Setting the corresponding "content.learner.count" value
- For the 'faster' policy the node in question is always included in the count. In the event that this is not satisfied, a further check is made against acceptors. The check passes if half or more (rounded up) of the available voters took delivery of the content.
Setting the corresponding "content.min.learners.required" value
For Faster, set this to "false".
All the acceptors (voters) must also be learners (carry replica data that can be changed).
If all the acceptors are not learners, we switch to 'reliable' policy with a log message. A node always includes itself in the count - in contrast with the "reliable" policy where a node never includes itself in the count.
Steps for a policy change
Use this procedure to change between the above Content Distribution policies.
- Make a back up and then edit the /opt/wandisco/git-multisite/replicator/properties/application.properties file (Read more about the properties files).
- Change the value of content.min.learners.required, make it "true" for reliability, "false" for speed (default is true).
- Save the file and perform a restart of the node.
Set Policy on a per-state machine basis
When editing the property, add the state machine identity followed by '.content.push.policy'. e.g.
<machine_identity_name>.content.push.policy=fasterThe system assigns policy by looking up the state machine policy followed by 'content.push.policy'. If none are available, 'reliable' is chosen. Conditional switch between 'faster' and 'reliable' remains in effect regardless of the policy.
Example 1 - Faster policy on a 2-node replication group
Two-node Replication Group, NodeA (Active Voter) and NodeB (Active).
content.push.policy=faster
content.min.learners.required=true
content.learners.count=1- A Commit to NodeA (AV) will go through faster and before all content has been received on NodeB (A).
- A commit to the NodeB (A) will not go through until NodeA (AV) has received ALL content.
Example 2 - Acceptors policy on a 4-node replication group
Four nodes split between two sites. On Site 1 we have NodeA and NodeB, both are Active Voters. On site 2 we have NodeC (AV) and NodeD (A).
content.push.policy=acceptors
content.min.learners.required=true
content.learners.count=1- Acceptors policy requires delivery to half the voters (rounded-up). There are three nodes so commits at Site 1 need to reach both local AV nodes in order to go through.
- Commits to NodeC at site 2 will also need to be delivered to one of the nodes at Site 1 in order to go through. This configuration could support a "follow-the-sun" approach if one of the active voters at site 1 could be switched for NodeB at site 2, thus providing developers at site 2 with better performance.
4.8 Replicating Environmental Variables
Administrators are now able to specify a subset of the node's environmental variables for use with standard Git hooks. The selected environmental variables are passed the other replicated nodes via replicated hooks (specifically rp-post-update and rp-post-receive).
The set of environment variables from which you can choose are found in the process context of the post-receive hook on the node where the original push was made to.
The environmental variables are configured as a replicated property, with the key: "gitms.hooks.env". The value is a comma separated list of environment variables that the administrator wishes to capture. This list is case sensitive, and should not contain spaces. You can manually set the configuration per node by adding the correct values in application.properties, but this would only affect that node. To push replicated properties to the replication network, a rest call and a little XML is needed:
curl -u <username:password> --header "Content-Type: application/xml" --data @<xml_file_path> -X PUT http://<ip>:<rest_port>/api/configuration/replicated
For setting most variables you'd instead use the REST API, if you need to make changes to the application.properties file it may be worth checking with WANdisco's support team before making the change.
XML format
<?xml version="1.0" encoding="UTF-8" standalone="yes"?> <configuration> <property> <key>gitms.hooks.env</key> <value>NODE_NAME,GIT_DIR</value> </property> </configuration>
In this example, we've configured the replictor to take the values of NODE_NAME and GIT_DIR from the context of the post-recieve process on the originating node and pass them onto other nodes to use in their rp-post-update and rp-post-receive scripts. Example hook scripts are provided below which can be placed in a repository to verify that the configuration is successful:
/tmp/rp-post-update
Arguments: refs/heads/master ENVIRONMENT VARIABLES: SHELL=/bin/bash TERM=xterm LC_ALL=en_GB.UTF-8 USER=gitms NLSPATH=/usr/dt/lib/nls/msg/%L/%N.cat PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin JAVA=/usr/bin/java PWD=/home/gitms/repo1.git XFILESEARCHPATH=/usr/dt/app-defaults/%L/Dt HOME=/home/gitms SHLVL=5 LOGNAME=gitms _=/bin/env
And after having configured NODE_NAME and GIT_DIR to replicate:
/tmp/rp-post-receive
oldrev: c1a4067286d5fdcd92ed98a6f8a6bbbd94434fc0 newrev: 27e3052234a1a8bd2d91d9860d389fb7aa7a953f refname: refs/heads/master ENV VARIABLES: GIT_DIR=. SHELL=/bin/bash TERM=xterm LC_ALL=en_GB.UTF-8 USER=gitms NLSPATH=/usr/dt/lib/nls/msg/%L/%N.cat PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin JAVA=/usr/bin/java PWD=/home/gitms/repo1.git XFILESEARCHPATH=/usr/dt/app-defaults/%L/Dt HOME=/home/gitms SHLVL=5 LOGNAME=gitms NODE_NAME=Node-2 _=/bin/env
/tmp/rp-post-update
Arguments: refs/heads/master ENVIRONMENT VARIABLES: GIT_DIR=. SHELL=/bin/bash TERM=xterm LC_ALL=en_GB.UTF-8 USER=gitms NLSPATH=/usr/dt/lib/nls/msg/%L/%N.cat PATH=/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin JAVA=/usr/bin/java PWD=/home/gitms/repo1.git XFILESEARCHPATH=/usr/dt/app-defaults/%L/Dt HOME=/home/gitms SHLVL=5 LOGNAME=gitms NODE_NAME=Node-2 _=/bin/env
Copyright © 2010-2013 WANdisco plc.
All Rights Reserved
This product is protected by copyright and distributed under
licenses restricting copying, distribution and decompilation.
Git MultiSite
Last doc build: 10:45 - Wednesday 27th August 2014