1. Welcome
1.1. Product overview
The Fusion Plugin for Live Hive enables WANdisco Fusion to replicate Hive’s metastore, allowing WANdisco Fusion to maintain a replicated instance of Hive’s metadata and, in future, support Hive deployments that are distributed between data centers.
1.2. Documentation guide
This guide contains the following:
- Welcome
-
This chapter introduces this user guide and provides help with how to use it.
- Release Notes
-
Details the latest software release, covering new features, fixes and known issues to be aware of.
- Concepts
-
Explains how Live Hive uses WANdisco’s LiveData platform.
- Installation
-
Covers the steps required to install and set up Live Hive into a WANdisco Fusion deployment.
- Operation
-
The steps required to run, reconfigure and troubleshoot Live Hive.
- Reference
-
Additional Live Hive documentation, including documentation for the available REST API.
1.2.1. Symbols in the documentation
In the guide we highlight types of information using the following call outs:
| The alert symbol highlights important information. |
| The STOP symbol cautions you against doing something. |
| Tips are principles or practices that you’ll benefit from knowing or using. |
| The KB symbol shows where you can find more information, such as in our online Knowledge base. |
1.3. Contact support
See our online Knowledge base which contains updates and more information.
If you need more help raise a case on our support website.
1.4. Give feedback
If you find an error or if you think some information needs improving, raise a case on our support website or email docs@wandisco.com.
2. Release Notes
2.1. Live Hive 4.0.1 Build 1505
2 October 2019
The 4.0.1 release adds support for the Fusion Plugin for Databricks Delta Lake.
For the release notes and information on known issues, please visit the Knowledge base - WANdisco Live Hive Plugin 4.0.1 Build 1505.
2.2. Live Hive 4.0.0 Build 1497
13 August 2019
The Fusion Plugin for Live Hive extends WANdisco Fusion by replicating Apache Hive metadata. With it, WANdisco Fusion maintains a Live Data environment including Hive content, so that applications can access, use, and modify a consistent view of data everywhere, spanning platforms and locations, even at petabyte scale. WANdisco Fusion ensures the availability and accessibility of critical data everywhere.
For the release notes and information on known issues, please visit the Knowledge base - WANdisco Live Hive Plugin 4.0 Build 1497.
3. Concepts
3.1. Product concepts
Familiarity with product and environment concepts will help you understand how to use the Fusion Plugin for Live Hive. Learn the following concepts to become proficient with replication.
- Apache Hive
-
Hive is a data warehousing technology for Apache Hadoop. It is designed to offer an abstraction that supports applications that want to use data residing in a Hadoop cluster in a structured manner, allowing ad-hoc querying, summarization and other data analysis tasks to be performed using high-level constructs, including Apache Hive SQL querys.
- Hive Metadata
-
The operation of Hive depends on the definition of metadata that describes the structure of data residing in a Hadoop cluster. Hive organizes its metadata with structure also, including definitions of Databases, Tables, Partitions, and Buckets.
- Apache Hive Type System
-
Hive defines primitive and complex data types that can be assigned to data as part of the Hive metadata definitions. These are primitive types such as TINYINT, BIGINT, BOOLEAN, STRING, VARCHAR, TIMESTAMP, etc. and complex types like Structs, Maps, and Arrays.
- Apache Hive Metastore
-
The Apache Hive Metastore is a stateless service in a Hadoop cluster that presents an interface for applications to access Hive metadata. Because it is stateless, the Metastore can be deployed in a variety of configurations to suit different requirements. In every case, it provides a common interface for applications to use Hive metadata.
The Hive Metastore is usually deployed as a standalone service, exposing an Apache Thrift interface by which client applications interact with it to create, modify, use and delete Hive metadata in the form of databases, tables, etc. It can also be run in embedded mode, where the Metastore implementation is co-located with the application making use of it.
- WANdisco Fusion Live Hive Proxy
-
The Live Hive Proxy is a WANdisco service that is deployed with Live Hive, acting as a proxy for applications that use a standalone Hive Metastore. The service coordinates actions performed against the Metastore with actions within clusters in which associated Hive metadata are replicated.
- Hive Client Applications
-
Client applications that use Apache Hive interact with the Hive Metastore, either directly (using its Thrift interface), or indirectly via another client application such as Beeline or HiveServer2.
- HiveServer2
-
is a service that exposes a JDBC interface for applications that want to use it for accessing Hive. This could include standard analytic tools and visualization technologies, or the Hive-specific CLI called Beeline.
Hive applications determine how to contact the Hive Metastore using the Hadoop configuration property
hive.metastore.uris. - HiveServer2 Template
-
A template service that amends the HiveServer2 config so that it no longer uses the embedded metastore, and instead correctly references the
hive.metastore.urisparameter that points to our "external" Hive Metastore server. - Hive pattern rules
-
A simple syntax used by Hive for matching database objects.
- Fusion Plugin for Live Hive
-
The Fusion Plugin for Live Hive is a plugin for WANdisco Fusion. Before you can install it you must first complete the installation of the core WANdisco Fusion product. See WANdisco Fusion user guide.
| Get additional terms from the Big Data Glossary. |
3.2. Product architecture
The native Hive Metastore is not replaced, instead, Live Hive runs as a proxy server that issues commands via the connected client (i.e. beeline) to the original metastore, which is on the cluster.
The Live Hive proxy passes on read commands directly to the local Hive Metastore, while Fusion co-ordinates any write commands, so all metastores on all clusters will perform the write operations, such as table creation. Live Hive will also automatically start to replicate Hive tables when their names match a user defined rule.
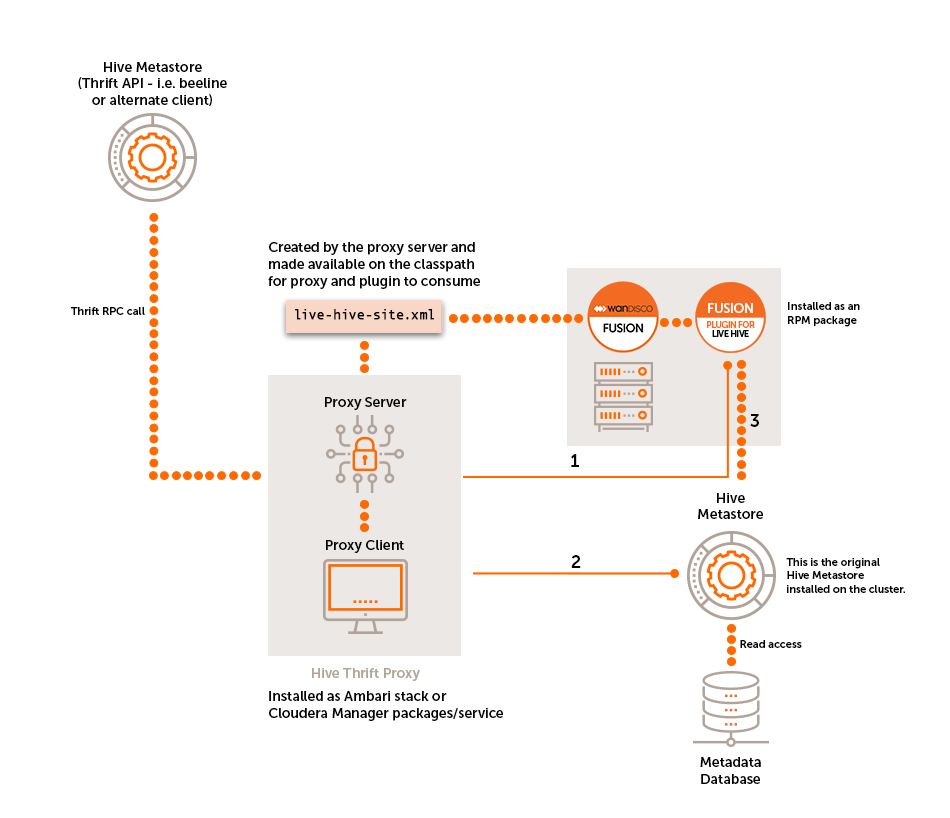
-
Write access needs to be co-ordinated by Fusion before executing the command on the metastore.
-
Read Commands are 'passed-through' straight to the metastore as we do not need to co-ordinate via Fusion.
-
Makes connection to the metastore on the cluster.
3.2.1. Limitations
Membership changes
There is currently no support for dynamic membership changes. Once installed on all Fusion nodes, the Live Hive plugin is activated. See Activate Live Hive Plugin. During activation, the membership for replication is set and cannot be modified later. For this reason, it’s not possible to add new Live Hive nodes at a later time, including a High Availability node running an existing Live Hive proxy that wasn’t part of your original membership.
Any change to membership in terms of adding, removing or changing existing nodes will require a complete reinstallation of Live Hive.
Where to install Live Hive
-
Install Live Hive on all zones. While it is possible to only install on a subset of your zones, there are two potential problem scenarios:
-
Live Hive installed on all zones but a Hive replicated rule is on a membership spanning a subset of zones.
-
Live Hive not installed on all zones, but a replicated rule is on a membership spanning all zones.
-
Both situations result in unpredictable behaviour that may end up causing serious problems.
-
HDP/Ambari only On HDP you cannot co-locate the Live Hive proxy on a node that is running the Hive Metastore. This is because Ambari uses the value from
hive.metastore.uristo determine what port the metastore should listen on, which would clash with Live Hive. -
You must install Live Hive on all Fusion nodes within a zone. Note that while the plugin must be installed on all nodes within a zone, the plugin’s proxy does not.
Hive must be running at all zones
All participating zones must be running Hive in order to support replication. We’re aware that this currently prevents the popular use case for replicating between on-premises clusters and s3/cloud storage, where Hive is not running. We intend to remove the limitation in a future release.
Support for Hive transactions
By default, Hive transactions will be rejected by the Live Hive Proxy. Where this is an absolute requirement for enabling transactions to pass through follow the steps here.
| Don’t enable pass-through of Hive transactions when they are used on tables which are under replication as it will cause inconsistency in Hive data across zones. |
3.3. Deployment models
The following deployment models illustrate some of the common use cases for running Live Hive.
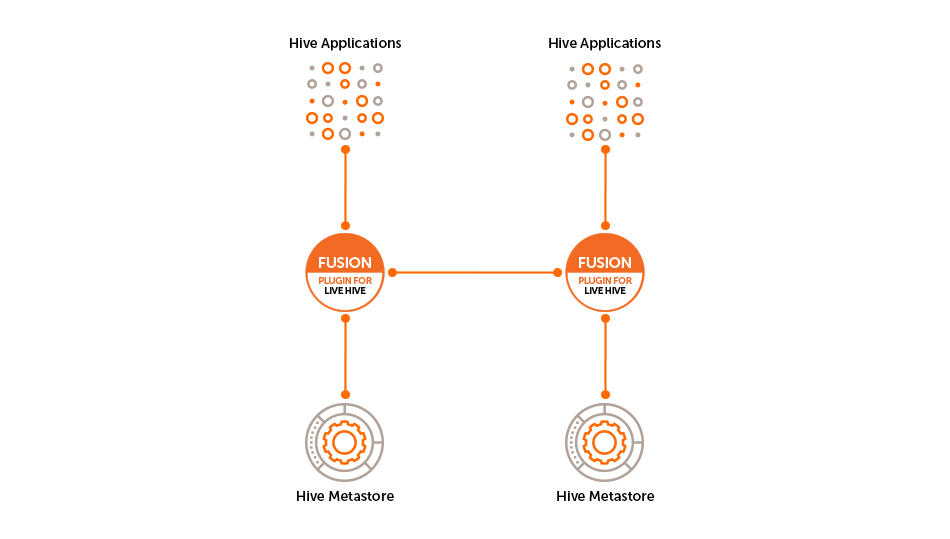
3.4. Analytic off-loading
In a typical on-premises Hadoop cluster, data ingest, analytic jobs all run through the same infrastructure where some activities impose a load on the cluster that can impact other activities. Fusion Plugin for Live Hive allows you to divide up the workflow across separate environments, which lets you isolate the overheads associated with some events. You can ingest in one environment while using a different environment where capacity is provided to run the analytic jobs. You get more control over each environment’s performance.
-
You can ingest data from anywhere and query that at scale within the environment.
-
You can ingest data on premises (or where ever the data is generated) and query it at scale in another optimized environment, such as a cloud environment with elastic scaling that can be spun up only when queries jobs are queued. In this model, you may ingest data continuously but you don’t need to run a large cluster 24-hours-per-day for queries jobs.
3.5. Multi-stage jobs across multiple environments
A typical Hadoop workflow might involve a series of activities: ingesting data, cleaning data and then analyzing the data in a short series of steps. You may be generating intermediate output to be run against end-stage reporting jobs that perform analytical work. Running all of these work streams on a single cluster could require a lot of careful coordination with different types of workloads, conducting multi-stage jobs. This is a common chain of query activities for Hive, where you might ingest raw data, refine and augment it with other information, then eventually run analytic jobs against your output on a periodic basis, for reporting purposes, or in real-time.
In a replicated environment, however, you can control where those job stages are run. You can split this activity across multiple clusters to ensure the queries jobs needed for reporting purposes will have access to the capacity necessary to ensure that they run within SLAs. You also can run different types of clusters to make more efficient use of the overall chain of work that occurs in multi-stage job environments. You could have a cluster running that is tweaked and tuned for most efficient ingest, while running a completely different kind of environment that is tuned for another task, such as the end-stage reporting jobs that run against processed and augmented data. Running with LiveData across multiple environments allows you to run each different type of activity in the most efficient way.
4. Installation
4.1. Pre-requisites
An installation should only proceed if the following prerequisites are met on each Live Hive Plugin node:
-
Hadoop Cluster - see the release notes for which platforms are supported
-
Hive installed, configured and running on the cluster
-
Fusion 2.14.x
It’s extremely useful to complete some work before you begin a Live Hive deployment. The following tasks and checks will make installation easier and reduce the chance of an unexpected roadblock causing a deployment to stall or fail.
It’s important to make sure that the following elements meet the requirements that are set in the Pre-requisites.
4.1.1. Server OS
One common requirement that runs through much of the deployment is the need for strict consistency between Fusion nodes, running Live Hive. Your nodes should, as a minimum, be running with the same versions of:
-
Hadoop/Manager software
-
Linux
-
Check to see if you are running a niche variant, e.g. Oracle Linux is compiled from Red Hat Enterprise Linux (RHEL), but it is not identical to a RHEL installation.
-
-
Java 8
-
Ensure you are running the same Java 8 version, on consistent paths.
-
4.1.2. Hadoop Environment
Before installing, confirm that your Hadoop clusters are fully operational.
-
Review all available Hadoop daemon log files for errors that may impact WANdisco Fusion or WANdisco Live Hive installations.
-
All nodes must have a "fusion" system user account for running Fusion services; as part of the installation of WANdisco Fusion, this system user will have been created.
|
Folder Permissions
When installing the Live Hive proxy or plugin, the permissions of /etc/wandisco/fusion/plugins/hive/ is set to match the Fusion user (FUSION_SERVER_USER) and group (FUSION_SERVER_GROUP), which are set in the Fusion node installation procedure. Permissions on the folder are also set such that processes can write new files to that location as long as the user associated with the process is the FUSION_SERVER_USER or is a member of the FUSION_SERVER_GROUP. No automatic fix for granting authorization
Changes to the fusion user/group are not automatically updated in their directories. You need to manually fix these issues, following the above guidelines. |
Live Hive dependencies
Generally, Live Hive is reliant on distribution artefacts being available for it to load. Proxy init scripts, plugin cp-extra scripts, etc, load in relevant items from the cluster it is installed on.
For Cloudera deployments, these functions will work as expected because all managed nodes have the CDH Parcel, regardless of the role of the node, thus libs are available. However, on Ambari deployments there is a requirement to load in the needed items.
Fusion Client libraries
Live Hive will require the Fusion Client to be installed on the Live Hive Proxy and Fusion nodes prior to install. If the NameNode Proxy was selected instead of the other URI selection options, then a manual installation of the client will be required to ensure compatibility.
- Manual install of Fusion Client on Fusion node(s)
-
You can install the client by running the following command on the Fusion node(s).
RHELyum install -y /opt/wandisco/fusion-ui-server/ui-client-platform/downloads/client_packages/fusion-hcfs-<distro-version>-client-hdfs-<fusion-version>.noarch.rpm
Debianapt-get install -y /opt/wandisco/fusion-ui-server/ui-client-platform/downloads/client_packages/fusion-hcfs-<distro-version>-client-hdfs-<fusion-version>.deb
If the Live Hive Proxy was co-located on the Fusion node(s), no further action is required, but please read further if the Live Hive Proxy was installed on different node(s).
- Manual install of Fusion Client on Live Hive Proxy node(s)
-
Obtain the client package first by running the following command on the Live Hive Proxy node:
RHELscp $FUSION_NODE:/opt/wandisco/fusion-ui-server/ui-client-platform/downloads/client_packages/fusion-hcfs-<distro-version>-client-hdfs-<fusion-version>.noarch.rpm .
Debianscp $FUSION_NODE:/opt/wandisco/fusion-ui-server/ui-client-platform/downloads/client_packages/fusion-hcfs-<distro-version>-client-hdfs-<fusion-version>.deb .
The package can then be installed:
RHELyum install -y fusion-hcfs-<distro-version>-client-hdfs-<fusion-version>.noarch.rpm
Debianapt-get install -y fusion-hcfs-<distro-version>-client-hdfs-<fusion-version>.deb
Hive Metastore Libraries (Ambari)
Check that Hive Metastore libraries are available on the Fusion node. These instructions are dependent on availability of the binaries and any local policies for access and use of the native system packages or access to repositories. The following commands check if the requirement packages / libraries are already installed:
rpm -qa "hive*-metastore"
dpkg -l "hive*-metastore"
ls /usr/*/current/hive-metastore/lib/
If running any of these commands shows that Hive Metastore is installed, no further action should be required. If the packages are not in place, you should run the appropriate package:
-
Hadoop Cluster (CDH or HDP, meeting Fusion requirements, see the Prerequisites Checklist)
-
Hive installed, configured and running on the cluster
-
WANdisco Fusion 2.14.x or later
# can be made non-interactive with -y flag yum install "hive*-metastore"
# can be made non-interactive with --non-interactive flag zypper install "hive*-metastore"
# can be made non-interactive with -y flag apt-get install "hive*-metastore"
4.1.3. Firewalls and Networking
Most of the items below should already be covered as part of the WANdisco Fusion installation, however, they are reiterated below:
-
If iptables or SELinux are running, you must confirm that any rules that are in place will not block Live Hive communication.
-
If any nodes are multi-homed, ensure that you account for this when setting which interfaces will be used during installation.
-
Ensure that you have hostname resolution between clusters, if not add suitable entries to your hosts files.
-
Check your network performance to make sure there are no unexpected latency issues or packet loss.
4.1.4. Security
This section explains how you can secure your Live Hive deployment.
Kerberos Configuration
As part of the automated installation of Live Hive, KDC admin credentials will be requested. This will allow the Live Hive Proxy keytabs to be generated by the Cluster manager.
If selecting or utilising a manual Kerberos setup, follow the next section below.
Manual Kerberos Setup
Prepare a Kerberos principal for each WANdisco Fusion/Live Hive Proxy node and place this in a keytab on the relevant node(s).
-
The principal value should be taken from the hive-site.xml property
hive.metastore.kerberos.principal.The keytab/principal that you specify for the live hive service must use the same principal that is used by the rest of the Hive stack. Usually it appears in the form hive/_HOST@DOMAIN.COM. Other values are likely to cause proxied requests to fail at the proxy-to-metastore step. -
The keytab should be exported to path located in hive-site.xml property
hive.metastore.kerberos.keytab.file. -
Please ensure the keytab is owned by the Live Hive user:group and has suitable permissions, such as 640.
-
The Live Hive user and WANdisco Fusion user must also be a part of a common group.
Example
Live Hive user =hive
WANdisco Fusion user =hdfs
Common group =hadoop
If a non-superuser principal is used, it also needs sufficient permission to impersonate all users. See the Secure Impersonation (proxyuser) section for details on how to set this up.
Secure Impersonation (proxyuser)
Normally the Hive user has superuser permissions on the HiveServer2 and Hive Metastore nodes.
If you are installing into different nodes, corresponding proxyuser parameters should also be updated in core-site.xml and kms-site.xml.
The Hive user on the Live Hive proxy nodes (e.g. the WANdisco Fusion nodes) must have permission to impersonate users.
<property>
<name>hadoop.proxyuser.$USERNAME.hosts</name>
<value>$HIVE_METASTORE,$HIVESERVER2,$LHV_PROXY01,$LHV_PROXY02</value>
</property>
<property>
<name>hadoop.proxyuser.$USERNAME.groups</name>
<value>*</value>
</property>
$USERNAME - the superuser who will act as a proxy to the other users, this is usually set as system user hive.
- hadoop.proxyuser.$USERNAME.hosts
-
Defines hosts from which client can be impersonated. This can be a comma separated list or a wildcard (*).
During installation, this value will automatically be set to include the Live Hive Proxy nodes. If the value has already been set as a wildcard (*), then it will be left untouched. - hadoop.proxyuser.$USERNAME.groups
-
A list of groups whose users the superuser is allowed to act as proxy. Include a wildcard (*), which will mean that proxies of any users are allowed. To clarify, for the superuser to act as proxy to another user, the proxy actions must be completed on one of the hosts that are listed, and the user must be included in the list of groups. Note that this can be a comma separated list or the noted wildcard (*).
This is only required if TDE Encryption (e.g. Ranger KMS, Navigator Key Trustee) is being used for HDFS.
<property> <name>hadoop.kms.proxyuser.$USERNAME.hosts</name> <value>$HIVE_METASTORE,$HIVESERVER2,$LHV_PROXY01,$LHV_PROXY02</value> </property> <property> <name>hadoop.kms.proxyuser.$USERNAME.groups</name> <value>*</value> </property>
SSL
Enablement of SSL encryption (optional) is covered in the WANdisco Fusion User Guide - SSL section.
To enable SSL encrypted communication between Fusion nodes, Java KeyStore and TrustStore files must be generated or available for all Live Hive nodes.
| We don’t recommend using Self-signed certificates, except for proof-of-concept/testing. |
-
Live Hive server ←→ Live Hive server
-
IHC server ←→ Live Hive server
-
client ←→ Live Hive server
-
browser ←→ UI server
4.1.5. Server utilisation
-
By default, the Live Hive Proxy will be installed on the same node as the WANdisco Fusion Server. Ensure there is suitable resources available for the Proxy to run alongside any other applications installed on the WANdisco Fusion Server.
-
Use
ulimit -u && ulimit -nto check on the the number of processes / open files being sufficient for the Live Hive user (e.g.hive). Compare with those set for the nodes that have active HiveServer2 component(s) installed. -
Use netstat to review the connections being made to the server. Verify that the port required by the Live Hive Proxy is not in use (default: 9090).
4.2. Installation
4.2.1. Cloudera-based steps
Run the installer
Obtain the Live Hive installer from WANdisco. Open a terminal session on your Fusion node and run the installer as follows:
-
Using an account with appropriate permissions, run the Live Hive installer on each host required:
./live-hive-installer_<version>.sh
You will see the following messaging.
# ./live-hive-installer_<version>.sh Verifying archive integrity... All good. Uncompressing WANdisco Live Hive....................... :: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### ##### You are about to install WANdisco Live Hive version 4.0.0.0 Do you want to continue with the installation? (Y/n) wd-live-hive-plugin-4.0.0.0.tar.gz ... Done live-hive-fusion-core-plugin-4.0.0.0-1459.noarch.rpm ... Done storing user packages in '/opt/wandisco/fusion-ui-server/ui-client-platform/downloads/core_plugins/live-hive' ... Done live-hive-ui-server-4.0.0.0-dist.tar.gz ... Done All requested components installed. Go to your WANdisco Fusion UI Server to complete configuration.
|
Installer options
View the Installer Options section for details on additional installer functions, including the ability to install selected components.
|
| IMPORTANT: Once you run this installer script, do not restart the Fusion node until you have fully completed the installation steps (up to activation) for this node. |
Configure Live Hive
-
Open a session to your Fusion UI. You will see a message confirming that the Live Hive Plugin has been detected.
 Figure 3. Live Hive install - dashboard
Figure 3. Live Hive install - dashboard -
Go to the Settings page, the plugin Fusion Plugin for Live Hive now appears on the plugins list. Click the button labelled Install Now.
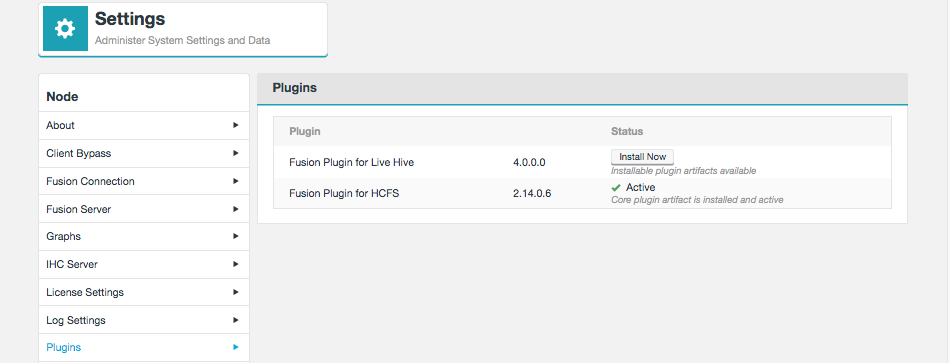 Figure 4. Live Hive install - settings
Figure 4. Live Hive install - settings -
The installation process runs through four steps that handle the placement of parcel files onto your Cloudera Manager server.
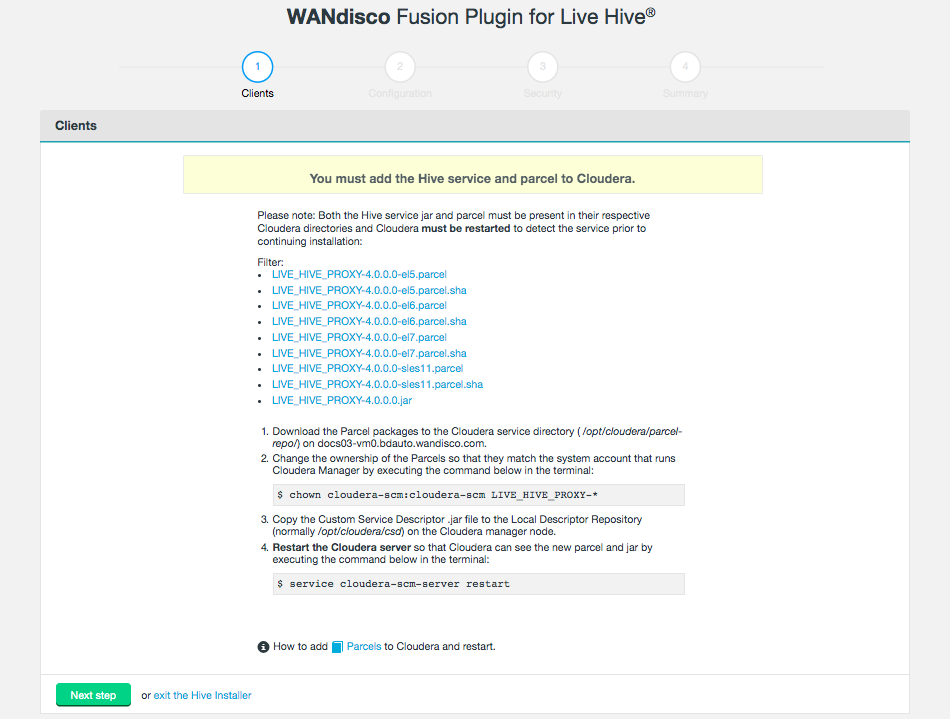 Figure 5. Live Hive install - clientsParcelsParcels need to be placed in the correct directory to make them available to the manager. To do this:
Figure 5. Live Hive install - clientsParcelsParcels need to be placed in the correct directory to make them available to the manager. To do this:Copy the paths for the .parcel and .parcel.sha files for your corresponding platform type,
e.g. el6 (Enterprise Linux version 6).-
Download the Parcel packages to the Cloudera service directory (/opt/cloudera/parcel-repo/) on your node, e.g.
cd /opt/cloudera/parcel-repo wget <your-fusion-node.hostname>:8083/ui/downloads/core_plugins/live-hive/parcel_packages/LIVE_HIVE_PROXY-<version>-el6.parcel wget <your-fusion-node.hostname>:8083/ui/downloads/core_plugins/live-hive/parcel_packages/LIVE_HIVE_PROXY-<version>-el6.parcel.sha
-
Change the ownership of the parcel files to match up with Cloudera Manager, e.g. use 'chown cloudera-scm:cloudera-scm LIVE_HIVE_PROXY-*'
-
Copy the Custom Service Descriptor (LIVE_HIVE_PROXY-x.x.x.jar) file to the Local Descriptor Repository (normally /opt/cloudera/csd/) on your node. e.g.
cd ../csd wget http://<your-fusion-node.hostname>:8083/ui/downloads/core_plugins/live-hive/parcel_packages/LIVE_HIVE_PROXY-<version>.jar Resolving <your-fusion-node.hostname>... 10.0.0.1 Connecting to <your-fusion-node.hostname>.com|10.10.0.1|:8083... connected. HTTP request sent, awaiting response... 200 OK Length: 4041 (3.9K) [application/java-archive] Saving to: LIVE_HIVE_PROXY-<version>.jar 100%[=============================================================================================>] 4,041 --.-K/s in 0s
-
Restart the Cloudera server so that Cloudera can see the new parcel and jar, e.g.
service cloudera-scm-server restart
After restarting the Cloudera Server, the Cloudera Manager Service(CMS) will report a stale config, which requires a restart via Cloudera Manager. e.g. Login to Cloudera Manager and click on the stale config spinner.
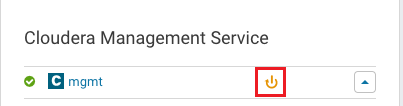 Figure 6. Live Hive installation - CMS restart
Figure 6. Live Hive installation - CMS restart
-
-
The second installer screen handles Configuration.
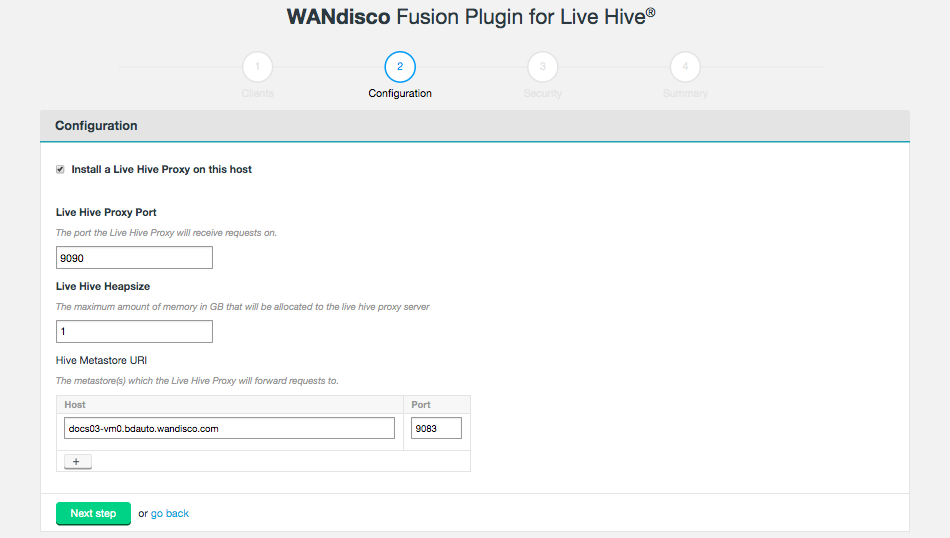 Figure 7. Live Hive installation - validation
Figure 7. Live Hive installation - validation- Install a Live Hive Proxy on this host
-
The installer lets you choose not to install the Live Hive proxy onto this node. While you must install Live Hive on all nodes, if you don’t wish to use a node to store Hive metadata, you can choose to exclude the Live Hive proxy from the installation. If you do this, the node still plays its part in transaction coordination, without keeping a local copy of the replicated data.
If you deselect Live Hive proxy on ALL nodes, then replication will not work. You must install at least 1 proxy in each zone. Should you have a cluster that doesn’t have a single Live Hive proxy, you will need to perform the following procedure to enable Hive metadata replication. - Live Hive Proxy Port
-
The HTTP port used by the Plugin. Default: 9090
- Hive Metastore URI
-
The metastore(s) which the Live Hive proxy will send requests to.
Add additional URIs by clicking the + Add URI button and entering additional URI / port information.If you add additional URIs, you must complete the necessary information or remove them. You cannot have an incomplete line. 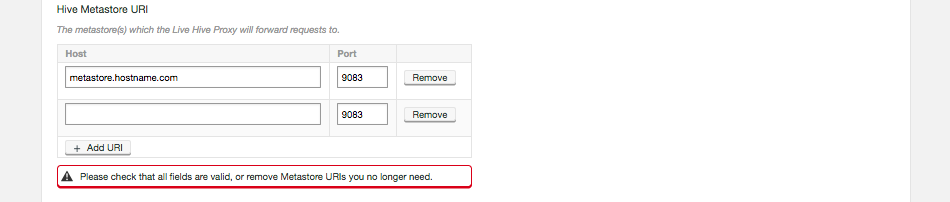 Figure 8. Live Hive installation - Additional URIs
Figure 8. Live Hive installation - Additional URIsClick on Next step to continue.
-
Step 3 of the installation covers security. If you have not enabled Kerberos on your cluster, you will pass through this step without adding any additional configuration.
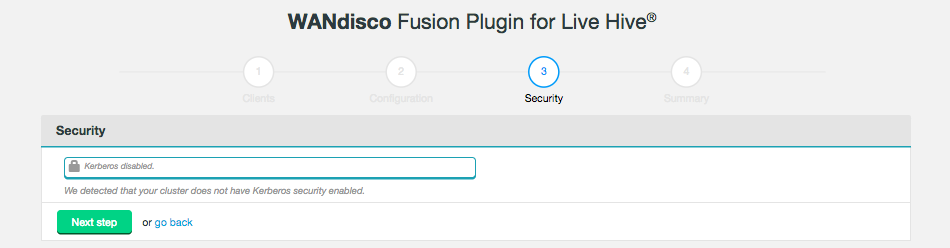 Figure 9. Live Hive installation - security disabled
Figure 9. Live Hive installation - security disabledIf kerberos is enabled on your cluster, supply your kerberos credentials.
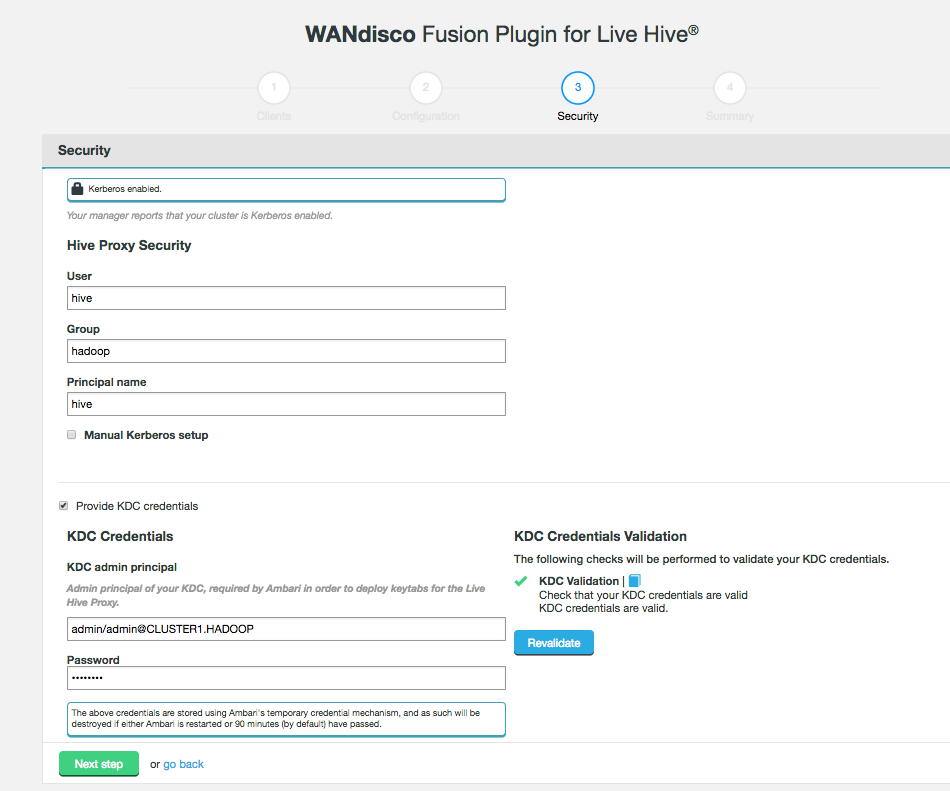 Figure 10. Live Hive installation - security enabled
Figure 10. Live Hive installation - security enabledHive Proxy Security
- User
-
System user used for Hive Proxy
- Group
-
System group for secure access
- Principal name
-
The name of the Kerberos principal name for access
Ensure that you use the same principal as is used for the Hive stack. If you use a different principal then Live Hive will not work due to basic security constraints. - Manual Kerberos setup
-
Tick the manual Kerberos setup
- Provide KDC credentials
-
Tick the checkbox to configure KDC credentials
KDC Credentials
- KDC admin principal
-
Admin principal of your KDC, required by the Hadoop manager in order to deploy keytabs for the Live Hive Proxy.
- Password
-
Password for the KDC admin principle.
The above credentials are stored using stored using the Hadoop Manager’s temporary credential mechanism, and as such will be destroyed if either the Hadoop manager is restarted or 90 minutes (by default) have passed.
- Keytab file path
-
The installer now validates that there is read access to the keytab that you specify here.
- Metastore Service Principal Name
-
The installer validates where there are valid principals in the keytab.
- Metastore Service Hostname
-
Enter the hostname of your Hive Metastore service.
-
The final step is to complete the installation. If you want to restart services automatically, check the box, then click Start Install.
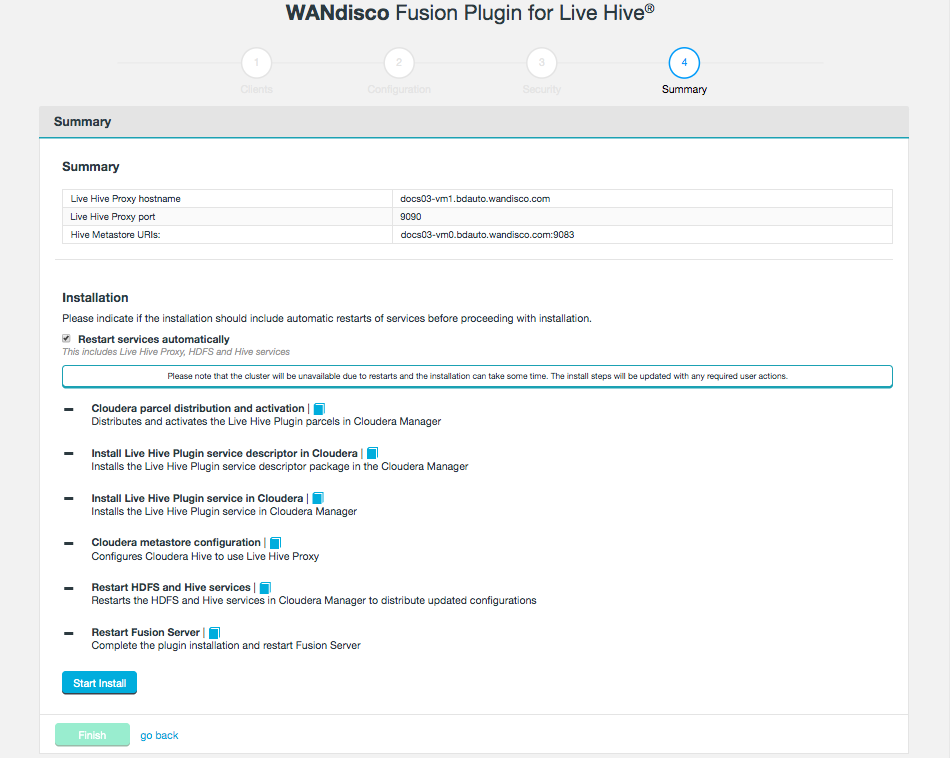 Figure 11. Live Hive installation - summary
Figure 11. Live Hive installation - summaryThe following steps are carried out:
- Cloudera parcel distribution and activation
-
Distributes and activates the Live Hive Plugin parcels in Cloudera Manager
- Install Live Hive Plugin service descriptor in Cloudera
-
Installs the Live Hive Plugin service descriptor package in Cloudera Manager
- Install Live Hive Plugin service in Cloudera
-
Installs the Live Hive Plugin service in Cloudera Manager
- Cloudera metastore configuration
-
Configures Cloudera Hive to use the Live Hive Proxy
- Restart HDFS and Hive services
-
Restarts the HDFS and Hive services in Cloudera Manager to distribute updated configurations
- Restart Fusion Server
-
Complete the plugin installation and restart Fusion Server
- Configure Impala (if installed)
-
Configures Cloudera Impala to be compatible with Live Hive
-
The installation will complete with a message Live Hive installation complete!.
Click Finish to close the plugin installer screens.
Now advance to the Activation steps.
4.2.2. Ambari-based steps
|
Important HDP/Ambari requirement On HDP you cannot co-locate the Live Hive proxy on a node that is running the Hive Metastore. This is because Ambari uses the value from hive.metastore.uris to determine what port the Metastore should listen on, which would clash with Live Hive.
|
Run the installer
Obtain the Live Hive installer from WANdisco. Open a terminal session on your Fusion node and run the installer as follows:
-
Using an account with appropriate permissions, run the Live Hive installer on each host required:
./live-hive-installer_<version>.sh
You will see the following messaging.
# ./live-hive-installer_<version>.sh Verifying archive integrity... All good. Uncompressing WANdisco Live Hive....................... :: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### ##### You are about to install WANdisco Live Hive version 4.0.0.0 Do you want to continue with the installation? (Y/n) wd-live-hive-plugin-4.0.0.0.tar.gz ... Done live-hive-fusion-core-plugin-4.0.0.0-1459.noarch.rpm ... Done storing user packages in '/opt/wandisco/fusion-ui-server/ui-client-platform/downloads/core_plugins/live-hive' ... Done live-hive-ui-server-4.0.0.0-dist.tar.gz ... Done All requested components installed. Go to your WANdisco Fusion UI Server to complete configuration.
| IMPORTANT: Once you run this installer script, do not restart the Fusion node until you have fully completed the installation steps for this node. |
Configure Live Hive
-
Open a session to your Fusion UI. You will see a message that confirms that the Live Hive plugin has been detected.
Figure 12. Live Hive install - dashboard -
Go to the Settings page, the plugin Fusion Plugin for Live Hive now appears on the plugins list. Click the button labelled Install Now.
Figure 13. Live Hive install - settings -
The installation process runs through four steps that handle the placement of parcel files onto your Cloudera Manager server.
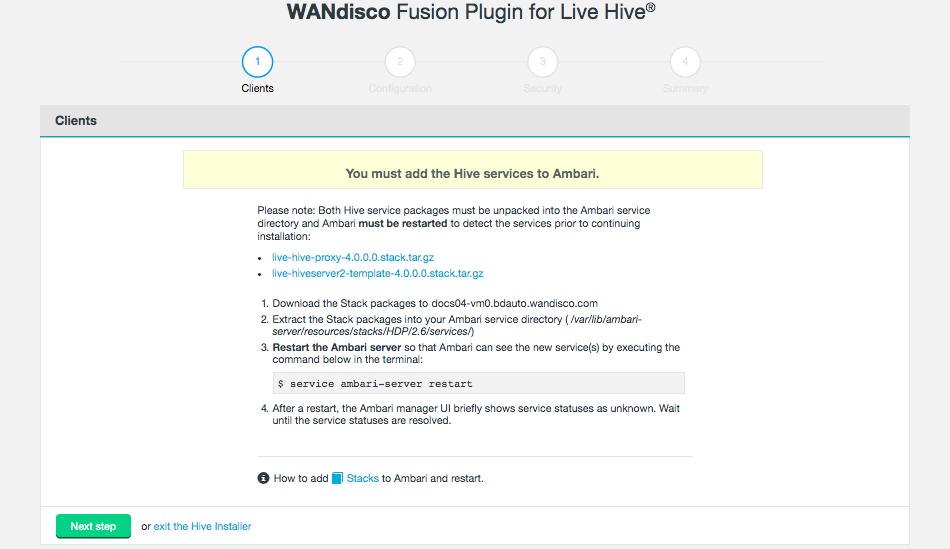 Figure 14. Live Hive installation - ClientsStacks
Figure 14. Live Hive installation - ClientsStacksStacks need to be placed in the correct directory to make them available to the manager. To do this:
-
Download the service from the installer client download panel
-
The services are gz files that will expand to the directories /LIVE_HIVE_PROXY and /LIVE_HIVESERVER2_TEMPLATE.
-
For HDP, place this directory in /var/lib/ambari-server/resources/stacks/HDP/<version>/services.
-
Restart the Ambari server.
-
Check on your Ambari manager that the services are present.
 Figure 15. Stacks present
Figure 15. Stacks present
-
-
The second installer screen handles Configuration.
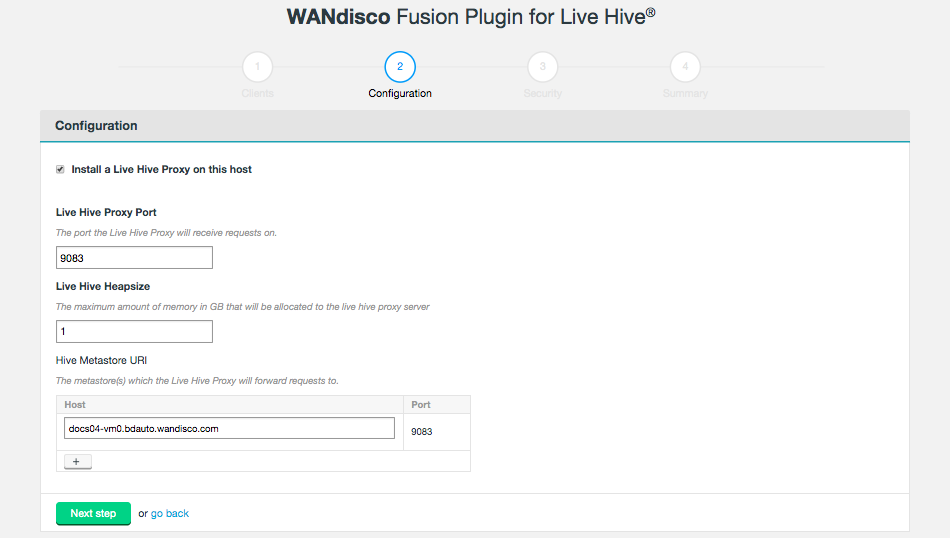 Figure 16. Live Hive installation - Configuration
Figure 16. Live Hive installation - Configuration- Install a Live Hive Proxy on this host
-
The installer lets you choose not to install the Live Hive proxy onto this node. While you must install Live Hive on all nodes, if you don’t wish to use a node to store Hive metadata, you can choose to exclude the Live Hive proxy from the installation. If you do this, the node still plays its part in transaction coordination, without keeping a local copy of the replicated data.
If you deselect Live Hive proxy on ALL nodes, then replication will not work. You must install at least 1 proxy in each zone. Should you have a cluster that doesn’t have a single Live Hive proxy, you will need to perform the following procedure to enable Hive metadata replication. - Live Hive Proxy Port
-
The HTTP port used by the Plugin. Default: 9090
- Hive Metastore URI
-
The metastore(s) which the Live Hive proxy will send requests to.
Add additional URIs by clicking the + Add URI button and entering additional URI / port information.If you add additional URIs, you must complete the necessary information or remove them. You cannot have an incomplete line.
Figure 17. Live Hive installation - Additional URIsClick on Next step to continue.
-
Step 3 of the installation covers security. If you have not enabled Kerberos on your cluster, you will pass through this step without adding any additional configuration.
 Figure 18. Live Hive installation - security disabled
Figure 18. Live Hive installation - security disabledIf you enable Kerberos, you will need to supply your Kerberos credentials.
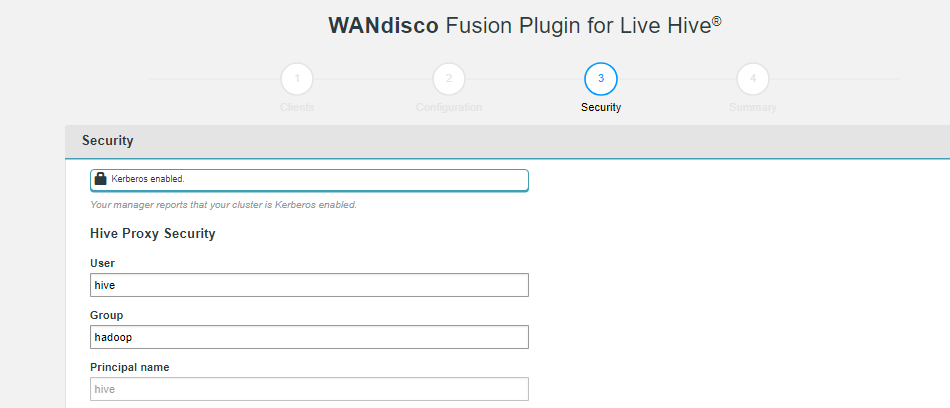 Figure 19. Live Hive installation - security enabled
Figure 19. Live Hive installation - security enabled- Hive Proxy Security
-
Kerberos settings for the Hive Proxy.
- User
-
The system user for Hive.
- Group
-
The system group for Hive.
- Principal name
-
The Principal name for the Hive user.
Ensure that you use the same principal as is used for the Hive stack. If you use a different principal then Live Hive will not work due to basic security constraints.
- Manual Kerberos setup (checkbox)
-
Tick this checkbox to provide the Kerberos details for Hive Proxy Kerberos.
- Hive Proxy Kerberos
-
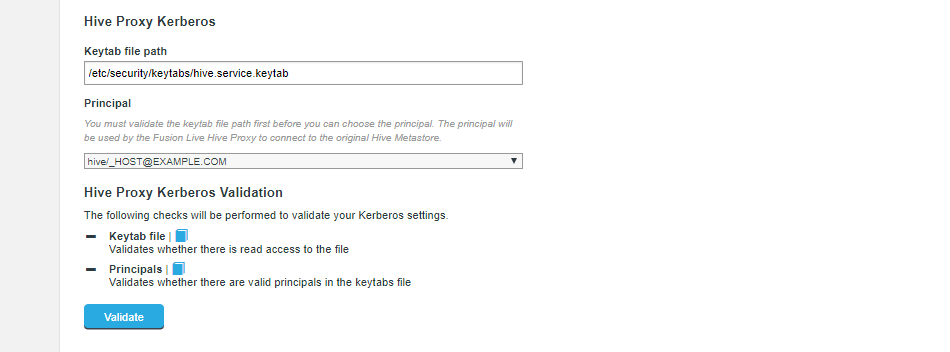 Figure 20. Live Hive installation - Kerberos
Figure 20. Live Hive installation - Kerberos- Keytab file path
-
The installer now validates that there is read access to the keytab that you specify here.
Validate firstYou must validate the keytab file before you choose the principal.
- Principal
-
Select from the available principals. This is the principal that will be used to connect to the original Hive Metastore. Validation checks that the principal is valid.
- Provide KDC credentials (Checkbox)
-
Tick the checkbox to provide details for a KDC’s admin principal and password.
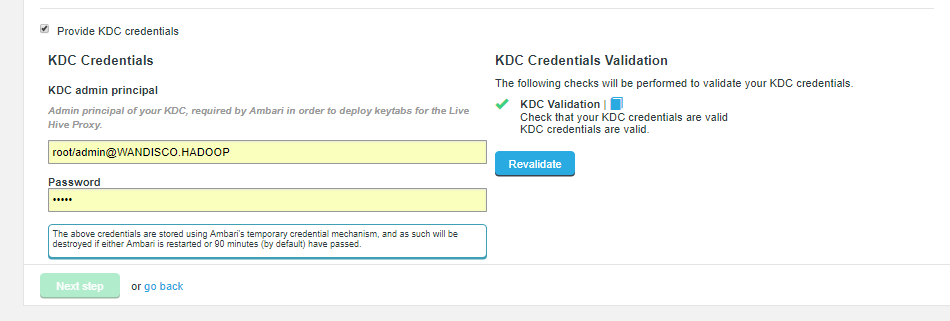 Figure 21. Live Hive installation - KDC credentials
Figure 21. Live Hive installation - KDC credentials - KDC Credentials
-
If Ambari is managing the cluster’s Kerberos implementation, you must provide the following KDC credentials or the plugin installation will fail. - KDC admin principal
-
Admin principal of your KDC, required by the Hadoop manager in order to deploy keytabs for the Live Hive Proxy.
- Password
-
Password for the KDC admin principle.
The above credentials are stored using stored using the Hadoop Manager’s temporary credential mechanism, and as such will be destroyed if either the Hadoop manager is restarted or 90 minutes (by default) have passed.
-
The final step is to complete the installation. If you want to restart services automatically, check the box, then click Start Install.
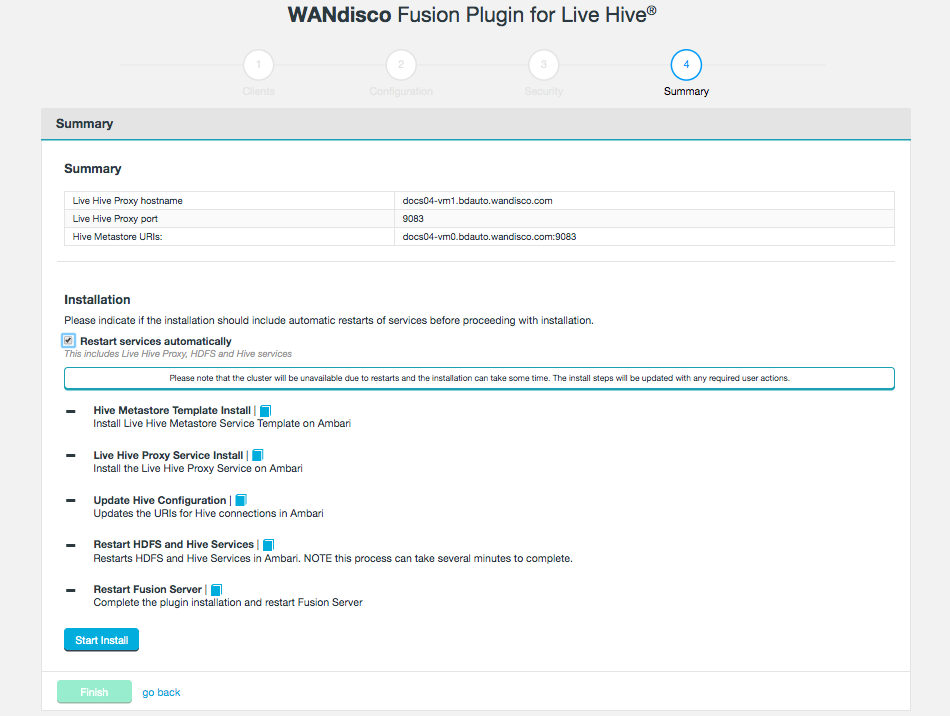 Figure 22. Live Hive installation - summary
Figure 22. Live Hive installation - summaryThe following steps are carried out:
- Hive Metastore Template Install
-
Install Live Hive Metastore Service Template on Ambari.
- Live Hive Proxy Service Install
-
Install the Live Hive Proxy Service on Ambari.
- Update Hive Configuration
-
Updates the URIs for Hive connections in Ambari.
- Restart HDFS and Hive Service
-
Restarts HDFS and Hive Services in Ambari.
You will also need to restart any dependent services that are impacted by the installation, such as Big SQL. - Restart Fusion Server
-
Complete the plugin installation and restart Fusion Server.
-
The installation will complete with a message Live Hive installation complete.
Click Finish to close the plugin installer screens.
You must now activate the plugin.
4.2.3. Installer Options
The following section provides additional information about running the Live Hive installer.
Installer Help
The bundled installer provides some additional functionality that lets you install selected components, which may be useful if you need to restore or replace a specific file. To review the options, run the installer with the --help option, i.e.
./live-hive-installer.sh --help Verifying archive integrity... All good. Uncompressing WANdisco Hive Live.......................
This usage information describes the options of the embedded installer script. Further help, if running directly from the installer is available using '--help'. The following options should be specified without a leading '-' or '--'. Also note that the component installation control option effects are applied in the order provided.
Installation options
General options: help Print this message and exit Component installation control: only-fusion-ui-client-plugin Only install the plugin's fusion-ui-client component only-fusion-ui-server-plugin Only install the plugin's fusion-ui-server component only-fusion-server-plugin Only install the plugin's fusion-server component only-user-installable-resources Only install the plugin's additional resources skip-fusion-ui-client-plugin Do not install the plugin's fusion-ui-client component skip-fusion-ui-server-plugin Do not install the plugin's fusion-ui-server component skip-fusion-server-plugin Do not install the plugin's fusion-server component skip-user-installable-resources Do not install the plugin's additional resources
Standard help parameters
./live-hive-installer.sh --help Makeself version 2.1.5 1) Getting help or info about ./live-hive-installer.sh : ./live-hive-installer.sh --help Print this message ./live-hive-installer.sh --info Print embedded info : title, default target directory, embedded script ... ./live-hive-installer.sh --lsm Print embedded lsm entry (or no LSM) ./live-hive-installer.sh --list Print the list of files in the archive ./live-hive-installer.sh --check Checks integrity of the archive 2) Running ./live-hive-installer.sh : ./live-hive-installer.sh [options] [--] [additional arguments to embedded script] with following options (in that order) --confirm Ask before running embedded script --noexec Do not run embedded script --keep Do not erase target directory after running the embedded script --nox11 Do not spawn an xterm --nochown Do not give the extracted files to the current user --target NewDirectory Extract in NewDirectory --tar arg1 [arg2 ...] Access the contents of the archive through the tar command -- Following arguments will be passed to the embedded script 3) Environment: LOG_FILE Installer messages will be logged to the specified file
4.2.4. Silent installation for Cloudera and Ambari
Instead of installing through the UI, you can install using the silent (scripted) installer. These steps need to be repeated on each node you want the Live Hive Plugin installed on.
-
Obtain the Live Hive Plugin installer from WANdisco and open a terminal session on your Fusion node.
-
Ensure the downloaded file is executable e.g.
chmod +x live-hive-installer.sh
-
Run the Live Hive Plugin installer using an account with appropriate permissions e.g.
./live-hive-installer.sh
-
Now place the parcels or stacks in the relevant directory. They can be found in the directory
/opt/wandisco/fusion-ui-server/ui-client-platform/downloads/core_plugins/live-hive-<version>. The steps are the same steps as in the UI installer. For more information see Parcels if you are using Cloudera, or Stacks if using Ambari. Ensure that you restart your Cloudera or Ambari server. -
Now edit the live_hive_silent_installer.properties file, located in /opt/wandisco/fusion-ui-server/plugins/live-hive-ui-server-<your version>/properties.
The following fields are required:
live.hive.proxy.thrift.host- the hostname to which the Live Hive Proxy server will bind.live.hive.proxy.thrift.port- the port the Live Hive Proxy will run on.live.hive.proxy.remote.thrift.uris- the original Hive Metastore thrift host and port. This must be in the form host:port. If vanilla metastore HA is configured, this should be a comma separated list of all existing metastore host:ports. For kerberized clusters, please see the notes in the properties file specific to your setup. -
To start the silent installation, go to
/opt/wandisco/fusion-ui-server/plugins/live-hive-ui-server-<version>and run:./scripts/silent_installer_live_hive.sh ./properties/LIVE_HIVE_PROXY-silent-installer.properties
-
Repeat these steps on each node.
-
Once the plugin is installed on all nodes that will replicate Hive metadata, activate the plugin.
4.3. Activate Live Hive
After completing the installation on all applicable Fusion nodes, you will need to activate Live Hive before you can use it. Use the following steps to complete the plugin activation.
-
Log into the Fusion UI. The Live Hive will be visible on the dashboard, but inactive.
 Figure 23. Live Hive inactive - dashboard
Figure 23. Live Hive inactive - dashboard -
On the Settings tab, go to the Plugin Activation link in the Live Hive section of the side menu. The Live Hive Plugin Activation screen will appear.
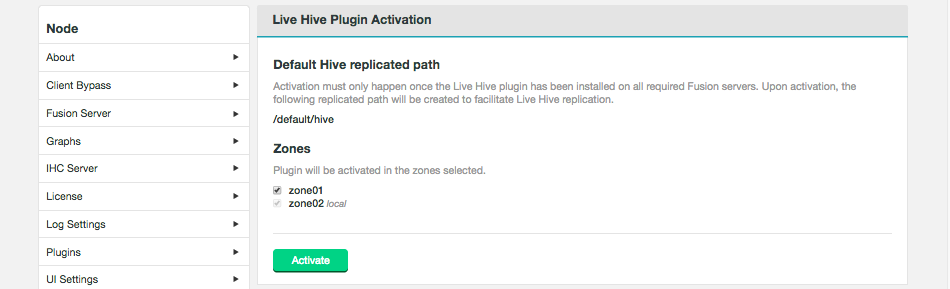 Figure 24. Live Hive activation - activateEnsure that your clusters have been inducted before activating.The plugin will not work if you activate before completing the induction of all applicable zones.
Figure 24. Live Hive activation - activateEnsure that your clusters have been inducted before activating.The plugin will not work if you activate before completing the induction of all applicable zones.Tick the checkboxes that correspond to the zones that you want to replicate Hive metadata between, then click Activate.
-
A message will appear at the bottom of the screen that confirms that the plugin is active.
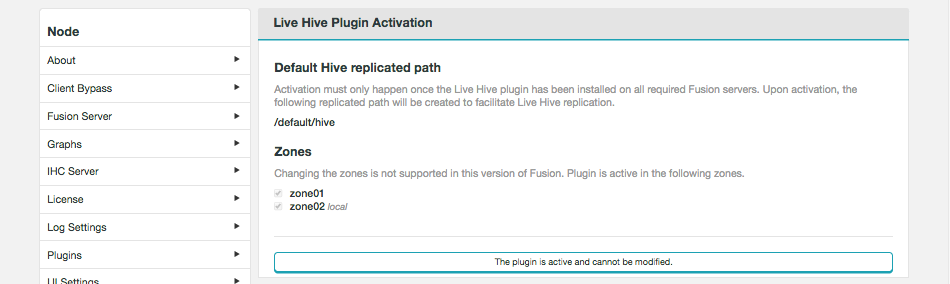 Figure 25. Live Hive activation - activated
Figure 25. Live Hive activation - activatedYou can’t change membership, once activated. See Membership changes. -
Reload your browser to use the new plugin.
 Figure 26. Live Hive activation - reload window
Figure 26. Live Hive activation - reload windowIt will now also be visible on the dashboard.
 Figure 27. Live Hive active - dashboard
Figure 27. Live Hive active - dashboard
4.4. Validation
Hive replication can use the full potential of WANdisco’s LiveData, meaning metadata DDL commands such as Create, Alter and Drop table commands are replicated, in addition to the inserts and data stores in HDFS.
The following section offers guidance in testing live replication of Hive metadata and related HDFS data.
Both Hive, Fusion and the Live Hive Proxy/Plugin are assumed to be in a healthy state prior to running through these validation steps.
4.4.1. Live Hive Plugin configuration
In order to enable Hive replication, two rules are needed:
-
HCFS rule that covers the location of Hive data in the Hadoop file system - see Create a rule.
-
This rule must be consistent before creating Hive rules.
-
-
Hive rule that defines patterns to match the database name and table names - see Create Hive rule.
Once complete, the Replication tab on the UI should display the rules like the example below:

In this example, the rules will allow for live replication of any HDFS data written to the /apps/hive/warehouse path, and for a database named directory with any tables contained within (*).
This may not be suitable for all environments (especially production ones), as a more restricted dataset may be desired. Adjust for your own requirements when creating the rules.
4.4.2. Creating and Replicating New Hive Databases and Tables
To start replicating Hive data and metadata, create a database and table(s) in Hive that match the replication rules created in the previous section (Live Hive Plugin configuration).
All links below reference the Apache Hive documentation.
-
Connect to HiveServer2 via Beeline.
Beeline example - Guidance on connecting to the HiveServer2 service using a Beeline connection. -
Create a Database to be used and ensure that it matches the replication rules created for both the HCFS and Hive data.
Create/Drop/Alter/Use Database - Documentation for Database commands. -
Create table(s) within the database to be used for testing.
Create/Drop/Truncate Table - Documentation for Table commands.Managed vs External Tables - Guidance on tables used within Hive databases.
-
Verify that the database and tables have been created and exist in Hive on the source zone.
Show Databases - Documentation for listing databases.Show Tables - Documentation for listing tables in a specified database.
If the replication rules have been set up correctly to match the database/table(s) created, then it will be possible to perform a Hive consistency check on these rules to ensure Hive metadata replication has occurred on the remote zone(s).
If performing a Hive consistency check at this point, it is also recommended to run a HCFS consistency check on the relevant HCFS rule.
Adding and replicating data to a Hive table
This section will provide guidance in demonstrating live replication of data within a Hive table, followed by a query of the data.
-
On the source cluster, download a sample data set from a public AWS S3 bucket ("fusion-demo").
wget https://s3-us-west-1.amazonaws.com/fusion-demo/datastream1.txt
-
On the source cluster, create a Hive table with the following schema, note that the
<database_name>and<table_name>will need to be replaced with names that match a Hive replication rule:use <database_name>; CREATE TABLE IF NOT EXISTS <table_name> (id int , fname string, lname string, email string,social string, age string, secret string,license string, ip string ) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',' STORED AS TEXTFILE;
-
On the source cluster, place the data file (
datastream1.txt) into HDFS, so that it can be replicated to the remote cluster and queried from Hive in the next step.hdfs dfs -put datastream1.txt /path/to/replication_rule/<database_name>.db/<table_name>
-
On source and remote clusters, open a beeline connection and run a query on the data set.
use <database_name>; select count(*) from <table_name> where id >=0; select * from <table_name> where fname=<username> order by lname;
The output from the two
selectqueries should match for each cluster/zone defined in the replication rule. As an example, if you use the<username>Helen, 680 rows will be returned in the example dataset.
Alter and Drop Table Examples
These next steps will demonstrate replicating the Alter and Drop commands.
-
On the source cluster, run a
alter tablecommand and provide the replace<new_table_name>with a different name.Note that the new table name must still match up with a Hive replication rule.
use <database_name>; alter table <table_name> rename to <new_table_name>;
-
On a remote cluster, verify the
alter tablecommand has replicated.use <database_name>; show tables;
The
<new_table_name>should now be shown in the tables list with the original<table_name>no longer present. -
On the source cluster, run a
drop tablecommand on the newly renamed table.use <database_name>; drop table <new_table_name>;
-
On a remote cluster, verify that
<new_table_name>no longer exists.use <database_name>; show tables;
The renamed table should no longer be listed.
4.5. Upgrade
If you wish to perform a Live Hive upgrade, please contact WANdisco support.
An outline of the steps involved:
-
Run a script to gather information on existing configurations
-
Reset environment
-
Upgrade plugin components
-
Renew configurations
4.6. Uninstallation
If you wish to uninstall Live Hive, please contact WANdisco support. The uninstall procedure currently requires manual editing and should not be done without calling WANdisco’s support team for assistance. The process involves both service and package removal.
4.7. Installation Troubleshooting
This section covers any additional settings or steps that you may need to take in order to successfully complete an installation.
4.7.1. Ensure hadoop.proxyuser.hive.hosts is properly configured
The following Hadoop property needs to be checked, when running with the Live Hive Plugin. While the settings apply specifically to HDP/Ambari, it may also be necessary to check the property for Cloudera deployments.
Configuration placed in core-site.xml
<property>
<name>hadoop.proxyuser.hive.hosts</name>
<value>host1.domain.com,host-LIVE_HIVE_PROXY.organisation.com,host2.domain.com </value>
<description>
Hostname from where superuser hive can connect. This
is required only when installing hive on the cluster.
</description>
</property>
Proxyuser property
- Name
-
Hive hostname from which the superuser "hive" can connect.
- Value
-
Either a comma-separated list of your nodes or a wildcard. The hostnames should be included for HiveServer2, Metastore hosts and Live Hive proxy.
Some cluster changes can modify this property
| Systems changes to properties such as hadoop.proxyuser.hive.hosts, should be made with great care. If the configuration is not present, impersonation will not be allowed and connection will fail. |
There are a number of changes that can be made to a cluster that might impact configuration, e.g.
-
adding a new Ambari component
-
adding an additional instance of a component
-
adding a new service using the Add Service wizard
These additions can result in unexpected configuration changes, based on installed components, available resources or configuration changes. Common changes might include (but are not limited to) changes to Heap setting or changes that impact security parameters, such as the proxyuser values.
Handling configuration changes
If any of the changes, listed in the previous section trigger a system change recommendation, there are two options:
-
A checkbox (selected by default) allowing you to say Ambari should apply the recommendation. You can uncheck this (or use the bulk uncheck at the top) for these.
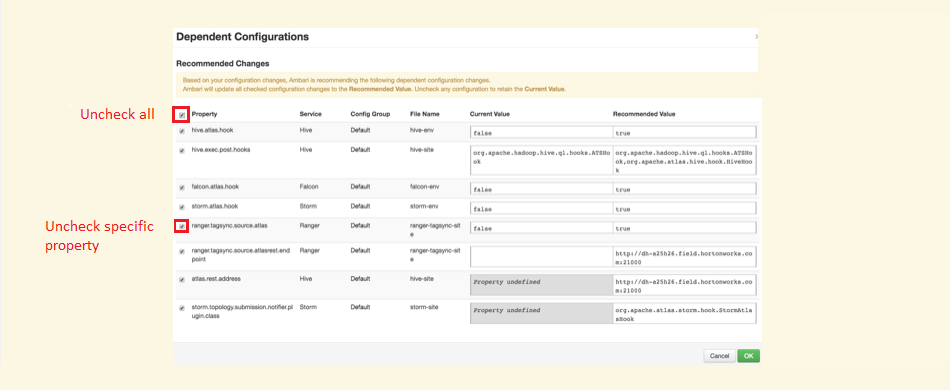 Figure 28. Stopping a system change from altering hadoop.proxyuser.hive.hosts
Figure 28. Stopping a system change from altering hadoop.proxyuser.hive.hosts -
Manually adjust the recommended value yourself, as you can specify additional properties that Ambari may not be aware of.
The Proxyuser property values should include hostnames for HiveServer2, Metastore hosts and Live Hive proxy. Accepting recommendations that do not contain this (or the alternative all encompassing wildcard *), will more than likely result in service loss for Hive.
5. Operation
This section covers the steps required for setting up and configuring Live Hive after installation has been completed.
5.1. Setting up Hive Metadata Replication
This section covers the essential steps required for replicating Hive metadata between zones.
Live Hive requires that you create two kinds of rules in order to replicate Hive metadata.
- HCFS Rule
-
Create a rule that matches the location of your underlying Hive data on the HDFS file-system. This rule handles the actual data replication, without it, a corresponding Hive rule will not work. See the Create a rule section in the WANdisco Fusion user guide for details.
|
Must have a consistent HCFS rule before creating a Hive rule
Before creating a Hive rule, the corresponding HCFS rule must be consistent.
See the Consistency Check and Make Consistent sections for more detail.
|
- Hive Rule
-
Create a rule that uses Hive’s pattern syntax to describe Hive databases and tables. This rule applies to any matching HCFS rule, contextualizing Hive metadata. See Create Hive rule.
5.1.1. Replication limitations
-
An alter table which changes the location of the table will not necessarily guarantee replication if the original directory was not replicated. Moving to a replicated directory does not cause replication. You will need to make the tables consistent for replication to occur.
-
Database descriptions will be replicated but they cannot be changed using the make consistent tool.
-
If using a Hortonworks set up, Hive does not support changes of database locations. This can however be done manually, see Hive: Changing Database Location for more information.
5.1.2. Create Hive rule
To replicate Hive metadata between zones, a Hive pattern-based rule must be created. This rule uses patterns from Hive’s own DDL (data definition language), which deals with schema(structure) and description, of how the data should reside in the Hive.
| For more information about Hive Patterns, used in creating replication rules, see Hive LanguageManual |
-
Go to the Fusion UI. Click on Replication tab and + Create.
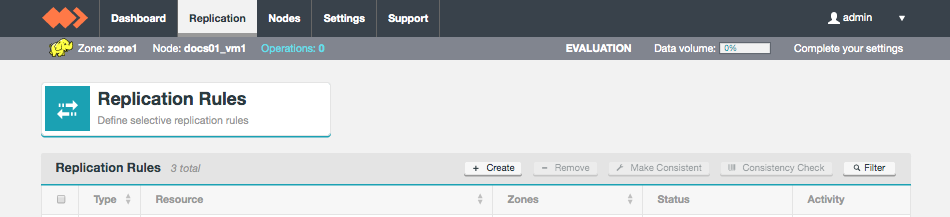 Figure 29. Live Hive - Create ruleNo Hive rule option?After Live Hive activation, if you don’t see the option to create Hive-based replication rules, ensure that you have refreshed your browser session.
Figure 29. Live Hive - Create ruleNo Hive rule option?After Live Hive activation, if you don’t see the option to create Hive-based replication rules, ensure that you have refreshed your browser session. -
From the Type dropdown, select Hive. Enter the criteria for the Hive pattern that will be used to identify which metadata will be replicated between nodes.
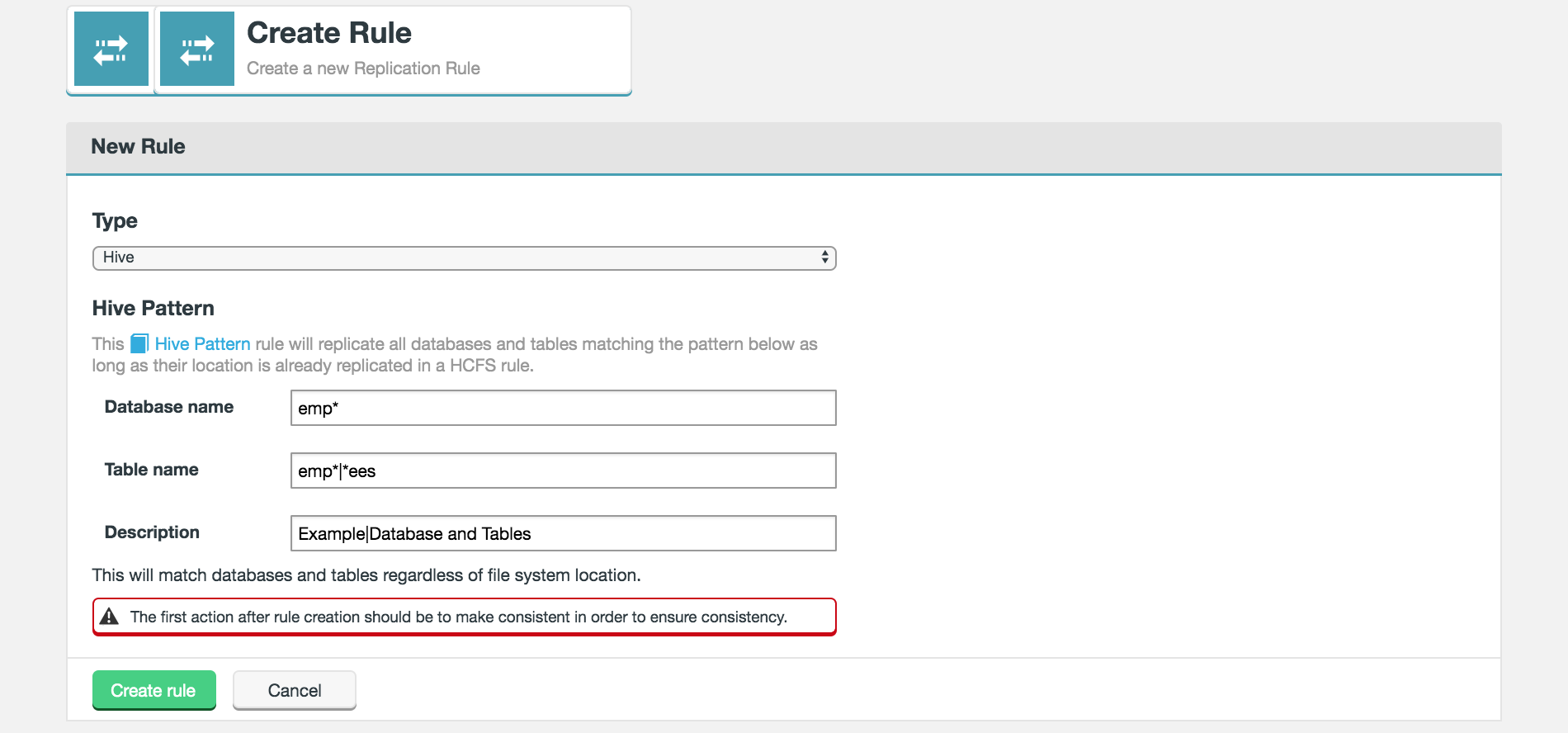 Figure 30. Live Hive - Create a rule
Figure 30. Live Hive - Create a ruleHive Pattern
Replication rules can be created to match Hive tables based on the same simple syntax used by Hive for pattern matching, rather than more complex regular expressions. Wildcards in replication rules can only be * for any character(s) or | for a choice.
| Examples: employees, emp*, emp*|*ees, all match a table named employees. The asterisk wildcard will select all words beginning with emp, and the pipe "|" will match all words that begin with emp or end with ees. |
- Database
-
Name of a Hive database.
- Table name
-
Name of a table in the above database.
- Description
-
A description that will help identify or distinguish the Hive-pattern replication rule.
Click Create to apply the rule.
-
Once created, Hive metadata that matches the Hive pattern will automatically have a replication rule created.
|
File system location is currently fixed
The File system location is locked to the wildcard .* This value ensures that the file system location is always found. In a future release the File system location will be opened up for the user to edit. |
5.1.3. Delete Hive Rule
You can delete unwanted Hive rules, through the Fusion web UI, using the following procedure.
-
Navigate to the Fusion UI. Click on the Replication Tab.
-
Click on the Rule that you want to delete.
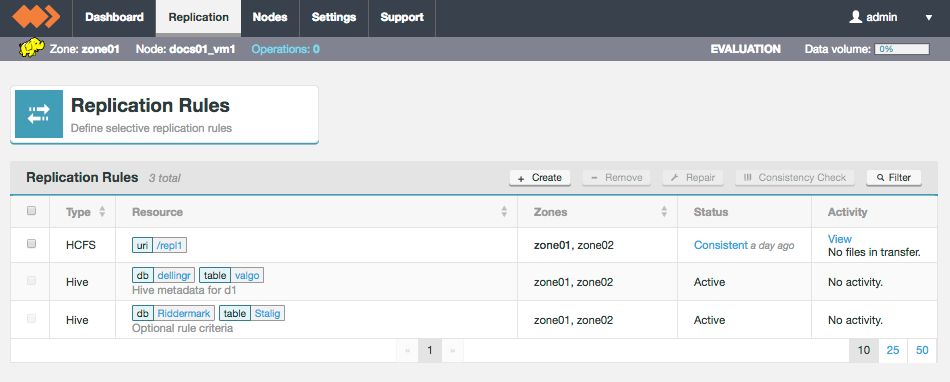 Figure 31. Live Hive - Delete rule
Figure 31. Live Hive - Delete rule -
Click on the Delete Rule button at the bottom of the panel.
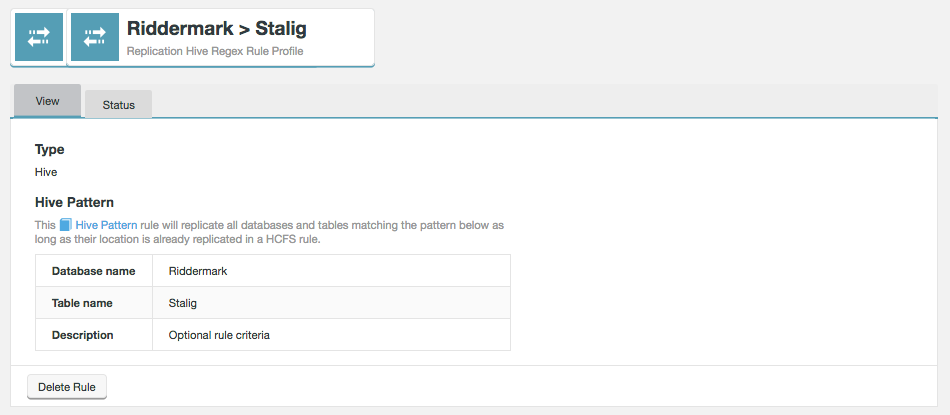 Figure 32. Live Hive - Delete rule
Figure 32. Live Hive - Delete rule -
A warning message "Are you sure you want to delete this rule? Metadata that matches this Hive Pattern rule will stop replicating after deletion. Click Confirm only if you are sure you wish to proceed.
 Figure 33. Live Hive - Delete rule
Figure 33. Live Hive - Delete rule -
The Replication screen will refresh. You can confirm that the deletion was successful if the rule no longer appears on the screen.
 Figure 34. Live Hive - Delete rule
Figure 34. Live Hive - Delete rule
5.1.4. Review Hive Rule
Review the status of existing Hive rules through the Replication tab of the Fusion UI.
-
Click on the Hive Rule that you wish to review.
 Figure 35. Live Hive - View rule
Figure 35. Live Hive - View rule -
The View screen of the selected Hive pattern will appear.
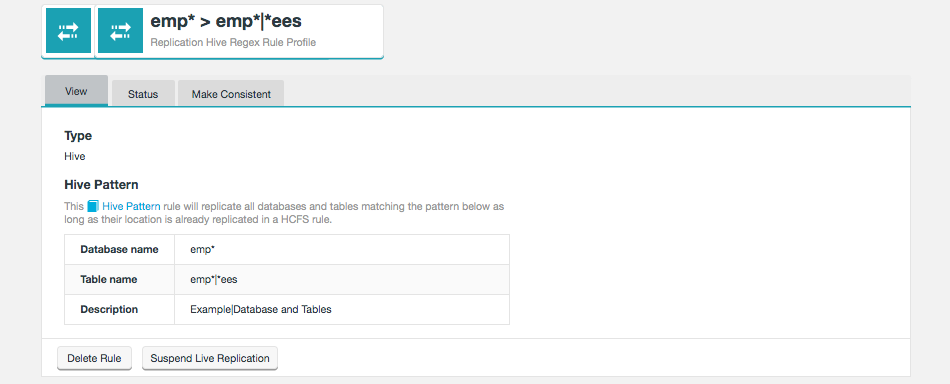
This Hive Pattern rule will replicate all databases and tables matching the pattern below as long as their location is already replicated in a HCFS rule.
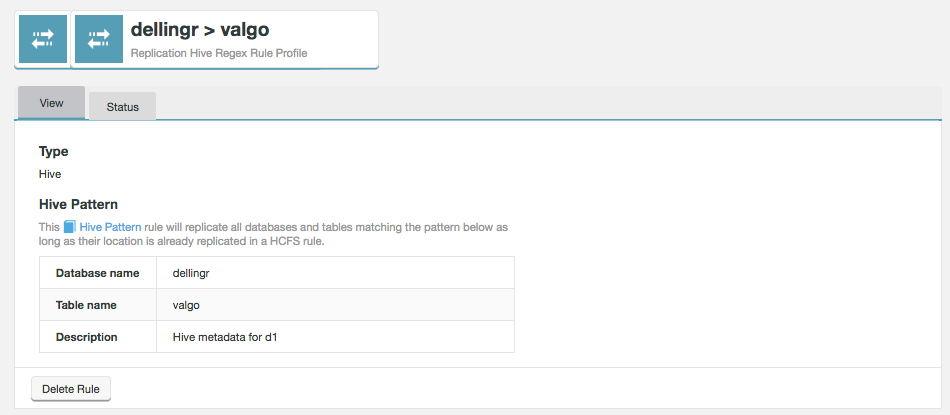 Figure 36. Live Hive - View rule
Figure 36. Live Hive - View rule- Database name
-
The name of the Hive database that is getting its Hive metadata replicated.
- Table name
-
A table within the above named Hive database for which Hive metadata is replicated.
- Description
-
A description of the rule that you provided during its creation to help identify what it does, later.
- Delete Rule
-
This button is used to remove the rule. For more details, see Delete Hive Rule.
-
Click on the Status tab.
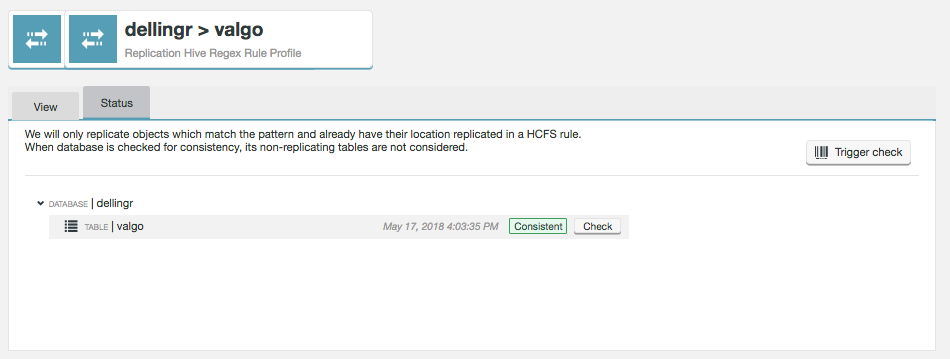 Figure 37. Live Hive - Rule status
Figure 37. Live Hive - Rule statusThe status provides an up-to-date view of the status of the metadata being replicated. All databases and tables are listed on the screen, along with their latest consistency check results.
We will only replicate objects which match the pattern and already have their location replicated in a HCFS rule. When database is checked for consistency, its non-replicating tables are not considered.
- Trigger check
-
This button triggers a rule-wide consistency check.
- Database name
-
A name of a Hive databases that will be matched the databases that exist in your Hive deployment.
- Table name
-
The name of a table that stored in the above database that you intend to replicate.
- File system location
-
The location of the data in the local file system.
|
File system location is currently fixed
The File system location is locked to the wildcard .* This value ensures that the file system location is always found. In a future release the File system location will be opened up for the user to edit. |
- Description
-
A description that you provide during the setup of the regex rule.
- Zones
-
A list of the zones that take part in the replication of this resource.
| It’s not currently possible to change the zones of an existing rule. |
5.1.5. Running a Consistency Check
Live Hive provides a tool for checking that replica metadata is consistent between zones.
|
When to complete a consistency check?
|
To complete a check:
-
Click on the Replication tab.
-
Click on the applicable Resource of the Replication Rule.
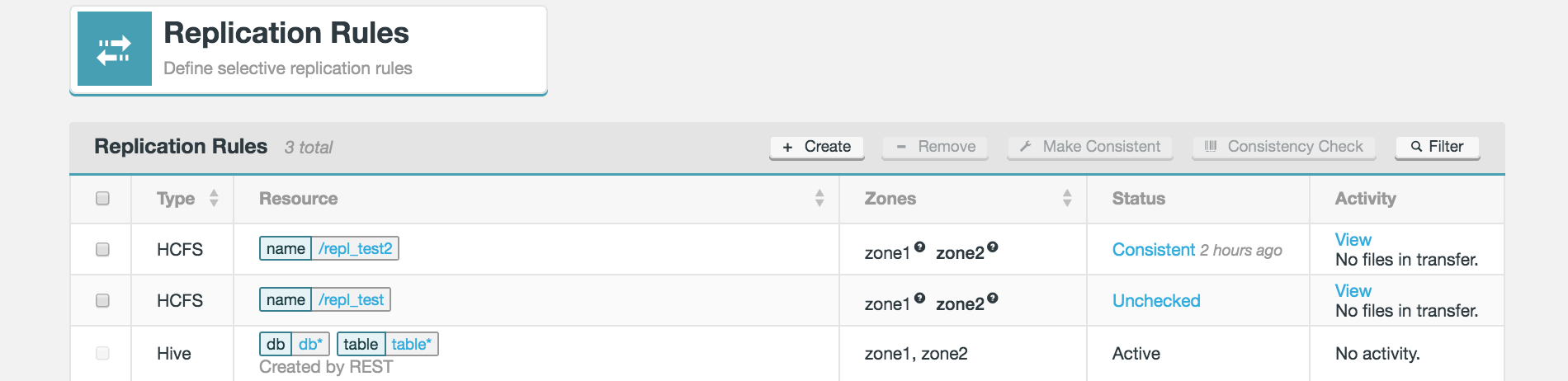 Figure 38. Live Hive - Select resource
Figure 38. Live Hive - Select resource -
On the Status tab you can trigger a consistency check of the whole rule, or more granularly.
-
Click Trigger check to run a consistency check on everything.
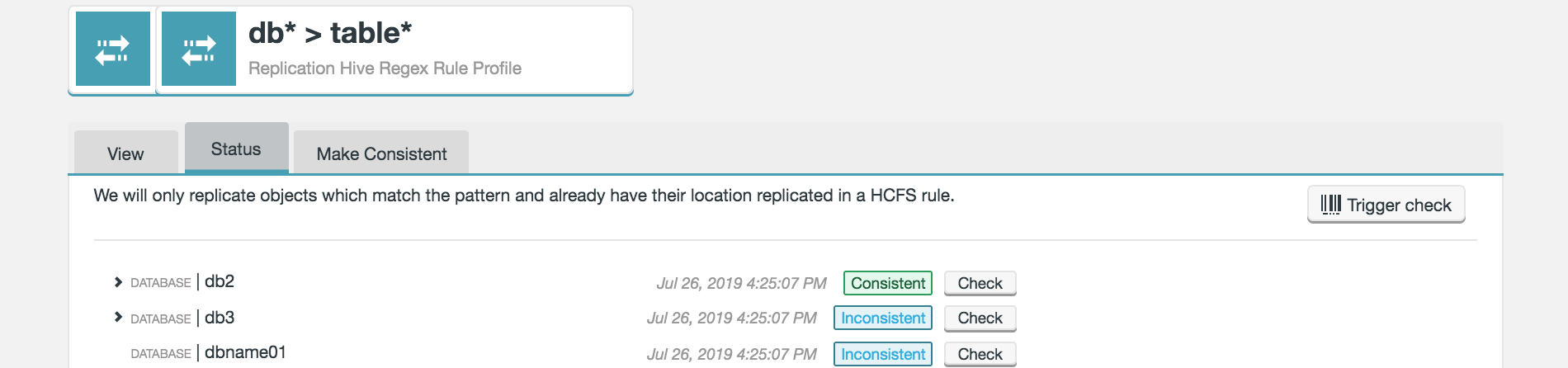 Figure 39. Live Hive - Trigger Consistency Check
Figure 39. Live Hive - Trigger Consistency Check -
Click Check at the end of the relevant row to run the consistency check on a specific table, for example.
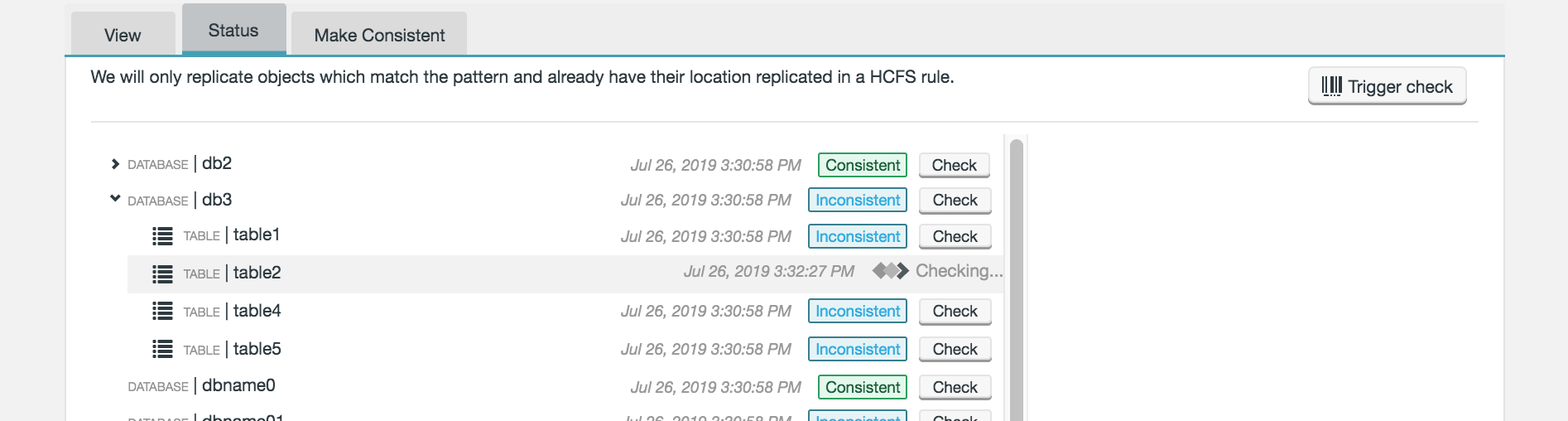 Figure 40. Live Hive - Trigger specific Consistency Check
Figure 40. Live Hive - Trigger specific Consistency Check
-
-
If the result is inconsistent, click on Inconsistent to use the Make Consistent tool. See the next section for details.
5.1.6. Make consistent
In the event that metadata is found to be inconsistent, you can use this tool to make the data consistent. The associated HCFS rule must be consistent before performing this operation.
-
Identify the nature of the inconsistency from the Detailed View panel. Select the zone that contains the correct version of the metadata, then select what actions you want the to take.
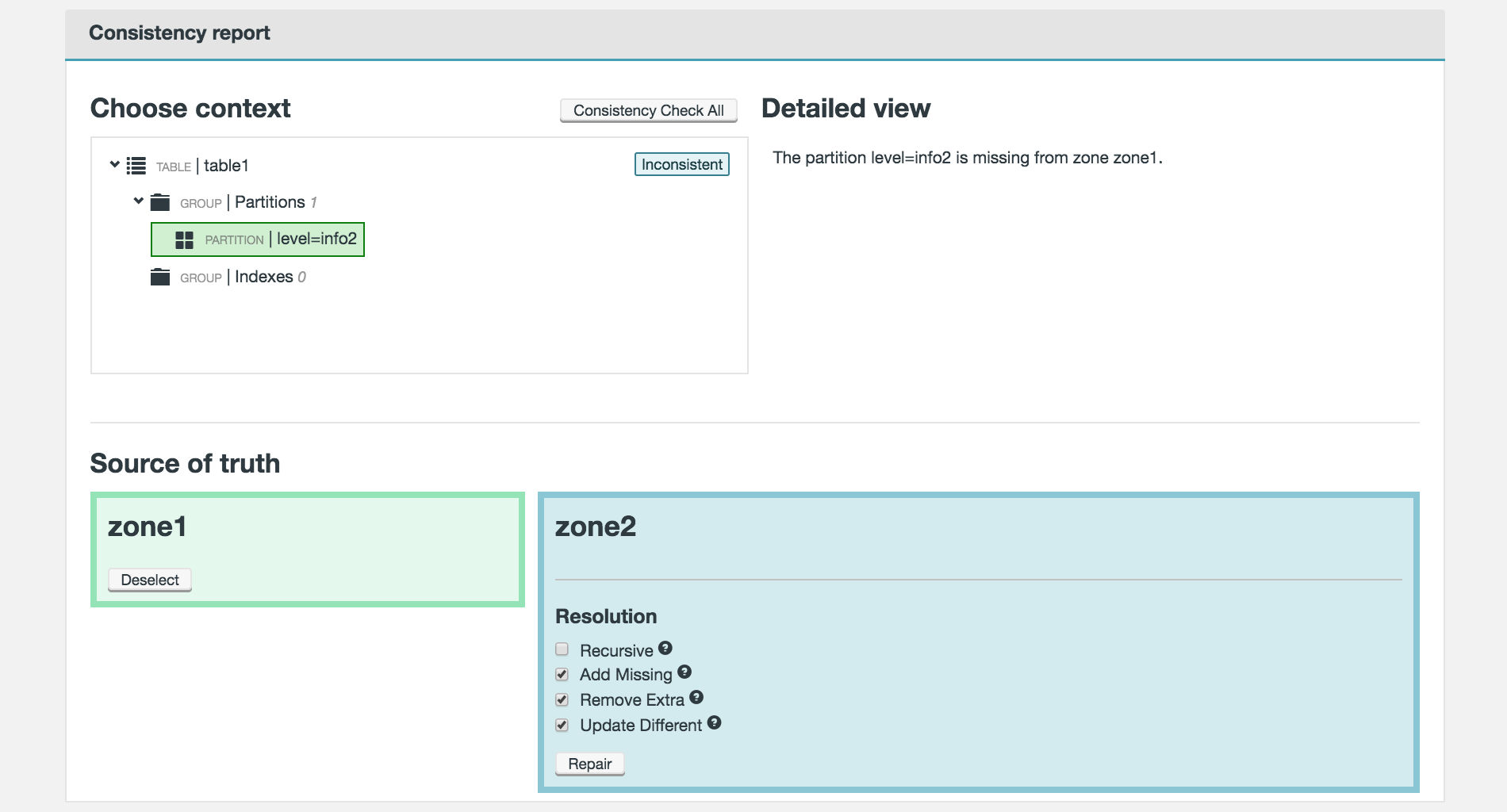 Figure 41. Live Hive - Make consistent
Figure 41. Live Hive - Make consistent- Recursive
-
If checkbox is ticked, this option will cause the selected context i.e database/table/index/partition and all the child objects under it to be made consistent. The default is true, but is ignored if the selected context represents an index or partition.
- Add Missing
-
Tick to create any database/table/index/partitions that are missing from a zone depending on the context selected.
- Remove Extra
-
Database/Tables/Index/Partitions that exist in the target zone will be removed if they do not exist in the zone selected as your source of truth. Parents of the selected context will never be removed. e.g if a table is selected then it’s parent database will not be removed even if it is missing from the source of truth.
- Update Different
-
Database/Tables/Index/Partitions that exist on both the source and target zones will be overwritten to match the source zone. Database/Tables/Index/Partitions that already exist on the target zone will not be modified if this option is left unchecked.
Now click Repair.
-
The status will now show as Unknown. To check if data has successfully been made consistent, re-run the consistency check and review the status.
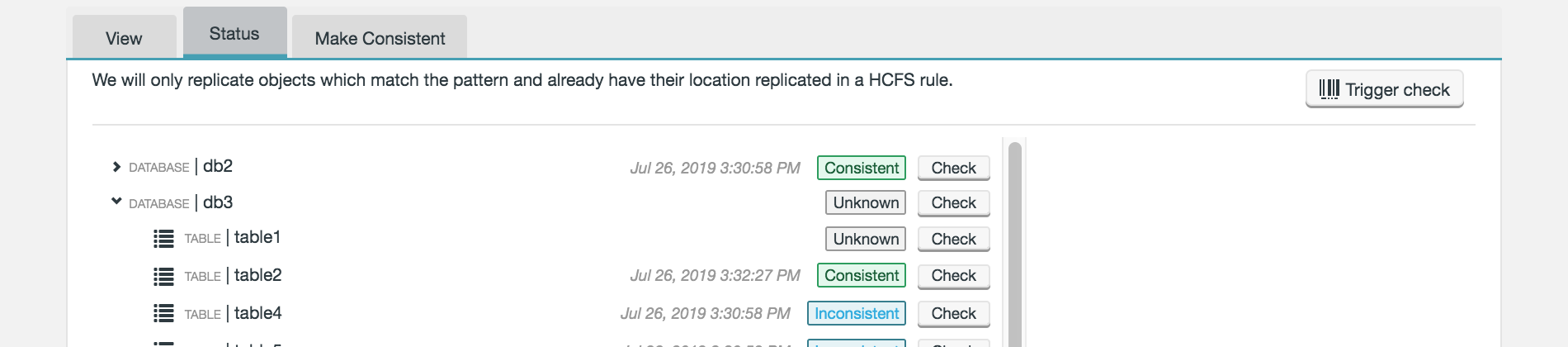 Figure 42. Live Hive - status
Figure 42. Live Hive - status
Note If you are making a table consistent and the source of truth’s partition keys are different, then the table cannot be made consistent with an ALTER TABLE command. The table therefore has to be dropped and re-created from the source of truth. This operation will also drop the table’s partitions and indices, as they are children of the table.
You can also use the Make Consistent tab to access this functionality.
5.2. Administration
5.2.1. Enable Hive transactions
By default, ACID / Hive transactions will be rejected by the Live Hive Proxy if the block.txn.services property is not explicitly set to false in the Live Hive configuration.
This property will not appear in the configuration by default.
If you do need to enable Hive transaction pass-through on replicated tables, the block.txn.services property must be added to the live-hive-site.xml and set to false.
Follow the steps below to achieve this depending on your environment.
| Don’t enable pass-through of Hive transactions when they are used on tables which are under replication as it will cause inconsistency in Hive data across zones. |
Via the Cloudera UI:
-
Go to the Live Hive Proxy → Live Hive Metastore Proxy Advanced Configuration Snippet (Safety Valve) for live-hive-site.xml.
-
Add the
block.txn.servicesproperty and set it tofalse. -
Save the configuration and restart the Live Hive service as directed by the Manager.
Via the Ambari UI:
-
Go to the Live Hive Proxy → Custom live-hive-site.
-
Add the
block.txn.servicesproperty and set it tofalse. -
Save the configuration and restart the Live Hive service as directed by the Manager.
5.2.2. Live Hive and NameNode Proxy compatibility
If WANdisco Fusion is configured to use the NameNode Proxy for data replication, then additional steps to maintain compatibility with Live Hive are required.
Both Live Hive Proxy and NameNode Proxy can receive and initiate replication of HCFS data, as such, it is necessary to configure Hive so that it ignores the NameNode Proxy’s HCFS write requests. Hive requests can be composed of data and metadata changes, and the Live Hive Proxy will handle both sets of changes.
If the requests are not bypassed by one of these components, then the Live Hive Proxy and NameNode Proxy will attempt to replicate the same sets of HCFS data.
Requirements for compatibility
-
HDFS must be configured with a nameservice, rather than the FQDN of a single namenode. This will be the default in HDFS environments where NameNode HA is enabled.
The compatibility steps require that the nameservice set for Hive Metastore is adjusted so that the underlying NameNodes are referenced rather than the NameNode Proxy(s).
-
NameNode Proxy must be installed and configured as a nameservice (see HDP or CDH links for guidance) rather than a single hostname and port (non-HA).
-
The NameNode Proxy nameservice must be the defined value for the
fs.defaultFSproperty in the HDFS config (see HDP or CDH links for guidance).Otherwise, you must ensure all applications will use the NameNode Proxy nameservice in their application specific configurations.
Configuration steps
This example uses the following variables:
NameNode Proxy nameservice = nnproxies
NameNode nameservice = nameservice01
NameNode 1 unique identifier = nn1
NameNode 2 unique identifier = nn2
-
Navigate to the HDFS configuration to add new entries that will overwrite the
hdfs-site.xml(see option a or b depending on platform).-
Ambari
HDFS → Configs → Advanced → Custom hdfs-site. -
Cloudera
HDFS → Configuration → HDFS Service Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml.
-
-
Create new properties so that the NameNode Proxy nameservice will contain references to the underlying NameNodes through their unique identifiers.
-
dfs.namenode.rpc-address.nnproxies.nn1=<nameservice01.namenode1’s rpc-address>:8020 -
dfs.namenode.rpc-address.nnproxies.nn2=<nameservice01.namenode2’s rpc-address>:8020Please note that the default NameNode RPC ports are shown above, adjust if your environment differs from these values.
-
-
Save the configuration after adding the new properties and restart designated services.
-
Navigate to the Hive Metastore configuration to add a property that will overwrite the
core-site.xml(see option a or b depending on platform).-
Ambari
Hive → Configs → Advanced → Custom hivemetastore-site. -
Cloudera
Hive → Configuration → Hive Metastore Server Advanced Configuration Snippet (Safety Valve) for core-site.xml.
-
-
Add a property that will point the Hive Metastore(s) to the NameNodes (rather than the NameNode Proxies) by setting
dfs.ha.namenodes.<nnproxies-nameservice>to reference the NameNodes' unique identifiers.-
Add the
dfs.ha.namenodes.nnproxies=nn1,nn2property. -
Ensure that the property has the Final option selected, so that the hdfs-site does not overwrite it.
-
Save the configuration changes.
-
-
Deploy the configuration and restart the Hive service.
The Hive Metastore(s) will now specifically be directed to the underlying NameNodes, whilst the rest of the cluster services will be directed to the NameNode Proxy(s).
5.2.3. Live Hive Bypass
Hive replication can be stopped at either a global or rule level. This is a similar to the WANdisco Fusion Manual Bypass for HCFS rules feature.
Bypass allows clients to bypass WANdisco Fusion and can be used for maintenance and troubleshooting. When bypass is enabled, consistency check and make consistent can still continue in both directions. Replication can also continue from the remote zone to the zone with the bypass in place.
Live Hive Global Bypass
The Global Bypass setting stops the replication of Hive metadata. To stop both Hive data and metadata, see Manual Bypass in the WANdisco Fusion user guide.
To enable Live Hive Global Bypass go to the Settings page → Live Hive → Plugin Bypass.
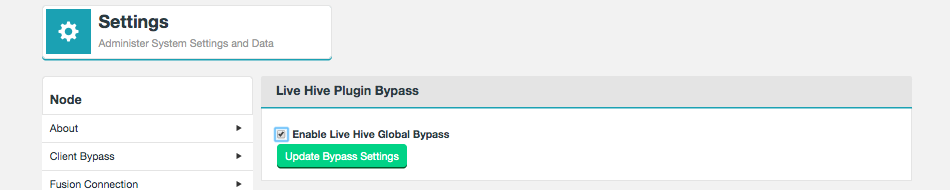
Suspend Live Replication
To suspend replication for specific rules go to the relevant rule page and click Suspend Live Replication.
Once suspended, the rule will have the warning This rule is currently not actively replicating. Hive requests matching this rule will not be automatically replicated.
5.2.4. Tuning
Certain properties useful for tuning Live Hive performance are defined in the Hadoop Hive configuration, not in Live Hive itself. Live Hive matches these directly and so performance issues maybe fixed by altering these values. For example:
-
hive.metastore.server.min.threads -
hive.metastore.server.max.threads -
hive.metastore.server.tcp.keepalive
5.3. Troubleshooting
The following tips should help you to understand any issues you might experience with Live Hive operation:
5.3.1. Check the Release notes
Make sure that you check the latest release notes, which may include references to known issues that could impact Live Hive.
5.3.2. Check log files
Observe information in the log files, generated for the WANdisco Fusion server and Live Hive to troubleshoot issues at runtime.
Exceptions or log entries with a SEVERE label may represent information that can assist in determining the cause of any problem.
As a distributed system, Live Hive will be impacted by the operation of the underlying Hive database with which it communicates. You may also find it useful to review log or other information from these endpoints.
Log Type |
Default Location |
Metastore |
/var/log/hive |
Live Hive Node |
/var/log/fusion/plugins/live-hive-proxy/ |
Hive Server |
/var/log/hive |
Change the timezone
You can ensure that logging between zones is consistent by making sure that logging is manually updated. By default, Logs use UTC timezone but this can be manually altered through log4j configuration.
To alter the timezone the xxx.layout.ConversionPattern property needs to be overwritten.
log4j.appender.stdout.layout.ConversionPattern=%d{ISO8601}{UTC} %p %c - %t:[%m]%n
{UTC} can be replaced with, for example {GMT} or {ITC+1:30}. If offsetting from a timezone, + or - can be used, hours must be between 0 and 23, and minutes must be between 00 and 59.
This property is located in several properties files. For an example set up these are listed below, but the exact paths may differ for your set up:
-
/var/log/fusion/plugins/live-hive-proxy/
-
/etc/wandisco/fusion/server/log4j.properties
-
/etc/wandisco/fusion/ihc/server/hdp-2.6.0/log4j.properties
-
/opt/wandisco/fusion-ui-server/lib/fusion_ui_log4j.xml
After updating all the relevant files, Live Hive needs to be restarted for the changes to take effect.
5.3.3. Consistency between zones.
We strongly recommend that you replicate between zones running with identical setups, with the same vendors and versions. Even modest differences in configuration may result in replication or consistency problems.
Metastore Schema incompatibility
While making Hive metadata consistent, it’s possible that you would see errors such as,
"INSERT INTO COLUMNS_V2 (CD_ID,COMMENT,"COLUMN_NAME",TYPE_NAME,INTEGER_IDX) VALUES (?,?,?,?,?)"
This may be caused by differences in the Hive Metastore schema in different zones. You should investigate and ensure that all zones have exactly the same Hive Metastore schema, if necessary, run with a custom schema.
Manager configuration
Cloudera
-
Login to Cloudera Manager.
-
In Live Hive Metastore Proxy Logging Advanced Configuration Snippet (Safety Valve) add where the timezone can be specified, i.e. GM+1, in the following example:
log4j.appender.RFA.layout=org.apache.log4j.EnhancedPatternLayout
log4j.appender.RFA.layout.ConversionPattern=%d{ISO8601}{GMT+1} %p %c - [%t]: %m%n
5.3.4. Connection issues
Any metastore connection issues will show in the logs, usually caused by an issue with SASL negotiation / delegation tokens. Start your investigation "from the outside, going inwards", i.e. first metastore, then proxy, then Hive server. It’s always worth trying a restart of the proxy/Fusion server before looking elsewhere.
5.3.5. Plugin initialization failure
Various errors that might occur have been shown to be caused by the Live Hive Plugin not starting properly.
This has the effect of blanking configuration and where there is no configuration available then fusion-server’s request for the property will fail. If there is any process removing old configs the this can cause a race condition as the proxy needs to come up before the fusion-server, or at least before plugin initialisation, to ensure that config is discoverable.
The plugin status may appear as "unknown" on the Plugins screen, under Settings.
6. Reference Guide
6.1. API
Fusion Plugin for Live Hive offers increased control and flexibility through a RESTful (REpresentational State Transfer) API.
Below are listed some example calls that you can use to guide the construction of your own scripts and API driven interactions.
|
API documentation is still in development:
Note that this API documentation continues to be developed. Contact our support team if you have any questions about the available implementation.
|
Note the following:
-
All calls use the base URI:
http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/
-
The internet media type of the data supported by the web service is application/xml.
-
The API is hypertext driven, using the following HTTP methods:
| Type | Action |
|---|---|
POST |
Create a resource on the server |
GET |
Retrieve a resource from the server |
PUT |
Modify the state of a resource |
DELETE |
Remove a resource |
6.1.1. Unsupported operations
As part of Fusion’s replication system, we capture and replicate some "write" operations to an underlying DistributedFileSystem/FileSystem API.
However, the truncate command is not currently supported.
Do not run this command as your Hive metadata will become inconsistent between clusters.
6.1.2. Example WADL output
The application.wadl provides further details on the API usage:
http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/application.wadl
Adding ?detail=true to the above will provide further details.
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<application xmlns="http://wadl.dev.java.net/2009/02">
<doc xmlns:jersey="http://jersey.java.net/" jersey:generatedBy="Jersey: 2.25.1 2017-01-19 16:23:50"/>
<doc xmlns:jersey="http://jersey.java.net/" jersey:hint="This is simplified WADL with user and core resources only. To get full WADL with extended resources use the query parameter detail. Link: http://livehive-host.com:8082/plugins/hive/application.wadl?detail=true"/>;
<grammars>
<include href="application.wadl/xsd0.xsd">
<doc title="Generated" xml:lang="en"/>
</include>
</grammars>
<resources base="http://livehive-host.com:8082/plugins/hive/">
<resource path="/">
<resource path="consistencyCheck">
<method id="startConsistencyCheck" name="POST">
<request>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="dbName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="tableName" style="query" type="xs:string" default=""/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="simpleCheck" style="query" type="xs:boolean" default="true"/>
</request>
<response>
<representation mediaType="/"/>
</response>
</method>
<resource path="{taskIdentity}">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="taskIdentity" style="template" type="xs:string"/>
<method id="getConsistencyCheckReport" name="GET">
<request>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="withDiffs" style="query" type="xs:boolean" default="false"/>
</request>
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
<resource path="{taskIdentity}/diffs">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="taskIdentity" style="template" type="xs:string"/>
<method id="getConsistencyReportPage" name="GET">
<request>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="pageSize" style="query" type="xs:int" default="2147483647"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="page" style="query" type="xs:int" default="0"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="dbName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="tableName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="partitions" style="query" type="xs:boolean" default="false"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="indexes" style="query" type="xs:boolean" default="false"/>
</request>
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
<resource path="{ruleIdentity}">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="ruleIdentity" style="template" type="xs:string"/>
<method id="startConsistencyCheckForRule" name="POST">
<request>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="dbName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="tableName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="simpleCheck" style="query" type="xs:boolean" default="true"/>
</request>
<response>
<representation mediaType="/"/>
</response>
</method>
</resource>
</resource>
<resource path="repair">
<resource path="{ruleIdentity}">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="ruleIdentity" style="template" type="xs:string"/>
<method id="repair" name="PUT">
<request>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="truthZone" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="dbName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="tableName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="partName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="indexName" style="query" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="recursive" style="query" type="xs:boolean" default="true"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="addMissing" style="query" type="xs:boolean" default="true"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="removeExtra" style="query" type="xs:boolean" default="true"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="updateDifferent" style="query" type="xs:boolean" default="true"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="simpleCheck" style="query" type="xs:boolean" default="true"/>
</request>
<response>
<representation mediaType="/"/>
</response>
</method>
</resource>
</resource>
<resource path="hiveRegex">
<method id="getReplicationRules" name="GET">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
<resource path="{id}">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="id" style="template" type="xs:string"/>
<method id="getReplicationRuleById" name="GET">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
<method id="deleteReplicationRuleById" name="DELETE">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
<resource path="addHiveRule">
<method id="addReplicationRule" name="PUT">
<request>
<ns2:representation xmlns:ns2="http://wadl.dev.java.net/2009/02" xmlns="" element="hiveRule" mediaType="application/xml"/>
<ns2:representation xmlns:ns2="http://wadl.dev.java.net/2009/02" xmlns="" element="hiveRule" mediaType="application/json"/>
</request>
<response>
<representation mediaType="/"/>
</response>
</method>
</resource>
<resource path="active">
<method id="getActiveRules" name="GET">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
</resource>
<resource path="hiveReplicatedDirectories">
<method id="getReplicationRules" name="GET">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
<resource path="{regexRuleId}">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="regexRuleId" style="template" type="xs:string"/>
<method id="getReplicationRuleById" name="GET">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
<resource path="path">
<method id="getReplicationRuleByPath" name="GET">
<request>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="path" style="query" type="xs:string"/>
</request>
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
</resource>
<resource path="hiveMetastore">
<resource path="{ruleId}/{databaseName}/tables/{tableName}">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="databaseName" style="template" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="ruleId" style="template" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="tableName" style="template" type="xs:string"/>
<method id="getTable" name="GET">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
<resource path="{ruleId}/databases">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="ruleId" style="template" type="xs:string"/>
<method id="getDatabases" name="GET">
<request>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="databaseFilter" style="query" type="xs:string"/>
</request>
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
<resource path="{ruleId}/databases/{databaseName}">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="databaseName" style="template" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="ruleId" style="template" type="xs:string"/>
<method id="getDatabase" name="GET">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
<resource path="{ruleId}/{databaseName}/tables">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="databaseName" style="template" type="xs:string"/>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="ruleId" style="template" type="xs:string"/>
<method id="getTables" name="GET">
<request>
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="tableFilter" style="query" type="xs:string"/>
</request>
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
<resource path="{ruleId}/summary">
<param xmlns:xs="http://www.w3.org/2001/XMLSchema" name="ruleId" style="template" type="xs:string"/>
<method id="getRuleSummary" name="GET">
<response>
<representation mediaType="application/xml"/>
<representation mediaType="application/json"/>
</response>
</method>
</resource>
</resource>
</resource>
</resources>
</application>6.1.3. Example REST calls
The following examples illustrate some simple use cases, most are direct calls through a web browser, although for deeper or interactive examples, a curl client may be used.
Optional query params
?dbName= &tableName= &path=
GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/hiveRegex/{hiveRegexRuleId} > returns a HiveReplicationRuleDTO >
@XmlRootElement(name = "hiveRule")
@XmlType(propOrder =
Permitted value
-
private String dbNamePattern = "";
-
private String tableNamePattern = "";
-
private String tableLocationPattern = "";
-
private String membershipIdentity = "";
-
private String ruleIdentity;
-
private String description = "";
List Hive Replication Rule DTO
GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/hiveRegex/ > HiveReplicationRulesListDTO
-
(all known rules) list of HiveReplicationRuleDTO (see below for format)
PUT http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/hiveRegex/addHiveRule/ PAYLOAD HiveReplicationRuleDTO >
{dbNamePattern:'mbdb.*', tableNamePattern:'tabl.*', tableLocationPattern:'.*', membershipIdentity:'824ce758-641c-46d6-9c7d-d2257496734d', ruleIdentity:'6a61c98b-eaea-4275-bf81-0f82b4adaaef', description:'mydbrule'}
GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/hiveRegex/active/ >
-
Returns HiveReplicationRulesListDTO of all ACTIVE hiveRegex rules
GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/hiveReplicatedDirectories > HiveReplicatedDirectoresDTOList<HiveReplicatedDirectoryDTO> :
-
Will get all HCFS replicated directories that were created via a Hive pattern rule automatically upon table creation. Returns JSON in format:
{"hiveReplicatedDirectoryDTOList":[{"rd":"ReplicatedDirectoryDTO","propertiesDTO":{"properties":"Map<String, String>"},"consistencyTaskId":"str","consistencyStatus":"str","lastConsistencyCheck":0,"consistencyPending":true}]}
GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/hiveReplicatedDirectories/{regexRuleId} >
-
Returns same as above but returns only directories created via a given regex Rule Id as a path parameter.
GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/hiveReplicatedDirectories/path?path=/some/location >
-
Returns same as above again but this time with query param of the path of the HCFS location.
Consistency Checks
Perform a consistency check on the database specified. The response will contain the location of the Platform task that is coordinating the consistency check. This task will exist on all nodes in the membership and at completion each task will be in the same state. The {@code taskIdentity} can be used to view the consistency check report using the {@code /hive/consistencyCheck/{taskIdentity} API.
<rule-ID> is needed in some of the following commands, it can be found by viewing the rule in the Fusion UI, or use GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/hiveRegex for a list of all Hive rules.
Start a Consistency Check on a particular Hive Database and Table
POST http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/consistencyCheck/<rule-ID>?dbName=<db Name>&tableName=<table Name>
-
tableName,dbNameandsimpleCheckare optional query parameters and if omitted will default totableName="",dbName=""andsimpleCheck=true
Get the Consistency Check report for a Consistency Check task previously requested by the API above
GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/consistencyCheck/{taskid}?withDiffs=true
-
The
withDiffsquery parameter is optional and defaults to false if not supplied.
Get part of the consistency check report depending on the query parameters set
GET http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/consistencyCheck/{taskId}/diffs?pageSize=10&page=0&dbName=test_db&tableName=test_table&partitions=true&indexes=true
-
Returns part of the diff from the consistency check. The hierarchy is: dbName / tableName / one of [partitions=true or indexes=true].
- dbname
-
Name of the database to check.
- tableName
-
Name of the database table to check, the default of " " will check all tables. If specified then either partitions or indexes must be specified.
- pageSize
-
Optional. Will default to pageSize = 2,147,483,647
- page
-
Optional. Will default to page=0.
Repair
Start to repair the specified database and table.
PUT http(s)://<FUSION-HOSTNAME>:8082/plugins/hive/repair/<rule-ID>?truthZone=zone1&dbName=test_db&tableName=test_table&partName=testPart&indexName=test_index]&recursive=true&addMissing=true&removeExtra=true&updateDifferent=true&simpleCheck=true
- truthZone (required)
-
Zone which is the source of truth.
- dbName (required)
-
Database to repair in. Note, this database has to exist on zone where this API call is done.
- tableName (optional)
- partName (optional)
- indexName (optional)
- recursive (optional)
-
Defaults to false.
- addMissing (optional)
-
Defaults to true. If true, the objects, which are missing will be created.
- removeExtra (optional)
-
Defaults to true. If true, the objects, which don’t exist in truthZone will be removed.
- updateDifferent (optional)
-
Defaults to true. If true, the objects which are different will be fixed.
- simpleCheck (optional)
-
Defaults to true. If true then the repair operation will only involve a simple check and not include any extended parameters of the objects being repaired.