6. Reference Guide
The reference guide walks through WD Fusion's various screens, providing a basic explanation of what everything does. For specific instruction on how to perform a particular task, you should view the Admin Guide
Technical Overview
What is WANdisco Fusion
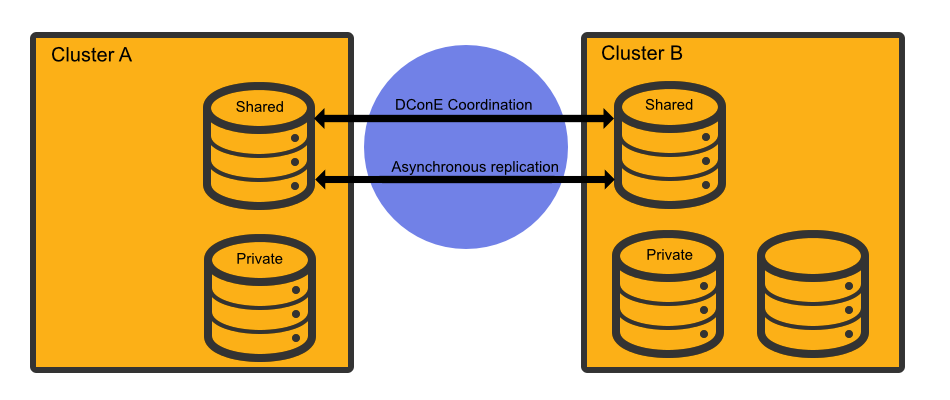
WANdisco Fusion (WD Fusion) shares data between two or more clusters. Shared data is replicated between clusters using DConE, WANdisco's proprietory coordination engine. This isn't a spin on mirroring data, every cluster can write into the shared data directories and the resulting changes are coordinated in real-time between clusters.
100% Reliablity
Paxos-based algorythms enable DConE to continue replicate even during brief networks outages. Data changes will automatically catch up once connectivity between clusters is restored.
Below the coordination stream, actual data transfer is done as an asynchronous background process and doesn't consume MapReduce resources.
Replication where and when you need
WD Fusion supports Selective replication, where you control which data is replicated to particular clusters, based on your security or data management policies. Data can be replicated globally if data is available to every cluster or just one cluster.
The Benefits of WANdisco Fusion
- Ingest data to any cluster, sharing it quickly and reliably with other clusters. Removing fragile data transfer bottlenecks, and letting you process data at multiple places improving performance and getting you more utilization from backup clusters.
- Support a bimodal or multimodal architecture to enable innovation without jeopardizing SLAs. Perform different stages of the processing pipeline on the best cluster. Need a dedicated high-memory cluster for in-memory analytics? Or want to take advantage of an elastic scale-out on a cheaper cloud environment? Got a legacy application that's locked to a specific version of Hadoop? WANdisco Fusion has the connections to make it happen. And unlike batch data transfer tools, WANdisco Fusion provides fully consistent data that can be read and written from any site.
- Put away the emergency pager. If you lose data on one cluster, or even an entire cluster, WANdisco Fusion has made sure that you have consistent copies of the data at other locations.
- Set up security tiers to isolate sensitive data on secure clusters, or keep data local to its country of origin.
- Perform risk-free migrations. Stand up a new cluster and seamlessly share data using WANdisco Fusion. Then migrate applications and users at your leisure, and retire the old cluster whenever you're ready.
6.2 A Primer on Paxos
Replication networks are composed of a number of nodes, each node takes on one of a number of roles:
Acceptors (A)
The Acceptors act as the gatekeepers for state change and are collected into groups called Quorums. For any proposal to be accepted, it must be sent to a Quorum of Acceptors. Any proposal received from an Acceptor node will be ignored unless it is received from each Acceptor in the Quorum.
Proposers (P)
Proposer nodes are responsible for proposing changes, via client requests, and aims to receive agreement from a majority of Acceptors.
Learners (L)
Learners handle the actual work of replication. Once a Client request has been agreed on by a Quorum the Learner may take the action, such as executing a request and sending a response to the client. Adding more learner will improve availability for the processing.
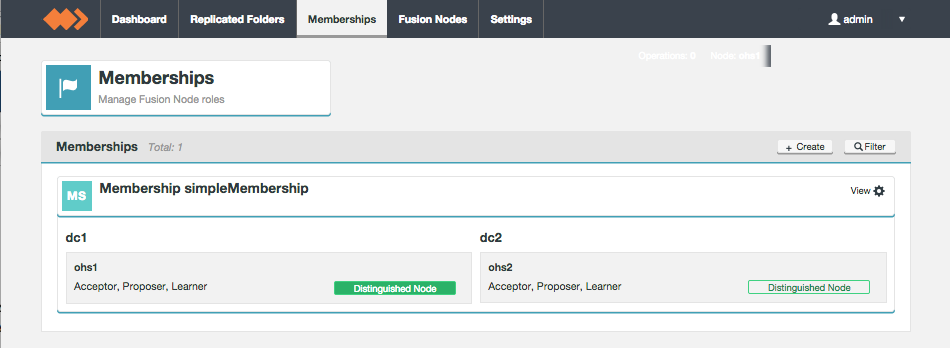
Distinguished Node
It's common for a Quorum to be a majority of participating Acceptors. However, if there's an even number of nodes within a Quorum this introduces a problem: the possibility that a vote may tie. To handle this scenario a special type of Acceptor is available, called a Distinguished Node. This machine gets a slightly larger vote so that it can break 50/50 ties.
6.3 Paxos Node Roles in DConE
When setting up your WD Fusion servers they'll all be Acceptors,Proposers and Learners. In a future version of the product you'll then be able to modify each WD Fusion server's role to balance between resilience and performance, or to remove any risk of a tied vote.
Creating resilient Memberships
WD Fusion is able to maintain HDFS filesystem replication even after the loss of WD Fusion nodes from a cluster. However, there are some configuration rules that are worth considering:
Rule 1: Understand Learners and Acceptors
The unique Active-Active replication technology used by WD Fusion is an evolution of the Paxos algorithm, as such we use some Paxos concepts which are useful to understand:
Learners:
Learners are the nodes that are involved in the actual replication of Namespace data. When changes are made to HDFS metadata these Namenodes raise a proposal for the changes to be made on all the other copies of the filesystem space on the other data centers running WD Fusion within the membership.Learner Nodes are required for the actual storage and replication of hdfs data. You need a learner node where ever you need to store a copy of the shared hdfs data.
-
Acceptors:
All changes being made in the replicated space at each data center must be made in exactly the same order. This is a crucial requirement for maintaining synchronization. Acceptors are nodes that take part in the vote for the order in which proposals are played out.
Acceptor Nodes are required for keeping replication going. You need enough Acceptors to ensure that agreement over proposal ordering can always be met, even after accounting for possible node loss. For configurations where there are a an even number of Acceptors it is possible that voting could become tied. For this reason it is possible to make an Acceptor node into a tie-breaker which has slightly more voting power so that it can outvote another single Acceptor node.
Rule 2: Replication groups should have a minimum membership of three learner nodes
Two-node clusters (running two WD Fusion servers) are not fault tolerant, you should strive to replicate according to the following guideline:
The number of learner nodes required to survive population loss of N nodes = 2N+1
where N is your number of nodes.So in order to survive the loss of a single WD Fusion server equipped datacenter you need to have a minium of 2x1+1= 3 nodes
In order to keep on replicating after losing a second node you need 5 nodes.
Rule 3: Learner Population - resilience vs rightness
During the installation of each of your nodes you can configure the Content Node Count number, this is the number of other learner nodes in the replication group that need to receive the content for a proposal before the proposal can be submitted for agreement.
Setting this number to 1 ensures that replication won't halt if some nodes are behind and have not received replicated content yet. This strategy reduces the chance that a temporary outage or heavily loaded node will stop replication, however, it also increases the risk that namenode data will go out of sync (requiring admin-intervention) in the event of an outage.
Rule 4: 2 nodes per site provides resilience and performance benefits
Running with two nodes per site provides two important advantages.
- Firstly it provides every site with a local hot-backup of the namenode data.
- Enables a site to load-balance namenode access between the nodes which can improve performance during times of heavy usage.
- Providing the nodes are Acceptors, it increases the population of nodes that can form agreement and improves resilience for replication.
WD Fusion Configuration
This section lists the available configuration for WD Fusion's component applications. You should take care making any configuration changes on your clusters.
WD Fusion Server
WD Fusion server configuration is stored in two files:/opt/fusion-server/application.properties| Property | Description | Permitted Values | Default | Checked at... |
| application.port | The port DConE uses for communication. | 1-65535 | 6444 | Startup |
| data.center | The zone where the Fusion server is located. | Any String | None - must be present | Startup |
| database.location | The directory DConE will use for persistence. | Any existing path | None - must be present | Startup |
| executor.threads | The number of threads executing agreements in parallel. | 1-Integer.MAX_VALUE | 20 | Startup |
| fusion.decoupler | The decoupler the Fusion server will use. | dcone, disruptor, simple | dcone | Startup |
| disruptor.wait.strategy | The wait strategy to use when the disruptor is selected for fusion.decoupler. | blocking, busy.spin, lite.blocking, sleeping, yielding | yielding | Startup |
| jetty.http.port | The port the Fusion HTTP server will use. | 1-65535 | 8082 | Startup |
| request.port | The port Fusion clients will use. | 1-65535 | None - must be present | Startup |
| transport | The transport the Fusion server should use. | OIO, NIO, EPOLL | NIO | Startup |
| transfer.chunk.size | The size of the "chunks" used in a file transfer. Used as input to Netty's ChunkedStream. | 1 - Integer.MAX_VALUE | 4096kb | When each pull is initiated |
/opt/fusion-server/core-site.xml
To be confirmed
IHC Server
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://cert01-vm0.devnuc02.wandisco.com:8020/</value>
<final>true</final>
</property>
<property>
<name>fs.fusion.impl</name>
<value>com.wandisco.fs.client.FusionFs</value>
</property>
<property>
<name>fs.fusion.server</name>
<value>cert01-vm1.devnuc02.wandisco.com:8023</value>
</property>
</configuration>
WD Fusion Client
Client configuration is handled in
/etc/hadoop/conf/core-site.xml
| Property | Description | Permitted Values | Default | Checked at... |
| fs.fusion.impl | The FileSystem implementation to be used. | com.wandisco.fs.client.FusionFs | None - must be present | Startup |
| fs.AbstractFileSystem.fusion.impl | The Abstract FileSystem implementation to be used. | com.wandisco.fs.client.FusionAbstractFs | None - must be present | Startup |
| fs.fusion.server | The hostname and request port of the Fusion server. | String:[1 - 65535] | None - must be present | Startup |
| fs.fusion.transport | The transport the FsClient should use. | OIO, NIO, EPOLL | NIO | Startup |
| fs.fusion.ssl.enabled | If Client-WD Fusion server communications use SSL encryption. | true, false | false | Startup |
| fusion.underlyingFs | The address of the underlying filesystem | Often this is the same as the fs.defaultFS property of the underlying hadoop. However, in cases like EMRFS, the fs.defaultFS points to a local HDFS built on the instance storage which is temporary, with persistent data being stored in S3. Our customers are likely to use the S3 storage as the fusion.underlyingFs | None - must be present | Startup |
IHC Server
The Inter-Hadoop Communication Server is configured from a single file located at:
/etc/wandisco/ihc/{distro}.ihc.
| Property | Description | Permitted Values | Default | Checked at... |
| ihc.server | The hostname and port the IHC server will listen on. | String:[1 - 65535] | None - must be present | Startup |
| ihc.transport | The transport the IHC server should use. | OIO, NIO, EPOLL | NIO | Startup |
| ihc.ssl.enabled | Signifies that WD Fusion server - IHC communications should use SSL encryption. | true, false | false | Startup |
| http.server | The hostname and port the IHC HTTP server will listen on. | String:[1 - 65535] | None - must be present | Startup |
WD Fusion UI Reference Guide
Installation directories
WD Fusion Server
Default installation directory:
/opt/fusion-server
The server directory contains the following subdirectories:
-rw-r--r-- 1 hdfs hdfs 62983 Mar 30 21:09 activation-1.1.jar
-rw-r--r-- 1 hdfs hdfs 44925 Mar 30 21:09 apacheds-i18n-2.0.0-M15.jar
-rw-r--r-- 1 hdfs hdfs 691479 Mar 30 21:09 apacheds-kerberos-codec-2.0.0-M15.jar
-rw-r--r-- 1 hdfs hdfs 16560 Mar 30 21:09 api-asn1-api-1.0.0-M20.jar
-rw-r--r-- 1 hdfs hdfs 79912 Mar 30 21:09 api-util-1.0.0-M20.jar
-rw-r--r-- 1 hdfs hdfs 314 Apr 1 17:21 application.properties
-rw-r--r-- 1 hdfs hdfs 43033 Mar 30 21:09 asm-3.1.jar
-rw-r--r-- 1 hdfs hdfs 436561 Mar 30 21:09 avro-1.7.6-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 94463 Mar 30 21:09 bcmail-jdk14-1.48.jar
-rw-r--r-- 1 hdfs hdfs 590499 Mar 30 21:09 bcpkix-jdk14-1.48.jar
-rw-r--r-- 1 hdfs hdfs 2319441 Mar 30 21:09 bcprov-jdk14-1.48.jar
-rw-r--r-- 1 hdfs hdfs 188671 Mar 30 21:09 commons-beanutils-1.7.0.jar
-rw-r--r-- 1 hdfs hdfs 206035 Mar 30 21:09 commons-beanutils-core-1.8.0.jar
-rw-r--r-- 1 hdfs hdfs 41123 Mar 30 21:09 commons-cli-1.2.jar
-rw-r--r-- 1 hdfs hdfs 58160 Mar 30 21:09 commons-codec-1.4.jar
-rw-r--r-- 1 hdfs hdfs 575389 Mar 30 21:09 commons-collections-3.2.1.jar
-rw-r--r-- 1 hdfs hdfs 241367 Mar 30 21:09 commons-compress-1.4.1.jar
-rw-r--r-- 1 hdfs hdfs 298829 Mar 30 21:09 commons-configuration-1.6.jar
-rw-r--r-- 1 hdfs hdfs 24239 Mar 30 21:09 commons-daemon-1.0.13.jar
-rw-r--r-- 1 hdfs hdfs 143602 Mar 30 21:09 commons-digester-1.8.jar
-rw-r--r-- 1 hdfs hdfs 112341 Mar 30 21:09 commons-el-1.0.jar
-rw-r--r-- 1 hdfs hdfs 305001 Mar 30 21:09 commons-httpclient-3.1.jar
-rw-r--r-- 1 hdfs hdfs 185140 Mar 30 21:09 commons-io-2.4.jar
-rw-r--r-- 1 hdfs hdfs 284220 Mar 30 21:09 commons-lang-2.6.jar
-rw-r--r-- 1 hdfs hdfs 62050 Mar 30 21:09 commons-logging-1.1.3.jar
-rw-r--r-- 1 hdfs hdfs 1599627 Mar 30 21:09 commons-math3-3.1.1.jar
-rw-r--r-- 1 hdfs hdfs 273370 Mar 30 21:09 commons-net-3.1.jar
-rw-r--r-- 1 hdfs hdfs 417 Apr 1 17:21 core-site.xml
-rw-r--r-- 1 hdfs hdfs 68866 Mar 30 21:09 curator-client-2.6.0.jar
-rw-r--r-- 1 hdfs hdfs 185245 Mar 30 21:09 curator-framework-2.6.0.jar
-rw-r--r-- 1 hdfs hdfs 248171 Mar 30 21:09 curator-recipes-2.6.0.jar
drwxr-xr-x 1 hdfs hdfs 4 Apr 1 17:21 dcone
-rw-r--r-- 1 hdfs hdfs 504946 Mar 30 21:09 DConE-1.3.0-rc6.jar
-rw-r--r-- 1 hdfs hdfs 897053 Mar 30 21:09 DConE_Platform-1.3.0-rc5.jar
-rw-r--r-- 1 hdfs hdfs 79474 Mar 30 21:09 disruptor-3.3.2.jar
-rw-r--r-- 1 hdfs hdfs 19167 Mar 30 21:09 enunciate-core-annotations-1.29.jar
-rw-r--r-- 1 hdfs hdfs 22659 Mar 30 21:09 enunciate-core-rt-1.29.jar
-rw-r--r-- 1 hdfs hdfs 25653 Mar 30 21:09 enunciate-jersey-rt-1.29.jar
-rw-r--r-- 1 hdfs hdfs 48238 Mar 30 21:09 fusion-common-2.0.2-SNAPSHOT-cdh-5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 7129 Mar 30 21:09 fusion-ihc-client-2.0.2-SNAPSHOT-cdh-5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 11573 Mar 30 21:09 fusion-ihc-common-2.0.2-SNAPSHOT-cdh-5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 12486 Mar 30 21:09 fusion-netty-2.0.2-SNAPSHOT.jar
-rw-r--r-- 1 hdfs hdfs 239075 Mar 30 21:09 fusion-server-2.0.2-SNAPSHOT.jar
-rw-r--r-- 1 hdfs hdfs 190432 Mar 30 21:09 gson-2.2.4.jar
-rw-r--r-- 1 hdfs hdfs 1648200 Mar 30 21:09 guava-11.0.2.jar
-rw-r--r-- 1 hdfs hdfs 21575 Mar 30 21:09 hadoop-annotations-2.5.0-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 73096 Mar 30 21:09 hadoop-auth-2.5.0-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 3151457 Mar 30 21:09 hadoop-common-2.5.0-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 7689502 Mar 30 21:09 hadoop-hdfs-2.5.0-cdh5.3.0.jar
-rw-r--r-- 1 hdfs hdfs 352254 Mar 30 21:09 httpclient-4.1.2.jar
-rw-r--r-- 1 hdfs hdfs 181200 Mar 30 21:09 httpcore-4.1.2.jar
-rw-r--r-- 1 hdfs hdfs 227517 Mar 30 21:09 jackson-core-asl-1.8.8.jar
-rw-r--r-- 1 hdfs hdfs 17883 Mar 30 21:09 jackson-jaxrs-1.8.3.jar
-rw-r--r-- 1 hdfs hdfs 669065 Mar 30 21:09 jackson-mapper-asl-1.8.8.jar
-rw-r--r-- 1 hdfs hdfs 32319 Mar 30 21:09 jackson-xc-1.8.3.jar
-rw-r--r-- 1 hdfs hdfs 38940 Mar 30 21:09 java-uuid-generator-3.1.3.jar
-rw-r--r-- 1 hdfs hdfs 18490 Mar 30 21:09 java-xmlbuilder-0.4.jar
-rw-r--r-- 1 hdfs hdfs 105134 Mar 30 21:09 jaxb-api-2.2.2.jar
-rw-r--r-- 1 hdfs hdfs 890168 Mar 30 21:09 jaxb-impl-2.2.3-1.jar
-rw-r--r-- 1 hdfs hdfs 458739 Mar 30 21:09 jersey-core-1.9.jar
-rw-r--r-- 1 hdfs hdfs 147952 Mar 30 21:09 jersey-json-1.9.jar
-rw-r--r-- 1 hdfs hdfs 713089 Mar 30 21:09 jersey-server-1.9.jar
-rw-r--r-- 1 hdfs hdfs 539735 Mar 30 21:09 jets3t-0.9.0.jar
-rw-r--r-- 1 hdfs hdfs 67758 Mar 30 21:09 jettison-1.1.jar
-rw-r--r-- 1 hdfs hdfs 516429 Mar 30 21:09 jetty-6.1.14.jar
-rw-r--r-- 1 hdfs hdfs 163121 Mar 30 21:09 jetty-util-6.1.14.jar
-rw-r--r-- 1 hdfs hdfs 185746 Mar 30 21:09 jsch-0.1.42.jar
-rw-r--r-- 1 hdfs hdfs 100636 Mar 30 21:09 jsp-api-2.1.jar
-rw-r--r-- 1 hdfs hdfs 33015 Mar 30 21:09 jsr305-1.3.9.jar
-rw-r--r-- 1 hdfs hdfs 489884 Mar 30 21:09 log4j-1.2.17.jar
-rw-r--r-- 1 hdfs hdfs 847 Mar 30 21:09 log4j.properties
-rw-r--r-- 1 hdfs hdfs 1610 Mar 30 21:09 logger.properties
-rw-r--r-- 1 hdfs hdfs 1199572 Mar 30 21:09 netty-3.6.2.Final.jar
-rw-r--r-- 1 hdfs hdfs 1887979 Mar 30 21:09 netty-all-4.0.25.Final.jar
-rw-r--r-- 1 hdfs hdfs 105291 Mar 30 21:09 prevayler-2.3WD5.jar
-rw-r--r-- 1 hdfs hdfs 533455 Mar 30 21:09 protobuf-java-2.5.0.jar
-rw-r--r-- 1 hdfs hdfs 105112 Mar 30 21:09 servlet-api-2.5.jar
-rw-r--r-- 1 hdfs hdfs 26176 Mar 30 21:09 slf4j-api-1.6.6.jar
-rw-r--r-- 1 hdfs hdfs 9711 Mar 30 21:09 slf4j-log4j12-1.6.6.jar
-rw-r--r-- 1 hdfs hdfs 23346 Mar 30 21:09 stax-api-1.0-2.jar
drwxr-xr-x 1 hdfs hdfs 12 Apr 1 17:21 webapps
-rw-r--r-- 1 hdfs hdfs 15010 Mar 30 21:09 xmlenc-0.52.jar
-rw-r--r-- 1 hdfs hdfs 7188 Mar 30 21:09 xmlpull-1.1.3.1.jar
-rw-r--r-- 1 hdfs hdfs 481770 Mar 30 21:09 xstream-1.4.3.jar
-rw-r--r-- 1 hdfs hdfs 94672 Mar 30 21:09 xz-1.0.jar
-rw-r--r-- 1 hdfs hdfs 1351733 Mar 30 21:09 zookeeper-3.4.5-cdh5.3.0.jar
WD Fusion UI
Default installation directory for WD Fusion is
/opt/wandisco/fusion-ui-serverThis folder contains the following subfolders:
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 bin
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 config
drwxr-xr-x 3 hdfs hdfs 4096 Mar 30 14:28 docs
-rw-r--r-- 1 hdfs hdfs 12614 Mar 27 22:07 fusion-ui-server-delegate.jar
-rw-r--r-- 1 hdfs hdfs 499861 Mar 27 22:07 fusion-ui-server.jar
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 lib
drwxr-xr-x 2 hdfs hdfs 4096 Apr 7 10:51 logs
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 properties
drwxr-xr-x 2 hdfs hdfs 4096 Mar 30 14:28 tmp
drwxr-xr-x 8 hdfs hdfs 4096 Mar 30 14:28 ui
drwxr-xr-x 3 hdfs hdfs 4096 Mar 30 14:28 varWD Fusion Guide
Dashboard
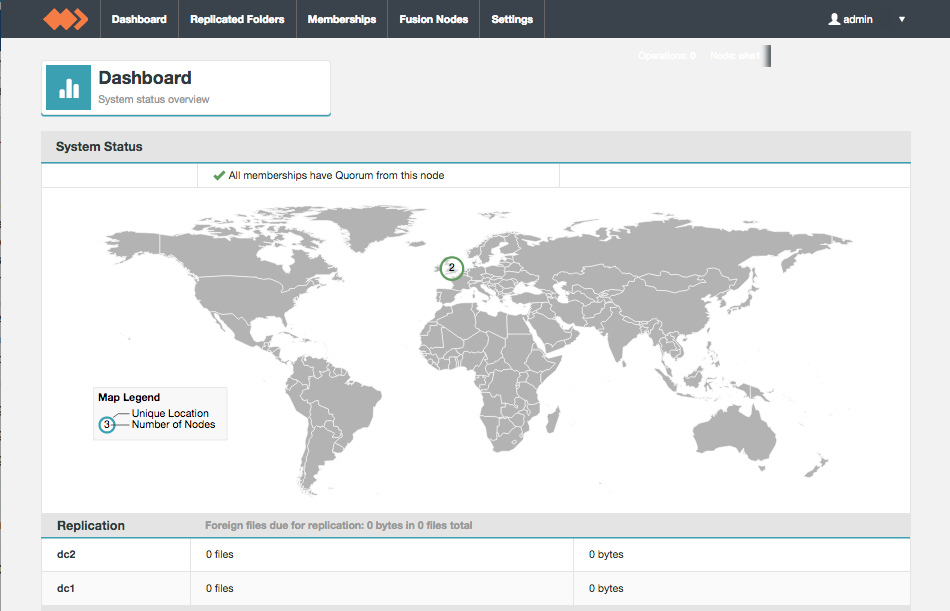
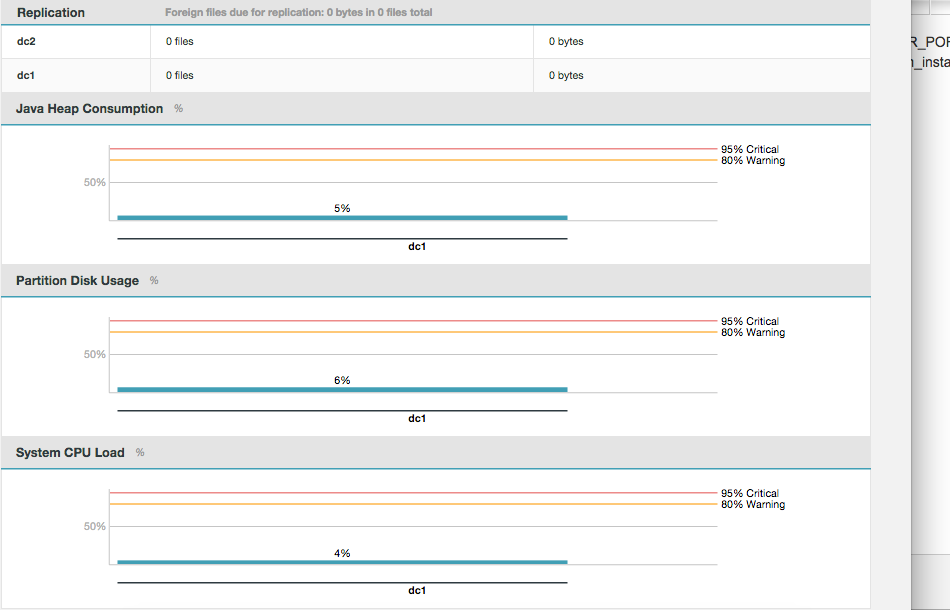
System Usage Graphs
The dashboard provides running monitors for key system resources.
Replicated Folders
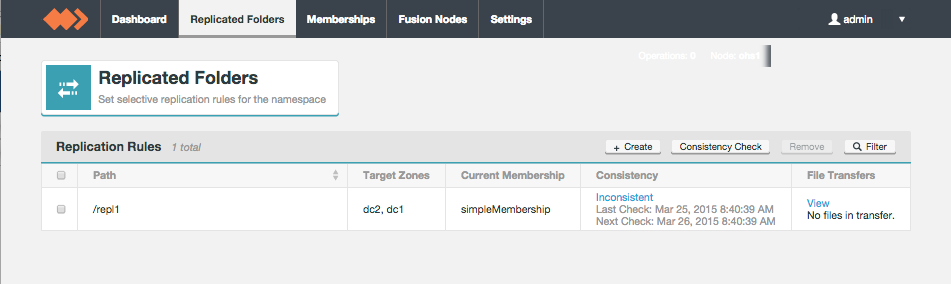
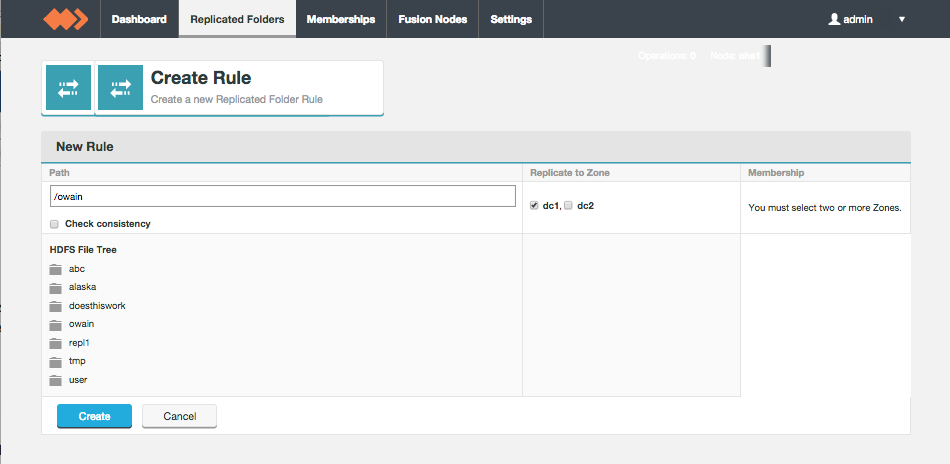
The Replicated Folders screen lists those folders in the cluster's hdfs space that are set for replication between WD Fusion nodes.

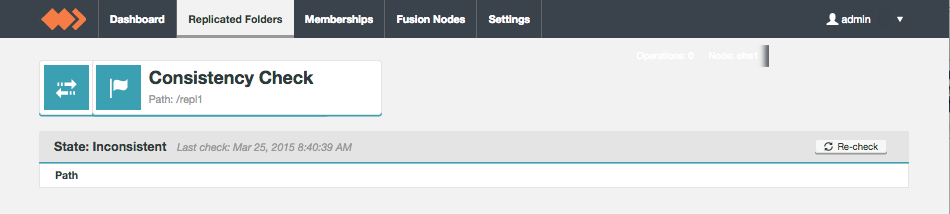
Consistency Check
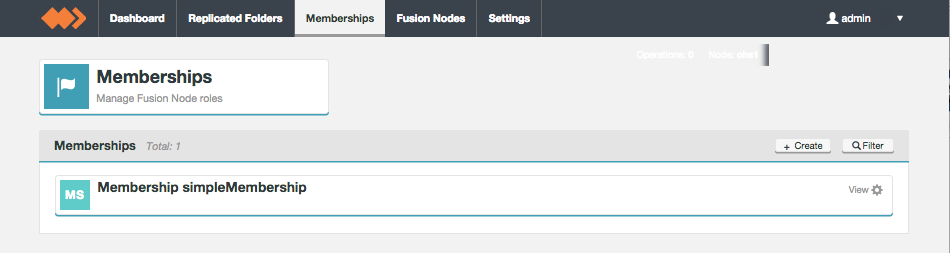
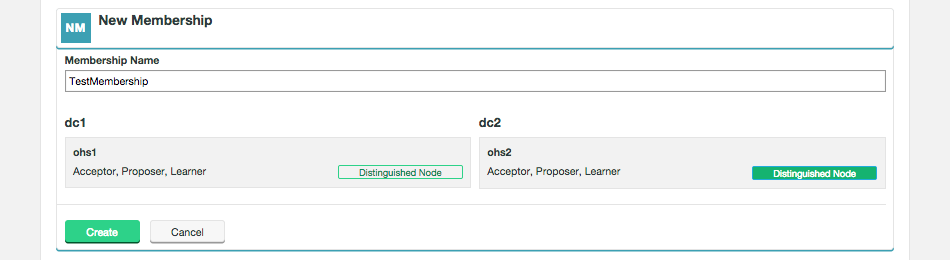
Membership
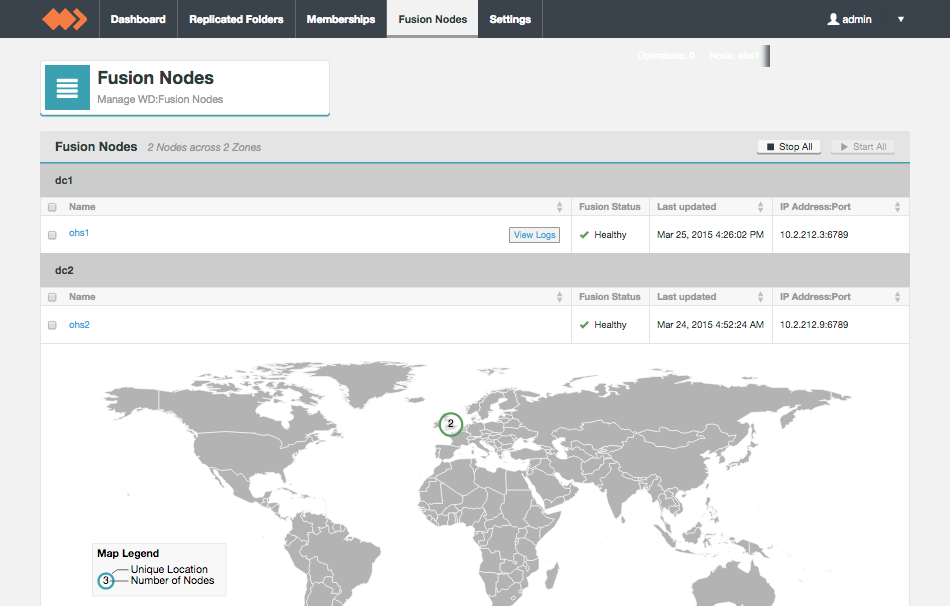
Fusion Nodes
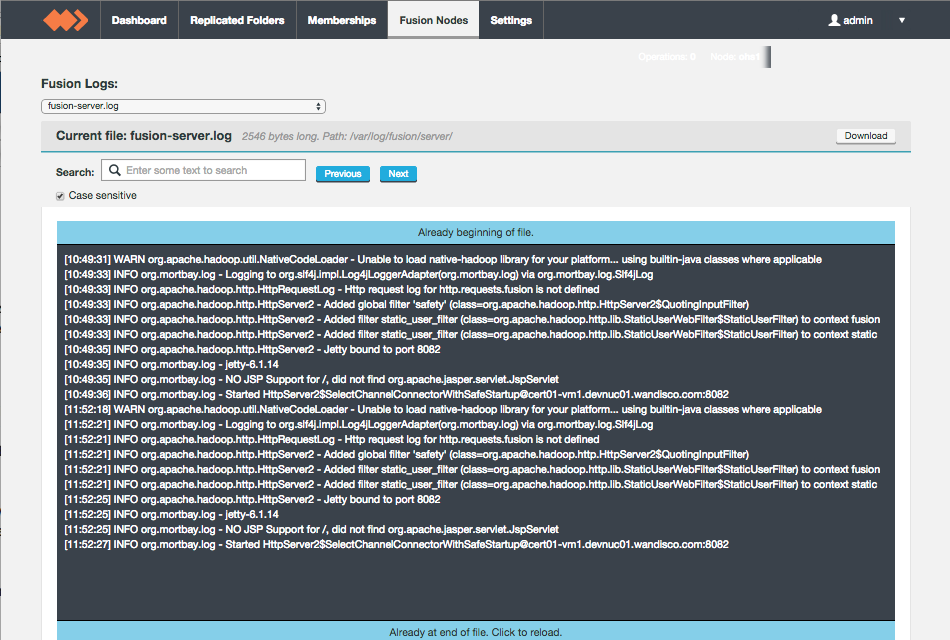
Logs
Settings
About This Node
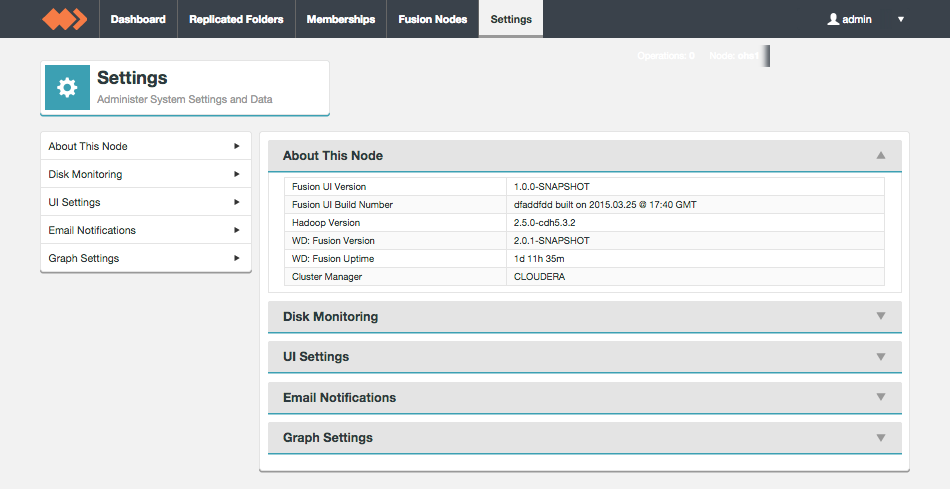
The About This Node panel shows the version information for the underlaying Hadoop deployment as well as the WD Fusion server and UI components:
- Fusion UI Version
- The current version of the WD Fusion UI.
- Fusion Build Number
- The specific build for this version of the WD Fusion UI.
- Hadoop Version
- The version of the underlying Hadoop deployment.
- WD Fusion Version
- The version of the WD Fusion replicator component.
- WD Fusion Uptime
- The time elapsed system the WD Fusion system last booted up.
- Cluster Manager
- The management application used with the underlying Hadoop.
Email Notifications
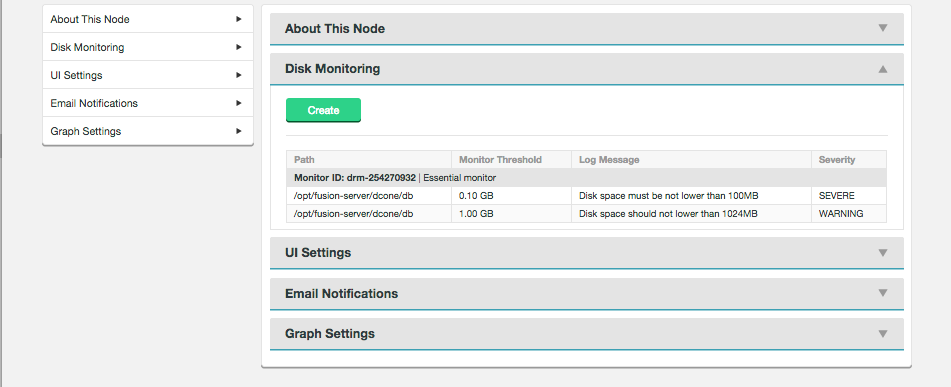
Disk Monitoring
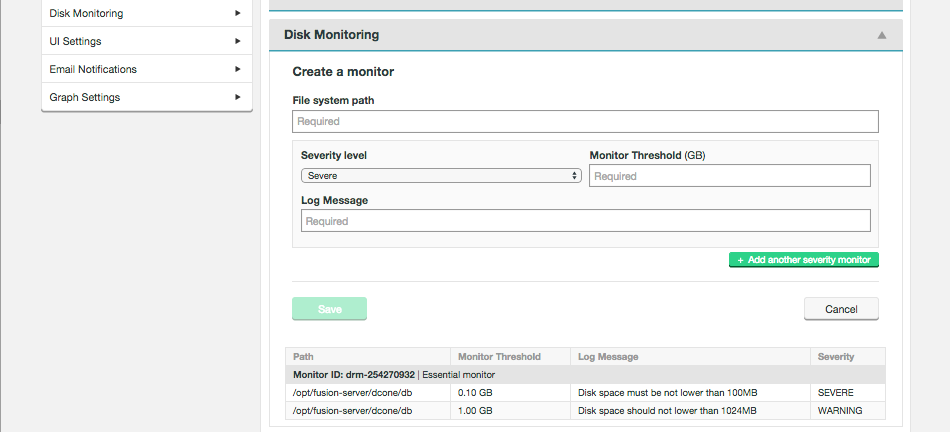
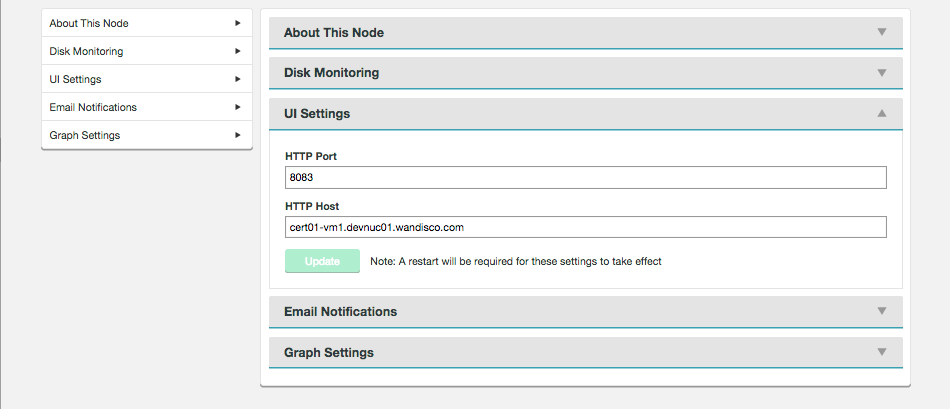
Create Monitor
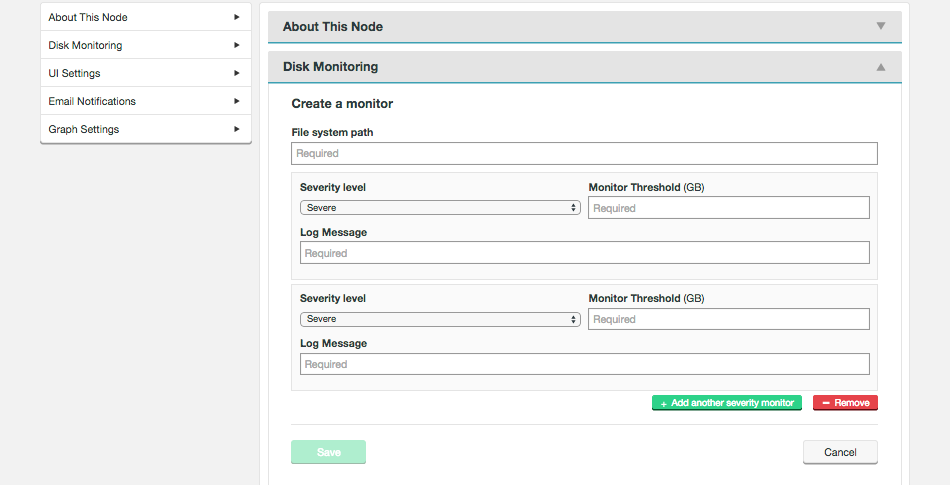
UI Settings