2. Installation Guide
This section will run through the installation of WD Fusion from the initial steps where we make sure that your existing environment is compatible, through the procedure for installing the necessary components and then finally configuration.
2.1 Deployment Overview
[EXAMPLE DEPLOYMENT ILLUSTRATION]2.2 Hardware requirements
This section describes hardware requirements for deploying Hadoop using WD Fusion. These are guidelines that provide a starting point for setting up data replication between your Hadoop clusters.
WD Fusion Deployment Components
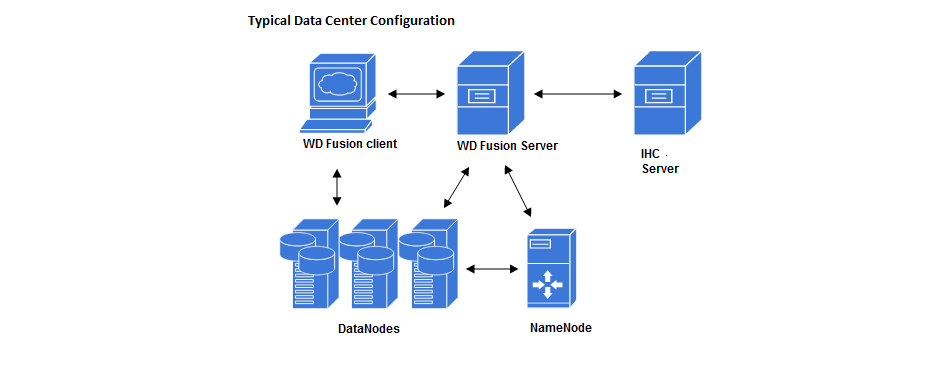
Example WD Fusion Data Center Deployment.
- WD Fusion Server
- The core WD Fusion server. Using HCFS (Hadoop Compatible File System) to permit the replication of HDFS data between data centers, while maintaining strong consistency.
- WD Fusion UI
- A seperate server that provides administrators with a browser-based management console for each WD Fusion server. This can be installed on the same machine as WD Fusion's server or on a different machine within your data center.
- IHC Server
-
Inter Hadoop Communication servers handle the traffic that runs between zones or data centers that use different versions of Hadoop. IHC Servers are matched to the version of Hadoop running locally.
It's possible to deploy different numbers of IHC servers at each data center, additional IHC Servers can form part of a High Availability mechanism. - WD Fusion Client
- Client jar files to be installed on each Hadoop client, such as mappers and reducers that are connected to the cluster.
WD Fusion servers must not be co-located with HDFS servers (DataNodes, etc)
HDFS's default block placement policy dictates that if a client is co-located on a DataNode, then that co-located DataNode will receive 1 block of whatever file is being put into HDFS from that client. This means that if the WD Fusion Server (where all transfers go through) is co-located on a DataNode, then all incoming transfers will place 1 block onto that DataNode.
In which case the DataNode is likely to consumes lots of disk space in a transfer-heavy cluster, potentially forcing the WD Fusion Server to shut down in order to keep the Prevaylers from getting corrupted.
WD Fusion and IHC servers' requirements
The following guidelines apply to both the WD Fusion server and for separate IHC servers. We recommend that you deploy on physical hardware rather than on a virtual platform, however, there are no reasons why you can't deploy on a virtual environment.
If you plan to locate both the WD Fusion and IHC servers on the same machine then check the Collocated Server requirements:
| CPUs: | Type: Multi-CPU servers perform best. Recommended: 2 x quad core CPUs. Minimum: 1 x quad core. Architecture: 64-bit only. |
| System memory: | There are no special memory requirements, except for the need to support a high throughput of data:
Type: Use ECC RAM Size: Recommended 64 GB recommended (minimum of 16 GB) System memory requirements are matched to the expected cluster size and should take into account the number of files and block size. The more RAM you have, the bigger the supported file system, or the smaller the block size. Collocation of WD Fusion/IHC servers |
| Disk space: | Type: Hadoop operations are disk-intensive so we strongly recommend that you use Enterprise class Solid State Drives (SSDs). Size: Recommended: 1 TB Minimum: You need at least 500 GB of disk space for a production environment. |
| Network | Connectivity: Minimum 1Gb Ethernet between local nodes, but 10Gb recommended. TCP Port Allocation: Two ports are required for deployment of WD Fusion: DConE port: (default 8082) IHC ports: (7000 range for command ports) (8000 range for HTTP) HTTP interface: (default 50070) is re-used from the stand-alone Hadoop NameNode Web UI interface: (default 8083) |
2.3 Software requirements
| Operating systems: |
|
| Java: | Hadoop requires Java JDK 1.7. It is built and tested on Oracle's version of Java, which is used in most test environments. We do not recommend using a different version of Java. Architecture: 64-bit only Heap size: Set Java Heap Size of to a minimum of 1Gigabytes, or the maximum available memory on your server. Use a fixed heap size. Give -Xminf and -Xmaxf the same value. Make this as large as your server can support. Avoid Java defaults. Ensure that garbage collection will run in an orderly manner. Configure NewSize and MaxNewSize Use 1/10 to 1/5 of Max Heap size for JVMs larger than 4GB. Stay deterministic! Where's Java? rm f /usr/bin/javaand link /usr/bin/java to the java installed by your Hadoop manager. Cloudera/Hortonworks may install Sun JDK with the high strength encryption package included. For good measure, remove any JDK 6 that might be present in /usr/java. Make sure that /usr/java/default and /usr/java/latest point to a java 7 version your Hadoop manager installs ones.
Ensure that you set the JAVA_HOME environment variable for the root user on all nodes. Remember that, on some systems, invoking sudo strips environmental variables, so you may need to add the JAVA_HOME to Sudo's list of preserved variables. |
| File descriptor/Maximum number of processes limit: | Maximum User Processes and Open Files limits are low by default on some systems. It is possible to check their value with the ulimit or limit command:
ulimit -u && ulimit -n
-u The maximum number of processes available to a single user. For optimal performance, we recommend both hard and soft limits values to be set to 64000 or more: RHEL6 and later: A file /etc/security/limits.d/90-nproc.conf explicitly overrides the settings in security.conf, i.e.:
# Default limit for number of user's processes to prevent
# accidental fork bombs.
# See rhbz #432903 for reasoning.
* soft nproc 1024 <- Increase this limit or ulimit -u will be reset to 1024
Both Ambari and Cloudera manager will set various ulimit entries, you must ensure hard and soft limits are set to 64000 or higher. Check with the ulimit or limit command. If the limit is exceeded the JVM will throw an error: java.lang.OutOfMemoryError: unable to create new native thread.
|
| Additional requirements: | passwordless ssh If you plan to set up the cluster using the supplied WD Fusion orchestration script you must be able to establish secure shell connections without using a passphrase. KB Security Enhanced (SE) Linux You need to disable Security-Enhanced Linux (SELinux) for the installation to ensure that it doesn't block activity that's necessary to complete the installation. Disable SELinux on all nodes, then reboot them: sudo vi /etc/sysconfig/selinuxSet SELINUX to the following value: SELINUX=disabled iptables Disable iptables. $ sudo chkconfig iptables offReboot. When the installation is complete you can re-enable iptables using the corresponding command: sudo chkconfig iptables on Comment out requiretty in /etc/sudoersThe installer's use of sudo won't work with some linux distributions (CentOS where /etc/sudoer sets enables requiretty, where sudo can only be invoked from a logged in terminal session, not through cron or a bash script. When enabled the installer will fail with an error:
execution refused with "sorry, you must have a tty to run sudo" messageEnsure that requiretty is commented out: # Defaults requiretty |
Supported versions
This table shows the versions of Hadoop and Java that we currently support:
| Distribution: | Console: | JDK: |
| Apache Hadoop 2.5.0 | Oracle JDK 1.7_45 64-bit | |
| HDP 2.1 / 2.2 | Ambari 1.6.1 / 1.7 Support for EMC Isilon 7.2.0.1 and 7.2.0.2 |
Oracle JDK 1.7_45 64-bit |
| CDH 5.2.0/5.3.0/5.4 | Cloudera Manager 5.3.2 Support for EMC Isilon 7.2.0.1 and 7.2.0.2 |
Oracle JDK 1.7_45 64-bit |
Hadoop Compatible File System (HCFS)
WD Fusion supports Hadoop applications that work with the HCFS. Applications that require direct access to Hadoop are not supported. A good test of compatibility: if your application can run on Amazon S3's built-in driver then there is a very high propbability that they are compatible with WD Fusion.
Installation Overview
The installation of WANdisco's WD Fusion is assumed to run through the following steps.
- Install and configure working Hadoop clusters. We assume that your Hadoop deployment is already up-and-running.
- Install the WD Fusion server element in your first zone. See 2.4 WD Fusion server installation
- Install the WD Fusion UI element in your first zone. See 2.5 WD Fusion server installation
- Repeat the sequence for each additional zone.
- Configure WD Fusion for replication. See #2.6 Configuration
- When all nodes have been installed and configured, set up tests to confirm that replication is working.
Installation requirements
Time requirements
The time required to complete a deployment of WD Fusion will in part be based on its size, larger deployments with more nodes and more complex replication rules will take correspondingly more time to set up. Use the guide below to help you plan for for deployments.
- Run through this document and create a checklist of your requirements. 1-2 hours
- Complete the WD Fusion server installations (20 minutes per node, or 1 hour for a test deployment)
- Install WD Fusion UI (30 minutes)
- Complete client installations and complete basic tests 1-2 hours.
Of course, this is a guideline to help you plan your deployment. You should think ahead and determine if there are additional steps or requirements introduced by your organization's specific needs.
Network requirements
See the deployment checklist for a list of the TCP ports that need to be open for WD Fusion.
Kerberos Security
If you are running Kerberos on your cluster you should consider the following requirements:
- Kerberos is already installed and running on your cluster
- Fusion-Server is configured for Kerberos as described in Setting up Kerberos.
- We will be using the same keytab and principal we generated for fusion-server. Assume it's in
/etc/hadoop/conf/fusion.keytab
Update Fusion-UI configuration:
- Copy DC's /etc/hadoop/conf/hdfs-site.xml into fusion UI's lib folder:
/opt/wandisco/fusion-ui-server/lib/ - Copy DC's /etc/hadoop/conf/core-site.xml into fusion UI's lib folder:
/opt/wandisco/fusion-ui-server/lib/ - Add core-site.xml and hdfs-site.xml path to the configuration file:
client.core.site=/etc/hadoop/conf/core-site.xml client.hdfs.site=/etc/hadoop/conf/hdfs-site.xml - Enable kerberos in fusion-ui configuration (
/opt/wandisco/fusion-u-serveri/properties/ui.properties):kerberos.enabled=true kerberos.generated.config.path=/opt/wandisco/fusion-ui-server/properties/kerberos.cfg kerberos.keytab.path=/etc/hadoop/comf/fusion.keytab kerberos.principal=fusion/${hostname}@${krb_realm}
2.4 WD Fusion server installation
Before installing the latest version of WD Fusion, you need to run through the WD Fusion cleanup section.
- Before you start, make sure that you've run through the installation requirements. Take special note that you are running the right version of Java and that you have passwordless ssh enabled between your installation machine and every other machine in your cluster. See JAVA requirements and Passwordless SSH.
- Download the WD Fusion archive file and save it onto your 'install' server.
- Extract the archive. This creates the following files and directories:
[root@vmhost08-vm0 orch]# ls -l -rw-rw-r-- 1 hdfs hdfs 447 Mar 17 17:00
mydefines.sh.example-rwxr-xr-x 1 hdfs hdfs 8473 Mar 20 10:36orchestrate-fusion.shdrwxrwxr-x 4 hdfs hdfs 4096 Mar 21 08:14rpmsEdit the
mydefines.sh.examplefile and save it as "mydefines.sh". Enter the hostnames for your namenode, WD Fusion node and all your DataNodes. Take note of the comments that indicate properties that are specific to the data center's Hadoop version:############## ZONE1 ############## # Distribution for ZONE1
The definitions for the required Hortonworks/Cloudera RPM packages are already set in the mydefines.sh script, you don't need to edit this.ZONE1=cdh-5.3.0# Currently you need to round down manager version # e.g. CDH 5.3.1 becomes cdh-5.3.0 # Manager Hosts/Configs for ZONE1ZONEMGR1="vmhost08-vm0.bdfrem.wandisco.com" ZONECLUSTERNAME1="hdfs" ZONEUSER1="admin" ZONEPW1="admin" ZONEAPI1="v9"# CDH5.2 use "v8" # CDH5.3.x use "v9" # HDP 2.1/2.2 use "v1"ZONEYARNSERVICENAME1="yarn"# "YARN" for HDP # "yarn" for CDH # Fusion Server and IHC for ZONE1ZONEFS1="vmhost08-vm1.bdfrem.wandisco.com" ZONEIHC1[0]="vmhost08-vm1.bdfrem.wandisco.com"# Filesystem Hosts for ZONE1ZONENN1="vmhost08-vm0.bdfrem.wandisco.com" ZONEDN1[0]="vmhost08-vm1.bdfrem.wandisco.com" ZONEDN1[1]="vmhost08-vm2.bdfrem.wandisco.com" ZONEDN1[2]="vmhost08-vm3.bdfrem.wandisco.com"############## ZONE2 ############## # Distribution for ZONE2ZONE2=hdp-2.2.0# Manager Hosts/Configs for ZONE2ZONEMGR2="vmhost08-vm0.bdfrem.wandisco.com" ZONECLUSTERNAME2="hdp22" ZONEUSER2="admin" ZONEPW2="admin" ZONEAPI2="v1" ZONEYARNSERVICENAME2="YARN"# Fusion Server and IHC Host for ZONE2ZONEFS2="vmhost08-vm1.bdfrem.wandisco.com" ZONEIHC2[0]="vmhost08-vm1.bdfrem.wandisco.com"# Filesystem Hosts for ZONE2ZONE2NN="vmhost08-vm0.bdva.wandisco.com" ZONEDN2[0]="vmhost08-vm1.bdva.wandisco.com" ZONEDN2[1]="vmhost08-vm2.bdva.wandisco.com" ZONEDN2[2]="vmhost08-vm3.bdva.wandisco.com"############## ZONE3 ############## # Distribution for ZONE3ZONE3=hdp-2.2.0# Manager Hosts/Configs for ZONE3ZONEMGR3="vmhost08-vm0.bdfrem.wandisco.com" ZONECLUSTERNAME3="hdp22" ZONEUSER3="admin" ZONEPW3="admin" ZONEAPI3="v1" ZONEYARNSERVICENAME3="YARN"# Fusion Server and IHC Host for ZONE3ZONEFS3="vmhost08-vm1.bdfrem.wandisco.com" ZONEIHC3[0]="vmhost08-vm1.bdfrem.wandisco.com"# Filesystem Hosts for ZONE3ZONE3NN="vmhost08-vm0.bdva.wandisco.com" ZONEDN3[0]="vmhost08-vm1.bdva.wandisco.com" ZONEDN3[1]="vmhost08-vm2.bdva.wandisco.com" ZONEDN3[2]="vmhost08-vm3.bdva.wandisco.com" - Create the hdfs directories that you want to replicate between both data centers, e.g.
/repl1
To ensure that you avoid permission issues, have the owning Linux user created in HDFS, e.g.a. hadoop fs -mkdir /user/replicator1 b. hadoop fs -chown -R replicated1:groupname /user/replicated1
- As system user "hdfs", run the following commands in each data center: -+
hadoop fs -mkdir /repl1 hadoop fs -chown replicator1:replicator1 /repl1
-
Run the command:
The RPM packages will now get installed.sudo ./orchestrate-fusion.sh ./mydefines.sh installrpms - Run the command:
In this examplesudo ./orchestrate-fusion.sh ./mydefines.sh configure /repl1/repl1is set up as the replicated directory. - Using your management tool (Ambari or Cloudera Manager etc), add the following entries to the cluster-wide
core-site.xml. The values are specific to each Data Center, i.e. you need one set of values for DC1 and another for DC2.<property> <name>fs.fusion.impl</name> <value>com.wandisco.fs.client.FusionFs</value> </property> <property> <name>fs.fusion.server</name> <value>YOUR.WDFUSION.COM:8023</value> </property>Replace YOUR.WDFUSION.COM with your Fusion server that you configured in your mydefines.sh. Please use port :8023.<property> <name>fusion.underlyingFs</name> <value>hdfs://vmhost08-vm0.bdfrem.wandisco.com:8020</value> </property>Replace the URL with your own cluster's underlying files system, make sure that you don't leave a trailing splash. <property> <name>fs.AbstractFileSystem.fusion.impl</name> <value>com.wandisco.fs.client.FusionAbstractFs</value> </property>Notes
Replace thehdfs://vmhost08-vm0.bdfrem.wandisco.com:8020URL with your own cluster's underlying filesystem.
Important! Take care not to add a trailing slash "/" at the end, it won't work.<property> <name>fs.AbstractFileSystem.fusion.impl</name> <value>com.wandisco.fs.client.FusionAbstractFs</value> </property> - Log in as the system user account that owns the replicated directory, e.g. "replicator1", run the command:
You'll then find the file installed inhadoop fs -copyFromLocal /etc/hosts fusion:///repl1/repl1in both data centers. - Perform a test by running
terasortandteragenon the same replicated folder.
Ensure that you have user "hdfs" on your Fusion Servers. This is because the WD Fusion server is started as user "hdfs" and will fail otherwise.
Running WD Fusion on multi-homed servers
The following guide runs through what you need to do to correctly configure a WD Fusion deployment if the nodes are running with multiple network interfaces.
Overview
- A file is created in DC1. A Client writes the Data.
- Periodically after the data is written, a proposal is sent by the WD Fusion Server in DC1, telling the WD Fusion server in DC2 to pull the new file. This proposal includes the map of IHC server public IP addresses, in this case, listening at <Public-IP>:7000 (Fusion Server in DC1 read this from
/etc/wandisco/fusion/server/ihcList)
- Fusion Server in DC2 gets this agreement, connects to <Public-IP>:7000 and pulls the data.
Procedure
- Stop all WD Fusion services.
- Reconfigure your IHCs to your preferred address in /etc/wandisco/ihc/*.ihc for each IHC node.
- For the WD Fusion servers, delete all files in /etc/wandisco/fusion/server/ihclist/*.
- Copy zone1 IHC's
/etc/wandisco/ihc/*.ihcfiles to zone1 Fusion-Server/etc/wandisco/fusion/server/ihcList - Copy zone2 IHC's
/etc/wandisco/ihc/*.ihcfiles to zone2 Fusion-Server/etc/wandisco/fusion/server/ihcList - Restart all services
Troubleshooting
First, ensure that DC2's WD Fusion server can connect to DC1's IHC server. You can quickly test this by running
nc <DC1's IHC Public-IP>:7000If you get a 'connection refused' or 'no route to host' message, you'll have a networking problem that will need to be fixed.
2.5 WD Fusion UI Installation
Control of your WD Fusion server is done through a separate browser-based management console that we refer to as the WD Fusion UI. The WD Fusion UI can be installed on the same servers as the WD Fusion Server, although it is possible to install them on dedicated servers. This procedure covers a manual installation that requires user entry of configuration. There's a non-interactive installation option available if you prefer to automate the installation. See Non-interactive installation
When you're ready to install and configure WD Fusion UI, go through this procedure. If you experience any difficulties don't hesitate to contact WANdisco's Support team.
Before you start, get this information:
During the installation you will be asked for various configuration. The installer has a short time-out so it's a good idea to have the following things ready:
- UI Hostname/Port:
- Host and TCP Port for the Hadoop WD Fusion UI server.
- Target Hostname/ Delegate Port:
- Hostname and TCP port used by the WD Fusion server. We currently run the WD Fusion server and UI on the same host. As this doesn't need to be the case, you can specify a different hostname, here.
- Manager hostname/port
- Hostname and TCP port for the Hadoop manager's (Ambari, etc) server.
- Download the installer script to the WD Fusion server.
- Open a terminal session, navigate to the installer script, make it executable and then run it, i.e.
chmod +x fusion-ui-server_rpm_installer.sh sudo ./fusion-ui-server_rpm_installer.sh - The installer will start by checking its file integrity, confirming where you want the installation to be placed.
Verifying archive integrity... All good. Uncompressing WANdisco Fusion UI Server.......... :: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### #####Press return to install to the default location. - The installer confirms which version of WD Fusion UI will be installed. You then need to confirm that you wish to continue with the installation.
Welcome to the WANdisco Fusion UI installation You are about to install WANdisco Fusion UI version 1.0.0-76 Do you want to continue with the installation? (Y/n) Y
- The installer checks for supporting software that you need to have in place before you can complete the installation:
Checking prerequisites: Checking for perl: OK Checking for java: OK
- The installer will now allocate the Java heap space for the JVM running the UI. The ammount of memory allocated should be estimated as part of the evaluation process. The default values will be enough to run the software but won't take into account the other JVMs running on the server (WD Fusion server, IHC servers, etc).
INFO: Using the following Memory settings: INFO: -Xms128m -Xmx512m Do you want to use these settings for the installation? (Y/n)
Click enter to continue. - The installer will now get you to select the manager type that you are running in the current your data center:
Please specify the type of Manager from the list below. 1) Ambari 2) Cloudera Choose a Manager Type (answer 1 or 2): 1
- Enter the following hostnames and ports:
Please specify the Manager hostname: 10.2.212.3 Which port is the Manager listening on? 8080 Please specify the HDFS hostname: 10.2.212.3
- Manager hostname
- The hostname/IP of your Hadoop manager, e.g. Ambari.
- Manager listening port
- The TPC port used for your Hadoop mananger, e.g. Ambari's standard port 8080 for http or 8440 for https.
- HDFS hostname
- The hostname/IP of the NameNode. WD Fusion uses the NameNode to grab the hdfs filetree for picking folders for replication.
- The installer will now capture the system user/group that will be used to run the application.
We strongly advise against running Fusion UI as the root user. Which user should Fusion UI run as? hdfs Which group should Fusion UI run as? hdfs
You should never run applications in a production environment using the root account. We recommend that you create a specific account with suitable write permissions for running hadoop applications. - You will now see a summary of your entries, allowing you to check over them before continuing:
Installing with the following settings: UI Hostname: redhat6.3-64bit UI Port: 8083 Target Hostname: redhat6.3-64bit Target Port: 8082 Target Delegate Port: 9999 Manager Type: AMBARI Manager Hostname: 10.2.212.3 Manager Port: 8080 HDFS Hostname: 10.2.212.3 HDFS Port: 50070 Application Minimum memory: 128 Application Maximum memory: 512 Do you want to continue with the installation? (Y/n)
Click enter to continue. - The installer now gives you the option to set up WD Fusion UI to start on boot. Click enter to get this in place.
Would you like WD Fusion UI to start automatically when the system boots? (Y/n) y
- The installation is now complete, WD Fusion UI will now start up.
Starting delegate:[ OK ] Starting ui:[ OK ] Checking if the GUI is listening on port 8083: ......Done Please visit http://<thisHost>:8083/ to access the WANdisco Fusion UI Server Installation Complete
You are now directed to the browser UI. Open a browser and enter the address along with the UI port that you selected, 8082 is the default. The WD Fusion UI Dashboard will appear in the browser.

Installation complete.
- You should hold off interacting with the WD Fusion UI until you have all WD Fusion servers installed. Once WD Fusion is successfully installed on all nodes you should proceed to set up set up data replication. See Replication overview in the Admin Section.
2.6 Configuration
Once WD Fusion has been installed on all data centers you can proceed with setting up replication on your HDFS file system. You should plan your requirements ahead of the installation, matching up your replication with your cluster to maximise performance and resiliance. The next section will take a brief look at a example configuration and run through the necessary steps for setting up data replication between two data centers.
Replication Overview

Example WD Fusion Deployment in a 3 data center deployment.
In this example, each one of three data centers ingests data from it's own datasets, "Weblogs", "phone support" and "Twitter feed". An administrator can choose to replicate any or all of these data sets so that the data is replicated across any of the data centers where it will be available for compute activiities by the whole cluster. The only change required to your Hadoop applications will be the addition of a replication specific URI. You can read more about adapting your Hadoop applications for replication.
Setting up Replication
The following steps are used to start replicating hdfs data. The detail of each step will depend on your cluster setup and your specific replication requirements, although the basic steps remain the same.
- Create a membership including all the data centers that will share a particular directory. See Create Membership
- Create and configure a Replicated Folder. See Replicated Folders
- Perform a consistency check on your replicated folder. See Consistency Check
- Configure your Hadoop applications to use WANdisco's protocol. See Configure Hadoop for WANdisco replication
- Run Tests to validate that your replicated folder remains consistent while data is being written to each data center. See Testing replication
Running WD Fusion with Tez:
Apache Tez is a YARN application framework that supports high performance data processing through DAGs. When set up, Tez uses its own tez.tar.gz containing the dependencies and libraries that it needs to run DAGs. For a DAG to access WD Fusion's fusion:/// URI it needs our client jars:
Configure the tez.lib.uris property with the path to the WD Fusion client jar files.
...
<property>
<name>tez.lib.uris</name>
# Location of the Tez jars and their dependencies.
# Tez applications download required jar files from this location, so it should be public accessible.
<value>${fs.default.name}/apps/tez/,${fs.default.name}/apps/tez/lib/</value>
</property>
...2.7 Appendix
The appendix section contains extra help and procedures that may be required when running through a WD Fusion deployment.
Cleanup WD Fusion
The following section is used when preparing to install WD Fusion on system that already has an earlier version of WD Fusion installed. Before you install an updated version of WD Fusion you need to ensure that components and configurartion for an earlier installation have been removed. Go through the following steps before installing a new version of WD Fusion:
Cleanup WD Fusion / IHC Server processes
Ensure that there are no WD Fusion / IHC server processes running. The WD Fusion orchestration script has a cleanup option for this. Run:
sudo ./orchestrate-fusion.sh ./mydefines.sh cleanupjps -lCheck that none of your WD Fusion machines are not running.
'com.wandisco.fs.ihc.server.Main' or 'com.wandisco.fs.server.Main'
If required "kill -9 the processes. Then clean up the DConE databased with the following command:
rm -rf /opt/fusion-server/dcone/db/*/*
Cleanup WD Fusion packages
If you have a previous install of WD Fusion on your clusters, run 'removerpms' first to remove the RPMs.
In case RPM file names have been changed, you should use the orchestration script that corresponds with your old version, rather than the latest version.
sudo ./orchestrate-fusion.sh ./mydefines.sh removerpms
Continue with your new installation
You can now continue with the installation of the latest version of WD Fusion. Remember to make any necessary changes to the mydefines.sh file to include the new packages.
Non-interactive Installation
WD Fusion UI supports a non-interactive installation method favoured by administrators who need to script/automate their work.
- Place the installer script on your server.
- Set up the necessary variables that are required by the installer:
- FUSIONUI_USER
- The system user account that will run the WD Fusion UI.
- FUSIONUI_GROUP
- The system group that will be associated with WD Fusion UI.
- FUSIONUI_UMASK
- THe umask setting for the server. See File descriptor limit
- FUSIONUI_MEM_LOW
- The Java heap minimum memory allocation for the UI's JVM.
- FUSIONUI_MEM_HIGH The Java heap Maximum allocated memory.
- FUSIONUI_INIT
- FUSIONUI_UI_HOSTNAME
- The hostname or IP of the server hosting the WD Fusion UI.
- FUSIONUI_UI_PORT
- The TCP port used for handling access to the UI.
- FUSIONUI_TARGET_HOSTNAME
- The hostname or IP of the machine hosting the WD Fusion server.
- FUSIONUI_TARGET_DELEGATE_PORT
- The TPC port that WD Fusion server uses to deligate write operations, for replication.
- FUSIONUI_TARGET_PORT
- The TCP port used by WD Fusion server.
- FUSIONUI_MANAGER_TYPE
- The Hadoop management application, e.g. "CLOUDERA" or "AMBARI".
- FUSIONUI_MANAGER_HOSTNAME
- Hostname or IP address of the Hadoop manager.
- FUSIONUI_MANAGER_PORT
- The Hadoop manager's TCP port.
- FUSIONUI_HDFS_HOSTNAME
- The hostname or IP address of the NameNode.
- FUSIONUI_HDFS_PORT
- The TCP port used for communicating with the NameNode. E.g. 50070.
- Start an installation using your own variant of the following command:
sudo FUSIONUI_MANAGER_TYPE=AMBARIFUSIONUI_MANAGER_HOSTNAME=managerhostFUSIONUI_MANAGER_PORT=9876FUSIONUI_HDFS_HOSTNAME=hdfshostFUSIONUI_USER=hdfsFUSIONUI_GROUP=hadoop ./fusion-ui-server_rpm_installer.sh
orchestrate-fusion.sh script commands
Below are the available commands for running
Install all RPMs
sudo ./orchestrate-fusion.sh ./mydefines.sh installrpms
Configure replication directory
sudo ./orchestrate-fusion.sh ./mydefines.sh configure /repl1
Completely uninstall Fusion
Before installing new Fusion build with
orch.tar.gz.2.XX-YYY user needs to uninstall old build from existing /orch dir
sudo ./orchestrate-fusion.sh ./mydefines.sh removerpms
Stop all Fusion services
sudo ./orchestrate-fusion.sh ./mydefines.sh stopservices
Start all Fusion services
sudo ./orchestrate-fusion.sh ./mydefines.sh startservices
Remove configs and Dcone DBs
sudo ./orchestrate-fusion.sh ./mydefines.sh cleanup
Removing WD Fusion UI
If you need to remove WD Fusion UI from a system, follow these steps:
- Open a terminal session and run the following package removal command.
sudo yum erase fusion-ui-server
- Remove the install files with:
sudo rm -rf /opt/wandisco/fusion-ui-server
WD Fusion will now be completely removed from the server.