1. Welcome
1.1. Product overview
Fusion Backup adds backup and data restoration capabilities to Fusion’s Live Data environment. HCFS data can be snapshotted and stored within the Fusion system, then, if required data from snapshots can be restored to your clusters, using Fusion’s replication system.
The Fusion Backup uses existing Fusion mechanisms for the replication of HDFS data to other clusters, extending the capability to include a system for capturing snapshots of state for a replicated location that can later be restored from earlier states. This includes administrative, application or user-initiated changes to HDFS content so that a user with suitable privileges can restore the state of a selected portion of the file system to that from a time before the error occured.
Unlike some alternative mechanisms for backup, Fusion Backup does not require a dedicated cluster for holding backup content and state (a regular Fusion zone can be marked for backup purposes on a per-location basis).
1.2. Documentation guide
This guide contains the following:
- Welcome
-
This chapter introduces this user guide and provides help with how to use it.
- Release Notes
-
Details the latest software release, covering new features, fixes and known issues to be aware of.
- Concepts
-
Explains the basics of how Fusion Backup works and integrates with WANdisco Fusion.
- Installation
-
Covers the steps required to install and set up Fusion Backup into a WANdisco Fusion deployment.
- Operation
-
The steps required to run, reconfigure and troubleshoot Fusion Backup.
- Reference
-
Additional Fusion Backup documentation, including documentation for the available REST API.
1.2.1. Symbols in the documentation
In the guide we highlight types of information using the following call outs:
| The alert symbol highlights important information. |
| The STOP symbol cautions you against doing something. |
| Tips are principles or practices that you’ll benefit from knowing or using. |
| The i symbol shows where you can find more information, such as in our online Knowledgebase. |
1.3. Contact support
See our online Knowledgebase which contains updates and more information.
If you need more help raise a case on our support website.
1.4. Give feedback
If you find an error or if you think some information needs improving, raise a case on our support website or email docs@wandisco.com.
2. Release Notes
2.1. Backup 2.0 Build 149
1 November 2018
Wandisco is pleased to present the first release of the Wandisco Fusion Backup 2.0, available now from the Wandisco file distribution site. This release provides backup and data restoration functionality in a Live Data environment. HCFS data can be snapshotted and stored within Wandisco Fusion system periodically, allowing restoration of data from those snapshots if required at a later time.
2.2. Installation
The Fusion Backup Plugin supports an integrated installation process that allows it to be added to an existing Wandisco Fusion deployment. Please consult the Installation Guide for details.
2.3. Highlighted New Features
This release includes the following major features:
2.3.1. Backup using HDFS Snapshots
Fusion Backup 2.0 allows backup of HCFS data using the HDFS snapshot mechanism. Please refer to our Reference Guide to learn more about HDFS snapshots.
2.3.2. Schedule periodic backups
Fusion Backup 2.0 supports scheduling of backups per replicated directory. Please refer to Setting up a backup to learn how to enable scheduled backups.
2.4. Supported Platforms
This release of Fusion Backup Plugin supports deployment into Wandisco Fusion 2.12.2 or later for the following versions of Hadoop:
-
CDH 5.4.0 - CDH 5.15.0
-
HDP 2.1.0 - HDP 2.6.5
2.5. System Requirements
Before installing, ensure that your systems, software, and hardware meet the requirements for Wandisco Fusion found in the Pre-requisites section of the User Guide.
2.6. Known Issues
Fusion Backup Plugin 2.0 includes a small set of known issues:
-
Backup does not execute during writer re-election -
WD-BUP-166 -
Backup status on the user interface does not update until browser refresh -
WD-BUP-140 -
Kerberos Relogin Failure with Hadoop 2.6.0 and JDK7u80 or later
Hadoop Kerberos relogin fails silently due to HADOOP-10786. This impacts Hadoop 2.6.0 when JDK7u80 or later (including JDK8) is used. Note: As Backup requires JDK8, you can’t downgrade to an earlier version of JDK7.-
Users MUST run with Java 8
-
Users should upgrade to Hadoop 2.6.1 or later.
-
3. Concepts
Familiarity with the plugin architecture and underlying concepts helps you to understand how Fusion Backup works, what it does and how it is used.
3.1. Product concepts
This section describes the underlying principals and concepts that make Backup work.
Backup builds on WANdisco’s principle of offering the core LiveData Fusion product and then extending functionality through a family of plugins, allowing system administrators to tailor their deployments to exactly match their requirements.
| Backup replicates backups between nodes within each zone, it does not replicate backups between zones. However, each zone in which you install Backup can be run with its own backup schedule, separate from those set in the other zones. |
3.2. Architecture
This section describes the essential parts, helping to show how Backup functions.
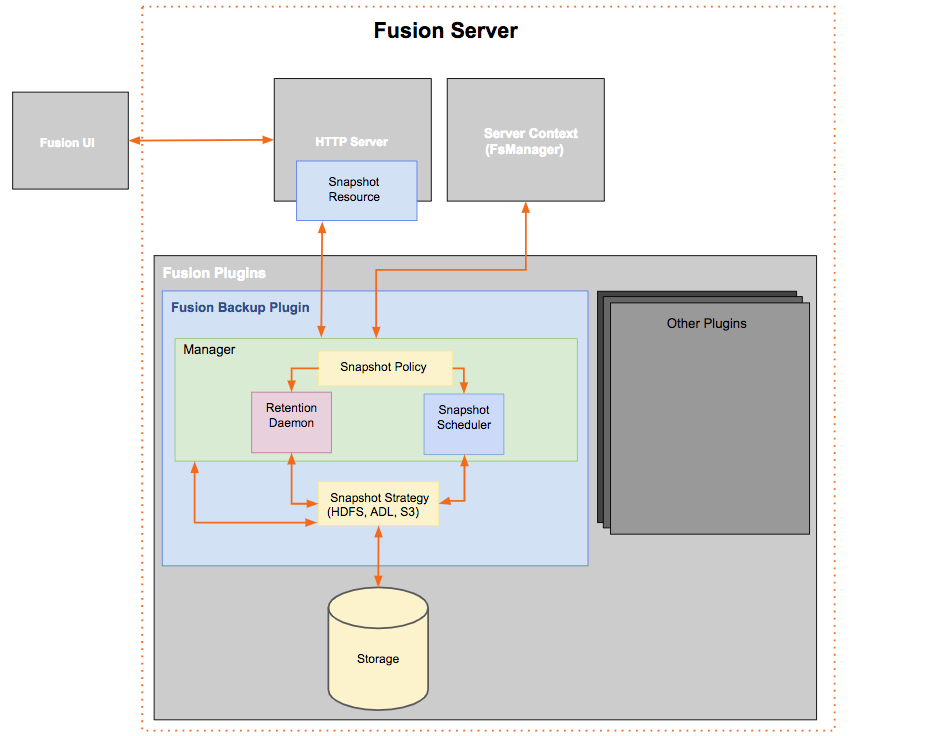
- Backup Plugin
-
The Fusion Backup plugs into the Fusion server, enabling it to use Fusion’s feature set to generate HCFS snapshots.
- Http Server
-
The Fusion Backup will contribute a new resource, the Snapshot Resource, where snapshot, recover, and listing functionality will be implemented via the REST API. More information on this is provided in the API Chapter.
- Server Context
-
Fusion Backup needs a reference to the Server Context as it needs to use the FsManager and Fusion’s GlobalPathProperties. The plugin needs to be able to identify which ReplicatedDirectories are available, and whether or not the Fusion server is the writer.
- Manager
-
The manager handles all logic except for actually snapshotting, recovering, and getting the snapshots. To do these, the manager will talk to the Snapshot strategy. The manager will then hold the state of the current snapshot policy, and along with the retention daemon and snapshot scheduler, work with the snapshot strategy to create or remove snapshots. The manager will also delegate requests from the resource to the snapshot strategy.
- Snapshot Policy
-
The Snapshot Policy handles the configurations for every zone’s replicated directory’s snapshots, using Fusion’s GlobalPathProperties, which replicates replicated directory-specific configurations across all nodes.
- Snapshot Scheduler
-
The Fusion Backup will have a scheduler that uses cron jobs to schedule snapshots per replicated directory. The cron will be provided in the Snapshot Policy and is updated via API.
The scheduler schedules snapshots per Replicated Directory. When the Snapshot Policy is updated, the scheduler will add, remove, or edit the schedule of its policies.
- Retention Daemon
-
The Plugin will also honor the retention period in the Snapshot policy by having a daemon that checks when old snapshots should be deleted. This daemon will run every hour, and will delete old snapshots.
- Snapshot Strategy
-
The snapshot strategy is the storage-specific implementation of how snapshots and recoveries are handled.
3.2.1. Limitations
-
Backups can only be taken on the same underlying file system that Fusion is already replicating.
-
Each zone in which Backup operates is independent of other zones, that is, backup operations are not replicated between zones, only between nodes within a zone. However, Fusion Backup must be deployed on all nodes in a given zone.
-
Only HDFS snapshots are supported in this version of Fusion Backup. Other storage types, such as S3 and ADL may be supported in future versions.
-
Replicated directories that are selected for backup must be able to be snapshotted. The snapshot is done by the consuming Fusion Server of the enableSnapshot API. The allowing of snapshots in HDFS can fail for the following reasons:
-
Fusion doesn’t have permissions to snapshot (is not directory owner or is not HDFS super user).
-
Hadoop Namenode is in safemode.
-
A directory’s parent or subdirectory is already set up for snapshots. Nested snapshots are currently unsupported in HDFS (see Snapshottable Directories).
-
Any of the above conditions will stop a snapshot from being created. The call will fail immediately, and the snapshot will not be scheduled.
3.3. Supported Functionality
-
Create backups (in the form of HDFS snapshots) of data stored in Replicated Directories, based upon a user-defined schedule policy.
-
Backups are replicated between nodes in a zone, with the writer node handling the backup operation. In the event of the writer node failing, a new writer is nominated from the remaining pool of nodes and it will handle the next scheduled backup.
-
Backups are not replicated between zones. Each Zone can operate its own set of backup policies. A backup policy sets the directory to be backed-up, the schedule and the maximum number of backup snapshots to be stored.
3.4. Deployment models
3.4.1. Use Cases for the Fusion Backup
The following use cases illustrate how Fusion Backup may be integrated into different types of deployments to provide different levels of backup and recovery support.
Backup enabled in a single zone
An example of the resulting file system content across a two-zone deployment, with only the zone on the right having Backup installed and configured:
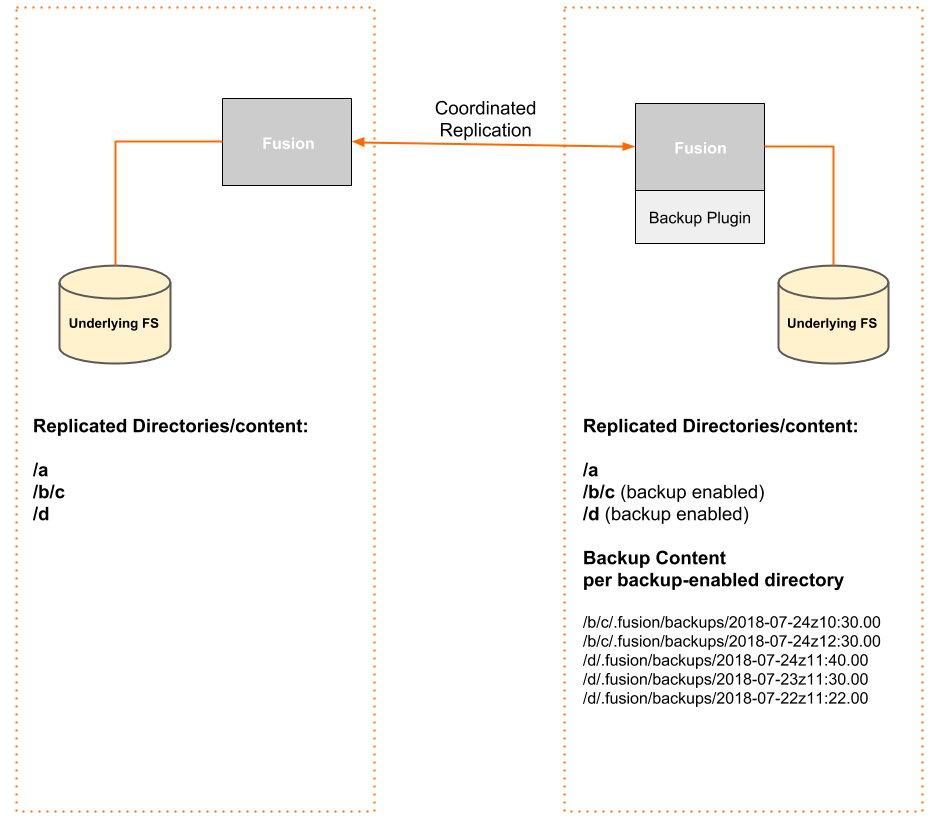
Backup is installed on the right-hand zone where /b/c and /d are set for periodic backup. While the contents of the replicated directories are also instanced on the other zone, no backups are created there.
Backup enabled in multiple zones
In the following example, the Fusion Backup is applied to directories within the replicated file system across a two-zone deployment, with both zones configured with different schedules and backup paths:
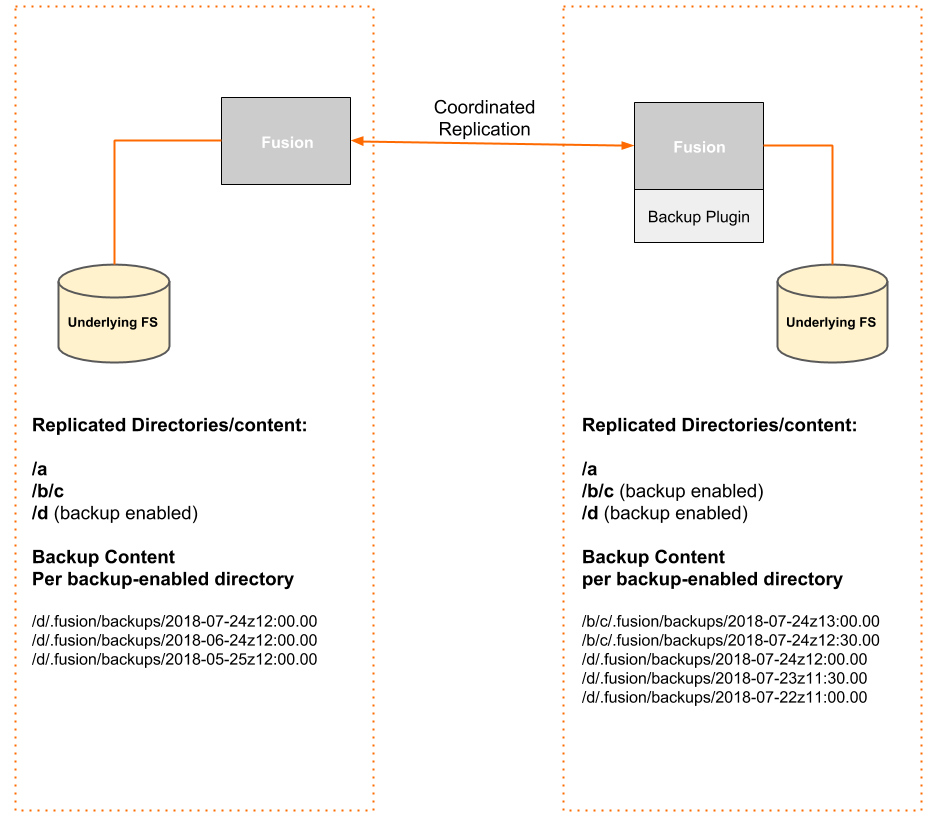
Backup is installed on both zones
Backup Location
Backups are stored in a .snapshot directory, located within the Replication Rule’s given path.
E.g., if you have a replication rule applied to the path /repl1/araminta/ then you will see the backups for this rule in the following directory:
$ hdfs dfs -ls /repl1/araminta/.snapshot Found 10 items drwxrwxrwx - hdfs hdfs 0 2018-10-14 23:00 /repl1/araminta/.snapshot/fusion-SCHEDULED-UTC-20181014T230000 drwxrwxrwx - hdfs hdfs 0 2018-10-15 00:00 /repl1/araminta/.snapshot/fusion-SCHEDULED-UTC-20181015T000000 drwxrwxrwx - hdfs hdfs 0 2018-10-15 01:00 /repl1/araminta/.snapshot/fusion-SCHEDULED-UTC-20181015T010000 drwxrwxrwx - hdfs hdfs 0 2018-10-15 02:00 /repl1/araminta/.snapshot/fusion-SCHEDULED-UTC-20181015T020000
4. Installation
4.1. Pre-requisites
An installation should only proceed if the following prerequisites are met on each Backup Plugin node:
-
Hadoop Cluster CDH (5.12.0 - CDH 5.14.0) or HDP (2.6.0 - HDP 2.6.4)
-
WANdisco Fusion 2.12.2 or later
-
Java 8
It’s extremely useful complete some work before you begin a Backup deployment. The following tasks and checks will make installation easier and reduce the chance of an unexpected roadblock causing the installation to fail.
It’s important to make sure that the following elements meet the requirements that are set in the Fusion Pre-requisites.
4.1.1. Server OS
One common requirement that runs through much of the deployment is the need for strict consistency between Backup nodes. Your nodes should, as a minimum, be running with the same versions of:
-
Hadoop/Manager software.
-
Linux.
-
Check to see if you are running a niche variant, e.g. Oracle Linux is compiled from RHEL but it is not identical to a RHEL installation.
-
-
Java 8 is required for Backup.
-
Ensure all nodes are running the same version of Java 8, on consistent paths.
-
4.1.2. Hadoop Environment
Confirm that your Hadoop clusters are working.
-
Ensure that as part of your base Fusion installation, the node has a "fusion" system user account and group for Fusion services to run under on all Fusion nodes.
4.1.3. System Requirements
System requirements are as noted in the Fusion user guide.
| Note that the inclusion of Backup should not significantly change your platform’s data storage requirements as snapshots only store diffs rather than full copies of data. |
4.2. Installation
This section runs through the steps required for getting Fusion Backup.
| Apply these steps to all nodes in a zone. You can install Backup plugin across multiple zones but each zone will use its own backup schedules. |
4.2.1. Installation components
The installation script contains an archive/RPM package with the following contents. You don’t need to interact with these files, they’re listed here only for reference.
# rpm -qlp fusion-backup-plugin-hdfs-2.0.0.2.el6.noarch.rpm /opt/wandisco /opt/wandisco/fusion /opt/wandisco/fusion/plugins /opt/wandisco/fusion/plugins/fusion-backup /opt/wandisco/fusion/plugins/fusion-backup/backup-adk-clientui-2.0.0.2.jar /opt/wandisco/fusion/plugins/fusion-backup/backup-adk-strategy-2.0.0.2.jar /opt/wandisco/fusion/plugins/fusion-backup/backup-hdfs-strategy-2.0.0.2.jar /opt/wandisco/fusion/plugins/fusion-backup/fusion-backup-plugin-2.0.0.2.jar /opt/wandisco/fusion/plugins/fusion-backup/guava-15.0.jar /opt/wandisco/fusion/plugins/fusion-backup/log4j-1.2.17.jar /opt/wandisco/fusion/plugins/fusion-backup/slf4j-api-1.7.21.jar /opt/wandisco/fusion/plugins/fusion-backup/slf4j-log4j12-1.7.21.jar
4.2.2. Install the plugin
-
Obtain the Fusion Backup installer from WANdisco and open a terminal session on your Fusion node.
Ensure the downloaded file is executable e.g.# chmod +x backup-plugin-installer-2.0.0.2.sh EnterRun the Backup Plugin installer e.g.# sudo ./backup-plugin-installer-2.0.0.2.sh Enter -
Enter "Y" and press Enter to kick off the installation. Once the installation is completed, the installer will offer to perform a necessary Fusion server restart. You can enter "y" to permit this or hold off the restart until later by entering "N".
# ./backup-plugin-installer-2.0.0.2.sh Verifying archive integrity... All good. Uncompressing WANdisco Live Backup............... :: :: :: # # ## #### ###### # ##### ##### ##### :::: :::: ::: # # # # ## ## # # # # # # # # # ::::::::::: ::: # # # # # # # # # # # # # # ::::::::::::: ::: # # # # # # # # # # # ##### # # # ::::::::::: ::: # # # # # # # # # # # # # # # :::: :::: ::: ## ## # ## # # # # # # # # # # # :: :: :: # # ## # # # ###### # ##### ##### ##### You are about to install WANdisco Live Backup version 2.0.0.2 Do you want to continue with the installation? (Y/n) yes wd-backup-plugin-2.0.0.2.tar.gz ... Done fusion-ui-backup-plugin-2.0.0.2-dist.tar.gz ... Done fusion-backup-plugin-hdfs-2.0.0.2.el6-110.noarch.rpm ... Done All requested components installed. Running additional post install actions... Restarting fusion-server is required as part of plugin activation Do you wish to restart fusion-server now? (y/N) y Restarting WANdisco Fusion Server: fusion-server Stopped WANdisco Fusion Server process 27490 successfully. Started WANdisco Fusion Server process successfully. Go to your WANdisco Fusion UI Server to complete configuration. -
Ensure that you repeat the installation on all Fusion nodes in the zone. Once Fusion Backup is installed on all nodes within a zone, it will automatically activate.
See the Troubleshooting section for how to check the Plugin’s status.
4.3. Activate Backup
Backup will automatically activate when it has been installed on all Fusion nodes within a zone.
4.4. Validation
-
Create a test backup schedule. Follow the procedure to Schedule a backup.
-
Verify that the snapshot policy has been created, e.g.
http://fusion-node-domain.com:8082/plugin/backup/getPolicy?path=/replicated/directory
-
When the backup is created a Backup available label will appear on the Replicated Directories screen. Open a terminal and check that the snapshot is in place, e.g.
hdfs dfs -ls /replicated/directory/.snapshot drwxrwxrwx - hdfs supergroup 0 2018-10-22 12:10 /replicated/directory/.snapshot/fusion-SCHEDULED-UTC-<timestamp>
4.5. Uninstallation
The following procedure removes Backup from a node.
| Apply these steps to all nodes in a zone. |
-
Stop the Fusion core and UI servers, e.g.
service fusion-server stop service fusion-ui-server stop
-
Remove the plugin using the package manager command applicable to your environment, e.g.
yum erase -y fusion-backup-plugin-hdfs*
-
Remove the plugin installation files, e.g.
rm -rf /opt/wandisco/fusion-ui-server/ui-client-platform/plugins/wd-backup-plugin/
rm -rf /opt/wandisco/fusion-ui-server/plugins/fusion-ui-backup-plugin-2.0.0.2/
-
Start the Fusion servers, e.g.
service fusion-server start service fusion-ui-server start
-
Login to the Fusion UI and check the Plugins section under the Settings tab to ensure the plugin has been removed.
-
Repeat the steps on each node in the zone.
5. Operation
This section describes how to use Backup to schedule backups.
5.1. Configuration
You can select to have Backup plugin create snapshots of any number of selected directories on any number of zones, based on schedules that may differ on each zone. Backed up content is stored in a timestamped location directory, by default it is located here:
/<replicated-directory>/.snapshot/fusion-scheduled-UTC-20180910T225424/dir/file
The following rules apply for taking snapshots.
-
In HDFS, the .snapshot directory and all its contents are set to read only, so no edits can be made to snapshots. If a Replicated Directory can be snapshotted, then the directory owner or the HDFS superuser are the only system user that may create the snapshot.
-
You cannot snapshot a subdirectory of a Replicated Directory that is already being snapshotted.
| Although there’s currently no mechanism for manually triggering a backup, you may trigger one manually via HDFS Snapshotting, and providing that you specify the .snapshot directory as the save location. |
5.2. Administration
5.2.1. Backup tab
When Backup is installed on all nodes within a zone, the plugin will automatically activate. Once activated, a backup tab will be appear on all Replication Rules screens.

Backup Status
The backup status of each Replication Rule is noted as a label on the Replication Rules list.
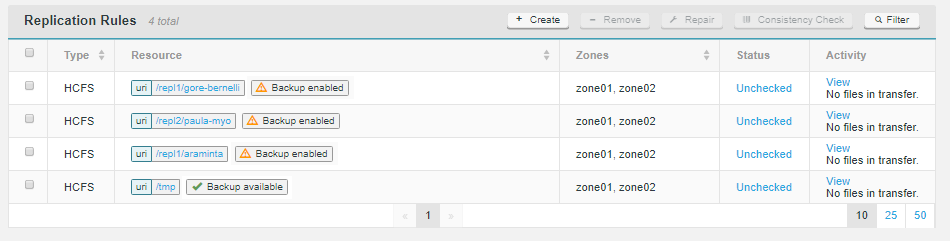
- Backup available
-
the replication rule’s file path can be backed up.
- Backup enabled
-
a backup schedule is in place on this replication rule.
Reports the status of the following:
- Last backed up…
-
This shows you when the last backup was created, in terms of how long ago, followed by the specific date and time.
- Next scheduled backup in…
-
Shows how long till the next scheduled backup, followed by the date and time.
Schedule Backup
Schedule a backup for this replication rule at an interval. Note that schedule time is in UTC.
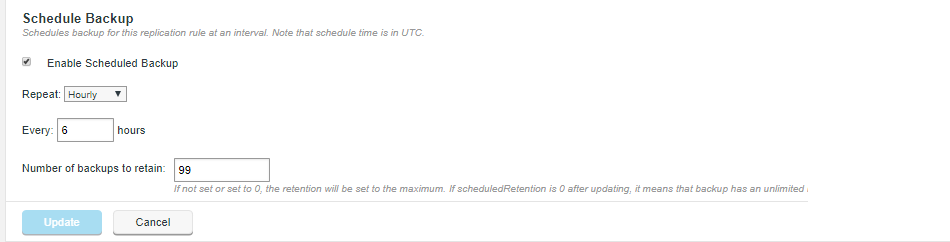
- Enable Scheduled Backup [Checkbox]
-
Tick this checkbox to enable a periodic backup, based on your provided schedule settings.
Scheduled backup settings
- Repeat [Dropdown]
-
Select from the available dropdown values - Hourly, Daily and Weekly.
- Every date at
-
Provide time increments that correspond with your selected Repeat.
Hourly - Every x hours (select a number of hours)
Daily - Every day at x : y (hours and minutes)
Weekly - Every x at y: z (day, hours and minutes) - Number of backups to retain
-
Sets the limit of how many backups to store. When this number of backups is reached, each new backup will replace the oldest of the stored backups. For the maximum number of permitted backups (65,536), leave the entry field blank or set to 0.
| Setting no limit to backup may consume large amounts of storage. Ensure that your system has a suitable monitor in place to ensure that storage space doesn’t get exhausted. |
5.2.2. Setting up a backup
Use this procedure for setting up a backup. Remember, backups are not replicated, they are created per-zone.
-
Select or create a replication rule. Click on the rule.
 Figure 7. click on rule
Figure 7. click on rule -
Click on the backup tab.
 Figure 8. click on backup tab
Figure 8. click on backup tab -
Enter the backup settings (detailed here) and tick the Enable schedule checkbox.
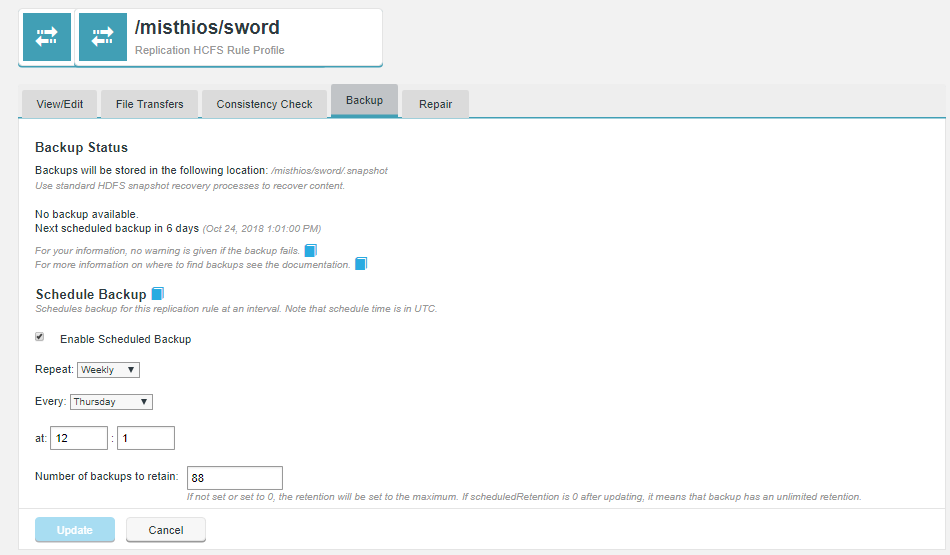 Figure 9. Tick Enable Scheduled Backup
Figure 9. Tick Enable Scheduled Backup -
You can view the resulting Schedule Policy via the following API call through your browser:
http://docs01-vm1.bdfrem.wandisco.com:8082/plugin/backup/getPolicy?path=/misthios/sword
backup policy output<policy> <path>/misthios/sword</path> <schedule>0 1 12 ? * 4</schedule> <scheduledRetention>88</scheduledRetention> <requestedCapacity>0</requestedCapacity> </policy>
| The requestedCapacity property is not yet supported. It will be used in a future version of Backup for requested (non-scheduled) backups. |
See more examples in the REST API section.
5.2.3. Recovering data from a backup
To recover accidental deletion or data error, replicated data is restored by copying the applicable data from its snapshot’s path, e.g.,
hdfs dfs -cp /replication/path/.snapshot/<snapshot name> /snapshotted/data/
This will restore the lost set of files and directories to the working data set.
| Recovering from backups won’t work like a version control system, files and directories are not deleted if you recovery data from a point in time earlier than those files/directories were created. |
Performing a data Recovery (Command-line)
Once you identify where data has been deleted/mistakenly overwritten or corrupted, use the following procedure to complete a recovery:
-
Login to the node on which you need to make the repair using the appropriate system user, in this example, running as hdfs.
-
Check the location of the data that you intend to recover. In this example, the contents of a file "zeus.dat" in the directory kronos/children have been mistakenly blanked.
hdfs dfs -ls /kronos/children/.snapshot Found 3 items drwx------ - hdfs supergroup 0 2018-10-18 13:17 /kronos/children/.fusion -rw-r--r-- 3 hdfs supergroup 33551597 2018-10-18 13:17 /kronos/children/demeter.dat -rw-r--r-- 3 hdfs supergroup 33551597 2018-10-18 13:17 /kronos/children/hades.dat -rw-r--r-- 3 hdfs supergroup 5 2018-10-22 10:52 /kronos/children/zeus.dat
-
To recover the file, identify which stored backup is suitable for recovery, you may need to check back further than the latest snapshot, depending on when the mistaken overwrite occurred. You could use the snapshotDiff command to compare snapshots to see which snapshot to use for the recovery. See Using snapshotDiff.
hdfs dfs -ls /kronos/children/.snapshot Found 87 items ... drwxrwxrwx - hdfs supergroup 0 2018-10-22 02:00 /kronos/children/.snapshot/fusion-SCHEDULED-UTC-20181022T020005 drwxrwxrwx - hdfs supergroup 0 2018-10-22 03:00 /kronos/children/.snapshot/fusion-SCHEDULED-UTC-20181022T030000 drwxrwxrwx - hdfs supergroup 0 2018-10-22 04:00 /kronos/children/.snapshot/fusion-SCHEDULED-UTC-20181022T040000
Search/grep the available snapshots for the version of zeus.dat that we want to restore.
-
Having decided that the snapshot created at 02:00 is the last one to store the correct version of zeus.dat, run the following command. Note that the -f is required to force the overwrite of the incorrect version of zeus.dat, you wouldn’t need this if the file has been deleted.
hdfs dfs -cp -f /kronos/children/.snapshot/fusion-SCHEDULED-UTC-20181022T020005/zeus.dat /kronos/children/
-
Recheck the hdfs directory to confirm the restored file is in place.
hdfs dfs -ls /kronos/children/ Found 4 items drwx------ - hdfs supergroup 0 2018-10-18 13:17 /kronos/children/.fusion -rw-r--r-- 3 hdfs supergroup 33551597 2018-10-18 13:17 /kronos/children/demeter.dat -rw-r--r-- 3 hdfs supergroup 33551597 2018-10-18 13:17 /kronos/children/hades.dat -rw-r--r-- 3 hdfs supergroup 33551597 2018-10-22 11:03 /kronos/children/zeus.dat
5.3. Troubleshooting
5.3.1. How to check the plugin’s status
You can confirm that the plugin has been successfully installed by checking the Plugins section of the Settings tab.

There is a Plugins Status panel of the Fusion UI Dashboard:

5.3.2. If a backup fails
No warnings are generated through the Fusion UI that will tell you that a backup has not been created. If error logging is required you will need to set this up using external tooling and processes.
A backup may fail in the following circumstances:
-
Replicated directory is removed.
-
Replicated directory is set to no longer support the creation of hcfs snapshots.
-
Replication directory permissions are adversely changed.
-
Available storage space is exhausted.
6. Reference Guide
6.1. HDFS snapshots
6.1.1. Snapshottable Directories
Snapshots can be taken on any directory once the directory has been set with the appropriate properties for allowing snapshots to be created.
-
Such a directory can accommodate a maximum of 65,536 snapshots.
-
There is no limit on the number of snapshottable directories.
-
Administrators may set any HDFS directory to be snapshottable.
-
If there are snapshots in a snapshottable directory, the directory can not be deleted or renamed before all the snapshots are deleted.
-
Once a snapshot directory is in place, you can not create another snapshot directory in either a subdirectory or a parent directory.
Nested snapshot directories are currently not supported.
6.1.2. Snapshot tips and tools
Snapshots are read-only
Since snapshots are read-only, HDFS will also protect against user or application deletion of the snapshot data itself. The following operation will fail:
hdfs dfs -rm -r /replication/path/.snapshot/<snapshot name> /snapshotted/data/
Listing snapshottable hdfs directories
Use the lsSnapshottableDir command to list all the directories for which the current user has permission to create snapshots.
[hdfs@docs02-vm1 root]$ hdfs lsSnapshottableDir drwxr-xr-x 0 hdfs supergroup 0 2018-10-22 13:00 25 65536 /gaia drwxr-xr-x 0 hdfs hdfs 0 2018-10-22 13:00 10 65536 /repl1 drwxrwxrwx 0 hdfs supergroup 0 2018-10-22 13:00 90 65536 /kronos/children drwxr-xr-x 0 hdfs supergroup 0 2018-10-20 09:55 1 65536 /misthios/helm drwxr-xr-x 0 hdfs supergroup 0 2018-10-18 14:22 1 65536 /misthios/spear drwxr-xr-x 0 hdfs supergroup 0 2018-10-21 11:22 1 65536 /misthios/sword
Using snapshotdiff
The snapshotDiff command to list differences between two snapshots, e.g.
hdfs snapshotDiff <path> <fromSnapshot> <toSnapshot>
Example
hdfs snapshotDiff /kronos/children fusion-SCHEDULED-UTC-20181018T140000 fusion-SCHEDULED-UTC-20181022T130000 Difference between snapshot fusion-SCHEDULED-UTC-20181018T140000 and snapshot fusion-SCHEDULED-UTC-20181022T130000 under directory /kronos/children: M . + ./zeus.dat - ./zeus.dat M ./.fusion/fdb55089-d2d7-11e8-ae1f-fe6664333694 + ./.fusion/fdb55089-d2d7-11e8-ae1f-fe6664333694/metadata M ./.fusion/fdb55089-d2d7-11e8-ae1f-fe6664333694/gsn/d0 + ./.fusion/fdb55089-d2d7-11e8-ae1f-fe6664333694/gsn/d0/2776 + ./.fusion/fdb55089-d2d7-11e8-ae1f-fe6664333694/gsn/d0/2777 + ./.fusion/fdb55089-d2d7-11e8-ae1f-fe6664333694/gsn/d0/2779 + ./.fusion/fdb55089-d2d7-11e8-ae1f-fe6664333694/gsn/d0/2791 <SNIPPED>
Create Snapshots
You can manually create a snapshot outside of your backup schedule by using the following command.
hdfs dfs -createSnapshot path [snapshot-name]
| By design, you can’t create manual snapshots in the .snapshot directory. If you want to create manual backups, create a subdirectory for this purpose. |
E.g.
hdfs dfs -mkdir /kronos/children/manual.snapshots/ fusion-backup-REQUSTED-2018102411110000
6.2. API
Fusion Backup offers increased control and flexibility through a RESTful (REpresentational State Transfer) API.
Below are listed some example calls that you can use to guide the construction of your own scripts and API driven interactions.
|
API documentation is still in development:
Note that this API documentation continues to be developed. Contact our support team if you have any questions about the available implementation.
|
Note the following:
-
All calls use the base URI:
http://<host>:<post>/plugin/backup
-
The internet media type of the data supported by the web service is application/xml.
-
The API is hypertext driven, using the following HTTP methods:
| Type | Action |
|---|---|
POST |
Create a resource on the server |
GET |
Retrieve a resource from the server |
PUT |
Modify the state of a resource |
DELETE |
Remove a resource |
Available API REST endpoints are listed below.
6.2.1. enableBackup
Enable backup on the Replicated Directory of the current zone. Internally, this just updates the storage policy.
Type: PUT
Path: /enableBackup
Parameters
Required:
-
String path
-
String schedule
-
int scheduleRetention
Optional:
-
int requestedCapacity
example
curl --negotiate -u : -v -s -X PUT "Content-Type: application/xml" "http://<hostname>:<port>/plugin/backup/enableBackup?path=/<filepath>&schedule=<schedule-in-cron-format>&scheduledRetention=<numberOfBackupsStored>"
Sets the following parameters:
- path
-
the path to the replicated folder
- schedule
-
Cron schedule for backup
- scheduleRetention
-
The maximum number of scheduled backups to be stored
| Consider the following hard limit: scheduleRetention + manualCapacity < 65536. |
<backupPolicy>
<schedule>0/5+14,18,3-39,52+*+?+JAN,MAR,SEP+MON-FRI+2002-2010</schedule>
<scheduledRetention>10</scheduledRetention>
<requestedCapacity>15</requestedCapacity>
</backupPolicy>
6.2.2. disableBackup
Disables backup on the Replicated Directory of the current zone. Internally, this just updates this storage policy.
Type: PUT
Path: /disableBackup
6.2.3. getPolicy
Gets the policy for all paths or for a given path when specified.
Parameters
Required:
String path (defaults to retrieving all snapshot policies for a zone, but if a path is supplied, this REST call will retrieve just the snapshot policy of that path)
Examples:
All policies:
curl --negotiate -u : -v -s -X GET "Content-Type: application/xml" "http://<hostname>:<port>/plugin/backup/getPolicy"
Policy for one path:
curl --negotiate -u : -v -s -X GET "Content-Type: application/xml" "<hostname>:<port>/plugin/backup/getPolicy?path=/replDir"
6.2.4. updatePolicy
Updates an existing policy for a path.
Parameters
Required:
-
String path of replicated directory with enabled backups
-
At least one of the two optional parameters:
-
String schedule
-
Long retention
-
Examples:
curl --negotiate -u : -v -s -X PUT "Content-Type: application/xml" "http://<hostname>:<port>/plugin/backup/updatePolicy?path=/<replDir>&schedule=<schedule-in-cron-format>&scheduledRetention=<numberOfBackupsStored>"